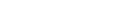
Dieser Abschnitt beschreibt,
wie Sie die Attribute eines neuen Reports festlegen.
Aufruf siehe Neuen Report erstellen.
bzw. wie Sie Attribute in einer vorhandenen Report-Definition ändern.
Aufruf siehe Report ändern.
Die Felder für die Report-Definition befinden sich auf den Registerkarten Allgemeine, Identifikation, Verteilung, Drucken, Benutzer-Separation und Report-Formatierung.
Beim Erstellen eines neuen Reports sind einige Felder mit Standardwerten vorbelegt. Diese Vorgaben können für einen neu anzulegenden Report durch Überschreiben geändert werden. Weitere Informationen siehe Standardwerte Report in der Systemverwaltung-Dokumentation.
Auf der Registerkarte Allgemeine können Sie die allgemeinen Attribute des Reports festlegen.
Anmerkung:
Einige der Felder können durch den Administrator mit
Standardparametern vorbelegt werden. Siehe
Standardwerte
Report in der
Systemverwaltung-Dokumentation. Sie können diese Vorgaben
für die neu anzulegende Report-Definition durch Überschreiben ändern.
| Feld | Beschreibung | ||||||
|---|---|---|---|---|---|---|---|
| Report Name | Wenn Sie einen neuen Report anlegen, müssen Sie
zuerst einen Reportnamen angeben, bevor Sie andere Daten eingeben.
Anmerkung: |
||||||
| Beschreibung | Geben Sie eine kurze Beschreibung des Reports ein. | ||||||
| Typ |
|
||||||
| Eigentümer | Der Monitor nimmt die Benutzerkennung des Haupteigentümers, um Druckjobs für diejenigen Reports zu starten, die automatisch gedruckt werden sollen. Dieses Feld wird mit der Benutzerkennung der Person initialisiert, die die Report-Definition anlegt. | ||||||
| Schlüsselwörter | Geben Sie bis zu 3 Schlüsselwörter ein, die Ihnen später bei der Suche nach Reports nützlich sein können. | ||||||
| Reportinhalt in NOM-Datenbank kopieren | Markieren Sie Ja, um den
Inhalt des Reports aus der Spool zu nehmen und in der NOM-Aktivdaten-Datei zum
späteren Einsehen oder Archivieren zu speichern. Andernfalls markieren Sie
Nein.
Wenn Sie keinen Speicherort angeben (Entire Output Management oder Con-nect), dann bleibt der Report in der Spool-Datei. |
||||||
| Aufbewahrungszeiten | Die Aufbewahrungszeit des Reports legt fest,
wie lange der aktive Report online zum Einsehen und Drucken zur Verfügung
steht. Wenn die Aufbewahrungszeit abläuft, wird der aktive Report entweder zum
Archivieren markiert oder gelöscht (siehe Feld
).
Siehe auch Verarbeitung eines aktiven Reports. |
||||||
| Aktion | Folgende Angaben sind möglich:
Wenn ein aktiver Report archiviert wird, dann stehen sein Inhalt nicht mehr online zur Verfügung, sondern existiert nur noch in dem Archiv-Dataset. Der aktive Report muss zunächst reaktiviert werden, damit sein Inhalt wieder eingesehen oder gedruckt werden kann. |
||||||
| Anzahl | Geben Sie die Anzahl der Arbeitstage, absoluten Tage, Wochen oder Monate ein, die der Report zur Verfügung stehen soll. Die Voreinstellung ist die systemweite, vom Systemadministrator definierte Zeitspanne. | ||||||
| Einheit | Wählen Sie eine Einheit für die Anzahl.
Mögliche Werte:
Die Einheit bedeutet die Anzahl der Instanzen eines aktiven Reports, die aufbewahrt werden. Ältere aktive Reports, die diese Anzahl überschreiten, werden gemäß der gewählten Aktion behandelt. |
||||||
| Kalender | Wählen Sie einen Kalender aus, wenn Sie
"Arbeitstage" als Einheit für den Aufbewahrungszeitraum angegeben
haben.
Anmerkung: |
||||||
| Archivtyp | Wenn der Report in einem benutzerdefinierten
Archiv archiviert werden soll, benutzen Sie das Listenfeld auf der rechten
Seite, um den gewünschten Archivtyp auszuwählen.
Lassen Sie das Feld leer oder wählen Sie "(keine)", wenn der Report in einer standardmäßigen Entire Output Management-Archivdatei zu archiviert werden soll. |
||||||
| Archivieren für | Geben Sie an, wie lange der aktive Report im
Archiv aufbewahrt werden soll.
Nach Ablauf dieses Zeitraums wird der aktive Report aus dem Archiv-Dataset gelöscht. Ein aktiver Report kann unabhängig davon, wo er gespeichert ist, archiviert werden. |
||||||
| Reaktivierten Report bereithalten für | Geben Sie an, wie lange der Inhalt eines
reaktivierten aktiven Reports online zum Einsehen und Drucken zur Verfügung
stehen soll. Nach Ablauf dieses Zeitraums wird diese Kopie des archivierten
Reports automatisch gelöscht.
Geben Sie Werte für Anzahl, Einheit und Kalender ein. Siehe auch Verarbeitung eines aktiven Reports. |
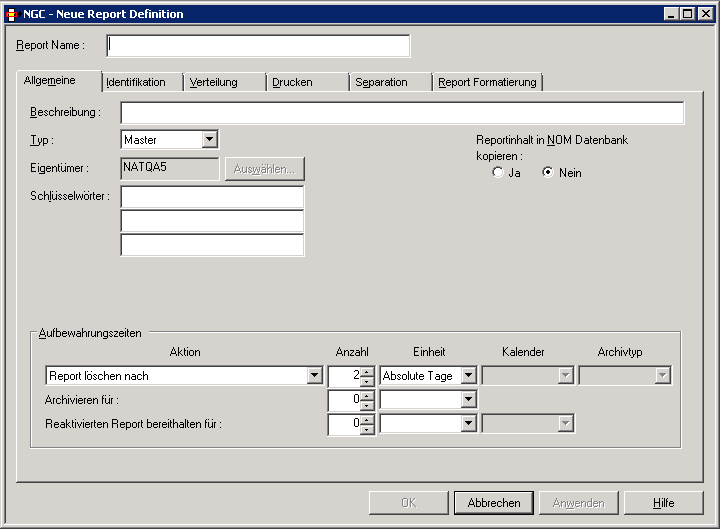
Wenn Sie auf der Registerkarte Identifikation im Feld Identifikationsquelle "POWER" wählen, können Sie festlegen, wie Reports in der POWER-Spool identifiziert werden.
Der Report kann durch Jobnamen, Destination, Writer oder Form und eine Spool-Datei-Angabe identifiziert werden.
Anmerkung:
Ein Report kann identifizierende Attribute aus nur einer
Identifikationsquelle enthalten.
| Feld | Erklärung |
|---|---|
| POWER-Attribute | Es muss mindestens eines der folgenden drei POWER-Attribute
angegeben werden.
Diese Attribute dienen dann als primäres Auswahlkriterium für Report-Definitionen. Eine Report-Definition gilt als identifiziert, wenn mindestens ein primäres Auswahlkriterium zutrifft. Beachten Sie bitte, dass die Anzahl der identifizierten Definitionen durch die primären Auswahlkriterien eingeschränkt wird. Eine Nachselektion erfolgt über den (die) Dateinamen. |
| Jobname | Wenn Sie den Report durch den Namen des ursprünglichen Jobs
identifizieren möchten, geben Sie hier einen Jobnamen an.
Sie können auch einen Stern (*) eingeben, um Auswahlkriterien für den Jobnamen zu definieren (z.B. IEE* für alle Jobs, deren Namen mit IEE beginnen). Indem Sie die Felder im Bereich und Dateien ausfüllen, können Sie die Spool-Dateien, denen der Report zugewiesen werden soll, in diesem Job wählen. |
| oder Destination | Wenn Sie den Report anhand des Parameters
DEST des ursprünglichen Jobs identifizieren möchten,
geben Sie hier einen Wert ein.
|
| oder Form | Wenn Sie den Report anhand des Parameters
FORM des ursprünglichen Jobs identifizieren möchten,
geben Sie hier einen Wert ein.
|
| und Dateien |
Um die Spool-Dateien in den ausgewählten Jobs anzugeben, die den Report bzw. die Reports identifizieren, füllen Sie diese Felder wie folgt aus:
Folgende Sonderzeichen werden als Platzhalter unterstützt:
Anmerkung: |
Anmerkung:
Die Verarbeitung sequenzieller Dateien wird ebenfalls durch
Einträge in der Spool-Queue angestoßen. Die Spool-Datei enthält hierzu keine
Druckdaten, sondern zeigt auf die zu verarbeitende sequentielle Datei. Dieser
Eintrag kann mit beliebigen Utilities (z.B. einem Natural-Programm) erzeugt
werden und muss folgende Merkmale besitzen:
NOM DSN=<data-set-name> VOL=<volser> NOM RECFM=<recform> RECSIZE=<record-length> NOM BLKSIZE=<block-size> CC=<carriage-control>
Maximale Länge des DSN-Musters zur Identifizierung des Datasets ist 22.
Maximale Länge des Eingabe-Dataset-Namens ist 26.
<carriage-control> = ASA, MACHINE oder NONE.
Die Datei wird vor der Verarbeitung umbenannt.
Wenn Sie auf der Registerkarte Identifikation im
Feld Identifikationsquelle BS2000 wählen,
können Sie festlegen, wie Reports in der BS2000/OSD-Spool identifiziert
werden.
Der Report kann durch Jobnamen, Destination, Writer oder Form und eine Spool-Datei-Angabe identifiziert werden.
Anmerkung:
Ein Report kann identifizierende Attribute aus nur einer
Identifikationsquelle enthalten.
