ADACMP の入力として指定するフィールド定義は、次の目的で使用されます。
入力レコードに含まれる各フィールドの長さとフォーマットを指定します。 これにより ADACMP は、編集および圧縮時に正しいフィールド長とフォーマットを判断できます。
ファイルのフィールド定義テーブル(FDT)を作成します。 このテーブルは、Adabas コマンド実行中にファイル内のすべてのフィールド(またはグループ)の論理構造と特徴を判断するために Adabas が使用します。
フィールド定義を入力する場合は、次の構文に従ってください。 最小 1 個、最大 926 個の定義を指定できます。
| フィールドとグループ |
FNDEF='level,name[,length,format][,MU[(occurrences)]][,option]...' |
|---|---|
| ピリオディックグループ |
FNDEF='level,name[,PE[(occurrences)]]' |
| 照合ディスクリプタ |
COLDE='number,name[,UQ [,XI]]=parentfield' |
| ハイパーディスクリプタ |
HYPDE='number,name,length,format[{,option}...]={parentfield},...' |
| フォネティックディスクリプタ |
PHONDE='name(field)' |
| サブディスクリプタ |
SUBDE='name[,UQ [,XI ] ]=parentfield(begin,end)' |
| サブフィールド |
SUBFN='name=parentfield( begin,end)' |
| スーパーディスクリプタ |
SUPDE='name[,UQ [,XI ]]=parentfield(begin,end)},...' |
| スーパーフィールド |
SUPFN='name=parentfield(begin,end)[,parentfield(begin,end)]...' |
各定義の右側にユーザーコメントを入力することができます。 ユーザーコメントと定義の間には少なくとも 1 つの空白を指定する必要があります。
これらの各定義タイプについては、このドキュメントで説明されています。
FNDEF パラメータでは、Adabas フィールド定義またはグループ定義を指定できます。 フィールド定義およびグループ定義のエントリを構成するには、次の構文を使用します。

レベル番号と名前は必須です。 定義エントリの間に空白をいくつ入れても構いません。
各 FNDEF パラメータについては、このセクションで説明されています。
MU パラメータについては、「フィールドオプション」で説明されています。
レベル番号は 01~07 の範囲内の 1 桁または 2 桁の数字(先行のゼロは任意)を使用し、フィールドグルーピングと合わせて使用します。 02 またはそれ以上のレベル番号のついたフィールドは、それより小さいレベル番号のついた直前のグループの一部であるとみなされます。
グループで定義すると、グループ名を使用して一連のフィールド(または 1 つのフィールドだけでもよい)を参照することができます。 これは一連の連続フィールドを参照するのに便利で効果的な方法です。
レベル番号 01~06 は、グループの定義に使用することができます。 グループは他のグループを含むことができます。 ネスト構造のグループにレベル番号をつけるときは、レベル番号を飛ばしてはなりません。
次の例では、フィールド A1 および A2 はグループ GA に含まれます。 フィールド B1 とグループ GC(フィールド C1 と C2 で構成)はグループ GB に含まれます。
| FNDEF='01,GA' | グループ | |
| FNDEF='02,A1,...' | エレメンタリまたはマルチプルバリューフィールド | |
| FNDEF='02,A2,...' | エレメンタリまたはマルチプルバリューフィールド | |
| FNDEF='01,GB' | グループ | |
| FNDEF='02,B1,...' | エレメンタリまたはマルチプルバリューフィールド | |
| FNDEF='02,GC' | グループ(ネスト構造) | |
| FNDEF='03,C1,...' | エレメンタリまたはマルチプルバリューフィールド | |
| FNDEF='03,C2,...' | エレメンタリまたはマルチプルバリューフィールド |
フィールド(またはグループ)に割り当てる名前を指定します。
名前はファイル内でユニークでなければなりません。 名前は 2 文字で指定しなければならず、最初の文字は英字で、2 番目の文字は英字か数字でなければなりません。 特殊文字は使用できません。
値 E0~E9 は編集マスク用に予約されており、使用してはなりません。
| 正しい名前例 | 誤りの名前例 |
|---|---|
| AA | A(2 文字ではない) |
| B4 | E3(編集マスク) |
| S3 | F*(特殊文字が含まれている) |
| WM | 6M(最初の文字が英字ではない) |
フィールドの長さ(バイト単位)を指定します。 長さの値を使用して、次のことが行われます。
各入力レコード内に存在するフィールドの長さを ADACMP に示します。
コマンド処理中に Adabas で使用される標準(デフォルト)長を定義します。
この標準長はフィールド定義テーブル(FDT)に格納され、フィールドの読み込み/更新時に、ユーザーから特に長さの指定がない場合に使用されます。
指定できる最大フィールド長は、フォーマット値に応じて異なります。
| フォーマット | 最大長 |
|---|---|
| 英数字(A) | 253 バイト |
| 2 進数(B) | 126 バイト |
| 固定小数点(F) | 4 バイト(常に 2 または 4 バイト) |
| 浮動小数点(G) | 8 バイト(常に 4 または 8 バイト) |
| パック 10 進数(P) | 15 バイト |
| アンパック 10 進数(U) | 29 バイト |
| ワイド文字(W) | 253 バイト* |
* FWCODE 属性値によっては、W フィールドの最大長が 253 バイトより小さくなることがあります。 例えば、FWCODE にデフォルト値(つまり、Unicode)を使用した場合、最大長は 252 バイト(1 文字が 2 バイト)になります。
標準長をグループ名に指定することはできません。
FI オプションを使用しない限り、標準長によってフィールド値のサイズが制限されることはありません(「FI:固定ストレージ」を参照)。 読み込みまたは更新コマンドで、そのフォーマットに許される最大長までのフィールド長を指定して、フィールドの標準長を変更することができます。
フィールドの標準長がゼロの場合、そのフィールドは可変長フィールドとみなされます。 可変長フィールドには標準(デフォルト)長はありません。 固定小数点(F)フィールドに対して長さ指定を行う場合、2 バイトまたは 4 バイトの長さのみを指定できます。浮動小数点(G)フィールドに対しては、4 バイトまたは 8 バイトの長さのみを指定できます。
Adabas コマンドで可変長フィールドを長さ指定なしで参照すると、フィールド値の先頭に値の長さ(長さバイトを含む)を示す 1 バイトの 2 進数フィールドが付けられて返されます。 この長さの値は、フィールド更新時に指定する必要があります。また、ADACMP で処理される入力レコード内のフィールドに対しても指定する必要があります。 ロング英数字(LA)オプションを使用して定義されたフィールドの場合、フィールド値の先頭に値の長さ(長さバイトを含む)を示す 2 バイトの 2 進数フィールドが付けられます。
フィールドの標準フォーマットを指定します(1 文字のコードで表す)。
| A | 英数字(左詰め) |
| B | 2 進数(右詰め、符号なし、正の数) |
| F | 固定小数点(右詰め、符号あり、2 の補数表示) |
| G | 浮動小数点(一般形式、符号あり) |
| P | パック 10進数(右詰め、符号あり) |
| U | アンパック 10進数(右詰め、符号あり) |
| W | ワイド文字(左詰め) |
標準フォーマットは次の目的で使用されます。
各入力レコード内に存在するフィールドのフォーマットを ADACMP に示します。
コマンド処理中に Adabas で使用される標準(デフォルト)フォーマットを定義します。 この標準フォーマットはフィールド定義テーブル(FDT)に格納されており、フィールドの読み込み/更新時に、ユーザーが特にフォーマットを指定していない場合に使用されます。
標準フォーマットはフィールドに必ず指定しなければなりません。 グループ名に指定することはできません。 グループを読み込む(書き込む)とき、グループ内のフィールドは必ず個々の各フィールドの標準フォーマットに従って返されます(指定する必要があります)。 指定したフォーマットに基づいて、フィールドに対する圧縮処理のタイプが決定されます。
固定小数点フィールドの長さは 2 バイトまたは 4 バイトです。 正の値は一般的な形式で示され、負の値は 2 の補数で示されます。
浮動小数点フォーマットで定義されたフィールドの長さは、4 バイト(単精度)または 8 バイト(倍精度)で指定します。 浮動小数点として定義されたフィールドの値を他のフォーマットに変換することは可能です。
バイナリフィールドをディスクリプタとして定義する場合、またはフィールドに正の数と負の数の両方が含まれている可能性がある場合は、B フォーマットの代わりに F フォーマットを使用する必要があります。これは、B フォーマットではすべての値が符号なし(正の数)とみなされるためです。
ワイド文字フィールドは、英数字フィールドと同様に、FDT で定義された標準長(バイト単位)または可変長になります。 ワイド文字フィールドを可変長フォーマット以外で書き換える場合は、ユーザーエンコードとの互換性が必要です。例えば、Unicode のユーザーエンコードでは、偶数の長さが要求されます。 数値(U、P、B、F、G)からワイド文字フォーマットへの変換は許可されていません。
MUPEX オプションを指定している場合に、レコード内に含める MU フィールドのオカレンスの数を指定します。 これは任意のパラメータです。
オプションは 2 文字のコードで指定します。 複数のコードを指定することができます(フィールドで適用可能な場合)。 これらのコードは、コンマ(,)で区切って任意の順番で指定できます。
