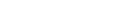
このドキュメントでは ADACMP ユーティリティについて説明します。
次のトピックについて説明します。
圧縮ユーティリティ ADACMP は、ユーザーの未加工データを一括更新ユーティリティ ADAMUP が使用できる形式に圧縮するものです。
このユーティリティに対する入力データは、シーケンシャルファイルでなければいけません。LOB フィールドの値は別のファイルでも指定できます。
入力データの論理構造と特性は、フィールド定義テーブル(FDT)によって記述されます。これらのステートメントは、レベル番号、フィールド名、標準長および形式を、その他フィールドに割り当てられるすべての定義オプション(ディスクリプタ、ユニークディスクリプタ、マルチプルバリューフィールド、空値省略、固定ストレージ、ピリオディックグループ)とともに指定します。データベースのファイルのレイアウトおよび入力データの属性については、『管理マニュアル』の「FDT のレコード構造」を参照してください。
オプション SY(システム生成)が指定されていない入力レコードの各フィールドが圧縮されます。圧縮は、英数字フィールドの後方の空白および数値フィールドの上位桁のゼロを除去します。アンパック形式およびパック形式のフィールドは正しいデータかチェックされます。固定ストレージオプションで定義されたフィールドは圧縮されません。ユーザー出口が提供されているので、ユーザー作成ルーチンを使用して各入力レコードの追加編集ができます。
システム生成フィールドは、ADACMP パラメータ SYFINPUT に指定されたキーワードに応じて、再生成または圧縮解除されます。
このユーティリティは、次の 3 タイプの出力ファイルを作成します。
圧縮データ
ディスクリプタ値
エラーのあるレコード
すべてのディスクリプタ値の大きさは、実行の最後にリストされます。
エラーファイルにレコードが書き込まれると、ユーティリティはゼロ以外のステータスで終了します。
注意:
ICU 3.2 照合ディスクリプタを含むファイルにデータを追加する場合は、注意してください。
FDT をパラメータ DBID および FILE とともに指定すると、FDT はデータベースから変更されずに取得されます。これは、ICU バージョンが 3.2 のままであることを意味します。データをファイルに追加できますが、ICU のバージョンは 3.2 のままになります。
CMPFDT ファイルから FDT を取得すると、CMPFDT ファイルから新しい FDT が作成され、ICU バージョンが 5.4 に設定されます。これは、データが空の場合、および NEW_FDT オプションを指定した場合にのみ、データをファイルに追加できることを意味します。使用される ICU のバージョンは 5.4 です。
このユーティリティは単一機能ユーティリティです。
シーケンシャルファイル CMPDTA、CMPDVT および CMPERR は複数のエクステントを持つことができます。エクステントが複数あるシーケンシャルファイルの詳細については、『Adabas Basics』の「ユーティリティの使用」に記載されている「Adabas シーケンシャルファイル」の「Adabas シーケンシャルファイルの複数エクステント」を参照してください。CMPLOB はディレクトリであり、データベースに LOB 値として保存されている可能性があるファイルが含まれています。
| データセット | 環境 変数/ 論理名 |
記憶 媒体 |
追加情報 |
|---|---|---|---|
| アソシエータ | ASSOx | ディスク | |
| 圧縮データ | CMPDTA | ディスク、テープ(* 注参照) | ADACMP の出力 |
| ディスクリプタバリューテーブル | CMPDVT | ディスク、テープ(* 注参照) | ADACMP の出力 |
| 拒否データ | CMPERR | ディスク、テープ(* 注参照) | ADACMP の出力 |
| 入力データ FDT | CMPFDT | ディスク、テープ(* 注参照) | ユーティリティマニュアル |
| ユーザー入力データ | CMPIN | ディスク(* 注参照) | ユーティリティマニュアル |
| ユーザー LOB 入力データ | CMPLOB | ディスク | ユーティリティマニュアル |
| ADACMP コントロール ステートメント |
stdin/ SYS$INPUT |
ユーティリティマニュアル | |
| ADACMP メッセージ | stdout/ SYS$OUTPUT |
メッセージおよびコード |
注意:
(*)名前付きパイプをこのシーケンシャルファイルに使用できます(詳細については、『管理マニュアル』の「ユーティリティの使用」に記載されている「Adabas シーケンシャルファイル」、「名前付きパイプの使用」を参照)。
SINGLE_FILE オプションを設定した場合、ディスクリプタバリューテーブル(DVT)と圧縮ユーザーデータはともに論理名 CMPDTA に書き込まれます。
このユーティリティはチェックポイントを書き込みません。
次のコントロールパラメータを使用できます。
DBID = number
D [NO]DST
FDT