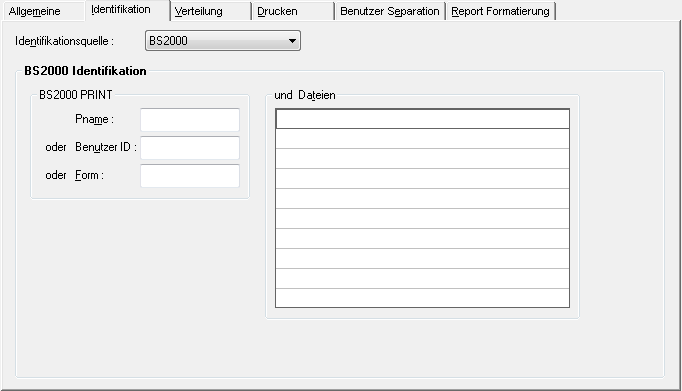
| Feld | Erklärung |
|---|---|
| BS2000 PRINT | Es muss mindestens eines der folgenden drei PRINT-Attribute angegeben werden. Diese Attribute dienen als primäres Auswahlkriterium für Report-Definitionen. Eine Report-Definition gilt dann als identifiziert, wenn zumindest ein primäres Auswahlkriterium zutrifft. Beachten Sie bitte, dass die Anzahl der identifizierten Definitionen durch die primären Auswahlkriterien eingeschränkt wird. Eine Nachselektion erfolgt über den (die) Dateinamen. |
| Pname | Wenn Sie den Report durch den PNAME-Option des
Print-Kommandos identifizieren möchten (/Print ...,PNAME=ADAREP),
geben Sie hier den PNAME ein. Sie können auch einen Stern (*) eingeben, um
Auswahlkriterien für den PNAME zu definieren (z.B. ADA* für alle Jobs, deren
PNAME mit ADA beginnen).
|
| oder Benutzer-ID | BS2000/OSD-Benutzerkennung, in der das Print-Kommando
eingegeben wurde. Wenn Sie den Report über diese ID identifizieren möchten,
geben Sie die hier ein (z.B.: PROD01).
|
| oder Form | FORM-Angabe vom Print-Kommando. Möchten Sie die Report-Definition über die FORM-Angabe identifizieren, geben Sie hier die FORM an. |
| und Dateien | Geben Sie hier einen voll- oder teilqualifizierten Dateinamen
an, der den Report identifiziert (Nachselektion). Eine Report-Definition gilt
dann als identifiziert, wenn zusätzlich zu einem der primären Auswahlkriterien,
ein Datei-Parameter aus der Liste der Dateien zutrifft.
Anmerkung: |
Wenn Sie im Feld Pname den Wert ADA*
eingeben und im Feld und Datei den Wert
*L.ADAREP.* eingeben, werden alle Dateien identifiziert deren
PNAME mit ADA beginnt und deren Dateiname den Bestandteil
L.ADAREP. enthält.
| Sonderzeichen | Bedeutung |
|---|---|
| ? (Fragezeichen) | Gibt eine einzelne Position an, die nicht geprüft werden soll. |
| _ (Unterstrich) | Wie Fragezeichen (?). |
| * (Stern) | Steht für beliebig viele Positionen, die nicht geprüft werden
sollen.
Beispiel: |
Ob eine Druckdatei Vorschubsteuerzeichen beinhaltet und welche, wird
am RECFORM-Parameter der Datei erkannt:
(F,A),(V,A),... enthält ASA-Vorschubsteuerzeichen.
(F,M),(V,M),... enthält
EBCDIC-Vorschubsteuerzeichen.
(F,N),(V,N),... enthält keine
Vorschubsteuerzeichen.
Es empfiehlt sich, Dateien mit fester Satzlänge zu verwenden, da innerhalb von ihnen eine Positionierung weniger aufwendig ist als bei Dateien mit variabler Satzlänge.
| Warnung: Dateien mit fester Satzlänge, die mit OPEN-EXTENT erweitert wurden, werden nicht unterstützt. Verwenden Sie in diesem Fall Sätze variabler Länge. |
Wenn Sie auf der Registerkarte Identifikation im Feld Identifikationsquelle "JES" wählen, können Sie festlegen, wie Reports in der JES-Spool identifiziert werden.
Der Report kann durch Jobnamen, Destination, Writer oder Form und eine Spool-Datei-Angabe identifiziert werden.
Anmerkung:
Ein Report kann identifizierende Attribute aus nur einer
Identifikationsquelle enthalten.
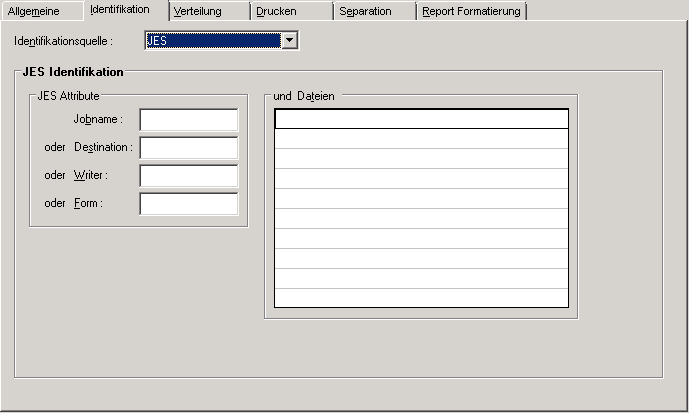
Sie müssen mindestens eines der folgenden vier JES-Attribute angeben. Diese Attribute dienen als primäres Auswahlkriterium für Report-Definitionen. Ein Report gilt dann als identifiziert, wenn mindestens ein primäres Auswahlkriterium zutrifft. Beachten Sie bitte, dass die Anzahl der identifizierten Definitionen durch die primären Auswahlkriterien eingeschränkt wird. Eine Nachselektion erfolgt über den (die) Dateinamen.
| Feld | Beschreibung |
|---|---|
| Jobname | Wenn Sie den Report durch den Namen des
ursprünglichen Jobs identifizieren möchten, geben Sie hier einen Jobnamen an.
Sie können auch einen Stern (*) eingeben, um Auswahlkriterien für den Jobnamen
einzugeben. Zum Beispiel: IEE* für alle Jobs, deren Namen mit
IEE beginnen). Indem Sie die Felder unter der Überschrift
und Dateien ausfüllen, können Sie die Spool-Dateien in
diesem Job wählen, die dem Report zugewiesen werden sollen.
|
| oder Destination | Wenn Sie die Spool-Datei über den Parameter
Destination des ursprünglichen Jobs identifizieren
möchten, geben Sie hier die Destination ein.
|
| oder Writer | Wenn Sie die Spool-Datei über den Parameter
External Writer identifizieren möchten, geben Sie hier den
Writer-Namen ein. Damit setzen Sie die Verknüpfung zwischen dem Report und der
Spool-Datei, die diesem Writer zugeordnet ist. Die Verwendung eines externen
Writers, der dem Report-Namen ähnlich ist, erleichtert die
Identifikation.
|
| oder Form | Wenn Sie den Report über den Parameter
FORMS des ursprünglichen Jobs identifizieren möchten,
geben Sie hier die Form ein.
|
| und Dateien | Siehe Felder: "und Dateien" weiter unten.
Anmerkung: |
![]() Um die Spool-Dateien in den ausgewählten Jobs anzugeben, die den
bzw. die Reports identifizieren, füllen Sie diese Felder wie folgt aus:
Um die Spool-Dateien in den ausgewählten Jobs anzugeben, die den
bzw. die Reports identifizieren, füllen Sie diese Felder wie folgt aus:
Entweder:
Geben Sie <Dateityp>
<Dateinummer> ein.
Dabei ist Dateityp:
JL |
JCL-Statements |
SI |
Systemeingabe |
SM |
System-Meldungen |
SO |
Systemausgabe |
Beispiele:
Geben Sie SO 1 ein für die erste SYSOUT-Datei.
Geben Sie SO 1:2 ein für die erste und zweite
SYSOUT-Datei.
Oder:
Geben Sie eine komplette Liste der DDNAME-Kennzeichner ein, im
Format:
<PROCNAME>.<STEPNAME>.<DDNAME> |
Beispiel: PROC1.STEP1.DDN1
PROCNAME und
STEPNAME sind keine Pflichtangaben. Ein
Stern * (für "beliebig") wird angenommen, wenn sie fehlen. Sie
können einen Stern * benutzen, um Auswahlkriterien für die Dateinamen
einzugeben.
Beispiel: *.STEP1.DDN1
Dies weist auf eine Spool-Datei mit STEPNAME=STEP1,
DDNAME=DDN1 und einem beliebigen
PROCNAME hin.
*.*.DDN1, *.DDN1 oder DDN1,
z. B. sind gleichbedeutend und weisen auf eine Spool-Datei mit
DDNAME=DDN1 in einem beliebigen
PROCNAME oder
STEPNAME im Job hin.
Oder:
Geben Sie TYPE=AL ein, um einen aktiven Bericht zu
generieren, der alle Systemmeldungen und Sysout-Datensätze für einen Job
enthält, die zu den angegebenen JES-Attributen passen. Der Job muss mindestens
eine Spool-Datei in einer von Entire Output Management verwalteten Klasse
enthalten. TYPE=AL darf nur das einzige Datensatz-Kriterium
sein.
Anmerkung:
Soll mehr als eine JES2 Spool-Datei eines Jobs durch Entire Output
Management verarbeitet werden, so ist es zwingend erforderlich, dass alle zu
verarbeitenden Spool-Dateien eines Jobs mit jeweils der gleichen Gruppenkennung
gemeinsam in eine für Entire Output Management reservierte Klasse gelangen.
