このドキュメントでは、次のトピックについて説明します。
ADACMP の非圧縮レコードが長すぎてシーケンシャルデータセットで許容されている最大レコード長に収まらない場合(32 KB 以下)、ADACMP では、このレコードを複数の物理レコードにセグメント化することができます。 1 つの非圧縮論理レコードを 1 つ以上の非圧縮物理レコードにスパンすることができます。
また、ADACMP ユーティリティでは、非圧縮出力に特別なヘッダー(ADAH および ADAC)を作成することができます。 これらの特別なヘッダーは、ADACMP 処理でのみ使用されます。 論理レコード内のペイロードデータの位置、および同じ論理レコード内の複数の物理レコード間の関係は、これらのヘッダーから識別されます。 ADAH ヘッダーが論理レコードの最初の物理レコードに使用され、ADAC ヘッダーが論理レコードを構成する 2 番目以降の物理レコードに使用されます。 非圧縮論理レコードのセグメント化が必要ない場合(1 つの物理レコードに収まる場合)、ADAH ヘッダーのみが作成されます。ADAC ヘッダーは不要です。
ADACMP 圧縮解除ロジックおよびレコードスパニングで発生するレコードのセグメンテーションと混同しないでください。 スパンドレコードも複数の物理レコード(1 つのプライマリレコードと複数のセカンダリレコード)で構成されますが、圧縮レコードになります。 また、各スパンドレコードには、標準スパンドレコードヘッダーが自動的に割り当てられます。このヘッダーは、ADACMP を使用して非圧縮レコード用に作成可能な ADAH および ADAC ヘッダーとは異なります。ADACMP によって生成されるセグメント化されたレコードには、標準スパンドレコードヘッダーは含まれません。 スパンドレコードの詳細については、「スパンドレコード」を参照してください。
このセクションでは、次のトピックについて説明します。
ADACMP DECOMPRESS の HEADER パラメータでは、圧縮解除ロジックで出力にヘッダーを作成するかどうかを制御します。 ADACMP COMPRESS の HEADER パラメータでは、圧縮ロジックで非圧縮入力の一部として ADACMP ヘッダーを許容するかどうかを制御します。
このセクションでは、次のトピックについて説明します。
ADACMP ヘッダーを使用する場合、論理レコードの最初の物理レコードは、次の情報を含む ADAH ヘッダーで始まります。
文字 "ADAH"
ADAH ヘッダーの長さ
これが論理レコード内で最後の物理レコードであるのか、同じ論理レコードの別の物理レコードがこのレコードに続くのかを示す継続インジケータです。
レコード(ヘッダーを含む)の全体の長さ 最初の物理レコードが書き込まれるときにレコードの全体の長さが不明な場合、値がゼロになることがあります。
この物理レコード内のペイロードデータ(論理レコードのセグメント)の長さ ペイロードデータの長さを表し、ADAH ヘッダーの長さは含まれません。 長さは、物理レコードの長さからヘッダーの長さを引いた値以下である必要があります。 この値よりも小さい場合は、物理レコード内のその他のデータ(ペイロードデータ長でカバーされないデータ)はすべて無視されます。
ペイロードデータは、ADAH ヘッダーの後に続きます。
ADAH DSECT は、分散 Adabas 8 MVSSRCE ライブラリのメンバ ADAH 内にあります。
ADACMP 非圧縮レコードのセグメント化を行った場合、および ADACMP ヘッダーが要求された場合は、論理レコードを構成する 2 番目以降のすべての物理レコードの先頭に、次の情報を含む ADAC ヘッダーが置かれます。
文字 "ADAC"
ADAC ヘッダーの長さ
これが論理レコード内で最後の物理レコードであるのか、同じ論理レコードの別の物理レコードがこのレコードに続くのかを示す継続インジケータです。
論理レコード内のこのセカンダリレコードのシーケンス番号 論理レコードの 2 番目の物理レコードは最初のセカンダリレコードになるため、そのシーケンス番号は "1" です。 シーケンス番号は、番号抜けのない昇順になります。
この物理レコードに含まれるペイロードデータ(セグメント)の論理レコード内のオフセット このオフセットは、論理レコード内の先行する各物理レコードのペイロードデータ長の合計です。
