データベースシステムは、知識が豊富で経験に富んだユーザーのみが設計または使用することができる、複雑なデータ構造やデータ処理手順を伴うことが少なくありません。 一方、Adabas の構造は非常にシンプルですが、操作の効率性、設計の容易さ、定義、およびデータベースの展開が格段に優れています。
このドキュメントでは、次のトピックについて説明します。
Adabas では、フィールドが情報の論理的な最小単位(現在の給与など)で、この単位はユーザーにより定義され、参照されます。 レコードは、完結した情報のまとまりを構成する関連フィールドの集合を指します。例えば、従業員 1 人の全給与データがこれに該当します。 ファイルは、同じフォーマットを持つ関連レコードのグループを指します。ただし、例外もあるので、「単一ファイル内の複数のレコードタイプ」を参照してください。 データベースは、関連するファイルのグループを指します。
下の表は、各エンティティについて、メインフレーム Adabas がサポートする上限数を示しています。
| エンティティ | 最大値 |
|---|---|
| データベース | 65,535 |
| データベースあたりのブロック数 | 2,147,483,646(4 バイト RABN 使用) |
| データベースあたりのファイル数 | 5,000 またはアソシエータのブロックサイズから 1 を引いた値のいずれかの少ない方 |
| ファイルあたりのレコード数 | 4,294,967,294(4 バイト ISN 使用) |
| レコードあたりのフィールド数 | 926 |
| 非圧縮レコード長 | オペレーティングシステムによって異なる |
| 圧縮レコード長 | データストレージブロックサイズ
スパンドレコードは Adabas バージョン 8 以降でサポートされており、1 つの論理レコードを複数の物理レコードに分割します。分割後の各物理レコードは、1 個のデータストレージ(DS)ブロックより小さくなります。 詳細は、「スパンドレコードのサポート」を参照してください。 |
単一の Adabas データベースに割り当てられたディスクストレージスペースは、論理 Adabas ファイルにセグメント化されます。 データベース内のスペース全体のうち、特定の部分が、各論理ファイルに割り当てられます。 ファイルのレコードを格納すると、スペースに空きがなくなる場合には、共通のフリースペースプールから追加のスペースが自動的に割り当てられます。 このダイナミックなスペース割り当てと、解放されたスペースのダイナミックなリカバリを併用すると、特に操作しなくても Adabas データベースを長期間にわたって実行できます。
ディスクドライブ全体にわたってのデータベーススペースの分配は、スペースを複数の独立したデータセットに物理的にセグメント化することによって制御されます。 すべての物理データベーススペースが使用されて空きがなくなった場合、追加のデータセットがダイナミックに割り当てられるか、既存のデータセットのサイズが増加されるため、新しい物理ファイルは、データベース全体を再編成することなくロードされます。
データとアクセス構造の分離をサポートするため、Adabas ニュークリアスは次の 3 つのデータベースコンポーネントを使用します。
このセクションでは、これらの各データベースコンポーネントについて説明します。
データストレージは、ブロックに分割されます。各ブロックは、3 または 4 バイトの相対 Adabas ブロック番号(RABN)によりブロックの物理的な場所がコンポーネントの先頭から相対的に識別されます。 データストレージのブロックには、1 つ以上の物理レコード、およびブロックのレコードを拡張するための予備スペースとしてパディングエリアが含まれています。
各物理レコードの先頭の 4 バイトに格納されている論理 ID には制御情報のみが含まれ、データブロックに格納されます。 この内部シーケンス番号(ISN)により、各レコードは一意に識別され、変更されることはありません。 レコードが追加されると、既存の最も大きな ISN に 1 を加えた ISN が割り当てられます。 レコードが削除されると、そのレコードの ISN は再利用されます。これは Adabas に再利用を設定した場合のみ行われます。 ISN の再利用は、一部の検索においてシステムのオーバーヘッドを削減するため、頻繁に追加や削除が行われるレコードを含むファイルには ISN の再利用が推奨されます。
各ファイルごとに、各ブロックの 1~90 %(デフォルトは 10 %)がパディングエリアとして割り当てられます。この値は、予想される更新の量および種類によって決定されます。 この予約済みスペースにより、レコードは他のブロックに移行することなく拡張できるため、システムのオーバーヘッドの削減が可能になります。
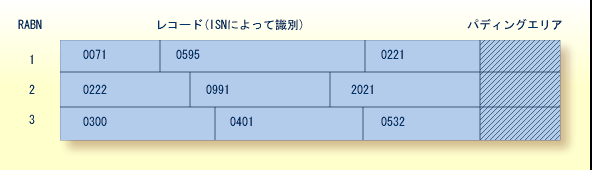
レコードが大きくなり、ブロックに収まらなくなった場合、新しい場所に移行されます。 レコードが移行または削除されると、最後のレコードとパディングエリアの間に空きスペースができます。 次の図は、ISN 0401 のレコードが大きくなりブロックに収まらなくなったため、他のブロックに移行されて作成された空きスペースを示しています。
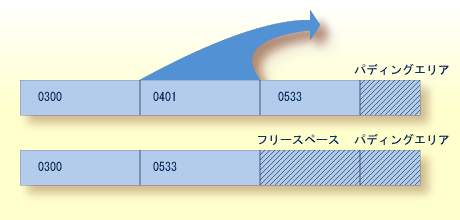
空きスペースを再利用するように Adabas を設定できます。 スペースを再利用すると、Adabas は検索中により少ない物理ブロックを読むだけで済み、コンピュータの処理時間が節約されます。 これは、すべてのファイルに対して推奨されます。
データ圧縮により、必要なストレージの量が大幅に削減されます。 また、1 回の物理的な転送で送信できる情報量が増加するため、I/O 効率が向上します。
Adabas では、データレコードを圧縮形式で保持します。 圧縮には、数種類のオプションがサポートされています。
デフォルトの圧縮
空値省略
固定フォーマット
フォワードまたは接頭辞インデックス圧縮
最初の 3 つのオプションは、フィールドレベルで定義および実行されます。空値省略および固定フォーマット圧縮はフィールドオプションとして追加されます。
4 番目のオプションのフォワードまたは接頭辞インデックス圧縮は、アソシエータのインバーテッドリストに含まれるディスクリプタ値を圧縮します。 このオプションは、ファイルまたはデータベースレベルで実装できます。この場合、ファイルごとに別々の設定を行うことができます。ファイルレベルの設定の方がデータベースレベルの設定よりも優先度が高くなります。 フォワードインデックス圧縮オプションは、ADALOD ユーティリティを使用して設定されます。また、ADAORD ユーティリティを使用して変更できます。 この圧縮オプションについては、の「インバーテッドリスト」で詳細に説明されています。
フィールドオプションとして追加される空値省略および固定フォーマットオプションについては、「データ圧縮オプション FI および NU」で説明されています。
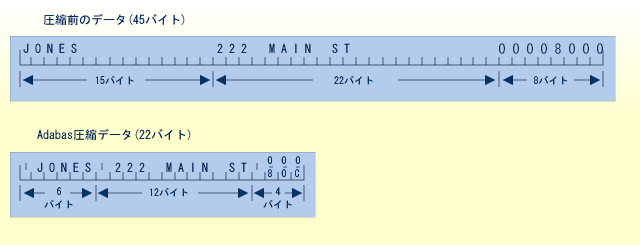
デフォルトの圧縮は、英数字フィールドの末尾の空白、およびバイナリフィールドの先行のゼロを削除します。 フィールドの先頭の包括長さバイト(ILB)は、ILB 自身を含む、格納されている総バイト数を示しています。 したがって、20 文字長で定義されデフォルト圧縮が設定された "名前 "フィールドに "Susan" が入力された場合、格納されるサイズは、文字が 5 バイト、ILB が 1 バイトの合計 6 バイトとなります。 また、レコードに含まれる空値フィールドは格納されず、空値フィールドは 1 バイトの空値フィールドカウンタ(EFC)に置き換えられます。 Adabas では、16 進数の 1 バイトに最大 63 個の連続した空値フィールドを格納できます。
多くの Adabas ファイルでは、未加工データが使用するスペースの 50~60 %のスペースしか必要ではありません。 アソシエータに格納されるアクセス構造用に約 25 %が追加されても、Adabas に必要なストレージは、データの圧縮を行わない従来のファイルストレージまたは DBMS よりも少ない容量で済みます。
アソシエータは、データストレージ内のデータにアクセスするために必要な構造を保存するときに使用するまとまったユニットです。 アソシエータには次の要素が含まれます。
データベース用の 2 つのジェネラルコントロールブロック(GCB)。 GCB は、データベースの物理的な特性に関する情報を提供します。例えば、データベース ID(DBID)、ロードされたファイル数、アソシエータ、データストレージおよびワークエクステントの数、アソシエータ、データストレージおよびワークデバイスのタイプ、システムファイル情報、データストレージスペーステーブル(DSST)のエクステント、データベースのバージョンインジケータなどが含まれます。
各ファイル用の個別のファイルコントロールブロック(FCB)。 FCB は、データベースファイルの物理的な特性および関連する RABN を識別します。 その内容には、ファイル名、ファイル番号、現在のファイルステータス、ISN の再使用設定、スペースの再使用設定、MINISN および MAXISN 設定、最初の空き ISN、およびファイルに対する更新回数が含まれます。 さらに、最初の RABN、最後の RABN、および最初の未使用 RABN が FCB に格納されます。
各ファイル用のフィールド定義テーブル(FDT)、物理的にカップリングされたファイル用のカップリングリストなど、データベースを制御および維持するために必要なすべてのテーブル。 FDT の詳細は、「レコードおよびフィールドの定義」を参照してください。 物理的にカップリングされたファイルの詳細は、カップリングファイル」を参照してください。