Falls dies nicht bereits durch die DD Anweisungen geschieht, sondern z.B. per
Programm mittels Entire System Server-Funktionalität, sollte dazu die View
SPOOL-UPDATE wie folgt verwendet werden:
PROCESS SPOOL-UPDATE
USING FUNCTION = 'CHANGE'
USING JOB-NAME = #JOB-NAME
USING JOB-NUMBER = #JOB-NUMBER
USING GROUP-ID = #GROUP-ID
USING CLASS = #NOM-CLASS
USING NODE = #NODE
GIVING ERROR-CODE
ERROR-TEXT
Geben Sie den Dateinamen ein, wenn die Spool-Daten in einer
sequenziellen Datei stehen. Der Dateiname beginnt mit DSN=.
Folgende Sonderzeichen werden als Platzhalter unterstützt:
| Zeichen | Bedeutung |
|---|---|
| ? (Fragezeichen) | Gibt eine einzelne Position an, die nicht geprüft werden soll. |
| _ (Unterstrich) | Wie Fragezeichen. |
| * (Stern) | Steht für beliebig viele Positionen, die nicht
geprüft werden sollen.
Beispiel: |
Anmerkung:
Die Verarbeitung sequenzieller Dateien wird ebenfalls durch
Einträge in der Spool-Queue angestoßen. Die entsprechende Spool-Datei enthält
keine Druckdaten, sondern zeigt auf die zu verarbeitende sequenzielle Datei.
Dieser Eintrag kann mit beliebigen Utilities erzeugt werden und muss folgende
Merkmale besitzen:
NOM DSN=<Dateiname>
Maximale Länge des DSN-Musters zur Identifizierung des Datasets ist
22. Genauer: Das Muster muss mit DSN= beginnen und kann dann bis
zu 22 Zeichen inklusive Platzhalterzeichen ("Wildcards")
haben.
Maximale Länge des Eingabe-Dataset-Namens ist 26.
Der STEPNAME zur Erzeugung der Spool-Datei muss NOMDSN
sein.
//JOB 1 JOB... ...... //NOMDSN EXEC PGM=IEBGENER //SYSPRINT DD SYSOUT=* //SYSUT2 DD SYSOUT=3 //SYSIN DD DUMMY //SYSUT1 DD * NOM DSN=OUTPUT.LISTING /*
Wenn Sie auf der Registerkarte Identifikation im
Feld Identifikationsquelle NATURAL wählen,
können Sie festlegen, wie Reports identifiziert werden, die von Natural (z.B.
mit Access Method NOM) oder Add-on-Produkten wie Natural Advanced Facilities
(NAF) oder Open Print Option (OPO) erstellt wurden.
Der Report wird durch die Natural-Benutzerkennung, Natural-Bibliothekkennung oder den logischen Druckernamen identifiziert, und kann auch durch Natural-Programm, -Formular und -Report-Name identifiziert werden.
Anmerkung:
Ein Report kann identifizierende Attribute aus nur einer
Identifikationsquelle enthalten.
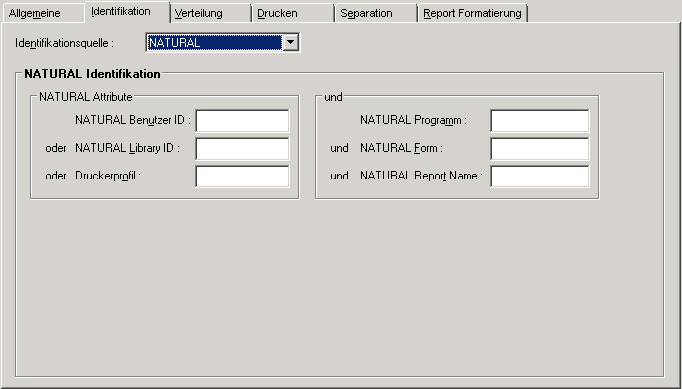
Die Ausgabe von Natural wird während der Verarbeitung eines
spezifischen Programms erzeugt. Dieses Programm ist in einer Natural-Bibliothek
gespeichert und wird von einem Natural-Benutzer ausgeführt. Diverse Attribute
können für diese Ausgabe im Natural-DEFINE PRINTER-Statement
definiert sein. Um diese Ausgabe zu identifizieren, geben Sie eine oder mehrere
Attribute an.
Sie können in allen Feldern Stern-Notation (*) verwenden, jedoch nicht im Feld Druckerprofil.
Anmerkungen:
Beispiel:
Wenn Sie als Benutzerkennung den Wert ABC und als
Bibliothekkennung den Wert SYSNOM angeben, werden alle
Druckdateien identifiziert, die entweder vom Benutzer ABC oder in der
Bibliothek SYSNOM erstellt wurden.
Wenn Sie auf der Registerkarte Identifikation im Feld Identifikationsquelle "SAP-Spool" wählen, können Sie festlegen, wie Reports in der SAP-Spool identifiziert werden.
Anmerkung:
Ein Report kann identifizierende Attribute aus nur einer
Identifikationsquelle enthalten.
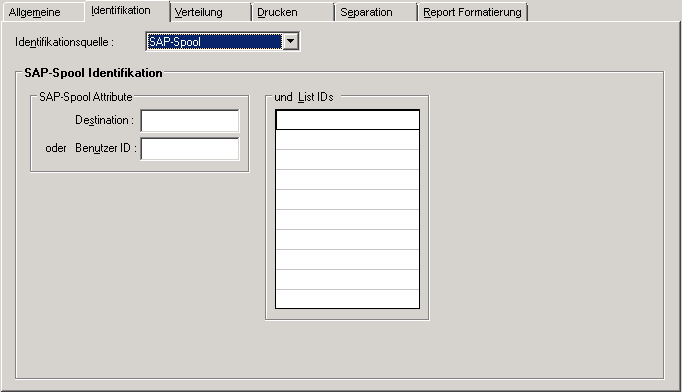
Auf dieser Registerkarte können Sie Attribute definieren, die auf der SAP-Spool-Schnittstelle aufbauen. Identifizierende Primärattribute sind Destination und Benutzer-ID. Mittels Listen-Identifikation kann nachselektiert werden.
| Feld | Beschreibung | |
|---|---|---|
| SAP-Spool Attribute | Mindestens eines der beiden
SAP-Spool-Attribute muss angegeben werden. Diese Attribute dienen als primäre
Auswahlkriterien für Reports.
Anmerkungen:
|
|
| Destination | Soll die Druckdatei durch die Destination identifiziert werden, geben Sie hier deren Namen an. | |
| oder Benutzer-ID | Soll die Druckdatei durch die Benutzerkennung identifiziert werden, geben Sie hier die Benutzerkennung an. | |
| und List-IDs | Geben Sie hier einen voll- oder
teilqualifizierten Listennamen an, der den Report identifiziert
(Nachselektion).
Eine Report-Definition gilt dann als identifiziert, wenn zusätzlich zu einem primären Auswahlkriterium eine Listenkennung (List-ID) aus dieser Liste zutrifft. |
|
Wenn Sie auf der Registerkarte Identifikation im Feld Identifikationsquelle "UNIX" wählen, können Sie festlegen, wie Reports auf UNIX- oder Windows-Knoten identifiziert werden.
Auf dieser Registerkarte definieren Sie, wie Reports auf UNIX-/Windows-Knoten identifiziert werden.
Anmerkung:
Ein Report kann identifizierende Attribute aus nur einer
Identifikationsquelle enthalten.
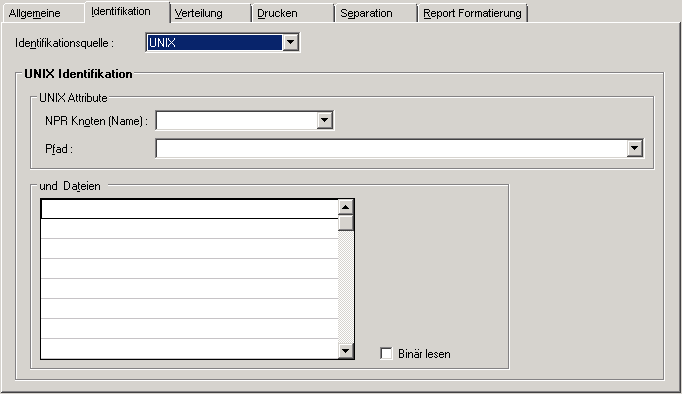
Ein Report wird anhand von Knotenname, Pfad und Dateimuster identifiziert. ASCII-Dateien werden im angegebenen Verzeichnis durchsucht und an das hier angegebene Dateimuster angepasst. Diese Dateien werden in eine Entire Output Management-Container-Datei verschoben und können wie üblich abgearbeitet werden. Eine ASCII-Datei kann Zeilenvorschübe, Seitenvorschübe und Tabulatoren enthalten, alle anderen Arten von Steuerzeichen werden ignoriert und in Leerzeichen umgesetzt.
Binärdateien können beliebiges Format haben. Ihr Format wird in Base64-Format gewandelt, und sie werden in einer Management-Container-Datei gespeichert. Zur Druckzeit wird die Datei dann wieder in das Binärformat zurückgewandelt.
Zusätzlich zu den im Dateisystem unter UNIX oder Windows
untergebrachten Dateien kann der Identifizierungsprozess von Entire Output
Management Metadaten verarbeiten. Wenn ein Dateipaar wie z.B.
file-name.extension und
file-name.extention.nomxml gefunden
wird, dann wird die Datei mit der Erweiterung
nomxml als Metadatei im XML-Format
behandelt. Dieses Format entspricht den Metadatendateien, die von der Open
Print Option verarbeitet werden; siehe Open Print
Option installieren. Dazu muss der Monitor in die Lage
versetzt werden, XML-Dateien zu verarbeiten; siehe Entire Output Management für OPO
konfigurieren.