この物理レコード内のペイロードデータ(セグメント)の長さ ペイロードデータの長さを表します。ADAC ヘッダーの長さは含まれません。 長さは、物理レコードの長さからヘッダーの長さを引いた値以下である必要があります。 この値よりも小さい場合は、物理レコード内のその他のデータ(ペイロードデータ長でカバーされないデータ)はすべて無視されます。
ペイロードデータは、ADAC ヘッダーの後に続きます。
ADAC DSECT は、分散 Adabas 8 MVSSRCE ライブラリのメンバ ADAC 内にあります。
次の表は、非圧縮データの 3 つの論理レコードを 7 つの物理レコードにスパンした例を示しています。
注意:
ADAH および ADAC ヘッダーの DSECT は、分散 Adabas 8 MVSSRCE ライブラリのメンバ ADAH および
ADAC 内にあります。
| 論理レコード | 物理レコードヘッダー | ヘッダーフィールド | 説明 | |
|---|---|---|---|---|
| フィールド | 値 | |||
| 1 | ADAH | ADAHEYE | ADAH | ADAH ヘッダーのアイキャッチャー |
| ADAHLEN | 32 | ADAH ヘッダー長 | ||
| ADAHIND | C | 継続インジケータ。 正しい値は次のとおりです。
C:後続の継続レコードセグメント |
||
| 予約済み | 0 | バイナリの 0 を含んでいる必要があります。 | ||
| ADAHTLEN | 50000 | 論理レコードの全体の長さ。 最初のセグメントが書き込まれるときに全体の長さが不明な場合、この値は 0 になることがあります。 | ||
| 予約済み | 0 | 予約済み | ||
| ADAHSLEN | 27962 | このセグメントの長さ(ペイロードデータの長さ)。 ADAHLEN と ADAHSLEN の値の合計が、物理レコードの最小長です。 物理レコードはこの値よりも長くすることができます。この場合、超過したデータに意味はなく、無視されます。 | ||
| ADAHDATA | 'Record 1 - payload data part 1' | ペイロードデータ | ||
| ADAC | ADACEYE | ADAC | ADAC ヘッダーのアイキャッチャー | |
| ADACLEN | 32 | ADAC ヘッダー長 | ||
| ADACIND | E | 継続インジケータ。 正しい値は次のとおりです。
C:後続の継続レコードセグメント |
||
| 予約済み | 0 | 予約済み | ||
| ADACSEQ | 1 | 論理レコードにおける継続レコードのシーケンス番号(最初の ADAC レコードのシーケンス番号は "1")。 | ||
| ADACOFFS | 27962 | 論理レコードにおけるセグメントのオフセット(最初のペイロードデータバイトのオフセットは "0")。 | ||
| 予約済み | 0 | 予約済み | ||
| ADACSLEN | 22038 | このセグメントの長さ(ペイロードデータの長さ)。 ADACLEN と ADACSLEN の値の合計が、物理レコードの最小長です。 物理レコードはこの値よりも長くすることができます。この場合、超過したデータに意味はなく、無視されます。 | ||
| ADACDATA | 'Record 1 - payload data part 2' | 継続レコードのペイロードデータ | ||
| 2 | ADAH | ADAHEYE | ADAH | ADAH ヘッダーのアイキャッチャー |
| ADAHLEN | 32 | ADAH ヘッダー長 | ||
| ADAHIND | E | 継続インジケータ。 正しい値は次のとおりです。
C:後続の継続レコードセグメント |
||
| 予約済み | 0 | バイナリの 0 を含んでいる必要があります。 | ||
| ADAHTLEN | 25000 | 論理レコードの全体の長さ。 最初のセグメントが書き込まれるときに全体の長さが不明な場合、この値は 0 になることがあります。 | ||
| 予約済み | 0 | 予約済み | ||