FIELDS {uncompressed_field_definition | FDT}...[END_OF_FIELDS | . ]
FILE = number
D [NO]LOBS
D [NO]LOWER_CASE_FIELD_NAME
D MAX_DECOMPRESSED_SIZE = number [K|M]
D MUPE_C_L = {1|2|4}
D [NO]NULL_VALUE
D NUMREC = number
D RECORD_STRUCTURE = keyword
SEPARATOR = character | \character
D [NO]SHORT_RECORDS
D [NO]SINGLE_FILE
SKIPREC = number
D SOURCE_ARCHITECTURE = (keyword[,keyword][,keyword])
D SYFINPUT = keyword
D TZ {=|:} [timezone]
D [NO]USEREXIT
D [NO]USERISN
D WCHARSET = char_set
DBID = number
このパラメータは、FILE パラメータによって指定されるファイルが存在するデータベースを選択するものです。
[NO]DST
DST パラメータは、オプション TZ を使用して日付/時刻フィールドに夏時間インジケータが提供されている場合に必要です。夏時間インジケータは、2 バイトの整数値(フォーマット F)として日付/時刻値の後に追加する必要があります。実際の時間(通常は 0 または 3600)を取得するために、この値には、標準時間に追加する秒数が含まれます。
DST パラメータが指定されていない場合、時刻が標準時刻に戻るまで、時間の時刻値を定義できません。
デフォルトは NODST です。
注意:
DT フィールドには次の定義があります:1,DT,8,P,DT=E(DATE_TIME),TZ
このフィールドには、次の値を指定する必要があります。
編集マスク DATE_TIME に対応する 8 バイトパック値としてのローカル日付/時刻値
夏時間インジケータ。通常は、2 バイトの固定小数点値として標準時間は 0、夏時間は 3600
Case 1 (DT has a date/time value with daylight saving time): 0x0200910250230000E10 Case 2 (DT has a date/time value with standard time): 0x0200910250230000000
FDT
このパラメータが最初のパラメータとして指定されている場合、または [NO]LOWER_CASE_FIELD_NAMES の後に 2 番目のパラメータとして指定されている場合、ADACMP はシーケンシャルファイル CMPFDT に含まれている FDT 情報を読み取り、FDT を表示します。
注意:
または、FDT の代わりに DBID と FILE を使用して、最初のパラメータとして指定することも、[NO]LOWER_CASE_FIELD_NAMES(これは DBID と FILE の前に許可されます)の後に 2 番目のパラメータとして指定することもできます。この場合、ファイルの
FDT が圧縮のベースとして使用されます。
FDT パラメータは複数回指定できますが、FDT または DBID と FILE パラメータを指定して、圧縮に FDT を使用するようにすでに決定している場合は、FDT パラメータを再度指定すると、FDT のみが表示され、FDT は CMPFDT で上書きされません。
FIELDS {uncompressed_field_definition | FDT}...[END_OF_FIELDS | . ]
このパラメータは、FDT のフィールドのサブセットおよび、それらのフォーマットと長さを指定するために使用します。FDT で指定されているすべてのフィールドが入力レコードに含まれている必要はありません。つまり、別のフォーマットか長さでフィールドを指定できるということです。構文と使用方法はフォーマットバッファの場合とほぼ同じです。ただし、非圧縮レコードに LOB 値自体ではなく、LOB 値を含むファイルの名前が含まれている場合に、(LOB 参照の)R 要素も指定できる点だけが異なります。詳細については、『管理マニュアル』の「データのロードとアンロード」の「非圧縮データフォーマット」を参照してください。
指定リストの入力時に、圧縮解除するファイルの FDT を表示する FDT 機能を使用できます。指定リストは END_OF_FIELDS または「.」を入力することで終了または中断できます。「.」オプションは暗黙の END_OF_FIELDS であり、フォーマットバッファ構文と互換性があります。FIELDS または END_OF_FIELDS は常にそれ自体を行に入力する必要がありますが、「.」はそれ自体を行に入力することも、フォーマットバッファ要素の末尾に入力することも可能です。
END_OF_FIELDS パラメータを使用してフィールド定義を消去する場合、LOWER_CASE_FIELD_NAMES パラメータを使用するときに、このパラメータを大文字で指定する必要があります。また、LOWER_CASE_FIELD_NAMES を使用する場合は、FDT パラメータも大文字で指定する必要があります。
