このドキュメントでは、Natural を使用して Adabas データベースのデータにアクセスするときのさまざまな面について説明します。
次のトピックについて説明します。
Natural を Adabas と使用するときに適用される Natural プロファイルパラメータの概要を説明する『オペレーション』ドキュメントの「Adabas での Natural」も参照してください。
Natural がデータベースファイルにアクセスできるようにするには、物理データベースファイルの論理定義が必要です。 このような論理ファイル定義は、データ定義モジュール(DDM)と呼ばれます。
このセクションでは、次のトピックについて説明します。
データ定義モジュールには、ファイルの個々のフィールドについての情報が含まれています。この情報は、Natural プログラムでこれらのフィールドを使用するために必要です。 DDM は、物理データベースファイルの論理ビューを構成しています。
データベースの各物理ファイルに、1 つ以上の DDM を定義できます。 各 DDM には、1 つ以上のデータビューを定義できます。ステートメントドキュメントの DEFINE DATA の「ビューの定義」を参照してください。
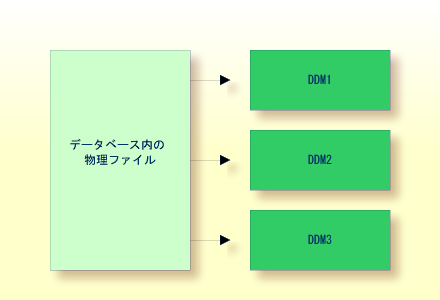
DDM は、Natural 管理者が Predict(Predict を使用できない場合は、対応する Natural 機能)を使用して定義します。
システムコマンド SYSDDM を使用して、SYSDDM ユーティリティを呼び出します。 SYSDDM ユーティリティを使用すると、Natural のデータ定義モジュールの作成および管理に必要なすべての機能を実行できます。
SYSDDM ユーティリティの詳細については、『エディタ』ドキュメントの「SYSDDM ユーティリティ」を参照してください。
各データベースフィールドについて、DDM にはデータベース内部のフィールド名の他に、Natural プログラムで使用されるフィールドの名前である "外部" フィールド名も含まれています。 また、フィールドのフォーマットと長さ、およびフィールドが DISPLAY または WRITE ステートメントで出力されるときに使われる各種の指定(列見出し、編集マスクなど)も DDM に定義されます。
DDM に定義されるフィールド属性については、『エディタ』ドキュメントの「SYSDDM ユーティリティ」セクションの「DDM エディタ画面の使用」を参照してください。
希望する DDM の名前がわからない場合は、システムコマンド LIST DDM を使用して、現在のライブラリで使用できる既存のすべての DDM のリストを取得できます。 このリストから、表示する DDM を選択できます。
名前がわかっている DDM を表示するには、システムコマンド LIST DDM ddm-name を使用します。
例:
LIST DDM EMPLOYEES
DDM に定義されているすべてのフィールドのリストが、各フィールドの情報とともに表示されます。 DDM に定義されるフィールド属性については、『エディタ』ドキュメントの「SYSDDM ユーティリティ」を参照してください。
Adabas は、マルチプルバリューフィールドおよびピリオディックグループの形で、データベース内の配列構造をサポートします。
このセクションでは、次のトピックについて説明します。
マルチプルバリューフィールドは、任意のレコード内に複数の値を持つことができるフィールドです。値の数は 65534 以下ですが、Adabas バージョンおよび FDT の定義に応じて異なります。
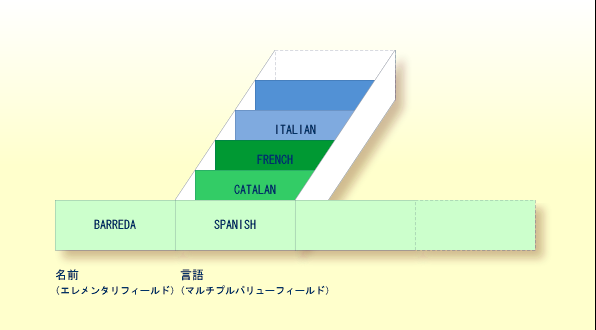
上記の図を EMPLOYEES ファイルのレコードと仮定すると、最初のフィールド(Name)はエレメンタリフィールドであり、1 つの値、つまり従業員の名前のみを含めることができます。これに対して 2 つ目のフィールド(Languages)には、従業員が話す言語が含まれています。従業員は複数の言語を話せる可能性があるので、マルチプルバリューフィールドになっています。
ピリオディックグループは、任意のレコード内で複数のオカレンスを持つことができるエレメンタリフィールドまたはマルチプルバリューフィールドのグループです。オカレンスの数は 65534 以下ですが、Adabas バージョンおよび FDT の定義に応じて異なります。
マルチプルバリューフィールドに含まれる各値は、一般に "オカレンス" と呼ばれます。オカレンスの数は、フィールドに含まれる値の数であり、特定のオカレンスは特定の値を表します。 同様に、ピリオディックグループでは、オカレンスは複数の値の集まりを表します。
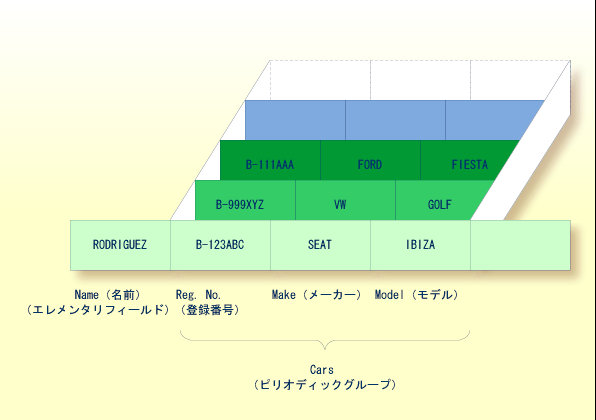
上の図が車両ファイル内のレコードであると仮定すると、最初のフィールド(Name)は人物の名前を含むエレメンタリフィールドです。「Cars」は、その人物が所有する自動車を含むピリオディックグループです。 ピリオディックグループは、各自動車の登録番号、メーカー、およびモデルの 3 つのフィールドで構成されています。 Cars の各オカレンスには 1 台の車に関する値が含まれます。
マルチプルバリューフィールドまたはピリオディックグループの 1 つ以上のオカレンスを参照するには、フィールド名の後に "インデックス表記" を指定します。
次の例では、上述の例のマルチプルバリューフィールド LANGUAGES とピリオディックグループ CARS を使用します。
マルチプルバリューフィールド LANGUAGES の各値は、次のように参照できます。
| 例 | Explanation |
|---|---|
LANGUAGES (1) |
最初の値(SPANISH)を参照します。
|
LANGUAGES (X) |
変数 X の値によって、参照する値が決まります。 |
LANGUAGES (1:3) |
最初の 3 つの値(SPANISH、CATALAN、および FRENCH)を参照します。
|
LANGUAGES (6:10) |
6 番目から 10 番目の値を参照します。 |
LANGUAGES (X:Y) |
変数 X と変数 Y の値によって、参照する値が決まります。
|
ピリオディックグループ CARS のさまざまなオカレンスも同様の方法で参照できます。
| 例 | Explanation |
|---|---|
CARS (1) |
最初のオカレンス(B-123ABC/SEAT/IBIZA)を参照します。
|
CARS (X) |
変数 X の値によって、参照するオカレンスが決まります。
|
CARS (1:2) |
最初の 2 つのオカレンス(B-123ABC/SEAT/IBIZA と B-999XYZ/VW/GOLF)を参照します。
|
CARS (4:7) |
4 番目から 7 番目のオカレンスを参照します。 |
CARS (X:Y) |
変数 X と変数 Y の値によって、参照するオカレンスが決まります。
|
Adabas 配列には、2 次元まで、つまり 1 つのピリオディックグループ内に 1 つのマルチプルバリューフィールドを含めることができます。
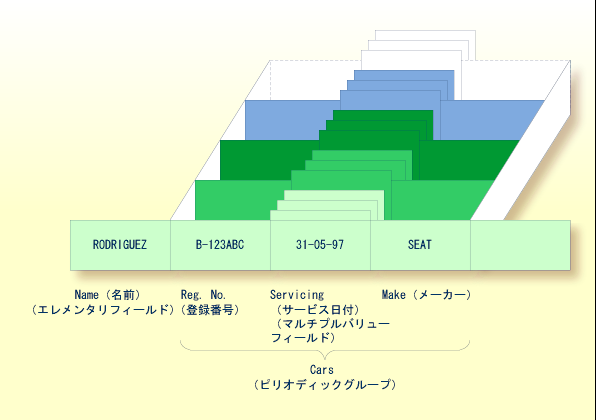
上の図が車両ファイル内のレコードであると仮定すると、最初のフィールド(Name)は人物の名前を含むエレメンタリフィールドです。「Cars」は、その人物が所有する自動車を含むピリオディックグループです。 ピリオディックグループは、各自動車の登録番号、サービス日付、およびメーカーの 3 つのフィールドで構成されています。 ピリオディックグループ Cars 内のフィールド Servicing はマルチプルバリューフィールドであり、各車の異なるサービス日付が含まれています。
ピリオディックグループ内のマルチプルバリューフィールドの 1 つ以上のオカレンスを参照するには、フィールド名の後に "インデックス表記" を指定します。
次の例では、上述の例のピリオディックグループ CARS 内のマルチプルバリューフィールド SERVICING を使用します。 マルチプルバリューフィールドの各値は、次のように参照できます。
| 例 | Explanation |
|---|---|
SERVICING (1,1) |
CARS の最初のオカレンスにある SERVICING の最初の値(31-05-97)を参照します。
|
SERVICING (1:5,1) |
CARS の最初の 5 つのオカレンスにある SERVICING の最初の値を参照します。
|
SERVICING (1:5,1:10) |
CARS の最初の 5 つのオカレンスにある SERVICING の最初の 10 個の値を参照します。
|
レコードに値またはオカレンスがいくつ存在するかが不明なマルチプルバリューフィールドやピリオディックグループの参照が必要になることがあります。 Adabas では、各マルチプルバリューフィールドの値の数、および各ピリオディックグループのオカレンスの数の内部カウントが保持されています。
このカウントは、READ ステートメントでフィールド名の直前に C* を指定することによって読み込むことができます。
