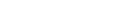
このドキュメントでは ADADBM ユーティリティについて説明します。
次のトピックについて説明します。
ADADBM ユーティリティは、データベースに対する修正を行うために、次にあげる各機能から構成されています。
ADD_CONTAINER 機能は、新規コンテナファイルをアソシエータまたはデータストレージデータセットに追加します。
ADD_FIELDS 機能は、新規フィールドをファイルの FDT の最後に追加します。
ALLOCATE NI、UI、AC、または DS 機能は、ファイルに割り当てられたノーマルインデックス、アッパーインデックス、アドレスコンバータ、またはデータストレージスペースを増やします。
CHANGE 機能は、フィールド定義テーブル(FDT)内のフィールドの標準長を変更します。
CHANGE_FIELDS 機能は、ファイル内の 1 つまたは複数の指定を変更します。
DEALLOCATE 機能は、ALLOCATE とは逆の働きをする機能です。NI、UI、AC、または DS 機能は、ファイルにとって不要となったノーマルインデックス、アッパーインデックス、アドレスコンバータ、またはデータストレージスペースをフリースペーステーブル(FST)に戻します。
DELCP 機能は、日付範囲を指定してチェックポイントファイルから古いチェックポイントレコードを削除します。
DELETE 機能は、データベースから Adabas ファイルを 1 つまたは範囲で削除します。
DELETE_DATABASE 機能は、データベースを削除します。指定されたキーワードに応じて、コンテナのみが削除されるか、データベースディレクトリとそのコンテンツが削除されます。
DISPLAY 機能は、ユーティリティコミュニケーションブロック(UCB)を表示します。
DROP_FIELDS 機能は、指定フィールドを存在しないものとしてマークします。これらは、それらにアクセスできなくなったことを意味します。
DROP_LOBFILE 機能は、ADAFDU ADD_LOBFILE の逆の機能です。
DROP_REFINT 機能は、既存の参照制約をドロップします。
EXTEND_CONTAINER 機能は、データベースに定義された最後のコンテナファイルを拡張します。
NEW_DBID 機能は、使用しているデータベースの ID を変更します。
NEWWORK 機能は、新規の Adabas WORK データセットを割り当てし、フォーマットします。
PGM_REFRESH 機能は、アプリケーションプログラム内での E1 コマンドによる Adabas ファイルのリフレッシュの有効/無効を切り替えます。
RBAC_FILE 機能は、Adabas 認可モードに必要な RBAC システムファイルを作成します。
RECOVER 機能は、フリースペーステーブルに欠如したスペースを戻します。
REDUCE_CONTAINER 機能は、データベースに定義された最後のコンテナファイルのサイズを縮小します。
REFRESH 機能は、1 つのファイルまたは指定範囲のファイルをレコードがまったくロードされていない状態にリセットします。
REMOVE_CONTAINER 機能は、アソシエータまたはデータストレージデータセットからコンテナファイルを削除します。
REMOVE_DROP 機能(後続の REFRESH と連携して使用される)は、ドロップされたフィールドを FDT から削除します。
REMOVE_REPLICATION 機能は、すべてのレプリケーション処理を停止し、レプリケーションシステムファイルを削除します。
RENAME 機能は、データベース名またはロードされたファイルの名前を変更します。
RENUMBER 機能は、ロードされるファイルの番号を振り直すか、またはロードされるファイル同士の番号を交換します。
REPLICATION_FILES 機能は、Adabas-Adabas レプリケーションに必要なシステムファイルを作成します。
RESET 機能は、UCB からエントリを消去します。
RESET_REPLICATION_TARGET 機能は、Adabas ファイルのレプリケーションターゲットフラグをリセットします。
REUSE 機能は、Adabas によるデータストレージスペースや ISN の再使用を制御します。
SECURITY 機能は、データベースのセキュリティモードを設定します。
SYFMAX 機能は、指定されたファイル内のシステム生成マルチプルバリューフィールドに対して生成される値の最大数を指定します。
このユーティリティは多機能ユーティリティです。
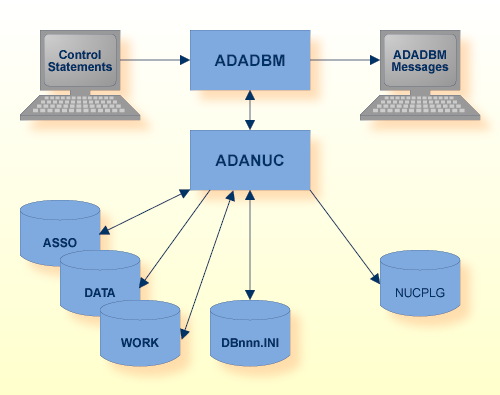
Adabas ニュークリアスがアクティブな場合、ADADBM はデータベースコンテナを修正するためにニュークリアスを呼び出します。いくつかのタスクは、チェックポイントが書き込まれませんが、アクティビティがデータベースログに書き込まれます。リカバリの場合は、アクティブティが自動的に再実行されます。
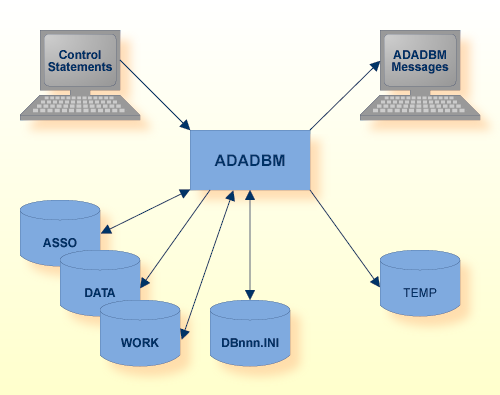
Adabas ニュークリアスがアクティブでない場合、ADADBM がデータベースコンテナを修正します。
| データセット | 環境 変数/ 論理名 |
記憶 媒体 |
追加情報 |
|---|---|---|---|
| アソシエータ | ASSOx | ディスク | |
| データストレージ | DATAx | ディスク | |
| DBnnn.INI | ディスク | Adabas 拡張オペレーションマニュアル | |
| コントロールステートメント | stdin | ユーティリティマニュアル | |
| ADADBM メッセージ | stdout | メッセージおよびコード | |
| プロテクションログ (オンラインモードのみ) |
NUCPLG | ディスク | ユーティリティマニュアル: ADANUC、ADAPLP |
| 一時ストレージ (オフラインモードのみ) |
TEMP1 | ディスク | NEWWORK 機能用の新しい WORK データセット。この機能の実行後には、WORK の環境変数/論理名のポイント先を新しい WORK データセットに変更する必要があります。 |
| WORK | WORK1 | ディスク |
次の表は、各機能に対するニュークリアス条件と記録チェックポイントを示しています。
| 機能 | ニュークリアスのアクティブ化が必要 | ニュークリアスの非アクティブ化が必要 | ニュークリアスは不要 | 記録チェックポイント |
|---|---|---|---|---|
| ADD_CONTAINER | X | SYNP | ||
| ADD_FIELDS | X |
SYNP(オフライン) SYNX(オンライン) |
||
| ALLOCATE | X | SYNP | ||
| CHANGE | X | - | ||
| CHANGE_FIELDS | X |
SYNP(オフライン) SYNX(オンライン) |
||
| DEALLOCATE | X | SYNP | ||
| DELCP | X | SYNP | ||
| DELETE | X |
SYNP(オフライン) SYNX(オンライン) |
||
| DELETE_DATABASE | X | - | ||
| DISPLAY | X | - | ||
| DROP_FIELDS | X |
SYNP(オフライン) SYNX(オンライン) |
||
| DROP_LOBFILE | X | SYNP | ||
| EXTEND_CONTAINER | WORK の場合 | ASSO または DATA の場合 | SYNP | |
