このドキュメントでは ADADCU ユーティリティについて説明します。
次のトピックについて説明します。
圧縮解除ユーティリティ ADADCU は、ADACMP、ADAMUP および ADAULD ユーティリティによって生成されたレコードを圧縮解除します。
圧縮解除ユーティリティ ADADCU の出力は、標準オペレーティングシステムのファイルアクセスメソッドを使用しているプログラムに対する入力として使用できます。
また、データ構造を変更したい時やファイルのデータ定義を変更したいときに、圧縮ユーティリティ ADACMP に対する入力としても使用できます。このユーティリティによって作成された圧縮解除出力ファイル(DCUOUT ファイル)が空の場合は、警告メッセージが発行されます。
ADADCU では、ユーティリティ ADAULD と ADACMP の SINGLE オプションで作成されたファイルも圧縮解除されますが、ユーティリティが判別するので、パラメータは必要ありません。
ADADCU には次の機能が装備されています。
圧縮解除すると、レコードが完全に復元され、FDT で記述されているフォーマットと長さに戻ります。出力レコードの各マルチプルバリューフィールドまたはピリオディックグループの先頭には、1 バイトのカウントフィールドが付きます。
LOB フィールドの値は別のファイルに保存することもでき、生成されるファイルの名前は非圧縮レコードに配置されます。
複数のフィールドを圧縮解除できます。
複数のフィールドを圧縮解除する場合、フィールドをレコード内で再配置できます。つまり、レコード構造を次のように変更できます。
フィールド長を変更できます。
フィールドフォーマットを変更できます。
リテラルエレメントまたは空白エレメントを使用して後続の新規フィールドの追加に対してスペースを割り当てできます。
エラーファイルにレコードが書き込まれると、ユーティリティはゼロ以外のステータスで終了します。
このユーティリティは単一機能ユーティリティです。
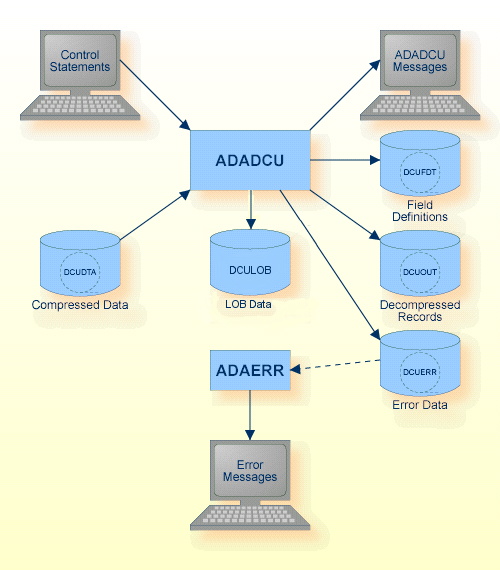
DCULOB は、LOB の値が別のファイルで保存されるディレクトリです。シーケンシャルファイル DCUDTA および DCUERR は複数エクステントを持つことができます。複数のエクステントを持つシーケンシャルファイルの詳細については、『Adabas Basics』の「ユーティリティの使用」を参照してください。
| データセット | 環境 変数/ 論理名 |
記憶 媒体 |
追加情報 |
|---|---|---|---|
| 圧縮 データレコード |
DCUDTA | ディスク、テープ(* 注参照) | ADACMP または ADAULD の出力 |
| 拒否データ | DCUERR | ディスク、テープ(* 注参照) | ADADCU の出力 |
| 出力データ FDT | DCUFDT | ディスク、テープ(* 注参照) | ADADCU の出力 ユーティリティマニュアル |
| 非圧縮レコード | DCUOUT | ディスク、テープ(* 注参照) | ユーティリティマニュアル |
| LOB データ | DCULOB | ディスク | ユーティリティマニュアル |
| コントロールステートメント | stdin/ SYS$INPUT |
ユーティリティマニュアル | |
| ADADCU メッセージ | stdout/ SYS$OUTPUT |
メッセージおよびコード |
注意:
(*)このシーケンシャルファイルには、名前付きパイプを使用できます(OpenVMS にはない。詳細については、『Adabas Basics』の「ユーティリティの使用」を参照)。
このユーティリティはチェックポイントを書き込みません。
次のコントロールパラメータを使用できます。
D [NO]DCUFDT D [NO]DST FDT FIELDS {field_specification | FDT},...[END_OF_FIELDS | .] D [NO]LOWER_CASE_FIELD_NAMES D MAX_DECOMPRESSED_SIZE = number [K|M] D MUPE_C_L = {1|2|4} MUPE_OCCURRENCES D [NO]NULL_VALUE D NUMREC = number D RECORD_STRUCTURE = keyword SKIPREC = number D TARGET_ARCHITECTURE = (keyword[,keyword[,keyword]]) D [NO]TRUNCATION TZ {=|:} [timezone] D [NO]USERISN WCHARSET = char_set
