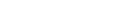
このドキュメントでは、次のトピックについて説明します。
Adabas データベース内のデータにアクセスするプログラムは、Adabas コマンドを発行する必要があります(詳細については、『コマンドリファレンスセクション』を参照してください)。Adabas ダイレクトコールコマンドインターフェイスは、下位レベルのインターフェイスです。そのため、Software AG は、次のような Adabas への上位レベルのインターフェイスもいくつか提供しています。
開発環境 Natural:このプログラミング言語に、Adabas へのアクセスが統合されています。
Adabas SQL Gateway:Adabas 用の SQL インターフェイスです。
Adabas SOA Gateway:サービス指向アーキテクチャ(SOA)への Adabas インターフェイスです。
Adabas コマンドを発行するプログラムは、Adabas クライアントと呼ばれます。Adabas コマンドは、Adabas ニュークリアスと呼ばれるデータベースサーバーによって実行されます。
データベースにアクセスするには、Adabas クライアントを Adabas インターフェイスとリンクする必要があります。Adabas インターフェイスとして、例えば、Adabas クライアントパッケージに含まれている Adabas インターフェイスがあります。詳細については、『コマンドリファレンス』の「アプリケーションプログラムのリンク」を参照してください。
Adabas クライアントは、Adabas ニュークリアスと同じ(物理または仮想)マシンでローカルで実行することも、別のマシンでリモートから実行することもできます。リモートアクセスには、追加の製品 Entire Net-Work が必要です。
Adabas ニュークリアスに加えて、Adabas データベースにアクセスする、データベース管理用の Adabas ユーティリティも多数用意されています。
次の図は、プログラムが Adabas にアクセスする方法を示しています。
注意:
データベースコンテナは、別のストレージサーバーに保存することもできます。
注意:
データベースコンテナには、別のマシンからアクセスできます。ただし、データベースの一貫性は、データベースのデータベースコンテナに同時にアクセスしているすべてのユーティリティおよびニュークリアスプロセスが、同じマシン上で実行されている場合にのみ保証されます。これは、ユーティリティプロセスとニュークリアスプロセスの同期に、同じマシン上でのみ表示できる IPC リソースが使用されていることが理由です。例外は、データベースコンテナにはアクセスせず、特別なリモート Adabas コールを実行するリモートユーティリティです。データベースのすべてのユーティリティおよびニュークリアスプロセスが終了したら、別のマシンでデータベースプロセスを再起動できます。ただし、データベースのデータベースプロセスが古いマシン上でアクティブであるときに、新しいマシンでデータベースプロセスを開始しないようにするのは、データベース管理者の責任です。これは、Adabas
によってはチェックされません。
システムのパフォーマンスの判断基準は、実行に必要な時間とコンピュータリソースです。これらは次のような理由から重要です。
指定時間内で完了しなければならないシステム機能がある場合
厳しい時間制約のある他のシステムと、コンピュータリソースの競合が起こる場合
ただし、パフォーマンスが最も重要な目標であるとは限りません。パフォーマンスと次の項目のどちらを優先するかについてよく考える必要があります。
柔軟性
データ独立性
情報のアクセスし易さ
セキュリティに関する考慮
情報が最新であること
スケジュールのしやすさ、データベースの同時使用ユーザー数の影響
ディスクスペース
パフォーマンスが、最適化すべき目標ではなく制約になる場合もあります。システムは時間やボリュームの問題が生じたとき、パフォーマンスよりは他の項目に注意を向けるべき場合もあり得ます。
十分なパフォーマンスを実現できるかどうかは、次に掲げる事項の完成度にかかっていると考えられます。
ハードウェアの設計
データベースの設計
データベースにデータをロードするときに使用するオプション
アプリケーション機能のロジック(例えば、ダイレクトアクセスを使用するか、ソートと順次処理を組み合わせるか)
オペレーション手順とスケジューリング
どの程度のパフォーマンスが必要かはシステム設計段階の早い時期に考慮しなければなりません。パフォーマンスを制御するうえでの基本要件として、次の事項を確認します。
主なシステム機能について、ユーザーに時間の制約を聞きます。大半の場合、この要求事項は絶対的なものです。すなわち、この制約が満たされないと、システムは使用することができません。
他のデータベースで試したり、予期される負荷をシミュレーションしたりして、利用可能なハードウェアリソースが十分であるかどうか評価します。新しいハードウェアが必要な場合、次の事項を考慮します。
処理速度の速い高価な数台程度のハードウェアを組み合わせて使用するか、処理速度は比較的低速でも安価なハードウェアを何台も組み合わせて使用するかを決定する必要があります。通常、ハードウェアを何台も組み合わせて使用すると、低予算で大規模な計算能力を得ることができますが、これは、並列処理を使用する意味がある場合に限られます。同時使用ユーザー数がある程度以上であれば、このようなハードウェアを使って並列処理する意味がありますが、主にバッチプログラムを順次実行し、並列処理の必要性がない場合には、Adabas を並列処理する意味はあまりありません。
ハードウェアスレッドを複数のソケットに分散できます。さらに、ソケットを複数のボードに分散できます。このようにした場合、異なるソケットに接続されているハードウェアスレッド間で同期にかかる時間は、同じソケットに接続されている場合よりも大幅に長くなる可能性があります。データベースブロックがバッファプールから読み取られる場合は、各データベースコマンドが複数のデータベースブロック(インデックスとデータブロック、アドレスコンバータ、ファイルコントロールブロック、フィールド記述テーブル)を読み込む必要があるので、常に同期が必要です。スレッドを追加することによる処理能力向上の利点は、追加のスレッドが別のソケットまたはボードにある場合には同期時間が長くなり、打ち消される可能性があります。
もう 1 つの問題は、メモリが通常複数のソケットに分散されていることです。ソケット自体のメモリへのアクセスは比較的高速ですが、別のソケットに属するメモリへのアクセスは比較的低速です。特に、別のボードに配置されている場合はさらに低速になります。ハードウェアにもよりますが、リモートメモリへのアクセスには、ローカルメモリへのアクセスよりも、時間が約 3 倍かかります(NUMA アーキテクチャ:不均一メモリアクセス)。
したがって、ADANUC は、同じソケットまたはボード上のハードウェアスレッドに制限する必要があります。これは、特殊なオペレーティングシステムコマンドを使用するか、オペレーティングシステム仮想化のコンセプトを使用して実現できます。通常、この方法でパフォーマンスが向上します。同期コストの削減とローカルメモリへのメモリアクセスの高速化は、並列処理を増やすことによる利点よりも大きくなります。
このような最新のアーキテクチャでパフォーマンスを向上させるために、Adabas は Adabas 処理ユニット(ADANUC パラメータ APU)のコンセプトを使用しています。ここでは、1 つの Adabas 処理ユニット(APU)は、コマンドキューとコマンドが処理される専用のスレッドで構成されます。オペレーティングシステムが、1 つの APU に属するスレッドがグループになっていることを認識し、それらを同じソケット/ボード上にスケジュールすると、完全なニュークリアスプロセスを 1 つのソケット/ボードにバインドするよりも、パフォーマンスが向上する場合があります。1 つのソケットで完全なニュークリアスプロセスが実行されている場合は、APU コンセプトを使用すると、パフォーマンスが向上する場合があります。これは、複数のコマンドキューを使用すると、1 つの大きなコマンドキューを使用した場合と比較して、ロックの競合数が減少することが理由です。