データベース内の各ファイルに含まれるディスクリプタ用のインバーテッドリスト、および各ファイル用のアドレスコンバータ。
ファイルにスパンドレコードが使用されている場合はセカンダリアドレスコンバータ。
インバーテッドリストは、Adabas 検索コマンドの解決および論理順のレコード読み込みに使用されます。キーフィールドまたは ディスクリプタとして設計された Adabas ファイル内のフィールドごとに構築および維持されます(「ディスクリプタオプション DE、UQ、および XI」を参照)。 ISN ではなく、ディスクリプタ値の順で並べられているため、インバーテッドリストと呼ばれます。 このリストは、ノーマルインデックス(NI)および、14 個までのアッパーインデックス(UI)で構成されます。
特定のディスクリプタに対するインバーテッドリストのノーマルインデックス(NI)には各値に対するエントリが含まれます。 エントリには、値、値が含まれるレコードの数、およびそれらのレコードの ISN が含まれます。
検索の効率を向上するため、アッパーインデックス(UI)レベルが必要に応じて自動的に Adabas によって作成されます。各レベルは直下レベルのインデックスを管理します。 管理対象の NI と同様に、最初のレベルの UI には、各インデックスブロックの 1 つのディスクリプタに対するエントリのみが含まれます。 その他のすべての UI レベルには、各インデックスブロックのすべてのディスクリプタのエントリが含まれます。 UI には最小サイズのスペースが必要です。最小サイズとは 2 ブロックです。
注意:
Adabas
ダイレクトアクセスメソッド(ADAM)機能を使用すると、インバーテッドリストにアクセスせずに、データストレージから直接レコードを取り出すことができます。
レコードが格納されているデータストレージブロック番号は、レコードの ADAM キーに基づきランダマイジングアルゴリズムを使用して計算されます。 ADAM
は、アプリケーションプログラム、クエリおよびレポートライタの機能に対して完全に透過的に使用されます。 詳細は、「Adabas
ダイレクトアクセスメソッド(ADAM)を使用したランダムアクセス」を参照してください。
次の図は、顧客ファイル内のディスクリプタ CITY に対する一般的なノーマルインデックスを示しています。
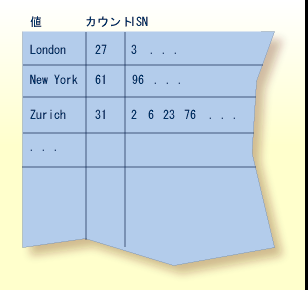
この例では、CITY が Zurich であるレコードが 31 個あることを示しています(これらのレコードの ISN は 2、6、23、76 と続きます)。
フォワード(またはフロント、接頭辞)インデックス圧縮は、インデックス値から余分な接頭辞情報を削除します。 1 つのインデックスブロック内で、最初の値は完全な長さで保存されます。 後続のすべての値については、前者と共通の接頭辞が圧縮されます。 インデックス値は、次のように表現されます。
<l,p,value>
ここでは次の内容を表しています。
| p | 前の値の接頭辞と等しいバイト数です。 |
| l | p バイトを含む残りの値の排他的な長さです。 |
例
| 圧縮前 | 圧縮後 |
|---|---|
| ABCDE | 6 0 ABCDE |
| ABCDEF | 2 5 F |
| ABCGGG | 4 3 GGG |
| ABCGGH | 2 5 H |
インデックス値の類似点とファイルサイズに基づいて、インデックス値を圧縮するかどうかを判断します。
インデックス値が類似するほど、圧縮の結果が良くなります。
小さいファイルは節約されるスペースの絶対量が小さくなるので、圧縮には向いていませんが、大きいファイルはインデックス圧縮に向いています。
ファイルのインデックス値の圧縮率がよくない場合がありますが、それでもインデックスが圧縮されていれば、圧縮されていない場合よりも必要になるインデックスブロックが少なくなります。
アドレスコンバータはレコードの物理的な場所を特定します。 インデックスは、レコードの論理 ID(ISN)を、レコードが格納されているデータストレージブロックの相対 Adabas ブロック番号にマッピングします。 スパンドレコードでは、セカンダリアドレスコンバータを使用して、セカンダリレコードが格納されているデータストレージブロックの RABN にセカンダリ ISN をマッピングします。 スパンドレコードの詳細は、「スパンドレコード」を参照してください。
アドレスコンバータには、ISN の順に並んだ RABN が含まれています。 アドレスコンバータには、RABN のみが実際に格納されているため、ISN はその相対的な位置で識別されます。
次の図は、インバーテッドリスト、アドレスコンバータおよびデータストレージの関係を示しています。 例えば、ISN が 6 のレコードの物理的な場所を特定するには、Adabas は ISN をアドレスコンバータのインデックスとして使用します。 アドレスコンバータの 6 番目のエントリは 2 です。 したがって、ISN 6 は、このファイルのデータストレージ内の物理ブロック 2 にあることがわかります。
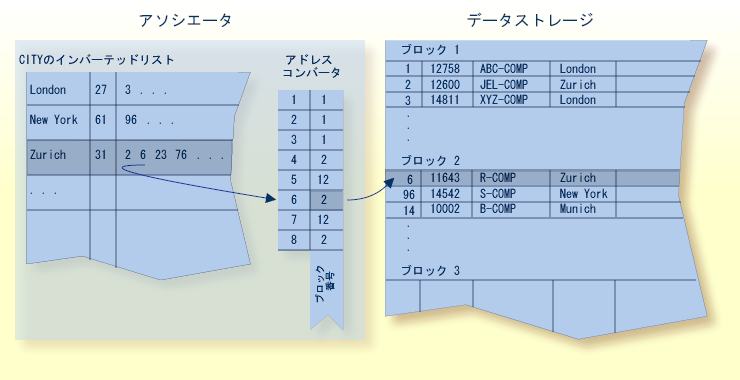
レコードが移動したり削除された場合、Adabas は自動的また透過的にアドレスコンバータを更新します。
レコードの ISN は変わることがなく、また物理ブロックアドレスはアドレスコンバータのエントリにのみ格納されているため、レコード自身がデータストレージ内で移動するときに、アドレスコンバータの更新は 1 回だけで、レコードのアクセスパスの増やす必要はありません。
レコードに多くのディスクリプタが定義されていても、各ディスクリプタに対するインバーテッドリストには ISN が含まれているため変更する必要がありません。
この処理は、いかに Adabas が検索の複雑さに関係なく迅速かつ効率的に、データストレージ内にポインタ情報を格納せずに実行できるかを示しています。
ワークワークエリアは、次の 4 つのパートに情報を格納します。
| パート | 格納するアイテム |
|---|---|
| 1 | 自動再スタートと自動バックアウト用のルーチンで必要となるデータ保護情報を格納します。 詳細は、「バックアウト、リカバリ、および再スタート」を参照してください。 |
| 2 | 検索コマンドの中間結果(ISN リスト) |
| 3 | 検索コマンドの最終結果(ISN リスト) |
| 4 | 2 フェーズコミット処理に関連したデータ |
さらに、特定の Adabas ユーティリティ(ADAINV と ADALOD)では、データのソートと中間ストレージ用に、2 つのデータセット(ソートデータセットと中間データセット)が必要になります。 その他のユーティリティの特定の機能では、中間ストレージ用の中間データセットを必要とします。
中間データセットおよびソートデータセットのサイズは、実行するユーティリティの機能により異なります。 これらのデータセットは、ジョブの実行中に割り当てと解放を行うか、永久的なデータセットを割り当てて再利用することができます。
コマンドログ(CLOG)は、発行される各 Adabas コマンドのコントロールブロックの情報を記録します。 CLOG によって作成される監査記録は、デバッグおよびリソース使用状況の監視に使用できます。 シングル、デュアル、またはマルチ(2~8)データセットを使用できます(マルチデータセットの使用をお勧めします)。
ADARUN の CLOGLAYOUT=8 パラメータを使用して作成された Adabas 8 コマンドログのタイムスタンプは、マシンタイム(GMT)で格納されます。一方、CLOGLAYOUT=5 タイムスタンプは常にローカルタイムで格納されます。 CLOGLAYOUT=8 を指定してコマンドログを作成した場合、LORECX レコードレイアウトには、CLOG レコードが書き込まれた時点のマシンタイムとローカルタイムの差が格納された時間差フィールドが含まれます。 このフィールドにより、コマンドログレコードのローカルタイムの計算が可能になります。
タイムスタンプ形式の違いにより、異なる CLOGLAYOUT 設定を用いて作成されたコマンドログを混在させたり、マージしたりすることはお勧めしません。 クラスタ環境の Adabas ニュークリアスでは、特に推奨されません。 詳細は、「CLOGLAYOUT コマンドログレイアウト」を参照してください。
プロテクションログ(PLOG)は、データベースに変更が生じたときに、レコードやその他のエレメントの変更前イメージと変更後イメージを記録します。 PLOG 情報は、再スタート後のデータベースのリカバリに使われます(最新の完了したトランザクションまたは ET まで)。 シングル、デュアル、またはマルチ(2~8)データセットを使用できます(マルチデータセットの使用をお勧めします)。
リカバリログ(RLOG)は、Adabas Recovery Aid がリカバリジョブストリームを構成するために使用する追加情報を記録します。 詳細は、ADARAI ユーティリティに関する説明を参照してください。
すべてのデータベースには、システムファイルとデータファイルが含まれます。 データファイルは、通常は必要な各レコード構造に対応して作成されます。つまり、識別されるすべての関連したフィールドのセットに対応して作成されます。
ファイルは、ADALOD ユーティリティを使用してデータベースにロードされます。 ファイル番号はデータベース内で一意である必要があります。また、MAXFILES パラメータでデータベースに対して定義された最大数を超えることはできません。 チェックポイント、セキュリティ、トリガ、およびシステムファイルは、2 バイトファイル番号を持つことができますが、5000 を超えることはできません。 物理的にカップリングされたファイルには、255 を超える番号のファイルを含めることはできません。 ファイル番号は、ユーザーによってどのような順序にも割り当てることができます。