FILE = number
このパラメータは、FDT 情報が読み取られるファイルを指定するものです。このパラメータは、DBID パラメータの後にしか指定できません。
[NO]LOWER_CASE_FIELD_NAMES
LOWER_CASE_FIELD_NAMES が指定されている場合、Adabas フィールド名は、大文字に変換されません。NOLOWER_CASE_FIELD_NAMES が指定されている場合、Adabas フィールド名は、大文字に変換されます。デフォルトは、NOLOWER_CASE_FIELD_NAMES です。
FDT の小文字フィールド名を大文字に変換しない場合は、FDT パラメータの前に、最初のパラメータとしてこのパラメータを指定する必要があります。FIELDS パラメータの小文字フィールド名を大文字に変換しない場合は、FIELDS パラメータの前に、このパラメータを指定する必要があります。
| 注意: CMPFDT ファイルに対して LOWER_CASE_FIELD_NAMES パラメータが指定されている場合、ファイル全体に対する大文字変換は行われません。フィールドフォーマットやフィールドオプションの小文字は、FDT 構文エラーの原因となります。この問題は、FIELDS パラメータの小文字でも発生します。 |
[NO]LOBS
このパラメータでは、圧縮データをデータベースにロードした後で、LA フィールドと LB フィールドの値を LOB ファイルに保存するかどうかを指定します。
パラメータ DBID とファイル番号を指定した場合、このパラメータは無視され、フィールドは次の説明のように処理されます。
パラメータ DBID とファイル番号を指定せず、LOBS を指定した場合、LA フィールドと LB フィールドのフィールド値は、フィールドがディスクリプタとして定義されていなければ、LOB ファイルでの保存用に準備されます。
パラメータ DBID とファイル番号を指定せず、NOLOBS を指定した場合、LA フィールドと LB フィールドのフィールド値は基本ファイルでの保存用に準備されます。この場合、LA フィールドと LB フィールドのフィールド値の長さは 16381 バイト以内にして、圧縮レコードが 32 KB DATA ブロックに収まる大きさにする必要があります。
ディスクリプタであるか、派生ディスクリプタ(スーパーディスクリプタなど)の親フィールドである LA フィールドと LB フィールドは、NOLOBS パラメータで説明したように常に処理されます。
デフォルトの動作は次のとおりです。
パラメータ DBID とファイル番号を指定し、ファイルが対応 LOB ファイルを含む基本ファイルである場合は、LOBS がデフォルトとなります。
パラメータ DBID とファイル番号を指定し、ファイルが対応 LOB ファイルを含む基本ファイルでない場合は、NOLOBS がデフォルトとなります。
パラメータ DBID とファイル番号を指定しない場合は、LOBS がデフォルトとなります。
MAX_DECOMPRESSED_SIZE = number [K|M]
このパラメータは、数字の後の「K」または「M」の仕様に応じて、非圧縮レコードの最大サイズをバイト、キロバイトまたはメガバイト単位で指定します。このパラメータは、無効な CMPIN ファイルを可能な限り早く認識するためのものです。
デフォルトは、65536 です。これは、最大値でもあります。
注意:
MUPE_C_L = {1|2|4}
非圧縮データにマルチプルバリューフィールドまたはピリオディックグループが含まれる場合、それらには MUPE_C_L バイトの長さのバイナリのカウントフィールドが先行します。
デフォルトは 1 です。
[NO]NULL_VALUE
標準 FDT に従って圧縮するとき、入力データに NC オプションフィールドのステータス値が与えられる場合、パラメータ NULL_VALUE が必須になります。通常、このような入力データは NULL_VALUE オプションを設定した ADADCU によって生成されます。
デフォルトは NONULL_VALUE です。
フィールド AA の FDT 内での定義:1, AA, 2, A, NC
ケース 1(AA が NULL 値を持っていない場合):入力レコード(16 進) = 00004142
ケース 2(AA が NULL 値を持っている場合):入力レコード(16 進) = FFFF2020
NUMREC = number
このパラメータは、処理される入力レコード数を指定するものです。このパラメータが省略された場合は、入力ファイルに含まれているすべての入力レコードが処理されます。
このパラメータの使用は、入力データファイルに大量レコードがある場合、ADACMP の初期実行時の使用に適しています。一度 ADACMP を実行しておくと、データ定義エラーや不当な入力データによって大量のエラーレコードが発生する場合に、すべてのレコードに対する不要な処理を避けることができます。
また、このパラメータは、テスト用に小さいファイルを作成する場合にも役立ちます。
RECORD_STRUCTURE = keyword
このパラメータは、環境変数 CMPIN に指定した入力ファイルに使用されるレコード区切りのタイプを指定するものです。次のキーワードを使用できます。
