Dieses Dokument beschreibt, wozu der Output Management GUI Client dient und wie er funktioniert.
Es behandelt folgende Themen:
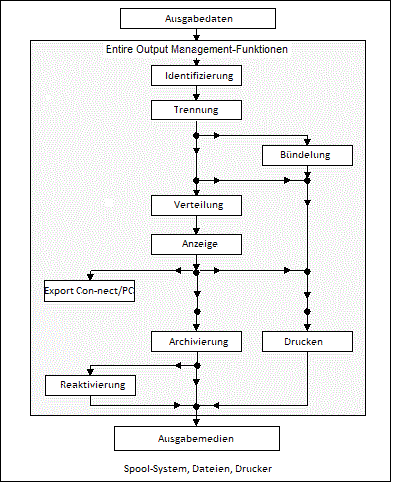
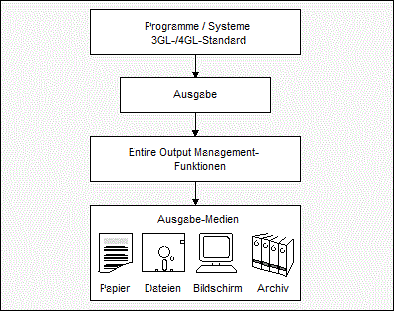
Über den Output Management GUI Client können Sie auf Entire Output Management-Funktionen auf einem Großrechner zugreifen.
Entire Output Management ist ein Werkzeug, das jegliche Art von Programmausgabedaten in heterogenen Client/Server-Umgebungen regelbasiert und automatisch endanwendergerecht aufbereitet, ohne dass hierzu irgendwelche Änderungen an den die Ausgabe erstellenden Anwendungen oder Programmsystemen erforderlich sind.
Entire Output Management kann zum einen im Rechenzentrum eingesetzt werden, um Prozesse der Arbeitsnachbereitung zu automatisieren. Es kann aber auch in Fachabteilungen benutzt werden, um Sachbearbeitern "ihre" Listenausgaben am Bildschirm so zu präsentieren, dass sie als Grundlage betrieblicher Entscheidungsprozesse verwendet werden können, ohne hierfür auf Ausgabelisten auf Papier zurückgreifen zu müssen. So hilft Entire Output Management, unnötige Druckkosten zu vermeiden.
Entire Output Management fungiert hierbei als logisches Verwaltungssystem für Ausgabedaten, d. h. es besitzt klar definierte Schnittstellen zu bestehenden Spooling-Systemen bzw. funktional äquivalenten Teilen des Betriebssystems.
Dies bedeutet insbesondere, dass die erzeugenden Programme unverändert bleiben: Ausgabedaten werden wie bisher erzeugt und dem Spooling-System zur Verwaltung übergeben. Anstelle eines automatischen Druckens liest Entire Output Management dann diese Daten und wendet auf sie vorher festgelegte Regeln an.
Unter vielen anderen Verarbeitungsformen bietet Ihnen Entire Output Management dann die Möglichkeiten, die Ausgabedaten oder Teile davon wieder an das Spooling-System zurückzugeben. Dieses überwacht dann den physischen Druckvorgang.
Entire Output Management bietet Ihnen die Möglichkeit, Ihr schon vorhandenes Listenverteilverfahren schrittweise umzustellen. Sie können dazu identifizierende Merkmale für die Prozesse bzw. Programme eingeben, für deren Ausgabedaten Sie die im Folgenden beschriebenen Entire Output Management-Funktionen anwenden möchten.
Des Weiteren können Sie dann bestimmen, welche Teile der Ausgabedaten der so identifizierten Programme der weiteren Verarbeitung durch Entire Output Management überhaupt unterzogen werden sollen. Dieser Trennungsvorgang wird "Separation" genannt, sein Ergebnis heißt "Report".
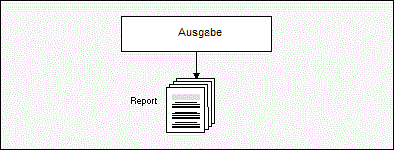
Unter einem Report kann man sich die für den Adressaten wichtigen Teile der Ausgabedaten vorstellen. Was wichtig oder unwichtig ist, können Sie auf sehr flexible und komfortable Weise mit Hilfe der bereits erwähnten Entire Output Management-Regeln selbst bestimmen.
Entire Output Management selbst ist also ein System, mit dem Reports erstellt und verarbeitet werden können.
Weitere Informationen siehe Reports im Benutzerhandbuch.
Reports können zu größeren Datenpaketen - sogenannten "Bündeln" - zusammengefasst werden. Eine solche Bündelung ist auch dann möglich, wenn die Reports auf unterschiedliche Datenquellen (z.B. Jobs) zeigen.
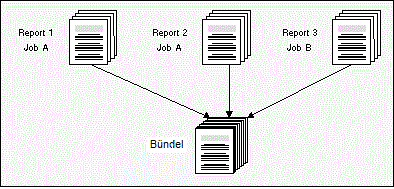
Weitere Informationen siehe Bündel im Benutzerhandbuch.
