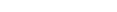
Dieses Kapitel beschreibt die von Natural geleistete dynamische und statische SQL-Unterstützung.
Die folgenden Themen werden behandelt:
Verwandte Dokumentation
Eine Liste der Fehlermeldungen, die bei der statischen Generierung ausgegeben werden können, finden Sie unter Static Generation Messages and Codes Issued under NDB in der Natural-Messages and Codes-Dokumentation.
Informationen zu Static SQL mit Natural Security finden Sie unter Integration mit Natural Security.
Die SQL-Unterstützung von Natural kombiniert die Flexibilität der dynamischen SQL-Unterstützung mit der hohen Leistungsfähigkeit der statischen SQL-Unterstützung.
Im Gegensatz zur statischen SQL-Unterstützung muss bei der
dynamischen SQL-Unterstützung von Natural keine besondere Rücksicht auf den
Betrieb der SQL-Schnittstelle genommen werden. Alle SQL-Statements, die zur
Ausführung einer Anwendungsanfrage erforderlich sind, werden automatisch
generiert und können mit dem Natural-Kommando RUN sofort
ausgeführt werden. Bevor Sie ein Programm ausführen, können Sie sich den
generierten SQLCODE mit dem Kommando LISTSQL
ansehen.
Der Zugriff auf Db2 über Natural erfolgt unabhängig davon, ob die dynamische oder die statische SQL-Unterstützung verwendet wird, in derselben Form. Bei statischer SQL-Unterstützung können dieselben SQL-Statements in einem Natural-Programm sowohl im dynamischen als auch im statischen Modus ausgeführt werden. Ein SQL-Statement kann innerhalb eines Natural-Programms kodiert und zu Testzwecken mit dynamischem SQL ausgeführt werden. Ist der Test erfolgreich, bleibt das SQL-Statement unverändert und es kann statisches SQL für dieses Programm generiert werden.
Während der Anwendungsentwicklung arbeitet der Programmierer also im dynamischen Modus und alle SQL-Statements werden dynamisch ausgeführt, während statisches SQL nur für Anwendungen erstellt wird, die in den Produktionsstatus überführt wurden.
Natural sorgt automatisch für die Vorbereitung und Ausführung jedes SQL-Statements und verwaltet das Öffnen und Schließen von Cursors, die zum Scannen einer Tabelle verwendet werden.
Die folgenden Themen werden behandelt:
E/A-Modul NDBIOMO für die dynamische Ausführung von SQL-Statements
Verarbeitung von SQL-Statements, die von Natural ausgegeben werden
Da jede dynamische Ausführung eines SQL-Statements ein statisch
definiertes DECLARE STATEMENT und DECLARE
CURSOR-Statement erfordert, wird ein spezielles E/A-Modul namens
NDBIOMO bereitgestellt, das eine feste Anzahl dieser Statements
und Cursors enthält. Diese Anzahl wird bei der Generierung des
NDBIOMO-Moduls im Rahmen des Natural for Db2-Installationsvorgangs
festgelegt.
Ein SQL-Statement wird nach Möglichkeit nur einmal vorbereitet und
kann dann bei Bedarf mehrfach ausgeführt werden. Zu diesem Zweck pflegt Natural
intern eine Tabelle mit allen vorbereiteten SQL-Statements und ordnet jedes
dieser Statements einem DECLAREd STATEMENT im Modul
NDBIOMO zu. Außerdem werden in dieser Tabelle die von den
SQL-Statements FETCH,
UPDATE
(positioned) und
DELETE
(positioned) verwendeten Cursor verwaltet.
Jedes SQL-Statement wird eindeutig identifiziert durch:
den Namen des Natural-Programms, das dieses SQL-Statement enthält,
die Zeilennummer des SQL-Statements in diesem Programm,
den Namen der Natural Library, in der dieses Programm per Stow abgelegt wurde,
den Zeitstempel, wann dieses Programm per Stow abgelegt wurde.
Ein vorbereitetes SQL-Statement kann mit Hilfe des dynamischen
SQL-Statements EXECUTE USING DESCRIPTOR oder OPEN CURSOR
USING DESCRIPTOR mehrmals mit unterschiedlichen Variablenwerten
ausgeführt werden.
Wenn das Fassungsvermögen der Statement-Tabelle erschöpft ist, überschreibt der Eintrag für das nächste vorbereitete Statement den Eintrag für ein freies Statement, dessen letzte Ausführung am wenigsten weit zurückliegt.