| NEW_DBID | X(注 1 参照) | SYNP | ||
| NEWWORK | X(注 1 参照) | SYNP | ||
| PGM_REFRESH | X | SYNP | ||
| RECOVER | X | SYNP | ||
| REDUCE_CONTAINER | ASSO または DATA の場合 | SYNP | ||
| REFRESH | X | SYNP | ||
| REMOVE_CONTAINER | X | SYNP | ||
| REMOVE_REPLICATION | X |
SYNP(オフライン) |
||
| RENAME | X | SYNP | ||
| RENUMBER | X | SYNP | ||
| REPLICATION_FILES | X |
SYNP(オフライン) SYNX(オンライン) (注 2 参照) |
||
| RESET | X | SYNX | ||
| RESET_REPLICATION_TARGET | ||||
| REUSE | X | SYNP | ||
| SECURITY | X | SYNP(オフライン) | ||
| SYFMAX | X |
SYNP(オフライン) SYNX(オンライン) |
注意:
次のコントロールパラメータを使用できます。
ADD_CONTAINER = keyword
D [,BLOCKSIZE=number[K] ]
,SIZE = number [B|M]
ADD_FIELDS = number {field_specification|FDT} ... [END_OF_FIELDS]
ALLOCATE = keyword, FILE = number [,RABN = number],
SIZE = number [B|M]
CHANGE = number, FIELD = string, LENGTH = number
CHANGE_FIELDS = number {field_specification|FDT} ... [END_OF_FIELDS]
M DBID = number
DEALLOCATE = keyword, FILE = number [,RABN = number],
SIZE = numberB
DEFINE_REFINT = number constraint_specification
DELCP = { * | ([absolute-date] [,[absolute-date]]) }
DELETE = (number [-number][,number[-number]]...)
DELETE_DATABASE = keyword
DISPLAY = UCB
DROP_FIELDS = number {field_name|FDT} ... [END_OF_FIELDS]
DROP_LOBFILE = number
DROP_REFINT = number, NAME {=|:}constraint_name
EXTEND_CONTAINER = keyword, SIZE = number [B|M]
D [NO]LOWER_CASE_FIELD_NAMES
NEW_DBID = number
NEWWORK [,BLOCKSIZE=number[K] ], SIZE = number [B|M]
PGM_REFRESH = keyword, FILE = number
RBAC_FILE = number
RECOVER
REDUCE_CONTAINER = keyword, SIZE = number B
REFRESH = (number [-number][,number[-number]]...)
REMOVE_CONTAINER = keyword
[NO]REMOVE_DROP
REMOVE_REPLICATION
RENAME = number, NAME {=|:} string
RENUMBER = (number, number)
REPLICATION_FILES = (file1, file2, file3, file4)
RESET = UCB, IDENT = { (number [,number]...) | * }
RESET_REPLICATION_TARGET = number
REUSE = (keyword [,keyword]), FILE = number
SECURITY = keyword
SYFMAX = number, FILE = number
ADD_CONTAINER = keyword
[,BLOCKSIZE=number[K] ]
,SIZE = number [B|M]
ADD_CONTAINER パラメータは、使用されるキーワードに従って、新規コンテナファイルを既存のアソシエータまたはデータストレージデータセットに追加します。キーワードの値は ASSO または DATA のいずれかです。
新しいコンテナファイルは、現在のコンテナファイルと同じデバイスに割り当てるか、または別のデバイスタイプに割り当てることができます。
新規コンテナファイルの配置は、環境変数/論理名 ASSOx や DATAx に応じて変わります。これには、完全なパス名を持つ正式なファイル名を設定する必要があります。ASSOx も DATAx も設定しない場合には、新規コンテナファイルは現在のディレクトリ内に作成されます。
注意:
新しいコンテナファイルのブロックサイズをバイト(または、K が数値の後に指定される場合はキロバイト)で指定します。
指定した値以上かつ最も近い 1K の倍数に切り上げられます。最小ブロックサイズは 1K、最大ブロックサイズは 32K です。
BLOCKSIZE に対するデフォルト値は、データベース内に存在する対象データセットの最後のコンテナファイルのブロックサイズです。
このパラメータは、新規コンテナファイルに対して割り当てられるブロック数(B)またはメガバイト数(M)を指定するものです。デフォルトでは、サイズはメガバイト単位で認識されます。
adadbm: add_container=data, size=10 %ADADBM-I-CREATED, dataset DATA2 , file /FS/fs0395/Adabas/adadb/db076/DATA2 created %ADADBM-I-FUNC, function ADD_CONTAINER executed
10 メガバイトの新規コンテナファイルがデータストレージに追加されます。ブロックサイズは DATA1 のブロックサイズと同じです。
ADD_FIELDS = number {field_specification|FDT}... [END_OF_FIELDS]
ADD_FIELDS パラメータは、number で定義されたファイルの末尾に 1 つまたは複数の新規フィールドを追加します。LOB ファイルを指定することはできません。この機能は END_OF_FIELDS の入力で完了します。
END_OF_FIELDS パラメータを使用してフィールド定義を消去する場合、LOWER_CASE_FIELD_NAMES パラメータを使用するときに、このパラメータを大文字で指定する必要があります。また、LOWER_CASE_FIELD_NAMES を使用する場合は、FDT パラメータも大文字で指定する必要があります。
注意:
ADADBM では、派生ディスクリプタを追加できません。これを追加するには、代わりに、ユーティリティ ADAINV を使用する必要があります。
この場合のフィールド指定リストは、ADAFDU での FDT 入力と同じ方法で入力されます。
level-number, name [,length] [,format] [(,option)...]