[NO]DCUFDT
このパラメータを DCUFDT に設定すると、非圧縮レコードの FDT 情報がシーケンシャルファイル DCUFDT に書き込まれます。デフォルトは NODCUFDT です。
FIELDS パラメータ(以下を参照)を使用した場合、フィールドは FIELDS に指定した順番でシーケンシャルファイル DCUFDT に書き込まれます。したがって、DCUFDT のフィールドは、オリジナルの FDT とは異なる順番になることがあります。
[NO]DST
DST パラメータは、オプション TZ を使用して日付/時刻フィールドに夏時間インジケータが提供されている場合に必要です。夏時間インジケータは、2 バイトの整数値(フォーマット F)として日付/時刻値の後に追加されます。この値には、実際の時間(通常は 0 または 3600)を取得するための、標準時間に追加する秒数が含まれています。
このパラメータは、時刻が標準時刻に戻る前の時間に TZ オプションが指定された日付/時刻値が含まれているレコードがある場合に必要です。このパラメータがないと、これらの値はエラーファイルに書き込まれます。
デフォルトは NODST です。
注意:
FDT
このパラメータは、圧縮レコードを含むファイルの FDT を表示します。
FIELDS {field_specification | FDT},...[END_OF_FIELDS | . ]
このパラメータは、FDT のフィールドのサブセットおよび、それらのフォーマットと長さを指定するために使用します。FDT で指定されているすべてのフィールドが、作成される非圧縮レコードに含まれている必要はない、つまり別のフォーマットか長さでフィールドを圧縮解除できるということです。構文と使用方法はフォーマットバッファの場合とほぼ同じです。ただし、非圧縮レコードに LOB 値自体ではなく、LOB 値を含むファイルの名前が含まれている場合に、(LOB 参照の)R 要素も指定できる点だけが異なります。詳細については、『管理マニュアル』の「データのロードとアンロード」の「非圧縮データフォーマット」を参照してください。
指定リストの入力時に、圧縮解除するファイルの FDT を表示する FDT 機能を使用できます。指定リストは END_OF_FIELDS または「.」を入力することで終了または中断できます。「.」オプションは暗黙の END_OF_FIELDS であり、フォーマットバッファ構文と互換性があります。FIELDS または END_OF_FIELDS は常にそれ自体を行に入力する必要がありますが、「.」はそれ自体を行に入力することも、フォーマットバッファ要素の末尾に入力することも可能です。FIELDS の入力によって任意のオプションまたはパラメータの設定後に処理を続行できます。
END_OF_FIELDS パラメータを使用してフィールド定義を消去する場合、LOWER_CASE_FIELD_NAMES パラメータを使用するときに、このパラメータを大文字で指定する必要があります。また、LOWER_CASE_FIELD_NAMES を使用する場合は、FDT パラメータも大文字で指定する必要があります。
adadcu: fields adadcu: ; This is a comment line adadcu: AA,AB,6,A,AC,P ; - inline comment - adadcu: AD,AF,CBC,CB1-N . ; implicit END_OF_FIELDS
フィールド AA はデフォルトの長さとフォーマットで出力され、フィールド AB は 6 バイトの英数字、フィールド AC はパックのデフォルト長さで出力されます。さらにフィールド AD および AF は、デフォルトの長さとフォーマットで出力され、その後には、フィールド CB の 1 バイトのバイナリマルチプルフィールドカウントと CB のすべてのオカレンスが続きます。
[NO]LOWER_CASE_FIELD_NAMES