カウントは、フォーマット/長さ N3 で返されます。 詳細については、「データベース配列の内部カウントの参照」を参照してください。
| 例 | Explanation |
|---|---|
C*LANGUAGES |
マルチプルバリューフィールド LANGUAGES の値の数を返します。
|
C*CARS |
ピリオディックグループ CARS のオカレンスの数を返します。
|
C*SERVICING (1) |
ピリオディックグループの最初のオカレンスにあるマルチプルバリューフィールド SERVICING の値の数を返します。SERVICING はピリオディックグループ内のマルチプルバリューフィールドであると仮定しています。
|
Natural プログラムでデータベースフィールドを使用できるようにするには、ビューでフィールドを指定する必要があります。
このセクションでは、次のトピックについて説明します。
Natural プログラムでデータベースフィールドを使用できるようにするには、ビューでフィールドを指定する必要があります。
ビューには次の内容を指定します。
フィールドの取得元となるデータ定義モジュール(DDM)の名前。
データベースフィールド自体の名前。つまり、データベース内部のショートネームではなく、ロングネーム。
データベースビューは、次のいずれかの場所に定義します。
プログラムの DEFINE DATA ステートメント内部
プログラム外部のローカルデータエリア(LDA)またはグローバルデータエリア(GDA)。DEFINE DATA ステートメントを使用して、該当するデータエリアを参照します。詳細については、「フィールドの定義」セクションを参照してください。
レベル 1 では、ビュー名を次のように指定します。
1 view-name VIEW OF ddm-name
view-name はビューに選択した名前、ddm-name はビューに指定されたフィールドの取得元となる DDM の名前です。
レベル 2 では、DDM のデータベースフィールドの名前を指定します。
次の図に示すように、ビューの名前は ABC で、DDM XYZ から取得したフィールド NAME、FIRST-NAME、および PERSONNEL-ID で構成されています。
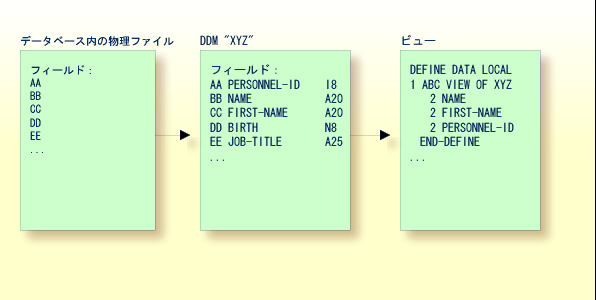
データベースフィールドのフォーマットと長さは、基礎となる DDM ですでに定義されているため、ビューに指定する必要はありません。
ビューは DDM 全体を含めたり、そのサブセットのみを含めたりすることができます。 ビューのフィールドの順番を、基礎となる DDM と同じにする必要はありません。
ビュー名は、アクセスするデータベースを決定するためにデータベースアクセスステートメントで使用されます。「データベースアクセスのステートメント」を参照してください。
データベースからデータを読み込むには、次のステートメントを使用できます。
| ステートメント | 説明 |
|---|---|
READ |
指定した順番でデータベースからレコードの範囲を選択します。 |
FIND |
指定した検索条件に一致するレコードをデータベースから選択します。 |
HISTOGRAM |
1 つのデータベースフィールドの値のみを読み込みます。または、指定した検索条件に一致するレコードの数を決定します。 |
次のトピックについて説明します。
READ ステートメントは、データベースからレコードを読み取るために使用します。 レコードがデータベースから読まれる順番は次のとおりです。
データベースに物理的に保存されている順番(READ IN PHYSICAL SEQUENCE)
Adabas 内部シーケンス番号の順番(READ BY ISN)
ディスクリプタフィールドの値の順番(READ IN LOGICAL SEQUENCE)
このドキュメントでは、READ IN LOGICAL SEQUENCE のみを取り上げます。これは最も頻繁に使用される形の READ ステートメントです。
他の 2 つのオプションの詳細については、『ステートメント』ドキュメントの READ ステートメントの説明を参照してください。
READ ステートメントの基本構文は次のとおりです。
READ view IN LOGICAL SEQUENCE BY descriptor |
または、以下のように短くすることができます。
READ view LOGICAL BY descriptor |
各項目の意味を次に示します。
view |
DEFINE DATA ステートメントで定義されるビューの名前(「DEFINE DATA ビュー」を参照)。
|
descriptor |
そのビューで定義されるデータベースフィールドの名前。 このフィールドの値によって、データベースから読み込まれるレコードの順番が決まります。 |
ディスクリプタを指定する場合は、キーワード LOGICAL を指定する必要はありません。
READ view BY descriptor |
ディスクリプタを指定しない場合は、DDM の デフォルト順 にデフォルトディスクリプタとして定義されたフィールドの値の順番でレコードが読み込まれます。 ただし、ディスクリプタを指定しない場合は、次のようにキーワード LOGICAL を指定する必要があります。
READ view LOGICAL |
** Example 'READX01': READ ************************************************************************ DEFINE DATA LOCAL 1 MYVIEW VIEW OF EMPLOYEES 2 NAME 2 PERSONNEL-ID 2 JOB-TITLE END-DEFINE * READ (6) MYVIEW BY NAME DISPLAY NAME PERSONNEL-ID JOB-TITLE END-READ END
プログラム READX01 の出力:
上記の例の READ ステートメントでは、EMPLOYEES ファイルのレコードが各従業員の姓のアルファベット順に読み込まれます。
プログラムによって次のような出力が作成され、各従業員の情報がそれぞれの姓のアルファベット順に表示されます。
Page 1 04-11-11 14:15:54
NAME PERSONNEL CURRENT
ID POSITION
-------------------- --------- -------------------------
ABELLAN 60008339 MAQUINISTA
ACHIESON 30000231 DATA BASE ADMINISTRATOR
ADAM 50005800 CHEF DE SERVICE
ADKINSON 20008800 PROGRAMMER
ADKINSON 20009800 DBA
ADKINSON 2001100
従業員を生年月日順にリストするレポートを作成するためにレコードを読み込む場合の適切な READ ステートメントは次のようになります。
READ MYVIEW BY BIRTH
指定できるのは、基礎となる DDM で "ディスクリプタ" として定義されているフィールドのみです。サブディスクリプタ、スーパーディスクリプタ、ハイパーディスクリプタ、フォネティックディスクリプタ、またはノンディスクリプタの場合もあります。
上記のプログラム例で示されているように、キーワード READ の後にカッコで囲んだ数字を次のように指定することによって、読み込まれるレコード数を制限できます。
READ (6) MYVIEW BY NAME
上記の例では、READ ステートメントで 6 件を超えるレコードは読み込まれなくなります。
リミット表記がない場合、上記の READ ステートメントによって、EMPLOYEES ファイルのすべてのレコードが姓の順に A から Z まで読み込まれます。
READ ステートメントでは、ディスクリプタフィールドの値に基づいてレコードの選択を限定することもできます。 BY 節または WITH 節で EQUAL TO/STARTING FROM オプションを設定することによって、読み込みを開始する値を指定できます。 THRU/ENDING AT オプションを追加して、読み込みを終了する値を論理順で指定することもできます。
例えば、TRAINEE で開始して Z まで継続する職種の順番で従業員をリストするには、次のいずれかのステートメントを使用します。
READ MYVIEW WITH JOB-TITLE = 'TRAINEE' READ MYVIEW WITH JOB-TITLE STARTING from 'TRAINEE' READ MYVIEW BY JOB-TITLE = 'TRAINEE' READ MYVIEW BY JOB-TITLE STARTING from 'TRAINEE'
等号(=)または STARTING FROM オプションの右側の値はアポストロフィで囲む必要があります。 値が数値の場合は、このテキスト表記は不要です。
BY オプションを使用するときは、WITH オプションを使用できません。この逆も同様です。
