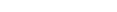
Die Profiler-Utility ist für interaktive (Online-) und Batch-Natural-Anwendungen verfügbar. Interaktive Natural-Anwendungen können auch von NaturalONE profiliert werden, was in der NaturalONE-Dokumentation detailliert beschrieben wird.
Dieses Dokument behandelt die folgenden Themen:
Die Grafik veranschaulicht den Prozessablauf, wenn die Profiler Utility im Online- oder im Batch-Modus Daten verfolgt (Profiler-Tracing).
Die Profiler-Utility basiert, wie in der Grafik dargestellt, auf der Natural Data Collector-Technik. Wenn in einer Natural-Großrechner-Anwendung ein Ereignis wie z. B. ein Programmstart auftritt, ruft der Natural-Nukleus den Natural Data Collector der SYSRDC Utility auf, der die Natural-Ereignisdaten im Natural Data Collector Buffer sammelt und die Ereignisdaten an die User-Exits des Natural Data Collector weitergibt. Die Art und Weise, wie die Ereignisdaten weiterverarbeitet werden, hängt davon ab, in welchem Modus Sie die Profiler Utility ausführen.
Die Grafik wird im folgenden Abschnitt erläutert:
- Profiler Utility im Online-Modus
Die Profiler Utility im Online-Modus ist menübasiert. Sie dient dazu, einen schnellen Überblick über die letzten Aktionen einer interaktiven Natural-Anwendung zu erhalten.
Der Natural Data Collector-Pufferspeicher (Natural Data Collector Buffer) hat eine maximale Größe von 128 KB und arbeitet im Wrap-around-Modus. Er liefert die jüngsten Ereignisse, während die ältesten Daten überschrieben werden, wenn der Puffer voll ist. Die Datensammlung wird gestoppt, wenn die Daten gelesen werden, und der Puffer wird geleert, wenn die Sammlung neu gestartet wird.
Die Profiler-Online-Komponente (Profiler Online Component) liest die Ereignisdaten aus dem Natural Data Collector Buffer. Sie bietet Funktionen zur Steuerung des Profiler-Tracing, zur Auswahl der gewünschten Ereignistypen, zur Pflege und Anzeige von Trace-Datensätzen, zum Herunterladen der Ereignisdaten auf den PC und zum Speichern der Ereignisdaten als Profiler-Ressourcendatei. Die Profiler-Ressourcendatei kann entweder mit den Profiler-Batch-Datenverarbeitungsfunktionen, NaturalONE oder der Profiler Rich GUI-Schnittstelle verarbeitet werden.
- Profiler Utility im Batch-Modus
Die Profiler-Utility im Batch-Modus wird durch JCL-Eingabe gesteuert. Sie wurde für die Analyse von Natural-Batch-Anwendungen entwickelt.
Der User Exit NATRDC1 des Natural Data Collector sammelt die Natural-Ereignisdaten im Profiler-Daten-Pool. Er erweitert den Natural Data Collector-Ereignisdatensatz um zusätzliche Ereignisinformationen und führt spezielle Funktionen wie Filtern oder Sampling (Stichprobentechnik) aus.
Der Profiler-Daten-Pool (Profiler Data Pool) hat eine maximale Größe von 2 GB und sammelt die Natural-Ereignisdaten für die Profiler Utility im Batch-Modus und für den NaturalONE Profiler. Eine spezielle Logik sorgt dafür, dass keine Daten verloren gehen, auch wenn der Pool voll ist.
Die Profiler-Batch-Datensammlung (Profiler Batch Data Collection) liest die Ereignisdaten asynchron aus dem Profiler-Daten-Pool, während die Anwendung und die Ablaufverfolgung (Tracing) weiterlaufen. Sie bietet Funktionen zur Steuerung des Profiler-Tracing, zur Auswahl erforderlicher Ereignistypen, zum Filtern, Entnehmen von Stichproben (Sampling) oder Konsolidieren der Daten, zum Messen der Natural-Codeabdeckung und zum Schreiben der resultierenden Ereignisse in eine Profiler-Ressourcendatei. Allgemeine Statistiken und ein Ereignis-Trace mit den wichtigsten Daten können in die Standardausgabe geschrieben werden.
Die Profiler-Ressourcendatei (Profiler Resource File) hat die Namenserweiterung
.nprf,.nprcoder.ncvfund ist eine Ressource, die abhängig von der Ressource-Library-Auswahl in der Natural-Systemdatei FNAT oder FUSER zugeordnet wird. Sie enthält die Ereignisdaten in komprimiertem Format mit einem um bis zu 80 % verringerten Speicherbedarf. Für eine optimierte Übertragung nach NaturalONE werden die Daten in Datenblöcken zusammengefasst.Während der Profiler-Batch-Datenverarbeitung (Batch Data Processing) liest und verarbeitet der Profiler die Ereignisdaten aus den Profiler-Ressourcendateien. Dabei stehen Funktionen für Datenkonsolidierung (Aggregation), Ereignis-Tracing und Programm-Tracing zur Verfügung. Der Profiler bietet außerdem eine Programmzusammenfassung, eine Zeilenzusammenfassung und eine Transaktionszusammenfassung und zeigt Profiler-Eigenschaften und -Statistiken an. Für die Natural-Codeabdeckungsdaten werden Programm- und Statement-Abdeckungsreports bereitgestellt. Die resultierenden Daten können in eine Datei im Text- oder CSV-Format (kommagetrennte Werte) exportiert werden.