第 1 追加フィールドはレベル 1 のフィールドとなる必要があります。
NN オプションは使用することができません。Adabas ニュークリアスがアクティブで、NU または NC オプションが一緒に指定されるときに限り、DE は指定できます。それ以外では、ADAINV ユーティリティを使用して新規のフィールドディスクリプタステータスを指定します。UQ は DE オプションとともにのみ指定できます。
注意:
システム生成フィールド(フィールドオプション SY が指定されたフィールド)をファイルに追加すると、データベース内にすでに存在していたレコード内では、これらのフィールドに空値が含まれます。これは、SY オプションが指定されていないフィールドと同じ動作です。
このパラメータは、フィールドを追加するファイルの FDT を表示します。
adadbm: add_fields=12
adadbm: fdt
Field Definition Table:
Level I Name I Length I Format I Options I Flags
-------------------------------------------------------------------------------
1 I AA I 15 I A I DE,UQ,NU I
1 I AB I 4 I F I FI I
1 I AC I 8 I A I DE I
1 I CD I I I I
2 I AD I 20 I A I DE,NU I SP
2 I AE I 20 I A I NU I
2 I AF I 10 I A I DE,NU I
1 I AG I 2 I U I NU I SP
1 I AH I 1 I A I DE,FI I
1 I AI I 1 I A I FI I
1 I AJ I 6 I U I NU I SP
1 I AK I I I I
2 I AL I 3 I A I NU I
2 I AM I 4 I P I NU,MU I
-------------------------------------------------------------------------------
Type I Name I Length I Format I Options I Parent field(s) Fmt
-------------------------------------------------------------------------------
SUPER I AN I 4 I B I NU I AJ ( 5 - 6 ) U
I I I I I AJ ( 3 - 4 ) U
-------------------------------------------------------------------------------
SUPER I AO I 22 I A I NU I AG ( 1 - 2 ) U
I I I I I AD ( 1 - 20 ) A
-------------------------------------------------------------------------------
adadbm: 01,dd,1,a
adadbm: 01,gr
adadbm: 02,g1,20,a,fi
adadbm: fdt
Field Definition Table:
Level I Name I Length I Format I Options I Flags
-------------------------------------------------------------------------------
1 I AA I 15 I A I DE,UQ,NU I
1 I AB I 4 I F I FI I
1 I AC I 8 I A I DE I
1 I CD I I I I
2 I AD I 20 I A I DE,NU I SP
2 I AE I 20 I A I NU I
2 I AF I 10 I A I DE,NU I
1 I AG I 2 I U I NU I SP
1 I AH I 1 I A I DE,FI I
1 I AI I 1 I A I FI I
1 I AJ I 6 I U I NU I SP
1 I AK I I I I
2 I AL I 3 I A I NU I
2 I AM I 4 I P I NU,MU I
1 I DD I 1 I A I I
1 I GR I I I I
2 I G1 I 20 I A I FI I
-------------------------------------------------------------------------------
Type I Name I Length I Format I Options I Parent field(s) Fmt
-------------------------------------------------------------------------------
SUPER I AN I 4 I B I NU I AJ ( 5 - 6 ) U
I I I I I AJ ( 3 - 4 ) U
-------------------------------------------------------------------------------
SUPER I AO I 22 I A I NU I AG ( 1 - 2 ) U
I I I I I AD ( 1 - 20 ) A
-------------------------------------------------------------------------------
adadbm: end_of_fields
%ADADBM-I-FUNC, function ADD_FIELDS executed
ALLOCATE = keyword, FILE = number [,RABN = number], SIZE = number [B|M]
指定されたキーワード(AC、DS、NI、UI)に応じて、ALLOCATE 機能はノーマルインデックス(NI)、アッパーインデックス(UI)、アドレスコンバータ(AC)、またはデータストレージ(DS)を指定したサイズまで大きくすることが可能です。要求されたタイプでの拡張ができるかどうかを見るために、最終エクステントがチェックされます。現在のエクステントがまったく拡張不可能な場合には、新たな拡張が作成されます。
この機能は、自動拡張を無効にする方法を DBA に提供するものであり、エクステントの増減を自由に割り当てることができます。これは、大規模なレコード数を追加する場合に特に便利です。この機能に関しては、ファイルの排他制御は必要ありません。
このパラメータは、拡張対象ファイルを指定するものです。
このパラメータは、割り当て開始 RABN を指定するものです。LOB ファイルの NI または UI の割り当てでは、指定 RABN のブロックサイズを 16 KB より小さくする必要があります。LOB ファイルの DS 割り当てでは、指定 RABN のブロックサイズを 32 KB にする必要があります。
このパラメータは、拡張エリアのサイズを指定します。数値に "B" が付いている場合、大きさはブロック扱いとなり、これ以外はメガバイト扱いとなります。
adadbm: allocate=ni, file=11, size=100b %ADADBM-I-ALLOC, 100 NI blocks allocated (611 - 710) adadbm: allocate=ds, file=11, size=10 %ADADBM-I-DEALLOC, 2560 DS blocks allocated (245 - 2804)