読み込む一連のレコードは、THRU 節または ENDING AT 節で終了制限を追加することによって、より厳密に指定できます。
職種が TRAINEE のレコードだけを読み込むには、次のように指定します。
READ MYVIEW BY JOB-TITLE STARTING from 'TRAINEE' THRU 'TRAINEE'
READ MYVIEW WITH JOB-TITLE EQUAL TO 'TRAINEE'
ENDING AT 'TRAINEE'
職種が A または B で始まるレコードだけを読み込むには、次のように指定します。
READ MYVIEW BY JOB-TITLE = 'A' THRU 'C' READ MYVIEW WITH JOB-TITLE STARTING from 'A' ENDING AT 'C'
値は、THRU/ENDING AT の後に指定された値まで、その値を含めて読み込まれます。 上記の 2 つの例では、職種が A または B で始まる全レコードが読み込まれます。職種 C があれば、これも読み込まれますが、次に高い値である CA は読み込まれません。
WHERE 節を使用して、読み込むレコードをさらに限定することができます。
例えば、米国通貨で給与が支払われ、職種が TRAINEE で始まる従業員のみを必要とする場合は、次のように指定します。
READ MYVIEW WITH JOB-TITLE = 'TRAINEE'
WHERE CURR-CODE = 'USD'
WHERE 節は、次のように BY 節とともに使用することもできます。
READ MYVIEW BY NAME
WHERE SALARY = 20000
WHERE 節は、次の 2 つの点で BY/WITH 節と異なります。
WHERE 節に指定するフィールドがディスクリプタである必要はありません。
WHERE オプションに続く式は論理条件です。
WHERE 節では次の論理演算子が有効です。
| EQUAL | EQ | = |
|---|---|---|
| NOT EQUAL TO | NE | ¬= |
| LESS THAN | LT | < |
| LESS THAN OR EQUAL TO | LE | <= |
| GREATER THAN | GT | > |
| GREATER THAN OR EQUAL TO | GE | >= |
次のプログラムは、STARTING FROM、ENDING AT、および WHERE の各節の使い方を説明するものです。
** Example 'READX02': READ (with STARTING, ENDING and WHERE clause)
************************************************************************
DEFINE DATA LOCAL
1 MYVIEW VIEW OF EMPLOYEES
2 NAME
2 JOB-TITLE
2 INCOME (1:2)
3 CURR-CODE
3 SALARY
3 BONUS (1:1)
END-DEFINE
*
READ (3) MYVIEW WITH JOB-TITLE
STARTING FROM 'TRAINEE' ENDING AT 'TRAINEE'
WHERE CURR-CODE (*) = 'USD'
DISPLAY NOTITLE NAME / JOB-TITLE 5X INCOME (1:2)
SKIP 1
END-READ
END
プログラム READX02 の出力:
NAME INCOME
CURRENT
POSITION CURRENCY ANNUAL BONUS
CODE SALARY
------------------------- -------- ---------- ----------
SENKO USD 23000 0
TRAINEE USD 21800 0
BANGART USD 25000 0
TRAINEE USD 23000 0
LINCOLN USD 24000 0
TRAINEE USD 22000 0
次の例のプログラムを参照してください。
次のトピックについて説明します。
FIND ステートメントは、指定した検索条件に一致するレコードをデータベースから選択するために使用します。
FIND ステートメントの基本構文は次のとおりです。
FIND RECORDS IN view WITH field = value |
または、以下のように短くすることができます。
FIND view WITH field = value |
各項目の意味を次に示します。
| view | DEFINE DATA ステートメントで定義されるビューの名前(「DEFINE DATA ビュー」を参照)。
|
|---|---|
| field | そのビューで定義されるデータベースフィールドの名前。 |
field に指定できるのは、基礎となる DDM で "ディスクリプタ" として定義されているフィールドのみです。サブディスクリプタ、スーパーディスクリプタ、ハイパーディスクリプタ、またはフォネティックディスクリプタの場合もあります。
完全な構文については、FIND ステートメントのドキュメントを参照してください。
上述した READ ステートメントの場合と同様に、キーワード FIND の後にカッコで囲んだ数字を指定することによって、処理するレコード数を制限できます。
FIND (6) RECORDS IN MYVIEW WITH NAME = 'CLEGG'
上記の例では、検索条件に一致する最初の 6 つのレコードだけが処理されます。
リミット表記がない場合は、検索条件に一致するすべてのレコードが処理されます。
注意:
FIND ステートメントに WHERE 節(下記参照)が含まれている場合、WHERE 節の結果として拒否されるレコードは制限に対してカウントされません。
FIND ステートメントの WHERE 節を使用すると、WITH 節で選択したレコードが読み込まれた後、このレコードの処理が実行される前に評価される追加の選択条件を指定できます。
** Example 'FINDX01': FIND (with WHERE)
************************************************************************
DEFINE DATA LOCAL
1 MYVIEW VIEW OF EMPLOYEES
2 PERSONNEL-ID
2 NAME
2 JOB-TITLE
2 CITY
END-DEFINE
*
FIND MYVIEW WITH CITY = 'PARIS'
WHERE JOB-TITLE = 'INGENIEUR COMMERCIAL'
DISPLAY NOTITLE CITY JOB-TITLE PERSONNEL-ID NAME
END-FIND
END
注意:
この例では、WITH 節と WHERE 節の両方の条件に一致するレコードだけが DISPLAY ステートメントで処理されます。
プログラム FINDX01 の出力:
CITY CURRENT PERSONNEL NAME
POSITION ID
-------------------- ------------------------- --------- --------------------
PARIS INGENIEUR COMMERCIAL 50007300 CAHN
PARIS INGENIEUR COMMERCIAL 50006500 MAZUY
PARIS INGENIEUR COMMERCIAL 50004700 FAURIE
PARIS INGENIEUR COMMERCIAL 50004400 VALLY
PARIS INGENIEUR COMMERCIAL 50002800 BRETON
PARIS INGENIEUR COMMERCIAL 50001000 GIGLEUX
PARIS INGENIEUR COMMERCIAL 50000400 KORAB-BRZOZOWSKI
WITH 節と WHERE 節に指定した検索条件に一致するレコードが見つからない場合、FIND 処理ループ内のステートメントは実行されません。上記の例では、DISPLAY ステートメントが実行されないため、従業員データは表示されません。
ただし、FIND ステートメントでは IF NO RECORDS FOUND 節も提供されます。これにより、検索条件に一致するレコードがない場合に実行する処理を指定できます。
** Example 'FINDX02': FIND (with IF NO RECORDS FOUND)
************************************************************************
DEFINE DATA LOCAL
1 MYVIEW VIEW OF EMPLOYEES
2 NAME
2 FIRST-NAME
END-DEFINE
*
FIND MYVIEW WITH NAME = 'BLACKSMITH'
IF NO RECORDS FOUND
WRITE 'NO PERSON FOUND.'