ただし、Software AG では、CPU バインディングと APU 使用率の最適な構成を推奨できません。これは、オペレーティングシステムによる差異や、ハードウェア実装による差異が大きすぎるからです。また、APU を使用してもまったくメリットがない場合もあります。お使いのハードウェア環境で異なる設定を試し、データベースのロードで最善の結果が得られる設定を選択することをお勧めします。
最新のストレージシステムの使用を考慮します。最新のストレージシステムを使用することにより、ディスクの故障によるダウンタイムを回避でき、良好なパフォーマンスを得ることができます。
また、「データベース設計」、「リカバリ/再スタート設計」、「データベースコンテナ、バックアップファイル、およびプロテクションログの場所」の各セクションも検討してください。
Adabas コンテナは、高可用性のクラスタ内に収容することができます。ただし、Adabas はこのクラスタを直接サポートしません。ユーザーが独自のスクリプトを記述する必要があります。クラスタ内のロードバランシングはサポートされません。
論理設計モデルの観点から、次の事項を明確化します。
各レコードタイプの処理方法
レコードを検出する場合のシーケンスとアクセスパス
実行頻度とボリューム
稼動時間
最も重要なパフォーマンスを持つプログラムを決定します。このとき、他のシステムのスケジューリングやパフォーマンスに関する影響、ボリューム、頻度、期限などについて考慮します。他のプログラムも最低限のパフォーマンス要求を持つことがあり、重要な機能の最適化の幅も狭まることがあります。
重要な機能それぞれについて、アクセスパスの短縮化、ロジックの最適化、オーバーヘッドを増加させるようなデータベース機能の削除などで、パフォーマンスを最適化します。第 1 段階では、柔軟性、情報へのアクセスのしやすさ、またはシステムの他の機能要件のレベルを下げずに、パフォーマンスがどうやって最適化するかを試行錯誤する必要があります。
重要な各機能のパフォーマンスを推定します。この推定値が満足のいくものでないときは、時間の制約か機能に対する要求を少しゆるめるよう調整するか、ハードウェアをアップグレードする必要があります。
その他のシステム機能のパフォーマンスを推定します。総費用を計算し、金銭上の制約と、費用やリソース要求のピーク期間とを比較します。この推定値が制約を満たさないと、ユーザー、オペレーション部門またはシニアマネージメントと調整を行い、解決しなければなりません。
可能な場合、テストデータベースをロードし各種機能の時間を計測して、推定値をチェックします。テストデータベースのファイル内のレコード数やディスクリプタの値の数は、実際に運用するときのデータベースと同程度にする必要があります。各レコード長は、順次処理のテスト以外ではあまり重要ではありません。これは、レコードを物理順に近い形で処理するときのみ重要になります。
Adabas は International Components for Unicode(ICU)ライブラリ(V3.2)に基づいて Unicode をサポートします。ICU の詳細については、https://www.ibm.com/software/globalization/icu にアクセスして ICU ホームページを参照してください。ワイド文字フィールドフォーマット(W)は Unicode フィールドのために導入されています。Adabas ユーザーは、Adabas コールまたは圧縮と圧縮解除のユーティリティ ADACMP と ADADCU を使用する際にどの外部エンコードを使用するかを指定できますが、内部的には、すべてのデータは UTF-8 で格納されます。
外部エンコードは次で指定することができます。
Adabas OP コマンド(Adabas セッションのデフォルトエンコードを指定することができます)
フォーマットバッファとサーチバッファ(フィールドレベルでエンコードを指定することができます)
ユーティリティ ADACMP および ADADCU(ユーティリティの実行中に使用されるデフォルトエンコードを指定することができます)
検索やソート処理の場合、Unicode バイトの順序は通常それほど重要というわけではありませんが、言語固有の照合は重要です。この理由のために、Adabas は照合ディスクリプタをサポートします。Unicode 照合アルゴリズムと言語固有の規則を適用することによって、照合ディスクリプタはオリジナルの文字列からバイナリの文字列を生成します。
Unicode 文字セットを使ってアプリケーションを作成し、メインフレームと UNIX/Windows の両方のプラットフォームでアプリケーションを実行するつもりであれば、次の点を考慮する必要があります。
テキストフィールドに W フォーマットを使うことを推奨します。A フォーマットを使用した方がよいケースは、値を構成している文字がどれも ASCII と EBCDIC に該当する場合、ASCII と EBCDIC の照合に関連性がない場合、照合ディスクリプタが必要ない場合に限定されます。
メインフレームでは、ユーザーが内部エンコードを選択することができますが、UNIX/Windows プラットフォームでは、すべての W フォーマットフィールドは UTF-8 として内部的に格納されます。文字列の長さはそのデコードに依存するので、メインフレームの内部エンコードにも UTF-8 を使用するか、他のプラットフォームの内部エンコードでも、アプリケーションが格納する値がオーバーフローする可能性がないことを確認する必要があります。
メインフレームでは、W フォーマットフィールドは ECS に基づきますが、UNIX/Windows プラットフォームでは、それらは ICU に基づきます。したがって、すべてのプラットフォームで利用可能なエンコードだけを使用する必要があります。
UNIX/Windows プラットフォームでは、照合ディスクリプタは ICU に基づきますが、メインフレームでは、ユーザーは、照合ディスクリプタを生成するためのユーザー出口を用意しておく必要があります。これらのユーザー出口は、UNIX/Windows プラットフォームで使用される ICU 照合と互換性のある照合順序を生成しなければなりません。UNIX/Windows のプラットフォームでは、メインフレーム上と同じ動作を実現するために HE オプションを使用する必要があります。
メインフレームと UNIX/Windows プラットフォームでの Adabas ダイレクトコマンドは、W フォーマットフィールドの取り扱いについて完全に互換性があるわけではありません。互換性のあるコマンドだけがクロスプラットフォームアプリケーションに使用されることを保証する必要があります。
概念設計段階で分けたレコードタイプ 1 つずつに、ファイルを 1 つずつ対応付けながら、Adabas データベースを設計することも可能です。このような構成にしておくと、さまざまなアプリケーション機能要件に対応可能になり、予想外の要求がでてきても取り扱いが簡単になる反面、次のような理由から、パフォーマンスという観点からみると必ずしも最良とはいえません。
Adabas の呼び出し回数が増えます。Adabas の呼び出しごとに、解釈、整合チェックおよびオーバーヘッドのキューイングが必要になります。
それぞれのファイルから、最低、1 回は、インデックス、アドレスコンバータおよびデータストレージブロックにアクセスします。この処理に必要な入出力に加えて、バッファプールスペースが必要であり、後で発生する要求に必要なブロックが上書きされる可能性が高くなります。
したがって、重要なプログラムが使用する Adabas ファイルの数を減らした方がよい場合があります。それには、次のような手法を使用します。
マルチプルバリューフィールドとピリオディックグループを使用します。
単一の Adabas ファイルで複数のレコードタイプを使用します。
データの重複を制御します。
これらの各手法については、後述します。
次の例では、注文項目は注文ファイルのピリオディックグループとして定義されています。注文項目の繰り返し数は、各レコードによって異なります。
Order Order Date Customer Item
Number Date Required Number Code Quantity
A1234E 29MAR 10JUN UK432M 24801K 200 1ST OCCUR.
30419T 100 2ND OCCUR.
273952 300 3RD OCCUR.