| ADAHSLEN | 25000 | このセグメントの長さ(ペイロードデータの長さ)。 ADAHLEN と ADAHSLEN の値の合計が、物理レコードの最小長です。 物理レコードはこの値よりも長くすることができます。この場合、超過したデータに意味はなく、無視されます。 | ||
| ADAHDATA | 'Record 2 - payload data' | ペイロードデータ | ||
| 3 | ADAH | ADAHEYE | ADAH | ADAH ヘッダーのアイキャッチャー |
| ADAHLEN | 32 | ADAH ヘッダー長 | ||
| ADAHIND | C | 継続インジケータ。 正しい値は次のとおりです。
C:後続の継続レコードセグメント |
||
| 予約済み | 0 | バイナリの 0 を含んでいる必要があります。 | ||
| ADAHTLEN | 0 | 論理レコードの全体の長さ。 最初のセグメントが書き込まれるとき、全体の長さが不明な場合は、この値はゼロになることがあります(論理レコード 3 の場合など)。 | ||
| 予約済み | 0 | 予約済み | ||
| ADAHSLEN | 27962 | このセグメントの長さ(ペイロードデータの長さ)。 ADAHLEN と ADAHSLEN の値の合計が、物理レコードの最小長です。 物理レコードはこの値よりも長くすることができます。この場合、超過したデータに意味はなく、無視されます。 | ||
| ADAHDATA | 'Record 3 - payload data part 1' | ペイロードデータ | ||
| ADAC | ADACEYE | ADAC | ADAC ヘッダーのアイキャッチャー | |
| ADACLEN | 32 | ADAC ヘッダー長 | ||
| ADACIND | C | 継続インジケータ。 正しい値は次のとおりです。
C:後続の継続レコードセグメント |
||
| 予約済み | 0 | 予約済み | ||
| ADACSEQ | 1 | 論理レコードにおける継続レコードのシーケンス番号(最初の ADAC レコードのシーケンス番号は "1")。 | ||
| ADACOFFS | 27962 | 論理レコードにおけるセグメントのオフセット(最初のペイロードデータバイトのオフセットは "0")。 | ||
| 予約済み | 0 | 予約済み | ||
| ADACSLEN | 27962 | このセグメントの長さ(ペイロードデータの長さ)。 ADACLEN と ADACSLEN の値の合計が、物理レコードの最小長です。 物理レコードはこの値よりも長くすることができます。この場合、超過したデータに意味はなく、無視されます。 | ||
| ADACDATA | 'Record 3 - payload data part 2' | 継続レコードのペイロードデータ | ||
| ADAC | ADACEYE | ADAC | ADAC ヘッダーのアイキャッチャー | |
| ADACLEN | 32 | ADAC ヘッダー長 | ||
| ADACIND | C | 継続インジケータ。 正しい値は次のとおりです。
C:後続の継続レコードセグメント |
||
| 予約済み | 0 | 予約済み | ||
| ADACSEQ | 2 | 論理レコードにおける継続レコードのシーケンス番号(最初の ADAC レコードのシーケンス番号は "1")。 | ||
| ADACOFFS | 55924 | 論理レコードにおけるセグメントのオフセット(最初のペイロードデータバイトのオフセットは "0")。 | ||
| 予約済み | 0 | 予約済み | ||
| ADACSLEN | 27962 | このセグメントの長さ(ペイロードデータの長さ)。 ADACLEN と ADACSLEN の値の合計が、物理レコードの最小長です。 物理レコードはこの値よりも長くすることができます。この場合、超過したデータに意味はなく、無視されます。 | ||
| ADACDATA | 'Record 3 - payload data part 3' | 継続レコードのペイロードデータ | ||
| ADAC | ADACEYE | ADAC | ADAC ヘッダーのアイキャッチャー | |