次の表は、フィールド定義およびグループ定義に使用できるオプションを示しています。 特定のオプションの詳細を確認するには、表内でオプション名をクリックします。
注意:
PE オプションは、別の Adabas フィールドオプションです。
ただし、このオプションは、ピリオディックグループを指定する場合にのみ、使用することができます。 詳細は、「FNDEF:ピリオディックグループ定義」を参照してください。
| コード | 説明 |
|---|---|
| DE:ディスクリプタ | フィールドがディスクリプタ(キー)であることを示します。 |
| FI:固定ストレージ | フィールド長が固定ストレージ長であることを示します。値は内部的な長さバイトなしで格納され、圧縮されません。また、定義したフィールド長を超えない必要があります。 |
| LA:ロング英数字フィールド | この A または W フォーマットの可変長フィールドには、長さが 16,381 バイトまでの値を格納できます。 |
| LB:ラージオブジェクトオプション | 英数字フィールドには 2,147,483,643(約 2 GB)までのデータを格納できます。 |
| MU:マルチプルバリューフィールド | フィールドには 1 レコードあたり 65,534 個までの値を格納できます。 |
| NB:空白圧縮オプション | LA および LB フィールドのどちらからも、末尾の空白を削除(圧縮)するべきではありません。 |
| NU:空値省略 | フィールドの空値は省略されます。 |
| NV:変換なし | この A または W フォーマットのフィールドは、レコードバッファ内で変換されることなく処理されます。 |
| UQ:ユニークディスクリプタ | フィールドがユニークディスクリプタであることを示します。つまり、ファイル内の各レコードで、ディスクリプタに異なる値が格納される必要があります。 |
| XI:除外インスタンス番号 | このフィールドでは、PE に設定された UQ オプションからインデックス(オカレンス)番号が除外されます。 |
| NC:SQL 空値オプション | Adabas には、NC および
NN の 2
つのデータ定義オプションが用意されています。これらのオプションを使用して、Software AG のメインフレーム Adabas SQL Gateway(ACE)および他の
SQL(Structured Query Language)データベース問い合わせ言語に対応する SQL 互換の空値表現を指定することができます。
これらのオプションの詳細は、「SQL
空値の表現」を参照してください。
NC オプションを使用した場合、フィールドには、SQL 解釈で値のないフィールドを示す空値を格納することができます。つまり、フィールドの値は定義されません(カウントされません)。 NN オプションを使用する場合、NC オプションで定義されたフィールドには、常に値が定義されている必要があります。つまり、SQL 空値を格納することはできません。 |
| NN:SQL 非空値オプション |
DE は、フィールドがディスクリプタ(キー)であることを示します。 エントリがフィールドのアソシエータインバーテッドリストに作成されることにより、該当フィールドは FIND コマンドのソートキーとして検索式で使用したり、論理的な順次読み込み処理を制御する方法として使用したり、ファイルカップリングの基準として使用したりできるようになります。
ディスクリプタオプションは慎重に使用する必要があります。特に、ファイルが大きく、ディスクリプタとみなされるフィールドが頻繁に更新される場合は、注意が必要です。
ディスクリプタフィールドの定義はレコード構造から独立していますが、ディスクリプタフィールドがレコードの最初に配列されず、論理的に物理レコードの終了を超えている場合、パフォーマンスの理由から、そのレコードに対するインバーテッドリストエントリが生成されないことに注意してください。 このケースでインバーテッドリストエントリを生成するには、ファイルのアンロード(SHORT モード)、圧縮解除、そして再ロードが必要です。あるいは、アプリケーションプログラムを使用してフィールドをファイルの各レコードの最初に再配列します。
FI では、フィールド長が固定ストレージ長であることを示します。 フィールドの値は内部的な長さバイトなしで格納され、圧縮されません。また、定義されたフィールド長を超えない必要があります。
空値を含む可能性の低い 1 バイトまたは 2 バイトの長さのフィールド(社員番号、性別など)、および圧縮できない値を含むフィールドに対しては、FI オプションを使用することをお勧めします。
マルチプルバリューフィールドやピリオディックグループ内のフィールドに対して FI オプションを使用することはお勧めしません。 このようなフィールドの空値は省略(圧縮)されないため、ディスクストレージスペースが無駄になるだけでなく、処理時間も増加します。
FI オプションは、次のフィールドに対しては指定できません。
U フォーマットのフィールド
NC、NN、または NU オプションフィールド
FNDEF ステートメントで長さがゼロ(0)に定義された可変長フィールド
ピリオディック(PE)グループ内のディスクリプタ
FI オプションで定義されたフィールドは、フィールドの標準長を超える値によって更新することはできません。
FI の使用例
| 定義 | ユーザーデータ | 内部表現 | |
|---|---|---|---|
| FI オプションなし | FNDEF='01,AA,3,P' | 33104C 00003C | 0433104F(4 バイト)023F(2 バイト) |
| FI オプションあり | FNDEF='01,AA,3,P,FI' | 33104C 00003C | 33104F(3 バイト)00003F(3 バイト) |
LA(ロング英数字)オプションは、可変長の英数字フィールドおよびワイド文字フォーマットのフィールド(つまり、フィールド定義 FNDEF で長さがゼロに定義された A または W フォーマットのフィールド)に対して指定できます。 LA オプションを指定したフィールドには、長さが 16,381 バイトまでの値を格納できます。
LA オプションを含む英字またはワイド文字フィールドは、このオプションを含まない英字またはワイド文字フィールドと同様に圧縮されます。 LA オプションを含むフィールドで実際に可能な最大長は、圧縮レコードを格納するブロックのサイズで制限されます。
LA オプションが指定されているフィールドが更新される(または読み込まれる)場合、そのフィールド値はレコードバッファに指定され(または返され)ます。このとき、フィールド値の先頭には、値の長さ(長さバイトを含む)を示す 2 バイトが付けられます(フィールド長 + 2)。
LA オプションが指定されたフィールドに関する考慮事項を以下に示します。
NU、NC/NN、NV、または MU オプションと一緒に指定できます。
PE グループのメンバにすることができます。
FI オプションは一緒に指定できません。
ディスクリプタフィールドにすることはできません。
サブ/スーパーフィールド、サブ/スーパーディスクリプタ、ハイパーディスクリプタ、またはフォネティックディスクリプタの親にすることはできません。
サーチバッファには指定できません。指定すると、レスポンスコード 61 が返されます。
詳細は、「フォーマットバッファでの LA(ロング英数字)フィールドのフィールド長の指定」および「レコードバッファでの LA(ロング英数字)フィールドのフィールド長の指定」を参照してください。
LA の使用例
| 定義 | ユーザーデータ | 内部表現 | |
|---|---|---|---|
| LA オプションなし | FNDEF='01,BA,0,A' | X'06',C'HELLO' -- |
X'06C8C5D3D3D6' (1 バイトの長さ)-- |
| LA オプションあり | FNDEF='01,BA,0,A,LA' | X'0007',C'HELLO' X'07D2',C' ... (2000 データバイト)...' |
X'06C8C5D3D3D6' (1 バイトの長さ)X'87D2 ... (2000 データバイト)... ' |
フィールドにラージオブジェクト(LB)オプションを指定すると、ラージオブジェクトフィールドにすることができます。 LB フィールドには、2,147,483,643 バイト(約 2 GB)までのデータを格納できます。 現時点では、LB フィールド全体を格納し、取り出せるだけで、LB フィールドの一部を格納し、取り出すことはできません。
LB フィールドのフォーマットは "A"(英数字)であり、そのデフォルトフィールド長は現在、0 として定義されている必要があります。
LB フィールドは、次のものにすることはできません。
ディスクリプタ、または特別なディスクリプタ(フォネティック、サブ、スーパー、またはハイパーディスクリプタ)の親
FI または LA オプションとともに定義する。
LA および LB のどちらとしてフィールドを定義するかを決定する場合は、「LA および LB フィールドの違い」を参考にしてください。
サーチバッファまたはフォーマットバッファのフォーマット選択条件で、指定されたフィールド
LB フィールドは次のいずれかです。
MU、NB、NC、NN、NU、または NV オプションのいずれかで定義されたフィールド
単一グループまたは PE グループの一部にする。
LB フィールド定義に NB(非空白圧縮)フィールドオプションがあるかどうかは、文字を含む LB フィールドで末尾の空白が Adabas により削除されたかどうかを示します。
バイナリと文字の両データを含む LB フィールドがサポートされています。 NV および NB オプションの両方で定義された LB フィールドには、バイナリラージオブジェクトデータを格納できます。これは、Adabas ではバイナリ LB フィールドが変更されることがないためです。 格納されているのと同じ LB バイナリバイト文字列が、LB フィールドが読み込まれたときに取り出されます。 また、バイナリ値を含む LB フィールドは NV および NB オプションで定義されているため、Adabas では、何らかの文字コードページに従って LB フィールドバイナリ値が変換されることも、バイナリ値を含む LB フィールドで末尾の空白が削除されることもありません。
注意:
バイナリ値を含む LB フィールドの定義には、フォーマット B は使用されません。これは、一部の環境ではフォーマット B
が、バイト順の異なるバイトスワップを意味するためです。 バイトスワッピングは、バイナリ LB フィールドに適用されません。
次の表は、LB フィールドの FDT 定義の有効な例を示しています。
| FDT の指定 | 説明 |
|---|---|
1,L1,0,A,LB,NU |
フィールド L1 は、空値省略の文字型のラージオブジェクトフィールドです。 |
1,L2,0,A,LB,NV,NB,NU,MU |
フィールド L2 は空値省略、マルチプルバリュー、バイナリフィールド型のラージオブジェクトフィールドです。 |
LB フィールドを扱うコマンドの対象は、LOB ファイルグループの基本ファイルにする必要があります。 LOB ファイルに対するユーザーコマンドは拒否されます。
LB フィールドの基本的な情報については、「ラージオブジェクト(LB)フィールドの基本」を参照してください。
マルチプルバリューフィールドオプションでは、フィールドの同一レコードに複数の値を格納できることを示します。 MUPEX パラメータを指定し、MUPECOUNT パラメータを "2" に設定した場合、フィールドには 1 レコードあたり 65,534 までの値を格納できます。 これらのパラメータを設定しない場合、フィールドには 1 レコードあたり 191 までの値を格納できます。 ADACMP の各入力レコードには、最低 1 つの値(空値でも可)が含まれている必要があります。
値は、フィールドに指定された他のオプションに従って格納されます。 最初の値の先頭には、フィールドに現在存在する値の数を示すカウントフィールドが付けられます。 格納される値の数は、ADACMP 入力レコードに含まれる値の数に、フィールドを後で更新したときに追加された値を加え、省略された値を差し引いた数と等しくなります(このことは、フィールドが NU オプションを指定して定義されている場合にのみ適用されます)。
ADACMP の各入力レコードに含まれる値の数が一定の場合、その数を MU 定義ステートメントで MU(n) の形式で指定できます。n は各入力レコードに含まれる値の数です。 次の例では、各入力レコードにマルチプルバリューフィールド AA の 3 つの値が含まれています。
FNDEF='01,AA,5,A,MU(3)'
値にゼロ(MU(0))を指定した場合、入力レコードにはマルチプルバリューフィールドの値が含まれていないことを示します。
値の数がすべての入力レコードで一定でない場合、各入力レコードの最初の値の先頭に、そのレコードに含まれる値の数を示す 1 バイトまたは 2 バイトの 2 進数のカウントフィールド(MUPECOUNT パラメータの設定によって異なる)が付けられます(「入力データの必要条件」も参照)。
FDT を指定している場合(FDT パラメータの説明を参照)、フィールドカウントは各入力レコードに 1 バイトまたは 2 バイトのバイナリ値として含まれる必要があります(MUPECOUNT パラメータの設定によって異なる)。
入力レコードが DECOMPRESS 機能を使用して作成された場合、入力レコードには必要なすべてのカウントフィールドがすでに含まれています。 この場合、フィールド定義ステートメントでカウントを指定する必要はありません。
入力または更新時に含まれるすべての値が圧縮されます(FI オプションを一緒に指定している場合を除く)。 FI オプションと MU オプションを一緒に使用する場合は、注意が必要です。これは、圧縮可能な値が多数存在すると、大量のディスクストレージが浪費される可能性がるためです。
NU オプションと MU オプションが一緒に指定されている場合は、空値が論理的および物理的の両形式で圧縮されます。 すべての値(空値を含む)の位置的関係は、通常、MU オカレンスで維持されます(オカレンスが NU オプションで定義されている場合を除く)。 多数の空値が MU フィールドグループに存在する場合、NU オプションを指定することによって、フィールドで必要となるディスクストレージを軽減できます。ただし、値の相対位置を維持する必要がある場合は、このオプションを使用しないでください。
NC(または NC/NN)オプションは、MU フィールドに対しては指定できません。
圧縮レコード内の 191 より多い MU および PE オカレンスを識別する方法については、「圧縮レコード内の 191 を超える MU および PE オカレンスの特定」を参照してください。
FNDEF='01,AA,5,A,MU,NU'
元の内容(L は値の長さ):
ファイルのロード後:
| 3 | L 値 A | L 値 B | L 値 C |
|---|---|---|---|
| count | AA1 | AA2 | AA3 |
値 B を空値に更新後:
| 2 | L 値 A | L 値 C |
|---|---|---|
| count | AA1 | AA2 |
FNDEF='01,AA,5,A,MU'
元の内容(L は値の長さ):
ファイルのロード後:
| 3 | L 値 A | L 値 B | L 値 C |
|---|---|---|---|
| count | AA1 | AA2 | AA3 |
値 B を空値に更新後:
| 3 | L 値 A | L 値 B | L 値 C |
|---|---|---|---|
| count | AA1 | AA2 | AA3 |
NB オプションを LA および LB フィールドとともに使用すると、空白圧縮を制御できます。 NB オプションを指定すると、フィールドの末尾の空白が削除されなくなります。指定しない場合は、英数字またはワイド文字フィールドの値の格納時に末尾の空白が削除されます。 フィールドに NB オプションを指定した場合、そのフィールドに NU オプションまたは NC オプションも指定する必要があります。NB 処理には、NC または NU の使用も同時に必要となります。
注意:
NB オプションを使用せずにフィールドを指定すると、格納したときと取り出したときのフィールドの長さが異なる可能性があります。
取り出したときの非 NB フィールドの長さは、空白圧縮のために、格納したときにそのフィールドに指定した長さよりも短くなる可能性が高くなります。
これは、値が実際は文字列ではなく、空白を表す文字コードで終わるバイナリ値であった場合に問題となることがあります。
したがって、格納したときと取り出したときのフィールドの長さを同じにしたい場合は、NB オプションを使用します。
NU では、フィールド内の空値を省略します。
標準圧縮(NU または FI を指定していない場合)では、空値を 2 バイトで表します(値の長さが 1 バイト、値自体(この場合、空値)が 1 バイト)。 空値省略では、空値フィールドを 1 バイトの空値フィールドインジケータで表します。 空値自体は格納されません。
空値を含む一連の連続フィールドに NU オプションを指定した場合、フィールドは 1 バイトの空値フィールド(バイナリ 11nnnnnn)インジケータで表されます。ここで、nnnnnn は、合計 63 までの空値を含むフィールドの連続バイト数です。 このため、NU オプションで定義されたフィールドはできるだけグルーピングする必要があります。
ディスクリプタに NU オプションを指定した場合、ディスクリプタの空値はインバーテッドリストに格納されません。 したがって、検索コマンドでこのディスクリプタを使用した場合、および空値を検索値として使用した場合、常にレコードは選択されません。ディスクリプタの空値を含むデータストレージにレコードが存在する場合でも同様です。 NU オプションで定義されたディスクリプタを使用して、論理順読み込み(L3/L6)コマンドで論理順を制御する場合、ディスクリプタの空値を含むレコードは読み込まれません。
ディスクリプタをファイルカップリングの基準として使用し、そのディスクリプタに多数の空値が存在する場合、NU オプションを指定して、カップリングリストの合計サイズを軽減する必要があります。
NU オプションは、NC/NN 組み合わせオプションまたは FI オプションで定義されたフィールドに対しては指定できません。
NU の使用例
| 定義 | ユーザーデータ | 内部表現 | |
|---|---|---|---|
| 標準圧縮 | FNDEF='01,AA,2,B' | 0000 | 0200(2 バイト) |
| FI オプションあり | FNDEF='01,AA,2,B,FI' | 0000 | 0000(2 バイト) |
| NU オプションあり | FNDEF='01,AA,2,B,NU' | 0000 | C1(1 バイト)* |
* C1 は 1 つの空値フィールドを示します。
英数字(A)フォーマットまたはワイド文字フォーマット(W)のフィールド用の無変換オプションです。このオプションを指定すると、該当フィールドがレコードバッファ内で変換なしで処理されます。
NV オプションで定義されたフィールドは、ユーザーとの間で変換されません。フィールドではファイルエンコードの特徴(つまり、デフォルトの空白)が保持されます。
A フィールドの場合は、常に、EBCDIC の空白(X'40')になります。
W フィールドの場合は、常に、W フォーマットのファイルエンコードの空白になります。
NV オプションは、変換しても意味のないデータ、またはアプリケーションで保管されているままのデータが必要とされるために変換すべきでないデータを含むフィールドに使用します。
NV フィールドのフィールド長は、ユーザーアーキテクチャでバイトスワップが採用されている場合、バイトスワップされます。
NV フィールドについては、A フォーマットを W フォーマットに変換したり、W フォーマットを A フォーマットに変換したりすることはできません。
UQ では、フィールドがユニークディスクリプタであることを示します。 ユニークディスクリプタには、ファイル内の各レコードで異なる値が含まれている必要があります。 FNDEF ステートメントでは、DE オプションを指定している場合にのみ UQ オプションを指定できます。 UQ オプションは、SUBDE、SUPDE、および HYPDE ステートメントでも使用できます。
フィールドを ADAM ディスクリプタとして使用する場合、UQ オプションを指定する必要があります(ADAMER ユーティリティを参照)。