In der Natural Server-Ansicht von NaturalONE werden die Profiler-Ressourcendateien als NPRF- oder NPRC-Ressourcen aufgelistet. Die Kontextmenüfunktion Open with Natural Profiler liest die Ressourcendaten in den NaturalONE Profiler. Der NaturalONE Profiler bietet die allgemeine Analyse der Ereignisdaten. Sie zeigt, wie sich die CPU-Zeit oder die verstrichene (elapsed) Zeit auf die Programme, Statements und sogar Programmzeilen der Anwendung verteilt und wie oft ein Statement ausgeführt wurde. Zusätzlich wird der vollständige Ereignis-Trace bereitgestellt.
Codeabdeckungs-Ressourcedateien (Coverage Resource Files, NCVF) können aus der NaturalONE Server-Ansicht zu einem Projekt im NaturalONE-Arbeitsbereich hinzugefügt werden. Die Kontextmenüfunktion Open with Natural Code Coverage liest die Ressourcendaten und zeigt sie in der Code Coverage-Ansicht an.
Von der NaturalONE Code Coverage-Ansicht aus kann der Natural Source Editor geöffnet werden. Er zeigt alle Quellcodezeilen mit einem oder mehreren abgedeckten Statements mit grünem Hintergrund.
Über die NaturalONE Tools and Utilities kann die Profiler Rich GUI-Schnittstelle gestartet werden. Sie listet alle Profiler-Ressourcen der gegebenen Library auf. Für eine ausgewählte Profiler-Ressource werden die Eigenschaften und Statistiken der Profil-Erstellung angezeigt. Das Tool bietet Funktionen zur Datenkonsolidierung und -auswertung, zur Analyse überwachter Programme oder zum Löschen einer Profiler-Ressourcendatei. Für die Auswertung werden Kreisdiagramme verwendet, um die Verteilung der Profiler-Leistungskennzahlen (KPIs, Key Performance Indicators) für ausgewählte Kriterien wie die Verteilung der CPU-Zeit für Programme anzuzeigen. Zusammengefasste Summen der KPI-Werte werden ebenfalls angezeigt. Für die Programmanalyse wird der Quellcode der überwachten Programme mit den Profiler-Daten kombiniert, wobei der Quellcode entsprechend dem Wert des ausgewählten KPI farblich hinterlegt wird.
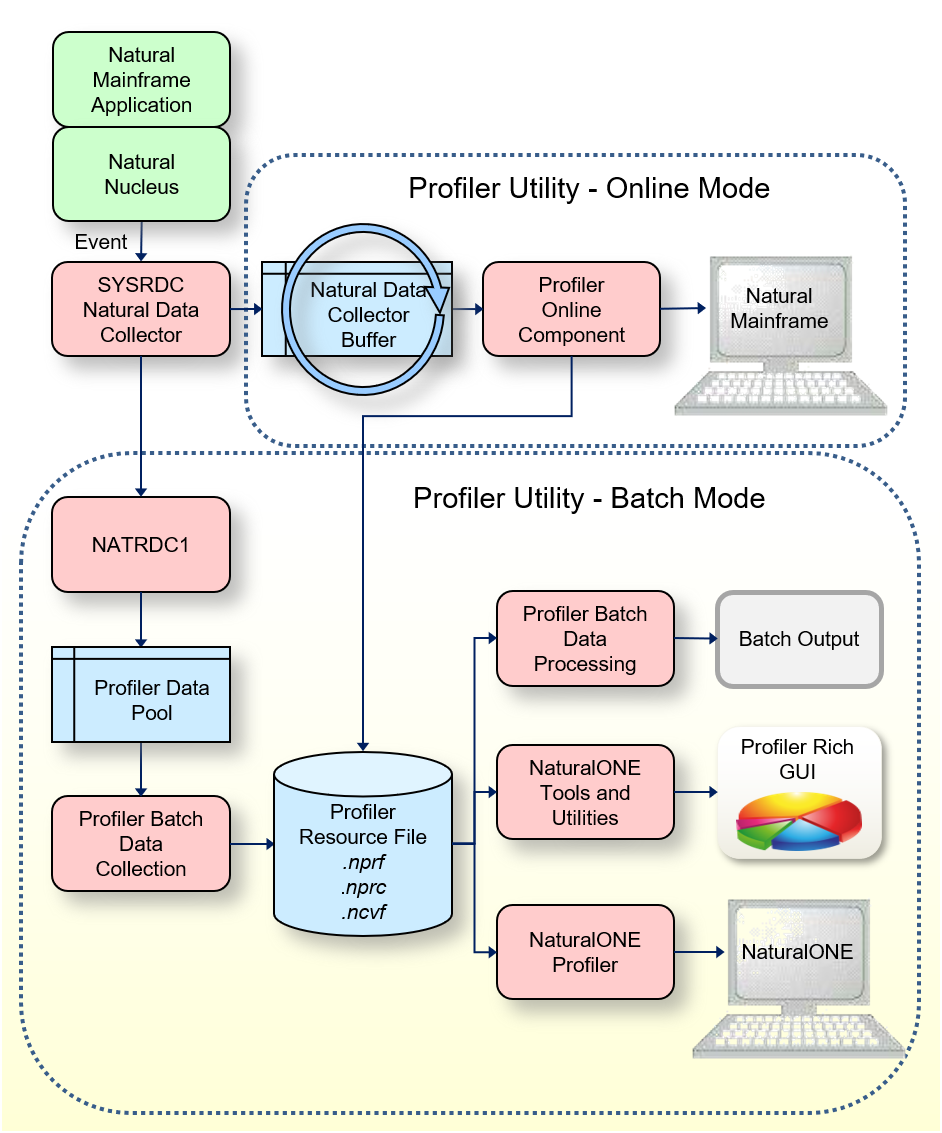
Diese Grafik zeigt, welche Aktionen die Profiler Utility bei der Profil-Erstellung einer Natural-Anwendung im Batch-Modus ausführt.