LOWER_CASE_FIELD_NAMES が指定されている場合、Adabas フィールド名は、大文字に変換されません。NOLOWER_CASE_FIELD_NAMES が指定されている場合、Adabas フィールド名は、大文字に変換されます。デフォルトは、NOLOWER_CASE_FIELD_NAMES です。
このパラメータは、FIELDS パラメータの前に指定する必要があります。
MAX_DECOMPRESSED_SIZE = number [K|M]
このパラメータは、数字の後の「K」または「M」の仕様に応じて、非圧縮レコードの最大サイズをバイト、キロバイトまたはメガバイト単位で指定します。このパラメータの目的は、誤って巨大な非圧縮レコードファイルが作成されることを防止することです(ファイルに LOB データが含まれることを考慮しなかった場合に発生します)。
デフォルトは、65536 です。これは、最大値でもあります。
注意:
このパラメータの正確な定義は、最大非圧縮レコードに必要な入力/出力バッファのサイズです。256 バイトの倍数のみが入力/出力バッファに使用されます。これにより、次の 256 の倍数に切り上げられる最大非圧縮レコード以上の値(先行する長さフィールドを含む)を指定する必要があります。
MUPE_C_L = {1|2|4}
データにマルチプルバリューフィールドまたはピリオディックグループが含まれる場合、圧縮解除データにおいて、それらには MUPE_C_L バイトの長さのバイナリのカウントフィールドが先行します。
デフォルトは 1 です。
MUPE_OCCURRENCES
このパラメータは、マルチプルフィールドおよびピリオディックグループのリストと、それらの最大オカレンス数を出力するために使用します。圧縮解除データが非常に大きくなることがあるので、出力した情報は重要です。範囲指定が大きすぎる場合、非圧縮レコードのサイズの限界を超えることがあります。
ファイルの FDT は次のような圧縮レコードを含みます。
1,AA,4,A,NU 1,PE,PE 2,PA,2,A,NU 2,PB,2,A,NU,MU 1,MM,2,U,NU,MU 1,X1,4,B
次に示すように、MUPE_OCCURRENCES の出力は、フォームのような形態になります。
Name Max occurrence --------------------- PE 4 PB 8 MM 12 %ADADCU-I-DCUREC, Number of decompressed records: 5023 %ADADCU-I-DCUIR, Number of incorrect records: 0
ファイルは次のように圧縮解除できます。
adadcu fields "AA,PA1-4,PB1-4(1-8),MM1-12,P,X1"
注意:
MU フィールドを含んでいるピリオディックグループのオカレンスが非常に多い場合、レコードは不正であるとみなされ、内部のオーバーフローを起こします。ピリオディックグループを含むこのレコードを圧縮解除することはできません。
[NO]NULL_VALUE
このパラメータは、レコードが NC パラメータフィールドおよびそれらのステータス値(S 要素)を含んでいる場合に、標準 FDT でレコードを圧縮解除するために、使用することができます。1 つ以上のフィールドに空値がある場合、必要となります。それ以外の場合は、これらのレコードはエラーファイルに格納されます。
フィールド AA の FDT エントリが1,AA,2,A,NC の場合には、NULL_VALUE の効果は次のようになります。
NULL_VALUE:第 1 出力レコード(16 進)00004141(AA に値がある)、第 2 出力レコード(16 進)FFFF2020(AA は空値)。
NONULL_VALUE:第 1 出力レコード(16 進)4141(AA に値がある)、第 2 出力レコード(16 進)AA は空値。そのため、レコードはエラーファイルに格納されます。
デフォルトは NONULL_VALUE です。
NUMREC = number
このパラメータは、入力ファイルから読み込んで圧縮解除するレコード数を指定するものです。このパラメータが省略され、SKIPREC が指定されないと、全レコードが処理されます。
adadcu: numrec = 100
100 レコードが読み込まれて圧縮解除されます。