Reports und Bündel können gezielt an Endanwender verteilt werden. Hierzu gibt es Verteilerlisten, die entweder einzelne Anwender oder wiederum Verteilerlisten oder aber beides enthalten.
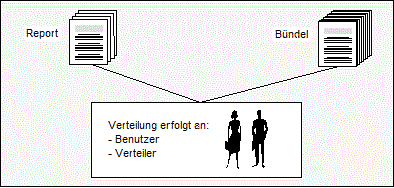
Nur wer Mitglied in der Verteilerliste eines Reports oder Bündels ist, hat Zugriff auf dessen Inhalt (Mandantenfähigkeit). Insbesondere besteht die Möglichkeit der Datenanzeige am Bildschirm.
Weitere Informationen siehe Verteiler im Benutzerhandbuch.
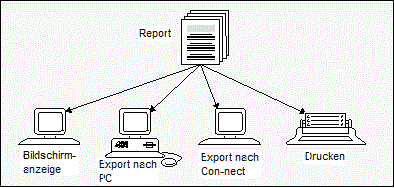
Während also bisher ein Empfänger die Daten auf Papier nach einem mehr oder weniger aufwendigen manuellem Verteilverfahren in der Form zu Gesicht bekam, die von der erzeugenden Anwendung bestimmt wurde, erhält er nun mit Hilfe von Entire Output Management die für seine Arbeit wichtigen Teile in einer für ihn bequemen Weise direkt auf dem Bildschirm an seinem Arbeitsplatz.
Bei Bedarf lassen sich dann Teile der angezeigten Daten zum Beispiel nach Con-nect, dem Büro-Kommunikationssystem der Software AG, exportieren. Der Export zur lokalen Weiterverarbeitung an einem PC ist ebenfalls möglich.
Natürlich können Reports und Bündel auch gedruckt werden. Dies kann entweder regelbasiert und folglich automatisch geschehen oder aber auf manuelle Anforderung eines Entire Output Management-Benutzers, der diese Daten gerade am Bildschirm betrachtet. Der Vorgang des Druckens unter Entire Output Management bewirkt, dass die ausgewählten Daten (Bündel, Reports, Teile von Reports) druckerspezifisch aufbereitet werden können. Sie werden danach an einen sogenannten logischen Drucker übergeben.
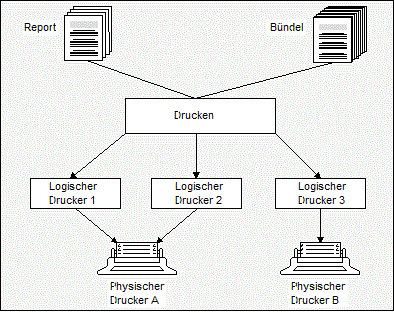
Hinter einem solchen logischen Drucker verbirgt sich dann ein physischer Drucker, der mit einem bestimmten Satz von Attributen angesteuert wird.
Weitere Informationen siehe Logische Drucker im Benutzerhandbuch.
Reports und Bündel haben eine individuelle Lebenszeit, während derer sie online verfügbar sind. Jedes Mitglied ihrer Verteilerlisten hat die Möglichkeit, anderen Benutzern Zugriffsberechtigung auf die jenigen Reports zu erteilen, zu denen dieses Mitglied selbst Zugang hat. Ein solcher Report bzw. Bündel erscheint dann im Posteingang des Adressaten, von wo er bzw. es in individuell definierte Fächer abgelegt werden kann.
Daneben gibt es auch öffentliche Fächer, zu denen jeder Benutzer Zugang hat. Für diese Fächer entfällt dann natürlich der oben beschriebene Vorgang des Verteilens.
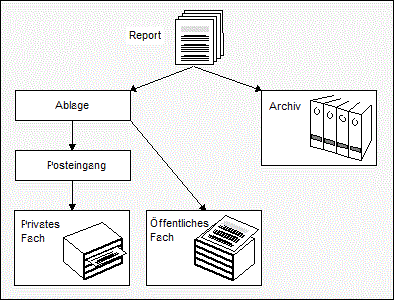
Weitere Informationen siehe Fächer verwalten im Benutzerhandbuch.
Nach Ablauf der Lebenszeit eines Reports kann dieser auf Langzeit-Datenträgern archiviert werden.
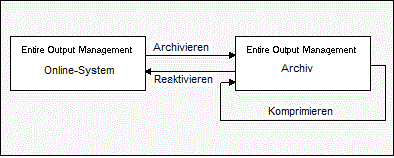
Entire Output Management führt hierüber Buch und gestattet es Ihnen darüber hinaus, bei Bedarf einen solchen Report zu reaktivieren, d. h. dem Online-System wieder verfügbar zu machen. Nicht mehr benötigte Archivdatenträger werden in Komprimierungsläufen freigegeben.