Wenn ein neues SELECT-Statement angefordert
wird, wird ihm ein freier Eintrag in der Statement-Tabelle mit dem
entsprechenden Cursor zugewiesen, und alle nachfolgenden
FETCH-,
UPDATE- und
DELETE-Statements,
die sich auf dieses SELECT-Statement beziehen,
verwenden diesen Cursor. Nach Beendigung der sequenziellen Abfrage der Tabelle
wird der Cursor freigegeben und für eine weitere Zuweisung verfügbar. Solange
der Cursor geöffnet ist, wird der Eintrag in der Statement-Tabelle als benutzt
markiert und kann nicht von einem anderen Statement wiederverwendet werden.
Wenn die Anzahl der verschachtelten FIND-
(SELECT-) Statements die Anzahl der in der Statement-Tabelle
verfügbaren Einträge erreicht, wird jedes weitere SQL-Statement zur
Ausführungszeit abgelehnt und eine Natural-Fehlermeldung zurückgegeben.
Die Größe der Statement-Tabelle hängt von der für das Modul
NDBIOMO angegebenen Größe ab. Da die Statement-Tabelle im
Pufferbereich von Db2 enthalten ist, reicht die Einstellung des
Natural-Profilparameters DB2SIZE (siehe
auch Natural Parameter Modifications for Natural for DB2 in
Installing
Natural for DB2 on z/OS in der
Installation-Dokumentation) möglicherweise nicht aus und
muss erhöht werden.
Das eingebettete SQL verwendet die Cursor-Logik zur Verarbeitung
von SELECT-Statements. Die
Vorbereitung und Ausführung eines SELECT-Statements läuft wie
folgt ab:
Das typische SELECT-Statement wird durch einen
Programmablauf vorbereitet, der die folgenden eingebetteten SQL-Statements
enthält (dabei sind X und
SQLOBJ SQL-Variablen, keine
Programm-Labels):
DECLARE SQLOBJ STATEMENT DECLARE X CURSOR FOR SQLOBJ INCLUDE SQLDA (copy SQL control block)
Dann wird das folgende Statement in die SQLSOURCE
verschoben:
SELECT PERSONNEL_ID, NAME, AGE
FROM EMPLOYEES
WHERE NAME IN (?, ?)
AND AGE BETWEEN ? AND ?
Anmerkung:
Die Fragezeichen (?) oben sind
Parametermarkierungen, die angeben, wo Werte zur Ausführungszeit eingefügt
werden sollen.
PREPARE SQLOBJ FROM SQLSOURCE
Then, the SELECT statement is executed as
follows:
OPEN X USING DESCRIPTOR SQLDA FETCH X USING DESCRIPTOR SQLDA
Der Deskriptor SQLDA wird verwendet, um eine
variable Liste von Programmbereichen anzugeben. Wenn das
OPEN-Statement ausgeführt wird, enthält es die Adresse, die Länge
und den Typ jedes Wertes, der eine Parametermarkierung in der
WHERE-Klausel des SELECT-Statements ersetzt. Bei der
Ausführung des FETCH-Statements enthält es die Adresse, die Länge
und den Typ aller Programmbereiche, die aus der Tabelle gelesene Felder
erhalten.
Bei der ersten Ausführung des FETCH-Statements
wird die Natural-Systemvariable *NUMBER
auf einen Wert ungleich Null gesetzt, wenn mindestens ein Satz gefunden wird,
der den Suchkriterien entspricht. Anschließend werden alle Datensätze, die die
Suchkriterien erfüllen, durch wiederholte Ausführung der
FETCH-Statements gelesen.
Zur Verbesserung der Performance, insbesondere bei der
Verwendung verteilter Datenbanken, kann die Db2-spezifische FOR FETCH
ONLY-Klausel verwendet werden. Diese Klausel wird generiert und
ausgeführt, wenn nur Zeilen abgerufen werden sollen, d.h. wenn keine Änderungen
vorgenommen werden sollen.
Wenn alle Datensätze gelesen wurden, wird der Cursor durch die Ausführung des folgenden Statements freigegeben:
CLOSE X
In diesem Abschnitt wird beschrieben, wie Sie Natural-Programme für die statische Ausführung vorbereiten.
Die folgenden Themen werden behandelt:
Eine Erklärung der Symbole, die in diesem Abschnitt zur Beschreibung der Syntax von Natural-Statements verwendet werden, finden Sie unter Syntax-Symbole in der Statements-Dokumentation.
Statisches SQL wird im Natural-Batch-Modus für eine oder mehrere Natural-Anwendungen generiert, die aus einem oder mehreren Natural-Objektprogrammen bestehen können. Die Anzahl der Programme, die in einem Durchlauf des Generierungsverfahrens für die statische Ausführung modifiziert werden können, ist auf 999 begrenzt.