RECORD_STRUCTURE = keyword
このパラメータは、論理名 DCUOUT で指定された出力ファイル内で使用されるレコード区切りのタイプを、指定するものです。次のキーワードを使用できます。
| キーワード | 説明 |
|---|---|
| ELENGTH_PREFIX | DCUOUT ファイルのレコードは、2 バイトの長さフィールド(フィールド長にはフィールド自体の長さは含まれない)によって区切られます。区切り文字がないため、このフォーマットの使用は一切の制限を受けません。 |
| E4LENGTH_PREFIX | 非圧縮データファイル内のレコードは、4 バイトの長さフィールド(長さフィールド自体の長さを除く)で区切られます。 |
| ILENGTH_PREFIX | DCUOUT ファイルのレコードは、2 バイトの長さフィールド(フィールド長にはフィールド自体の長さも含まれる)によって区切られます。区切り文字がないため、このフォーマットの使用は一切の制限を受けません。 |
| I4LENGTH_PREFIX | 非圧縮データファイル内のレコードは、4 バイトの長さフィールド(長さフィールド自体の長さを含む)で区切られます。 |
| NEWLINE_SEPARATOR | DCUOUT ファイル内のレコードは、改行文字によってて区切られます。DCUOUT ファイルを ADACMP の入力として使用する場合に、このキーワードを指定できるのは、出力のフィールド値に改行文字が含まれていないときに限ります。つまり、アンパック形式のフィールド、英数字フィールド、Unicode
フィールドだけが存在する場合と、英数字フィールドと Unicode フィールドに出力可能な文字のみが含まれる場合がこれに該当します。 このキーワードと USERISN パラメータは相互に排他的です。 |
| RDW | DCUOUT ファイル内のレコードは、FTP site rdw オプションを使って IBM ホストへ転送可能な形式にフォーマットされます。 |
| RDW_HEADER | RDW と同じように、HEADER=YES を使用してメインフレームで圧縮できる非圧縮レコードの場合。 |
| VARIABLE_BLOCKED | レコードは、ブロックとして格納されます。各レコードは 4 バイト(長さバイトの長さを含む)のフィールド長で始まります。 |
デフォルトは ELENGTH_PREFIX です。
SKIPREC = number
このパラメータは、圧縮解除を始める前にスキップされるレコード数を指定するものです。
TARGET_ARCHITECTURE = (keyword[,keyword[,keyword]])
このパラメータは、出力データレコードの形式(文字セット、浮動小数点フォーマットおよびバイト順)を指定するものです。次のキーワードを使用できます。
| キーワードグループ | 有効なキーワード |
|---|---|
| 文字セット |
ASCII EBCDIC |
| 浮動小数点フォーマット |
IBM_370_FLOATING IEEE_FLOATING VAX_FLOATING |
| バイト順 |
HIGH_ORDER_BYTE_FIRST LOW_ORDER_BYTE_FIRST |
キーワードグループのキーワードを指定しない場合、このキーワードグループのデフォルトは、ADADCU を実行しているマシンのアーキテクチャに対応するキーワードになります。
注意:
FDTは、常に ASCII フォーマットで出力されます。
出力レコードを IBM 形式に圧縮解除する場合は、ユーザーは次のように指定しなければなりません。
TARGET_ARCHITECTURE = (EBCDIC, IBM_370_FLOATING, HIGH_ORDER_BYTE_FIRST)
[NO]TRUNCATION
このパラメータは、英数字フィールド値の桁落ちを有効または無効にするものです。
NOTRUNCATION がデフォルトです。この場合は、英数字フィールド値が切り詰められたすべてのレコードは、エラーファイルに書き込まれます。
数値の切り詰めはできず、値は標準長または指定長内でなければなりません。数値の桁落ちが発生すると、該当レコードはエラーファイルに書き込まれます。
TZ {=|:} [timezone]