マルチプルバリューフィールドまたはピリオディックグループは、メインレコードを呼び出しと入出力を行う際に、同時に検索/更新の対象にすることができます。その結果、CPU タイムが短縮され、入出力回数も少なくて済みます。
マルチプルバリューフィールドやピリオディックグループの使用法に関して、注意が必要な制約を次に示します。
ピリオディックグループの中に別のピリオディックグループを含むことはできません。
1 オカレンスの圧縮後のサイズによっては、レコードサイズが極端に大きくなることがあり、Adabas がサポートする最大レコード長より大きなレコード長になることもあります。
ピリオディックグループ内のディスクリプタや、ピリオディックグループ内のフィールドに基づいているディスクリプタは、FIND や SORT コマンドのソートキーとしては使用できません。さらに、マルチプルバリューフィールドとして定義されているディスクリプタや、ピリオディックグループ内に含まれているディスクリプタをいくつか対象とする検索要求には、決まった規則が適用されます。この規則については、『コマンドリファレンスマニュアル』に記述されています。
ファイル数を減らすもう 1 つの方法に、同一 Adabas ファイルに 2 つの論理レコードタイプのデータを格納するという方法があります。例えば、下図の「複数のレコードタイプ(1)」に示す顧客ファイルと注文ファイルとを組み合わせる方法です。この方法は、Adabas の空値省略機能の利点を活用しています。
組み合わせたファイルについてのフィールド定義テーブル内のフィールドには、次のものがあります。
Key, Record Type, Order Data, Order Item Data
格納されるレコードは、次の形式です。
Key Type Order Data *
Key Type * Order Item Data
* は空値省略を示しています。
注文項目レコードのキーは、注文番号とこの注文内のシーケンス番号から構成されます。
この手法では顧客レコードと注文レコードタイプがコントロールブロックと上位レベルのインデックスブロックを共用するので、入出力回数を減らすことができます。したがって、ファイルの処理を開始するために読み込むブロック数も減り、空きスペースが増えるため、バッファプールには別タイプのブロックを読み込むことができます。
顧客レコードと注文レコードは、データストレージにいっしょにグルーピングされるので、ある顧客に対するすべての注文を検索するとき読むブロックを減らすことができます。顧客と同時に全注文を追加するときも、必要な入出力回数は減ります。
顧客データと注文データのどちらにも効率良くアクセスできるように、キーの設計は注意して行わなければなりません。顧客レコードのキーには、通常、空値の接尾辞を入れて、そのレコードに付加される同じ顧客の注文をそれぞれ区別できるようにします(下図「複数のレコードタイプ(2)」参照)。
A00231 000 Order header for order A00231 A00231 001 Order item 1 A00231 002 Order item 2 A00231 003 Order item 3 A00232 000 Order header for order A00232 A00232 001 Order item 1
キーの接尾辞の内容から、顧客レコードか注文レコードかプログラムが区別できる場合には、レコードタイプフィールドは不要です。プログラムは、追加フィールドを読み取るためにレコードを読み直すか、そうでなければ、Adabas にすべてのレコードタイプに関して全フィールドを返す必要があります。
詳細レコードへのアクセス時に、ほぼ毎回、ヘッダーレコード内のいくつかのフィールドが必要になる場合があります。例えば、請求書を作成する場合、注文項目データと製品レコードの一部である製品の記述が必要です。この情報がプログラムで迅速に使用できるようにする最も簡単な方法は、注文項目データ内に製品記述情報のコピーを持つことです。すでに、他で物理的に存在するデータを重複して持つので、これを物理的重複といいます。
各詳細レコードのフィールドをいくつかヘッダーレコード内にピリオディックグループとして格納した場合にも、物理的重複として成立します。
クレジット制御ルーチンが、顧客に送付する請求書に合計が必要な場合を仮定します。この情報は関連する請求書を読み取り、それらを合計して求めることができますが、大量のレコードにランダムにアクセスする必要があります。この情報が顧客レコード内に常に格納され、正しく更新されていればもっと迅速に得ることができます。これを論理的重複といいます。重複した情報は他の場所に存在しているわけではなく、別のレコードの内容として存在しているからです。
物理的または論理的に重複している情報を更新するプログラムでは、重複しているデータも更新しなければならないので実行速度は遅くなります。物理的重複の場合は、通常、更新頻度の少ないフィールドによって大きな問題が起こることはほとんどありません。論理的重複では、たいていの場合 1 レコードの変更が他の何レコードかのデータに影響するので、更新も重複して行わねばなりません。
Adabas ファイル構造が決まったら、次はファイルのフィールド定義テーブルを定義します。フィールド定義の入力方法については、「FDT のレコード構造」を参照してください。このセクションでは、フィールドに使用できるオプションとパフォーマンスとの関係について説明します。
フィールドは、読み取りや更新の頻度の高い順に、レコードの先頭になるべく近い位置から並べます。これによって、レコードのフィールドを探すために必要な CPU 時間を短縮できます。読み取られることはほとんどありませんが、主に検索条件として使用されるフィールドは、最後の方に配置します。
グループを使用すると、読み込みや更新コマンドの内部処理の効率が良くなります。すなわち、フォーマットバッファが短くなるので処理時間の節約になり、Adabas が保持する内部フォーマットバッファプールのスペースが少なくて済みます。
数値フィールドは、最も頻繁に使用するフォーマットにロードします。こうすれば、必要になるフォーマット変換が最小限になります。ただし、節約される CPU 時間と必要なディスクスペースの関係を考慮しなければなりません。
固定ストレージ(FI)オプションを使用すると、通常、フィールドの処理時間は短縮されますが、必要なディスクスペースは増えます。特に、ピリオディックグループ内にフィールドが含まれている際は増えます。NU フィールドは、できるだけまとめる必要があります。FI フィールドは、できるだけまとめる必要があります。
各 Adabas 基本レコードを 1 つのデータブロックに納めることが重要です。データブロックの最大サイズは 32KB です(ブロックサイズの詳細については、「コンテナファイル」を参照)。Adabas フィールドに必要なスペースの詳細については、「ディスクスペースの使用法」を参照してください。Adabas フィールドに必要なスペースに加えて、各データブロックに 4 バイトおよび各 Adabas レコードに 6 バイトが必要です。
通常、各 Adabas レコードは 1 つのデータブロック内に収まらなければなりません。ただし、例外として、253 バイトを超える値(いわゆるラージオブジェクト値、LOB 値)は、別の内部 Adabas ファイル(相互に関連付けられた LOB ファイル)に格納されます。元の Adabas ファイルは基本ファイルと呼ばれ、基本ファイル内のレコードは基本レコードと呼ばれます。LOB ファイル内のレコードは、LOB レコードと呼ばれます。LOB 値には、次の規則が適用されます。
Adabas ファイルと関連付けされた LOB ファイルが存在しない場合、すべての値は基本レコードに格納されます。この場合、最大フィールド長は、16381 バイトに制限されます。
LOB フィールドがディスクリプタまたは派生ディスクリプタの親フィールドである場合、フィールド値は常に基本レコードに格納され、最大フィールド長は 16381 バイトに制限されます。
それ以外の場合、253 バイトまでの値は常に基本レコードに格納され、253 バイトを超える値は LOB ファイル内の 1 つ以上の LOB セグメントレコードに格納されます。この場合、基本レコードには 16 バイトの LOB 値参照が代わりに含まれます。
次の表は、Adabas のドキュメントで LOB 値と関連して使用される用語の概要を示しています。
| 用語 | 定義 |
|---|---|
| 基本ファイル | 1 つ以上の LOB フィールドが含まれたユーザー定義の FDT を持つ Adabas ファイルです。 |
| 基本レコード | 基本ファイル内のレコードです。このレコード内の LOB 値は、LOB ファイル内の LOB セグメントレコードを指し示す LOB 値参照により表現されます。実際の LOB 値はこれらのセグメントレコード内に含まれます。 |
| LOB | ラージオブジェクト。初期状態では、Adabas の LOB 値は最大約 2 GB(理論値)です。 |
| LOB フィールド | LOB 値を格納する、Adabas ファイルの新しいタイプのフィールドです。 |
| LOB ファイル | 定義済みの FDT を持つ Adabas ファイルです。1 つ以上の LOB セグメントレコードに LOB 値が分散して格納されます。 |
| LOB ファイルグループ | 基本ファイルと LOB ファイルで構成される組み合わせです。単一のユニットとして表示されます。 |
| LOB セグメント | パーティション分割された LOB 値の一部分です。LOB 値は、1 つ以上の LOB セグメントで構成されます。 |
| LOB セグメントレコード | LOB ファイル内のレコードです。ペイロードデータとして LOB セグメントを、制御データとしてその他の情報を含みます。 |
| LOB 値 | LOB のインスタンスです。 |