このセクションでは、異なるタイプのデータベースファイルについて説明します。
Adabas は特定のファイルを使用して、システム情報を格納します。 ADALOD ユーティリティの FILE パラメータを使用して、Adabas システムファイルを次のいずれかとして指定することができます。
| チェックポイント | Adabas チェックポイントファイル |
| SECURITY | Adabas セキュリティファイル |
| SYSFILE | Adabas システムファイル |
| TRIGGER | Adabas トリガファイル |
ファイルカップリングにより、単一の検索コマンドを使用して、別ファイル内の指定された値を含むレコードに関連付けられた(カップリングされた)あるファイルからレコードを選択できます。
ファイル番号が 255 以下の 2 つのファイルは、同じフォーマットと長さの定義を持つ共通のディスクリプタ(「ディスクリプタオプション DE、UQ、および XI」を参照)が、両方のファイルに存在すれば、どのようなファイルでもカップリングできます。 1 つのファイルは、18 個まで他のファイルとカップリングが可能ですが、2 つのファイル間には同時に 1 個のカップリング関係だけが許されます。 自分自身とのカップリングは行うことはできません。
ファイルがカップリングされると、カップリングされた両方のファイルに対してカップリングリストがアソシエータ内に作成されます。 ファイルカップリングは、2 つのカップリングリストが各カップリング関係に対して作成され、各リストは他のファイルへカップリングされる ISN を含むため、階層的ではなく双方向的と言えます。
物理カップリングリストが作成されると、両方のファイルのすべてのキーフィールドを検索条件内で使用することができます。
ファイルの更新頻度が高い場合、物理カップリングにより、オーバーヘッドの量が多くなる可能性があります。 いずれかのファイルのレコードが追加/削除されたり、カップリングの元になるディスクリプタの更新が起きると、カップリングリストも更新しなければなりません。
物理カップリングは、次の場合の情報取得システムに有効です。
ファイルがほとんど変更されない
カップリングリストの追加オーバーヘッドが、問い合わせ作成の容易さの向上と比較すると問題とならない
ファイルが小さく、主に問い合わせに向いている
検索条件に、ファイル間のリンケージに使用されるフィールドを指定して、複数ファイルの問い合わせを行うこともできます。 これにより、Adabas がすべての必要な検索、読み込み、内部リストのマッチング操作を行います。
この方法は、物理的なファイルカップリングを必要としないことから、論理カップリングまたはソフトカップリングと呼ばれます。 論理カップリングには読み込みコマンドが必要ですが、カップリングリストによるオーバーヘッドを避けることができるため、通常ではより効果的な方法です。
Adabas データベースの構成がレコードタイプごとにファイルが 1 つずつ分かれる場合は、データベースに必要なアプリケーション機能はどのようなものでもサポートされ、問い合わせに対応するうえで操作方法が簡単になりますが、最良のパフォーマンスは得られません。
Adabas ファイルの数が増えるにつれ、Adabas コールの数も増えます。 各 Adabas コールは解釈、整合性チェックが必要であり、マルチユーザーモードではスーパーバイザーコール(SVC)およびキューイングのオーバーヘッドが必要になります。
各ファイルから、少なくとも 1 回ずつインデックス、アドレスコンバータ、データストレージブロックにアクセスするために入力/出力(I/O)オペレーションが必要になるだけでなく、レコードタイプごとに 1 ファイルを持つ構造はバッファプールを必要とします。 十分なバッファスペースが用意されていない場合、将来の要求に対して必要となるブロックが上書きされてしまう可能性があります。
重要なプログラムによって使用される Adabas ファイルの数は次の方法で削減できます。
マルチプルバリューフィールドおよびピリオディックグループの使用(「フィールドレベル」を参照)
複数の物理ファイルを 1 つの論理(拡張)ファイルにリンクする
Adabas ファイル内に複数タイプのレコードを含める
Adabas(マルチクライアント)ファイルに複数ユーザーのカテゴリのレコードを含める
データの重複を制御してリソースの使用率を抑える
このセクションでは、次のトピックについて説明します。
同じタイプのレコードが大量に存在する場合は、複数の物理ファイルに分散させる必要があります。
アクセスするファイル数を減らすために、同一フォーマットのレコードをもった複数の物理ファイルをリンクして、1 つの論理ファイルに結合することができます。 このようなファイル構造のことを拡張ファイルと呼び、この拡張ファイルを構成する物理ファイルのことをコンポーネントファイルと呼びます。 拡張ファイルは、それぞれに異なった論理 ISN の範囲を持った 128 までのコンポーネントファイルによって構成されます。 1 つの拡張ファイルのレコード数は、4,294,967,294 までです。
注意:
Adabas では、より大きいファイルサイズ、より多くの Adabas
物理ファイルやデータベースがサポートされるようになったので、拡張ファイルの必要性はほとんどなくなりました。
アプリケーションプログラムから論理ファイルがアクセスされても(ファイルのアドレスは拡張ファイルの基本コンポーネントの番号、あるいはアンカーファイル)、Adabas では基準フィールドとして定義したフィールドのデータに基づいて正しいファイルが選択されます。 このフィールドのデータは 1 つのコンポーネントファイル内でのみ、レコードをユニークに識別する特性を持ちます。 アプリケーションが拡張ファイルを更新するとき、Adabas は更新するコンポーネントファイルを決定するために書き込むレコードの基準フィールドのデータを検索します。 拡張ファイルデータを読み込むとき、Adabas は論理 ISN をキーとして使用し、正しいコンポーネントファイルを見つけます。
単一の物理レコード内で複数のレコードタイプを定義できます。各レコードタイプは、ファイルに対して定義されたフィールドのサブセットで構成される論理レコードです。 指定されたタイプに属さないフィールドは空値省略されます。
レコードタイプは次の方法で Adabas により識別されます。
別のタイプとして区別できる値でレコードタイプフィールドを定義する
タイプを区別できる既存のフィールドの値を使用する。例えば、2 つのタイプを区別するには、両方のタイプに共通なフィールドをゼロ値で 1 つのタイプとして識別し、同じフィールドをゼロ以外の値で他のタイプとして識別する方法があります。
複数のユーザーまたはユーザーのグループが使用するレコードを、マルチクライアントとして定義された単一の Adabas 物理ファイルに格納することができます。 マルチクライアント機能では、各レコードに内部的なオーナー ID をつけることで、物理ファイルを複数の論理ファイルに分割します。
オーナー ID は、ユーザー ID に対して割り当てられます。 1 つのユーザー ID は、1 つのオーナー ID しか持つことができませんが、同じオーナー ID が複数のユーザーに所属していてもかまいません。 各ユーザーは、ユーザーのオーナー ID に関連付けられたレコードのサブセットだけにアクセスできます。
注意:
RACF、CA-ACF2、または CA-Top Secret
などの外部セキュリティパッケージがインストールされている場合でも、ユーザーは変わらず Natural ETID またはログオン ID
で識別されます。
マルチクライアントファイルへのすべてのデータベース要求は、Adabas ニュークリアスにより処理されます。
物理的な冗長性を持たせると、ストレージの必要量が増えますが、パフォーマンスが向上し、複雑さを減らすことができます。 例えば、データベースの顧客注文ファイルに顧客と注文の情報を格納して、在庫ファイルに商品の詳細情報を格納し、請求書発行プログラムが顧客注文データに加えて商品の詳細情報を必要とする場合、商品の詳細情報のコピーを顧客注文ファイル内に格納すると、パフォーマンスが向上する可能性があります。
論理的な冗長性を持たせた場合も、ストレージの必要量が増えますが、複雑さを減らすことができます。 これは、あるファイルに格納する処理結果と別ファイルを関連付けることになるので、同じデータが、物理的に 2 か所に格納されるのではなく、別のファイルの内容として存在することになります。
物理的および論理的な冗長性により、更新プログラムの実行速度が遅くなります。 あるファイルを変更すると別ファイルのレコードにも影響を与える場合、別ファイルも更新する必要があるため、パフォーマンスを極度に低下させることがあります。 冗長性は、静的なデータ、またはほとんど更新されないデータのみで使用する必要があります。 マルチプルバリューフィールド、ピリオディックグループ、および単一ファイル内の複数のレコードタイプを使用して、データの冗長性を制御できます。
Adabas では、物理ファイル内のレコード構造および各フィールドの内容が、アソシエータ内に格納されているフィールド定義テーブル(FDT)で示されます。 データベースファイルごとに 1 つの FDT があります。 FDT は、Adabas コマンド実行中にファイル内のすべてのフィールド(またはグループ)の論理構造と特徴を判断するために Adabas が使用します。
スパンドレコードは Adabas バージョン 8 以降でサポートされており、1 つの論理レコードを複数の物理レコードに分割します。分割後の各物理レコードは、1 個のデータストレージ(DS)ブロックより小さくなります。 詳細は、「スパンドレコードのサポート」を参照してください。
このセクションでは、次のトピックについて説明します。