END-NOREC
DISPLAY NAME FIRST-NAME
END-FIND
END
上記のプログラムでは、NAME フィールドに BLACKSMITH の値があるすべてのレコードが選択されます。 選択された各レコードについて、姓(NAME)と名前(FIRST-NAME)が表示されます。 NAME = 'BLACKSMITH' のレコードがファイルに見つからない場合は、IF NO RECORDS FOUND 節内の WRITE ステートメントが実行されます。
プログラム FINDX02 の出力:
Page 1 04-11-11 14:15:54
NAME FIRST-NAME
-------------------- --------------------
NO PERSON FOUND.
次の例のプログラムを参照してください。
次のトピックについて説明します。
HISTOGRAM ステートメントは、1 つのデータベースフィールドの値だけを読み込むか、または指定した検索条件に一致するレコード数を決定するために使用します。
HISTOGRAM ステートメントでは、HISTOGRAM ステートメントに指定されたもの以外のデータベースフィールドへのアクセスは提供されません。
HISTOGRAM ステートメントの基本構文は次のとおりです。
HISTOGRAM VALUE IN view FOR field |
または、以下のように短くすることができます。
HISTOGRAM view FOR field |
各項目の意味を次に示します。
| view | DEFINE DATA ステートメントで定義されるビューの名前(「DEFINE DATA ビュー」を参照)。
|
|---|---|
| field | そのビューで定義されるデータベースフィールドの名前。 |
完全な構文については、HISTOGRAM ステートメントのドキュメントを参照してください。
READ ステートメントの場合と同様に、キーワード HISTOGRAM の後にカッコで囲んだ数字を指定することによって、読み込まれるレコード数を制限できます。
HISTOGRAM (6) MYVIEW FOR NAME
上記の例では、フィールド NAME の最初の 6 つの値だけが読み込まれます。
リミット表記がない場合は、すべての値が読み込まれます。
READ ステートメントと同様に、HISTOGRAM ステートメントでも、開始値と終了値を指定して読み込む値の範囲を絞り込むために、STARTING FROM 節と ENDING AT(またはTHRU)節が提供されます。
HISTOGRAM MYVIEW FOR NAME STARTING from 'BOUCHARD' HISTOGRAM MYVIEW FOR NAME STARTING from 'BOUCHARD' ENDING AT 'LANIER' HISTOGRAM MYVIEW FOR NAME from 'BLOOM' THRU 'ROESER'
HISTOGRAM ステートメントでも、値が読み込まれた後、その値の処理が実行される前に評価される追加の選択条件を指定できる WHERE 節が提供されます。 WHERE 節に指定するフィールドは、HISTOGRAM ステートメントの主節のフィールドと同じである必要があります。
** Example 'HISTOX01': HISTOGRAM ************************************************************************ DEFINE DATA LOCAL 1 MYVIEW VIEW OF EMPLOYEES 2 CITY END-DEFINE * LIMIT 8 HISTOGRAM MYVIEW CITY STARTING FROM 'M' DISPLAY NOTITLE CITY 'NUMBER OF/PERSONS' *NUMBER *COUNTER END-HISTOGRAM END
上記のプログラムでは、システム変数 *NUMBER と *COUNTER も HISTOGRAM ステートメントで評価され、DISPLAY ステートメントで出力されます。 *NUMBER には最後に読み込まれた値が含まれるデータベースレコードの数が入り、*COUNTER には読み込まれた値の合計数が入ります。
プログラム HISTOX01 の出力:
CITY NUMBER OF CNT
PERSONS
-------------------- ----------- -----------
MADISON 3 1
MADRID 41 2
MAILLY LE CAMP 1 3
MAMERS 1 4
MANSFIELD 4 5
MARSEILLE 2 6
MATLOCK 1 7
MELBOURNE 2 8
このセクションは、Adabas データベースのマルチフェッチレコード検索機能について説明します。
このセクションで説明するマルチフェッチ機能は、Adabas に対してのみサポートされます。 DB2 データベースのマルチフェッチレコード検索機能の詳細については、『データベース管理システムインターフェイス』ドキュメントの「Natural for DB2」セクションの「複数行の処理」を参照してください。
次のトピックについて説明します。
標準モードの Natural は、単一のデータベースコールでは複数のレコードを読み込みまず、フェッチごとに 1 つのレコードを取得するモードで常に稼働します。 このような稼働は堅実で安定していますが、大量のデータベースレコードの処理には時間がかかる場合があります。
これらのプログラムのパフォーマンスを向上させるために、MULTI-FETCH 節を FIND、READ、または HISTOGRAM の各ステートメントで使用できます。 これにより、データベースアクセス 1 回当たりに読み込まれるレコードの数を指定する数値であるマルチフェッチ要因を定義できます。
|
|
FIND |
|
|
MULTI-FETCH |
|
ON |
|
|
READ |
OFF |
|||||||
HISTOGRAM |
OF multi-fetch-factor |
multi-fetch-factor はフォーマット整数(I4)の定数または変数のいずれかです。
ステートメント実行時には、1 よりも大きい multi-fetch-factor がデータベースステートメントに与えられているかどうかがランタイムによってチェックされます。
multi-fetch-factor の値に応じて、動作は次のようになります。
| 負の値 | ランタイムエラーが発生します。 |
| 0 または 1 | データベースコールは、アクセスごとに 1 つのレコードを取得する通常のモードで継続します。 |
| 2 以上 | データベースコールは、補助バッファへの単一のデータベースアクセスで 10 個など複数のレコードを読み込むためにダイナミックに行われます(マルチフェッチバッファ)。 正常に読み込まれると、最初のレコードが、基礎となるデータビューに転送されます。
次のループの実行時には、データベースにアクセスしなくても、マルチフェッチバッファからデータビューにレコードが直接読み込まれます。 すべてのデータがマルチフェッチバッファからフェッチされた後は、次のループで次のレコードセットのデータベースからの読み込みが行われます。
エンドオブレコード、ESCAPE、STOP などによってデータベースループが終了した場合、マルチフェッチバッファの内容は解放されます。
|
マルチフェッチアクセスはブラウズループ、つまりレコードが "ホールドなし" で読み込まれる場合のためにのみサポートされます。
プログラムは、各ループごとにデータベースから "新しい" レコードを取得するのではなく、最も新しいマルチフェッチアクセスで取得したイメージで動作します。
READ/HISTOGRAM ステートメントに対してループの再位置決めが発生すると、その時点のマルチフェッチバッファの内容が解放されます。
READ/HISTOGRAM ステートメントに対してダイナミックな方向変更(IN DYNAMIC...SEQUENCE)がコーディングされている場合は、マルチフェッチ機能を利用できず、コンパイル時に該当する構文エラーが発生します。
FIND ループの最初のレコードは、最初の S1 コマンドで検索されます。 Adabas のマルチフェッチはあらゆる種類の Lx コマンドに対して定義されているため、2 つ目のレコードから使用することができます。
データベースループに占有されるマルチフェッチバッファの大きさは、次のルールに従って決定されます。
| ((レコードバッファ長 + ISN バッファエントリ長) * マルチフェッチ要因) + 4 + ヘッダー長 |
| = |
| ((ビューフィールドのサイズ + 20) * マルチフェッチ要因) + 4 + 128 |
必要なスペースを小さくするため、次の条件下ではランタイムでマルチフェッチ要因が自動的に減らされます。
READ (2) .. などの "ループ制限" の方が小さい場合。ただし、WHERE 節が含まれない場合のみ。
"ISN 数" の方が小さい場合。FIND ステートメントの場合のみ。
処理後のレコードバッファまたは ISN バッファのサイズが 32KB よりも大きくなる場合。
さらに、次の条件下では、ランタイムにマルチフェッチオプションが完全に無視されます。
マルチフェッチ要因に 1 以下の値が入っている場合。
マルチフェッチバッファが利用不可であるか、または十分なフリースペースがない場合。詳細については、次の「マルチフェッチバッファのサイズ」を参照してください。
マルチフェッチの目的で使用できるストレージの量を制御するために、マルチフェッチバッファの最大サイズを制限することができます。