Die Natural-Trace-Session ist die Sitzung, in der die Natural Batch-Anwendung ausgeführt und die Profiler-Trace-Daten generiert und gesammelt werden.
Wenn die Funktion INIT der Profiler Utility
ausgeführt wird, wird eine neue Natural-Session als asynchroner Subtask
gestartet. Diese Session wird als Monitor-Session bezeichnet, weil sie die
Ereignisse überwacht. In beiden Sessions läuft eine Natural-Nukleus-Instanz mit
einem verlinkten NATRDC1-Exit. Die INIT-Funktion löst die
Ausführung der Profiler Utility in der Monitor-Session aus und leitet die
INIT-spezifischen Schlüsselwörter an sie weiter.
In der Monitor-Session wird die Profiler-Ressourcendatei erstellt, in der die Ereignisse später gespeichert werden. Dann wird der Exit NATRDC1 aufgerufen, um die Monitor-Session zu initialisieren. NATRDC1 ordnet den Profiler-Daten-Pool zu, der verwendet wird, um die Ereignisdaten von der Trace-Session in die Monitor-Session zu übertragen. Er initialisiert auch die Entnahme von Stichproben (Sampling) und legt Standardwerte für Filter fest.
Wenn der Profiler in der Trace-Session feststellt, dass die Monitor-Session erfolgreich initialisiert wurde, ruft er den NATRDC1-Exit auf, um die Trace-Session zu initialisieren. Standardmäßig wird die Datensammlung nach der Initialisierung angehalten.
Nach der Initialisierung können die Profiler-Filter eingestellt werden. Dies sollte durchgeführt werden, bevor die Datensammlung gestartet wird, damit die Filter gleich zu Beginn einsatzbereit sind.
Die Datensammlung beginnt mit der START-Funktion.
Der Profiler in der Trace-Session sendet eine Startanforderung an den Exit
NATRDC1, der die Ereignisse der nachfolgenden Natural-Anwendungen im
Profiler-Daten-Pool sammelt. Gleichzeitig ruft der Profiler in der
Monitor-Session den Exit NATRDC1 auf, um die Ereignisdaten aus dem
Profiler-Daten-Pool zu lesen. Der Speicherplatz der Ereignisdaten wird sofort
freigegeben, so dass die Trace-Session ihn wiederverwenden kann. Der Profiler
in der Monitor-Session komprimiert die Ereignisdaten und schreibt sie in die
Profiler-Ressourcendatei.
Mit der PAUSE-Funktion kann die Datensammlung
angehalten werden. Der Profiler sendet in der Trace-Session eine
Pausenanforderung an den Exit NATRDC1, der ein MP-Ereignis
(Monitor Pause) in den Profiler-Daten-Pool schreibt und die Datensammlung
aussetzt, d.h. er lehnt alle Ereignisse ab, bis eine Startanforderung empfangen
wird oder die Trace-Session endet.
Am Ende der Anwendung wird ein ST-Ereignis (Session
Termination) in den Profiler-Daten-Pool geschrieben. Die Trace-Session wird
jedoch nicht sofort beendet (was den Subtask der Monitor-Session abbrechen
würde). Stattdessen wartet sie, bis die Monitor-Session die verbleibenden Daten
aus dem Profiler-Daten-Pool liest. Wenn der Profiler in der Monitor-Session das
ST-Ereignis im Profiler-Daten-Pool findet, schließt er die
Profiler-Ressourcendatei, schreibt die Statistikdaten und sendet eine
Beendigungsanforderung an den Exit NATRDC1, der die Monitor-Session beendet.
Zuletzt wird auch die Trace-Session beendet.
Bei der Profiler Utility werden Techniken verwendet, die mit dem
NaturalONE Profiler eingeführt wurden, wie z. B. der User Exit NATRDC1 und der
Profiler-Daten-Pool. Daher ist die Verarbeitung der Ereignisdaten auf
NaturalONE-Benutzer beschränkt, die den NaturalONE Profiler und die Profiler
Utility zur Auswertung der Ereignisdaten verwenden können. Die
Datenkonsolidierungs- und Verarbeitungsfunktionen der Profiler Utility
(CONSOLIDATE, READ, LIST und
DELETE) müssen aktiviert werden, bevor sie verwendet werden
können. Die Aktivierung ist unter Voraussetzungen
beschrieben.
Dieser Abschnitt behandelt die folgenden Themen:
Wenn eine Natural-Anwendung profiliert wird, sammelt der Natural Profiler für jedes Ereignis einen Datensatz. Je nach Anwendung kann dies riesige Datenmengen erzeugen, insbesondere wenn Natural-Statements überwacht werden. Je mehr Daten der Profiler generiert, desto mehr Zeit wird benötigt, um die Daten vom Server zum NaturalONE-Client zu transportieren.
Die Profiler Utility und die Profiler Rich GUI-Schnittstelle
bieten eine serverseitige Datenkonsolidierung, die die Datenmenge erheblich
reduziert und gleichzeitig den Transportfluss erhöht. Die
Profiler-Datenkonsolidierung kombiniert ähnliche Datensätze in einem
konsolidierten Datensatz mit aggregierten Zeitwerten und einem Trefferzähler.
Die konsolidierten Daten werden in eine Ressourcendatei geschrieben, die den
gleichen Namen wie die entsprechende nicht konsolidierte Ressourcendatei hat,
aber die Erweiterung .nprc (Natural Profiler resource
consolidated).