Ausgaben von einer UNIX- oder Windows-Anwendung werden als eine sequenzielle ASCII-Datei in einem hier definierten Verzeichnis gespeichert. Der Monitor verschiebt dann diese Datei (keine Kopie!) in eine Entire Output Management-Container-Datei und erstellt aktive Reports. Wenn keine Report-Definition dem Dateinamensmuster entspricht und wenn kein Standard-Report gefunden wurde, kann die Datei nicht verarbeitet werden. Sie wird dann in ein temporäres Verzeichnis verschoben, das für diesen Knoten mit der Systemverwaltungsfunktion Standardwerte UNIX für diesen Knoten definiert wurde. Bei Datei- und Pfadnamen wird zwischen Groß- und Kleinschreibung unterschieden. Knoten-Name und Pfad müssen zuerst mit der Systemverwaltungsfunktion Standardwerte UNIX definiert werden, ebenso wie die Anmeldedaten für diesen Knoten.
| Feld | Erklärung |
|---|---|
| UNIX-Attribute | |
| NPR Knoten (Name) | Wählen Sie einen Entire System Server-Knotennamen, der vom Administrator in den UNIX-Standardwerten vordefiniert wurde. |
| Binär lesen |
|
| Pfad | Wählen Sie aus der Standard-Definition, die mit der
Systemverwaltungsfunktion Standardwerte UNIX
angelegt wurde, einen Pfad aus.
Pfad-Definitionen dürfen keine Platzhalterzeichen ("Wildcards") enthalten. Entire Output Management ist der Eigentümer des definierten Pfades. Der Monitor arbeitet dann jede in diesem Pfad gefundene Datei ab. Verzeichnisse werden nicht abgearbeitet. Wenn in diesem Verzeichnis eine Datei gefunden wurde, die nicht abgearbeitet werden kann, wird sie ins Zwischenverzeichnis verschoben (siehe Erläuterung weiter oben). |
| und Dateien | Geben Sie bis zu 10 Dateien oder Dateimuster ohne Eintrag des
jeweiligen Pfades ein.
Anmerkungen:
Für jede mit dem/den Muster/n übereinstimmende Datei wird ein aktiver Report erstellt. Der Datei-Inhalt wird allerdings nur einmal für jeden Pfad in die Containerdatei kopiert. Nach Abarbeiten der Datei wird sie auf dem UNIX- oder Windows-Knoten gelöscht. |
Siehe auch 3GL-Schnittstelle und Verwaltung der 3GL-Schnittstellen in der Systemverwaltung-Dokumentation.
Wenn Sie auf der Registerkarte Identifikation im Feld Identifikationsquelle "3GL" wählen, können Sie Reports definieren, die auf einer allgemeinen, benutzerdefinierten 3GL-Schnittstelle basieren.
Anmerkung:
Ein Report kann identifizierende Attribute aus nur einer
Identifikationsquelle enthalten.
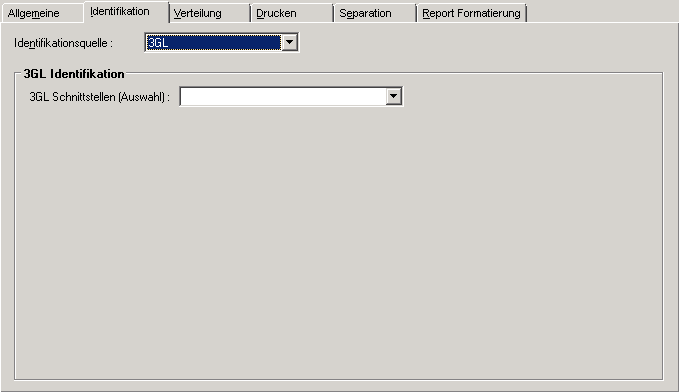
Wählen Sie eine 3GL-Schnittstelle aus.
Wenn Sie auf der Registerkarte Identifikation im Feld Identifikationsquelle "CA Spool" wählen, können Sie festlegen, wie Reports in CA Spool identifiziert werden.
Anmerkung:
Ein Report kann identifizierende Attribute aus nur einer
Identifikationsquelle enthalten.
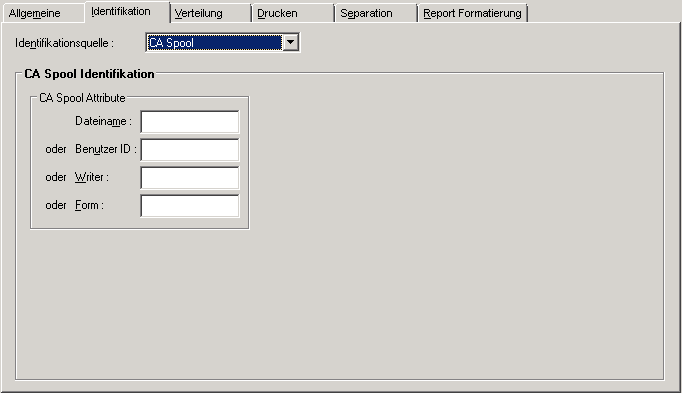
| Feld | Erklärung |
|---|---|
| CA Spool Attribute | |
| Dateiname | Geben Sie hier den Dateiname an, wie er im CA
Spool-Bildschirm zur Anzeige der Druckdateien (Display
Files Panel) angezeigt wird. Der Dateiname kann die Benutzerkennung
des Erstellers, den Jobnamen oder einen Parameter, der im Feld
OWN beim OPEN-Request gemacht wurde, enthalten. Nähere
Einzelheiten entnehmen Sie der CA Spool-Literatur.
Wenn Sie den Report durch den Dateinamen identifizieren möchten, geben Sie hier den Dateinamen an. Anmerkung: |
| oder Benutzer-ID | Benutzerkennung des Benutzers, der die Liste erstellt hat. Wenn Sie den Report über diese Benutzerkennung identifizieren möchten, machen Sie hier Ihre Eingabe (Feld UID beim OPEN-Request). |
| oder Writer | Geben Sie hier den Writer-Namen an, wenn Sie den Report über
den Writer-Parameter identifizieren möchten (Feld
WTR beim OPEN-Request).
|
| oder Form |
Geben Sie hier den Formularnamen an, wenn Sie die den Report
über den |
Anmerkung:
Eine Definition gilt als identifiziert, wenn mindestens eines der
CA Spool-Attribute zutrifft.
Wenn Sie bei Dateiname den Wert MRS*
und bei Benutzer-ID den Wert MRS eingeben,
werden alle Druckdateien identifiziert, deren Dateiname mit MRS
beginnt oder vom Benutzer mit der Benutzerkennung MRS erstellt wurden.
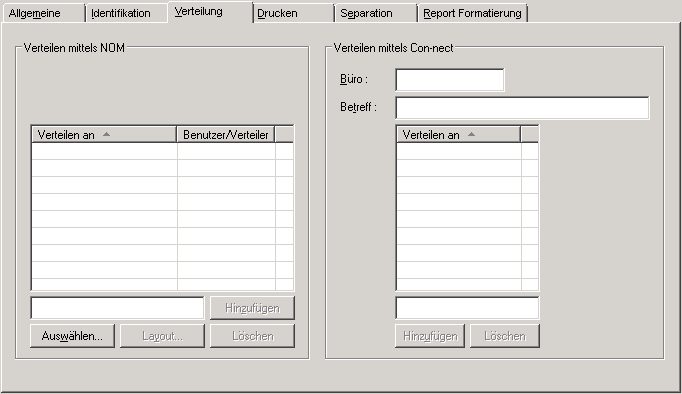
Auf der Registerkarte Verteilung können Sie die Empfänger eines Reports und die zur Verteilung benutzten Funktionen festlegen.
Weitere Informationen siehe:
| Feld | Erklärung |
|---|---|
| Verteilen mittels NOM | |
| Benutzer/Verteiler |
Geben Sie bis zu 10 Benutzerkennungen oder Verteilernamen ein. Wenn der Report erstellt ist, können alle hier angegebenen Benutzer oder Mitglieder der aufgeführten Verteiler auf diesen Report zugreifen, d.h. ihn zeigen, drucken usw. AUTOPRNT - automatisches Ausdrucken von Reports mit
speziellem Layout
Wenn ein Report mit einem speziellen Layout automatisch gedruckt
werden soll, definieren Sie |
| Verteilen mittels CON-NECT | |
| Büro | Geben Sie den Namen eines Con-nect-Büros ein,
in dem der Report-Inhalt als Dokument abgelegt werden soll (optional).
Wenn Sie kein Dokument in einem Benutzer-Büro anlegen, sondern es direkt an Con-nect- Benutzer verteilen möchten, sollten Sie dieses Feld leer lassen und nur das Feld Verteilen an (siehe unten) ausfüllen. In diesem Fall wird der Report in Con-nect in dem eigenständigen Büro namens SYSNOMC abgelegt. |
| Betreff | Geben Sie eine Beschreibung ein, die zusammen mit dem Con-nect-Dokument erscheinen soll. |
| Verteilen an | Wenn Sie den Report direkt an Con-nect-Benutzer verteilen möchten, geben Sie bis zu 10 Benutzer-IDs ein. Eine Kopie des Reports wird in Con-nect in dem eigenständigen Büro namens SYSNOMC abgelegt. Entire Output Management benutzt die Funktion Senden von Con-nect, um den Report an alle in diesen Feldern definierten Con-nect-Benutzer zu verteilen. |
Sie können bis zu 10 Benutzer oder Verteiler auswählen. Wenn der Report erstellt ist, wird er an den Posteingang der ausgewählten Benutzer verteilt. Alle hier mit den hier eingegebenen Benutzerkennungen oder Verteilern verknüpften Benutzer können sich den Report anzeigen lassen und ihn ausdrucken.
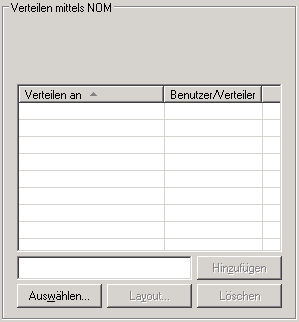
![]() Um einen Benutzer oder Verteiler zum Empfang eines Reports
auszuwählen:
Um einen Benutzer oder Verteiler zum Empfang eines Reports
auszuwählen:
Wählen Sie die Schaltfläche unter .
