このドキュメントでは、次のトピックについて説明します。
Unicode アプリケーションの開発環境は、Natural Single Point of Development(SPoD)です。
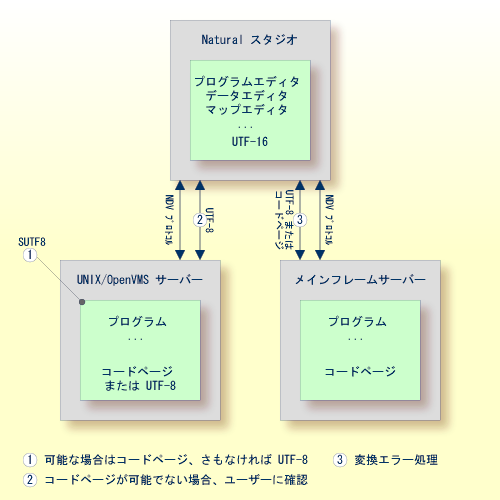
SPoD 環境では、Natural 開発サーバー(NDV)上の Unicode アプリケーションの Natural オブジェクトは、Natural スタジオを使用して変更できます。 サーバーによってサポートされている場合、ソースはクライアントとサーバー間で UTF-8 フォーマットで交換されます。
UNIX および OpenVMS 用の NDV サーバーでは、プロファイルパラメータ SUTF8 の設定によって、Natural オブジェクトをサーバーに保存するときに使用されるフォーマットが決まります。 これは、ローカルの Windows の場合と同様に処理されます。
メインフレーム用の NDV サーバーでは、プロファイルパラメータ SRETAIN の設定に応じて、デフォルトまたは元のエンコードでオブジェクトが保存されます。
Windows、UNIX、および OpenVMS プラットフォームでは、Natural コードを変更する前に、環境に対して正しいデフォルトコードページを定義することが重要です。 詳細については、「既存アプリケーションの移行」を参照してください。
異なる言語の文字をソースに保存する場合、Windows、UNIX、または OpenVMS プラットフォームで UTF-8 フォーマットでソースを保存するか、ソースで 16 進 UH 定数を使用する必要があります。 プロファイルパラメータ SUTF8 および SRETAIN を使用して、どのフォーマットでソースを保存するかを制御できます。 次の表に、いくつかの状況と推奨設定を示します。
注意:
UNIX および OpenVMS では、パラメータ SUTF8 は SPoD 環境でのみ使用できます。
| 状況 | 設定 | 効果 |
|---|---|---|
| ソースは Windows 上にあります。U 定数が必要です。 | SUTF8=ON, SRETAIN=OFF |
Natural 6.2 以降で保存する場合、すべてのソースは UTF-8 フォーマットで保存されます。 新しいソースは UTF-8 フォーマットで作成されます。 すべての文字を 1 つのソースに保存できます。 |
| ソースは Windows、UNIX、または OpenVMS 上にあります。U 定数が必要であり、SPoD が開発に使用されます。 | SUTF8=ON, SRETAIN=ON |
元のコードページへの変換が不可能になった場合、すべてのソースは UTF-8 フォーマットで保存されます。可能な場合には、ソースのコードページは変更されません。 新しいソースは UTF-8 フォーマットで作成されます。 すべての文字を 1 つのソースに保存できます。 UTF-8 フォーマットのソースは、SPoD でのみ変更できます。Natural for UNIX または Natural for OpenVMS エディタでは処理できなくなります。 |
| ソースは Windows、UNIX、または OpenVMS 上にあります。U 定数は必要ありません。 | SUTF8=OFF, SRETAIN=ON |
すべてのソースは元のコードページで保存されます。 新しいソースは、サーバーのデフォルトコードページで保存されます。 1 つのソースに保存できるのは、ソースコードページからの文字のみです。 ソースは、引き続き Natural for UNIX または Natural for OpenVMS エディタで処理できます。 |
| ソースは Windows、UNIX、OpenVMS、またはメインフレーム上にあります。U 定数が必要であり、SPoD が開発に使用されます。 | SUTF8=OFF, SRETAIN=ON |
すべてのソースは元のコードページで保存されます。 新しいソースは、サーバーのデフォルトコードページで保存されます。 1 つのソースに保存できるのは、ソースコードページからの文字のみです。 ソースは、引き続き Natural for UNIX、Natural for OpenVMS、および Natural for Mainframes エディタで処理できます。 すべての Unicode 定数は、16 進定数(UH)として定義される必要があります。 |
パラメータ SUTF8 が "OFF" に設定されており、異なる文字セットの文字を含むが、まだ UTF-8 フォーマットで保存されていないソースを格納する場合、生成プログラムは作成されるが、ソースは保存不可能であり、そのためにソースは変更されないままである場合があります。 これは、異なる文字セットの文字がコメントまたは
U 定数で使用される場合に発生します。 このため、異なる文字セットの文字を含むソースを作成する場合、およびソースをメインフレームプラットフォームに分散する必要がない場合は、パラメータ SUTF8 を "ON" に設定することをお勧めします。
パラメータ SRETAIN が "OFF" に設定されている場合、すべてのソースはデフォルトコードページで保存されます。 この設定には注意が必要です。以前の Natural バージョンで作成されたソースがある場合、この設定によってコードページ情報が不適切になる可能性があるためです。 この場合、ソースのエンコード情報は割り当てられておらず、ソースは常にデフォルトコードページ(システム変数