CHANGE = number, FIELD = string, LENGTH = number
このパラメータは、数値部分に指定されたファイル内のフィールドの標準長を変更します。LOB ファイルを指定することはできません。固定小数点フィールド(オプション FI)と浮動小数点フィールド(フォーマット G)の長さは変更できません。
フィールド長の変更は、データストレージ内での修正を必要としませんが、標準長を使用するプログラムに対しては影響を及ぼします。
オプション SY=OPUSER で定義されたフィールドは変更できません。
このパラメータは、標準長を変更するフィールドを指定するものです。このフィールドは該当ファイルのフィールド定義テーブル内で定義されていなければなりません。
このパラメータは、フィールドの新たな標準長を定義するものです。
adadbm: change=12, field=ac, len=11 %ADADBM-I-FUNC, function CHANGE executed
CHANGE_FIELDS = number {field_specification|FDT}... [END_OF_FIELDS]
CHANGE_FIELDS 機能は、number で定義されたファイル内の 1 つまたは複数のフィールド指定を変更します。この機能は END_OF_FIELDS の入力で完了します。
END_OF_FIELDS パラメータを使用してフィールド定義を消去する場合、LOWER_CASE_FIELD_NAMES パラメータを使用するときに、このパラメータを大文字で指定する必要があります。また、LOWER_CASE_FIELD_NAMES を使用する場合は、FDT パラメータも大文字で指定する必要があります。
許可される変更は、ファイル内にレコードが存在するかどうかに応じて異なります。すべてのファイルに次の制限事項が適用されます。
フィールドレベル番号は変更できません。
グループはグループのままにする必要がありますが、レベル 1 で定義されている場合は、ピリオディックグループに変換できます。
ピリオディックグループは、ピリオディックグループのままにするか、非ピリオディックグループに変換する必要があります。
グループでもピリオディックグループでもないフィールドは、グループまたはピリオディックグループに変換しないでください。
空でないファイルには、次の追加の制限事項が適用されます。
フィールド長:新しい長さは、新しいフィールドフォーマットおよびフィールドオプションと互換性がある必要があります。長さを変更すると、フォーマットバッファでフィールド長が指定されていない Adabas コマンドの動作が変化します。
フィールドフォーマット:A は W に変更でき、その逆も可能です。フォーマットを A から W に変更した場合は、フィールドに UTF-8 値が含まれていることを確認するのはユーザーの責任です。フォーマットを W から A にした場合は、フィールドに UTF-8 値が含まれます。Adabas コマンドのフォーマットバッファで指定する形式は、A および W フィールドのフィールド定義のフォーマットと同になっている必要があります。したがって、既存のプログラムを適宜適合させることが必要になる場合があります。A と W の間で変更する場合を除き、フィールドフォーマットのその他の変更は許可されません。
フィールドオプション:オプション DE、FI、HF、MU、UQ は、追加も削除もできません。
次のフィールドオプションの変更が可能です。
| 古いフィールドオプション | 新しいフィールドオプション | コメント |
|---|---|---|
| DT が設定されていません | DT が設定されます、TZ は設定されることも設定されないこともあります | データベース内の値が指定された日付/時刻編集マスクに準拠しているかどうかを確認するチェックは行われません。TZ を編集マスク名 DATE、TIME、および NATDATE に設定することはできません。
注意: |
| DT が設定されました | DT が設定されていません | フォーマットバッファのフィールドに日付/時刻編集マスクは指定できなくなりました。 |
| HF が設定されています | HF が設定されていません | クロスプラットフォームコールの動作が変更されます。この変更を適用するには、ファイルが空になっている必要があります。 |
| HF が設定されていません | HF が設定されています | |
| LA および LB が設定されていません | LA または LB が設定されています | 可変長を含むフィールドにアクセスするコールの動作が変更されます。 |
| LA が設定されています | LA が設定されていません、LB が設定されました | |
| LB が設定されています | LB が設定されていません、LA が設定されています | ファイルに LOB ファイルが定義されていない場合、またはフィールドが派生ディスクリプタの親のディスクリプタの場合にのみ許可されます。可変長を含むフィールドにアクセスするコールの動作が変更されます。 |
| NB が設定されていません | NB が設定されています | |
| NC および NN が設定されました | FI、NC、NU、および NN が設定されていません | この変更の後、N1/N2 コマンドのフォーマットバッファでフィールドが必須ではなくなります。指定しない場合、フィールドには Adabas 空値が設定されます。 |
| NC および NN が設定されました | NC が設定されています、NN が設定されていません | この変更の後、N1/N2 コマンドのフォーマットバッファでフィールドが必須ではなくなります。指定しない場合、フィールドには SQL 空値が指定されます。 |
| NU が設定されています | NC が設定されています | 空の値は空値に変換されます。NU と NC は相互に排他的なので、「NC が設定されている -> NU が設定されていない」になります。 |
| NV が設定されています | NV が設定されていません | クロスプラットフォームコールの動作が変更されます。 |
| NV が設定されていません | NV が設定されています | |
| SY が設定されていません | SY が設定されています | A1、N1、および N2 コマンドの動作が変更されます。フィールドフォーマットは、SY オプションと互換性がある必要があります。既存値の妥当性を確認するチェックは行われないことに注意してください。 |
| SY が設定されています | SY が設定されていません | A1、N1、および N2 コマンドの動作が変更されます。 |
| TR が設定されていません | TR が設定されています | |
| TZ が設定されていません、DT が設定されています | TZ が設定されています、DT は変更されません | 日付/時刻の編集マスクを指定すると、データベース内の値が UTC からローカル時間に変換されます。 |
| TZ が設定されています | TZ が設定されていません | 日付/時刻の編集マスクを指定したときに、データベース内の値が UTC からローカル時間に変換されなくなります。 |
この場合のフィールド指定リストは、ADAFDU での FDT 入力と同じ方法で入力されます。
level-number, name [,length] [,format] [(,option)...]
