このドキュメントでは、次のトピックについて説明します。
次の図に、Unicode データおよびパラメータがどのようにアクセスされるかを示します。
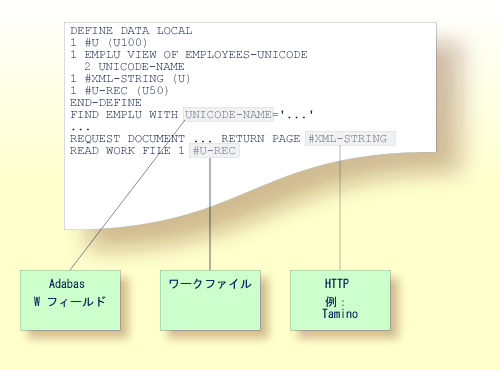
Natural を使用すると、Adabas データベースのワイド文字フィールド(フォーマット W)にアクセスできます。
- データ定義モジュール
Adabas ワイド文字フィールド(W)は、Natural データフォーマット U(Unicode)にマップされます。
- アクセスコンフィグレーション
Natural は Adabas からデータを受け取り、共通のエンコードとして UTF-16 を使用してデータを Adabas に送ります。
このエンコードは、
OPRBパラメータによって指定され、オープン要求によって Adabas に送信されます。これはワイド文字フィールドに使用され、Adabas ユーザーセッション全体を通して適用されます。
詳細については、『プログラミングガイド』の「Adabas データベースのデータへのアクセス」の「Unicode データ」を参照してください。
以下では次のトピックについて説明します。
次の情報は、ステートメント WRITE WORK FILE に適用されます。このステートメントの詳細については、『ステートメント』ドキュメントを参照してください。
次のワークファイルタイプによって、コードページデータが書き込まれます。
ASCII および圧縮 ASCII
Unformatted
CSV
Entire Connection
ワークファイルタイプおよびコードページは、コンフィグレーションユーティリティで定義される必要があります。詳細については、『コンフィグレーションユーティリティ』の「ワークファイル設定」を参照してください。
オペランド A(英数字)および U(Unicode)で定義されたすべての Natural データは、指定されたコードページに変換されます。コードページが指定されていない場合、すべてのデータは CP パラメータで定義されたデフォルトコードページに変換されます。
注意:
ワークファイルでは、書き込まれるすべての A および U オペランドデータは、コードページフォーマットです。
U オペランドデータをこれらのワークファイルに書き込み、後でこれらのワークファイルからデータを欠落させずに読み取る必要がある場合、UTF-8 をコードページとしてコンフィグレーションユーティリティで定義する必要があります。この場合、すべての A
および U オペランドデータは、UTF-8 フォーマットで書き込まれます。ワークファイルもコードページ UTF-8 を使用して設定されている後続の READ WORK
FILE ステートメントによって、オペランド U データはデータを欠落させずに読み取られます。
注意:
上記のワークファイルタイプのいずれかが指定され、ワークファイルに対してコードページ UTF-8 が定義された場合、ワークファイル属性 BOM(バイトオーダマークを書き込む)および NOBOM(バイトオーダマークを書き込まない)が有効になります。これらの属性は、コンフィグレーションユーティリティの Work
Files カテゴリで、DEFINE WORK FILE ステートメントを使用して指定できます。ワークファイルに対してコードページ UTF-8 が定義され、ワークファイル属性 BOM が指定された場合、UTF-8 バイト順マーク(16 進表示:H'EFBBBF')がワークファイルの先頭、ワークファイルデータの前に書き込まれます。
上記のワークファイルタイプ以外のワークファイルタイプがワークファイルの書き込みに使用された場合、またはワークファイルに対して UTF-8 以外のコードページが定義された場合は、ランタイム時に属性 BOM の指定は無視されます。次の表に、ステートメント WRITE WORK FILE および READ
WORK FILE の処理でのランタイム時の動作を示します。
| コードページおよび属性の設定 | WRITE WORK FILE |
READ WORK FILE |
|---|---|---|
|
ワークファイルにコードページ UTF-8 が指定されていません(デフォルト)。 ワークファイル属性 |
UTF-8 バイトオーダマークが書き込まれていません。 UTF-8 への変換は行われません。 |
UTF-8 バイトオーダマークの確認は行われません。 UTF-8 からの変換は行われません。 |
|
ワークファイルにコードページ UTF-8 が指定されています。 ワークファイル属性 |
UTF-8 バイトオーダマークが書き込まれています。 A および U フィールドは UTF-8 に変換されます。 |
UTF-8 バイトオーダマークを確認してください。 UTF-8 バイトオーダマークが見つかった場合、そのマークはワークファイルデータから削除されます。フィールドは UTF-8 からデフォルトコードページに変換されます。U フィールドは UTF-8 から Natural の内部ランタイム表現である UTF-16 に変換されます。 |