FDT には、ファイルのフィールドがレコードの物理的な順番に従って一覧表示されます。FDT の役割は、ファイルのレコードに対する簡易インデックスであり、ファイルのフィールド、サブフィールド、スーパーフィールド、およびディスクリプタ(照合ディスクリプタ、サブディスクリプタ、スーパーディスクリプタ、ハイパーディスクリプタ、およびフォネティックディスクリプタを含む)を定義します。 最小 1 個、最大 926 個のフィールド定義が指定できます。
各フィールドに関して、レベル、名前、長さ、フォーマット、オプション、特殊なフィールドおよびディスクリプタの属性についての情報が含まれます。
FIELD DESCRIPTION TABLE
I I I I I
LEVEL I NAME I LENGTH I FORMAT I OPTIONS I PARENT OF
I I I I I
------I------I--------I--------I--------------I----------------------------I
I I I I I I
1 I AA I 8 I A I DE,UQ I I
1 I AB I I I I I
2 I AC I 20 I A I NU I I
2 I AE I 20 I A I DE I SUPERDE,PHONDE I
2 I AD I 20 I A I NU I I
1 I AF I 1 I A I FI I I
1 I AG I 1 I A I FI I I
1 I AH I 6 I U I DE I I
1 I A2 I I I I I
1 I AO I 6 I A I DE I SUBDE,SUPERDE I
1 I AQ I I I PE I I
2 I AR I 3 I A I NU I SUPERDE I
2 I AS I 5 I P I NU I SUPERDE I
1 I A3 I I I I I
2 I AU I 2 I U I I SUPERDE I
2 I AV I 2 I U I NU I SUPERDE I |
FDT 内のフィールドの順番により、レコードの構成およびアクセスの効率が決まります。 フィールドの順番を決める際には、次の要因を考慮する必要があります。
頻繁にアクセスされるフィールドを FDT の先頭に置く必要があります。 この方法を応用すれば、Adabas はフィールドのアクセス時にすべてのレコードを読み取る必要が無くなるため、CPU タイムが削減されます。
同時に頻繁にアクセスされるフィールドを、1 つのグループフィールドに割り当てます。
常に同時にアクセスされるフィールドは、単一のフィールドとして定義します。 このように定義しておくと、圧縮や問い合わせ言語の使用が制限されることがありますが、内部処理が効率化されフォーマットバッファが短くなるため、処理時間が短縮されます。
必要に応じて、頻繁に空白になるフィールドは、FDT 内で順番に並べて、デフォルト圧縮または空値省略を使用します。
数値フィールドは、最もよく使用されるフォーマットでロードします。
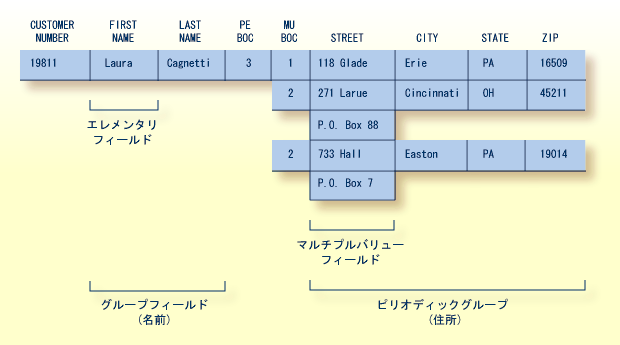
FDT 内の 2 つまたはそれ以上の連続したフィールドに同時に頻繁にアクセスする場合、グループフィールドを定義して、これらのフィールドをまとめて参照することができます。 フィールドのレベルと Adabas ショートネーム以外に、グループフィールドに定義された属性はありません。 このフィールドは、FDT 内のメンバフィールドの直前にあります。 メンバフィールドをグループフィールドに割り当てる際には、より高いフィールドレベル番号を使用します。 Adabas は 7 個までのフィールドレベルをサポートしています。 ユーザープログラムは、各メンバフィールドに個別にアクセスできます。グループフィールドを参照して、すべてのメンバフィールドに同時にアクセスすることもできます。
例えば、「レコードおよびフィールドの定義」セクションのフィールド定義テーブル(FDT)の図では、フィールド AB がグループフィールドとして定義され、レベル 1 が割り当てられています。 フィールド AC、AE、および AD はレベル 2 に割り当てられ、これらのフィールドがグループフィールド AB に属していることを示しています。 次のフィールド AF はレベル 1 に割り当てられ、このフィールドが AB グループの一部ではないことを示しています。 ユーザープログラムは、AC、AE、および AD の各フィールドに個別にアクセスできます。または、グループフィールド AB を参照して、これらのフィールドに同時にアクセスできます。
グループフィールドは、その構成フィールドが複数の値を持つことができる場合(図のフィールド AQ)、ピリオディックグループフィールドとして割り当てることができます。
フィールドは、2 文字の Adabas ショートネームにより Adabas に識別されます。このショートネームは最初の文字が英字、2 番目の文字は英数字でなければなりません。このうち E0 から E9 までは予約済みです。また特殊文字は使用できず、ファイル内でユニークである必要があります。 Adabas では、自動的にショートネームがフィールドに割り当てられますが、手動で割り当てることもできます。 Adabas では、内部でショートネームが使用され、このショートネームを使用して実際にフィールドにアクセスします。
フィールドは、長さを固定または可変にでき、値には英数字、バイナリ、固定小数点、浮動小数点、パック/アンパック 10 進数、または文字列の各フォーマットを適用できます。
フィールドの長さ(単位はバイト)およびフォーマット(1 文字のコードで表現)により、コマンド処理中に Adabas が使用する標準(デフォルト)を定義します。 この標準フォーマットは、フィールドの読み込み、更新時に、特にユーザーからの優先指定がない場合に使用されます。
フィールドの標準長がゼロの場合、そのフィールドは可変長フィールドとみなされます。 標準フォーマットはフィールドに必ず指定しなければなりません。 指定したフォーマットに従って、フィールドに対するデフォルトの圧縮処理のタイプが決められます。
指定できるフィールド長の最大値はフォーマット値によって異なります。
| フォーマット | フォーマットの説明 | 最大長 |
|---|---|---|
| A | 英数字(左づめ):「ロング英数字オプション LA」のロング英数字(LA)オプション、および「ラージオブジェクトオプション LB」のラージオブジェクト(LB)オプションも参照してください。 | 253 バイト |
| B | 2 進数(右詰め、符号なし、正の数) | 126 バイト |
| F | 固定小数点(右詰め、符号あり、一般的な形式で正の値、2 の補数形式で負の値) | 4 バイト(常に 2 または 4 バイト) |
| G | 浮動小数点(一般形式、符号あり) | 8 バイト(常に 4 または 8 バイト) |
| P | パック 10進数(右詰め、符号あり) | 15 バイト |
| U | アンパック 10進数(右詰め、符号あり) | 29 バイト |
| W | ワイド文字(左づめ):「ロング英数字オプション LA」のロング英数字(LA)オプションも参照してください。 | 253 バイト |
フィールドオプションは、2 文字のコードで指定します。指定する順番は任意で、コンマで区切ります。
| コード | オプション | 参照セクション |
|---|---|---|
| DE | フィールドがディスクリプタ(キー)であることを示します。 | ディスクリプタオプション DE、UQ、および XI |
| FI | フィールドは、固定ストレージ長です。値は、内部的な長さバイトなしで格納されます。圧縮はされません。定義したフィールド長よりもフィールドを長くすることはできません。 | データ圧縮オプション FI および NU |
| LA | 英数字またはワイド文字。可変長フィールドは、長さが 16,381 バイトまでの値を格納できます。 | ロング英数字オプション LA、LA および LB フィールドの違い |
| LB | 英数字フィールドには 2,147,483,643(約 2 GB)までのデータを格納できます。 | ラージオブジェクトオプション LB、LA および LB フィールドの違い |
| MU | 単一レコード内で、フィールドに最大約 65,534 個の値を含めることができます。 | MU および PE オプションおよびフィールドタイプ |
| NB | LA および LB フィールドのどちらからも、末尾の空白を削除(圧縮)するべきではありません。 このオプションの指定には、NU または NC の指定も必要とします。 | 空白圧縮オプション NB |
| NC | フィールドには、空値を含めることができます。SQL では、このフィールドには値がないと解釈されます。つまり、フィールドの値は未定義になり、カウントされません。 | SQL 互換性オプション NC および NN |
| NN | NC オプションを定義したフィールドには、必ず定義した値が存在しなければなりません。SQL の空値を含むことできません。 | SQL 互換性オプション NC および NN |
| NU | フィールドの空値は省略されます。 | データ圧縮オプション FI および NU |
| NV | 英数字またはワイド文字フィールドは、変換されずにレコードバッファ内で処理されます。 | エンコード変換オプション NV |
| PE | このグループフィールドは、FDT 内の連続フィールド(1 つ以上の MU フィールドを含めることができる)を定義します。これらのフィールドはレコード内で同じ順番で繰り返されます(最大約 65,534 回)。 | MU および PE オプションおよびフィールドタイプ |
| UQ | フィールドはユニークディスクリプタとなります。つまり、ファイル内のレコードごとに、ディスクリプタの値を別々にする必要があります。 | ディスクリプタオプション DE、UQ、および XI |