第 1 追加フィールドはレベル 1 のフィールドとなる必要があります。
このパラメータは、フィールドを追加するファイルの FDT を表示します。
DBID = number
このパラメータは、使用対象となるデータベースを選択するためのものです。
注意:
ニュークリアスのシャットダウンを要求または許可するユーティリティ機能は、そのデータセットに対して論理割り当てを必要とします。
adadbm: dbid=76 %ADADBM-I-DBOFF, database 76 accessed offline adadbm: dbid=76 %ADADBM-I-DBON, database 76 accessed online
DEALLOCATE = keyword, FILE = number [,RABN = number],
SIZE = numberB
指定されたキーワード(AC、DS、NI または UI)に応じて、このパラメータはアドレスコンバータ(AC)、データストレージ(DS)、ノーマルインデックス(NI)、またはアッパーインデックス(UI)に与えられているスペースを解放します。
エクステントに過度のスペースが割り当てられている場合、DBA は自動または手動でこのスペースをフリースペーステーブル(FST)に戻すことができます。
割り当ての解除は、1 回の実行につき 1 つのエクステントに限定されます。複数エクステントからスペースを解放するには、DEALLOCATE を複数回コールする必要があります。
このパラメータは、ファイルを指定します。
このパラメータは、解放するスペースの最初の RABN を指定するものです。このパラメータが省略された場合には、最終エクステントの末尾からスペースが解放されます。
このパラメータは、解放するスペースのエリアの大きさをブロック単位で指定します。
adadbm: deallocate=ni, file=11, size=110b
SIZE=110B
^
%ADADBM-E-VALUP, value has to be less-equal 100
%ADADBM-I-ABORTED, 14-NOV-2002 14:44:01, elapsed time: 00:00:00
adadbm: deallocate=ni, file=11, size=100b %ADADBM-I-DEALLOC, 100 NI blocks deallocated (611 - 710) adadbm: deallocate=ni, file=11, size=10b %ADADBM-I-DEALLOC, 10 NI blocks deallocated (323 - 332)
DEFINE_REFINT = number constraint_specification
この機能は、外部キーを含むファイル number に参照制約を追加します。制約の構文は、ADAFDU の FDT ファイルで使用される構文と同じで、『管理マニュアル』の「FDT レコード構造」、「参照制約」で説明されています。この制約は、プライマリファイルの FDT にも含まれるので、制約名がプライマリファイルで定義されていないようにする必要があります。
プライマリファイルとして指定されたファイルが PGM_REFRESH = YES で定義されている場合、参照制約の追加は許可されません。
参照整合性に違反があると、制約の追加は失敗します。参照整合性を確立するための、ファイルデータに対する更新は実行されません。
DELCP = { * | ([absolute-date] [,[absolute-date]]) }
この機能は、チェックポイントファイルからチェックポイントレコードを削除します。
アスタリスク(*)が入力されると、全チェックポイントレコードが削除されます。
adadbm: delcp=13-NOV-2006:15:09:48 %ADADBM-I-DELCP, 1 record deleted from CHECKPOINT file adadbm: delcp=(13-NOV-2006:15:09:48,) %ADADBM-I-DELCP, 81 records deleted from CHECKPOINT file adadbm: delcp=(,14-NOV-2006:14:37:24) %ADADBM-I-DELCP, 41 records deleted from CHECKPOINT file adadbm: delcp=(14-NOV-2006:14:37:25,14-NOV-1996:14:38:15) %ADADBM-I-DELCP, 42 records deleted from CHECKPOINT file adadbm: delcp=* %ADADBM-I-DELCP, 20 records deleted from CHECKPOINT file
DELETE = (number [-number][,number[-number]]...)
DELETE パラメータは、データベースから 1 つのファイルまたはある範囲のファイルを削除し、フリースペーステーブル(FST)に該当ファイルが割り当てられていた全スペースを戻します。LOB ファイルが指定された場合は無視されますが、LOB ファイルが割り当てられている基本ファイルをすべて指定した場合には、その LOB ファイルも削除されます。削除するファイルと指定されていない別のファイルとの間に、参照制約が存在していない必要があります。システムファイルの削除は許可されていません。
注意:
Adabas-to-Adabas レプリケーションの使用を停止する必要があり、そのためにレプリケーションシステムファイルを削除する場合は、DELETE FUNCTION ではなく ADADBM REMOVE_REPLICATION を使用する必要があります。
ADADBM はファイル削除に対する確認要求を行いません。したがって、ファイル番号を指定する際には十分な注意が必要です。
adadbm: delete=(4-11,14) %ADADBM-I-DELETED, file 11 deleted %ADADBM-I-DELETED, file 14 deleted
DELETE_DATABASE = keyword
DELETE_DATABASE 機能は、データベースを削除します。指定されたキーワード(CONTAINER または FULL)に応じて、コンテナのみが削除されたり、データベースディレクトリとその内容が削除されたりします。
キーワード CONTAINER を指定すると、ADABAS.INI ファイルの [DB_LIST] セクションにあるコンテナファイルと DBID エントリが削除されます。キーワード FULL を指定すると、データベースディレクトリとそのすべての内容が削除されます。
adadbm: dbid=12 delete_database=container
DBID 12 のデータベースのコンテナが削除されます。
DISPLAY = UCB
DISPLAY 機能は、ユーティリティコミュニケーションブロックを表示します。また、この機能は、AUTORESTART が保留状態でも実行が可能です。
adadbm: display=ucb
Date/Time Entry Id Utility Mode Files
--------- -------- ------- ---- -----
14-NOV-2006 14:38:40 233 adaopr UTO 11
14-NOV-2006 14:38:42 234 adabck ACC *
次の項目を表示します。
[DATE/TIME]には、ファイルがロックされた日付と時刻が表示されます。
[ENTRY ID]には、エントリに割り当てられた ID が表示されます。
[UTILITY]には、ユーティリティの名前が表示されます。
[MODE]には、ファイルがアクセスされているモードが表示されます。
[FILES]には、ロックされているファイルの数が表示されます。
DROP_FIELDS = number {field_name|FDT}... [END_OF_FIELDS]