NATPARM 定義内で、パラメータマクロ NTDS を使用して、スタティックな割り当てを次のように作成できます。
NTDS MULFETCH,nn
セッション開始時には、次のようにプロファイルパラメータ DS を使うこともできます。
DS=(MULFETCH,nn)
nn は、マルチフェッチの目的に割り当てることが可能な全体サイズを KB 単位で表します。 値は 0~1024 の範囲で設定でき、デフォルト値は 64 です。 大きな値を設定しても、必ずしもそのサイズのバッファが割り当てられるわけではありません。これは、マルチフェッチハンドラによって、マルチフェッチデータベースステートメントの実行に何が実際に必要であるかに応じて、ダイナミックアロケーションとサイズ変更が行われるためです。
Natural セッションでマルチフェッチデータベースステートメントが一度も実行されない場合は、設定された値にかかわらずマルチフェッチバッファは作成されません。
値 0 を指定した場合は、データベースアクセスステートメントに MULTI-FETCH OF .. 節が含まれているかどうかにかかわらず、マルチフェッチ処理は完全に無効になります。 この操作を行うことで、使用可能なストレージを現在の環境で十分に確保できない場合、またはデバッグの目的で、すべてのマルチフェッチアクティビティを完全にオフにすることができます。
注意:
Adabas の既存の制限により、レコードバッファ または ISN バッファを 32 KB よりも大きくすることはできません。 したがって、FIND、READ、または HISTOGRAM の単一ループでマルチフェッチバッファに必要なスペースは、最大でも 64 KB になります。 マルチフェッチバッファに必要な値の設定は、マルチフェッチで処理するデータベースループのネスト数に応じて異なります。
マルチフェッチ関連データベースコールの TEST DBLOG によるサポートの詳細については、『ユーティリティ』ドキュメントの「DBLOG ユーティリティ」、「マルチフェッチを使用する Adabas コマンドの表示」を参照してください。
このセクションでは、FIND、READ、または HISTOGRAM の各ステートメントの結果としてデータベースから選択されたデータの処理に必要な処理ループについて説明します。
次のトピックについて説明します。
Natural では、FIND、READ、または HISTOGRAM ステートメントの結果としてデータベースから選択されたデータの処理に必要な処理ループが自動的に作成されます。
次の例では、FIND ループを使用して、NAME フィールドに ADKINSON という値が含まれるすべてのレコードを EMPLOYEES ファイルから選択し、選択したレコードを処理します。 この例では、選択された各レコードの特定のフィールドを表示する処理が含まれます。
** Example 'FINDX03': FIND ************************************************************************ DEFINE DATA LOCAL 1 MYVIEW VIEW OF EMPLOYEES 2 NAME 2 FIRST-NAME 2 CITY END-DEFINE * FIND MYVIEW WITH NAME = 'ADKINSON' DISPLAY NAME FIRST-NAME CITY END-FIND END
WITH 節に加えて、FIND ステートメントに WHERE 節が含まれる場合は、WITH 節の結果として選択されたレコードのうち、さらに、WHERE 条件に一致するものだけが処理されます。
次の図は、データベース処理ループのフローロジックを示しています。
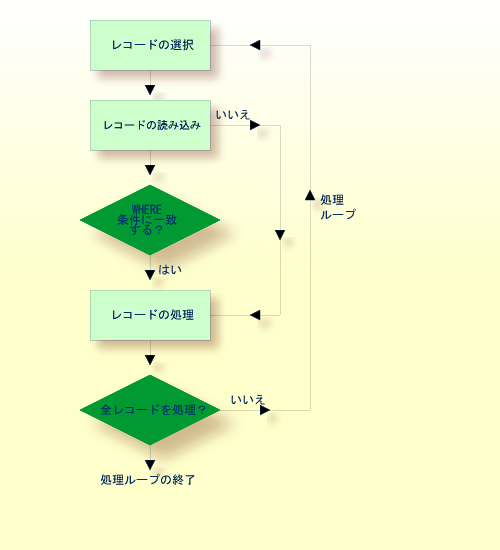
FIND および(または)READ ステートメントを複数使用することによって、次の例に示すように、処理ループの階層が作成されます。
** Example 'FINDX04': FIND (two FIND statements nested)
************************************************************************
DEFINE DATA LOCAL
1 PERSONVIEW VIEW OF EMPLOYEES
2 PERSONNEL-ID
2 NAME
1 AUTOVIEW VIEW OF VEHICLES
2 PERSONNEL-ID
2 MAKE
2 MODEL
END-DEFINE
*
EMP. FIND PERSONVIEW WITH NAME = 'ADKINSON'
VEH. FIND AUTOVIEW WITH PERSONNEL-ID = PERSONNEL-ID (EMP.)
DISPLAY NAME MAKE MODEL
END-FIND
END-FIND
END
上記のプログラムでは、ADKINSON という名前のすべての従業員が EMPLOYEES ファイルから選択されます。 選択された各レコード(従業員)は、その後、次のように処理されます。
VEHICLES ファイルから車を選択するために、1 つ目の FIND ステートメントで EMPLOYEES ファイルから選択されたレコードの PERSONNEL-ID を選択条件に使用して、2 つ目の FIND ステートメントが実行されます。
選択された各従業員の NAME が表示されます。この情報は EMPLOYEES ファイルから取得されます。 その従業員が所有する各車の MAKE と MODEL も表示されます。この情報は VEHICLES ファイルから取得されます。
2 つ目の FIND ステートメントでは、次の図に示すように、1 つ目の FIND ステートメントの外部処理ループ内に内部処理ループが作成されます。
この図は、上述のプログラム例における処理ループの階層のフローロジックを示しています。
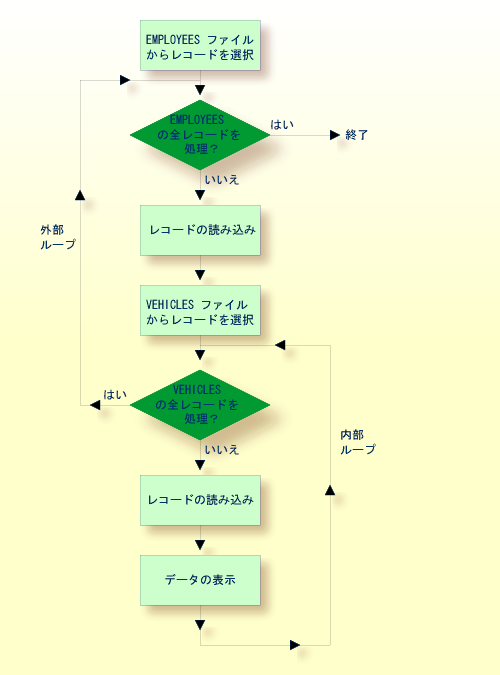
階層の両方のレベルで同じファイルが使用される処理ループの階層を構成することもできます。
** Example 'FINDX05': FIND (two FIND statements on same file nested)
************************************************************************
DEFINE DATA LOCAL
1 PERSONVIEW VIEW OF EMPLOYEES
2 NAME
2 FIRST-NAME
2 CITY
1 #NAME (A40)
END-DEFINE
*
WRITE TITLE LEFT JUSTIFIED
'PEOPLE IN SAME CITY AS:' #NAME / 'CITY:' CITY SKIP 1
*
FIND PERSONVIEW WITH NAME = 'JONES'
WHERE FIRST-NAME = 'LAUREL'
COMPRESS NAME FIRST-NAME INTO #NAME
/*
FIND PERSONVIEW WITH CITY = CITY
DISPLAY NAME FIRST-NAME CITY
END-FIND
END-FIND
END
上記のプログラムでは、まず姓が JONES で名前が LAUREL の従業員が EMPLOYEES ファイルからすべて選択されます。 次に、同じ都市に住んでいるすべての従業員が EMPLOYEES ファイルから選択され、そのリストが作成されます。 DISPLAY ステートメントで表示されるすべてのフィールド値は、2 つ目の FIND ステートメントから取得されます。
プログラム FINDX05 の出力:
PEOPLE IN SAME CITY AS: JONES LAUREL
CITY: BALTIMORE
NAME FIRST-NAME CITY
-------------------- -------------------- --------------------
JENSON MARTHA BALTIMORE
LAWLER EDDIE BALTIMORE
FORREST CLARA BALTIMORE
ALEXANDER GIL BALTIMORE
NEEDHAM SUNNY BALTIMORE
ZINN CARLOS BALTIMORE
JONES LAUREL BALTIMORE
次の例のプログラムを参照してください。
このセクションでは、トランザクションに基づいて Natural でデータベース更新処理が実行される方法について説明します。
次のトピックについて説明します。
Natural では、トランザクションに基づいてデータベース更新処理が実行されます。つまり、すべてのデータベース更新要求は論理トランザクション単位で処理されます。 論理トランザクションは、データベースに含まれている情報が論理的に一貫性を持っていることを確実にするために、完全に実行されなければならない最小の作業単位です。作業単位の定義はユーザーが行います。
論理トランザクションは、1 つ以上のデータベースファイルに関連する 1 つ以上の更新ステートメント(DELETE、STORE、UPDATE)で構成することができます。 また、論理トランザクションは、複数の Natural プログラムにまたがることもできます。
論理トランザクションは、レコードが "ホールド" 状態におかれたときに開始します。Natural では、レコードが更新のために読み込まれるとき、例えば、FIND ループに UPDATE ステートメントや DELETE ステートメントが含まれる場合に、この処理が自動的に行われます。