| キーワード | 説明 |
|---|---|
| ELENGTH_PREFIX | CMPIN ファイルのレコードは、2 バイトの長さフィールド(フィールド長にはフィールド自体の長さは含まれない)によって区切られます。 |
| E4LENGTH_PREFIX | 非圧縮データファイル内のレコードは、4 バイトの長さフィールド(長さフィールド自体の長さを除く)で区切られます。 |
| ILENGTH_PREFIX | CMPIN ファイルのレコードは、2 バイトの長さフィールド(フィールド長にはフィールド自体の長さも含まれる)によって区切られます。 |
| I4LENGTH_PREFIX | 非圧縮データファイル内のレコードは、4 バイトの長さフィールド(長さフィールド自体の長さを含む)で区切られます。 |
| NEWLINE_SEPARATOR | CMPIN ファイルのレコードは改行文字で区切られています。このキーワードは、改行として解釈される文字がフィールド値に含まれない場合(アンパック形式のフィールド、英数字フィールド、Unicode フィールドのみが含まれる場合、および英数字フィールドと Unicode フィールドに出力可能文字のみが含まれる場合)に限って指定できます。このキーワードおよび USERISN パラメータは相互に排他的です。 |
| RDW | CMPIN ファイルのレコードは、FTP site rdw オプションを使って IBM ホストから転送されたデータを含んでいます。ADACMP は cvt_fmt をはじめに使用しなくても、そのようなデータを処理することができます(以前のバージョンではそのようなデータの変換に、cvt_fmt という非サポートのツールを使っていました)。次にその例を示します。% ftp IBM-host ftp> binary 200 Representation type is Image ftp> site rdw 200 Site command was accepted ftp> get decomp % setenv CMPIN decomp % adacmp fdt record_structure=rdw source=(ebcdic,high) |
| RDW_HEADER | RDW と同じように、HEADER=YES を指定して、メインフレームで圧縮解除したデータの場合。 |
| HEADER | HEADER=YES を指定してメインフレームで圧縮解除されたデータ(圧縮解除されたデータにブロックまたはレコード長に関する追加情報が含まれていない場合)。 |
| VARIABLE_BLOCKED | BS2000 または IBM の可変ブロック形式。 |
デフォルトは ELENGTH_PREFIX です。
SEPARATOR = character | \character
このオプションを指定すると、未加工データレコードのフィールドは、指定した文字で区切られているものとして扱われます。Adabas ユーティリティにとって特別な意味を持たせる必要がなければ、文字をアポストロフィで囲む必要はありません。この場合には、それぞれのレコードの同一フィールドを別々の長さにすることができます。
FIELDS パラメータを使用して、フォーマットバッファを指定する場合、指定するフィールド名の順番は、フィールドが FDT に指定された順番と一致させなければなりません。異なった場合、不一致が生じます。
FDT にマルチプルバリューフィールド、またはピリオディックグループが含まれている場合、フォーマットバッファを FIELDS パラメータで指定する必要があります。ピリオディックグループのメンバは、ピリオディックグループインデックスと、FDT のフィールドの並び順に従って順序付ける必要があります(下の例 2 を参照)。
SEPARATOR オプションを使用している入力ファイルにはバイナリデータは予期されないので、RECORD_STRUCTURE パラメータは NEWLINE_SEPARATOR に設定されます。
FDT: 1, AA, 2, U
1, AB, 8, U
1, AC, 2, A
CMPIN: 12;12345678;AA
1234;5;BB
adacmp
fdt
separator=\;
or for UNIX
adacmp fdt separator=\\\;
or
adacmp fdt separator='\;'
上記の例では、2 レコードがデフォルトの FDT で圧縮されます。区切り文字はコロン(;)で、デフォルトのレコード構造は NEWLINE_SEPARATOR です。コロンはバックスラッシュで先行されていることに注意してください。そうでなければ、コメントの開始とみなされます。UNIX 環境において、直接コマンド行からパラメータを入力する場合、バックスラッシュとコロンの前に追加のバックスラッシュを付加するか、それらを引用符または二重引用符で囲む必要があります。そうしないと、特殊文字として扱われます。
FDT: 1, XX, PE
2, AA, 8, A
2, AB, 8, U
1, YY, 2, A
Correct: CMPIN: aaaa,1,bbbb,2,yy
Command: adacmp fdt separator=, fields AA1,AB1,AA2,AB2,YY.