DROP_FIELDS 機能は、"number" で定義されたファイルから 1 つ以上のフィールドをドロップします。指定されたフィールドはもはや存在しないものとしてマークされ、それらにアクセスすることはできません。LOB ファイルを指定することはできません。この機能は END_OF_FIELDS の入力で完了します。
END_OF_FIELDS パラメータを使用してフィールド定義を消去する場合、LOWER_CASE_FIELD_NAMES パラメータを使用するときに、このパラメータを大文字で指定する必要があります。また、LOWER_CASE_FIELD_NAMES を使用する場合は、FDT パラメータも大文字で指定する必要があります。
グループまたはピリオディックグループを指定する場合、グループまたはピリオディックグループに属しているすべてのフィールドがドロップされます。ディスクリプタまたはディスクリプタから派生したフィールドを指定することはできません。そのようなフィールドをドロップしたい場合は、最初に対応するすべてのディスクリプタを ADAINV で解放する必要があります。
DROP_FIELDS 機能が実行された後、ドロップされたフィールドの名前を、例えば ADADBM の ADD_FIELDS 機能を使用して再定義することができます。
注意:
このパラメータは、フィールドがドロップされるファイルの FDT を表示します。
DROP_LOBFILE = number
割り当て先の LOB ファイルが空になっている LOB ファイルの基本ファイルを削除するためのファイル番号を数値で指定する必要があります。
割り当て先の LOB ファイルが空でない場合、DROP_LOBFILE は許可されません。
DROP_REFINT = number, NAME {=|:} constraint_name
この機能は、外部キーを含む number で指定されたファイルから参照制約を削除します。この制約は、プライマリファイルの FDT からも削除されます。
EXTEND_CONTAINER = keyword, SIZE = number [B|M]
EXTEND_CONTAINER 機能は、使用されたキーワードに従ってデータベース用に定義された最後のアソシエータ、データストレージ、または WORK コンテナファイルを拡張します。キーワードの値は、ASSO、DATA、または WORK です。
注意:
WORK コンテナはオフラインモードでのみ拡張することができます。
このパラメータはブロック単位(B)またはメガバイト単位(M)で拡張エリアのサイズを指定します。デフォルトでは、サイズはメガバイト単位です。
[NO]LOWER_CASE_FIELD_NAMES
LOWER_CASE_FIELD_NAMES が指定されている場合、Adabas フィールド名は、大文字に変換されません。NOLOWER_CASE_FIELD_NAMES が指定されている場合、Adabas フィールド名は、大文字に変換されます。デフォルトは、NOLOWER_CASE_FIELD_NAMES です。
このパラメータは、ADD_FIELDS、CHANGE_FIELDS、または DEFINE_REFINT パラメータの前に指定する必要があります。
NEW_DBID = number
この機能は、使用されているデータベースの ID の変更に使用されます。新しい ID は、他のアクティブデータベースによって使用されているときには、このパラメータを使用することはできません。
adadbm: new_dbid=77 %ADADBM-I-FUNC, function NEW_DBID executed
NEWWORK [,BLOCKSIZE = number[K] ], SIZE = number [B|M]
この機能では既存の WORK1 コンテナファイルが削除され、新しい WORK1 コンテナファイルで置き換わります。新規 WORK1 コンテナファイルを割り当て、その後、必要に応じてフォーマットします。
新規 WORK を作成する前に、ニュークリアスおよびデータベースを使用している全ユーティリティを正常終了させなければいけません。この機能は、現在の WORK を必要とするため、現在の WORK は NEWWORK を実行する前に削除してはいけません。この機能を使用する場合、新規 WORK ファイルには TEMP1 を指示する必要があります。
注意:
新規 WORK の参照先をディスクセクションやファイルシステムに設定できます。TEMP1 が WORK1 と同じディスクセクションをポイントする場合、ADADBM は既存の WORK ファイルを拡張/縮小しようとします。いずれの場合も、新規 WORK
コンテナファイルの名前は WORK1 です。この機能が正常に完了すると、古い WORK1 は削除されます。
新しいコンテナファイルのブロックサイズをバイト(または、K が数の後に指定される場合はキロバイト)で指定します。
Adabas は、指定された値を 1024 の倍数に切り上げます。
指定できる最小ブロックサイズは 3072 で、最大ブロックサイズは 32768 です。
これらの最小値と最大値に加えて、ASSO と WORK のブロックサイズには、通常次のサイズ制限が適用されます。
MAX (ASSOBLS) < WORKBLS
MAX(ASSOBLS) は、ASSO の最大ブロックサイズを表わし、WORKBLS は WORK ブロックサイズを表わします。
BLOCKSIZE に対するデフォルト値は、古い WORK ファイルのブロックサイズです。
このパラメータは、新規 WORK ファイルに対して割り当てられるブロック数またはメガバイト数を指定するものです。デフォルトでは、サイズはメガバイト単位です。最小値は 200 ブロック、またはメガバイト単位での同等の値です。
PGM_REFRESH = keyword, FILE = number
このパラメータは、アプリケーションプログラムの E1 コマンド(ISN=0、CID=空白)で Adabas ファイルをリフレッシュ可能にしたり、不可能にしたりします。LOB ファイルを指定することはできません。キーワードには、YES または NO を指定します。参照制約のプライマリファイルとなっているファイルには、PGM_REFRESH = YES を設定できません。
このパラメータには、リフレッシュを可能/不可能にするファイル番号を指定します。
RBAC_FILE = number
この機能は RBAC システムファイルを作成し、初期セキュリティ定義をロードします。
adadbm: rbac_file=200
RECOVER
この機能は、アソシエータまたはデータストレージ内の失われたスペースをフリースペーステーブル(FST)に戻します。
スペースは、Adabas ユーティリティが正常終了しないと失われます。
adadbm: recover %ADADBM-I-FUNC, function RECOVER executed
REDUCE_CONTAINER = keyword, SIZE = number B
REDUCE_CONTAINER 機能は、使用されたキーワードに従って、データベースに定義されたアソシエータまたはデータストレージコンテナ末尾のフリースペースを割り当て解除します。キーワードに使用できる値は、ASSO または DATA です。
縮小する分のブロック数は、指定したコンテナの最後の部分では使用されていない必要があります。1 つ以上のコンテナエクステントのスペース全体を解放すると、そのコンテナエクステントは削除されます。ADADBM をオンラインで実行している場合、ADADBM は、コンテナエクステントが削除されることを通知するメッセージを表示しません。このメッセージはニュークリアスログに出力されます。
コンテナの末尾にあるフリースペースが、要求されたブロックよりも少ない場合、コンテナの末尾にあるすべてのフリースペースが割り当て解除され、次の警告が表示されます。
%ADADBM-W-PREDCONT, not all requested blocks removed
このパラメータは、コンテナを減らすサイズをブロック単位で指定します。
REFRESH = (number [-number][,number[-number]]...)