| LOB 値参照 | 基本レコードから、分割された LOB 値が含まれる LOB セグメントレコードへの参照またはポインタです。 |
次のタイプの LOB フィールドを定義できます。
バイナリ型ラージオブジェクト(BLOB):これらの LOB フィールドは、フォーマット A(英数字)と次のオプションで定義されます。LB(16381 バイトを超える値がサポートされています)、NB(値の最後の空白は切り捨てられません)、NV(オープンシステムプラットフォームとメインフレームプラットフォーム間で ASCII/EBCDIC 変換を行わないバイナリ値)。
文字型(ASCII/EBCDIC)ラージオブジェクト(CLOB):これらの LOB フィールドは、フォーマット A とオプション LB で定義されますが、オプション NB と NV は指定しません。さらに、フィールドオプション MU、NC、NN、NU を、これらのオプションの通常の規則を使用して定義できます。LOB フィールドはピリオディックグループのメンバとして定義することもできます。
注意:
Adabas ニュークリアスは、内部の Adabas ファイル(いわゆる Adabas システムファイル)を使用して内部データを保存します。これに対し、チェックポイントファイル、セキュリティファイル、およびユーザーデータファイルは、Adabas データベースで常に必要で、データベースの作成時に定義されます。レプリケーションシステムファイルは、Adabas-to-Adabas レプリケーションの初期化時にのみ作成されます。詳細については、「Adabas-to-Adabas(A2A)レプリケーション」セクションを参照してください。RBAC システムファイルは明示的に定義した場合にのみ作成されます。詳細については、「Adabas ユーティリティの認可(モード Adabas)」セクションを参照してください。
次の Adabas システムファイルが存在します。
Adabas チェックポイントファイルは、いくつかの重要なイベントである Adabas チェックポイントを記録するために使用されます。これらのチェックポイントは、次の場合に書き込まれます。
Adabas ユーティリティの実行
ニュークリアスの起動と停止
Adabas ファイルへの排他的アクセス権を持つ Adabas ユーザーセッション
ユーザー定義のチェックポイント
チェックポイントは、ユーティリティ ADAREP パラメータ CHECKPOINTS を使用して表示できます。このパラメータのドキュメントには、さまざまなチェックポイントタイプの説明が含まれています。
このチェックポイントは、データベースのバックアップ後に実行されたすべてのデータベース更新を再適用するユーティリティ ADAREC(データベースリカバリ)にとって特に重要です。ADAREC は、一部のユーティリティ操作を回復できません。そのため、ADAREC で回復できない、手動での再実行が必要なユーティリティの実行を示す SYNP チェックポイントを検出すると、ADAREC は停止します。
注意:
チェックポイントファイルに保存されている情報には、ユーティリティの再実行に必要なすべての情報が含まれているわけではありません。そのため、Software AG では、データベースを回復できるように、すべてのユーティリティの実行を記録することを強くお勧めしています。
Adabas セキュリティファイルには、Adabas セキュリティ定義が含まれています。Adabas セキュリティの詳細については、Adabas セキュリティ定義の維持に使用する、ADASCR ユーティリティのドキュメントを参照してください。
ユーザーデータファイルは、OP コマンドの Additions1 フィールドで指定されたすべてのユーザー ID(EIDS)の最後のトランザクションに関する情報の保存に使用されます。ETID を指定するのは、クラッシュ後に、Adabas を使用したプログラムの再起動処理の実装を可能にするためです。これを実装しないと、ETID を指定する意味がありません。
注意:
ADADBM REFRESH の機能を使用して、ユーザーデータファイルのデータを削除できます。当然ながら、ファイルに保存されているすべてのユーザーデータは失われます。
レプリケーションシステムファイルの詳細については、「Adabas-to-Adabas(A2A)レプリケーション」セクションを参照してください。
RBAC システムファイルの詳細情報については、「Adabas ユーティリティの認可(モード Adabas)」セクションを参照してください。
ディスクリプタは、効率的な検索処理のために Adabas がインデックスを作成したフィールドであり、論理的順次読み取り処理を制御します。また、FIND や SORT ISN LIST のような一部の Adabas コマンドのソートキーとしても使用します。したがって、ディスクリプタの使用は、ファイルに対するアクセス方法と密接に関係しています。各ディスクリプタについて、ディスクスペースの追加とオーバーヘッドの処理が必要です。更新が頻繁なディスクリプタについては特にそうなります。ファイルに対して、どのタイプのディスクリプタをいくつ定義するかについては、次の点を考慮します。
ディスクリプタの配分は、ディスクリプタを使用したときに、ファイルのレコードのうち数パーセント程度を選択できるほどにする必要があります。
既存のディスクリプタを使用して非常に少ない数のレコードを選択できる場合、検索条件をすっきりするためにディスクリプタを追加定義しないでください。
2 つか 3 つのディスクリプタが頻繁に組み合わせて使用される(例えば地域、部、課)ときは、別々のディスクリプタで定義せず、スーパーディスクリプタとして定義することができます。
あるディスクリプタについての選択条件がいつも値の範囲を含むときは、サブディスクリプタを使用することができます。
あるディスクリプタについての選択条件に空値選択が含まれていないが、そのディスクリプタに多くの空値を指定できるときは、そのディスクリプタは空値省略オプションで定義します。
更新の頻繁なフィールドについては、インデックスも更新されるので、ディスクリプタのために作成されたインデックスを使った検索処理が速くなる分、データベース更新処理は遅くなることを認識する必要があります。
フィールドをディスクリプタとして定義せずに、非ディスクリプタ検索を実行する場合、小規模のテストデータベースではパフォーマンスが良いかもしれませんが、大規模な本番データベースではパフォーマンスが低下する可能性があることを認識する必要があります。
データベースに 253 バイトを超えるディスクリプタ値を格納する場合、それらは少なくとも 16 KB のブロックサイズを持つインデックスブロックに格納されます。そのような値を格納したい場合、データベースは適切な ASSO コンテナファイルを持たなければなりません。または、データベースがそのような ASSO コンテナを作成できるように定義された位置が必要です。
ディスクリプタ値の最大長は 1144 バイトです。通常、より大きな値を挿入しようとするデータベース処理は拒否されますが、ディスクリプタに対してインデックス切り捨てオプションを指定した場合、より大きなインデックス値は切り捨てられます。この結果、切り捨てられたインデックス値が関連する場合、検索処理の結果が正確ではなくなるかもしれません。そのような場合には警告が発行されます。
スーパーディスクリプタとは、最大 20 個までのフィールド(またはフィールドの一部)を組み合わせて作成するディスクリプタです。スーパーディスクリプタを構成するフィールドは、ディスクリプタであってもなくてもかまいません。検索条件に値の組み合わせが含まれるときは、通常のディスクリプタを組み合わせるよりもスーパーディスクリプタを使用した方が効果的です。これは、複数のインバーテッドリストの代わりに 1 つのインバーテッドリストにアクセスするだけで済むためです。また、該当レコードの最終的なリストを作成するために、ISN リストを AND 結合する必要がなくなります。スーパーディスクリプタは、ファイル読み取りの論理的順序の制御や ISN リストのソートに、通常のディスクリプタと同じように使用できます。
スーパーディスクリプタを使用する検索条件の値は、スーパーディスクリプタのフォーマットと同じでなければなりません(スーパーディスクリプタを構成するフィールドがすべて数値のときはバイナリフォーマット、それ以外のときは英数字フォーマット)。スーパーディスクリプタのフォーマットがバイナリの場合、問い合わせ機能やレポート機能を使用するときに、検索条件値を入力しにくくなることがあります。
サブディスクリプタとは、フィールドの一部から構成されるディスクリプタです。サブディスクリプタの元のフィールドはディスクリプタであってもなくてもかまいません。検索条件で英数字フィールドの先頭の n バイトや数値フィールドの最後の n バイトの値を範囲指定する場合、そのフィールドの必要なバイト数分をもとにして、サブディスクリプタとして定義することができます。これによって、検索条件では値の範囲ではなく 1 つの値だけを指定すればよいので、Adabas は中間の ISN リストを作成しマージする必要がなくなり、検索を効率よく行うことができます。例えば、AREA が 8 バイトの英数字フィールドであり、先頭の 3 バイトで REGION、後の 5 バイトで DEPARTMENT を表すとします。REGION が 111 のレコードだけが必要な場合、AREA = 11100000~11199999 という検索条件を指定しなければなりません。AREA の先頭の 3 バイトをサブディスクリプタと定義すれば、REGION = 111 という検索条件を指定することができます。
フォネティックディスクリプタはフォネティック検索を行うために定義します。FIND コマンドでフォネティックディスクリプタを使用すると、同じようなフォネティック値を含むレコードがすべて返されます。ディスクリプタのフォネティック値はフィールド値の先頭 20 バイトに基づくもので、英字の値のみが考慮されます(数値、特殊文字および空白は無視されます)。