ユニーク値のチェックは、ADACMP では行われません。このチェックを行うには、ADALOD ユーティリティまたは ADAINV ユーティリティで INVERT 機能を実行します。 ファイルのロード中にユニークでない値が検出されると、ADALOD はエラーメッセージを出力して終了します。
ADAINV と ADALOD は拡張ファイルチェーン内のファイルごとに別々に実行する必要があるため、チェーン全体でユニークであるかどうかをチェックすることはできません。
ただし、Adabas では、拡張ファイルチェーン間でユニークディスクリプタの値をチェックできます。 追加(N1/N2)または更新(A1)対象の値がチェーン内のすべてのファイル間でユニークでない場合、レスポンスコード 198 が返されます。
デフォルトでは、ユニークディスクリプタ(UQ)として定義されたピリオディックグループ(PE)内のフィールドのオカレンス番号がディスクリプタ値の一部として含まれます。 つまり、異なるレコード内の別々のピリオディックグループオカレンスに同じフィールド値が含まれることもあります。
XI オプションを使用すると、値をユニークに保つために、ディスクリプタ値からオカレンス番号を除外できます。 XI オプションを設定した場合、すべてのレコード内の PE フィールドの全オカレンスで、フィールド値が 1 つまでに限定されます。
Adabas には、NC および NN の 2 つのデータ定義オプションがあります。これらのオプションを使用すると、Software AG のメインフレーム Adabas SQL Gateway(ACE)および他の SQL(Structured Query Language)データベース問い合わせ言語に対応する SQL 互換の空値表現を指定することができます。
NC および NN オプションは、以下で定義されたフィールドには適用できません。
Adabas 空値省略(NU)
固定小数点データタイプ(FI)
マルチプルバリュー(MU)
ピリオディックグループ内(PE)
グループフィールドとして
また、NN オプションは、NC オプションを指定したフィールドに対してのみ指定できます。
サブフィールド/スーパーフィールドまたはサブディスクリプタ/スーパーディスクリプタの親フィールドでは、NC オプションを指定できます。 ただし、単一のスーパーフィールドまたはディスクリプタの親フィールドでは、NU および NC フィールドを組み合わせて使用することはできません。 1 つの親フィールドが NC の場合、他の親フィールドを NU フィールドに指定することはできません。また、その逆についても同様です。
フィールド AA を定義し、NC および NN オプションを割り当てるための正しい ADACMP COMPRESS FNDEF ステートメントを以下に示します。
ADACMP FNDEF='01,AA,4,A,NN,NC,DE'
NC/NN オプションを不適切な方法で使用すると、ADACMP ユーティリティで ERROR-127 が発生します(次の例を参照)。
| 不適切な例 | 理由 |
|---|---|
| ADACMP FNDEF='01,AA,4,A,NC,NU' | NU オプションと NC オプションは互換性がありません。 |
| ADACMP FNDEF='01,AB,4,A,NC,FI' | NC オプションとおよび FI オプションは互換性がありません。 |
| ADACMP FNDEF='01,PG,PE' ADACMP FNDEF='02,P1,4,A,NC' |
PE グループ内で NC オプションを指定することはできません。 |
このセクションでは、次のトピックについて説明します。
NC(非カウント)オプションを使用しない場合、空値は、フィールドのフォーマットに応じて、ゼロまたは空白になります。
NC オプションを使用した場合、レコードバッファに指定されたゼロまたは空白は、空値インジケータ値に従って、真のゼロまたは空白として(つまり、有意性のある空値として)解釈されるか、または未定義値として(つまり、真の SQL または有意性のない空値として)解釈されます。
NC オプションで定義されたフィールドに、レコードバッファに指定された値が含まれていない場合、フィールド値は常に SQL 空値として扱われます。
真の SQL 空値として解釈された場合、その空値は SQL 解釈で値のないフィールドを示します。 つまり、 フィールド値は格納されていない(定義されていない)ことを示します。
空値インジケータ値には、空値の内部 Adabas 表現を示す役割があります。 詳細は、次のセクションの「空値インジケータ値」、および「サーチバッファ」を参照してください。
NC フィールドを含むレコードを圧縮または圧縮解除する際には次の規則が適用されます。
FORMAT パラメータを指定している場合、ADACMP は、更新タイプのコマンドに対するニュークリアスの動作と同じように動作します。 『Adabas コマンドリファレンス』を参照してください。
FORMAT パラメータを指定していない場合
圧縮の場合:
NC フィールドの値のみが入力レコードに含まれます。空値インジケータバイト(2 バイト)は省略する必要があります。 値は、空値インジケータバイトがゼロに設定されている場合と同じように圧縮されます。 この方法で NC フィールドに空値を割り当てることはできません。
例
| フィールド定義テーブル(FDT)の定義 |
FNDEF='01,AA,4,A,NC' |
|---|---|
| 入力レコードの内容: |
MIKE |
圧縮解除の場合:
NC フィールドの値に有意性がない場合、レコードは DDFEHL(または FEHL)に書き込まれ、レスポンスコード 55 が返されます。
NC フィールドの値に有意性がある場合、値は通常どおり圧縮解除されます。 空値インジケータバイトはありません。
例
| フィールド定義テーブル(FDT)の定義 |
FNDEF='01,AA,4,A,NC' |
|---|---|
| 出力レコードの内容 |
MIKE |
空値インジケータ値は、データフォーマットにかかわらず、常に 2 バイトであり、固定小数点フォーマットです。 フィールド値が追加または変更されたときにレコードバッファに指定され、フィールド値が読み込まれたときにレコードバッファに返されます。
更新(Ax)コマンドまたは追加(Nx)コマンドでは、フォーマットバッファのフィールド指定に対応するレコードバッファ位置に空値インジケータ値を設定する必要があります。 設定は次のいずれかにする必要があります。
| 16 進数値 | 意味 |
|---|---|
| X'FFFF' | フィールド値を "未定義"、つまり有意性のない空値に設定します。レコードバッファ内のフィールドに値が指定されていないこと、バイナリの 0 が指定されていること、および空白が指定されていることの違いは、無視されます。すべてが "値が指定されていない" として解釈されます。 |
| 0000 | レコードバッファ内のフィールドに値が指定されていない場合、バイナリの 0 が指定されている場合、および空白が指定されている場合は、有意性のある空値が指定されているものとして解釈されます。 |
読み込み(Lx)コマンド、または読み込みを伴う検索(フォーマットバッファエントリを含む Sx)コマンドでは、フォーマットバッファのフィールドの位置に対応するレコードバッファ位置に空値インジケータ値が返されたかどうかをプログラムで確認する必要があります。 空値インジケータ値は、次の値のいずれかになります。これらの値はそれぞれ、選択したフィールドに含まれる実際の値の意味を示します。
| 16 進数値 | 意味 |
|---|---|
| X'FFFF' | フィールド内のゼロまたは空白には有意性がありません。 |
| 0000 | フィールド内のゼロまたは空白は有意性のある値(つまり、真のゼロまたは空白)です。 |
| xxxx | フィールドは切り捨てられます。 空値インジケータ値には、データベースレコードに格納されたとおりの値の全長(xxxx)が含まれます。 |
NC オプションで定義された 2 バイトの Adabas バイナリフィールド AA での空値のフィールド定義を以下に示します。
01,AA,2,B,NC
| 空値インジケータ値 (レコードバッファ) |
Adabas の内部表現 | ||
|---|---|---|---|
| ゼロ以外の値 | 0(バイナリの値に有意性あり) | 0005 | 0205 |
| 空白 | 0(バイナリの空値に有意性あり) | 0000(ゼロ) | 0200 |
| 空値 | FFFF(バイナリの空値に有意性なし) | (無関係) | C1 |
NN(非空値または空値指定不可)オプションは、データフィールドに NC オプションも指定している場合にのみ指定できます。 NN オプションでは、NC フィールドには必ず値(ゼロまたは空白を含む)が定義されている必要があることを示します。フィールドには、"値を指定する" 必要があります。
NN オプションを使用すると、レコードが追加または更新されたときにフィールドが未定義のまま残らなくなります。フィールドには、有意性のある値が必ず設定されている必要があります。 そうでない場合、Adabas からレスポンスコード 52 が返されます。
次の例は、NN オプションを指定した場合と指定しない場合に、2 バイトの Adabas 英数字フィールド AA で有意性のない空値がどのように処理されるかを示しています。
NN オプションを指定した場合、または指定しない場合に、2 バイトの Adabas 英数字フィールド AA では、有意性のない空値は次のように処理されます。
| オプション | フィールド定義 | 空値インジケータ値 | Adabas の内部表現 |
|---|---|---|---|
| NN 指定あり | 01,AA,2,A,NC,NN | FFFF(有意性のない空値) | なし(レスポンスコード 52 が返される) |
| NN 指定なし | 01,AA,2,A,NC | FFFF(有意性のない空値) | C1 |
ピリオディックグループ定義のエントリを構成するには、次の構文を使用します。

レベル番号と名前は必須です。 定義エントリの間に空白をいくつ入れても構いません。
これらの定義の各 FNDEF パラメータについては、このセクションで説明されています。
レベル番号は 01~07 の範囲内の 1 桁または 2 桁の数字(先行のゼロは任意)を使用し、フィールドグルーピングと合わせて使用します。 02 またはそれ以上のレベル番号のついたフィールドは、それより小さいレベル番号のついた直前のグループの一部であるとみなされます。