Das Dialogfenster erscheint im Inhaltsbereich (Beispiel):
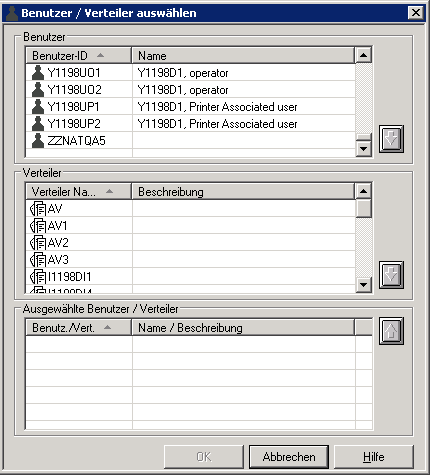
Markieren Sie eine Benutzerkennung oder einen Verteilernamen in der Liste der Benutzer bzw. der Liste der Verteiler.
Wählen Sie die "Nach-Unten"-Taste auf der rechten Seite.
Der ausgewählte Benutzer bzw. Verteiler erscheint im Bereich Ausgewählte Benutzer / Verteiler im unteren Teil des Dialogfensters.
Wählen Sie .
Der ausgewählte Benutzer bzw. Verteiler erscheint jetzt im Bereich .
![]() Um einen Benutzer oder Verteiler von der Liste
zu entfernen:
Um einen Benutzer oder Verteiler von der Liste
zu entfernen:
Markieren Sie einen Eintrag in der Liste.
Wählen Sie die Schaltfläche unterhalb der Liste.
Der ausgewählte Benutzer/Verteiler wird aus der Liste entfernt.
Sie können die Sicht eines Benutzers auf den Report einschränken, indem Sie ein individuelles Report-Layout definieren. In diesem Layout geben Sie an, welche Teile des Reports für den Benutzer sichtbar sein sollen.
Sie können für jeden Empfänger des Reports ein anderes Layout definieren. Wenn der Empfänger ein Verteiler ist, sehen alle Mitglieder dieses Verteilers das definierte Layout.
Anmerkung:
Diese Layouts gelten nur für Empfänger in Entire Output Management.
Empfänger in Con-nect sehen den gesamten Report.
![]() Um ein Layout für einen Benutzer oder Verteiler zu definieren:
Um ein Layout für einen Benutzer oder Verteiler zu definieren:
Markieren Sie den betreffenden Benutzer oder Verteiler.
Wählen Sie die Schaltfläche .
Das Dialogfenster Layout für Benutzer erscheint (Beispiel):
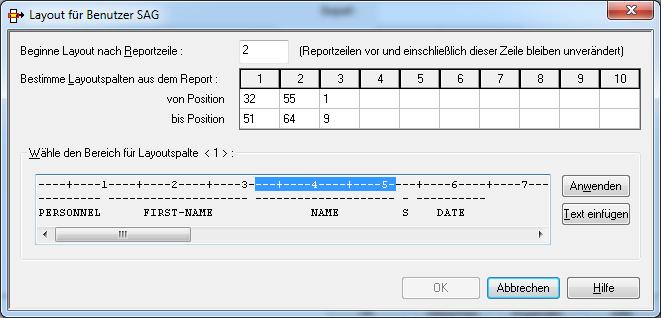
Sie können bis zu 10 verschiedene Spalten aus dem Report festlegen, die für den ausgewählten Benutzer bzw. Verteiler sichtbar sein sollen. Die dafür zur Verfügung stehenden Felder werden im Folgenden beschrieben. Der bzw. die Benutzer sehen dann nur die angegebenen Spalten.
Geben Sie im Feld Beginne Layout nach Reportzeile die Nummer der Zeile (Zählweise ab dem Seitenanfang) ein, ab der die Layout-Definitionen wirksam werden.
Reportzeilen oberhalb und einschließlich dieser Zeile behalten ihr ursprüngliches Format.
Geben Sie in den Feldern von Position und bis Position für jede anzuzeigende Spalte die erste und die letzte anzuzeigende Spalten-Position ein.
Die Positionen werden ab dem Anfang einer Reportzeile gezählt (ausschließlich ASA/Maschinen-Codes).
Die angegebenen Positionen werden im Feld Wähle Bereich für Layoutspalte gezeigt.
Oder:
Markieren Sie eine Spaltennummer (1 bis 10). Markieren Sie dann im
Feld Wähle Bereich für Layoutspalte mit dem Cursor den
gewünschte Bereich für die Layoutspalten, und wählen Sie die Schaltfläche
.
Die so gewählten Positionen werden in den Feldern von Position und bis Position für die Spalte angezeigt.
Um die Orientierung zu erleichtern, können Sie Textzeilen aus dem Original-Report in die Zwischenablage kopieren, und dann die Schaltfläche wählen, um sie in den Anzeigebereich einzufügen. Sie können mehrere Zeilen nacheinander einfügen, d.h. jeweils eine Zeile pro Kopiervorgang.
Wenn Sie alle anzuzeigenden Spalten angegeben haben, wählen Sie .
Wenn ein Report automatisch mit einem speziellen Layout gedruckt
werden soll, definieren Sie AUTOPRNT als Empfänger und verknüpfen
Sie das spezielle Layout mit diesem Empfänger (der Report wird nicht an
AUTOPRNT verteilt). Um diese Funktion zu benutzen, müssen Sie
außerdem einen Benutzer AUTOPRNT definieren.
![]() Um einen Report als ein Dokument in einem Con-nect-Büro zu
erstellen:
Um einen Report als ein Dokument in einem Con-nect-Büro zu
erstellen:
Geben Sie im Feld Büro im Bereich den Namen eines Büros ein.
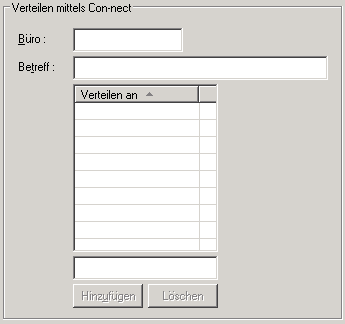
Geben Sie in das Feld Betreff eine Beschreibung ein, die beim Con-nect-Dokument erscheinen soll.
Wählen Sie die Schaltfläche .
Wenn Sie ein Dokument nicht in einem Benutzer-Büro erstellen möchten, es aber direkt an die Con-nect-Benutzer verteilen möchten, sollten Sie dieses Feld leer lassen und nur die Felder Verteilen an ausfüllen (wie nachfolgend beschrieben).
![]() Um einen Report direkt an Con-nect-Benutzer zu verteilen:
Um einen Report direkt an Con-nect-Benutzer zu verteilen:
Geben Sie in das Feld am unteren Rand des Verteilers Verteilen an eine Con-nect-Benutzerkennung ein.
Wählen Sie die Schaltfläche .
Die Benutzerkennung wird in den Verteiler Verteilen an geschrieben.
Sie können bis zu 10 Con-nect-Benutzerkennungen eingeben. Eine Kopie des Reports wird im autonomen Con-nect-Büro mit Namen SYSNOMC erstellt.
Entire Output Management benutzt Con-nect, um den Report an alle in diesen Feldern angegebenen Con-nect-Benutzer zu senden.
Auf der Registerkarte Drucken können Sie festlegen, wie Reports automatisch gedruckt werden.
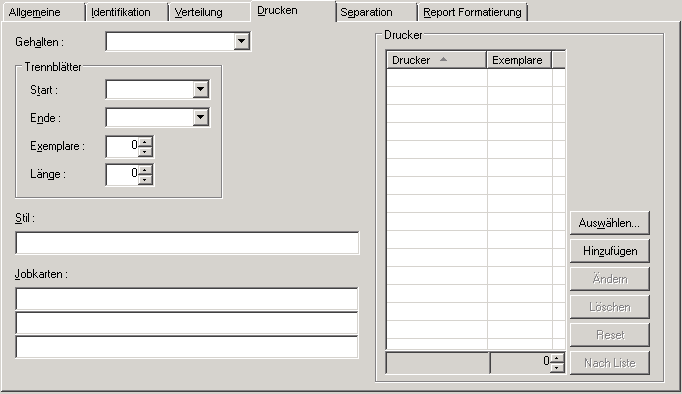
| Feld | Beschreibung | |
|---|---|---|
| Gehalten | Dieses Feld steuert, wie der Report zum Drucken in die Warteschlange gestellt wird. Wählen Sie einen der folgenden Werte aus dem Dropdown-Listenfeld: | |
| (keine) | ||
| Manuell freigeben | Der Report bleibt in der Warteschlange der Druckaufträge, bis er manuell freigegeben wird. | |
| Alle Benutzer bestätigen | Der Report bleibt in der Warteschlange der Druckaufträge, bis er manuell von allen Empfängern bestätigt worden ist. Alle Benutzer im Verteiler erhalten eine Nachricht, mit der sie aufgefordert werden, das Drucken des Reports zu bestätigen. Nachdem alle Benutzer bestätigt haben, wird der Report automatisch zum Drucken freigegeben. | |
| Umgehend freigeben | Der Report wird sofort gedruckt. | |
| Trennblätter | Start | Geben Sie den Namen des Trennblattes ein, das am Anfang des Reports gedruckt werden soll. |
| Ende | Geben Sie den Namen des Trennblattes ein, das am Ende des Reports gedruckt werden soll. | |
| Exemplare | Geben Sie an, wie oft jedes Trennblatt gedruckt werden soll. | |
| Länge | Geben Sie eine Länge für das Trennblatt an, wenn die Länge Ihres Trennblattes größer als die Länge Ihres Reports ist. Die Standard-Länge ist die Länge des Reports. | |
| Weitere Informationen siehe Trennblätter in der Systemverwaltung-Dokumentation. | ||
| Jobkarten |
Geben Sie die Jobkarten an, die beim Drucken mittels Batchjob benutzt werden sollen. Sie können folgende Ersetzungsvariablen verwenden:
Wenn Sie hier keine Jobkarten eingeben, werden die in der Definition des logischen Druckers angegebenen Jobkarten benutzt. |
|
| Drucker | Siehe Drucker für einen Report auswählen weiter unten. | |
![]() Um einen oder mehrere Drucker für einen Report auszuwählen:
Um einen oder mehrere Drucker für einen Report auszuwählen:
Wählen Sie im Abschnitt Drucker des Dialogfensters Angaben zum Drucken die Schaltfläche .