Während der Profil-Erstellung können die Daten
sofort konsolidiert werden, indem das Schlüsselwort CONSOLIDATE
der INIT-Funktion der Profiler Utility aktiviert
wird. Nicht konsolidierte Daten einer NPRF-Datei können
später mit der Profiler Utility oder der Profiler Rich GUI-Schnittstelle
CONSOLIDATE-Funktion konsolidiert werden.
Ein Natural-Statement wird 1000 Mal in einer
FOR-Schleife ausgeführt. Die nicht konsolidierten Daten enthalten
1000 Datensätze für jede Ausführung des Statement. Jeder Datensatz enthält
neben anderen Informationen die Ereigniszeit und den CPU-Zeitstempel. Die
Profiler-Konsolidierung fasst diese 1000 Datensätze zu einem konsolidierten
Datensatz zusammen. Alle gemeinsamen Informationen (z.B. die Library oder der
Programmname) werden beibehalten, die verstrichene (elapsed) Zeit und die
CPU-Zeit jeder Ausführung des Statement werden bestimmt, zusammengefasst und im
Konsolidierungsdatensatz gespeichert. Darüber hinaus wird eine Trefferzahl von
1000 aufgezeichnet.
Anmerkungen:
Die Natural-Codeabdeckung wird verwendet, um ausgeführte und
nicht ausgeführte Statements einer Natural-Anwendung zu überwachen. Sie wird
durch Einschalten des Schlüsselworts COVERAGE der
INIT-Funktion der Profiler Utility gestartet.
Für die Codeabdeckung verwendet der Profiler automatisch einen
Ereignisfilter, so dass nur die Ereignisse "Programmstart"
(PS) und "Natural Statement" (NS)
gesammelt werden. Darüber hinaus enthalten die Statement-Ereignisse in diesem
Fall einen GP-Offset, der benötigt wird, um das Statement eindeutig zu
identifizieren.
Für jedes aufgerufene Programm wird das entsprechende katalogisierte Programm (GP = Generated Program) gelesen und die Statement-Tabelle gebaut, die die Zeilennummer, den GP-Offset, den Objektcode und die Copycode-Informationen des Statement enthält. Darüber hinaus wird eine invertierte Liste von GP-Offsets für die schnelle Suche nach dem Offset erstellt.
Während die Anwendung läuft, wird der GP-Offset zu jedem ausgeführten Statement in der Statement-Tabelle gesucht und als abgedeckt markiert. Schließlich werden die abgedeckten Statements und die nicht abgedeckten Statements (die nicht markiert worden sind) in eine Natural-NCVF-Ressourcendatei geschrieben.
Wenn die NCVF-Abdeckungsressourcendatei mit der Profiler
READ-Funktion analysiert wird, wird der Quellcode der überwachten
Programme gelesen und die Zeilen werden entsprechend der Abdeckung der
Statements in der Zeile markiert.
Anmerkung:
Die Natural-Codeabdeckung ist nicht für Programme vorgesehen,
die mit dem Natural Optimizer
Compiler (NOC) katalogisiert wurden.
Die folgende Grafik zeigt, wie die Profiler Utility nicht konsolidierte und konsolidierte Daten verarbeitet:
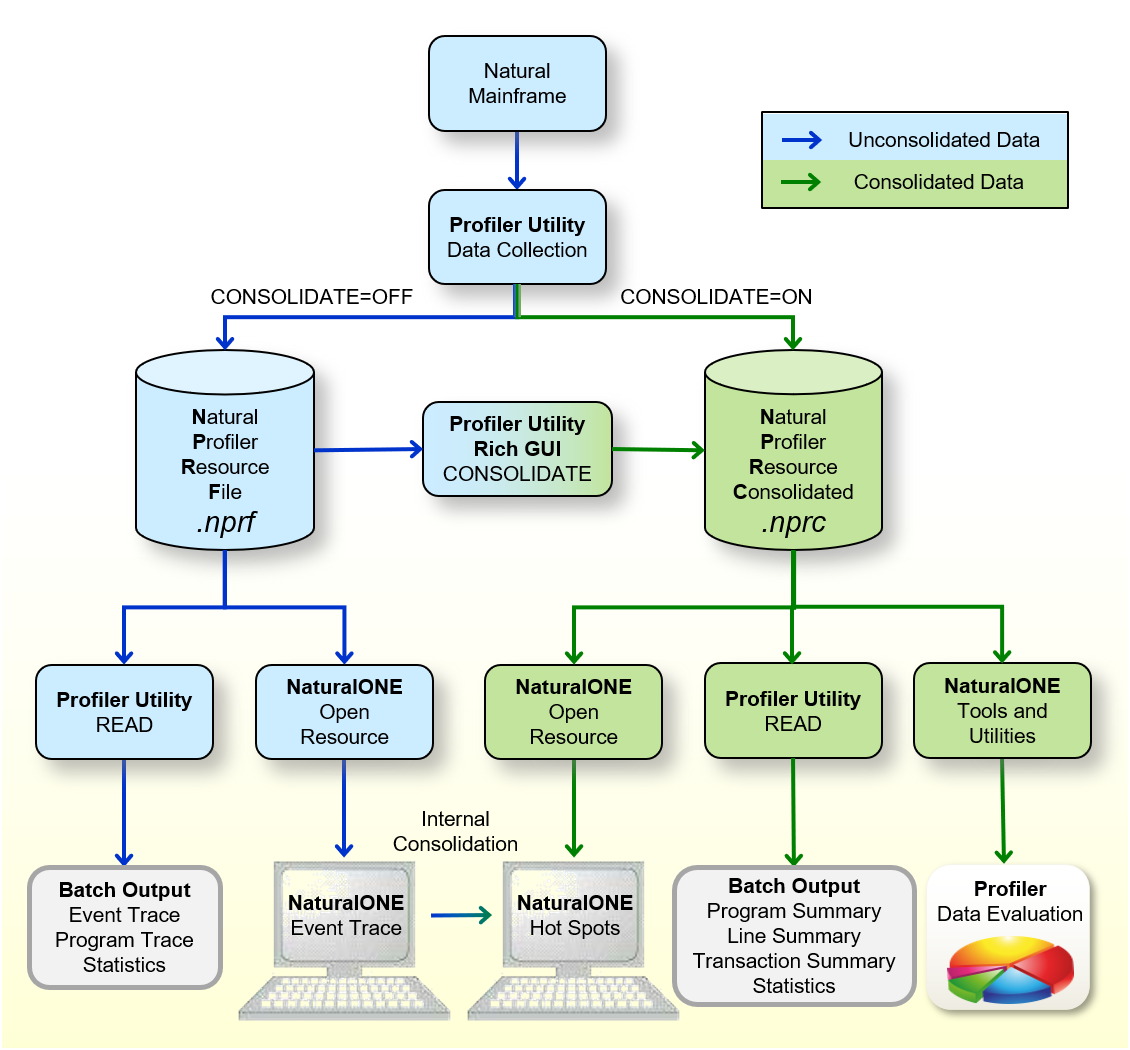
Die Grafik wird im folgenden Abschnitt erläutert:
Wenn eine Großrechner-Natural-Batch-Anwendung mit der
Datensammlung der Profiler Utility profiliert wird, werden die resultierenden
Ereignisdaten, abhängig von der Einstellung des
CONSOLIDATE-Schlüsselworts der INIT-Funktion der
Profiler Utility, in eine Natural Profiler-Ressourcendatei (NPRF) oder eine
konsolidierte Natural Profiler-Ressourcendatei (NPRC) geschrieben.
Die Natural Profiler-Ressourcendatei (Erweiterung