Während des Generierungsvorgangs werden die in den angegebenen Natural-Objekten enthaltenen Datenbankzugriffs-Statements extrahiert, in Arbeitsdateien geschrieben und in ein temporäres Assembler-Programm umgewandelt. Wenn kein Natural-Programm gefunden wird, das einen SQL-Zugriff enthält, oder wenn bei der statischen SQL-Generierung ein Fehler auftritt, bricht das Batch Natural ab und gibt den Bedingungscode 40 zurück, was bedeutet, dass alle weiteren JCL-Schritte nicht mehr ausgeführt werden dürfen.
Die Natural-Module NDBCHNK und NDBSTAT
müssen sich in einer Steplib des Generierungsschrittes befinden. Beide werden
bei der Ausführung des Generierungsschrittes dynamisch geladen.
Das temporäre Assembler-Programm wird in eine temporäre Datei (das
Natural Workfile CMWKF06) geschrieben und vorkompiliert. Die Größe
dieser Arbeitsdatei ist proportional zur maximalen Anzahl der Programme, der
Anzahl der SQL-Statements und der Anzahl der in den SQL-Statements verwendeten
Variablen. Während des Vorkompilierungsschritts wird ein
Datenbankanforderungsmodul (DBRM) erstellt, und nach dem
Vorkompilierungsschritt wird die Precompiler-Ausgabe aus dem Assembler-Programm
extrahiert und in die entsprechenden Natural-Objekte geschrieben, was bedeutet,
dass die Natural-Objekte für die statische Ausführung modifiziert (vorbereitet)
werden. Das temporäre Assembler-Programm wird nicht mehr verwendet und
gelöscht.
Ein statisches Datenbankanforderungsmodul wird entweder mit dem auf dem Installationsmedium mitgelieferten Beispiel-Job oder mit einem entsprechenden Job, der mit der Funktion Create DBRM erstellt wurde, erstellt.
Um statisches SQL für Natural-Programme zu generieren:
 Um statisches SQL für Natural-Programme zu generieren:
Um statisches SQL für Natural-Programme zu generieren:
Melden Sie sich bei der Natural System Library SYSDB2 an.
Da bei der Installation von Natural for Db2 eine neue SYSDB2-Library angelegt wurde, müssen Sie sicherstellen, dass diese alle Predict-Schnittstellenprogramme enthält, die für die Generierung von statischem SQL erforderlich sind. Diese Programme werden zum Zeitpunkt der Predict-Installation in SYSDB2 geladen (siehe die entsprechende Predict-Produktdokumentation).
Geben Sie das Kommando CMD
CREATE und die für die statische SQL-Generierung erforderlichen
Natural-Eingaben an. Das Kommando CMD CREATE hat die
folgende Syntax:
CMD
CREATE DBRM
static-name
USING
using-clause |
{application-name,object-name,excluded-object} |
:
|
:
|
Die Generierungsprozedur liest die angegebenen Natural-Objekte, verändert sie aber nicht. Wenn eines der angegebenen Programme nicht gefunden wurde oder keinen SQL-Zugriff hatte, wird am Ende des Generierungsschritts der Rückmeldecode 4 zurückgegeben.
Wenn die Option
PREDICT
DOCUMENTATION verwendet werden soll, muss ein entsprechender
statischer Predict-SQL-Eintrag vorhanden sein und der
static-name muss dem Namen dieses
Eintrags entsprechen. Außerdem muss der
static-name dem Namen des DBRM
entsprechen, das bei der Vorkompilierung erzeugt werden soll. Der
static-name kann bis zu 8 Zeichen lang
sein und muss den Assembler-Namenskonventionen entsprechen.
Die using-clause gibt
die Natural-Objekte an, die im DBRM enthalten sein sollen. Diese Objekte können
entweder explizit als INPUT DATA in der JCL angegeben werden oder
als PREDICT
DOCUMENTATION von Predict bezogen werden.
|
|
|
|
WITH
XREF
|
|
|
|
|
|
FS
|
|
|
|
|
[LIB lib-name
] |
|
DCTODP
|
|
|
|
|
Wenn die anzugebenden Parameter nicht in eine Zeile passen,
geben Sie die Kommandokennung (CMD) und die verschiedenen
Parameter in separaten Zeilen an und verwenden Sie sowohl das
Eingabetrennzeichen (wie mit dem Natural-Profil-/Session-Parameter
ID angegeben
- Standardeinstellung ist das Komma (,) - als auch das
Fortsetzungszeichen - wie mit dem Natural-Profil-/Session-Parameter
CF angegeben
- Standardeinstellung ist das Prozentzeichen (%) - wie im
folgenden Beispiel gezeigt:
Beispiel:
CMD CREATE,DBRM,static,USING,PREDICT,DOCUMENTATION,WITH,XREF,NO,% LIB,library
Alternativ können Sie auch Abkürzungen verwenden, wie im folgenden Beispiel gezeigt:
Beispiel:
CMD CRE DBRM static US IN DA W XR Y FS OFF LIB library
Die Reihenfolge der Parameter USING,
WITH, FS und
LIB ist optional.