"Verdichtungsjobs" lesen Archive und löschen alle nicht mehr aktuellen Daten, deren Verweildauer überschritten ist und die nicht mehr gebraucht werden. Somit ist es einfacher, Archivdatenbestände (die aus sequenziellen Dateien bestehen) so klein wie möglich zu halten. Eine Funktion zur Definition von Standardwerten für die automatische Archivierung ermöglicht es Ihnen, einen Schwellenwert für die Anzahl der Reports zu definieren, ab der Archivdateien für die Verdichtung markiert werden.
Weitere Informationen siehe Standardwerte für die automatische Archivierung, Felder: Archivierung (Verdichtung Schwelle) bzw. Verdichtung-Task in der Systemverwaltung-Dokumentation.
Zum Entfernen abgelaufener Dateien und zum Löschen nicht mehr benötigter Quellen bietet Entire Output Management verschiedene Bereinigungsfunktionen.
Weitere Informationen siehe Standardwerte für die automatische Bereinigung in der Systemverwaltung-Dokumentation.
Es gibt drei Arten der Bereinigung:
Tägliche Bereinigung
Quell-Bereinigung
Report-Bereinigung
Die Hauptbereinigungsart ist die tägliche Bereinigung. Entire Output Management führt eine tägliche Bereinigung genau einmal täglich bei seiner nächsten Aktivierung nach der in den Systemeinstellungen angegebenen Zeit durch. Ist hier keine Zeit angegeben, wird die tägliche Bereinigung bei der ersten Aktivierung nach Mitternacht durchgeführt.
Quell- und Report-Bereinigung sind optional und können über die entsprechende Systemverwaltungsfunktion aktiviert werden. Sie können einzeln aktiviert werden, und es kann ein Zeitplan für sie definiert werden. Sie können den Zeitplan beliebig festlegen. Mittels eines Kalenders können Sie angeben, an welchen Wochen- und Monatstagen die Bereinigung laufen soll, ob sie vor oder nach arbeitsfreien Tagen laufen soll, in welchem Zeitraum sie laufen soll und wie oft. Sie könnten beispielsweise definieren, dass die Quell- bzw. Report-Bereinigung montags, mittwochs und freitags zwischen 8:00 und 20:00 Uhr alle zwei Stunden durchgeführt werden soll.
Die tägliche Bereinigung verarbeitet alle abgelaufenen Einheiten:
Aktive Reports, die abgelaufen sind, werden entweder gelöscht oder als zu archivieren markiert.
Aktive Bündel, Druckaufträge und Protokolleinträge, die abgelaufen sind, werden gelöscht.
Reaktivierte Reports werden "ent-reaktiviert", das heißt, ihr Inhalt wird gelöscht, wenn der Report auf die Datenbank reaktiviert wurde, und der aktive Report wird auf seinen archivierten Status zurückgesetzt.
Archivierte aktive Reports werden gelöscht.
Aktive Report-Quellen (Spool-Dateien oder Container-Datei-Einträge) werden geprüft und gelöscht, wenn sie nicht länger benötigt werden.
Die Quell-Bereinigung prüft die Quellen von Entire Output Management (zum Beispiel JES- oder Power-Spool-Dateien in Entire Output Managements temporären Klassen oder Einträge in den Container-Dateien), um festzustellen, ob sie noch benötigt werden - und löscht sie, falls sie nicht mehr benötigt werden. Sie gelten als nicht mehr benötigt, wenn sich kein aktiver Report mit Speicherort "S" (Source) mehr auf sie bezieht. Nicht länger benötigte Container-Dateien werden auch dann gelöscht, wenn das Feld Spool-Bereinigung nicht markiert ist.
Die Report-Bereinigung prüft alle aktiven Reports mit Speicherort "S" (Source), um herauszufinden ob die Quell-Datei noch verfügbar ist. Falls nicht, wird der aktive Report gelöscht.
Der tägliche Bereinigungsvorgang kann sehr zeitaufwendig sein (in einer typischen Produktionsumgebung dauert er in der Regel 30 bis 60 Minuten), und während dessen kann der Monitor keine andere Aufgabe ausführen, da der Monitor als "Single Task" läuft; das heißt, solange die tägliche Bereinigung stattfindet, können keine Reports, Bündel oder Druckaufträge verarbeitet werden.
Um dieses Problem zu vermeiden, kann die tägliche Bereinigung in einem
asynchronen Stapeljob laufen. Hierzu führen Sie das Programm
NOMCLEAN in einem Standard-Batch-Natural aus (mit den
entsprechenden Parametern, wie etwa LFILE 206). Dieser Stapeljob
kann dann von einem Job-Scheduler aktiviert werden und ein paar Stunden, bevor
die tägliche Bereinigung durch den Entire Output Management-Monitor ansteht,
laufen. Unmittelbar bevor dann der Monitor seine tägliche Bereinigung startet,
kann der Monitor feststellen, dass NOMCLEAN bereits gelaufen ist
und er selbst daher keine Bereinigung mehr durchführen muß.
NOMCLEAN und der Monitor verständigen sich mittels zweier
Kontrollsätze in der Entire Output Management-Systemdatei über ihren jeweiligen
Status. Der Zugriff auf diese Kontrollsätze erfolgt über die View
NRM-ARCHIVE-TASK und den Deskriptor M-MONITOR-ID =
'CLEANUP' oder M-MONITOR-ID = SYSNOM (d. h. die Bibliothek,
von der aus Entire Output Management ausgeführt wird).