論理トランザクションの終了は、プログラムの END TRANSACTION ステートメントによって決まります。 このステートメントは、トランザクション内のすべての更新が正常に適用されたことを保証し、トランザクション中に "ホールド" 状態におかれていたすべてのレコードを解放します。
DEFINE DATA LOCAL 1 MYVIEW VIEW OF EMPLOYEES 2 NAME END-DEFINE FIND MYVIEW WITH NAME = 'SMITH' DELETE END TRANSACTION END-FIND END
選択された各レコードは "ホールド" 状態に置かれ、削除され、その後は END TRANSACTION ステートメントが実行されるときに "ホールド" 状態から解放されます。
注意:
Natural 管理者が設定する Natural プロファイルパラメータ ETEOP は、各 Natural プログラムの終了時に Natural で END TRANSACTION ステートメントを生成するかどうかを決定します。 詳細については、Natural 管理者に確認してください。
次のプログラム例では、EMPLOYEES ファイルに新しいレコードを追加します。
** Example 'STOREX01': STORE (Add new records to EMPLOYEES file)
*
** CAUTION: Executing this example will modify the database records!
************************************************************************
DEFINE DATA LOCAL
1 EMPLOYEE-VIEW VIEW OF EMPLOYEES
2 PERSONNEL-ID(A8)
2 NAME (A20)
2 FIRST-NAME (A20)
2 MIDDLE-I (A1)
2 SALARY (P9/2)
2 MAR-STAT (A1)
2 BIRTH (D)
2 CITY (A20)
2 COUNTRY (A3)
*
1 #PERSONNEL-ID (A8)
1 #NAME (A20)
1 #FIRST-NAME (A20)
1 #INITIAL (A1)
1 #MAR-STAT (A1)
1 #SALARY (N9)
1 #BIRTH (A8)
1 #CITY (A20)
1 #COUNTRY (A3)
1 #CONF (A1) INIT <'Y'>
END-DEFINE
*
REPEAT
INPUT 'ENTER A PERSONNEL ID AND NAME (OR ''END'' TO END)' //
'PERSONNEL-ID : ' #PERSONNEL-ID //
'NAME : ' #NAME /
'FIRST-NAME : ' #FIRST-NAME
/*********************************************************************
/* validate entered data
/*********************************************************************
IF #PERSONNEL-ID = 'END' OR #NAME = 'END'
STOP
END-IF
IF #NAME = ' '
REINPUT WITH TEXT 'ENTER A LAST-NAME'
MARK 2 AND SOUND ALARM
END-IF
IF #FIRST-NAME = ' '
REINPUT WITH TEXT 'ENTER A FIRST-NAME'
MARK 3 AND SOUND ALARM
END-IF
/*********************************************************************
/* ensure person is not already on file
/*********************************************************************
FIP2. FIND NUMBER EMPLOYEE-VIEW WITH PERSONNEL-ID = #PERSONNEL-ID
/*
IF *NUMBER (FIP2.) > 0
REINPUT 'PERSON WITH SAME PERSONNEL-ID ALREADY EXISTS'
MARK 1 AND SOUND ALARM
END-IF
/*********************************************************************
/* get further information
/*********************************************************************
INPUT
'ENTER EMPLOYEE DATA' ////
'PERSONNEL-ID :' #PERSONNEL-ID (AD=IO) /
'NAME :' #NAME (AD=IO) /
'FIRST-NAME :' #FIRST-NAME (AD=IO) ///
'INITIAL :' #INITIAL /
'ANNUAL SALARY :' #SALARY /
'MARITAL STATUS :' #MAR-STAT /
'DATE OF BIRTH (YYYYMMDD) :' #BIRTH /
'CITY :' #CITY /
'COUNTRY (3 CHARS) :' #COUNTRY //
'ADD THIS RECORD (Y/N) :' #CONF (AD=M)
/*********************************************************************
/* ENSURE REQUIRED FIELDS CONTAIN VALID DATA
/*********************************************************************
IF #SALARY < 10000
REINPUT TEXT 'ENTER A PROPER ANNUAL SALARY' MARK 2
END-IF
IF NOT (#MAR-STAT = 'S' OR = 'M' OR = 'D' OR = 'W')
REINPUT TEXT 'ENTER VALID MARITAL STATUS S=SINGLE ' -
'M=MARRIED D=DIVORCED W=WIDOWED' MARK 3
END-IF
IF NOT(#BIRTH = MASK(YYYYMMDD) AND #BIRTH = MASK(1582-2699))
REINPUT TEXT 'ENTER CORRECT DATE' MARK 4
END-IF
IF #CITY = ' '
REINPUT TEXT 'ENTER A CITY NAME' MARK 5
END-IF
IF #COUNTRY = ' '
REINPUT TEXT 'ENTER A COUNTRY CODE' MARK 6
END-IF
IF NOT (#CONF = 'N' OR= 'Y')
REINPUT TEXT 'ENTER Y (YES) OR N (NO)' MARK 7
END-IF
IF #CONF = 'N'
ESCAPE TOP
END-IF
/*********************************************************************
/* add the record with STORE
/*********************************************************************
MOVE #PERSONNEL-ID TO EMPLOYEE-VIEW.PERSONNEL-ID
MOVE #NAME TO EMPLOYEE-VIEW.NAME
MOVE #FIRST-NAME TO EMPLOYEE-VIEW.FIRST-NAME
MOVE #INITIAL TO EMPLOYEE-VIEW.MIDDLE-I
MOVE #SALARY TO EMPLOYEE-VIEW.SALARY (1)
MOVE #MAR-STAT TO EMPLOYEE-VIEW.MAR-STAT
MOVE EDITED #BIRTH TO EMPLOYEE-VIEW.BIRTH (EM=YYYYMMDD)
MOVE #CITY TO EMPLOYEE-VIEW.CITY
MOVE #COUNTRY TO EMPLOYEE-VIEW.COUNTRY
/*
STP3. STORE RECORD IN FILE EMPLOYEE-VIEW
/*
/*********************************************************************
/* mark end of logical transaction
/*********************************************************************
END OF TRANSACTION
RESET INITIAL #CONF
END-REPEAT
END
プログラム STOREX01 の出力:
ENTER A PERSONNEL ID AND NAME (OR 'END' TO END) PERSONNEL ID : NAME : FIRST NAME :