| ADACLEN | 32 | ADAC ヘッダー長 | ||
| ADACIND | E | 継続インジケータ。 正しい値は次のとおりです。
C:後続の継続レコードセグメント |
||
| 予約済み | 0 | 予約済み | ||
| ADACSEQ | 3 | 論理レコードにおける継続レコードのシーケンス番号(最初の ADAC レコードのシーケンス番号は "1")。 | ||
| ADACOFFS | 83886 | 論理レコードにおけるセグメントのオフセット(最初のペイロードデータバイトのオフセットは "0")。 | ||
| 予約済み | 0 | 予約済み | ||
| ADACSLEN | 16114 | このセグメントの長さ(ペイロードデータの長さ)。 ADACLEN と ADACSLEN の値の合計が、物理レコードの最小長です。 物理レコードはこの値よりも長くすることができます。この場合、超過したデータに意味はなく、無視されます。 | ||
| ADACDATA | 'Record 3 - payload data part 4' | 継続レコードのペイロードデータ | ||
ADACMP では、U(アンパック形式)または P(パック形式)フォーマットで定義されたフィールドをチェックし、フィールド値が数字であり、かつ正しいフォーマットであることを確認します。 値が空値である場合、この空値はそのフィールドに指定されたフォーマットに対応している必要があります(「フィールド定義ステートメント」セクションの「SQL 空値の表現」を参照)。
| 英数字(A) | 空白(16 進数 X'40') |
| 2 進数(B) | バイナリの 0(16 進数 X'00') |
| 固定小数点(F) | バイナリの 0(16 進数 X'00') |
| 浮動小数点(G) | バイナリの 0(16 進数 X'00') |
| パック形式(P) | 符号付きパック 10 進数のゼロ(右端の下位バイトに、X'00' に続けて X'0F'、X'0C'、または X'0D' を伴う) |
| アンパック形式(U) | 符号付アンパック 10 進数のゼロ(右端の下位バイトに、X'F0' に続けて X'C0' または X'D0' を伴う) |
無効なデータを含むレコードは、すべて ADACMP エラー(DDFEHL)データセットに書き込まれ、圧縮データセットには書き込まれません。
各フィールドの値は(FI オプションの指定がない限り)次のように圧縮されます。
A フォーマットで定義されたフィールドの末尾の空白は削除されます。
数字フィールド(B、F、P、または U フォーマットで定義されたフィールド)の先行ゼロは削除されます。
フィールドが U フォーマット(アンパック形式)で定義されている場合、値は P フォーマット(パック形式)に変換されます。
浮動小数点(G フォーマット)フィールドの末尾のゼロは削除されます。
フィールドが NU オプションを指定して定義され、かつ値が空値である場合は、1 バイトのインジケータが格納されます。 このインジケータバイトでは、16 進数の X'C1' は 1 個の空値フィールドが後に続くことを示し、X'C2' は 2 個の空値フィールドが後に続くことを示し、以下同様に、最大で 63 個の空値フィールドを表現します。64 個以上の場合は、インジケータバイトが繰り返されます。 SQL 空値(NC オプションフィールド)の圧縮については、「フィールド定義ステートメント」セクションの「SQL 空値の表現」を参照してください。
レコードの末尾にある空値フィールドは格納されないため、圧縮されません。
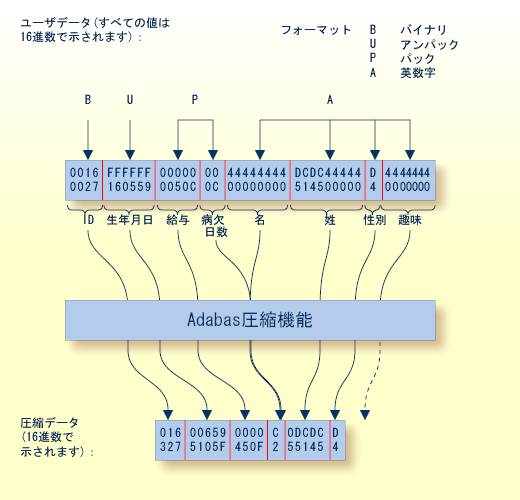
下図は、次のフィールド定義とその値が ADACMP によってどのように処理されるかを示しています。
FNDEF='01,ID,4,B,DE' FNDEF='01,BD,6,U,DE,NU' FNDEF='01,SA,5,P' FNDEF='01,DI,2,P,NU' FNDEF='01,FN,9,A,NU' FNDEF='01,LN,10,A,NU' FNDEF='01,SE,1,A,FI' FNDEF='01,HO,7,A,NU'