グループで定義すると、グループ名を使用して一連のフィールド(または 1 つのフィールドだけでもよい)を参照することができます。 これは一連の連続フィールドを参照するのに便利で効果的な方法です。
レベル番号 01~06 は、グループの定義に使用することができます。 グループは他のグループを含むことができます。 ネスト構造のグループにレベル番号をつけるときは、レベル番号を飛ばしてはなりません。
次の例では、フィールド A1 および A2 はグループ GA に含まれます。 フィールド B1 とグループ GC(フィールド C1 と C2 で構成)はグループ GB に含まれます。
| FNDEF='01,GA' | グループ | |
| FNDEF='02,A1,...' | エレメンタリまたはマルチプルバリューフィールド | |
| FNDEF='02,A2,...' | エレメンタリまたはマルチプルバリューフィールド | |
| FNDEF='01,GB' | グループ | |
| FNDEF='02,B1,...' | エレメンタリまたはマルチプルバリューフィールド | |
| FNDEF='02,GC' | グループ(ネスト構造) | |
| FNDEF='03,C1,...' | エレメンタリまたはマルチプルバリューフィールド | |
| FNDEF='03,C2,...' | エレメンタリまたはマルチプルバリューフィールド |
フィールド(またはグループ)に割り当てる名前を指定します。
名前はファイル内でユニークでなければなりません。 名前は 2 文字で指定しなければならず、最初の文字は英字で、2 番目の文字は英字か数字でなければなりません。 特殊文字は使用できません。
値 E0~E9 は編集マスク用に予約されており、使用してはなりません。
| 正しい名前例 | 誤りの名前例 |
|---|---|
| AA | A(2 文字ではない) |
| B4 | E3(編集マスク) |
| S3 | F*(特殊文字が含まれている) |
| WM | 6M(最初の文字が英字ではない) |
ピリオディックグループフィールドオプションでは、グループフィールドの後に、特定レコードで複数回使用できるピリオディックグループ定義が続くことを示します。 MUPEX パラメータを指定し、MUPECOUNT パラメータを "2" に設定した場合、ピリオディックグループは 1 レコードあたり最大で 65,534 回使用できます。 これらのパラメータを設定しない場合、ピリオディックグループは 1 レコードあたり最大で 191 回使用できます。 各 ADACMP 入力レコードには、1 つ以上のオカレンス(オカレンス内の値がすべて空値の場合でも可)が存在する必要があります。
ピリオディックグループ:
1 つ以上のフィールドで構成されます。 最大で 254 のエレメンタリフィールドを指定できます。 ディスクリプタまたはマルチプルバリューフィールド(あるいはその両方)、および他のグループを指定できますが、ピリオディックグループに別のピリオディックグループを含めることはできません。
MUPEX パラメータを指定し、MUPECOUNT パラメータを "2" に設定した場合、ピリオディックグループは特定グループ内で 0~65,534 回使用できます。ただし、各 ADACMP 入力レコードには、1 つ以上のオカレンス(オカレンス内の値がすべて空値の場合でも可)が存在する必要があります。 これらのパラメータを設定しない場合、ピリオディックグループは特定グループ内で 0~191 回使用できます。
01 レベルで定義する必要があります。 ピリオディックグループ内のすべてのフィールドが直後に続き、さらにレベル 02 以上で定義されている必要があります(最大で 7 まで 1 ずつ増加)。 次の 01 レベル定義は、現在のピリオディックグループの終了を示します。
グループ名とともにのみ指定できます。 長さパラメータとフォーマットパラメータをグループ名とともに指定することはできません。
圧縮レコード内の 191 より多い MU および PE オカレンスを識別する方法については、「圧縮レコード内の 191 を超える MU および PE オカレンスの特定」を参照してください。
ピリオディックグループ定義の 2 つの例を以下に示します。
FNDEF='01,GA,PE' FNDEF='02,A1,6,A,NU' FNDEF='02,A2,2,B,NU' FNDEF='02,A3,4,P,NU'
この例では、ピリオディックグループ GA はフィールド A1、A2、および A3 で構成されます。 レコード内のピリオディックグループのオカレンス数は、1 バイトまたは 2 バイトのバイナリ値として定義されます(MUPECOUNT パラメータの設定によって異なる)。すべてのレコードで、各オカレンスグループの前に指定します。
FNDEF='01,GB,PE(3)' FNDEF='02,B1,4,A,DE,NU' FNDEF='02,B2,5,A,MU(2),NU' FNDEF='02,B3' FNDEF='03,B4,20,A,NU' FNDEF='03,B5,7,U,NU'
この例では、ピリオディックグループ GB はフィールド B1、B2、およびグループ B3(フィールド B4 および B5 を含む)で構成されます。 レコードには、ピリオディックグループの 3 つのオカレンスを含めることができます。
MUPEX オプションを指定している場合に、レコード内に含める PE フィールドのオカレンスの数を指定します。 これは任意のパラメータです。
照合ディスクリプタオプションを使用すると、ユーザー指定のアルゴリズムに基づいてディスクリプタ値をソート(照合)できます。
値は、特別な照合ディスクリプタユーザー出口(CDX01~CDX08)でコーディングされたアルゴリズムに基づきます。 各照合ディスクリプタはユーザー出口に割り当てられなければならず、単一のユーザー出口は複数の照合ディスクリプタを処理します。

照合出口機能は次のイベントで呼び出されます。
ニュークリアスセッションの開始
照合出口が定義されたときのユーティリティの初期化(ADARUN パラメータ)
親の値の更新/挿入/削除(ニュークリアス)
照合ディスクリプタを検索値に指定して検索(ニュークリアス)
レコードの圧縮(ADACMP)
出口が DECODE 機能をサポートする場合のみ、照合 DE によるインデックス(L9)の読み込み(ニュークリアス)
ユーザー出口に対して指定する入力パラメータについては、「照合ディスクリプタ出口 01~08」を参照してください。 入力パラメータには次のものがあります。
入力文字列のアドレスと長さ
出力エリアのアドレスとサイズ
返される出力文字列長のフルワードのアドレス
ユーザー出口によって、返される出力文字列の長さが設定されます。
詳細は、「CDXnn:照合ディスクリプタユーザー出口」を参照してください。
注意:
照合ディスクリプタは、次の構文を使用して定義します。

上記の意味は次に示すとおりです。
| number | 照合ディスクリプタに割り当てるユーザー出口番号です。 Adabas ニュークリアスでは、この番号を使用して、呼び出す照合ディスクリプタユーザー出口を決定します。 |
| name | 照合ディスクリプタに使用する名前です。 照合ディスクリプタの命名規則は、Adabas フィールド名の命名規則と同一です。 |
| UQ | ユニークディスクリプタオプションを照合ディスクリプタに割り当てることを示します。 |
| XI | インデックス(オカレンス)番号を除外することによって、照合ディスクリプタをユニークに保つことを示します。 |
| parent-field | エレメンタリ A または W フィールドの名前です。 照合ディスクリプタには、1 つの親フィールドを含めることができます。 フィールド名とアドレスはユーザー出口に渡されます。 |
MU、NU、および PE オプションは親フィールドから取得され、照合ディスクリプタに暗黙的に設定されます。
親フィールドを NU オプションで指定した場合、空値フィールドを含むレコードについては照合ディスクリプタのインバーテッドリストにエントリが作成されません。 これは、他の照合ディスクリプタエレメントの値の有無にかかわらず同様です。
親フィールドが初期化されず、論理的に物理レコードの終了を超えた場合、そのレコードのインバーテッドリストエントリは、パフォーマンスの理由から生成されません。 このとき、インバーテッドリストエントリを生成するには、ファイルのアンロード、圧縮解除、再ロードを行います。あるいは、アプリケーションプログラムを使用してファイルのレコードごとにフィールドを初期化してください。
フィールド定義:
FNDEF='01,LN,20,A,DE,NU' Last-Name
照合ディスクリプタ定義:
COLDE='1,Y2=LN'
照合ディスクリプタユーザー出口 1(CDX01)がこの照合ディスクリプタに割り当てられます。名前は Y2 です。
照合ディスクリプタの長さとフォーマットは親フィールドから取得されます。長さとフォーマットはそれぞれ 20 と英数字です。 照合ディスクリプタは、空値省略(NU)のマルチプルバリュー(MU)フィールドです。
照合ディスクリプタの値は、親フィールド LN から派生します。
ハイパーディスクリプタオプションを使用すると、ユーザー指定のアルゴリズムに基づいてディスクリプタ値を生成できます。
値は、特別なハイパーディスクリプタユーザー出口(HEX01~HEX31)でコーディングされたアルゴリズムに基づきます。 各ハイパーディスクリプタはユーザー出口に割り当てられる必要があり、単一のユーザー出口で複数のハイパーディスクリプタが処理されます。

ハイパーディスクリプタ値が Adabas ニュークリアスまたは ADACMP ユーティリティによって処理されるとき、常に出口が呼び出されます。
ユーザー出口に対して指定する入力パラメータを以下に示します。
ハイパーディスクリプタ名
ファイル番号
データストレージレコードからフィールド名と PE インデックス(該当する場合)とともに取得されるフィールドのアドレス これらのアドレスは圧縮後のフィールド値を指します。 これらのフィールドの名前は、ADACMP または ADAINV の HYPDE パラメータを使用して定義する必要があります。
ユーザー出口からはディスクリプタ値(DVT)が圧縮形式で返される必要があります。 ハイパーディスクリプタに割り当てられているオプション(PE、MU)に応じて、値が返されないか、1 つ以上の値が返されます。
