Folgende Themen werden behandelt:
Der Natural Single Point of Development (SPoD) ist die Entwicklungsumgebung für Unicode-Anwendungen.
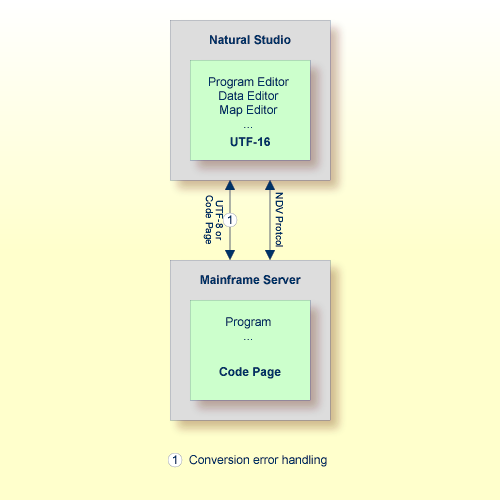
In einer SPoD-Umgebung können die Natural-Objekte, die auf einem Natural Development Server (NDV) liegen, mittels Natural Studio geändert werden. Falls vom Server unterstützt, werden die Quellcode-Objekte im Format UTF-8 zwischen Client und Server ausgetauscht.
Auf NDV-Servern werden die Objekte mit der Standard-Codepage oder
mit ihrer Original-Zeichencodierung gespeichert. Dies ist abhängig von der
Einstellung des Profilparameters SRETAIN.
Wenn der Profilparameter SRETAIN auf
OFF gesetzt ist, werden alle Quellcode-Objekte mit der
Standard-Codepage gespeichert.
Bei dieser Einstellung ist Vorsicht geboten, weil sie zu inkorrekten
Codepage-Informationen führen kann, wenn Sie Quellcode-Objekte haben, die mit
einer früheren Natural-Version erstellt wurden. In diesem Fall ist die
Zeichencodierungsinformation des Quellcode-Objektes nicht zugewiesen und das
Quellcode-Objekt wird immer mit der Standard-Codepage (Wert der Systemvariablen
*CODEPAGE)
geöffnet. Dies wird oft funktionieren, selbst wenn die Standard-Codepage nicht
die korrekte Zeichencodierung des Quellcodes ist. In diesem Fall werden manche
sprachspezifischen Zeichen falsch angezeigt. Wenn ein solches Quellcode-Objekt
mit der falschen Codepage geöffnet wird und wenn beim Speichern der
Profilparameter SRETAIN auf ON gesetzt ist,
dann wird für das Quellcode keine Zeichensatzcodierung gespeichert; das
Quellcode kann später korrekt geöffnet werden, wenn Natural mit der korrekten
Standard-Codepage gestartet wird. Wenn Sie jedoch einmal das Quellcode mit
SRETAIN auf OFF gespeichert haben, wird die
Standard-Codepage als die Zeichencodierung des Quellcodes gespeichert; von da
an wird das Quellcode immer mit dieser Codepage geöffnet.
Deshalb sollten Sie diese Einstellung nur benutzen, wenn Sie sicher sind, dass alle Ihre Natural-Quellcode-Objekte in der Standard-Codepage kodiert sind.
Editoren, die in Natural for Windows sind vollständig Unicode-fähig. Über SPoD können Sie auch für Großrechner-Quellcodee benutzt werden. Die in Natural für Großrechner vorhandenen Editoren sind nicht Unicode-fähig.
Anmerkung:
Die in Natural für Großrechner vorhandenen Editoren bieten
Codepage-Unterstützung. Siehe Codepage-Unterstüzung bei Editoren,
Systemkommandos und Utilities.
Wenn ein Quellcode in einem Editor in Natural Studio (Natural for Windows) geöffnet wird, wird der Inhalt des Quellcodes von der entsprechenden Codepage nach Unicode umgewandelt, bevor es in den Editor geladen wird. Dadurch wird sichergestellt, dass alle Zeichen sogar dann korrekt angezeigt werden können, wenn das Quellcode Zeichen enthält, die in der System-Codepage nicht enthalten sind. Falls die Umwandlung von der Codepage des Quellcodes nach Unicode fehlschlägt, wird ein Fehler angezeigt und der Editor wird nicht geöffnet. In diesem Fall muss der Benutzer die korrekte Zeichencodierung für das Quellcode definieren. Die Quellcode-Zeichencodierung (Encoding) kann im Dialogfenster Properties (Eigenschaften) geändert werden (siehe Properties for the Nodes in der Using Natural Studio-Dokumentation).