このセクションでは、ラージオブジェクト(LB)フィールドの値、LB フィールドの値参照、および 32 KB より長い論理レコードを ADACMP COMPRESS 機能の入力データセットでどのように表現する必要があり、これらの項目が ADACMP DECOMPRESS 機能の出力データセットでどのように表現されるかについて説明します。
FORMAT パラメータを指定せずに ADACMP を実行した場合、非圧縮データ内の各ラージオブジェクト(LB)フィールド値の先頭に 4 バイトの長さフィールドが付けられます。 長さの値は、固有の LB フィールド値の長さに、長さフィールド自体の 4 バイトを加えた値になります。 NB オプションを指定せずに定義されたフィールドの場合、空の LB フィールド値は、値 5 と 1 つの空白を含む長さフィールドで構成されます。NB オプションを指定して定義されたフィールドの場合、空の LB フィールド値は、値 4 のみを含む長さフィールドで構成されます。
ADACMP COMPRESS を使用して LB フィールドを含む FDT を定義する場合、非圧縮入力の各 LB フィールド値は 253 バイトと等しいかそれより小さくする必要があります。
LOBVALUES=NO を指定して ADACMP DECOMPRESS 機能を実行し、LOB ファイルグループの基本ファイル内のレコードのみを圧縮解除した場合(関連する LOB ファイルに格納されている LB フィールド値はすべて省略)、LOB ファイル内の LB フィールド値に対する基本ファイルレコード内の各参照は、非圧縮出力で次のように表現されます。
LB フィールド値の 4 バイトの長さフィールドには、LB フィールド値への参照の存在を示す X’FFFFFFFF’(高い値)が含まれます。
インジケータの後には、LB フィールド値参照に関する 2 バイトの長さフィールド(長さバイトを含む)が続きます。 長さの値は、固有の LB フィールド値参照の長さに、長さフィールド自体の 2 バイトを加えた値になります。
長さフィールドの後には、固有の LB フィールド値参照が続きます。
ADACMP COMPRESS 機能で LOBVALUES=NO を指定した場合、処理対象の基本ファイルに関連付られている LOB ファイルに格納されている LB フィールド値の場所で、同じ構造が要求されます。
ADACMP COMPRESS の入力として使用する LB フィールド値参照は、ADACMP DECOMPRESS から取得する必要があります。 COMPRESS を使用して新しい LB フィールド値参照を取り入れる適切な方法はありません。これは、LOB ファイル内の既存の LB フィールド値を正しく参照できないためです。
圧縮レコード内に 191 を超える MU および PE オカレンスがある場合は、そのオカレンスカウントの先頭に x'C0' バイトが付加されることによって、そのことが示されます。 このバイトは、レコードの圧縮時に ADACMP ユーティリティまたはニュークリアスにより設定されます。 x'C0' インジケータバイトの後に、後続の MU または PE オカレンスカウントに使用されるカウントバイトの数を示すバイトが続きます。 例えば、次のインジケータの場合を考えます。
X’C0020204’
この例では、x'C0' はこれが拡張カウントであることを示し、x'02' はカウントバイトが 2 つあることを示します。また、x'0204' は、このフィールドに 516 個のオカレンスが存在することを示します。
ADACMP には再スタート機能は備えられていません。 ADACMP の実行が中断された場合、最初からやり直す必要があります。
ADACMP COMPRESS 処理時の編集用に、ユーザー出口 6 と呼ばれるユーザー作成ルーチンを使用することができます。 このルーチンは、アセンブラまたは COBOL で記述できます。 記述したルーチンは、アセンブルまたはコンパイルした後、Adabas ロードライブラリ(またはそれに連結されたライブラリ)にリンクする必要があります。
ユーザー出口 6 は、次のように指定して呼び出します。
ADARUN UEX6=program
ここで、program はロードライブラリ内のルーチン名です。
ユーザー出口 6 の構造とパラメータの詳細は、ユーザー出口とハイパー出口に関する説明を参照してください。