.nprf) enthält die Ereignisdaten in einem nicht konsolidierten
Format, was bedeutet, dass es für jedes Ereignis einen Datensatz gibt.
Die READ-Funktion der Profiler Utility liest die
Ereignisdaten aus der NPRF-Ressourcendatei. Sie bietet ein Ereignis-Trace, ein
Programm-Trace und die Profiler-Statistiken. Die resultierenden Daten können in
eine Datei im Text- oder CSV-Format (kommagetrennte Werte) exportiert
werden.
Wenn die NPRF-Ressourcendatei von NaturalONE aus geöffnet wird, werden die nicht konsolidierten Ereignisdaten auf der NaturalONE Event Trace-Seite aufgelistet.
Die NaturalONE Hot Spots-Seite zeigt die Ereignisdaten in konsolidierter Form an. Wenn die Daten aus einer NPRF-Ressourcendatei stammen, konsolidiert NaturalONE die Daten intern.
Die CONSOLIDATE-Funktion der
Profiler Utility und die Profiler Rich GUI-Schnittstelle liest die
Ereignisdaten aus der NPRF-Ressourcendatei, konsolidiert sie und schreibt sie
in eine NPRC-Ressourcendatei.
Die konsolidierte Natural Profiler-Ressourcendatei
(Erweiterung .nprc) enthält die Ereignisdaten in einem
konsolidierten Format, was bedeutet, dass ähnliche Datensätze in einem
konsolidierten Datensatz aggregiert werden. Im Allgemeinen ist eine
NPRC-Ressourcendatei viel kleiner als die entsprechende NPRF-Ressourcendatei
und daher viel schneller zu verarbeiten.
Wenn die NPRC-Ressourcendatei von NaturalONE aus geöffnet wird, werden die konsolidierten Ereignisdaten auf der Hot Spots-Seite angezeigt. Es ist nicht möglich, das Ereignis-Trace anzuzeigen, da die NPRC-Ressourcendatei nicht die Daten jedes einzelnen Ereignisses enthält.
Die READ-Funktion der Profiler-Utility liest die Ereignisdaten aus der NPRC-Ressourcendatei. Sie liefert ein Trace der konsolidierten Datensätze, eine Programmzusammenfassung, eine Zeilenzusammenfassung, eine Transaktionszusammenfassung und Profiler-Statistikdaten. Die resultierenden Daten können in eine Datei im Text- oder CSV-Format (kommagetrennte Werte) exportiert werden.
Die Profiler Rich GUI-Schnittstelle (gestartet mit NaturalONE Tools and Utilities) visualisiert die Profiler-Ereignisdaten und Statistiken in einer grafischen, interaktiven Browser-Oberfläche.
Allgemein werden Profiler in ereignisbasierte oder statistische Profiler eingeteilt. Statistische Profiler, die mittels Stichproben (Sampling) arbeiten, unterbrechen das Betriebssystem in regelmäßigen Abständen, um die Profiling-Daten zu erhalten. Die resultierenden Daten sind nicht genau, sondern eine statistische Annäherung.
Der Natural Profiler ist ein ereignisbasierter Profiler. Er erhält die Kontrolle und sammelt die Profiling-Daten, wenn ein Natural-Ereignis eintritt. Obwohl der Natural Profiler das Betriebssystem nicht unterbricht, bietet er eine Stichprobentechnik, die die gleichen Profilierungsdaten wie statistische Profiler generiert.
Das Natural Profiler Sampling funktioniert wie ein Filter: Es eliminiert alle Ereignisse außer dem letzten in einem Stichprobenintervall. Darüber hinaus ersetzt es den CPU-Zeitstempel des Ereignisses durch die nachfolgende Abtastzeit. Auf diese Weise sammelt der Natural Profiler nur die Ereignisse, die zu Beginn eines Stichprobenintervalls aktiv waren.