この機能は、"number" に指定されたファイルをレコードがロードされていない状態にリセットします。ノーマルインデックス、アドレスコンバータおよびデータストレージに対する最初のエクステントだけは保持されます。その他のエクステントはフリースペーステーブル(FST)に戻されます。アッパーインデックスは再構築され、未使用のアッパーインデックスのエクステントはフリースペーステーブルに戻されます。LOB ファイルが指定された場合は無視されますが、LOB ファイルが割り当てられている基本ファイルをすべて指定した場合には、その LOB ファイルもリフレッシュされます。参照整合性制約のプライマリファイルは、参照制約の外部ファイルもリフレッシュされている場合にのみリフレッシュできます。
ADADBM は、リフレッシュされるファイルの確認を要求しません。したがって、ファイル番号を指定する際には十分な注意が必要です。
この機能は、テスト環境でのテストファイルをクリアする場合に便利です。ファイルを削除してから再びロードするよりもこの方法のほうが効率的です。
ADAM 機能を使用しているファイルはリフレッシュできません。
REMOVE_DROP 機能が設定されている場合、ドロップするフィールドは FDT から削除されます。
adadbm: refresh=13 %ADADBM-I-REFRESH, file 13 refreshed
REMOVE_CONTAINER = keyword
この機能は、使用されるキーワードに従って最後のデータベースコンテナファイルを既存のアソシエータまたはデータストレージデータセットから削除します。キーワードに使用できる値は、ASSO または DATA です。
削除対象のコンテナファイルは、この機能が実行されるときに使用中であってはいけません。すなわち、ファイル内のすべてのブロックがフリーでなければいけません。
コンテナファイルは、ファイルシステムからまたは RAW ディスクセクションから削除されます。
コンテナファイルが削除できるためには、ニュークリアスおよびデータベースを使用しているすべてのユーティリティが正常に終了していなければなりません。
注意:
コンテナを削除すると、DBnnn.INI ファイル内で、このコンテナファイルに対応するエントリが削除されます。
adadbm: remove_container=data %ADADBM-I-DMCONREM, container DATA2 removed
[NO]REMOVE_DROP
REMOVE_DROP を指定すると、後続の REFRESH 機能がドロップされたフィールドを FDT から削除します。
NOREMOVE_DROP を指定すると、後続の REFRESH 機能はドロップされたフィールドを FDT から削除しません。
デフォルトは NOREMOVE_DROP です。
adadbm: remove_drop adadbm: refresh=2 %ADADBM-I-REFRESH, file 2 refreshed adadbm: refresh=3 %ADADBM-I-REFRESH, file 3 refreshed adadbm: noremove_drop adadbm: refresh=4 %ADADBM-I-REFRESH, file 4 refreshed
ファイル 2 はリフレッシュされ、ドロップされたフィールドは FDT から削除されました。ファイル 3 はリフレッシュされ、ドロップされたフィールドは FDT から削除されました。ファイル 4 はリフレッシュされ、ドロップされたフィールドは FDT から削除されませんでした。
REMOVE_REPLICATION
この機能は、すべてのレプリケーション処理を停止し、すべてのレプリケーションシステムファイルを削除します。
注意:
この機能は、Adabas を搭載した Event Replicator(Adabas レプリケーション)を使用している顧客にのみ関連します。
RENAME = number, NAME {=|:} string
この機能は、ファイルまたはデータベースの名前を変更します。number には名前の変更を行うファイル番号を指定します。number にゼロを指定すると、データベース名が変更されます。
"string" の部分には、指定したファイルまたはデータベースの新しい名前を指定します。等号を指定する場合、「文字列」に指定された値が大文字に変換されます。コロンを指定した場合、大文字の変換は実行されません。
adadbm: rename=11, name=employee-file %ADADBM-I-FUNC, function RENAME executed
RENUMBER = (number, number)
この機能は、ロードされた Adabas ファイルのファイル番号を変更します。しかし、そのファイルの新しい番号がロード済みファイルに使用されていた場合には、そのファイル間でファイル番号の交換が行われます。
指定部分の最初の number には、現在ファイルに割り当てられている番号を指定します。そして 2 番目の number には、新たにファイルに割り当てる番号を指定します。
adadbm: renumber=(12,14) %ADADBM-I-RENUM, File 12 renumbered to 14 %ADADBM-I-RENUM, File 14 renumbered to 12
REPLICATION_FILES = (file1, file2, file3, file4)
この機能は、Adabas-Adabas レプリケーションに必要なすべての初期化ステップを実行し、レプリケーションシステムファイルを作成します。
注意:
RESET = UCB, IDENT = { (number [,number]...) | * }
この機能は、1 つまたは複数のエントリをユーティリティコミュニケーションブロック(UCB)から削除するものです。またこのオプションは、AUTORESTART が保留状態でも使用することができます。
UCB は、データベース内の特定のリソース(データベース全体、1 つまたは複数のファイル等)へのアクセスを制御するのに使用されます。また UCB は、Adabas ユーティリティのデータベース処理および、ユーティリティが関与するリソース関連の情報のセーブを行います。
エントリは、ユーティリティのリソースへのアクセスが認められるごとに UCB 内に作成されます。このエントリには、ユーティリティおよびユーティリティがロックするリソースに関する情報が含まれます。リソースが必要なくなると、ユーティリティは自動的にエントリを削除します。UCB の内容の表示方法については、このユーティリティの DISPLAY=UCB の記述部分を参照してください。