ハイパーディスクリプタを使用すると、ハイパー出口に記述されているユーザー作成のアルゴリズムに基づいてディスクリプタ値を生成できます。単一の Adabas データベースに対して、最大 255 個までの異なるユーザー作成のハイパー出口を定義できます。各ハイパー出口は、複数のハイパーディスクリプタを処理することができます。
ハイパーディスクリプタは n 個から構成されるスーパーディスクリプタ、派生キー、またはその他のキー構造を実装するために使用できます。ハイパーディスクリプタの詳細については、「FDT のレコード構造」および「ユーザー出口とハイパー出口」を参照してください。
検索条件の内部ファイルリンケージに使用するフィールドを指定することによってマルチファイルクエリを実行できます。この機能はソフトカップリングと呼ばれ、ファイルを物理的にカップリングする必要はありません。
Adabas ファイルの各レコードは、4 バイトの 0 より大きい符号なし整数である、内部シーケンス番号(ISN)を持っています。問い合わせを効率的に実行するために、Adabas で内部的に ISN が使用され、Adabas FIND コマンドの結果は ISN リストとしての結果を表します。
レコードの ISN が知られている場合、その ISN 経由でレコードをアクセスすることは非常に効率的です(Adabas L1 コマンド)。
ファイル内の各レコードの ISN は、通常、Adabas が自動的に割り当てますが、オプションとしてユーザーが割り当てることもできます。このことにより、インバーテッドリストを使用せずに、直接 ISN を使用して順次検索することが可能となります。ただし、ユーザー自身が、ISN 割り当てのアルゴリズムを開発しなければなりません。この ISN の値は、ファイルのアドレスコンバータに割り当てられたスペースに入る値(詳細については、『Adabas ユーティリティ』の「ADAFDU」の MAXISN パラメータを参照)でなければなりません。また、ファイルにレコードを追加するアプリケーションはそれぞれ、必ずユーザーの ISN 割り当てのアルゴリズムを含んでいなければなりません。
インバーテッドリストを使用せずに、レコード内に関連レコードの ISN を格納して直接関連レコードを読み取ることもできます。
例えば、注文レコードを 1 つ読み取り、この注文に対する全顧客レコードを検索して読み取るアプリケーションを考えます。顧客レコードの ISN(1 つの注文レコードに対して複数の顧客が存在している場合、マルチプルバリューフィールドを使用できます)を注文レコードに格納する場合、注文レコードの中に ISN があるので、顧客レコードを直接読み取ることができます。これによって、その注文に対する顧客レコードを確認する際に、顧客ファイルに対して FIND コマンドを実行する必要がなくなります。この方法では、顧客レコードの ISN を含むフィールドを注文レコード内に設定し保持する必要があり、ファイルをアンロードしたり、再ロードしても、同じ ISN が保持されていなければ、顧客ファイルの ISN の変更はないことを前提にしています。
Adabas ダイレクトアクセスメソッド(ADAM)を使用すると、インバーテッドリストをアクセスせずにデータストレージから直接レコードを検索できます。レコードが格納されているデータストレージのブロック番号は、レコードの ADAM キーに基づきランダマイジングアルゴリズムを使用して計算されます。ADAM を使用することによって、アプリケーションプログラムに対して完全な透過性があります。
ADAM ディスクリプタを使用することによるパフォーマンス面での主な利点は、インバーテッドリストに対するアクセス数が減少することです。ADAM キーとして ISN を使用する主な利点は、アドレスコンバータに対するアクセス数が減ることです。
インバーテッドリストを使用した検索では 3~4 回の I/O が必要ですが、ADAM キーを使用してレコードを検索すれば、ADAM では一般的に平均 1.2~1.5 回(理論値)の I/O で済みます。この平均には、アソシエータの制御下でファイルの他のブロックに格納されるオーバーフローレコードの平均も含まれます。オーバーフローレコードについては、通常のインバーテッドリスト参照で取得されます。
ADAM キーの値はユニークでなければなりません。レコードの ISN を ADAM キーとして使用してもかまいません。
注意:
ファイル定義ユーティリティ ADAFDU を使用して、ディスクリプタや ISN を ADAM キーとして定義します。パラメータには次の 3 つがあります。
| パラメータ | 説明 |
|---|---|
| ADAM_KEY | ADAM キーの定義 |
| ADAM_PARAMETER | データレコード分布アルゴリズムに関するパラメータ |
| ADAM_OVERFLOW | オーバーフローブロック数 |
ADAM のデータスペースは、(DSSIZE(ブロック単位) - ADAM_OVERFLOW)として計算します。

ADAM のデータスペースは後から拡張できません。ADAM オーバーフローエリアのみを拡大できます。しかし、ADAM 領域は初期化時に複数の DS エクステントにまたがることができます。ADAM 領域は ADAFDU 実行中にフォーマットされて、使用中のマークが付けられます。
ADAM_OVERFLOW パラメータでオーバーフロー領域に使用するブロック数を定義します。少なくとも 1 ブロックは必要で、後でブロックを追加できます。オーバーフローブロックは、新規レコードの ADAM に必要なブロックに対する空きがない場合に使用します。オーバーフロー領域に大量のレコードが格納されると、ADAM を使用して得られたパフォーマンス効果が減少します。ADAM ファイル内のレコード分布はファイル情報ユーティリティ ADAFIN を使用してチェックできます。
ファイルに領域の再利用オプションを指定している場合、それはオーバーフロー領域にだけ適用します。DATA パディングファクタは両方の領域(DATA とオーバーフロー)に適用します。
ADAM_PARAMETER パラメータを使用して、データレコードの分布を設定します。
ADAM キーが ISN または固定小数点形式のディスクリプタである場合、1 ブロックに格納される連続する値の数を決定します。基本のアルゴリズムは次のとおりです。
DS number = (actual value/ADAM_PARAMETER) modulo number_adam_blocks
ADAM キーのフォーマットが英数字、バイナリまたは浮動小数点の場合、ADAM パラメータは、8 バイト抽出の値の末尾からのオフセットを定義します。
ADAM_PARAMETER = 3 Value's lengths = 5, 10, 15
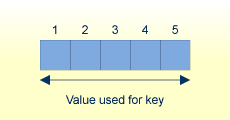
値の長さが 8 バイト以下の場合、値全体が抽出値として使用されます。
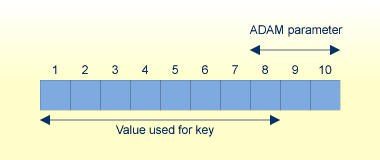
(値の長さ - ADAM パラメータ)が 8 バイト以下の場合、最初の 8 バイトが抽出値として使用されます。
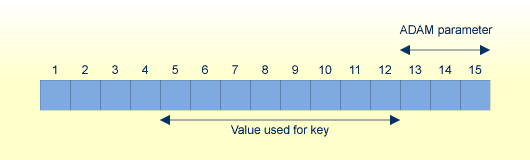
それ以外の場合は、ADAM パラメータのバイト数を削除した後の、最後の 8 バイトが抽出値として使用されます。
相対 DS 番号の計算アルゴリズムは次のとおりです。
DS number = (extraction value) modulo (number of ADAM blocks)
ADAM キーがパックまたはアンパック形式の場合、ADAM パラメータは値の末尾から ADAM 値に必要と思われる位置までを定義します。位置 1 から位置(値の長さ - ADAM パラメータ)までの ADAM 値は 8 バイトの整数値に変換されます。
ADAM_PARAMETER = 2 Value's length = 8
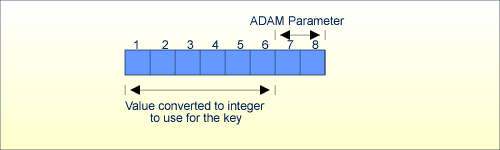
相対 DS 番号の計算アルゴリズムは次のとおりです。
DS number = (integer value) modulo (number of ADAM blocks)
ADAM キーのフォーマットが固定小数点の場合、または ADAM キーが ISN の場合、抽出値は(ADAM キー値) / (ADAM パラメータ)です。
ADAFDU に次の値を入力します。
DSSIZE = 40 B ADAM_KEY = FF ADAM_OVERFLOW = 10 ADAM_PARAMETER = 12
ファイルは ADAM ファイルで、ADAM キーにユニークディスクリプタ FF を使用します。ADAM DS 領域は 30 ブロック使用し、オーバーフロー領域に 10 ブロック確保します。各ブロックには 12 個の連続する値が格納されます。
値は次のように DS ブロックに格納されます。
| FF 値 | DS ブロック |
|---|---|
| 0~11 | 1 |
| 12~23 | 2 |
| 24~35 | 3 |
| ... | ... |
| 348~359 | 30 |
| 360~371 | 1 |
| 372~383 | 2 |
| ... | ... |
データベース環境においては、次の理由から、ディスクスペースの効果的な使用が重要になります。
複数のユーザー間でデータを共有(同時に、異なる組み合わせで)するときは、通常、組織のデータのかなりの部分をオンライン(ディスクを使用する)で格納する必要があります。
アプリケーションによっては、非常に大容量のデータを保持しています。
ディスクスペースの効率的な使用法については、システムの他の目標(パフォーマンス、柔軟性、使い易さ)を考慮しながら決定を下さなければなりません。このセクションでは、これらの要素とディスクスペースの効果的使用法との兼ね合いに関する考察と手法について説明します。