| XI | このフィールドでは、オカレンス(インデックス)番号が、ピリオディックグループ(PE)に設定されたユニークディスクリプタ(UQ)オプションから除外されます。 | ディスクリプタオプション DE、UQ、および XI |
ディスクリプタは検索キーです。 DE オプションは、フィールドがディスクリプタであることを示しています。 DE が指定されている場合のみ、UQ オプションを指定できます。UQ オプションは、DE フィールドが、ファイル中のレコードごとにそれぞれ異なる値(ユニークな値)を持つことを示します。 UQ フィールドが MU フィールドまたはピリオディックグループ内のフィールドでもある場合、同一レコード内で、そのフィールドの値が複数回出現する場合がありますが、異なるレコード間ではユニークである必要があります。 DE フィールドに応じて、アソシエータのインバーテッドリストにエントリが作成され、ディスクスペースが追加されたり、必要なオーバーヘッドが処理されたりします。
選択条件の中では、あらゆるフィールドを使用できます。 広範囲に使用されるフィールドが検索条件としてディスクリプタ(キー)に定義されると、選択処理が大幅に速くなります。これは、Adabas が、データストレージからレコードを読み込まずに、インバーテッドリストから直接、ディスクリプタの値にアクセスできるためです。
ディスクリプタフィールドは、検索コマンドでソートキーとして使用したり、論理的な順次読み込み処理(昇順または降順の値)を制御する方法として使用したり、ファイルカップリングの基準として使用したりすることができます。
ファイル中のいかなるフィールドもディスクリプタとして定義でき、その数には制限がありません。 マルチプルバリューフィールド、またはピリオディックグループ内のフィールドがディスクリプタとして定義された場合、レコードに対して複数のキーの値が生成されます。 キー検索は、ピリオディックグループ内の特定のオカレンスに限定される場合があります。
ディスクリプタフィールドが、ピリオディックグループ内のフィールド(PE フィールド)の一部である場合、グループインデックスは、インデックス内のディスクリプタ値の一部とみなされます。 これにより、値だけでなくグループインデックスも検索対象にすることができます。 デフォルトでは、任意の値と、レコードのあるオカレンスのグループインデックスの組み合わせは、同じ値と、別のレコードの別のグループインデックスの組み合わせとは異なるとみなされます。 グループインデックスが異なるため、これらの 2 つのオカレンスは "一意性" 条件に違反しません。 一意性条件からグループインデックスを除外したい場合は、XI オプションを使用します。 XI オプションは、ピリオディックグループ内のユニークディスクリプタに使用され、一意性の定義からオカレンス(インデックス)番号を除外します。
インバーテッドリストはディスクスペースおよび更新オーバーヘッドを必要とするため、ディスクリプタオプションは注意深く使用する必要があります。特に、ファイルが大きく、ディスクリプタとして見なされるフィールドが頻繁に更新される場合は注意が必要です。 例えば、ディスクリプタとして使用されているピリオディックグループのインバーテッドリストは、すべてのオカレンスを含むために非常に大きくなる可能性があります。
ディスクリプタは、ファイルの作成時に定義できます。または、Adabas ユーティリティを使用してファイルの作成後に定義することもできます。 ディスクリプタの定義はレコード構造から独立していて影響を受けないため、ディスクリプタは、データベースの再構築や再構成を必要とせずに、いつでも作成または削除が可能です。
ただし、ディスクリプタフィールドがレコード構造の最初に配列されず、論理的に物理レコードの終了を超えた場合、パフォーマンス上の理由から、そのレコードに対するインバーテッドリストエントリが生成されないことに注意してください。 このケースでインバーテッドリストエントリを生成するには、ファイルのアンロード(SHORT モード)、圧縮解除、そして再ロードが必要です。あるいは、アプリケーションプログラムを使用してフィールドをファイルの各レコードの最初に再配列します。
フィールドの一部をサブディスクリプタとして定義することができます。また、フィールドやその一部を組み合わせてスーパーディスクリプタとして定義することもできます。ユーザー指定のアルゴリズムに基づいて、照合ディスクリプタやハイパーディスクリプタを定義したり、発音によるエンコードアルゴリズムに基づいて、フォネティックディスクリプタを定義したりできます。フォネティックディスクリプタは、言語固有の要件に合わせてカスタマイズすることが可能です。 詳細は、「特殊なフィールドおよびディスクリプタフィールド」を参照してください。
デフォルトのデータ圧縮については、「圧縮」セクションで説明されています。 フィールドレベルでは、追加の圧縮を指定できます(空値省略オプション)。または、すべての圧縮を無効にできます(固定ストレージオプション)。
空値省略(NU)はデフォルトの圧縮とは異なり、空値省略が指定されたディスクリプタフィールドを検索すると、ディスクリプタフィールドが空白のレコードは返さません。
固定フォーマット(FI)として定義されたフィールドには、長さバイトが含まれません。また、圧縮は行われません。 このオプションを指定すると、1 バイトフィールドまたは日常的に頻繁に使用されるフィールド(個人を特定する ID を含むフィールドなど)に必要なストレージスペースを節約できます。
英数字(A)またはワイド文字(W)フォーマットのフィールドに NV オプションを指定すると、そのフィールドはユーザーとの間では変換されず、レコードバッファ内で処理されます。
このフィールドはファイルエンコードの特性を持つため、デフォルトは空白です。
A フィールドは常に EBCDIC の空白(X'40')になります。
W フィールドは常に W フォーマットのファイルエンコードの空白になります。
NV オプションは、変換しても意味のないデータ、またはアプリケーションで保管されているままのデータが必要とされるために変換すべきでないデータを含むフィールドに使用します。
NV フィールドのフィールド長は、ユーザーアーキテクチャでバイトスワップが採用されている場合、バイトスワップされます。
ロング英数字(LA)オプションは、長さがゼロの A または W フォーマットフィールドのように、可変長の英数字またはワイド文字フィールドにのみ指定できます。 LA オプションでは、このような英数字またはワイド文字フィールドに最長 16,381 バイトの値を含めることができます。
LA オプションを含む英字またはワイド文字フィールドは、このオプションを含まない英字またはワイド文字フィールドと同様に圧縮されます。 LA オプションを含むフィールドで実際に可能な最大長は、圧縮レコードを格納するブロックのサイズで制限されます。
Adabas 8(以降)では、NB(空白圧縮なし)オプションを LA フィールドに指定して空白圧縮を制御できます。
LA フィールドには、同時に LB フィールドオプションを定義することはできません。 LA および LB のどちらとしてフィールドを定義するかを決定する際に、「LA および LB フィールドの違い」を参考にしてください。
フィールドにラージオブジェクト(LB)オプションを指定すると、ラージオブジェクトフィールドにすることができます。 LB フィールドには、2,147,483,643 バイト(約 2 GB)までのデータを格納できます。 現時点では、LB フィールド全体を格納し、取り出せるだけで、LB フィールドの一部を格納し、取り出すことはできません。
LB フィールドのフォーマットは "A"(英数字)であり、そのデフォルトフィールド長は現在、0 として定義されている必要があります。
LB フィールドは、次のものにすることはできません。
ディスクリプタ、または特別なディスクリプタ(フォネティック、サブ、スーパー、またはハイパーディスクリプタ)の親
FI または LA オプションとともに定義する。
LA および LB のどちらとしてフィールドを定義するかを決定する際に、「LA および LB フィールドの違い」を参考にしてください。
サーチバッファまたはフォーマットバッファのフォーマット選択条件で、指定されたフィールド
LB フィールドは次のいずれかです。
MU、NB、NC、NN、NU、または NV オプションのいずれかで定義されたフィールド
単一グループまたは PE グループの一部にする。
LB フィールド定義に NB(非空白圧縮)フィールドオプションがあるかどうかは、文字を含む LB フィールドで末尾の空白が Adabas により削除されたかどうかを示します。
バイナリと文字の両データを含む LB フィールドがサポートされています。 NV および NB オプションの両方で定義された LB フィールドには、バイナリラージオブジェクトデータを格納できます。これは、Adabas ではバイナリ LB フィールドが変更されることがないためです。 格納されているのと同じ LB バイナリバイト文字列が、LB フィールドが読み込まれたときに取り出されます。 また、バイナリ値を含む LB フィールドは NV および NB オプションで定義されているため、Adabas では、何らかの文字コードページに従って LB フィールドバイナリ値が変換されることも、バイナリ値を含む LB フィールドで末尾の空白が削除されることもありません。
注意:
バイナリ値を含む LB フィールドの定義には、フォーマット B は使用されません。これは、一部の環境ではフォーマット B
が、バイト順の異なるバイトスワップを意味するためです。 バイトスワッピングは、バイナリ LB フィールドに適用されません。