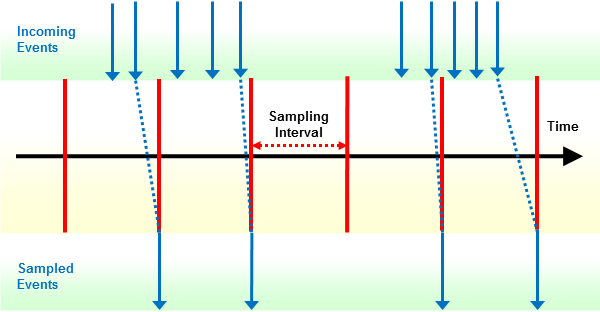
Bei Verwendung des Natural Profiler Sampling ist Folgendes zu beachten:
Die Stichprobentechnik des Natural Profiler Sampling bietet eine gute Schätzung der verbrauchten CPU-Zeit. Es liefert keine anderen Schätzungen wie Trefferzahlen, verstrichene (elapsed) Zeiten und Adabas-Zeiten.
Das Natural Profiler Sampling ist ein statistischer Ansatz, der die Anzahl der Ereignisse mit fast den gleichen CPU-Zeitergebnissen stark reduziert.
Je kleiner das Stichprobenintervall, desto genauer das Ergebnis.
Je größer das Stichprobenintervall, desto weniger Daten werden produziert.
Die resultierende Ereignisdauer ist ein Vielfaches des Stichprobenintervalls.
Die Stichprobentechnik generiert höchstens einen Datensatz pro Stichprobenintervall.
Ereignisse, die mehr Zeit als ein Stichprobenintervall verbraucht haben, benötigen nur einen Datensatz.
Das Ereignis der Sitzungsbeendigung (ST, Session
Termination) wird unverändert aufgezeichnet.
Wenn die gesamte CPU-Zeit der Anwendung bekannt ist und Stichprobentechnik verwendet wird, kann die Anzahl der Ereignisse geschätzt werden:
Anzahl der Ereignisse
≈ |
|
In der folgenden Beispielanwendung ruft das Programm
XPROF drei Subprogramme auf. Die Anwendung wird zweimal
profiliert:
Ohne Stichprobennahme.
Mit Stichprobennahme, wobei ein Stichprobenintervall von 100 Mikrosekunden verwendet wird.
Für die Stichprobennahme werden die folgenden Schlüsselwörter mit
der INIT-Funktion der Profiler Utility angegeben:
FUNCTION=INIT /* Initialize Profiling SAMPLING=ON /* Use sampling INTERVAL=100 /* Microseconds
Die unten aufgeführten, mit der Natural Profiler Rich GUI-Schnittstelle erzeugten Kreisdiagramme zeigen für jedes Programm den Namen des Programms, die aufgewendete CPU-Zeit (Einheit: Millisekunden) und den CPU-Zeitprozentsatz in Bezug auf die gesamte CPU-Zeit. Das linke Diagramm spiegelt den Lauf ohne Stichprobennahme (Without Sampling) und das rechte Diagramm den Lauf mit Stichprobennahme (Sampling) wider. Obwohl das Sampling die Anzahl der Ereignisse von 240.086 auf 4.664 reduzierte, sind die resultierende CPU-Zeit und -verteilung fast gleich.
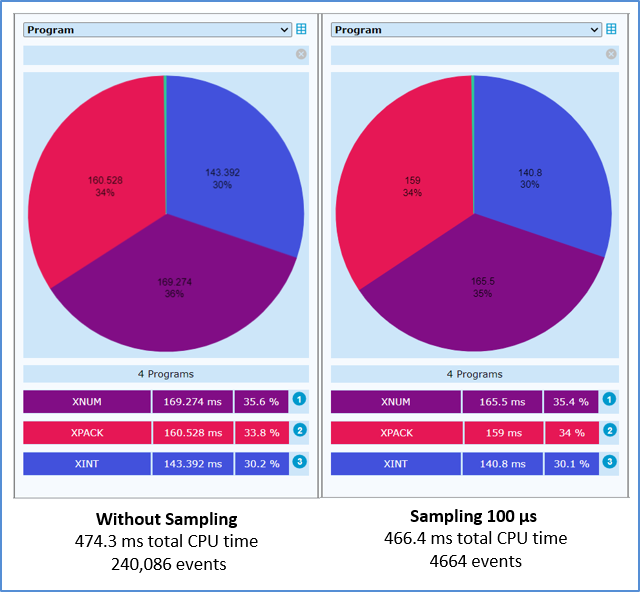
Das Profilieren einer Anwendung wirkt sich in der Regel auf die Performance (Laufzeitverhalten) der Anwendung aus. Die Auswirkungen können die Messung und die Gesamtdauer des Jobs betreffen. Im Natural Profiler sind mehrere Funktionen implementiert, um die Messung so genau und den Performance-Verlust so gering wie möglich zu halten.
Die Profiler-Monitor-Session, die die Daten aus dem Profiler-Daten-Pool liest und in die Profiler-Ressourcendatei schreibt, läuft als asynchroner Task. Die für die Monitor-Session aufgewendete Zeit wird daher bei der Anwendungszeitmessung nicht berücksichtigt. Da die Profiler-Trace-Session jedoch am Ende warten muss, bis die Monitor-Session beendet ist, kann sie sich auf die Gesamtdauer des Jobs auswirken.