Das Dialogfenster erscheint:
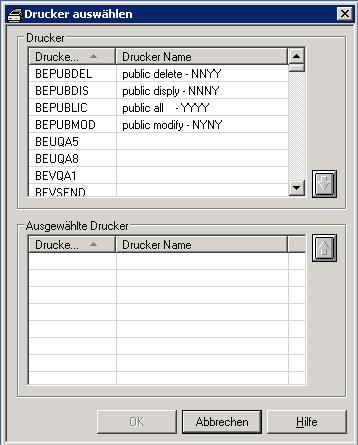
Markieren Sie im Abschnitt Drucker im oberen Teil des Dialogfensters eine Druckerkennung.
Wählen Sie die "Nach-Unten"-Taste auf der rechten Seite.
Die Druckerkennung wird in die Liste der ausgewählten Drucker Ausgewählte Drucker im unteren Teil des Dialogfensters geschrieben.
Wählen Sie .
Der ausgewählte Drucker erscheint jetzt im Abschnitt Drucker der Angaben zum Drucken.
Dieser Abschnitt beschreibt die verschiedenen Trennungsattribute, die unter dem Register Separation zur Verfügung stehen. Im Feld Separation Routine stehen folgende Routinen zur Auswahl:
Die Spool-Datei-Datensätze können über eine mitgelieferte Benutzerroutine satzweise selektiert werden. Mit verschiedenen Aktionskodes kann die Benutzerroutine den Trennungsprozess und die Positionierung innerhalb der Ausgabe steuern und den Inhalt der erstellten Reports bestimmen.
Felder: Benutzer-Separation
| Feld | Beschreibung | |
|---|---|---|
| Separation-Routine | Wählen Sie aus, welche
Benutzer-Routine oder welche Standard-Routine verwendet werden soll.
Anmerkungen:
|
|
| Reportdefinitionen erstellen für aktive Reports durch Separation | Wenn aktive Reports beim Trennen mittels Standard- oder Benutzerroutine dynamisch erzeugt werden, werden normalerweise auch die entsprechenden Report-Definitionen automatisch erstellt. Markieren Sie Nein, , um das automatische Erstellen zu unterdrücken. Dies ist sinnvoll, wenn aktive Reports nur einmalig erstellt werden. | |
| Benutzer-Routine | Diese drei Felder werden zur Definition der Benutzerroutine benutzt, die den Report-Inhalt festlegt: | |
| Natural Programm | Geben Sie den Namen des Natural-Programms ein, das die Benutzerroutine enthält. | |
| Natural Bibliothek | Die Benutzerroutine kann ein
Natural-Subprogramm sein. Sie können den Namen der Natural-Bibliothek eingeben,
die die Benutzerroutine enthält, oder dieses Feld leer lassen. Der
Bibliotheksname darf nicht mit SYS beginnen, es sei denn, es
handelt sich um SYSNOMU.
|
|
| 3GL | Wenn die Benutzerroutine in einer anderen
Sprache als in Natural geschrieben ist, geben Sie den Namen der Routine ein.
Diese Benutzerroutine wird durch ein CALL-Statement
aufgerufen.
|
|
| Parameter | Geben Sie bis zu 5 Parameter ein, die beim Start der Report-Verarbeitung an die Benutzerroutine übergeben werden. | |
Standard-Separation 1 trennt die Spool-Daten in unterschiedliche Reports, je nach dem Gruppenwechsel des angegebenen Suffixes. Das Suffix muss nicht in sortierter Reihenfolge erscheinen. Diese Trennung sucht nach einer definierten Zeichenkette in einer definierten Zeile oder irgendwo auf einer Seite. Wenn die Zeichenkette auf einer Seite erscheint, wird ein Suffix ausgewertet (beim Gruppenwechsel des Suffix-Wertes wird ein neuer Report geöffnet). Wenn die Zeichenkette nicht gefunden wird, wird die Seite zu dem zurzeit geöffneten Report hinzugefügt. Wenn kein Report geöffnet ist, wird die Seite zurückgewiesen.
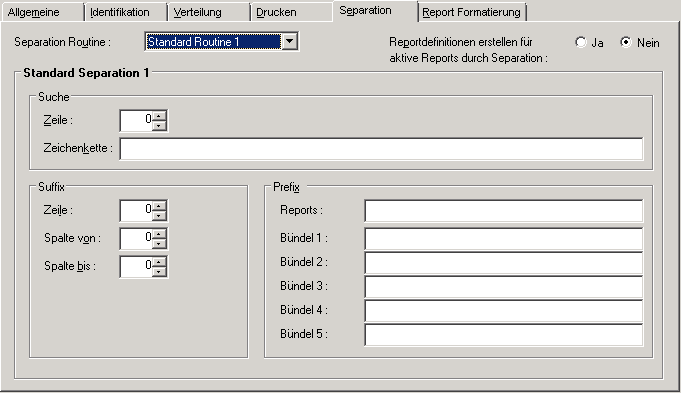
Felder: Standard-Separation 1
| Element | Beschreibung | |
|---|---|---|
| Suche | in Zeile | Geben Sie die Zeilennummer (ab Seitenanfang
gezählt) an, in der die Zeichenkette vorkommen muss. Zählen Sie beim Bestimmen
dieser Zeilennummer auch die Zeilen mit, die nur Vorschubsteuerzeichen
enthalten
Wenn Sie das Feld Suche in Zeile leer lassen, wird die Zeichenkette auf der gesamten Seite gesucht. |
| Zeichenkette | Geben Sie die zu suchende Zeichenkette ein.
Wenn diese Zeichenkette auf einer Seite vorkommt, wird das Suffix ausgewertet
(beim Gruppenwechsel des Suffixwertes wird ein neuer Report geöffnet). Wird die
Zeichenkette nicht gefunden, wird die Seite dem zurzeit geöffneten Report
hinzugefügt. Wenn kein Report geöffnet ist, wird die Seite zurückgewiesen.
Sie können als Zeichenkette beispielsweise angeben: *STRING1*STRING2*
oder: *STRING1%STRING2*
wobei der Stern (*) für eine beliebige Zeichenkette und das Prozentzeichen (%) für ein beliebiges Zeichen steht. Anmerkung: |
|
| Suffix | aus Zeile | Geben Sie die Zeilennummer (ab Seitenanfang
gezählt) an, in der das Report-Suffix vorkommt. Zählen Sie beim Bestimmen
dieser Zeilennummer auch die Zeilen mit, die nur Vorschubsteuerzeichen
enthalten.
Wenn Sie hier nichts angeben, nimmt Entire Output Management an, dass das Suffix im Feld Suche in Zeile steht. |
| Spalte von | Geben Sie die Spalte in der Zeile an, in der das Report-Suffix beginnt (Wertebereich 1-251). Zählen Sie beim Bestimmen der Position auch die Vorschubsteuerzeichen und/oder Tabellennummern mit. | |
| Spalte bis | Geben Sie die Spalte in der Zeile an, in der das Report-Suffix endet (Wertebereich 1-251). Zählen Sie beim Bestimmen der Position auch die Vorschubsteuerzeichen und/oder Tabellennummern mit. | |
| Präfix | Report | Geben Sie das Report-Präfix an, das zum Bestimmen des Reportnamens mit dem Suffix verknüpft wird. Beim Verknüpfen werden die führenden und nachfolgenden Leerzeichen des Suffixes unterdrückt. |
| Bündel | (Optional) Geben Sie das Bündel-Präfix ein,
das zum Bestimmen des Bündelnamens mit dem Suffix verknüpft wird. Beim
Verknüpfen werden die führenden und nachfolgenden Leerzeichen des Suffixes
unterdrückt. Sie können bis zu 5 Bündel angeben.
Um Bündel mit festen Namen zu generieren, füllen Sie dieses Feld vollständig aus. Dann wird kein Suffix angehängt. |
|
Eine Gehaltsliste, die nach Abteilungsnummern sortiert ist, soll nach den verschiedenen Abteilungen getrennt werden. Die Parameter für die Standardroutinen können wie folgt definiert werden, um eine automatische Trennung durchzuführen:
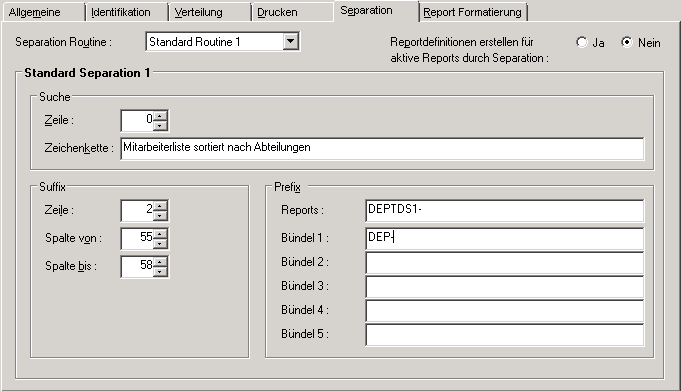
Diese Standardroutine trennt die Spool-Datei auf Seitenbasis und
erzeugt Reports, deren Namen mit DEPTDS1- beginnen. Der Reportname
wird erstellt, indem das Präfix DEPTDS1- mit dem Suffix verknüpft
wird. Das Suffix wird in der Spool-Datei an den im obigen Beispiel definierten
Positionen gefunden, z.B. DEPTDS1-FINA.