各フィールドは次の 3 つの圧縮に関する指定のうち 1 つを定義できます。
通常の圧縮(デフォルト)。Adabas は、英数字フィールドの末尾の空白と数値フィールドの先端のゼロを除去します。しかし、圧縮された値の長さが 126 以下の場合は追加の長さバイトを 1 バイト、126 より大きい場合は 2 バイトを必要とします。空値は長さバイト = 1 に圧縮されます。
空値省略。通常の圧縮に加えて、フィールドが空値のとき省略します。
固定ストレージ(FI)。フィールドの圧縮は行いません。ただし、データストレージ内の追加の長さバイトは省略します。
次の図に Adabas の圧縮の例を示します。この例では、5 バイトの英数字フィールドに各圧縮オプションを使用して値を格納しています。各格納値の前の数字は、長さバイトを含むフィールドのバイト長を示します(FI フィールドにはありません)。空値省略のアスタリスク(*)は、省略されたフィールド数を示しており、レコード内のこの位置で存在する空値の(省略された)フィールド数を示す 1 バイトのフィールドです。b は空白を示します。
Field Ordinary Fixed Null Value
Value Compression Storage Suppression
ABCbb 04414243 4142432020 04414243
(4 bytes) (5 bytes) (4 bytes)
ABCDb 0541424344 4142434420 0541424344
(5 bytes) (5 bytes) (5 bytes)
ABCDE 064142434445 4142434445 064142434445
(6 bytes) (5 bytes) (6 bytes)
bbbbb 01 2020202020 *
(2 bytes) (5 bytes) (1 byte)
Field Ordinary Fixed Null Value
Value Compression Storage Suppression
ABCbb 4ABC ABCbb 4ABC
(4 bytes) (5 bytes) (4 bytes)
ABCDb 5ABCD ABCDb 5ABCD
(5 bytes) (5 bytes) (5 bytes)
ABCDE 6ABCDE ABCDE 6ABCDE
(6 bytes) (5 bytes) (6 bytes)
bbbbb 1b bbbbb *
(1 byte) (5 bytes) (1 byte)
選択する圧縮オプションは、フィールドのインバーテッドリストの作成(ディスクリプタの場合)、またフィールドの圧縮と圧縮解除に必要な時間にも影響します。
固定ストレージとして定義したフィールドは、圧縮の対象になりません。長さバイトも付加されず、フィールドの標準長で格納されます。固定ストレージは、長さの短いフィールドや圧縮できないフィールドに対して有効なオプションです。FI フィールドを使用する際の制約については、「FDT のレコード構造」を参照してください。
通常の圧縮では英数字フィールドの末尾の空白や数値フィールドの先頭のゼロを除きます。上記の Adabas の圧縮に示したように、少なくとも 2 バイトの末尾の空白または先頭のゼロが除去されれば、ディスクスペースを節約することができます。
フィールドに対して空値省略を指定した場合にフィールド値が空値であると、長さバイトと圧縮済みの空値の代わりに、1 バイトの空値フィールドインジケータが格納されます(前記の図参照)。この空値インジケータは、レコード内のその位置で空値省略されたフィールド(連続フィールド)の数を示します。最高 63 個までの空のフィールドを 1 バイトで表すことができます。したがって、空値になる頻度の高いフィールドはレコード内での物理的な位置を隣接させ、空値省略と定義します。
ディスクリプタフィールドの場合、空値省略を指定すると、インバーテッドリストに空値は作られません。したがって、FIND コマンドでディスクリプタに空値を指定すると、データストレージ内にディスクリプタが空値のレコードがあっても、該当レコードなしという結果になります。空値省略と定義したフィールドから作られるサブディスクリプタやスーパーディスクリプタについても同様です。つまり、元のフィールドの該当バイトが空値で、フィールドが空値省略オプションで定義されていると、サブディスクリプタに対するエントリは作られません。また、元のフィールドの該当バイトが空値で、フィールドが空値省略オプションで定義されていると、スーパーディスクリプタに対してもエントリは作られません。
したがって、ディスクリプタフィールドに対して空値省略を使用するかどうかは、空値による検索が必要かどうかに依存し、またディスクリプタを論理的順次読み取りやソートの制御に使用する場合は、ディスクリプタが空値のレコードを読み取る必要があるかどうかに依存します。このような必要がなければ、空値省略を通常どおりに使用します(FI オプションを使用しないとき)。
空値省略をマルチプルバリューフィールドやピリオディックグループ内のフィールドに指定すると有効であり、必要なディスクスペースや内部処理を減らすことができます。これらのフィールドの更新は、使用する圧縮オプションによって変わります。空値省略オプションで定義したマルチプルバリューフィールドが空値に更新されると、右側の値はすべて左側にシフトされ、それに対応して値の数も減らされます。ピリオディックグループ内のフィールドがすべて空値省略で定義され、グループ全体が空値に更新されると、更新されたオカレンスが最終のオカレンスであれば、オカレンスカウントが減らされます。マルチプルバリューフィールドやピリオディックグループの更新に関する詳細については、「FDT のレコード構造」、および『コマンドリファレンス』の「A1 コマンド」、および『コマンドリファレンス』の「N1/N2 コマンド」を参照してください。
マルチプルバリューフィールドとピリオディックグループの値には、通常 8 バイトのヘッダーが先行します(または、1 バイトの MU または PE カウントが先行することもあります)。ピリオディックグループの各オカレンスには 2 バイトの長さインジケータが先行します。ピリオディックグループに空のオカレンスが含まれる場合、最高 32767 までの空のオカレンスが 2 バイトの空のピリオディックグループオカレンスカウンタに圧縮されます。
大量のレコード更新(A1 コマンド)が発生する場合、かなりの量のレコードが移行、すなわち、現在のブロックから拡張レコード用のスペースがある別のブロックへ移動することになります。ファイルのロード時、このファイルに対するデータストレージのパディングファクタを大きくとれば、移動するレコードの量を大幅に減らすことができます。パディングファクタとは、レコード拡張用に確保しておく各物理ブロック内の比率を表すものです。ファイルをロードしているときや、ファイルに新規レコードを追加するときは、パディングエリアは使われません。レコードの拡張される比率が小さい場合、レコードの拡張が発生しないブロックのパディングエリアは無駄になってしまうので、パディングファクタを大きくとるべきではありません。
大量のレコード更新/追加によって、1 つまたは複数のディスクリプタの現在の値の範囲内に多数の新しい値が挿入される場合、アソシエータ内でもかなりの量の移行が発生します。これはアソシエータのパディングファクタを大きくとれば減らすことができます。
パディングファクタを大きくとると、必要なディスクスペースが大きくなり(ブロック当りのレコードやエントリが小さくなる)、読み取られる物理ブロックが多くなるので順次処理の効率が悪くなります。
パディングファクタは、ファイルの定義(ユーティリティ ADAFDU を使用)時に定義し、リオーダ(ユーティリティ ADAORD を使用)のときに変更します。
このセクションでは、データベースのセキュリティに関する一般的な考慮点と、データベース内のデータの安全性を確保する Adabas のセキュリティ機能について説明します。
セキュリティを効果的に実行するには、次の点を考慮しなければなりません。
システムの安全性はシステムの最も弱い要素で決まります。この要素はシステムのデータ処理部門以外の場合も考えられます。例えば、印刷されたリストを正しく保護しなかったなどです。
「絶対に安全な」システムを設計するのはほとんど不可能です。それにかかる費用よりも利益の方が高いと思われる場合に、セキュリティ違反が行われる可能性が高いからです。
セキュリティにかかるコストが高くなることがあります。コストには、セキュリティを実施する方法の計画の調整とその効果の監視に必要なオーバーヘッド、マシンリソースおよび時間が含まれます。
セキュリティのためのコストは、セキュリティ違反の危険やコストを計るよりも容易ですが、しかし、セキュリティの実施方法によっては、セキュリティの分野以外にも利益をもたらす場合があるため、損得勘定が難しい場合もあります。セキュリティ違反のコストはその違反の種類によります。コストとしては、次のものが含まれます。
違反をリカバリするための時間
個人的な取り決め、契約などによるペナルティ(罰金)
顧客、供給者などとの関係に与える悪影響
このセクションでは、Adabas と Adabas サブシステムが提供するセキュリティ機能の概要について説明します。このセクションで扱う機能の詳細については、「Adabas のセキュリティ機能」セクションを参照してください。
Adabas 認証は、ユーザーに有効な資格情報を提供させることで、アプリケーションがユーザーのコンテキストでデータベースにアクセスする手段を提供します。
Adabas 認証の詳細については、「Adabas のセキュリティ機能」セクションの「Adabas 認証」を参照してください。
ユーティリティの認可は、選択的なアクセス権限を持つ役割をユーザーに割り当てることによって、データベースでの Adabas ユーティリティの使用を制限する手段を提供します。
Adabas ユーティリティの認可の詳細については、「Adabas のセキュリティ機能」セクションの「Adabas ユーティリティの認可」を参照してください。