First, the field values for the periodic group index 1 are
specified, and then the field values for periodic group index 2.
Invalid: CMPIN: aaaa,bbbb,1,2,yy
Command: adacmp fdt separator=, fields AA1-2,AB1-2,YY.
The fields specification is invalid because the 2nd value of
AA is specified before the 1st value of AB; you will get
the error SEPINV.
上記の例では、フォーマットバッファに指定されたフィールドを持つ 1 レコードが圧縮されます。区切り文字はコンマ(,)です。
FDT: 1, AA, 8, A
1, MA, 1, A, MU
CMPIN: aaaa%2%A%B
bbbb%3%C%D%E
adacmp dbid=9 file=15 separator=%, fields "AA,MAC,1,U,MA1-N"
上記の例では、フォーマットバッファに指定されたフィールドを持つ 2 レコードが圧縮されます。オカレンスカウントまたはマルチプルバリューフィールド MA はそれぞれのレコードで異なります。区切り文字はパーセント(%)です。
[NO]SHORT_RECORDS
SHORT_RECORDS を指定すると、空値を含んでいる非圧縮レコードの末尾のフィールドを省略することが可能です。
デフォルトは NOSHORT_RECORDS です。
フィールド全体を省略することだけが可能です。末尾の値を切り捨てることはできません。
英数字フィールド AA と AB を含んでいるファイルにパラメータを指定したと仮定します。
FIELDS AA,20,AB,20 END_OF_FIELDS SHORT_RECORDS
そのとき、次のレコードは認められます。
"Field AA "
次のレコードは認められません。
"Field AA"
[NO]SINGLE_FILE
SINGLE_FILE オプションを設定すると、ADACMP は、ディスクリプタバリューテーブル(DVT)と圧縮データを別々のファイルではなく、1 つのファイル(CMPDTA)にまとめて書き込みます。
デフォルトは NOSINGLE_FILE です。
SKIPREC = number
このパラメータは、圧縮を始める前にスキップされるレコード数を指定するものです。
SOURCE_ARCHITECTURE = ( keyword [,keyword [,keyword] ] )
このパラメータは、入力データレコードの形式(文字セット、浮動小数点フォーマット、およびバイト順)を指定するものです。次のキーワードを使用できます。
| キーワードグループ | 有効なキーワード |
|---|---|
| 文字セット |
ASCII EBCDIC |
| 浮動小数点フォーマット |
IBM_370_FLOATING IEEE_FLOATING VAX_FLOATING |
| バイト順 |
HIGH_ORDER_BYTE_FIRST LOW_ORDER_BYTE_FIRST |
キーワードグループのキーワードを指定しない場合、このキーワードグループのデフォルトは、ADACMP を実行しているマシンのアーキテクチャに対応するキーワードになります。
注意:
FDT は常に ASCII フォーマットの入力です。
圧縮される入力レコードが IBM 形式の場合は、ユーザーは次のように指定する必要があります。
SOURCE_ARCHITECTURE = (EBCDIC, IBM_370_FLOATING, HIGH_ORDER_BYTE_FIRST)
SYFINPUT = keyword
このパラメータは、システム生成フィールドの圧縮に使用する入力を指定します。次のキーワードを使用できます。
| キーワード | 説明 |
|---|---|
| SYSTEM | システム生成フィールド値は、ADACMP でシステムによって再生成されます。 |
| USER | システム生成フィールド値は、圧縮解除されたファイルから取得されます。 |
デフォルトは SYFINPUT = USER です。
TZ {=|:} [timezone]
指定されたタイムゾーンは、Olson データベース(https://www.iana.org/time-zones)として知られているタイムゾーンデータベースに含まれている有効なタイムゾーン名にする必要があります。タイムゾーンが指定されている場合、このタイムゾーンは、オプション TZ を含む日付/時刻フィールドのタイムゾーン変換に使用されます。
デフォルトは、UTC です。これは、オプション TZ を含む日付/時刻フィールドに内部的に保存するために使用されます。変換する必要はありません。