Die Kommunikationswege sind wie folgt:
Wenn NOMCLEAN startet, setzt es SYSNOMs
CLEANUP-IDENTIFIER auf CLEAN,
CLEANUP-ACTIVE-NOW auf TRUE und
CLEANUP-RESCHEDULE auf FALSE, um zu zeigen, dass es
aktiv ist.
RMONITOR (Monitor-Hauptschleife) löscht nicht länger
benötigte Quellen nur, wenn SYSNOMs
CLEANUP-IDENTIFIER nicht auf CLEAN bzw.
CLEANUP-ACTIVE-NOW nicht auf TRUE gesetzt ist (das
heißt, nur wenn NOMCLEAN nicht aktiv ist). Um
Parallelverarbeitungsprobleme beim Erstellen aktiver Reports zu verhindern,
setzt RMONITOR außerdem CLEANUPs
REPORT-PROCESSING-NOW während des Erstellens aktiver Reports auf
TRUE und anschließend wieder auf FALSE. Dies ist
nötig, um zu verhindern, dass NOMCLEAN Reports oder Quellen
löscht, mit denen der Monitor gerade arbeitet.
RMARCSCH (Monitor-Zeitplanfunktionen) führt die
tägliche Bereinigung nur durch, wenn SYSNOMs
CLEANUP-RESCHEDULE und CLEANUP-ACTIVE-NOW beide
FALSE sind (d. h. nur wenn NOMCLEAN nicht aktiv ist
und an diesem Tag nicht bereits gelaufen ist). Wenn
CLEANUP-RESCHEDULE auf TRUE ist, heißt das, dass
NOMCLEAN bereits gelaufen ist, und RMARCSCH setzt
CLEANUP-RESCHEDULE auf FALSE sowie den Zeitpunkt für
die nächste geplante tägliche Bereinigung auf dieselbe Zeit am nächsten Tag
zurück. RMARCSCH führt Quell- bzw. Report-Bereinigung nur durch,
wenn SYSNOMs CLEANUP-ACTIVE-NOW auf
FALSE gesetzt ist. Dadurch werden Konflikte mit
NOMCLEAN, das ebenfalls Quellen bereinigt, vermieden.
RMSRCK (Quell-/Report-Bereinigung) kann vom Monitor
oder von NOMCLEAN aufgerufen werden. Beim Aufruf durch
NOMCLEAN müssen die oben erwähnten Parallelverarbeitungsprobleme
vermieden werden. Hierzu prüft NOMCLEAN den
REPORT-PROCESSING-NOW und verwendet, wenn er auf TRUE
gesetzt ist, den View NPR EVENTING und versetzt sich selbst in
Wartezustand (wiederholt, jeweils für 5 Sekunden), bis
REPORT-PROCESSING-NOW auf FALSE steht, woraufhin
RMSRCK dann die Verarbeitung dort wieder aufnimmt, wo sie
unterbrochen wurde.
Wenn Multi-Tasking aktiv ist (d. h. mehr als ein Monitor-Task definiert ist), werden die Monitor-Bereinigungsfunktionen vom Haupt-Task (Task 1) durchgeführt. Dadurch ist es möglich, die Bereinigung von anderen Monitor-Funktionen wie Erstellen von aktiven Reports und Druckaufträgen zu trennen.
Entire Output Management verfügt über Methoden, um Drucker direkt zu adressieren. Dies wird via TCP/IP erreicht. Diese Druckmethode ist dazu gedacht, Drucker zu nutzen, die entweder eine speziell dafür vorgesehene IP-Adresse oder auf die über einen Drucker-Warteschlangen-Namen eines Drucker-Servers zugegriffen werden kann.
Diese Druckmethode dient vor allem dem direkten Drucken von kurzen Dokumenten direkt aus der Online-Anwendung heraus. Da das Drucken als Natural-Subtask ausgeführt wird, ist kein Speicher (wie z.B. CICS-Speicher) nötig. Kein Spooling-System ist notwendig und kein separater Adressraum wird gebraucht, auch kein Entire Systems Server. Diese Vorgehensweise macht das Drucken unabhängig von Stapelverarbeitung, Broker, CA Spool, Entire Systems Server, JES und Natural Advanced Facilities.
Hierdurch können Durchsatz-Verbesserungen erreicht werden. Ferner werden 4 MB Speicher für einen Entire Output Management-Druckauftrag pro 1000 Seiten gebraucht, sobald der Drucker (Server) den Erhalt des Auftrages bestätigt.
Zur Druckzeit wird die Druckausgabe online oder mittels des Monitors initialisiert und in einem der in Entire Output Management definierten Druckaufträge ausgeführt. Zur Ausführungszeit wird die Druckausgabe im virtuellen Speicher gehalten und dann mittels des LPR/LPD-Protokolls (RFC1179) direkt (per Socket-Programmierung) an TCP/IP gesandt.