次の表は、LB フィールドの FDT 定義の有効な例を示しています。
| FDT の指定 | 説明 |
|---|---|
1,L1,0,A,LB,NU |
フィールド L1 は、空値省略の文字型のラージオブジェクトフィールドです。 |
1,L2,0,A,LB,NV,NB,NU,MU |
フィールド L2 は空値省略、マルチプルバリュー、バイナリフィールド型のラージオブジェクトフィールドです。 |
LB フィールドを扱うコマンドの対象は、LOB ファイルグループの基本ファイルにする必要があります。 LOB ファイルに対するユーザーコマンドは拒否されます。
LB フィールドの基本的な情報については、「ラージオブジェクト(LB)フィールドの基本」を参照してください。
関連のある LA フィールドおよび LB フィールド機能を比較している次の表は、データベースのフィールドを定義する際にどちら使用するかを決定するのに役立ちます。
| 機能 | LA フィールドの動作 | LB フィールドの動作 |
|---|---|---|
| フォーマットバッファ内のゼロフィールド長指定 | 対応するレコードバッファエリア内の 2 バイトが、LA フィールドの実際の長さを格納するために使用されます。 | 対応するレコードバッファエリア内の 4 バイトが、LB フィールドの実際の長さを格納するために使用されます。 |
| データレコードストレージ | 英数字フィールドおよびワイド文字フィールドが、圧縮レコード内に格納されます。
すべての長い値は、同じ圧縮レコード内に収まらなければなりません。 シンプルデータレコードまたはスパンドデータレコードの最大長により、格納できる長い値の数および長さが制限されます。 複数の長い値がレコードに含まれると、問題となる場合があります。 |
一部の LB フィールド値(253 バイト超)は、別のラージオブジェクトファイル(LOB
ファイル)にオフラインで格納され、LOB ファイル内の LB フィールド値への参照のみがデータレコードに含まれます。 これにより、通常のフィールド、または
LA フィールドを使用するより、単一のデータレコードに長いオブジェクトを格納できるようになります。 ただし、この動作により、LB
フィールドの実行時およびファイルメンテナンスのパフォーマンスのオーバーヘッドが増加します。
小さな LB フィールド値(253 バイト以下)は圧縮レコード内に直接格納されます。 これにより、小さな値に対するパフォーマンスは向上しますが、同一の圧縮レコードに格納可能な小さな LB フィールドのオカレンス数が制限されます。 |
| フォーマットバッファ内のアスタリスク(*)フィールド長表記 | すべての長さの LA フィールドがサポートされます。 | すべての長さの LB フィールドがサポートされます。 |
| 最大長が 16,381 バイト以下の格納オブジェクト | 英数字またはワイド文字の LA フィールドを使用できます。 これにより、LB フィールドのオーバーヘッドを避けることができますが、単一レコードに格納できるフィールドの数が制限されます。 | 英数字の LB フィールドを使用できます。 |
| 最大長が 16,381 バイトを超える格納オブジェクト | サポートされません。 | 16,381 バイトを超えるオブジェクトがサポートされます。 |
| シンプルデータレコードまたはスパンドデータレコードに収まらない非常に多くのラージオブジェクト | サポートされません。 | 複数のラージオブジェクトがサポートされます。 |
Adabas では、エレメンタリフィールドとマルチプルバリューフィールドの 2 つの基本フィールドタイプがサポートされています。 エレメンタリフィールドの値は、レコードごとに 1 つだけです。 マルチプルバリュー(MU)フィールドは、1 レコードあたり 191 個(オカレンス)にするか、または最大約 65,534 個(オカレンス)にすることができます。 ファイル中で 191 個を超える MU フィールドまたは PE グループを使用することは、そのファイルが明示的に許可されている必要があります(デフォルトでは許可されません)。 この場合には、ADADBS MUPEX 機能または ADACMP COMPRESS MUPEX および MUPECOUNT パラメータを使用します。 それぞれのマルチプルバリューフィールドには、オカレンスの数を格納するバイナリオカレンスカウンタ(BOC)があります。
ピリオディック(PE)グループフィールドは、FDT 内の連続フィールドを定義します。これらのフィールドはレコード内でまとめて繰り返されます。 非ピリオディックグループフィールドのメンバ同様に PE メンバは、PE グループフィールドの直後にあり、PE フィールドより高いレベル番号を持ち、個別にも、グループとしてもアクセス可能です。 各 PE には、オカレンスの数を格納する BOC があります。
ピリオディックグループの繰り返し回数は、1 レコードあたり 191 にするか、または最大で 65,534 程度にすることができます。また、ピリオディックグループは 1 つ以上のマルチプルバリューフィールドを含むことができます。 ファイル中で 191 個を超える MU フィールドまたは PE グループを使用することは、そのファイルが明示的に許可されている必要があります(デフォルトでは許可されません)。 この場合には、ADADBS MUPEX 機能または ADACMP COMPRESS MUPEX および MUPECOUNT パラメータを使用します。 使用されないオカレンスまたは値には、ストレージスペースは不要です。
したがって、Adabas では、次の 4 種類のフィールドがサポートされています。
| レコードごとに単一の値 | レコードごとに複数の値 | |
|---|---|---|
| 単一のフィールド | エレメンタリ | MU |
| マルチプルフィールド | グループ | PE |
ファイル内の MU フィールドおよび PE グループのオカレンス数の上限は、実際にはデータストレージレコードの最大長(ADALOD MAXRECL パラメータ)によって決まり、デフォルトではデータストレージブロックのサイズから 4 を引いた数です。
レコード中の各 MU フィールドまたは各 PE グループのオカレンス数は 191 個にするか、または最大約 65,534 個にすることができます。その場合は、ADADBS MUPEX 機能または、ADACMP COMPRESS MUPEX および MUPECOUNT パラメータを使用します。 ただし、実際のオカレンス数は、データストレージレコードの最大長(ADALOD MAXRECL パラメータ)によって制限されます。デフォルトではデータストレージブロックのサイズから 4 を引いた数です。また、デバイスのタイプ、およびファイルのタイプ(スパンされているかどうか)によっても制限されます。 すべての MU フィールドおよび PE グループ、およびその他のフィールドは、1 つの圧縮レコードに収まらなければなりません。 スパンドレコード(Adabas 8 で導入)を使用すると、より多くの MU フィールドおよび PE グループを格納できます。
また、サブディスクリプタおよびスーパーディスクリプタを定義すると、レコードに含まれる MU フィールドまたは PE グループの数に影響する可能性があります。 例えば、スーパーディスクリプタが PE グループと 1 つまたは複数の MU フィールドの組み合わせとして作成されていて、オカレンス数が多い場合、パフォーマンスおよびリソースの問題が発生する可能性があります。
注意:
拡張 MU および拡張 PE フィールドの過度の使用は、パフォーマンスやリソースの問題を引き起こす場合があります。
これらの問題は、ワークストレージのオーバーフローを引き起こす可能性があり、その結果レスポンスコード 9 が返されます。
この問題が発生した場合は、データベースの ADARUN LP のサイズを増加させます。
すべての MU フィールドおよび PE グループ、およびその他のフィールドは、1 つの圧縮レコードに収まらなければなりません。 スパンドレコード(Adabas 8 で導入)を使用すると、より多くの MU フィールドおよび PE グループを格納できます。
次の図は、1 つのレコード構造内の 4 つのフィールドタイプを示しています。
PE フィールドは、別の PE グループ内でネストすることはできません。 上の図で示すように、PE グループ内での MU フィールドのネストは許可されますが、2 次元配列を導入する必要があり、プログラムが複雑になります。 また、データのアクセスと密接な関係があります。Adabas がピリオディックグループにアクセスすると、返される PE の各オカレンスに対して、MU フィールドの最初のオカレンスのみが返されます。
ピリオディックグループにはオカレンスの順番が変わらないという独特の特徴があり、この構造上の特性を活用する場合に、ピリオディックグループを使用します。 最初に 3 つのオカレンスが含まれているピリオディックグループは、第 1 または第 2 オカレンスが削除されると、それらのオカレンスが空値にセットされます。第 3 のオカレンスは、そのまま 3 番目の位置に残されます。 これとは対照的に、マルチプルバリューフィールドでは、先行する空値エントリが異なる方法で処理されます。 値の 1 つが削除された場合、マルチプルバリューフィールドの値の格納場所は、削除前と変わります。
拡張 MU または PE が制限されたファイルが作成された場合、MU フィールドまたは PE
グループのオカレンスカウントをレコードバッファの 1 バイトフィールドに読み込んではいけません。 これを行うと、Adabas はレスポンスコード
55、サブコード 9 を返します。 したがってフォーマットバッファで xxC
エレメントを使用してオカレンスカウントを読み込む(FB='MUC.' または FB='MUC,1,B.'