指定されたタイムゾーンは、Olson データベース(https://www.iana.org/time-zones)として知られているタイムゾーンデータベースに含まれている有効なタイムゾーン名にする必要があります。タイムゾーンが指定されている場合、このタイムゾーンは、オプション TZ を含む日付/時刻フィールドのタイムゾーン変換に使用されます。
デフォルトは、UTC です。これは、オプション TZ を含む日付/時刻フィールドに内部的に保存するために使用されます。変換する必要はありません。
空の値を指定する場合、日付/時刻フィールドが正しいことを確認するチェックマークは付いていません。
注意:
タイムゾーン名はファイル名になります。プラットフォームに応じて、これらのファイル名は大文字小文字を区別する場合としない場合があります。また、タイムゾーン名も、プラットフォームに応じて大文字/小文字を区別する場合としない場合があります。
tz:Europe/Berlin
これは、すべてのプラットフォームに適用されます。
TZ=Europe/Berlin
この仕様により、TZ は大文字の EUROPE/BERLIN に変換されます。これは、Windows では、ファイル名の大文字/小文字が区別されないため適用されます。ただし、Unix では、Unix ファイル名の大文字/小文字は区別されるため適用されません。
[NO]USERISN
このパラメータは、それぞれの非圧縮レコードと一緒に ISN を出力するかどうかを指示するものです。レコードに現在割り当てられている ISN を圧縮解除データと一緒に出力するかまたはそれを省略するかどうかをユーザーは指定できます。ユーザーが同じ ISN を持つファイルを再ロードしたい場合には、USERISN オプションを設定する必要があります。
このパラメータは、RECORD_STRUCTURE=NEWLINE_SEPARATOR が指定された場合には指定することができません。
このパラメータが省略されると、ISN は各レコードと一緒には出力されません。
NOUSERISN がデフォルトです。
adadcu: userisn
ISN が各レコードと一緒に出力されます。
WCHARSET = char_set
このパラメータは、http://www.iana.org/assignments/character-sets に記載されているエンコード名に基づいて、非圧縮ファイルで使用するデフォルトエンコードを指定します。このサイトに記載されているほとんどの文字セットは、ICU(Adabas 国際化サポートで使用)によってサポートされています。
ADADCU に対する入力は、アンロードユーティリティ ADAULD や圧縮ユーティリティ ADACMP などによって出力された圧縮レコードが存在するファイルでなければなりません。
ADADCU は、FIELDS 指定にしたがって各入力レコードを圧縮解除し、その結果のレコードを論理名 DCUOUT ファイルに書き込みます。このレコードは可変長形式で書き込まれます。デフォルトでは、レコードは 2 バイトの長さフィールド(長さフィールド自体はフィールド長に含まれない)によって区切られます。詳細に関しては、このセクションのパラメータ RECORD_STRUCTURE に関する説明を参照してください。
USERISN が指定されると、データレコードの先頭には 4 バイトの 2 進数形式で ISN が付きます。
シーケンシャルファイル DCUFDT(非圧縮レコードのフィールド定義情報)は、ファイル定義ユーティリティ ADAFDU または圧縮ユーティリティ ADACMP に対する入力として使用できます。
ADADCU によって拒否されたすべてのレコードは、ADADCU エラーファイルに書き込まれます。このエラーファイルの内容は、ADAERR ユーティリティを使用して表示します。レコードに出力不能文字が含まれているため、標準オペレーティングシステム出力ユーティリティを使用してエラーファイルを出力しないでください。
詳細については、ADAERR ユーティリティの説明を参照してください。
ADADCU は再スタート機能を備えていません。中断された ADADCU の実行は、最初から再実行しなければなりません。
ADADCU はデータベースを更新しないので、中断された ADADCU の実行を再実行する前にデータベースのステータスに関して考慮する必要はありません。