|
ワークファイルにコードページ UTF-8 が指定されています。 ワークファイル属性 |
UTF-8 バイトオーダマークが書き込まれていません。 A および U フィールドは UTF-8 に変換されます。 |
UTF-8 バイトオーダマークを確認してください。 UTF-8 バイトオーダマークが見つかった場合、そのマークはワークファイルデータから削除されます。フィールドは UTF-8 からデフォルトコードページに変換されます。U フィールドは UTF-8 から Natural の内部ランタイム表現である UTF-16 に変換されます。 |
次のワークファイルタイプによって、バイナリデータ(オペランドフォーマット U の UTF-16 など)が書き込まれます。
SAG
Portable
オペランド A および U で定義された Natural データは、コードページに変換されません。これらのデータは、ワークファイルにバイナリフォーマットで書き込まれます。U オペランドデータの場合、これは UTF-16 で行われます。
次の情報は、ステートメント READ WORK FILE に適用されます。このステートメントの詳細については、『ステートメント』ドキュメントを参照してください。RECORD オプションについて一覧表示されている制限に注意してください。
次のワークファイルタイプが使用されるとき、Natural U(Unicode)オペランドに読み取られるワークファイルデータは、指定されたコードページから UTF-16 に変換されます。
ASCII および圧縮 ASCII
Unformatted
CSV
Entire Connection
A(英数字)オペランドに読み取られるデータは、必要に応じて、指定されたコードページから、パラメータ CP で定義されたデフォルトコードページに変換されます。
上記のワークファイルタイプのいずれかが指定され、ワークファイルに対してコードページ UTF-8 が定義された場合、READ WORK FILE ステートメントによって、ワークファイルで UTF-8 バイトオーダマークが自動的に確認されます。ワークファイルの先頭で UTF-8 バイトオーダマークが見つかった場合、そのマークは削除されます。ワークファイルから読み取られたデータは、UTF-8
からデフォルトコードページに変換されます。
データが別のワークファイルタイプから読み取られた場合、バイトオーダマークの確認は実行されず、したがってバイトオーダマークは削除されません。
ステートメント WRITE WORK FILE および READ WORK FILE の処理でのランタイム時の動作の詳細については、前のセクションの表を参照してください。
次のワークファイルタイプが使用されるとき、ワークファイルデータは変換されずに Natural オペランド A および U に読み取られます。つまり、バイナリフォーマットで読み取られます。
SAG
Portable
ワークファイルタイプ Portable では、オペランドフォーマット U のデータのエンディアン変換がサポートされます。
オペランドフォーマット U は、一般にワークファイルタイプ転送がサポートされています。Entire Connection によって、選択されたファイルタイプの Unicode の読み取りまたは書き込みができない場合は、ランタイムエラーメッセージが表示されます。
出力ファイルの Unicode データの処理は、選択された論理デバイス(LPT1~LPT31)の出力方法によって異なり、現在は GUI(Windows のみ)または TTY です。
出力方法に関係なく、データは UTF-16 フォーマットで Natural 出力サービスに渡されます。つまり、フォーマット A フィールドデータはすでに Unicode に変換されています。
この Windows のみの出力方法では、データは Unicode(UTF-16)フォーマットで Windows プリンタドライバに渡されます。これは Windows での標準のデータ出力方法であるため、このデータはドライバによって常に適切に処理されます。したがって、この出力方法は、システムコードページに含まれない文字が使用されている場合に Windows で推奨される出力方法です。
この出力方法では、データは、デフォルトで内部(UTF-16)フォーマットからシステムコードページに変換されます。ただし、プリンタプロファイルを使用することによって、データが代わりに UTF-8 フォーマットに変換されるか、または任意の外部コードページに追加変換されることを指定できます。これらの代替手段の詳細については、『コンフィグレーションユーティリティ』の「プリンタプロファイル」を参照してください。
データをシステムコードページに変換するデフォルトの動作の理由は、現在、UTF-8 フォーマットの未加工テキストデータを直接受け取ることが可能なプリンタがないことです。