空の値を指定する場合、日付/時刻フィールドが正しいことを確認するチェックマークは付いていません。
注意:
タイムゾーン名はファイル名になります。プラットフォームに応じて、これらのファイル名は大文字小文字を区別する場合としない場合があります。また、タイムゾーン名も、プラットフォームに応じて大文字/小文字を区別する場合としない場合があります。
tz:Europe/Berlin
これは、すべてのプラットフォームに適用されます。
TZ=Europe/Berlin
この仕様により、TZ は大文字の EUROPE/BERLIN に変換されます。これは、Windows では、ファイル名の大文字/小文字が区別されないため適用されます。ただし、Unix では、Unix ファイル名の大文字/小文字は区別されるため適用されません。
[NO]USEREXIT
このオプションは、ユーザー出口が使用されるかどうかを指定します。USEREXIT を指定した場合、環境変数 ADAUEX_6/論理名 ADABAS$USEREXIT_6 は、ロード可能なユーザー作成ルーチンをポイントする必要があります。
詳細については、『管理マニュアル』の「ユーザー出口とハイパー出口」に関する説明を参照してください。
デフォルトは NOUSEREXIT です。
[NO]USERISN
このパラメータを USERISN に設定すると、入力ファイルの各レコードに対する ISN は、ユーザーによって割り当てられます。
USERISN を指定した場合、ユーザーは、各レコードに割り当てる ISN を各データレコードの直前に先行する 4 バイトの 2 進数として指定します。
ISN は、任意の順番で割り当てることはできますが、(同一ファイル内で)ユニークでなければいけません。ISN は、ファイルに指定された最大レコード数(MAXISN)を超えないようにする必要があります。詳細については、ファイル定義ユーティリティ「ADAFDU」を参照してください。
ADACMP は、ISN の一意性のチェックや ISN が MAXISN を超えるかどうかのチェックは行いません。これらのチェックは、一括更新ユーティリティ ADAMUP によって実行されます(エラーが検出されると、ADAMUP の実行は終了し、エラーメッセージが出力されます)。
このパラメータを NOUSERISN に設定すると、ISN は Adabas によって割り当てられます。
デフォルトは NOUSERISN です。
WCHARSET = char_set
このパラメータは、http://www.iana.org/assignments/character-sets に記載されているエンコード名に基づいて、非圧縮ファイルで使用するデフォルトエンコードを指定します。このサイトに記載されているほとんどの文字セットは、ICU(Adabas 国際化サポートで使用)によってサポートされています。
デフォルトは UTF-8 です。
ADACMP ユーティリティは、次の 3 つのファイルを出力します。
圧縮データ
ディスクリプタ値
エラーのあるレコード
ADACMP が処理、修正および圧縮したデータレコードは、FDT 情報と一緒にシーケンシャルファイルに出力されます。このファイルは、一括更新ユーティリティ ADAMUP に対する入力として使用されます。
出力ファイルにレコードがない場合(入力ファイルにレコードがない場合やすべてのレコードがエラーになった場合)にも、その出力を一括更新ユーティリティ ADAMUP に対する入力として使用できます。
このファイルの内容は、ディスクリプタバリューテーブル(DVT)です。
圧縮データレコードとディスクリプタバリューテーブルは、SINGLE_FILE オプションが指定されると 1 つのファイルに書き込まれます。
ADACMP によってエラーになったすべてのレコードは、ADACMP エラーファイルに書き込まれます。このエラーファイルの内容は、ADAERR ユーティリティを使用して表示します。レコードに出力不能文字が含まれているため、標準オペレーティングシステム出力ユーティリティを使用してエラーファイルを出力しないでください。
詳細については、「ADAERR」ユーティリティの説明を参照してください。
CMPFDT を入力として使用している場合には、ADACMP レポートの先頭に、入力したフィールド定義が出力されます。構文エラーのあるすべてのステートメントは、そのステートメントのすぐ後にメッセージをが表示されます。
データ定義ステートメントの出力の後には、ディスクリプタの概要、処理された入力レコード数、エラーになった入力レコード数、および圧縮された入力レコード数が出力されます。
ADACMP は再スタート機能を備えていません。中断した ADACMP の実行は、最初から再スタートしなければなりません。
ADACMP は、データベースを変更しないので、ADACMP の再スタート前にデータベースステータスに関して考慮する必要はありません。