入力値に割り当てられている元の ISN は変更可能です。
ハイパーディスクリプタユーザー出口の詳細は、「ハイパーディスクリプタ出口 01 - 31」を参照してください。
注意:
ハイパーディスクリプタは、次の構文を使用して定義します。

ここでは次の内容を表しています。
| number | ハイパーディスクリプタに割り当てるユーザー出口番号です。 Adabas ニュークリアスでは、この番号を使用して、呼び出すハイパーディスクリプタユーザー出口を決定します。 | ||||||||||||||||||
| name | ハイパーディスクリプタに使用する名前です。 ハイパーディスクリプタの命名規則は、Adabas フィールド名の命名規則と同一です。 | ||||||||||||||||||
| length | ハイパーディスクリプタのデフォルトの長さです。 | ||||||||||||||||||
| format |
|
||||||||||||||||||
| option |
|
||||||||||||||||||
| parent-field | エレメンタリフィールドの名前です。 ハイパーディスクリプタには、1~20 の親フィールドを含めることができます。
フィールド名とアドレスはユーザー出口に渡されます。
注意: |
||||||||||||||||||
親フィールドを NU オプションで指定した場合、空値フィールドを含むレコードについてはハイパーディスクリプタのインバーテッドリストにエントリが作成されません。 このことは、他のハイパーディスクリプタエレメントの値の有無にかかわらず同様です。
親フィールドが初期化されず、論理的に物理レコードの終了を超えた場合、そのレコードのインバーテッドリストエントリは、パフォーマンスの理由から生成されません。 このとき、インバーテッドリストエントリを生成するには、ファイルのアンロード、圧縮解除、再ロードを行います。あるいは、アプリケーションプログラムを使用してファイルのレコードごとにフィールドを初期化してください。
フィールド定義:
FNDEF='01,LN,20,A,DE,NU' Last-Name FNDEF='01,FN,20,A,MU,NU' First-Name FNDEF='01,ID,4,B,NU' Identification FNDEF='01,AG,3,U' Age FNDEF='01,AD,PE' Address FNDEF='02,CI,20,A,NU' City FNDEF='02,ST,20,A,NU' Street FNDEF='01,FA,PE' Relatives FNDEF='02,NR,20,A,NU' R-Last-Name FNDEF='02,FR,20,A,MU,NU' R-First-Name
ハイパーディスクリプタ定義:
HYPDE='2,HN,60,A,MU,NU=LN,FN,FR'
ハイパーディスクリプタユーザー出口 2 がこのハイパーディスクリプタに割り当てられます。名前は HN です。
ハイパーディスクリプタは、空値省略(NU)のマルチプルバリュー(MU)フィールドで、その長さは 60、フォーマットは英数字です。
ハイパーディスクリプタの値は、フィールド LN、FN、および FR から派生します。
ADACMP HYPDE= ステートメントは、次の例に示すように、別の行に続けることができます。 そのためには、まず、最初の行の引数全体の後、閉じ引用符の前にマイナス(-)を指定します。 その後、次の行のステートメント名(ADACMP)の直後に、残りの位置引数を引用符で囲んで入力します。
ADACMP HYPDE='1,HY,20,A=AA,BB,CC,-' ADACMP 'DD,EE,FF'
FIND コマンドでフォネティックディスクリプタを使用すると、類似したフォネティック値を含むすべてのレコードが返されます。 ディスクリプタのフォネティック値は、フィールド値の先頭 20 バイトに基づきます。 英字の値のみが考慮され、数値、特殊文字、および空白は無視されます。 英数字の大文字と小文字は、内部的に同一のものとして処理されます。
フォネティックディスクリプタは、次の構文を使用して定義します。

ここでは次の内容を表しています。
| name | フォネティックディスクリプタに使用する名前です。 フォネティックディスクリプタの命名規則は、Adabas フィールド名の命名規則と同一です。 |
| field | フォネティック処理されるフィールドの名前です。 |
フィールドは次の要件を満たす必要があります。
エレメンタリフィールドまたはマルチプルバリューフィールドであること
英数字フォーマットで定義されていること
フィールドはディスクリプタとして指定できます。
フィールドは次のようには指定できません。
サブディスクリプタ、スーパーディスクリプタ、またはハイパーディスクリプタ
ピリオディックグループ内
複数のフォネティックディスクリプタのソースフィールドとして
フォーマット W(ワイド文字)
フィールドを NU オプションで定義した場合、空値フィールド(指定のバイト位置内)を含むレコードについてはフォネティックディスクリプタのインバーテッドリストにエントリが作成されません。 フォーマットはフィールドの場合と同一です。
フィールドが初期化されず、論理的に物理レコードの終了を超えた場合、そのレコードのインバーテッドリストエントリは、パフォーマンスの理由から生成されません。 このとき、インバーテッドリストエントリを生成するには、ファイルのアンロード、圧縮解除、再ロードを行います。あるいは、アプリケーションプログラムを使用してファイルのレコードごとにフィールドを初期化してください。
フィールド定義:
FNDEF='01,AA,20,A,DE,NU'
フォネティック定義:
PHONDE='PA(AA)'
サブディスクリプタは、エレメンタリフィールドの一部から作成されるディスクリプタです。 そのエレメンタリフィールドは、ディスクリプタ自体であってもなくてもかまいません。 サブディスクリプタはサブフィールドとしても使用できます。つまり、レコードの出力フォーマットを制御するために、フォーマットバッファに指定できます。
サブディスクリプタは、次の構文を使用して定義します。

ここでは次の内容を表しています。
| name | サブディスクリプタ名です。 サブディスクリプタの命名規則は、Adabas フィールド名の命名規則と同一です。 |
| UQ | サブディスクリプタをユニークとして定義することを示します(オプション UQ の定義を参照)。 |
| XI | インデックス(オカレンス)番号を除外することによって、サブディスクリプタをユニークに保つことを示します(オプション XI の定義を参照)。 |
| parent-field | サブディスクリプタの派生元フィールドの名前です。 |
| begin | サブディスクリプタ定義を開始する親フィールド内の相対バイト位置です。 |
| end | サブディスクリプタ定義を終了する親フィールド内の相対バイト位置です。 |
* カウントは、英数字またはワイド文字フィールドの場合は左から右へと 1 から行われ、数値またはバイナリフィールドの場合は右から左へと 1 から行われます。 親フィールドを P フォーマットで定義した場合、出力サブディスクリプタ値の符号は下位バイトの下位 4 ビット(つまり、バイト 1)から取得されます。
サブディスクリプタの親フィールドは次のように指定できます。
ディスクリプタ
エレメンタリフィールド
マルチプルバリューフィールド(ただし、マルチプルバリューフィールドの特定のオカレンスは不可)
ピリオディックグループ内(ただし、ピリオディックグループの特定のオカレンス内は不可)
サブディスクリプタの親フィールドは次のようには指定できません。
サブ/スーパーフィールド、サブディスクリプタ、スーパーディスクリプタ、またはフォネティックディスクリプタ
フォーマット G(浮動小数点)
親フィールドを NU オプションで定義した場合、空値フィールド(指定のバイト位置内)を含むレコードについてはサブディスクリプタのインバーテッドリストにエントリが作成されません。 フォーマットは親フィールドの場合と同一です。
親フィールドが初期化されず、論理的に物理レコードの終了を超えた場合、そのレコードのインバーテッドリストエントリは、パフォーマンスの理由から生成されません。 このとき、インバーテッドリストエントリを生成するには、ファイルのアンロード、圧縮解除、再ロードを行います。あるいは、アプリケーションプログラムを使用してファイルのレコードごとにフィールドを初期化してください。
親フィールド定義:
FNDEF='01,AR,10,A,NU'
サブディスクリプタ定義:
SUBDE='SB=AR(1,5)'
サブディスクリプタ SB の値は、親フィールド AR のすべての値の先頭 5 バイト(左から右にカウント)から派生します。 すべての値は文字フォーマットで示されます。
| AR 値 | SB 値 |
|---|---|
| DAVENPORT | DAVEN |
| FORD | FORD |
| WILSON | WILSO |
親フィールド定義:
FNDEF='02,PF,6,P'
サブディスクリプタ定義:
SUBDE='PS=PF(4,6)'
サブディスクリプタ PS の値は、親フィールド PF のすべての値の 4~6 バイト(右から左にカウント)から派生します。 すべての値は 16 進数で示されます。
| PF 値 | PS 値 |
|---|---|
| 00243182655F | 02431F |
| 00000000186F | 0F(注参照) |
| 78426281448D | 0784262D |
注意:
親フィールド PF に NU オプションが指定されている場合、この値に対応する PS 値は作成されません。
ソースフィールド定義:
FNDEF='02,PF,6,P'
サブディスクリプタ定義:
SUBDE='PT=PF(1,3)'
PT の値は、PF のすべての値の 1~3 バイト(右から左にカウント)から派生します。 すべての値は 16 進数で示されます。
| PF 値 | PT 値 |
|---|---|
| 00243182655F | 82655F |
| 00000000186F | 186F |
| 78426281448D | 81448D |
サブフィールドには、次のような特徴があります。
Adabas 読み込みコマンドで読み込むことができるエレメンタリフィールドの一部です。