Der Report kann wahlweise einem Bündel mit dem Präfix
DEP- zugeordnet werden. Der Bündelname wird erzeugt, indem das
Präfix DEP- mit dem in der Spool-Datei gefundenen Suffix verknüpft
wird, z.B. DEP-FINA.
Anmerkung:
Wenn das Suffix und die identifizierende Zeichenkette nicht in der
gleichen Zeile stehen, müssen die Zeilenparameter benutzt werden. Geben Sie die
Nummern der Zeilen ein, in denen die identifizierende Zeichenkette und das
Suffix zu finden sind. Es müssen absolute Zeilennummern sein, gezählt ab Anfang
der Seite.
Standard-Separation 2 trennt die Spool-Daten in unterschiedliche Reports, in Abhängigkeit von bis zu 5 Gruppenwechsel-Bedingungen. Sie sucht nach einer definierten Zeichenkette in einer definierten Zeile oder irgendwo auf einer Seite. Wenn die Zeichenkette auf einer Seite erscheint, werden bis zu 5 Suffixe ausgewertet (beim Gruppenwechsel eines Suffix-Wertes, wird ein neuer Report für dieses Suffix geöffnet). Wenn keine Zeichenkette gefunden wird, wird die Seite den zurzeit geöffneten Reports hinzugefügt. Wenn kein Report geöffnet ist, wird die Seite zurückgewiesen.
Felder: Standard-Separation 2
| Feld | Beschreibung | |
|---|---|---|
| Suche | in Zeile | Geben Sie die Nummer der Zeile (ab
Seitenanfang gezählt) an, in der die Zeichenkette vorkommen soll. Zählen Sie
beim Bestimmen dieser Zeilennummer auch die Zeilen mit, die nur
Vorschubsteuerzeichen enthalten.
Wenn Sie das Feld Suche in Zeile leer lassen, wird die Zeichenkette auf der gesamten Seite gesucht. |
| Zeichenkette | Geben Sie die zu suchende Zeichenkette ein.
Wenn diese Zeichenkette auf einer Seite vorkommt, wird das Suffix ausgewertet
(beim Gruppenwechsel des Suffixwertes wird ein neuer Report geöffnet). Wird die
Zeichenkette nicht gefunden, wird die Seite dem zurzeit geöffneten Report
hinzugefügt. Wenn kein Report offen ist, wird die Seite zurückgewiesen.
Sie können als Zeichenkette beispielsweise angeben: *STRING1*STRING2*
oder: *STRING1%STRING2*
wobei der Stern (*) für eine beliebige Zeichenkette und das Prozentzeichen (%) für ein beliebiges Zeichen steht. Anmerkung: |
|
| (Suffix)
(In diesen drei Feldern können Sie Parameter für bis zu 5 Suffixe definieren.) |
aus Zeile | Geben Sie die Zeilennummer (ab Seitenanfang
gezählt) an, in der das Report-Suffix vorkommt. Zählen Sie beim Bestimmen
dieser Zeilennummer auch die Zeilen mit, die nur Vorschubsteuerzeichen
enthalten.
Wenn Sie dieses Feld leer lassen, nimmt Entire Output Management an, dass das Suffix im Feld Suche in Zeile steht. |
| Spalte von | Geben Sie die Spalte in der Zeile an, in der das Report-Suffix beginnt (Wertebereich 1-251). Zählen Sie beim Bestimmen der Position auch die Vorschubsteuerzeichen und/oder Tabellennummern mit. | |
| Spalte bis | Geben Sie die Spalte an, in der das Report- Suffix endet (Wertebereich 1-251). Zählen Sie beim Bestimmen der Position auch die Vorschubsteuerzeichen und/oder Tabellennummern mit. | |
| Report-Präfix | Geben Sie das Report-Präfix an, das zum Bestimmen des Reportnamens mit dem Suffix verknüpft wird. Beim Verknüpfen werden die führenden und nachfolgenden Leerzeichen des Suffixes unterdrückt. | |
| Bündel-Präfix |
(Optional) Geben Sie das Bündel-Präfix ein, das zum Bestimmen des Bündelnamens mit dem Suffix verknüpft wird. Beim Verknüpfen werden die führenden und nachfolgenden Leerzeichen des Suffixes unterdrückt. Sie können bis zu 5 Bündel-Präfixe für jedes Suffix angeben. Um Bündel mit festen Namen zu generieren, füllen Sie dieses Feld vollständig aus. Dann wird kein Suffix angehängt. Die Nummer des zurzeit angezeigten Präfixes erscheint hinter der Überschrift Bündel-Präfix. |
|
Eine Gehaltsliste, die nach Abteilungsnummern sortiert ist, soll nach den verschiedenen Haupt- und Unterabteilungen getrennt werden. Die Parameter für die Standardroutine können wie folgt definiert werden, um eine automatische Trennung durchzuführen:
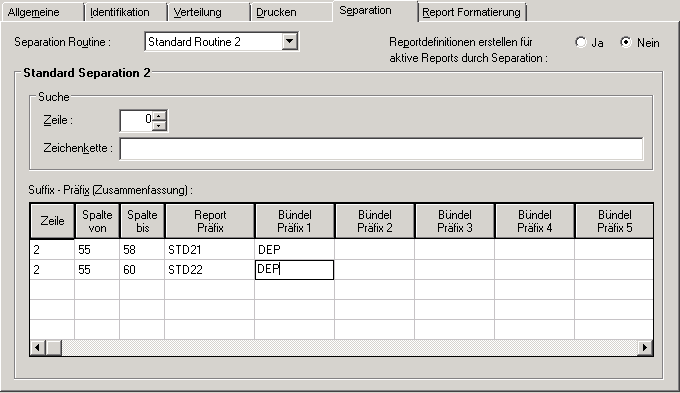
Diese Standardroutine trennt die Spool-Datei auf Seitenbasis und
erzeugt Reports, deren Namen für die Hauptabteilungen mit STD21-
und für die Unterabteilungen mit STD22- beginnen. Der Reportname
wird erstellt, indem das Präfix STD21- mit dem Abteilungsnamen
(Spalten 55 bis 58 in Zeile 2) bzw. das Präfix STD22- mit dem
Unterabteilungsnamen (Spalten 55 bis 60 in Zeile 2) aus den Spool-Daten
verknüpft wird.
Der Report kann wahlweise einem Bündel mit dem Präfix
DEP- zugeordnet werden. Der Bündelname wird erzeugt, indem das
Präfix DEP- mit dem Abteilungs- oder Unterabteilungsnamen
verknüpft wird.
Anmerkung:
Wenn das Suffix und die identifizierende Zeichenkette nicht in der
gleichen Zeile stehen, müssen die Zeilenparameter benutzt werden. Geben Sie die
Nummern der Zeilen ein, in denen die identifizierende Zeichenkette und das
Suffix zu finden sind. Es müssen absolute Zeilennummern sein, gezählt
ab Anfang der Seite.
Standard-Separation 3 sucht nach einer definierten Zeichenkette in einer definierten Zeile. Wenn die Zeichenkette auf einer Seite vorkommt, werden die Zeilen der Seite im Hinblick auf die definierte logische Druckausgabe analysiert. Wenn sie nicht vorkommt, wird die gesamte Seite zurückgewiesen.
Von der Startzeile (Start Filter in Zeile) bis zum Seitenende werden die Zeilen dem Report hinzugefügt, wenn sie der definierten logischen Druckausgabe entsprechen. Zeilen vor der Startzeile werden ebenfalls zurückgewiesen, es sei denn, sie sind als Kopfzeilen definiert.
Felder: Standard-Separation 3
| Feld | Beschreibung | ||
|---|---|---|---|
| Suche | in Zeile | Geben Sie die Nummer der Zeile (ab Seitenanfang gezählt) an, in der die Zeichenkette vorkommen muss. Zählen Sie beim Bestimmen dieser Zeilennummer auch die Zeilen mit, die nur Vorschubsteuerzeichen enthalten. | |
| Zeichenkette | Geben Sie die zu suchende Zeichenkette ein.
Wenn diese Zeichenkette auf einer Seite vorkommt, wird die Seite verarbeitet.
Wenn sie nicht vorkommt, wird die Seite ignoriert.
Sie können als Zeichenkette beispielsweise angeben: *STRING1*STRING2*
oder: *STRING1%STRING2*
wobei der Stern (*) für eine beliebige Zeichenkette und das Prozentzeichen (%) für ein beliebiges Zeichen steht. Anmerkung: |
||
| Kopfzeilen | Geben Sie die Anzahl der Zeilen
(ab Seitenanfang gezählt; Wertebereich 0-20) an, die als Kopfzeilen benutzt
werden sollen. Zählen Sie beim Bestimmen dieser Zeilennummer auch die Zeilen
mit, die nur Vorschubsteuerzeichen enthalten.