ある特別な状況においては(ADAMUP の異常終了など)、UCB 内にエントリが残り、リソースがロックされたままとなります。しかし、この RESET 機能を使用し、UCB から 1 つないし複数のエントリを削除することにより、そのリソースは解放されます。
UCB エントリをリセットすると、ユーザーキューから関連するエントリを取り除き、ニュークリアスがアクティブな場合、フリースペーステーブルに失われたブロックを返します。その他の場合は、RECOVER 機能を使用すれば、リソースをフリースペーステーブルに返すことができます。
このパラメータは、削除対象となるエントリの固有 ID を指定します。アスタリスク(*)を指定すると、すべてのエントリが削除対象となります。
RESET UCB 機能をオフラインで使用する場合、* だけを指定することができます。
adadbm: reset=ucb, ident=233 %ADADBM-I-RESUCB1, 1 entry deleted from UCB adadbm: reset=ucb, ident=(235,234) %ADADBM-I-RESUCB, 2 entries deleted from UCB adadbm: reset=ucb, ident=* %ADADBM-I-RESUCB1, 1 entry deleted from UCB
RESET_REPLICATION_TARGET = number
この機能は、Adabas ファイルのレプリケーションターゲットフラグをリセットします。その後に、再び通常のファイルとして処理されます。0 を指定すると、すべてのレプリケーションターゲットファイルのレプリケーションターゲットフラグがリセットされます。ファイル番号を指定すると、このファイル番号を持つファイルのレプリケーションターゲットフラグがリセットされます。
注意:
REUSE = (keyword [,keyword]), FILE = number
REUSE 機能は、Adabas によるデータストレージスペースまたは ISN の再利用を制御します。
指定したファイルのファイルコントロールブロック(FCB)は、新規レコードの追加または更新レコードの移動時に使用される割り当て方法を指示するように修正されます。
有効なキーワードは、[NO]DS および [NO]ISN です。
DS キーワードを指定すると、Adabas は十分なスペースを持つブロックを割り当てるために、データストレージスペーステーブル(DSST)を検索します。この場合、最初に検索された十分なスペースを持つブロックが使用されます。
NODS キーワードは、新たに追加されたレコードすべてと別のブロックに移動するレコード(更新によってレコードの拡張が発生した場合)をまとめて、ファイルに割り当てられたデータストレージエクステント内の最終使用ブロック内に移動させます。このブロックに十分なスペースがない場合、次のブロックが使用されます。
DS と NODS は相互に排他的です。デフォルトは REUSE = DS です。
ISN キーワードを設定すると、Adabas は新規レコードに対して削除レコードの ISN を再利用します。
NOISN を設定すると、Adabas は削除レコードの ISN を新規レコードに対して再利用しません。新規レコードにはそれぞれ次に大きい未使用 ISN が割り当てられます。
NOISN と ISN は相互に排他的です。デフォルトは REUSE = NOISN です。
このパラメータは、ファイルを指定します。
adadbm: reuse=nods, file=11 %ADADBM-I-FUNC, function REUSE executed adadbm: reuse=(ds,isn), file=12 %ADADBM-I-FUNC, function REUSE executed
SECURITY = keyword
SECURITY 機能は、データベースのセキュリティモードを設定します。キーワードは、ACTIVE または WARN のいずれかになります。
ACTIVE キーワードは、セキュリティ機能を有効にします。ACTIVE は、承認されたユーザーのみがデータベースにアクセスできることを意味しています。認証エラーなどのセキュリティ違反は、監査証跡で「エラー」として処理されます。
セキュリティ違反の場合、データベースへのアクセスは拒否されます。
重要:
データベースセキュリティを有効にした後は、セキュリティを無効にできなくなります。
WARN キーワードは、セキュリティ機能を有効にします。WARN は、すべてのユーザーがデータベースにアクセスできることを意味しています。認証エラーなどのセキュリティ違反は、監査証跡で「警告」としてプロトコル化されます。セキュリティ違反の場合、データベースへのアクセスは拒否されません。
このモードは、セキュアデータベースを使用するためにアプリケーションを移行することを意図しています。「ニュークリアスユーザー出口 21」も参照してください。
重要:
セキュリティモード WARN は、モード ACTIVE にのみ変更できます。
WARN キーワードは、セキュリティ機能を有効にします。WARN は、すべてのユーザーがデータベースにアクセスできることを意味しています。認証エラーなどのセキュリティ違反は、監査証跡で「警告」としてプロトコル化されます。セキュリティ違反の場合、データベースへのアクセスは拒否されません。
このモードは、セキュアデータベースを使用するためにアプリケーションを移行することを意図しています。「ニュークリアスユーザー出口 21」も参照してください。
重要:
セキュリティモード WARN は、モード ACTIVE にのみ変更できます。
デフォルトでは、セキュリティは有効になっていません。
SYFMAX = number, FILE = number
このパラメータは、指定されたファイル内のシステム生成マルチプルバリューフィールドに対して、生成される値の最大数を指定します。明示的な最大値はありませんが、値が高く定義されると、レコードオーバーフローが発生することに注意してください。圧縮データレコードは 1 つの DATA ブロック内に収まる必要もあり、SYFMAX 値がシステム生成マルチプルバリューフィールドに対して定義されています。SYFMAX 値が下げられ、この新しい値よりも、レコードに含まれるシステム生成フィールド値の数が多くなった場合は、このレコードの次の更新処理で余分な値が削除されます。
このパラメータは、ファイルを指定します。
ADADBM は再スタート機能を備えていません。しかし、各機能の終了に際してシステムは、その機能が正常終了したかどうかを調査します。正常終了しなかった場合には、その機能は再スタートする必要があります。