*CODEPAGE の値)で開かれます。 デフォルトコードページがソースの正しいエンコードではない場合でも、このように機能することがあります。 この場合、言語固有の一部の文字は正しく表示されません。 そのようなソースが間違ったコードページで開かれ、SRETAIN が "ON" に設定された状態で保存された場合、ソースに対してエンコードは保存されません。ソースは、Natural が正しいデフォルトコードページで開始された場合に、後で正しく開くことができます。 ただし、SRETAIN が "OFF" に設定された状態でソースを保存すると、デフォルトコードページがソースのエンコードとして保存されます。その後、ソースはこのコードページでのみ開かれます。 このため、この設定は、すべての Natural ソースがデフォルトコードページでエンコードされていることが確かな場合にのみ使用する必要があります。
『コンフィグレーションユーティリティ』ドキュメントの「地域の設定」も参照してください。
Natural for Windows エディタは、Unicode に完全に対応しています。 SPoD 経由で、メインフレーム、UNIX、および OpenVMS ソースに対しても使用できます。 Natural for Mainframes、Natural for UNIX、および Natural for OpenVMS で提供されるエディタは、Unicode 対応ではありません。
注意:
Natural for Mainframes で提供されるエディタでは、コードページのサポートが提供されます。 「メインフレームでのエディタ、システムコマンド、およびユーティリティのコードページのサポート」を参照してください。
Natural スタジオ(Natural for Windows)のエディタを使用してソースが開かれるとき、ソースの内容は、対応するコードページから Unicode に変換されてから、エディタにロードされます。 このことによって、システムコードページに含まれない文字がソースに含まれている場合でも、すべての文字を正しく表示できることが保証されます。 ソースのコードページから Unicode への変換が失敗した場合は、エラーが表示され、エディタは開かれません。 この場合、ユーザーはソースの正しいエンコードを定義する必要があります。 ソースのエンコードは、[プロパティ]ダイアログボックスで変更できます(『Natural スタジオの使用』ドキュメントの「ノードのプロパティ」を参照)。
Windows、UNIX、および OpenVMS ソースの場合、Natural for Windows エディタによって、異なる言語の文字を含むソースを UTF-8 フォーマットで保存できます。 メインフレームでは、UTF-8 ソースを保存できません。
注意:
UNIX または OpenVMS ソースを UTF-8 フォーマットで、またはデフォルトコードページとは異なるコードページを使用して保存した場合、ソースは Natural for UNIX または Natural for OpenVMS のネイティブエディタで開くことができなくなります。
メインフレームソースは、異なるコードページを使用して保存し、Natural for Mainframes のネイティブエディタで編集できます。
プログラムおよびソース内で Unicode 文字列を使用しない場合でも、Unicode 対応エディタには、インストールされているシステムコードページに関係なく、すべてのコードページのソースを記述できるという利点があります。 例えば、"windows-1252"(Latin 1)コードページをインストールしている場合に、キリル語文字を含むプログラムを記述し、このプログラムを "windows-1251"(キリル語)コードページで保存できます。 [名前をつけて保存]ダイアログボックスで、コードページ "windows-1251" を選択するだけです(『Natural スタジオの使用』ドキュメントの「新しい名前でのオブジェクトの保存」を参照)。
Natural for Windows プログラムエディタを使用して、テキスト定数を 16 進 Unicode 表現に変換できます(Natural for Windows『エディタ』ドキュメントの「プログラムエディタ」セクションの「16 進形式への変換」を参照)。 したがって、UTF-8 ソースが望ましくないプラットフォーム用に開発している場合、Unicode 定数のすべての文字を入力し、定数のすべての文字を選択し、それらを 16 進表示に変換して、Unicode 16 進定数の "UH" 接頭辞を追加できます。 さらに、テキスト定数の文字または選択された文字範囲の上にマウスポインタを置くと、対応する 16 進 Unicode 表現がツールヒントに表示されます。
バイトオーダマーク(BOM)は、データ文字列の先頭の文字コード "U+FEFF" で構成されます。その場所で、主にマークがないプレーンテキストファイルの、バイト順およびエンコード形式を定義する署名として使用できます。 Windows では、バイトオーダマークは一部のエディタ(メモ帳など)によって、UTF-8 ファイルをマークするために使用されます。 Natural for Windows エディタでは、UTF-8 バイトオーダマークはオブジェクトを読み込むときに認識されます。 それまでにオブジェクトに他のエンコードが定義されていない場合は、Natural によって UTF-8 と解釈され、オブジェクトが保存されるときに、UTF-8 がそのオブジェクトのエンコードとして保存されます。 この場合、バイトオーダマークは削除されます。
以下では次のトピックについて説明します。