Mit Entire Output Management können Sie auch Binärdaten verarbeiten, d.h., Sie können jede Art von Datei oder Druckauftrag in Entire Output Management halten, archivieren, drucken, verteilen oder an ein Zielsystem schicken.
Möglich ist dies mit UNIX- und Windows-Dateisystemen, aber nicht mit Großrechner-Spool-Systemen.
Anmerkung:
Werden Binärdaten gelesen, die von einem Großrechner (Spool oder
Dataset) stammen, kann es bei der Weiterverarbeitung zu
Natural-Programmabbrüchen kommen, z.B. IW060 oder
0C7. Auf Großrechnern können nur Textdaten verarbeitet werden. Aus
Performance-Gründen erfolgt jedoch keine Prüfung zur Sicherstellung, dass die
Eingabedaten keine Binärdaten enthalten.
Im Prinzip gibt es zwei Möglichkeiten, Binärdaten nach Entire Output Management zu übertragen:
Sie können die Direkteingabe-Schnittstelle zusammen mit der Open Print Option (OPO) verwenden. Ein Windows-Client leitet die Ausgabe der Windows-Systeme an Entire Output Management weiter. Dies kann die Ausgabe eines Windows-Druckertreibers oder eines beliebigen Programm sein, das Daten mittels des Windows-"Pipe"-Mechanismus an die Open Print Option weiterleiten kann. (Näheres siehe Abschnitt Open Print Option installieren in der Installation-Dokumentation). Mittels EntireX Remote Procedure Call (RPC) wird die Ausgabe nach Entire Output Management umgeleitet.
Sie können einen Report definieren, der binäre Daten von einem UNIX- oder Windows-Verzeichnis erhält. In der Report-Definition muß das Kontrollkästchen Binär lesen markiert werden, um anzugeben um anzugeben, dass die Datei in Binärformat verarbeitet werden soll.
Der Report wird durch die Entire Output Management-Trigger-Queue
geleitet, ähnlich wie bei der NOMPUT-Schnittstelle. Dazu muß die
Trigger-Queue aktiviert werden (Entire Output Management API und
User-Exit-Standardwerte). Der geöffnete aktive Report erhält den Typ
"binär" (spezieller CC-Typ).
Ein Binär-Dokument kann auf der zeichenbasierten Großrechner-Benutzungsoberfläche nicht angezeigt werden. Der Entire Output Management GUI Client hingegen kann die Daten empfangen, sie auf einem PC speichern (bitte beachten Sie, dass die ganze Datei übertragen werden muss) und sie mit der Windows-Standardanwendung des betreffenden Dateityps (z. B. ".doc" oder ".pdf") anzeigen.
Binäre aktive Reports können mit UNIXLP-Druckern oder auf
BS2000/OSD mit einem SYSPRBS2-Druckertyp gedruckt werden. Unter
UNIX steht der Druckertyp NATUNIX zur Verfügung, der die Daten an
die lp- oder lpr-Utility leiten kann (in diesem Fall
muß die Option -l verwendet werden, um sicherzustellen, dass die
Daten im transparenten Modus weitergeleitet werden), oder an ein Programm oder
Skript oder an eine Datei in einem UNIX-Verzeichnis.
Bitte beachten Sie, dass ein binärer Report, der die Ausgabe eines Windows-Druckertreibers ist, an die Hardware gebunden ist, für die er erstellt wurde. Die Entscheidung, wo die Daten, die Entire Output Management möglicherweise schon vor längerer Zeit erhalten hat, gedruckt werden, wird bereits bei der Erstellung getroffen. Wenn Sie binäre Daten langfristig aufgewahren möchten, sollten Sie die Verwendung von Dateiformaten wie PDF in Erwägung ziehen.
Entire Output Management wandelt binäre Daten in das Format BASE64 um. So können die Daten über Plattformen und Codepages hinweg weitergeleitet werden, da BASE64 ausschließlich aus druckbaren Zeichen besteht. Dies bedeutet allerdings auch, dass die Datenmenge größer ist als der ursprüngliche Binärdatenstrom. Wenn aktive Reports an Ziele ausgegeben werden, wird der BASE64-Datenstrom wieder in das Binärformat decodiert.
Eine Ausgabe über Druckertreiber resultiert oft in große Datenströme, da ein Druckertreiber Druckseiten mit allen grafischen Anweisungen der betreffenden Druckersprache erzeugt.
Theoretisch können Separation Exits verwendet werden. Allerdings können binäre Daten nicht mit Standard Exits separiert werden, da sie nicht lesbar sind.
Jeder Report, den Entire Output Management über die Open Print Option
(OPO) erhält, kann mit benutzerdefinierten Metadaten angereichert werden. Die
Metadaten können auf dem Spool-Attribute-Bildschirm eines aktiven Reports oder in einem
User Exit, der das Feld SPOOL-ATTRIBUTES-EXTENDED verwendet,
eingesehen werden. Metadatenwerte, die die Länge der Terminal-Zeilenlänge der
zeichenbasierten Benutzungsoberfläche von Entire Output Management
überschreiten, werden auf eine Zeile verkürzt und mit dem Fortsetzungszeichen
"..." markiert. Metadaten werden an Entire Output Management
mittels einer XML-Datei übergeben, die in einer OPO-Druckerdefinition definiert
werden kann. Näheres siehe Abschnitt Open Print
Option installieren in der
Installation-Dokumentation.