Der NATRDC1-Exit, der in der Profiler-Trace-Session läuft, misst die für das Zusammenstellen des Trace-Datensatzes benötigte CPU-Zeit separat und subtrahiert sie von der CPU-Zeit der Session.
Wenn Natural-Statement-Ereignisse mit der
Ereignisfiltereinstellung STATEMENT=ON gesammelt werden,
deaktiviert der Profiler die Generierung von Statement-Ereignissen im
Natural-Nukleus, solange ein Blockfilter (Library, Programm, Zeile, FNAT,
Ereignisanzahl oder Zeitfilter) aktiv ist. Dies reduziert die Belastung des
Natural-Nukleus, des SYSRDC
Data Collector und schließlich des Exit NATRDC1, der andernfalls das Ereignis
ablehnen würde.
Der Profiler komprimiert die Ereignisdaten, bevor er sie in die Ressource schreibt. Durch die Komprimierung kann bis zu 80 Prozent des Bedarfs an Datenspeicherplatz eingespart werden, was die Anzahl der E/A-Vorgänge drastisch reduziert. Die Ereignisdaten werden auch von NaturalONE im komprimierten Format gelesen, was die Transportflussrate erhöht.
Bei der Ausführung auf einem z/OS-Rechner mit zIIP (IBM System z Integrated Information Processor) geht Zeit verloren, wenn die Ausführung vom Allzweckprozessor (GCP, General Central Processor) zum zIIP wechselt und umgekehrt. Wenn Sie Natural for zIIP mit dem Profiler verwenden, läuft der NATRDC1-Exit auf dem zIIP mit einer minimalen Anzahl von Umschaltungen.
Wenn der Profiler-Daten-Pool voll ist, wartet die Profiler-Trace-Session eine Sekunde, damit die Profiler-Monitor-Session etwas Speicherplatz lesen und freigeben kann. Wenn der Daten-Pool zu klein ist, kann es vorkommen, dass die Profiler-Monitor-Session alle Daten liest, bevor die Trace-Session neu gestartet wird. Wenn die Monitor-Session keine Daten im Daten-Pool findet, wartet sie eine Sekunde auf neue Daten. Jetzt warten beide Sitzungen abwechselnd, was die Gesamtdauer des Jobs stark erhöht.
Die Eigenschaft Data pool empty after full
(Daten-Pool leer nach voll) in der Kategorie Trace Session
der Profiler-Statistik zeigt solche abwechselnden Wartezeiten an. Wenn der Wert
dieser Eigenschaft größer als Null (0) ist, müssen Sie den
Natural-Profilparameter PDPSIZE auf einen
entsprechenden Wert erhöhen.
PDPSIZE=50000
Das Profilieren einer langlaufenden Batch-Anwendung kann eine riesige Datenmenge erzeugen, insbesondere wenn Natural-Statements überwacht werden.
In diesem Abschnitt wird beschrieben, wie Sie die Anzahl der zu überwachenden Ereignisse minimieren und dabei wesentliche Informationen beibehalten können:
Wenn der Batch-Job mehrere Natural-Anwendungen startet, initialisieren und starten Sie den Profiler unmittelbar vor der ersten Anwendung von Belang. Sobald der Profiler initialisiert ist, wirkt er sich auf die Performance aus, auch wenn keine Ereignisse gesammelt werden.
Pausieren Sie den Profiler für Anwendungen, die nicht von Belang sind, und starten Sie ihn für die nächste Anwendung von Belang neu.
Verwenden Sie eventuell die Anwendungsprogrammierschnittstelle (API) USR8210N, um die Profil-Erstellung an bestimmten Stellen in der Anwendung zu starten und anzuhalten. Siehe auch Anwendungsprogrammierschnittstelle USR8210N benutzen.
Ein Job führt drei Natural-Anwendungen aus. Von diesen drei Anwendungen ist nur die zweite für eine Profiler-Analyse von Belang.
Initialisieren und starten Sie die Profil-Erstellung unmittelbar vor Beginn der Ausführung der zweiten Anwendung und pausieren Sie die Profil-Erstellung direkt nach der Ausführung, wie im folgenden Beispiel:
APP-01 PROFILER FUNCTION=INIT,... /* Initialize profiling FUNCTION=START /* Start data collection END-PROFILER /* End Profiler input APP-02 PROFILER FUNCTION=PAUSE /* Pause data collection END-PROFILER /* End Profiler input APP-03 FIN /*
Auf diese Weise hat die Profil-Erstellung keinen Einfluss auf die Performance der anderen Anwendungen.
Verwenden Sie den Ereignisfilter FNAT=OFF, um die
Überwachung von Natural-Systemprogrammen zu vermeiden, oder geben Sie das
Schlüsselwort FNAT überhaupt nicht an.
Statement-Ereignisse haben den größten Einfluss auf die Performance und Quantität. Die anderen Ereignisse haben nur einen geringen Einfluss auf die Performance, vergrößern aber die Menge. Überwachen Sie Statement-Ereignisse nur, wenn Sie sie wirklich benötigen. Überwachen Sie von den Nicht-Statement-Ereignissen nur diejenigen, die Sie analysieren möchten.
Wenn Sie beispielsweise in NaturalONE die Programm-Hot-Spots, aber weder das Statement noch die Zeilen-Hot-Spots anzeigen möchten, ist die folgende Profiler-Ereignisfiltereinstellung ausreichend:
FILTER=EVENT /* Set event filter EVENT=P /* Program events
Mit dieser Einstellung werden nur die Programm- und Session-Ereignisse überwacht, die für die Programm-Hot-Spots benötigt werden, während Statement- und FNAT-Sammlung standardmäßig deaktiviert sind.