Natural for Mainframes で提供されるプログラム、マップ、およびデータエリアエディタは、Unicode 対応ではありません。 代わりに、ソースはコードページ情報とともに保存されます。 プロファイルパラメータ SRETAIN の設定に従って、Natural ソースがエディタにロードされる場合に、コードページ情報を持つソースが、ソースの現在のコードページから現在の Natural セッションのデフォルトコードページ(システム変数 *CODEPAGE の値)に自動的に変換される場合があります。 変換できない文字がある場合は、コードポイント変換エラーがウィンドウに表示され、変換できないそれらのコードポイントの代替値が要求されます。 このメッセージの表示は、パラメータ CPCVERR の現在の設定とは関係ありません。 この場合、ユーザーは、ソースをデフォルトコードページに変換してエディタを開くか、または変換しないでエディタを開くことを決定できます。 変換されたソースを保存または格納すると、新しいコードページ情報が保存されます。
コードページ情報を持たないソース(以前の Natural バージョンで保存または STOW されたソースなど)は、変換されずにエディタにロードされます。 プロファイルパラメータ SRETAIN の設定に従って、ソースの現在のコードページ情報が保存されます。
.I コマンドまたは画面分割を使用してソースを挿入した場合にも、プロファイルパラメータ SRETAIN の設定に従って、必要に応じてソースは変換されます。 文字が変換できない場合は、代わりに定義済みの置換文字が挿入されます。
ソースのチェックおよび変換は、プログラムがソースエリアにロードされるときではなく、エディタが開始されるときに実行されます。 プログラムが RUN program-name によって実行される場合、変換は実行されません。 RUN program-name が NEXT 画面で入力されたかエディタ画面で入力されたかに応じて、動作は異なります。 RUN program-name が NEXT 画面で入力された場合は、その後に変換は実行されません。エディタ画面で入力された場合は、プログラムの実行直後にエディタが開始され、変換が実行されます。
保存または STOW された既存の Natural ソースに割り当てられるコードページは、プロファイルパラメータ SRETAIN および CP の値に応じて異なります。以下の表を参照してください。
| 元のソースコードページ情報 | SRETAIN の設定
|
CP が "OFF" 以外の値に設定されている場合の、SAVE または STOW 実行後のソースコードページ情報
|
CP が "OFF" 値に設定されている場合の、SAVE または STOW 実行後のソースコードページ情報
|
|---|---|---|---|
| コードページ情報を含まないソース | SRETAIN=ON SRETAIN=(ON,EXCEPTNEW) |
コードページ情報なし | コードページ情報なし |
| コードページ情報を含まないソース | SRETAIN=OFF |
CP の評価の結果のコードページ
|
コードページ情報なし |
| ソースが code page 1 でエンコードされている | SRETAIN=ON SRETAIN=(ON,EXCEPTNEW) |
元のコードページ(code page 1) | 元のコードページ(code page 1) |
| ソースが code page 1 でエンコードされている | SRETAIN=OFF |
CP の評価の結果のコードページ
|
元のコードページ(code page 1) |
保存または STOW された新規の Natural ソースに割り当てられるコードページは、プロファイルパラメータ SRETAIN および CP の値に応じて異なります。これを以下の表に示します。
SRETAIN の設定
|
CP が "OFF" 以外の値に設定されている場合の、SAVE または STOW 実行後のソースコードページ情報
|
CP が "OFF" 値に設定されている場合の、SAVE または STOW 実行後のソースコードページ情報
|
|---|---|---|
SRETAIN=ON |
CP の評価の結果のコードページ
|
コードページ情報なし |
SRETAIN=OFF |
CP の評価の結果のコードページ
|
コードページ情報なし |
SRETAIN=(ON,EXCEPTNEW) |
コードページ情報なし | コードページ情報なし |
デフォルトでは、システムコマンド LIST によって、ソースがシステムファイル内に変換されずに保存された状態で表示されます。
LIST コマンドの CONVERTED オプションを使用すると、ソースのコードページ情報がある場合、ソースがデフォルトコードページ(システム変数 *CODEPAGE の値)に変換されます。 変換不可能なすべての文字は、定義済みの置換文字によって置き換えられます。
システムコマンド LIST DIR によって、Natural ソースの使用されているコードページ情報がディレクトリウィンドウに示されます。
エディタと同様に、システムコマンド SCAN では、ソースが変換されてから実際の SCAN コマンドが実行されます。
オブジェクトハンドラによって、さまざまなコードページ情報を持つソースがアンロードおよびロードされ、元のコードページ情報が保持されます。
転送フォーマットオプション UTF-8 によって、ソースはアンロード時にコードページから UTF-8 フォーマットに変換され、元のコードページの情報はワークファイルに保存されます。 対応するロード機能によって、ソースは元のコードページに戻されるか、指定した場合、別のコードページに変換されます。 また、このオプションを使用すると、以前の Natural バージョンで保存または STOW されたためにコードページ情報を持たないソースに、コードページ情報を与えることもできます。
内部フォーマットのソースのアンロードおよびロードでは、コードページ情報がある場合は保持されます。
SYSCP ユーティリティを使用して、コードページに関する情報を取得し、ソースのコードページ割り当てをチェックまたは変更できます。