Weitere Informationen und Beispiele finden Sie im Abschnitt Umgebungen für binäre Dokumente einrichten in der Systemverwaltung-Dokumentation.
Entire Output Management kann Ausgaben von Großrechner-Betriebssystemen und von- UNIX- oder Windows-Systemen handhaben. Diese Ausgaben müssen als ASCII- oder EBCDIC-Dateien gespeichert werden (auf Großrechnern mit oder ohne Steuerzeichen).
Grundsätzlich handhabt Entire Output Management auf UNIX die selben Ausgabeformate wie auf Großrechnern, außer wenn Binärdaten verarbeitet werden müssen. Binärdaten müssen, bevor Sie von Entire Output Management verarbeitet werden, in das ASCII-Datenformat konvertiert werden.
Um Ausgabedaten aus UNIX- oder Windows-Verzeichnissen zu holen, benutzen Sie die UNIX-Knoten-Definitionen. Siehe Standardwerte UNIX in der Systemverwaltung-Dokumentation.
UNIX-Anwendungen können direkt in ein Entire Output
Management-Dateiverzeichnis (ASCII-Dateien) drucken oder auf Spool-Systeme,
z.B. CUPS, zugreifen, um Ausgaben in die Druckerschlange eines virtuellen
Druckers zu drucken. In diesem Fall muss die Druckerschlange von CUPS mit einem
CUPS Backend, z.B. "pipe", verbunden sein (Standardeinstellung:
/usr/lib/cups/backend), das die Daten als ASCII-Dateien in dem
Entire Output Management-Verzeichnis speichert, das bei den Standwerten für
UNIX definiert ist. Siehe Standardwerte
UNIX in der
Systemverwaltung-Dokumentation.
Es gibt jedoch enige Schnittstellen, die unter UNIX nicht existieren und deshalb in einer Entire Output Management UNIX-Umgebung nicht benutzt werden können:
CA Spool
NOMPUT (außer wenn NOMPUT auf einem Großrechner mit Adabas UNIX Entire Output Management-Container-Datei ausgeführt wird)
SAP
Unter UNIX ist Entire Output Management so ausgelegt, dass man nur auf Druckern des Typs NATUNIX und DISKUNIX drucken kann. Ausführliche Informationen siehe Abschnitt Physische Drucker verwalten in der Systemverwaltung-Dokumentation.
Ein Report kann entweder während des Einlesevorgangs oder während der Druckausgabe in eines der üblichen Multimedia-Formate konvertiert werden.
Die hier beschriebene Funktionalität ist noch nicht verfügbar. Sie wird mit der nächsten Version zur Verfügung gestellt.
Ein Report kann während des Einlesevorgangs in eines der üblichen Multimedia-Formate konvertiert werden. Das Quellformat muss Text, PDF oder PostScript sein (Großrechner-Formate wie ASA auf IBM-Betriebssystemen oder Maschinencode auf Siemens OSD werden wie Text behandelt). Außerdem wird ASCII-Textformat verarbeitet.
Das Zielformat für die Konvertierung ist das Format, das zum Speichern der Daten in Entire Output Management verwendet wird.
Die Formatierungsparameter werden an die Utilities Enscript und Ghostscript übergeben, damit diese den Eingabedatenstrom in das gewünschte Format wandeln, das in Entire Output Management als binärer Report gespeichert werden soll.
Falls das Originalformat bereits PDF oder PostScript ist, werden alle Enscript-Formatierungsparameter ignoriert, weil der Report ja schon formatiert wurde, d.h. berechnet und ausgegeben wurde ("Rendering").
Um das zu erreichen, muss ein Entire System Server UNIX-Knoten definiert werden, der auf einer Maschine läuft, auf der die Utilities Ghostscript und Enscript installiert sind. Bei Systemen, auf denen Entire Output Management auf UNIX läuft, kann dies der lokale Entire System Server-Knoten sein. Wenn eine Konvertierung auf Großrechnersystemen erfolgen soll, muss ein Remote Entire System Server UNIX-Knoten angegeben werden, der die Konvertierung durchführt und die Dateien nach Entire Output Management zurücksendet. Falls keine separate UNIX-Maschine für Großrechnersysteme zur Verfügung steht, kann die Verwendung eines z/Linux-Systems für die Konvertierung in Betracht gezogen werden.
Die Konvertierung kann durch Eingabe im Feld Report-Format in der Report-Definition angestoßen werden (siehe Felder: Report Definition >Report Formatierung im Benutzerhandbuch).