Natural を Adabas で使用する場合、更新するレコードは、END TRANSACTION または BACKOUT TRANSACTION ステートメントが発行されるまで、あるいはトランザクションタイムリミットを超えるまで、"ホールド" 状態におかれます。
1 人のユーザーに対してレコードが "ホールド" 状態におかれると、他のユーザーはそのレコードを更新できません。 同じレコードを更新しようとする他のユーザーは、最初のユーザーがそのトランザクションを終了またはバックアウトしてレコードが "ホールド" から解放されるまで "待ち" 状態におかれます。
ユーザーが待ち状態におかれることを防ぐために、セッションパラメータ WH(ホールドレコードの待機)を使用できます。『パラメータリファレンス』を参照してください。
プログラムで更新ロジックを使用するときには、以下の点を考慮する必要があります。
レコードをホールド状態における最大時間は、Adabas のトランザクションタイムリミット(Adabas パラメータ TT)によって決まります。 このタイムリミットを超えると、エラーメッセージが表示され、最後の END TRANSACTION 以降に行われたすべてのデータベース更新が取り消されます。
ホールドされるレコード件数およびトランザクションタイムリミットは、トランザクションのサイズ、つまり、プログラムにおける END TRANSACTION ステートメントの配置に影響されます。 どこで END TRANSACTION を発行するかを決めるときには、再スタート機能を考慮する必要があります。 例えば、処理中のレコードの大多数が更新されない場合は、レコードの "ホールド" 状態の制御には GET ステートメントが効率的です。 これにより、複数の END TRANSACTION ステートメントの発行が回避され、ホールドされる ISN の数が少なくなります。 大きなファイルを処理するときは、GET ステートメントでは追加の Adabas コールが必要となることに注意してください。 GET ステートメントの例を次に示します。
レコードを "ホールド" 状態に置く処理は、Natural 管理者が設定するプロファイルパラメータ RI(リリース ISN)によって制御されます。
** Example 'GETX01': GET (put single record in hold with UPDATE stmt)
**
** CAUTION: Executing this example will modify the database records!
***********************************************************************
DEFINE DATA LOCAL
1 EMPLOY-VIEW VIEW OF EMPLOYEES
2 NAME
2 SALARY (1)
END-DEFINE
*
RD. READ EMPLOY-VIEW BY NAME
DISPLAY EMPLOY-VIEW
IF SALARY (1) > 1500000
/*
GE. GET EMPLOY-VIEW *ISN (RD.)
/*
WRITE '=' (50) 'RECORD IN HOLD:' *ISN(RD.)
COMPUTE SALARY (1) = SALARY (1) * 1.15
UPDATE (GE.)
END TRANSACTION
END-IF
END-READ
END
アクティブな論理トランザクション中、つまり、END TRANSACTION ステートメントが発行される前に、BACKOUT TRANSACTION ステートメントを使用してトランザクションをキャンセルすることができます。 このステートメントを実行すると、これまでに適用されたすべての更新(追加または削除されたすべてのレコードを含む)が削除され、トランザクションによってホールドされていたすべてのレコードが解放されます。
END TRANSACTION ステートメントを使用して、トランザクション関連情報を保存することもできます。 トランザクション処理が異常終了する場合は、GET TRANSACTION DATA ステートメントでこの情報を読み取り、トランザクションを再スタートするときにどこで処理を再開するかを確認できます。
次のプログラムは、EMPLOYEES ファイルと VEHICLES ファイルを更新します。 再スタート処理の後で、正常に処理された最後の EMPLOYEES レコードがユーザーに通知されます。 ユーザーは、その EMPLOYEES レコードから処理を再開できます。 再スタート処理の前に正常に更新された最後の VEHICLES レコードを、トランザクションの再スタートメッセージに含めるように設定することもできます。
** Example 'GETTRX01': GET TRANSACTION
*
** CAUTION: Executing this example will modify the database records!
************************************************************************
DEFINE DATA LOCAL
01 PERSON VIEW OF EMPLOYEES
02 PERSONNEL-ID (A8)
02 NAME (A20)
02 FIRST-NAME (A20)
02 MIDDLE-I (A1)
02 CITY (A20)
01 AUTO VIEW OF VEHICLES
02 PERSONNEL-ID (A8)
02 MAKE (A20)
02 MODEL (A20)
*
01 ET-DATA
02 #APPL-ID (A8) INIT <' '>
02 #USER-ID (A8)
02 #PROGRAM (A8)
02 #DATE (A10)
02 #TIME (A8)
02 #PERSONNEL-NUMBER (A8)
END-DEFINE
*
GET TRANSACTION DATA #APPL-ID #USER-ID #PROGRAM
#DATE #TIME #PERSONNEL-NUMBER
*
IF #APPL-ID NOT = 'NORMAL' /* if last execution ended abnormally
AND #APPL-ID NOT = ' '
INPUT (AD=OIL)
// 20T '*** LAST SUCCESSFUL TRANSACTION ***' (I)
/ 20T '***********************************'
/// 25T 'APPLICATION:' #APPL-ID
/ 32T 'USER:' #USER-ID
/ 29T 'PROGRAM:' #PROGRAM
/ 24T 'COMPLETED ON:' #DATE 'AT' #TIME
/ 20T 'PERSONNEL NUMBER:' #PERSONNEL-NUMBER
END-IF
*
REPEAT
/*
INPUT (AD=MIL) // 20T 'ENTER PERSONNEL NUMBER:' #PERSONNEL-NUMBER
/*
IF #PERSONNEL-NUMBER = '99999999'
ESCAPE BOTTOM
END-IF
/*
FIND1. FIND PERSON WITH PERSONNEL-ID = #PERSONNEL-NUMBER
IF NO RECORDS FOUND
REINPUT 'SPECIFIED NUMBER DOES NOT EXIST; ENTER ANOTHER ONE.'
END-NOREC
FIND2. FIND AUTO WITH PERSONNEL-ID = #PERSONNEL-NUMBER
IF NO RECORDS FOUND
WRITE 'PERSON DOES NOT OWN ANY CARS'
ESCAPE BOTTOM
END-NOREC
IF *COUNTER (FIND2.) = 1 /* first pass through the loop
INPUT (AD=M)
/ 20T 'EMPLOYEES/AUTOMOBILE DETAILS' (I)
/ 20T '----------------------------'
/// 20T 'NUMBER:' PERSONNEL-ID (AD=O)
/ 22T 'NAME:' NAME ' ' FIRST-NAME ' ' MIDDLE-I
/ 22T 'CITY:' CITY
/ 22T 'MAKE:' MAKE
/ 21T 'MODEL:' MODEL
UPDATE (FIND1.) /* update the EMPLOYEES file
ELSE /* subsequent passes through the loop
INPUT NO ERASE (AD=M IP=OFF) //////// 28T MAKE / 28T MODEL
END-IF
/*
UPDATE (FIND2.) /* update the VEHICLES file
/*
MOVE *APPLIC-ID TO #APPL-ID
MOVE *INIT-USER TO #USER-ID
MOVE *PROGRAM TO #PROGRAM
MOVE *DAT4E TO #DATE
MOVE *TIME TO #TIME
/*
END TRANSACTION #APPL-ID #USER-ID #PROGRAM
#DATE #TIME #PERSONNEL-NUMBER
/*
END-FIND /* for VEHICLES (FIND2.)
END-FIND /* for EMPLOYEES (FIND1.)