Mit dem Programm-Editor in Natural for Windows können Sie Textkonstanten in ihre hexadezimale Unicode-Darstellung umwandeln (siehe Converting to Hexadecimal Format im Kapitel Program Editor der Natural for Windows Editors-Dokumentation). Wenn Sie für eine Plattform entwickeln, auf der Quellcodee im Format UTF-8 nicht bevorzugt werden, können Sie so alle Zeichen für eine Unicode-Konstante eingeben, alle Zeichen der Konstanten auswählen, sie in hexadezimale Darstellung umwandeln und das Präfix "UH" für hexadezimale Unicode-Konstanten hinzufügen. Und wenn Sie den Mauszeiger eine Weile über ein Zeichen oder einen ausgewählten Zeichenbereich einer Textkonstante halten, wird in einem Tool-Tip-Fenster die entsprechende hexadezimale Unicode-Darstellung angezeigt.
Folgende Themen werden behandelt:
Der Programm-Editor, der Masken-Editor (Map Editor) und der
Datenbereich-Editor (Data Area Editor) sind nicht Unicode-fähig. Stattdessen
werden Quellcodee mit Codepage-Informationen gespeichert. Je nach Einstellung
des Profilparameters SRETAIN können
Natural-Quellcode-Objekte mit Codepage-Informationen automatisch von der
aktuellen Codepage des Quellcodes in die Standard-Codepage der aktuellen
Natural-Session (Wert der Systemvariablen
*CODEPAGE)
umgewandelt werden, wenn der Quellcode in den Editor geladen wird. Falls es
Zeichen gibt, die nicht umgewandelt werden können, wird in einem Fenster ein
Codepoint-Konvertierungsfehler angezeigt und die Angabe von Ersatzwerten für
die nicht umwandelbaren Codepoints angefordert. Die Anzeige dieser Meldung ist
unabhängig von der aktuellen Einstellung des Profilparameters
CPCVERR.
In diesem Fall kann sich der Benutzer entscheiden, den Editor mit oder ohne
Umwandlung des Quellcodes in die Standard-Codepage zu öffnen. Beim Speichern
(SAVE) oder Katalogisieren (Kompilieren) und
Speichern (STOW) eines konvertierten Quellcodes wird
die neue Codepage-Information gespeichert. Quellcodes ohne Codepage-Information
(z.B. Quellcodes, die mit einer früheren Natural-Version gespeichert worden
sind), werden ohne Umwandlung in die Editoren geladen. Entsprechend der
Einstellung des Profilparameters SRETAIN wird die
aktuelle Codepage-Information des Quellcodes beibehalten.
Das Einfügen von Quellcodes mittels des Kommandos
.I oder der Split-Screen-Funktion (geteilter
Bildschirm) bewirkt ebenfalls (falls nötig) eine Umwandlung von Quellcodes
entsprechend der Einstellung des Profilparameters
SRETAIN.
Falls es Zeichen gibt, die nicht umgewandelt werden können, wird stattdessen
das definierte Ersatzzeichen eingefügt.
Die Prüfung und Umwandlung des Quellcodes wird durchgeführt, wenn
der Editor gestartet wird, nicht wenn das Programm in den Source-Bereich des
Editors geladen wird. Falls ein Programm mit dem Kommando RUN
program-name ausgeführt wird, erfolgt
keine Umwandlung. Das verursacht ein unterschiedliches Verhalten, je nachdem ob
das Kommando RUN
program-name im
NEXT-Bildschirm oder in einem Editor-Bildschirm eingegeben wird.
Wird RUN program-name im
NEXT-Bildschirm eingegeben, dann erfolgt keine Umwandlung. Wird
das Kommando in einem Editor-Bildschirm eingegeben, wird der Editor unmittelbar
nach der Ausführung des Programms gestartet und es wird eine Umwandlung
durchgeführt.