Adabas パスワードのセキュリティ(ADASCR)の詳細については、「Adabas のセキュリティ機能」セクションの「Adabas パスワードのセキュリティ」を参照してください。
暗号化しておけば、Adabas コンテナファイルの内容を権限のないユーザーに見られる心配がなくなります。Adabas は、コンテナファイルに格納するデータを暗号化できます。しかし、これはデータストレージに格納されるデータレコードにだけ当てはまり、アソシエータ上のインバーテッドリストには当てはまりません。
暗号化の詳細については、「Adabas のセキュリティ機能」セクションの「暗号化」を参照してください。
すべてのデータベースにおける重要なコンセプトは、データベースの整合性を保証するためのトランザクションの可用性のコンセプトです。トランザクションによって、一連のデータベース更新処理がコミットされることが保証されます。つまり、すべての更新がデータベース内で永続的になります。エラーが発生した場合は、すでに実行された更新処理が完全にロールバックされます。
このセクションでは、トランザクションの概念について簡単に説明します。詳細については、『コマンドリファレンスセクション』を参照してください。
Adabas には、トランザクションのコンセプトをサポートする、次のデータベースコマンドがあります。
ET - End of Transaction(トランザクションの終了)、トランザクションをコミットします
BT - Backout Transaction(バックアウトトランザクション)、トランザクションをロールバックします。
ファイルによっては、通常のトランザクションロジックに組み込まない方が望ましいものがあります。そのファイルについては、トランザクションがロールバックされたとしても、すべてのデータベース更新がデータベース内に保持する必要があります。このようなファイルの例としてログファイルがあります。ログファイルには、すべてのユーザーのアクティビティが記録される必要があり、後でバックアウトされるトランザクション内のアクティビティも記録される必要があります。
データベースの整合性を保証するために、トランザクションが必要なレコードを、他のユーザーが更新できないようにする必要があります。Adabas では、この目的で、トランザクションの間レコードをロックできます。
Adabas は次のタイプのロックをサポートしています。
| ロックタイプ | 説明 |
|---|---|
| 共有または読み取りロック(S) | レコードの排他的ロックを取得しているユーザーがいない場合は、共有ロックまたは読み取りロックを取得できます。S ロックを使用すると、他のユーザーはロックされているレコードを更新できません。ただし、他のユーザーは依然として共有ロックを取得できます。 |
| 排他的または書き込みロック(X) | ある Adabas レコードに対して S または X ロックを取得しているユーザーがいない場合にのみ、その Adabas レコードの排他的ロックまたは書き込みロックを取得できます。レコードの変更や削除は、レコードの X ロックがある場合にのみ可能です。新しいレコードを作成すると、そのレコードは自動的に排他的にロックされます。 |
場合によっては、トランザクション全体ではなく、トランザクションのサブセットのみをロールバックする必要があります。Adabas には、この目的でサブトランザクションのコンセプトがあります。これは、ET および BT コマンドの特別なオプションを介して実装されます。
次のような場合に、データベースは整合している状態になっている必要があります。
ADABCK を使用して、データベースのバックアップを作成する場合
ADAOPR EXT_BACKUP を使用して、外部バックアップを実行する場合
新しいプロテクションログ(PLOG)に切り替えた場合
注意:
新規の PLOG エクステントに切り替える場合は、PLOG のすべてのエクステントが 1 つの PLOG と見なされるので、ET 同期は必要ありません。
上記すべての場合で、データベースの ET 同期を実行する必要があります。つまり、以下のことを意味します。
現在アクティブなすべてのトランザクションは、トランザクションが終了するか、タイムアウトが発生するまで動作を続けます。タイムアウト時間は、Adabas ニュークリアスパラメータ TT、または ADABCK の場合はパラメータ ET_SYNC_WAIT によって定義されます。
Adabas コマンドが新しいトランザクションを開始しようとした場合、コマンドは ET 同期が完了するまで待機する必要があります。
すべてのアクティブなトランザクションが終了すると、すぐに ET 同期のフェーズ 2 が開始されます。これで、整合性のある状態で実行される必要があるすべてのアクティビティを実行できます。例えば、整合の取れた状態でデータベースをディスクに保存するためのバッファフラッシュなどです。
ET 同期のフェーズ 2 が終了すると、ET 同期の終了を待機していたすべてのコマンドを続行できます。
オプション NEW_PLOG なしで ADABCK DUMP ダンプを使用して、ファイルレベルでバックアップを作成した場合、ET 同期はファイルレベルでのみ実行されます。
ET 同期が待機するのは、ダンプされたファイルにアクセスするトランザクションの終了のみです。
新しいトランザクションは、それが他のファイルにのみアクセスしているのであれば、トランザクションを開始できます。ただし、このようなトランザクションがダンプされたファイルの 1 つに拡張された場合は、コマンドは ET 同期の終了を待機する必要があります。
このセクションでは、データベースのリカバリ/再スタートの設計について説明します。
システムを設計するうえで、リカバリ/再スタートの計画を十分に練っておくことが重要になりますが、データベースを使用するシステムでは、このことが特に重要になります。障害の原因の大部分は、基本的なシステム設計プロセスの段階で、予測、評価し、解決することができます。
リカバリ機能は、当然の機能として特に明示されないことがよくあります。すなわち、どのような事態になっても、システムがリカバリを行い再スタートできることが前提とされています。しかし、システムのいろいろなユーザーが必要とするリカバリレベルについて決定すべき事柄が存在します。リカバリ機能は、DBA がイニシアティブをとり、必要な事柄を設定すべき分野です。まず、システムを利用する予定のユーザーに対して、リカバリ/再スタートの要件について質問しなければなりません。考慮の必要な最も重要な点として次のものがあります。
システムが使用できなくなっても、どの位の期間ユーザーは業務を継続できるか。
どの位の期間、各フェーズを遅らすことが可能か。
手作業でユーザーが入出力チェックを行う場合、どのような方法があるか。また、どのくらいの時間が必要か。
リカバリ/再スタートが発生した場合、データ保全性が維持されていることを確認するためにどのような手順を行う必要があるか。
一度、リカバリ/再スタートが必要だと認められたら、DBA はこれらの要求を満たすのに必要な方法の計画に進むことができます。ここで述べる手法は上記を行うための基本的な手引として使えるはずです。
システム内のさまざまなユーザーがデータを共有するレベルや程度について決定します。
システムに対するリカバリパラメータを設定します。このパラメータとしては、予測/実際のブレークダウン率、平均の遅れと影響を受ける項目、およびセキュリティに使用する項目を含みます。
リカバリ設計の要点をまとめたアウトラインを準備します。このアウトライン内には次の情報を含むようにします。
整合性チェックに関する計画。データの整合性チェックは、できるだけシステムへのデータ入力時に近い時点で行う必要があります。レコード入力時と別にデータを中間で更新すると、リカバリはより難しくコスト高になります。
データベースや選択ファイルのダンプ(バックアップコピー)。
ユーザーチェックポイントと Adabas チェックポイント。
ET ロジック、排他ファイル制御、ET データの使用。
リカバリ方法の適合性、有効性およびコストを決定するために、リカバリ方法はすべての起こり得る故障の状況に対応できるものでなければなりません。
リカバリ/再スタートに必要なすべてのリソースが必要なときに使用できるかどうかが判断できるようオペレーション担当者とも相談する必要があります。
最終的なリカバリ設計はドキュメント化し、ユーザー、オペレーション担当者、その他システムに関連する人々に知らせ、再確認しなければなりません。
データベースのクラッシュ後にデータベースを再起動すると、自動再スタートが実行されます。ニュークリアスがクラッシュしたときにアクティブだったすべてのトランザクションがロールバックされ、不足しているすべてのデータベース更新が ASSO および DATA コンテナに書き込まれます。この目的のために、更新処理は WORK コンテナに記録されています。ただし、ディスクが破損している場合は、自動再スタートが失敗する可能性があります。このような場合に、バックアップおよびプロテクションログからデータベースの状態を復元できることが重要です。これは、バックアップファイルとプロテクションログ(PLOG)が別の独立したディスクに保存されている場合にのみ保証されます。Adabas は、更新処理を 2 回ログに記録します。つまり、自動再スタートの場合に WORK に 1 回、リストア/リカバリの場合に PLOG に 1 回です。これは、ログが保存されているディスクが破損した場合に現在のデータベース状態のリカバリを可能にするためです。
注意:
大体のリカバリ要件が決まったら、次にリカバリ/再スタートを行うための関連機能(Adabas 機能も Adabas 以外の機能も)を選択します。以下に、リカバリ/再スタートに関連する Adabas 機能について説明します。
多くのバッチ更新プログラムは、以下のような特性を持つ入力トランザクションストリームを処理します。