更新できません。
ADAINV INVERT SUBDE=... を使用してサブディスクリプタに変更できます。
サブフィールドは、次の構文を使用して定義します。
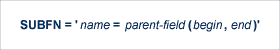
ここでは次の内容を表しています。
| name | サブフィールド名です。 サブフィールドの命名規則は、Adabas フィールド名の命名規則と同一です。 |
| parent-field | サブフィールドの派生元フィールドの名前です。 |
| begin* | サブフィールド定義を開始する親フィールド内の相対バイト位置です。 |
| end* | サブフィールド定義を終了する親フィールド内の相対バイト位置です。 |
* カウントは、英数字またはワイド文字フィールドの場合は左から右へと 1 から行われ、数値またはバイナリフィールドの場合は右から左へと 1 から行われます。 親フィールドを P フォーマットで定義した場合、出力サブフィールド値の符号は下位バイトの下位 4 ビット(つまり、バイト 1)から取得されます。
サブフィールドの親フィールドは次のように指定できます。
マルチプルバリューフィールド
ピリオディックグループ内
サブフィールドの親フィールドは G フォーマット(浮動小数点)にはできません。
SUBFN='X1=AA(1,2)'
スーパーディスクリプタは、複数のフィールド、フィールドの一部、またはこれらの組み合わせから作成されるディスクリプタです。
スーパーディスクリプタの定義に使用される各ソースフィールド(フィールドの一部)は、親と呼ばれます。 スーパーディスクリプタの定義には、2~20 の親フィールドまたはフィールドの一部を使用できます。 合計サイズは、253 以下である必要があります。
スーパーディスクリプタはユニークディスクリプタとして定義できます。
スーパーディスクリプタはスーパーフィールドとしても使用できます。つまり、レコードの出力フォーマットを決定するために、フォーマットバッファに指定できます。
このセクションでは、次のトピックについて説明します。
スーパーディスクリプタは、次の構文を使用して定義します。
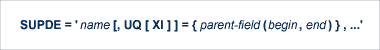
ここでは次の内容を表しています。
| name | スーパーディスクリプタ名です。 スーパーディスクリプタの命名規則は、Adabas の名前の命名規則と同一です。 |
| UQ | スーパーディスクリプタをユニークとして定義することを示します(オプション UQ の定義を参照)。 |
| XI | インデックス(オカレンス)番号を除外することによって、スーパーディスクリプタをユニークに保つことを示します(オプション XI の定義を参照)。 |
| parent-field | スーパーディスクリプタエレメントの派生元の親フィールドの名前です。最大で 20 の親フィールドを指定できます。 |
| begin* | スーパーディスクリプタエレメントを開始するフィールド内の相対バイト位置です。 |
| end* | スーパーディスクリプタエレメントを終了するフィールド内の相対バイト位置です。 |
* カウントは、英数字またはワイド文字フォーマットで定義されたフィールドの場合は左から右へと 1 から行われ、数値またはバイナリフォーマットで定義されたフィールドの場合は右から左へと 1 から行われます。 すべての親フィールド(FI で定義された親フィールドを除く)について、親フィールドのデータタイプで許可されている範囲内の開始値と終了値が有効です。
スーパーディスクリプタの親フィールドは次のように指定できます。
エレメンタリフィールド
最大 1 つの MU フィールド(ただし、特定の MU フィールド値は不可)
ピリオディックグループ内(ただし、特定のオカレンス内は不可)
ディスクリプタ
スーパーディスクリプタの親フィールドは次のようには指定できません。
スーパーディスクリプタ、サブディスクリプタ、またはフォネティックディスクリプタ
フォーマット G(浮動小数点)
NC オプションフィールド(別の親フィールドが NU オプションフィールドの場合)
ロング英数字(LA)フィールド
親フィールドを NC または NU オプションで指定した場合、空値フィールドを含むレコードについてはスーパーディスクリプタのインバーテッドリストにエントリが作成されません。 つまり、親の値が空値で、かつ NC/NU オプションが指定されている場合、値は作成されません。 このことは、他のスーパーディスクリプタエレメントの値の有無にかかわらず同様です。
親フィールドが初期化されず、論理的に物理レコードの終了を超えた場合、そのレコードのインバーテッドリストエントリは、パフォーマンスの理由から生成されません。 このとき、インバーテッドリストエントリを生成するには、ファイルのアンロード、圧縮解除、再ロードを行います。あるいは、アプリケーションプログラムを使用してファイルのレコードごとにフィールドを初期化してください。
スーパーディスクリプタ値の合計長は、253 バイト(英数字)または 126 バイト(2 進数)を超えない必要があります。
A(英数字)または W(ワイド文字)親フィールドから派生したスーパーディスクリプタエレメントが存在しない場合、スーパーディスクリプタのフォーマットは B(2 進数)です。A または W 親フィールドから派生したスーパーディスクリプタエレメントが存在する場合、スーパーディスクリプタのフォーマットには、最後の A または W エレメントが反映されます。例えば、最後の A または W エレメントが W の場合、スーパーディスクリプタのフォーマットは W になります。
バイナリ形式のすべてのスーパーディスクリプタが符号なしの数として処理されます。
ADACMP SUPDE= ステートメントは、別の行に続けることができます。そのためには、最初の行の閉じ引用符の直前にある引数の後にマイナス(-)を指定します。 その後、次の行のステートメント名(ADACMP)の直後に、残りの位置引数を引用符で囲んで入力します。 例としては、次のようなものがあります。
ADACMP SUPDE='SI=AA(10,20),BB(20,21),-' ADACMP 'CC(12,13),DD(14,15)'
スーパーディスクリプタに対するインターフェイスとして次のコマンドを使用できます。
| Adabas コマンド | スーパーディスクリプタ値は次のいずれかです。 |
|---|---|
| N1 または A1 | 親フィールドでスーパーディスクリプタの作成が強制される場合に、挿入処理および更新処理を行うと特定のフィールドを使用して暗黙的に構築されます。 |
| Sx または L3 | 検索式および論理読み込みのバリューバッファに指定されます。 |
| L9 | レコードバッファに返されます。 |
スーパーディスクリプタには、次のように計算される最終のスーパーディスクリプタフォーマットが適用されます。
| スーパーディスクリプタのフォーマット | 使用される状況: |
|---|---|
| A(英字) | 少なくとも 1 つの親フィールドがフォーマット A の場合 |
| B(2 進数) | 他のすべてがスーパーディスクリプタフィールドの場合 |
このセクションでは、次のトピックについて説明します。
注意:
変換が実行されるのは、親フィールドが NV
オプションで設定されている場合のみです。
スーパーディスクリプタは、すべての環境で同じ照合順序が適用されるように構築される必要があります。 ただし、このセクションで説明されているとおり、一部の組み合わせでは問題が発生します。
UNIX データベースに対する挿入または更新コールが IBM メインフレーム環境からのものである場合、すべての英字フィールドの値が EBCDIC から ASCII に変換されます。 その結果として、スーパーディスクリプタの親の値が自動的に ASCII に変換されます。 この場合、アプリケーションで特定のソート順(例えば、大文字と小文字の使用)が要求されるとき、処理が失敗する可能性があります。 EBCDIC フォーマットでは、小文字は大文字の前にきて、ASCII フォーマットでは、この順序が逆になります(大文字が小文字の前にきます)。
次の 2 つの方法のいずれかを使用して、この問題を解決できます。
EBCDIC-ASCII 矛盾を持つ親フィールドに対して NV オプションを使用します。 これにより、EBCDIC-ASCII 変換が無効になります。
スーパーディスクリプタの代わりにハイパーディスクリプタを使用します。
UNIX データベースに対する挿入または更新コールが IBM メインフレーム環境からのものである場合、すべての数字フィールドの値が EBCDIC から ASCII に変換されます。 その結果として、スーパーディスクリプタの親の値が自動的に ASCII に変換されます。最終のスーパーディスクリプタによって A(英字)または B(2 進数)フォーマットが要求された場合でも同様です。
プラットフォームによっては、バイナリバイト順序がビッグエンディアンフォーマットまたはリトルエンディアンフォーマットで格納されることがあります。 例えば、IBM および HP-UX プロセッサでは、ビッグエンディアンフォーマット(バイトは右から左に評価)で使用され、Intel プロセッサではリトルエンディアン順(バイトは左から右に評価)が使用されます。
Adabas では、スワップアーキテクチャのバイナリ値(左から右に評価されるリトルエンディアンバイナリ値)を含むスーパーディスクリプタを変換し、それらをインデックスに格納する前に標準ソート順にします。
親の長さが 1 を超えるバイナリフィールドを 1 つ以上含む英字のスーパーディスクリプタの場合、バイナリの親の値がスワップされます。
バイナリのスーパーディスクリプタの場合、親エントリの順序がスワップされ、バイナリ以外の親の値がスワップされます。
パック値の符号情報の表現は、プラットフォームによって異なります。 Adabas がオープンシステム上にある場合は、正の値(A、C、または F)が C に変換され、負の値(B または D)が D に変換されます。 Adabas がメインフレーム上にある場合は、正の値は F で表されます。 この結果、パック値がスーパーディスクリプタで使用されている場合は、パック値の符号から意味が失われる(標準のビットパターンになる)ため、照合順序の問題が発生します。 この問題が発生した場合、正のパック値が負のパック値としてソートされる可能性があります。