Die folgende Tabelle zeigt, welche Codepage einer existierenden
Natural Source zugewiesen wird, die gespeichert
(SAVE) oder gespeichert und katalogisiert
(STOW) wird, in Abhängigkeit von den Werten der
Profilparameter SRETAIN und
CP.
| Original-Source-Codepage-Informationen | Einstellung von
SRETAIN |
Source-Codepage-Informationen nach
SAVE oder STOW, wenn
CP auf einen Wert ungleich OFF gesetzt
ist
|
Source-Codepage-Informationen nach
SAVE oder STOW, wenn
CP auf OFF gesetzt ist
|
|---|---|---|---|
| Source ohne Codepage-Informationen |
SRETAIN=ON SRETAIN=(ON,EXCEPTNEW) |
Keine Codepage-Informationen | Keine Codepage-Informationen |
| Source ohne Codepage-Informationen |
SRETAIN=OFF |
Codepage ergibt sich aus der Auswertung
von CP |
Keine Codepage-Informationen |
| Source ist kodiert in code page 1 |
SRETAIN=ON SRETAIN=(ON,EXCEPTNEW) |
Original-Codepage (code page 1) | Original-Codepage (code page 1) |
| Source ist kodiert in code page 1 |
SRETAIN=OFF |
Codepage ergibt sich aus der Auswertung
von CP |
Original-Codepage (code page 1) |
Die folgende Tabelle zeigt, welche Codepage einer neuen Natural
Source zugewiesen wird, die gespeichert (SAVE) oder
gespeichert und katalogisiert (STOW) wird, in
Abhängigkeit von den Profilparametern SRETAIN und
CP.
Einstellung von
SRETAIN |
Source-Codepage-Informationen nach
SAVE oder STOW, wenn
CP auf einen Wert ungleich OFF gesetzt
ist
|
Source-Codepage-Informationen nach
SAVE oder STOW, wenn
CP auf OFF gesetzt ist
|
|---|---|---|
SRETAIN=ON |
Codepage ergibt sich aus der Auswertung
von CP |
Keine Codepage-Informationen |
SRETAIN=OFF |
Codepage ergibt sich aus der Auswertung
von CP |
Keine Codepage-Informationen |
SRETAIN=(ON,EXCEPTNEW) |
Keine Codepage-Informationen | Keine Codepage-Informationen |
Mit dem Systemkommando LIST wird
Quellcode standardmäßig so angezeigt, wie er in der Systemdatei gespeichert
ist, ohne Konvertierung.
Bei Auswahl der Option
CONVERTED des
LIST-Kommandos wird der Quellcode in die
Standard-Codepage (Wert der Systemvariablen
*CODEPAGE)
umgesetzt, falls die Codepage-Informationen des Quellcodes verfügbar sind. Alle
nicht konvertierbaren Zeichen werden dann durch das definierte Ersatzzeichen
ersetzt.
Das Systemkommando
LIST
DIR zeigt die Informationen der verwendeten Codepage
eines Natural-Quellcodes in einem Directory-Fenster.
Ähnlich wie die Editoren wandelt das Systemkommando
SCAN
die Quellcodes um, bevor die aktuelle Suche durch das
SCAN-Kommando ausgeführt wird.
Der Object Handler entlädt oder lädt Quellcodes mit unterschiedlichen Codepage-Informationen und bewahrt die Original-Codepage-Informationen.
Nach Auswahl der Transfer-Format-Option UTF-8 werden Quellcodes
beim Entladen aus einer beliebigen Codepage in das Format UTF-8 umgewandelt und
Informationen über die Original-Codepage in der Arbeitsdatei gespeichert. Die
entsprechende Ladefunktion wandelt den Quellcode zurück in die
Original-Codepage (falls angegeben). Diese Option ermöglicht es auch,
Codepage-Informationen für Quellcodes beizugeben, die mit früheren
Natural-Versionen gespeichert (SAVE) oder
gespeichert und katalogisiert (STOW) worden sind und
deshalb keinerlei Codepage-Informationen enthalten.
Lade- und Entlade-Quellcodes in internem Format behalten die Codepage-Informationen (falls vorhanden).
Die Utility SYSCP (siehe
Debugger und AE-Dienstprogramme-Dokumentation) kann
benutzt werden, um Informationen zu Codepages zu erhalten und die
Codepage-Zuweisung eines Quellcodes zu prüfen oder zu ändern.
Der Natural-Compiler, die Editoren und die Natural-Systemdatei unterstützen keinen Objekt-Quellcode, der in Unicode kodiert ist. Unicode-Konstanten, die in einem Objekt-Quellcode kodiert sind, werden in der Standard-Codepage gespeichert und das katalogisierte Objekt enthält die Unicode-Codepoints. Die einzige Möglichkeit, Unicode-Konstanten zu definieren, die kein Äquivalent in der Standard-Codepage haben, besteht darin, hexadezimale Definitionen (UH) zu benutzen.