など)すべてのアプリケーションは、オカレンスカウントを 2 バイト以上のフィールドに読み込ませるように(FB='MUC,2,B.' または
FB='MUC,4,B.' など)変更する必要があります。
NB オプションを LA および LB フィールドとともに使用すると、空白圧縮を制御できます。 NB オプションを指定すると、フィールドの末尾の空白が削除されなくなります。指定しない場合は、英数字またはワイド文字フィールドの値の格納時に末尾の空白が削除されます。 フィールドに NB オプションを指定した場合、そのフィールドに NU オプションまたは NC オプションも指定する必要があります。NB 処理には、NC または NU の使用も同時に必要となります。
注意:
NB オプションを使用せずにフィールドを指定すると、格納したときと取り出したときのフィールドの長さが異なる可能性があります。
取り出したときの非 NB フィールドの長さは、空白圧縮のために、格納したときにそのフィールドに指定した長さよりも短くなる可能性が高くなります。
これは、値が実際は文字列ではなく、空白を表す文字コードで終わるバイナリ値であった場合に問題となることがあります。
したがって、格納したときと取り出したときのフィールドの長さを同じにしたい場合は、NB オプションを使用します。
Adabas には特別なデータ定義オプションが含まれ、Software AG のメインフレーム Adabas SQL Gateway(ACE)などの SQL データベース問い合わせ言語でも、SQL 互換の空値を表現することができます。
NC(カウントなし)オプションを指定したフィールドには、SQL がフィールドに値がないと解釈できる空値を含めることができます。 NC フィールドに空値が含まれるということは、値が入力されていないことを意味します。つまり、フィールド値は未定義になります。
この未定義の状態は、値が指定されていない非 NC フィールドに割り当てられた空値とは異なります。非 NC フィールドにおける空値は、フィールドの値が、そのフィールドのフォーマットに応じてゼロまたは空白であることを意味します。
NN(非空値)オプションは、NC が定義されたフィールドにのみ指定できます。 このオプションは、NC フィールドが常に定義済みの値を持つ必要があることを示します。SQL 空値を持つことはできません。 これにより、レコードの作成時または更新時に、フィールドが未定義のままになることを防ぎます。 ただし、フィールド値をゼロまたは空白にすることは可能です。
FDT は、フィールドが照合ディスクリプタ、サブフィールド、スーパーフィールド、サブディスクリプタ、スーパーディスクリプタ、ハイパーディスクリプタ、またはフォネティックディスクリプタの親フィールドであるかどうかを示します。 ファイル中のすべての特殊なフィールドおよびディスクリプタ(照合ディスクリプタ、サブディスクリプタ、サブフィールド、スーパーディスクリプタ、スーパーフィールド、フォネティックディスクリプタ、およびハイパーディスクリプタ)は、FDT の一部である特殊ディスクリプタテーブル(SDT)内で保持されます。
SPECIAL DESCRIPTOR TABLE
I I I I I I
TYPE I NAME I LENGTH I FORMAT I OPTIONS I STRUCTURE I
I I I I I I
-------I------I--------I--------I----------------------I----------------I
I I I I I I
SUPER I H1 I 4 I B I DE,NU I AU ( 1 - 2) I
I I I I I AV ( 1 - 2) I
SUB I S1 I 4 I A I DE I AO ( 1 - 4) I
SUPER I S2 I 26 I A I DE I AO ( 1 - 6) I
I I I I I AE ( 1 - 20) I
SUPER I S3 I 12 I A I DE,NU,PE I AR ( 1 - 3) I
I I I I I AS ( 1 - 9) I
I I I I I I
PHON I PH I I I I PH =PHON(AE) I
I I I I I I
COL I Y1 I 20 I W I DE I CDX 8,PA I
COL I Y2 I 12 I A I DE,NU,PE I CDX 1,AR I
I I I I I I
I I I I I I
------------------------------------------------------------------------- |
このテーブルに含まれる情報としては、特殊フィールドおよびディスクリプタの名前、長さ、フォーマット、および指定オプションの他に、次のものがあります。
| 列 | 説明 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| TYPE |
|
||||||||||
| STRUCTURE | サブ、スーパー、またはハイパーディスクリプタの構成フィールドおよびフィールドバイト。 フォネティックディスクリプタは同等の英数字エレメンタリフィールドを示します。 照合ディスクリプタは関連付けられた照合ディスクリプタユーザー出口と親フィールドの名前を示します。 |
このセクションは、特殊なフィールドおよびディスクリプタについて説明します。
英数字またはワイド文字フィールドは、照合ディスクリプタの親フィールドとして定義することができます。 照合ディスクリプタは、フィールド値をユーザー定義の特別な順序でソートするために使用します。 LF コマンドは、照合ディスクリプタフィールドの情報をレポートします。
照合ディスクリプタには、照合ディスクリプタユーザー出口(1~8)が割り当てられます。このユーザー出口は、照合ディスクリプタ値のエンコードおよび元のフィールド値へのデコードに使用されます。 ADARUN のパラメータ CDXnn は、照合ディスクリプタユーザー出口の指定に使用します。
ハイパーディスクリプタオプションを使用すると、ユーザー指定のアルゴリズムに基づいてディスクリプタ値を生成できます。 単一の物理 Adabas データベースごとに 31 個までの異なるハイパーディスクリプタを定義できます。 使用するジョブの ADARUN ステートメントパラメータで適切な HEXnn を指定して各ハイパーディスクリプタに命名しなければなりません。
ハイパーディスクリプタを使用すると、あいまい一致検索が可能になります。例えば、検索条件と完全に一致するのではなく、類似しているデータを取り出すことができます。 ハイパーディスクリプタにより、マルチプルバリューインデックスが使用可能となります。つまり、1 つのデータフィールドに異なる複数の検索インデックスエントリを作成できるようになります。
ハイパーディスクリプタは n 個から構成されるスーパーディスクリプタ、派生キー、またはその他のキー構造を実装するために使用できます。 ハイパーディスクリプタを使用すると、厳密に正規化されたリレーショナル構造を基にしたアプリケーションよりも、簡単で柔軟なアプリケーションの開発が可能です。
ハイパーディスクリプタの応用分野として、名前の処理があります。 例えば、SCHROEDER という名前に対しては、それ自身のインデックス SCHROEDER だけが保存されますが、SCHRODER、SCHRADER などのさまざまな名前も、実質的にはインデックスとして保存されたことと同じになります。 したがって、物理的には SCHROEDER のみがデータベースのデータエリアに保存されますが、このデータに対して複数の検索インデックスが存在します。 後で、SCHRODER という名前で検索が行われた場合、SCHROEDER のレコードが検索されます。
ハイパーディスクリプタのより高度な応用分野として指紋検索があります。この検索では、指紋の一般的な特徴によりあいまい一致アルゴリズムの基本を形成できます。つまり、元の指紋がデータベースに保存されますが、元の指紋とわずかに違う指紋も一致すると認識するアルゴリズムに基づいて、任意の数の検索インデックスをこの指紋に対して作成することができます。
フォネティックディスクリプタを定義して、類似したフォネティック値を持つレコードの検索に使用できます。 ディスクリプタのフォネティック値はフィールド値の先頭 20 バイトに基づいて内部アルゴリズムにより決定され、英字の値のみが考慮されます(数値、特殊文字および空白は無視されます)。
フィールドの一部(サブフィールド)またはフィールドの組み合わせ(スーパーフィールド)をエレメンタリフィールドとして定義することができます(「MU および PE オプションおよびフィールドタイプ」を参照)。 サブフィールドとスーパーフィールドは、読み込みにのみ使用できます。 これらのフィールドが変更されるのは、元のフィールドが更新された場合のみです。
サブディスクリプタは、単一のフィールドの一部であり、ディスクリプタとして使用されます。 サブディスクリプタの元になるフィールドは、エレメンタリディスクリプタであってもなくてもかまいません(「ディスクリプタオプション DE、UQ、および XI」を参照)。 検索条件が、英数字フィールドの先頭 n バイトまたは数値フィールドの最後の n バイトを対象とするとき、そのフィールドの関連バイトだけからサブディスクリプタを定義できます。 サブディスクリプタは、ある範囲の複数の値ではなく、単一の値を指定するため、検索の効率を向上させることが可能です。