Die Ausgabe kann außerdem während der Druckausgabe in eines der üblichen Multimedia-Formate konvertiert werden. Der Druckertyp DISKUNIX steht zur Verfügung, um eine Datei zu konvertieren, nachdem sie auf die Platte geschrieben worden ist. Voraussetzung ist, dass die zu konvertierende Datei in Entire Output Management im Format "Text" (ASCII, ASA, Maschinencode), PDF oder PostScript (oder gemischt in Bündeln) gespeichert werden. Der DISKUNIX-Drucker konvertiert die Text-Reports gemäß den Formatdefinitionen in das gewünschte Format. Reports, die schon als PDF oder im PostScript-Format vorliegen, werden nicht formatiert, weil sie ja schon berechnet und ausgegeben wurden (Rendering). Reports, die in PDF oder PostScript formatiert worden sind, werden lediglich in das gewünschte Ausgabeformat konvertiert, ohne dass dabei die Enscript-Parameter zur Anwendung kommen (siehe Formatierungsattribute für die Dateiformatkonvertierung unter DISKUNIX-Drucker in der Systemverwaltung-Dokumentation). Wenn Trennblätter definiert sind, unterliegen diese jedoch den Formatdefinitionen, da es sich dabei um Textteile des Reports handelt. Wenn Bündel gedruckt werden sollen, sammelt DISKUNIX alle Reports, und zwar unabhängig davon, ob sie im Format Text, PDF oder PostScript vorliegen, und stellt sie in eine Einzeldatei des gewünschten Ausgabeformats. Alle Textteile (Text-Reports, Trennblätter) werden gemäß Definition in den Formatparametern konvertiert. Zur Durchführung der Konvertierung benutzt DISKUNIX die Utilities Ghostscript und Enscript. Diese Utilities müssen auf dem UNIX-System installiert sein, auf das DISKUNIX schreibt.
Die Konvertierung wird durch Eingabe im Ausgabeformat-Attributfeld in der Report-Definition angestoßen.
Bei Reports im Format PDF kann auf jeder Seite eine Maskendatei zur Anwendung kommen. Dabei handelt es sich um eine PDF-Datei mit transparentem Hintergrund. Diese Datei wird auf jeder Seite wie ein Stempel behandelt: Nur in den Teilen der Maskendatei, die transparent sind, erscheint der Originalbericht. Enthält die Maskendatei mehr als eine Seite, werden die entsprechenden Seiten des Originalreports überlagert.
Um die Überlagerungsfunktion in Entire Output Management benutzen zu können, muss das Software-Paket "pdftk" (PDF Toolkit) auf dem Konvertierungsknoten installiert werden. Dieses Paket steht für Windows- und Linus-Maschinen zur Verfügung. Wenn das Feld Command ausgefüllt wird, kann diese Kommandozeile benutzt werden, um die resultierende Datei nach der Konvertierung zu verarbeiten. Beispielsweise können die Utilities "ps2afp" oder "pdf2afp" (die im IBM-Produkt Infoprint enthalten sind) benutzt werden, um schließlich AFP-formatierte Dateien zur Weiterverarbeitung zu erstellen.
Die oben erwähnten UNIX-Utilities sind Produkte von Drittanbietern. Sie sind kein Bestandteil von Entire Output Management. Die Software AG liefert diese Utilites nicht und leistet auch keinen Support dafür.
Entire Output Management benutzt folgende Adabas-Dateien:
NOM-Definitionsdaten-Datei (logische Dateinummer 206)
NOM-Aktivdaten-Datei (logische Dateinummer 91)
Container-Dateien und spezielle Trigger-Container-Datei
Sie können die selbe Adabas-Datei sowohl für die NOM-Definitionsdaten-Datei als auch für die NOM-Aktivdaten-Datei benutzen, jedoch ist in beiden Fällen die Angabe der logischen Dateinummer 206 bzw. 91 erforderlich.
Entire Output Management kann den Inhalt von Reports von ihrer ursprünglichen Adresse (z.B. JES-Spool) entweder in eine Container-Datei oder in die Aktivdaten-Datei von Entire Output Management kopieren (oder in beide).
Das Kopieren in die Aktivdaten-Datei ist unabhängig von der Benutzung einer Container-Datei und erfolgt nur bei Reports, in deren Definition das Feld In NOM DB kopieren markiert ist.
Auf z/OS-Systemen sollten Reports nur in die Aktivdaten-Datei kopiert werden, wenn dies absolut notwendig ist (z. B. um versehentliche Verluste durch Spool-Löschungen zu vermeiden), weil es erheblichen Mehraufwand bedeutet, große Reports in der Datenbank zu speichern.
Eine spezielle Trigger-Container-Datei wird benutzt, um Trigger-Daten für Entire Output Management auf UNIX, für die Open Print Option (OPO) und für Natural Advanced Facilities (NAF) zu speichern.
Entire Output Management kopiert die Report-Sourcen in eine Container-Datei, wenn einer der folgenden Umstände zutrifft:
Wenn Entire Output Management auf UNIX, die Open Print Option (OPO) oder der Output Management GUI Client (NGC) benutzt wird.
Wenn der Report von CA Spool, Natural Advanced Facilities (NAF),
SAP Spool oder der 3GL-Schnittstelle (einschließlich der virtuellen
VTAM-Druckeranwendung NOMVPRNT mit der Parametereinstellung
STORE=DB) ist.