Überwachen Sie nur die Libraries und Programme, die Sie analysieren möchten. Verwenden Sie den Programmfilter, um die Profil-Erstellung einzuschränken.
Wenn beispielsweise ein (erster) Profiler ohne
Statement-Sammlung gezeigt hat, dass die meiste CPU-Zeit im Programm
HIGHCPU verbracht wurde, dann möchten Sie vielleicht nur wissen,
in welcher Zeile dieses Programms die meiste Zeit verbracht wurde und welche
anderen Ereignisse (Datenbankaufrufe, externe Programmaufrufe usw.) ausgeführt
werden:
FILTER=PROGRAM /* Set program filter LIBRARY=PRFDEMO /* Monitored library PROGRAM=HIGHCPU /* Monitored program FILTER=EVENT /* Set event filter EVENT=ALL /* All events STATEMENT=ON /* Collect statements (no count)
Für die CPU-Analyse einer langlaufenden Anwendung empfehlen wir die Stichprobennahme (Stichprobentechnik (Natural Profiler Sampling)). Wenn Sie bereits Filtereinstellungen verwenden, um die Anzahl der Ereignisse zu reduzieren, können Sie zusätzlich das Sampling aktivieren, um die Anzahl der Ereignisse weiter zu reduzieren.
Die meisten Ereignisdaten werden generiert, wenn Statements gesammelt werden. Daher wird die Stichprobennahme oft in Verbindung mit der Statement-Sammlung verwendet. Für sehr lange laufende Anwendungen kann es jedoch hilfreich sein, Stichproben zu verwenden, auch wenn keine Statements gesammelt werden. Wenn Sie Stichproben ohne Statement-Sammlung verwenden, empfehlen wir ein Stichprobenintervall, das höher ist als das, das bei der Statement-Sammlung angegeben wurde.
Die Stichprobennahme hat nur eingeschränkte Auswirkungen auf die Profiler-Performance, kann aber die Datenmenge drastisch reduzieren. Die Formel im Abschnitt Stichprobentechnik (Natural Profiler Sampling) (Probenahme), die hier neu angeordnet ist, kann verwendet werden, um ein Stichprobenintervall so auszuwählen, dass die Anzahl der Ereignisse gleich oder kleiner als ein Näherungswert ist:
Stichprobenintervall
≥ |
|
Zum Beispiel benötigt eine Batch-Anwendung 40 Minuten CPU-Zeit (2.400.000.000 μs). Die Stichprobennahme sollte die Anzahl der Ereignisse auf höchstens 500.000 Ereignisse beschränken. Das entsprechende Probenahmeintervall kann mit der obigen Formel berechnet werden.
Stichprobenintervall
≥ |
|
= 4.800 |
Geben Sie die folgende Stichprobeneinstellung bei der INIT-Funktion der Profiler Utility an:
SAMPLING=ON INTERVAL=4800
Wenn Sie die Performance der Ereignisdaten analysieren möchten und kein Ereignis- oder Programm-Trace benötigen, empfehlen wir Ihnen, die Ereignisdaten serverseitig zu konsolidieren. Die Profiler-Datenkonsolidierung kombiniert ähnliche Datensätze in einem konsolidierten Datensatz mit aggregierten Zeitwerten und einem Trefferzähler.
Die Ereignisdaten können während der Datensammlung mit dem
Schlüsselwort CONSOLIDATE in der INIT-Funktion der
Profiler-Utility konsolidiert werden, wie im Abschnitt
Profil-Erstellung
initialisieren beschrieben.
Nicht konsolidierte Ereignisdaten einer NPRF-Ressourcendatei (Natural Profiler Resource File) können mit der CONSOLIDATE-Funktion der Profiler Utility konsolidiert werden, wie im Abschnitt Ereignisdaten konsolidieren beschrieben, oder mit der CONSOLIDATE-Funktion der Natural Profiler Rich GUI-Schnittstelle, wie in der Dokumentation von NaturalONE beschrieben, die unter documentation.softwareag.com verfügbar ist. Siehe Using NaturalONE > Using Natural Tools and Utilities > Rich GUI Interface of the Natural Profiler.
Konsolidierte Daten werden in eine NPRC-Ressourcendatei (Natural Profiler Resource Consolidated) geschrieben, die allgemein deutlich kleiner ist als die entsprechende NPRF-Ressourcendatei. Sie lässt sich viel schneller von NaturalONE aus öffnen und bietet die gleichen Hot-Spots wie die NPRF-Ressourcendatei.
Anmerkung:
Natural-Codeabdeckungsdaten, die in eine NCVF-Ressourcendatei
geschrieben werden, werden automatisch durch Natural-Codeabdeckung
konsolidiert.
Mit dem Profilparameter RDC wird
der Natural Data Collector konfiguriert, der von der Profiler Utility und der
SYSRDC Utility benutzt wird. Siehe RDC - Konfiguration des Natural Data
Collector in der
Parameter-Referenz-Dokumentation.
Die CMRDC-Schnittstelle steuert die im Natural Data Collector-Puffer aufgezeichneten Daten. Siehe Aufruf des CMRDC-Interface im Dokument SYSRDC Utility in der Debugger und Dienstprogramme-Dokumentation.
Die Verwendung der Profiler Utility kann von Natural Security kontrolliert werden, siehe Protecting Utilities in der Natural Security-Dokumentation.
Die Verwendung des NaturalONE Profilers und der NaturalONE-Codeabdeckung ist in der NaturalONE-Dokumentation beschrieben.
Die NaturalONE Tools und Utilities einschließlich der Natural Profiler Rich GUI-Schnittstelle sind in der NaturalONE-Dokumentation beschrieben.