Da Natural-Quellcodes vor dem Speichern nicht in Unicode oder UTF-8 umgesetzt werden, können Sie noch von früheren Natural-Versionen gelesen werden. Codepage-Informationen werden im Kopfdatenbereich des Quellcodes gespeichert. Die Codepage-Informationen im Kopfdatenbereich werden einfach ignoriert, wenn auf einen Quellcode mit einer Natural-Version zugegriffen wird, die nicht Unicode-fähig ist.
Der Quellcode dieser Objekte wird nicht im Unicode-Format, sondern in der Standard-Codepage der aktuellen Natural-Session gespeichert. Der Name der Codepage wird im Verzeichnis (Directory) des Quellcodes gespeichert. Deshalb bleibt die Größe des Quellcodes im Vergleich zu früheren Natural-Versionen unverändert. Es erfolgt jedoch eine Prüfung durch den Editor, ob die Codepage des Quellcodes gleich der Standard-Codepage der Natural-Session ist. Falls die Codepages verschieden sind, wird der Quellcode in die Standard-Codepage umgewandelt, wobei es zu Umsetzungsfehlern kommen kann. Wenn ein Zeichen im Quellcode nicht in der Standard-Codepage abgebildet ist, erscheint im Editor ein Fenster, das die manuelle Umwandlung der bei der Umsetzung fehlgeschlagenen Zeichen ermöglicht. Beispiel: Ein Programm, das mit der Codepage IBM01140 erstellt wurde, enthält folgende Zeile:
WRITE '100 €'
Wenn das Programm erneut bearbeitet wird, während Natural mit der Codepage IBM037 läuft, tritt ein Umwandlungsfehler auf, weil das Zeichen "€" in der Codepage IBM037 nicht abgebildet ist.
Zu beachten ist, dass die Umwandlung erfolgt, wenn der Editor gestartet wird, und nicht wenn der Quellcode geladen wird.
Datendefinitionsmodule (DDMs) werden nicht in Unicode-Format, sondern in der Standard-Codepage der aktuellen Nautural-Session gespeichert. Der Name der Codepage wird im Verzeichnis (Directory) des Datendefinitionsmoduls gespeichert. Zu beachten ist, dass es in der Systemdatei kein Datendefinitionsmodul gibt. Im Vergleich zu früheren Natural-Version ist das Datendefinitionsmodul etwas größer. Beim Lesen eines Datendefinitionsmoduls erfolgt eine Prüfung durch den Editor, ob die Codepage des Datendefinitionsmoduls gleich der Standard-Codepage der Natural-Session ist. Falls die Codepages verschieden sind, wird das Datendefinitionsmodul in die Standard-Codepage umgewandelt, wobei es zu Umsetzungsfehlern kommen kann. Wenn ein Zeichen im Datendefinitionsmodul nicht in der Standard-Codepage abgebildet ist, erscheint im Editor ein Fenster, das die manuelle Konvertierung der bei der Umsetzung fehlgeschlagenen Zeichen ermöglicht. Beispiel: Ein Datendefinitionsmodul, das mit der Codepage IBM01140 erstellt wurde, enthält folgende Zeile:
* 100 €
Wenn das Datendefinitionsmodul erneut bearbeitet wird, während Natural mit der Codepage IBM037 läuft, tritt ein Umwandlungsfehler auf, weil das Zeichen "€" in der Codepage IBM037 nicht abgebildet ist.
Natural-Fehlermeldungen werden nicht in Unicode-Format, sondern in
der Standard-Codepage der aktuellen Natural-Session gespeichert. Der Name der
Codepage wird in einem zusätzlichen Adabas-Feld in der Systemdatei gespeichert.
Die Utility SYSERR bietet
die Möglichkeit, zu prüfen, ob die Codepage der Fehlermeldung gleich der
Standard-Codepage der Natural-Session ist. Falls die Codepages verschieden
sind, wird die Fehlermeldung in die Standard-Codepage umgewandelt.
Umsetzungsfehler werden ignoriert. Das bedeutet, es wird das Ersatzzeichen
(oder, falls definiert, das Platzhalterzeichen) verwendet.
Hilfetexte werden immer in der Codepage IBM01140 (English) gepflegt. Es wird keine Codepage-Definition mit gespeichert. Falls die Standard-Codepage nicht IBM01140 ist, wird der Hilfe-Text in die Standard-Codepage umgesetzt. Umsetzungsfehler werden ignoriert. Es wird das Ersatzzeichen (oder, falls definiert, das Platzhalterzeichen) verwendet.