トランザクションにより、プログラムが検索、追加、更新、削除を行うレコードの数は少数です。例えば、注文入力プログラムでは、各注文に対して顧客レコードと製品レコードを検索し、データベースにその注文と注文項目データを追加し、製品レコードの注文フィールドの量を更新します。
プログラムは、トランザクション開始から終了までに使用するレコードの排他制御が必要ですが、トランザクションが完了したら、レコードを解放し、他ユーザーが更新したり削除したりできるようにします。
トランザクションが未完了の状態になってはなりません。すなわち、2 レコードを更新する場合は、2 レコードを両方とも更新するか、いずれも更新されないかのどちらかでなければなりません。
Adabas ET コマンドを使用すると、次のことが可能です。
完了したトランザクションによる追加、更新、削除処理がすべてデータベースに適用されるようになります。
全体的または部分的なシステム障害により中断されたトランザクションについては、すべての更新処理をデータベースから取り除かれます。
プログラムで、Adabas システムファイルにユーザー再スタートデータ(ET データ)を格納することができます。この ET データは、Adabas の OP または RE コマンドで再スタート時に取り出すことができます。
トランザクション処理中にホールド状態にあった全レコードを解放します。
Adabas CL コマンドでユーザーの最新 ET データを更新できます(例えばジョブ完了フラグの設定)。
Adabas の OP コマンドを使用して、ユーザー再スタート後または新規ユーザー/Adabas セッションの開始時に、ET データを読むことができます。このとき、ユーザー識別子(ユーザー ID)も指定しなければなりません。このユーザー ID を使用して、Adabas はユーザーの ET データを検索します。
他のユーザーのユーザー ID がわかっていれば、RE コマンドを使用して他のユーザーの ET データを読み取ることができます。これは、例えばオンライン更新処理のスタッフ管理を行う場合に有効です。
Adabas セッションが異常終了すると、各 Adabas セッションの始めに自動的に呼び出された Adabas AUTOBACKOUT ルーチンが、中断されたすべてのトランザクションが行った更新処理をデータベースから除去します。
個々のトランザクションが中断された場合は、トランザクションが行った更新をすべてデータベースから自動的に除去します。また、アプリケーションプログラムでも、Adabas の BT コマンドを使用して、現在のトランザクションの処理をバックアウトするように明示的に指定できます。
ニュークリアスがクラッシュした場合、次の事項を考慮に入れる必要があります。
最後の ET がデータベースに適用される前に発行された No-BT ファイルへのすべてのデータベース更新。
最後の ET の適用後に発行された No-BT ファイルのデータベース更新が、データベースに適用されるかどうかは定義されません。
Adabas トランザクションリカバリについては、次のような制約を考慮しなければなりません。
アソシエータの重要な部分と Adabas WORK のデータプロテクションエリアのどちらか一方でも物理的に読み取りができなかったり、上書きされたりした場合には、トランザクションリカバリ機能は動作しません。このような状況はほとんど発生しませんが、発生した場合の対処手順を作成しておく必要はあります。物理的に破壊されたデータベースのリカバリ方法に関する詳細な手順については、リカバリ/再スタート手順の節を参照してください。
トランザクションリカバリ機能はデータベースの内容を回復するだけです。非 Adabas ファイルを再配置したり、ユーザープログラムのステータスを元どおりに戻すことはしません。
特定ユーザーのトランザクションによる処理だけをバックアウトすることはできません。このユーザーが追加または更新したレコードに対して別ユーザーがトランザクションを実行した可能性があるからです。
次の理由から、ある種のプログラムでは ET コマンドの使用は効果的ではありません。
各トランザクションの実行中、プログラムが多数のレコードをホールドしなければならない場合。このことは、デッドロックの可能性を増加させ(Adabas では 2 ユーザーの一方のトランザクションをバックアウトすることでデッドロックを自動的に解消しますが、大量のトランザクションを再処理しなければならなくなります)、Adabas ホールドキューをかなり大きくとる必要があります。
複合検索により見つかるレコードが多く長いリストをプログラムで処理する場合、このリストの途中から再スタートするのは困難です。
上記のようなプログラムでは、必要に応じて Adabas チェックポイントコマンド(C1)を使用して、プログラムが更新中である 1 つ以上のファイルのリストア可能地点を設定できます。実行中の更新のタイプ(排他制御)に応じて、特定のコマンドが使用されます。
ユーザーは 1 つ以上の Adabas ファイルの排他更新制御を要求できます。OP コマンドで排他制御を要求し、他ユーザーがファイルを現在更新中でなければ、排他制御を行えます。あるユーザーに排他制御が与えられると、他ユーザーはそのファイルを読み込むことはできますが、更新することはできません。
論理順にレコードを処理するときも、検索を実行するときも、プログラムが読み取ったり更新したりするレコードの件数が増えて処理時間が長くなりますが、排他制御を使用すれば、プログラムが使用するレコードをユーザーが更新する懸念はなくなります。これによって、各レコードに対してレコードホールドコマンドを実行する必要がなくなります。
排他制御ユーザーは ET コマンドを使用しても使用しなくてもかまいません。ET コマンドを使用しないときは、C1 コマンドを発行して(ユーザーデータを格納したい場合)、チェックポイントを設定することができます。
システムまたはプログラム障害が発生した場合、排他制御下で更新中のファイル(群)は、ADABCK または ADAMUP を使用して、障害が発生したプログラムの実行開始以前の状態にリストアすることができます。
排他ファイル制御には、次のような制限があります。
最終チェックポイントへのリカバリは自動的には行われず、障害が起きたときのデータプロテクションログがリカバリ処理に必要です。ただし、ユーザーが ET コマンドを発行したときは、これは適用されません。
システム障害後の再スタート状態で、Adabas は、システム中断時排他制御の下で更新されていたファイルを他ユーザーが更新するのをチェックせず、また回避もしません。
Adabas の ET および CL コマンドでは、オプションとして Adabas システムファイルに 2000 バイトまでのユーザーデータを格納できます。
Adabas の ET、C3 および CL コマンドでは、オプションとして Adabas システムファイルに 2000 バイトまでのユーザーデータを格納できます。
ユーザーごとにユーザーデータを 1 レコード保持します。ユーザーが新規にユーザーデータを書き読むたびに、このレコードは書き換えられます。OP コマンドでユーザー ID を指定したときだけ、Adabas セッションが終了してもデータが保持されます。ユーザーデータは OP または RE コマンドで読み取ることができます。また、他のユーザーのユーザー ID がわかっていれば、RE コマンドでそのユーザーデータを読み取ることも可能です。
ユーザーデータの第一の目的は、プログラムが自身で再スタートが可能となり、リカバリ手順が適切に行われたかをチェックできることです。ユーザーデータとして有効な情報タイプは、次のものです。
プログラムの実行日時および最終更新時刻。これにより、プログラムは端末ユーザー、コンソールオペレータまたはプリンタに適切なメッセージを送ることができ、ユーザーやオペレータはリカバリ/再スタート処理が正しく行われたかをチェックできます。特に、端末ユーザーが知らない真夜中に重大な障害が発生した場合、どの作業から再実行すべきかわかります。
入力データ収集日。
バッチ番号。この番号により、管理者は端末からの再入力が必要な作業を識別し、割り当てることができます。
識別データ。ある場合は、上記項目に対する単なる追加データまたは参照用のデータであり、また他の場合には、再スタート地点を決める場合に基づく基本データとなります。例えば、論理順スキャンを行うプログラムでは再開するキー値が必要です。
トランザクション番号/入力レコード位置。これにより、端末ユーザーやバッチプログラムが開始位置を決める労力を最小にできます。各トランザクションに Adabas はトランザクションシーケンス番号を返すが、次の理由からユーザーもシーケンス番号を保持したい場合があります。
再スタート後、Adabas シーケンス番号がリセットされるとき。
各トランザクションの処理内容が複雑で、Adabas トランザクションシーケンス番号と次の入力レコードやドキュメントの位置との関係が単純ではないとき。
入力エラーによりプログラムがトランザクションをバックアウトするとき。トランザクションを直ちに再入力するか(単純なキーイングミスなど)、または後で修正するために拒否するか(入力ドキュメントやレコードの基本的なエラーが発生した場合)を Adabas は判断できません。
その他の記述データや中間データ。例えば、繰越合計、レポートのページ番号や見出し、実行統計などです。
ジョブ/バッチ完了フラグ。すべての処理が完了後でオペレータやユーザーに知らされる前にシステムがダウンする場合もあります。この場合、オペレータがプログラムを再スタートしても、プログラムでは入力の終りまで実行せずに、このフラグをチェックできます。同様なことが端末から入力したドキュメントのバッチに対しても適用されます。
最終のジョブ/プログラム名。いくつかのプログラムが一定の順序でデータベースを更新しなければならないとき、同一のユーザー ID を使用し、順序が正しく保たれているかをチェックするためにユーザーデータを使用できます。