In BS2000/OSD: Wenn die Option Kopieren in DB Dateien im Dialog Monitor-Standardwerte gewählt und mindestens eine Destination (Ausgabemedium) definiert ist. Siehe Container-Dateien definieren.
In JES2, JES3 und POWER: Wenn eine Spool-Datei mit einer
DEST-Angabe verarbeitet wird, die mit einer der Destinationen
(Ausgabemedien) übereinstimmt, die im Dialog
Monitor-Standardwerte
definiert wurden. Siehe Container-Dateien
definieren.
Im Dialog Monitor-Standardwerte können Sie Ihre Container-Dateien für Großrechner-Spool- und Job-Eingabesysteme sowie die Spool-Destination, die in die damit verbundene Container-Datei kopiert wird, definieren. Siehe Container-Dateien definieren.
Container-Dateien für CA Spool, Natural Advanced Facilities (NAF), SAP Spool und die 3GL-Schnittstelle werden definiert unter Standardwerte für CA Spool, Standardwerte für Natural Advanced Facilities (NAF), Standardwerte für SAP-Spool bzw. 3GL-Schnittstelle.
Die Definition der speziellen Container-Datei für Trigger-Daten erfolgt unter Standardwerte für NOM APIs und User Exits.
Entire Output Management speichert Ausgaben in Arrays zu jeweils 16 KB. Adabas komprimiert Nullwerte und nachgezogene Leerstellen in alphanumerischen Feldern. Textdatenausgaben enthalten oftmals Blöcke mit Leerstellen, um die Daten in Listen- oder Tabellenform darzustellen. Diese Leerstellenblöcke werden von Entire Output Management selbst komprimiert. Das bewirkt eine effizientere Nutzung des Adabas-Datenbank-Speicherplatzes und weniger Datenbankzugriffe, und somit eine Verbesserung der Performance.
Trennen, Blättern und teilweises Drucken führt gewöhnlich dazu, dass ein Direktzugriff auf Satzbereiche der Ausgabe erforderlich ist. Dies ist allerdings bei Großrechner-Spooling-Systemen und Platten-Datasets mit variabler Satzlänge nicht gegeben. Der Zugriff auf die Entire Output Management Container-Datei erfolgt äußerst schnell.
Entire Output Management führt diese Speicherung in der Container-Datei vor der Verarbeitung von Report-Definitionen durch. Die Original-Ausgabe wird als Ganzes kopiert, alle folgenden Vorgänge wie Trennen, Blättern und teilweises Drucken laufen sehr schnell ab.
Entire Output Management hält die gesamte Original-Ausgabe in der
Datenbank gespeichert, solange es wenigstens einen aktiven, darauf zeigenden
Report mit Speicherort (Adresse) S (S steht für
Source, nicht Spool) gibt. Dies könnte bedeuten, dass die
Container-Datei mit sehr großen Ausgaben gefüllt wird, auch wenn wirklich nur
ein Bruchteil benötigt wird.
Eine Speicherung in einer Container-Datei ist immer dann sinnvoll, wenn intensive Trennverarbeitung, Blättern oder teilweises Drucken erforderlich ist.
Wenn Sie intensive Trennverarbeitung haben, aber die sich daraus
ergebenden Reports aus dem ganzen Original nur ein Bruchteil sind, wählen Sie
in der Report-Definition die Option
Reportinhalt in
NOM-Datenbank kopieren. Die sich daraus
ergebenden Reports werden dann von der in der Container-Datei liegenden
Original-Ausgabe in die Entire Output Management-Systemdatei kopiert, und der
Speicherort (Adresse) des Reports wird zu D. Wenn die nächste
Bereinigung durchgeführt wird und es keine Reports mit Speicherort
S gibt, die auf die Original-Ausgabe zeigen, wird sie aus der
Container-Datei gelöscht.
Es ist jedoch zu beachten, dass, während der
"Lebenszeit" der Original-Ausgabe in der Container-Datei, dies für
Reports, die mit der Option
Reportinhalt in
NOM-Datenbank kopieren bei der Report-Definition
erstellt wurden, bedeutet, dass diese Teile der Ausgabe tatsächlich wieder in
der Aktiven-Daten-Datei gespeichert werden, wohingegen Entire Output Management
bei der Speicherortangabe S nur Zeiger auf die Container-Datei
behält.
Verwenden Sie Container-Dateien für umfangreiche Verarbeitungen, z.B. bei Verwendung von Trenn-Exits.
Benutzen Sie die spezielle Container-Datei für Trigger-Daten bei Entire Output Management auf UNIX, bei der Open Print Option und bei Natural Advanced Facilities.
Wählen Sie außerdem die Option Reportinhalt in NOM-Datenbank kopieren, wenn nur kleine Teile des Originals benötigt werden, oder wenn die resultierenden Reports sehr unterschiedliche Ablaufdaten haben.
Denken Sie daran, dass der Report mit dem längsten Ablaufdatum die Lebenszeit der gesamten Original-Ausgabe in der Container-Datei festlegt.