END-REPEAT /* for REPEAT
*
STOP /* Simulate abnormal transaction end
END TRANSACTION 'NORMAL '
END
このセクションでは、ユーザー指定の論理条件に基づいてレコードを選択するために使用する ACCEPT ステートメントおよび REJECT ステートメントについて説明します。
次のトピックについて説明します。
ACCEPT ステートメントおよび REJECT ステートメントは、次のデータベースアクセスステートメントと連携して使用できます。
** Example 'ACCEPX01': ACCEPT IF ************************************************************************ DEFINE DATA LOCAL 1 MYVIEW VIEW OF EMPLOYEES 2 NAME 2 JOB-TITLE 2 CURR-CODE (1:1) 2 SALARY (1:1) END-DEFINE * READ (20) MYVIEW BY NAME WHERE CURR-CODE (1) = 'USD' ACCEPT IF SALARY (1) >= 40000 DISPLAY NAME JOB-TITLE SALARY (1) END-READ END
プログラム ACCEPX01 の出力:
Page 1 04-11-11 11:11:11
NAME CURRENT ANNUAL
POSITION SALARY
-------------------- ------------------------- ----------
ADKINSON DBA 46700
ADKINSON MANAGER 47000
ADKINSON MANAGER 47000
AFANASSIEV DBA 42800
ALEXANDER DIRECTOR 48000
ANDERSON MANAGER 50000
ATHERTON ANALYST 43000
ATHERTON MANAGER 40000
ACCEPT ステートメントおよび REJECT ステートメントを使用すると、READ ステートメントの WITH 節および WHERE 節で指定した論理条件に加えて、論理条件を指定できます。
ACCEPT/REJECT ステートメントの IF 節の論理条件基準は、レコードが選択されて読み込まれた後で評価されます。
論理条件演算子には次のものがあります。詳細については、「論理条件基準」を参照してください。
EQUAL |
EQ |
:= |
NOT EQUAL TO |
NE |
¬= |
LESS THAN |
LT |
< |
LESS EQUAL |
LE |
<= |
GREATER THAN |
GT |
> |
GREATER EQUAL |
GE |
>= |
ACCEPT/REJECT ステートメントの論理条件基準は、ブール演算子 AND、OR、および NOT で結合することもできます。 さらに、論理グループを示すためにカッコを使用することもできます。次の例を参照してください。
次のプログラムは、ACCEPT ステートメントでのブール演算子 AND の使用を示しています。
** Example 'ACCEPX02': ACCEPT IF ... AND ...
************************************************************************
DEFINE DATA LOCAL
1 MYVIEW VIEW OF EMPLOYEES
2 NAME
2 JOB-TITLE
2 CURR-CODE (1:1)
2 SALARY (1:1)
END-DEFINE
*
READ (20) MYVIEW BY NAME WHERE CURR-CODE (1) = 'USD'
ACCEPT IF SALARY (1) >= 40000
AND SALARY (1) <= 45000
DISPLAY NAME JOB-TITLE SALARY (1)
END-READ
END
プログラム ACCEPX02 の出力:
Page 1 04-12-14 12:22:01
NAME CURRENT ANNUAL
POSITION SALARY
-------------------- ------------------------- ----------
AFANASSIEV DBA 42800
ATHERTON ANALYST 43000
ATHERTON MANAGER 40000
次のプログラムは、REJECT ステートメントでブール演算子 OR を使用したものです。論理演算子が逆になっているため、前の例の ACCEPT ステートメントと同じ出力が生成されます。
** Example 'ACCEPX03': REJECT IF ... OR ...
************************************************************************
DEFINE DATA LOCAL
1 MYVIEW VIEW OF EMPLOYEES
2 NAME
2 JOB-TITLE
2 CURR-CODE (1:1)
2 SALARY (1:1)
END-DEFINE
*
READ (20) MYVIEW BY NAME WHERE CURR-CODE (1) = 'USD'
REJECT IF SALARY (1) < 40000
OR SALARY (1) > 45000
DISPLAY NAME JOB-TITLE SALARY (1)
END-READ
END
プログラム ACCEPX03 の出力:
Page 1 04-12-14 12:26:27
NAME CURRENT ANNUAL
POSITION SALARY
-------------------- ------------------------- ----------
AFANASSIEV DBA 42800
ATHERTON ANALYST 43000
ATHERTON MANAGER 40000
次の例のプログラムを参照してください。
このセクションでは、AT START OF DATA ステートメントおよび AT END OF DATA ステートメントの使用について説明します。
次のトピックについて説明します。
AT START OF DATA ステートメントは、データベース処理ループで一連のレコードの最初のレコードが読み込まれた後に実行する処理を指定するために使用します。
AT START OF DATA ステートメントは、処理ループ内に指定する必要があります。
AT START OF DATA 処理で出力が生成される場合は、最初のフィールド値の前に出力されます。 デフォルトでは、この出力は左揃えでページに表示されます。
AT END OF DATA ステートメントは、データベース処理ループのすべてのレコードが処理された後に実行する処理を指定するために使用します。
AT END OF DATA ステートメントは、処理ループ内に指定する必要があります。
AT END OF DATA 処理で出力が生成される場合は、最後のフィールド値の後に出力されます。 デフォルトでは、この出力は左揃えでページに表示されます。
次のプログラム例は、AT START OF DATA ステートメントおよび AT END OF DATA ステートメントの使用を示しています。
時刻を表示するために、Natural のシステム変数 *TIME が AT START OF DATA ステートメントに組み込まれています。
最後に選択された従業員の名前を表示するために、Natural のシステム関数 OLD が AT END OF DATA ステートメントに組み込まれています。
** Example 'ATSTAX01': AT START OF DATA
************************************************************************
DEFINE DATA LOCAL
1 MYVIEW VIEW OF EMPLOYEES
2 CITY
2 NAME
2 JOB-TITLE
2 INCOME (1:1)
3 CURR-CODE
3 SALARY
3 BONUS (1:1)
END-DEFINE
*
WRITE TITLE 'XYZ EMPLOYEE ANNUAL SALARY AND BONUS REPORT' /
READ (3) MYVIEW BY CITY STARTING FROM 'E'
DISPLAY GIVE SYSTEM FUNCTIONS
NAME (AL=15) JOB-TITLE (AL=15) INCOME (1)
/*
AT START OF DATA
WRITE 'RUN TIME:' *TIME /
END-START
AT END OF DATA
WRITE / 'LAST PERSON SELECTED:' OLD (NAME) /
END-ENDDATA
END-READ
*
AT END OF PAGE
WRITE / 'AVERAGE SALARY:' AVER (SALARY(1))
END-ENDPAGE
END
プログラムが次の出力を生成します。
XYZ EMPLOYEE ANNUAL SALARY AND BONUS REPORT
NAME CURRENT INCOME
POSITION
CURRENCY ANNUAL BONUS
CODE SALARY
--------------- --------------- -------- ---------- ----------
RUN TIME: 12:43:19.1
DUYVERMAN PROGRAMMER USD 34000 0
PRATT SALES PERSON USD 38000 9000
MARKUSH TRAINEE USD 22000 0
LAST PERSON SELECTED: MARKUSH
AVERAGE SALARY: 31333
次の例のプログラムを参照してください。
Natural を使用すると、Adabas データベースのワイド文字フィールド(フォーマット W)にアクセスできます。
次のトピックについて説明します。
Adabas のワイド文字フィールド(W)は、Natural フォーマット U(Unicode)にマッピングされます。
フォーマット U の Natural フィールドの長さの定義は、フォーマット W の Adabas フィールドのサイズの半分に一致します。 例えば、長さ 200 の Adabas のワイド文字フィールドは、Natural の (U100) にマッピングされます。
Natural は Adabas からデータを受け取り、共通のエンコードとして UTF-16 を使用してデータを Adabas に送ります。
このエンコードは OPRB パラメータで指定され、オープン要求で Adabas に送られます。 これはワイド文字フィールドに使用され、Adabas ユーザーセッション全体を通して適用されます。
照合ディスクリプタはサポートされていません。
Adabas および Unicode のサポートの詳細については、該当する Adabas 製品のドキュメントを参照してください。