Bei Kopfzeilen = 0 werden keine Kopfzeilen hinzugefügt. Ansonsten werden die Kopfzeilen hinzugefügt, wenn eine Seite mindestens eine Zeile enthält, welche die für die Trennung definierte logische Druckausgabe erfüllt. |
||
| Start-Filter in Zeile | Geben Sie die Nummer der Zeile (ab Seitenanfang gezählt) an, in der das Filtern beginnen soll. Die Zeilen vor der hier angegebenen Startzeile werden automatisch nicht in den Report aufgenommen, sofern sie nicht als Kopfzeilen definiert sind. Zählen Sie beim Bestimmen dieser Zeilennummer auch die Zeilen mit, die nur Vorschubsteuerzeichen enthalten. | ||
| AND/OR | Zwei Bedingungen können folgendermaßen logisch verknüpft werden: | ||
| Operator | Bedeutung | ||
AND |
Logische UND-Verknüpfung. | ||
OR |
Logische ODER-Verknüpfung. | ||
| (leer) | Verknüpft die gleiche Variable mit
OR=.
|
||
| Spalte von | Gibt die Position des Operanden an. Geben Sie an, von welcher Spalte bis zu welcher Spalte gefiltert werden soll (Wertebereich 1-251). | ||
| Spalte bis | |||
| Format | Format der Variablen:
|
||
| Logische Operatoren | Logische Vergleichsoperatoren. Mögliche Werte: | ||
| Operator | Bedeutung | ||
EQ,
= |
Gleich. | ||
GE, >=
|
Größer als oder gleich. | ||
GT,
> |
Größer als. | ||
LE,
<= |
Kleiner als oder gleich. | ||
LT,
< |
Kleiner als. | ||
NE,
! |
Ungleich. | ||
| Wert | Geben Sie einen numerischen oder
alphanumerischen Wert oder eine Masken-Definition ein.
Anmerkung: |
||
Aus einer nach Abteilungsnummern sortierten Gehaltsliste sollen folgende Angestellten herausgesucht werden: Geschlecht = M, Personalnummer >= 6000000 und Geburtstag <= 50/01/01 (Unterabteilung COMP12):
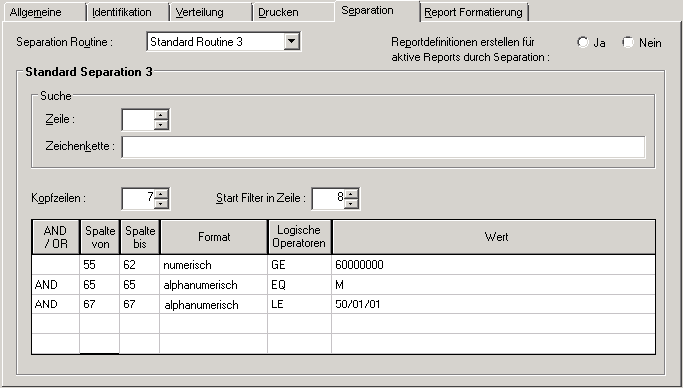
Die Zeilen 1 bis 7 werden als Kopfzeilen genommen. Das Filtern beginnt in Zeile 8.
Aus der CATALL-Liste sollen alle Zeilen mit Fehlernummer ungleich 0 herausgesucht werden:
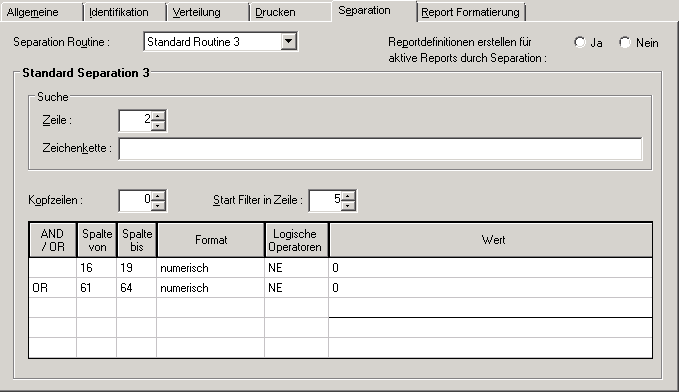
Es werden keine Kopfzeilen hinzugefügt. Das Filtern beginnt in Zeile
5 auf Seiten mit der Zeichenkette - Error Report - in Zeile 2.
Anmerkung:
Die in diesem Abschnitt beschriebene Funktionalität ist noch nicht
verfügbar. Sie wird mit der nächsten Version zur Verfügung gestellt.
Sie können einen Report während des Einlesevorgangs in ein übliches Multimedia-Format konvertieren. Der Original-Report muss im Textformat oder als PDF- oder als PostScript-Datei vorliegen. Falls ein anderes Eingabeformat verwendet werden soll, müssen Sie die Report-Datei in eines der gültigen Formate konvertieren. Dazu haben Sie folgende Möglichkeiten:
Benutzen Sie den Entire Output Management Input-Konverter.
Benutzen Sie die Open Print Option (OPO), um eine beliebige Datei unter Verwendung eines Windows-PostScript-Druckers in PostScript zu konvertieren.
Die Formatierungsparameter werden an die Utilities Enscript bzw. Gostscript übergeben. Dort wird der eingelesene Datenstrom in das gewünschte Format konvertiert, das in Entire Output Management als binärer Report gespeichert werden soll. Falls das Originalformat PDF oder PostScript ist, wird nur das Zielformat berücksichtigt. Die Formatierungsparameter (Enscript) betreffen nur Text-Reports.
Weitere Informationen siehe:
Konvertierung des Report-Formats im Dokument Konzept und Leistungsumfang
DISKUNIX-Drucker in der Systemverwaltung-Dokumentation
Auf der Registerkarte Report-Formatierung können Sie Report-Formatierungsattribute festlegen.
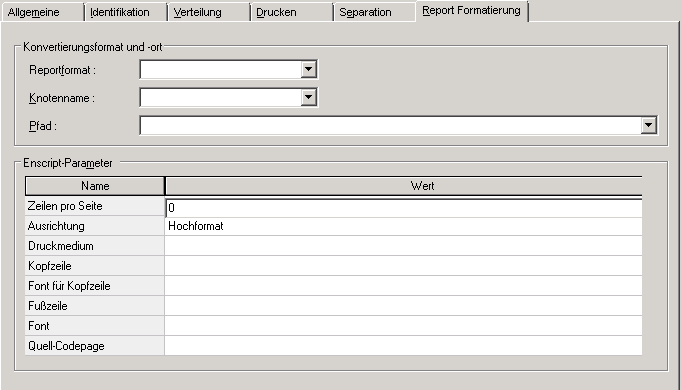
Auf diesem Bildschirm definieren Sie Attribute, die an die Utilities Enscript bzw. Ghostscript übergeben werden. Die ersten drei Attribute müssen Sie, die übrigen können Sie angeben.
| Feld | Beschreibung | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Konvertierungsformat und -ort | Reportformat | Gewünschtes Ausgabeformat (Pflichtfeld). Es stehen vordefinierte Formate zur Verfügung, die den folgenden Ghostscript Devices entsprechen: | ||||||||||||||||||||||
|
||||||||||||||||||||||||
| Falls das Ausgabeformat keinem der
vordefinierten Formate entspricht, wird der Inhalt dieses Feldes als Name eines
<ghostscript device> behandelt, das in der spezifischen Umgebung des
Benutzers vorhanden sein kann. Weitere Informationen siehe
Ghostscript-Dokumentation.
Wenn kein Ausgabeformat angegeben wird, erfolgt keine Dateikonvertierung. |
||||||||||||||||||||||||
| Knotenname | Entire Systems Server-Knotenname gemäß
Definition in den UNIX-Standardwerten. Siehe
Standardwerte
UNIX
Dieser Knoten wird benutzt, um die Dateikonvertierung in das gewünschte Format auszuführen. |
|||||||||||||||||||||||
| Pfad | Pfad, der während der Dateikonvertierung für die temporären Dateien auf dem Konvertierungsknoten benutzt werden soll. | |||||||||||||||||||||||
| Enscript-Parameter (optional) | Zeilen pro Seite | Anzahl Zeilen pro Seite bei einem Text-Report. | ||||||||||||||||||||||
| Ausrichtung | Ausrichtung im Hoch- oder im Querformat erstellen. Falls nicht gefüllt, wird der Report im Hochformat generiert. Wenn Sie ein beliebiges Zeichen eingeben, wird das Querformat benutzt. | |||||||||||||||||||||||
| Druckmedium | Papiergröße für den Druck. Leer: Standard. Gültige Werte: Letter, A4, A5 usw. Weitere Werte siehe Enscript-Dokumentation. | |||||||||||||||||||||||
| Kopfzeile | Name eines "Fancy Header" in
Enscript.
Wird das Feld leer gelassen, wird keine Kopfzeile erzeugt. Bei
Eingabe des Werts |
|||||||||||||||||||||||
| Font für Kopfzeile | Schriftart und Schriftgröße, die für die Kopf-
und die Fußzeile verwendet werden soll.
Beispiel: |
|||||||||||||||||||||||
| Fußzeile | Definition der Fußzeile gemäß Beschreibung in der Enscript-Dokumentation. | |||||||||||||||||||||||
| Font | Schriftart und Schriftgröße, die für den
Report-Text verwendet werden soll.
Beispiel: Wird das Feld leer gelassen, wird die Standard-Schriftart und Schriftgröße verwendet. |
|||||||||||||||||||||||
| Quell-Codepage | Der Zeichensatz des originalen Reports, in dem
der Text-Report gespeichert werden soll.
Beispiele: Wird das Feld leer gelassen, wird standardmäßig
|
|||||||||||||||||||||||
| Additional | In diesem Feld können Sie weitere Enscript-Parameter eingeben. Beschreibung siehe Enscript-Dokumentation. | |||||||||||||||||||||||
| Mask file | Name einer PDF-Maskendatei (mit Pfad), die bei
allen Seiten eines Reports, der im Format PDF vorliegt, überlagert werden kann.
Diese Datei wird auf jeder Seite quasi wie ein Stempel angewendet: Der
ursprüngliche Report erscheint nur an den transparenten Stellen der
PDF-Maskendatei. Auf diese Weise ist es möglich, Firmenzeichen (Logos) oder
Formulare in einen PDF-Report zu integrieren. Falls die PDF-Maskendatei mehr
als eine Seite enthält, werden die jeweils entsprechenden Seiten des
ursprünglichen Reports überlagert. Um die Überlagerungsfunktion benutzen
zu können, muss das PDF Toolkit "pdftk" auf dem
Konvertierungsknoten installiert sein.
Anmerkung: |
|||||||||||||||||||||||