さらに、パック値がスーパーディスクリプタに組み込まれている場合、メインフレーム向けの Adabas では負のパック値が正のパック値の前にソートされ、オープンシステム向けの Adabas では正のパック値が負のパック値の前にソートされます。
これらの問題を解決するために、スーパーディスクリプタの代わりにハイパーディスクリプタを使用することをお勧めします。
スーパーディスクリプタがバリューバッファに指定されている場合、関連するインデックスエントリと一致するように変換されます。
L9 コマンドで取得されたスーパーディスクリプタ値は、レコードバッファに返される前に変換される必要があります。 英字フィールドは、必要に応じて ASCII から EBCDIC に変換されます。 また、必要に応じて、スーパーディスクリプタのバイナリ部分がスワップされます。 スーパーディスクリプタのパック値部分のパック符号は変換されません。
フィールド定義:
FNDEF='01,LN,20,A,DE,NU' Last-Name FNDEF='01,FN,20,A,MU,NU' First-Name FNDEF='01,ID,4,B,NU' Identification FNDEF='01,AG,3,U' Age FNDEF='01,AD,PE' Address FNDEF='02,CI,20,A,NU' City FNDEF='02,ST,20,A,NU' Street FNDEF='01,FA,PE' Relatives FNDEF='02,NR,20,A,NU' R-Last-Name FNDEF='02,FR,20,A,MU,NU' R-First-Name
スーパーディスクリプタ定義:
SUPDE='SD=LN(1,4),ID(3,4),AG(2,3)'
スーパーディスクリプタ SD を作成します。 スーパーディスクリプタの値は、フィールド LN のバイト 1~4(左から右にカウント)、フィールド ID のバイト 3~4(右から左にカウント)、およびフィールド AG のバイト 2~3(右から左にカウント)から派生します。 すべての値は 16 進数で示されます。
| LN | ID | AG | SD |
|---|---|---|---|
| C6D3C5D4C9D5C7 | 00862143 | F0F4F3 | C6D3C5D40086F0F4 |
| D4D6D9D9C9E2 | 02461866 | F0F3F8 | D4D6D9D90246F0F3 |
| D7C1D9D2C5D9 | 00000000 | F0F3F6 | ID により値は格納されない |
| 404040404040 | 00432144 | F0F0F0 | LN により値は格納されない |
| C1C1C1C1C1C1 | 00000144 | F1F1F1 | C1C1C1C10000F1F1 |
| C1C1C1C1C1C1 | 00860000 | F0F0F0 | C1C1C1C10086F0F0 |
英数字フォーマットで定義された親フィールドから 1 つ以上のエレメントが派生しているため、SD のフォーマットは英数字になります。
フィールド定義:
FNDEF='01,LN,20,A,DE,NU' Last-Name FNDEF='01,FN,20,A,MU,NU' First-Name FNDEF='01,ID,4,B,NU' Identification FNDEF='01,AG,3,U' Age FNDEF='01,AD,PE' Address FNDEF='02,CI,20,A,NU' City FNDEF='02,ST,20,A,NU' Street FNDEF='01,FA,PE' Relatives FNDEF='02,NR,20,A,NU' R-Last-Name FNDEF='02,FR,20,A,MU,NU' R-First-Name
スーパーディスクリプタ定義:
SUPDE='SY=LN(1,4),FN(1,1)'
スーパーディスクリプタ SY をフィールド LN および FN(マルチプルバリューフィールド)から作成します。 すべての値は文字フォーマットで示されます。
| LN | FN | SY |
|---|---|---|
| FLEMING | DAVID | FLEMD |
| MORRIS | RONALD RON | MORRR MORRR |
| WILSON | JOHN SONNY | WILSJ WILSS |
英数字フォーマットで定義された親フィールドから 1 つ以上のエレメントが派生しているため、SY のフォーマットは英数字になります。
フィールド定義:
FNDEF='01,PN,6,U,NU' FNDEF='01,NA,20,A,DE,NU' FNDEF='01,DP,1,B,FI '
スーパーディスクリプタ定義:
SUPDE='SZ=PN(3,6),DP(1,1)'
スーパーディスクリプタ SZ を作成します。 スーパーディスクリプタの値は、フィールド PN のバイト 3~6(右から左にカウント)、およびフィールド DP のバイト 1 から派生します。 すべての値は 16 進数で示されます。
| PN | DP | SZ |
|---|---|---|
| F0F2F4F6F7F2 | 04 | F0F2F4F604 |
| F8F4F0F3F9F8 | 00 | F8F4F0F300 |
| F0F0F0F0F1F1 | 06 | F0F0F0F006 |
| F0F0F0F0F0F1 | 00 | F0F0F0F000 |
| F0F0F0F0F0F0 | 00 | PN により値は格納されない |
| F0F0F0F0F0F0 | 01 | PN により値は格納されない |
英数字フォーマットで定義された親フィールドから派生したエレメントはないため、SZ のフォーマットはバイナリになります。 最後の 2 つの値については、空値は格納されません。スーパーディスクリプタオプションが NU(PN フィールドから)で、PN フィールド値にアンパック形式のゼロ(X'F0')、つまり空値が格納されているためです。
フィールド定義:
FNDEF='01,PF,4,P,NU' FNDEF='01,PN,2,P,NU'
スーパーディスクリプタ定義:
SUPDE='SP=PF(3,4),PN(1,2)'
スーパーディスクリプタ SP を作成します。 スーパーディスクリプタの値は、フィールド PF のバイト 3~4(右から左にカウント)、およびフィールド PN のバイト 1~2(右から左にカウント)から派生します。 すべての値は 16 進数で示されます。
| PF | PN | SP |
|---|---|---|
| 0002463F | 003F | 0002003F |
| 0000045F | 043F | 0000043F |
| 0032464F | 000F | PN により値は格納されない |
| 0038000F | 044F | 0038044F |
英数字フォーマットで定義された親フィールドから派生したエレメントはないため、SP のフォーマットはバイナリになります。
フィールド定義:
FNDEF='01,AD,PE' FNDEF='02,CI,4,A,NU' FNDEF='02,ST,5,A,NU'
スーパーディスクリプタ定義:
SUPDE='XY=CI(1,4),ST(1,5)'
スーパーディスクリプタ XY をフィールド CI および ST から作成します。 すべての値は文字フォーマットで示されます。
| CI | ST | XY |
|---|---|---|
| (第 1 オカレンス)BALT | (第 1 オカレンス)MAIN | BALTMAIN |
| (第 2 オカレンス)CHI | (第 2 オカレンス)SPRUCE | CHI SPRUC |
| (第 3 オカレンス)WASH | (第 3 オカレンス)11TH | WASH11TH |
| (第 4 オカレンス)DENV | (第 4 オカレンス)bbbbb | ST により値は格納されない |
英数字フォーマットで定義された親フィールドから 1 つ以上のエレメントが派生しているため、XY のフォーマットは英数字になります。
スーパーフィールドは、Adabas 読み込みコマンドで読み込むことができる複数のフィールド、フィールドの一部、またはこれらの組み合わせで構成されるフィールドです。 スーパーフィールドに対して次の処理を行うことはできません。
更新する。
NC オプションで定義されたフィールドで構成する(別の親フィールドが NU オプションで定義されている場合)。
ディスクリプタとして使用する。
ADAINV ユーティリティの機能 INVERT SUPDE=... を使用すると、スーパーフィールドをスーパーディスクリプタに変更できます。
スーパーフィールドは、次の構文を使用して定義します。

ここでは次の内容を表しています。
| name | スーパーフィールド名です。 スーパーフィールドの命名規則は、Adabas の名前の命名規則と同一です。 |
| parent-field | スーパーフィールドエレメントの派生元フィールドの名前です。 |
| begin* | スーパーフィールドエレメントを開始するフィールド内の相対バイト位置です。 |
| end* | スーパーフィールドエレメントを終了するフィールド内の相対バイト位置です。 |
* カウントは、英数字またはワイド文字フォーマットで定義されたフィールドの場合は左から右へと 1 から行われ、数値またはバイナリフォーマットで定義されたフィールドの場合は右から左へと 1 から行われます。
スーパーフィールドの親フィールドは次のように指定できます。
マルチプルバリューフィールド
ピリオディックグループ内
スーパーフィールドの親フィールドは、フォーマット G(浮動小数点)にはできません。
スーパーフィールド値の合計長は、253 バイト(英数字)または 126 バイト(2 進数)を超えない必要があります。
A(英数字)または W(ワイド文字)親フィールドから派生したスーパーフィールドエレメントが存在しない場合、スーパーフィールドのフォーマットは B(2 進数)です。A または W 親フィールドから派生したスーパーフィールドエレメントが存在する場合、スーパーフィールドのフォーマットは、最後の A または W エレメントに合わせられます。例えば、最後の A または W エレメントが W の場合、スーパーフィールドのフォーマットは W になります。
SUPFN='X2=AA(1,2),AB(1,4),AC(1,1)'