例えば、5 バイトフィールドの最初の 2 バイトが地理的な地域を表していて、サブディスクリプタを使用せずに地域 11 のすべてのレコードを取得する場合、すべてのレコードに対して 11000~11999 の範囲で検索を行う必要があります。 このフィールドの最初の 2 バイトからなるサブディスクリプタを定義すれば、サブディスクリプタが 11 であるすべてのレコードを検索できます。
スーパーディスクリプタは 2~20 個のフィールドのすべてまたはその一部を組み合わせます。 スーパーディスクリプタの元になるフィールドは、エレメンタリディスクリプタであってもなくてもかまいません。 検索条件にフィールドの組み合わせを必要とする場合、スーパーディスクリプタを使用する方が、複数のエレメンタリディスクリプタを組み合わせるよりも効率的です。
例えば、ある地域内の顧客の姓で検索を行う場合、5 バイトの顧客番号フィールドの最初の 2 バイト(地理的な地域のインジケータ)と顧客の姓フィールド全体を組み合わせてスーパーディスクリプタを作成できます。
スーパーディスクリプタの定義については、ADACMP ドキュメントの「SUPDE:スーパーディスクリプタの定義」を参照してください。
Adabas 8 では、レコードをデータベース内でスパンすることができます。 データベース内では、論理レコードは多くの物理レコードに分割されます。それぞれのレコードは単一のデータストレージ(DS)ブロックに格納されます。 分割された各物理レコードには、それぞれ ISN が割り当てられます。 最初の物理レコードはプライマリレコードと呼ばれ、圧縮レコードの先頭が含まれ、プライマリ ISN が割り当てられます。 残りの物理レコードは、セカンダリレコードと呼ばれ、論理レコードの残りのデータを含みます。 セカンダリレコードには、セカンダリ ISN が割り当てられます。 これらの ISN は、N2 コマンドの使用時に割り当てられるユーザー ISN、または L1 コマンドの I オプション使用時に使用される ISN に影響しません。 スパンドレコードでは、セカンダリアドレスコンバータを使用して、セカンダリレコードが格納されているデータストレージブロックの RABN にセカンダリ ISN をマッピングします。
スパンドレコードは、1 つのプライマリレコードと 1 つ以上のセカンダリレコードで構成されます。 ただし、スパンドレコードのセグメント数は制限されています。 Adabas ニュークリアスは、スパンドレコード内に最大 5 個の物理レコード(1 個のプライマリレコードと 4 個のセカンダリレコード)を許可しています。
スパンドレコードはアプリケーションプログラムで直接表示させることはできません。 アプリケーションは、常にプライマリ ISN を経由してスパンドレコードにアドレスします。
スパンドレコードは、拡張 Adabas ファイルおよびマルチクライアントファイルでもサポートされています。
注意:
スパンドレコードのサポートは、ファイルに明示的に許可する必要があります。
ADADBS
RECORDSPANNING 機能、または
ADACMP
COMPRESS の SPAN
パラメータを使用してこれを行うことができます。 詳細は、ADADBS および ADACMP ユーティリティについての
Adabas ユーティリティ
のドキュメントを参照してください。
このセクションでは、次のトピックについて説明します。
スパンされた論理レコードは 1 つ以上の物理レコードで構成されます。この論理レコードには、1 つのプライマリレコードおよび 1 つ以上のセカンダリレコードが含まれます。 スパンドレコードを構成するレコード数は制限されています。 Adabas ニュークリアスは、スパンドレコード内に最大 5 個の物理レコード(1 個のプライマリレコードと 4 個のセカンダリレコード)を許可しています。
スパンドレコードのプライマリレコードおよびセカンダリレコードは ISN を使用して結合されます。 各物理レコードのヘッダーには、現在のレコードの ISN、プライマリレコードの ISN、また次のセカンダリレコードの ISN が含まれています。 また、ヘッダーには、現在のレコードがプライマリレコードかセカンダリレコードかを示す情報も含まれています。
各物理レコードのヘッダーは、そのレコードの長さ情報も提供します。これはレコードがセグメント化されていても同様です。この場合、レコード長はセグメントの長さになります。
ファイル上のスパンドレコードは、ADACMP COMPRESS の SPAN パラメータ 、ADADBS の RECORDSPANNING 機能 または同等な Adabas Online System 機能を使用して明示的に要求した場合のみ許可されます。 ADAREP データベースレポート機能および Adabas Online System レポート機能を使用すると、スパンドレコードを使用できるようにファイルが定義されているかどうかを確認できます。
ファイルの SPAN 属性は、ADAULD UNLOAD 機能内で保持されます。 つまり、ファイルがアンロードされたり、削除されたり、再ロードされた場合に、スパンドレコードのサポートは変わらずに維持されます。
191 を超える MU または PE オカレンスが許可されているファイルにも同じ規則が適用されます。 圧縮レコード内の 191 を超える MU および PE オカレンスの識別の詳細については、「圧縮レコード内の 191 を超える MU および PE オカレンスの特定」を参照してください。
セカンダリレコードは、フィールド単位またはバイト単位のいずれかでセグメント化されます。 パフォーマンス上の理由から、セグメンテーションは可能な限りフィールド単位に行われます。 ただし、LB(ラージオブジェクト)タイプではないフィールドのサイズがデータストレージブロックサイズよりも大きい場合、このレコードはバイト単位で分割されます。 フィールドのサイズがデータストレージブロックの残りの空きスペースより大きく、データストレージブロックサイズより小さい場合、このレコードはバイト単位ではなくフィールド単位で分割されます。 各セカンダリレコードのヘッダーには、セグメントレコードがどのタイプであるかを示す情報が格納されています。
パディングファクタは、ブロックの領域をすべて使用するために、一般的にはスパンドレコードでは無視されます。 したがって、大抵の場合はレポート上でゼロが表示されます。 パディングファクタは、スパンドレコードの最後の短いセグメントのみに使用されます。
プライマリレコードおよびセカンダリレコードは、アドレスコンバータ(AC)を使用して Adabas によりアドレスされます。 ただし、プライマリアドレスコンバータはプライマリレコードの ISN のみを、対応するデータストレージブロックの RABN にマッピングします。 スパンドレコードでは、セカンダリアドレスコンバータを使用して、セカンダリレコードが格納されているデータストレージブロックの RABN にセカンダリ ISN をマッピングします。 したがって、各スパンドレコードのインデックスは 1 つだけになり、インデックス構造に何も影響を与えません。
ISN の範囲は、プライマリ ISN およびセカンダリ ISN 用に個別に維持されます。 ISN が格納または取り扱われる場合は、必ずそのアクションの対象がプライマリ ISN なのか、セカンダリ ISN なのかが区別されます。
すべてのコマンドは、プライマリレコードの ISN を使用して指定する必要があります。セカンダリレコードの ISN は内部的なもので、ユーザーが使用することはできません。 物理シーケンシャルコマンドは、データストレージ内のセカンダリレコードを自動的にスキップします。 セカンダリ ISN を指定した読み取りコマンドにはエラーが返されます(レスポンスコード 113)。
プライマリレコードの ISN は、TOPISN および MAXISN 値に含まれます。 セカンダリレコードの ISN は含まれません。 代わりに、セカンダリ ISN は、MINSEC および MAXSEC 値に含まれます。 スパンドレコードを含むファイルは MINISN 値を指定してロードできますが、MINISN はプライマリレコードの ISN のみを参照する必要があります(セカンダリレコードの ISN は参照できません)。
スパンドレコードを含むファイルをサポートするために、次の ADARUN パラメータ値を大きくする必要がある場合があります。
更新するスパンドレコードの数も増加するため、ユーザーごとのホールドキュー内の ISN 数(NISNHQ パラメータ)を大きくする必要がある場合があります。
スパンドレコードのビフォーイメージとアフターイメージの両方を格納するスペースが必要なため、また、複数の更新スレッドの並行実行をサポートするため、Adabas ワークプール長(LWP)を大きくする必要がある場合もあります。 大きなディスクリプタバリューテーブルを格納するスペースが必要な場合もあります(PE グループのディスクリプタのオカレンス数は、最大 65,534 です)。
最大レコード長統計は、スパンされたファイルとは関連がありません。 最大レコード長をレポートするユーティリティは、統計結果として"[N/A]"(該当なし)を表示するようになりました。 FCB の最大レコード長フィールドは、スパンドレコードを使用しているファイルの場合には、値が大きくなります。
スパンドレコードを含んでいるファイルは、暗号化することができ、セキュリティバイバリューにより保護することができます。 プライマリレコードの ISN が参照されている場合、すべてのセカンダリのセグメントレコードも読み込まれる必要があります。したがって、処理時間が重要な要素となります。