Als Eingabedaten müssen in den nachfolgenden Zeilen des Jobs die
Anwendungen und die Namen der Natural-Objekte angegeben werden, die in das DBRM
aufgenommen werden sollen
(application-name,object-name). Eine
Teilmenge dieser Objekte kann auch wieder ausgeschlossen werden
(excluded-objects). Objekte in
Libraries, deren Namen mit SYS beginnen, können ebenfalls für die
statische Generierung verwendet werden.
Die Anwendungen und Namen von Natural-Objekten müssen durch das
Eingabetrennzeichen getrennt werden - wie mit dem Natural-Profilparameter
ID angegeben
- Standard ist ein Komma (,). Wenn Sie alle Objekte angeben
möchten, deren Namen mit einer bestimmten Zeichenfolge beginnen, verwenden Sie
einen object-name oder einen
excluded-objects, der mit einem Stern
(*) endet. Um alle Objekte in einer Anwendung anzugeben, verwenden Sie nur die
Stern-Notation (*).
Beispiel:
LIB1,ABC* LIB2,A*,AB* LIB2,* : .
Die Angabe von Anwendungen/Objekten muss durch eine Zeile
abgeschlossen werden, die nur einen Punkt (.) enthält.
Da Predict statisches SQL für Db2 unterstützt, können Sie
Predict auch die Eingabedaten für die Erstellung von statischem SQL liefern
lassen, indem Sie bereits vorhandene PREDICT DOCUMENTATION
verwenden.
Da Predict Active References statisches SQL für Db2 unterstützt, kann das erzeugte statische DBRM in Predict dokumentiert werden, und die Dokumentation kann mit Natural verwendet und aktualisiert werden.
Wenn die Option WITH XREF angegeben ist, können Sie
bei jeder Erstellung eines statischen DBRM die Cross-Referenzdaten für einen
statischen SQL-Eintrag in Predict speichern (YES). Sie können
stattdessen angeben, dass keine Cross-Referenzdaten gespeichert werden
(NO) oder dass geprüft wird, ob bereits ein statischer SQL-Eintrag
in Predict für dieses statische DBRM existiert (FORCE). Wenn ja,
werden die Cross-Referenzdaten gespeichert, wenn nicht, wird die Erstellung des
statischen DBRM nicht zugelassen. Nähere Informationen zu Predict Active
References finden Sie in der entsprechenden Predict-Dokumentation.
Wenn WITH XREF (YES/FORCE) angegeben ist, werden
XREF-Daten sowohl für den statischen Predict-SQL-Eintrag (falls in
Predict definiert) als auch für jedes generierte statische Natural-Programm
geschrieben. Die statische Generierung mit WITH XREF (YES/FORCE)
ist jedoch nur möglich, wenn die entsprechenden Natural-Programme mit
XREF ON katalogisiert wurden.
Die Option WITH XREF FORCE gilt nur für die Option
USING INPUT DATA.
Anmerkung:
Wenn Sie Predict nicht verwenden, muss die Option
XREF weggelassen oder auf NO gesetzt werden und das
Modul NATXRF2 braucht nicht mit dem Natural-Kern verknüpft zu
werden.
Wenn die Option FS (File Server) auf
ON gesetzt ist, wird ein zweites SELECT für den
Natural File Server für Db2 erzeugt. ON ist die
Standardeinstellung.
Wenn die FS-Option auf OFF gesetzt ist, wird kein
zweites SELECT generiert, was dazu führt, dass weniger
SQL-Statements in Ihrem statischen DBRM generiert werden und somit ein
kleineres DBRM entsteht.
Mit der Option LIB (Library) kann eine andere
Predict-Library als die Standard-Library (*SYSSTA*) angegeben
werden, die den statischen Predict-SQL-Eintrag und die XREF-Daten
enthält. Der Name der Library kann bis zu acht Zeichen lang sein.
Die Option DCTODP ist nur relevant, wenn Sie eine
statische Generierung für Programme durchführen, die mit dem Natural-Parameter
DC=',' katalogisiert wurden.
Mit dem DCTODP-Parameter kann festgelegt
werden, ob die statische Generierung dezimale Literale in SQL-Statements durch
das Ersetzen des Dezimalzeichens Komma (,) durch das
Dezimalzeichen Punkt (.) im generierten statischen
SQL-Assembler-Programm ändern soll. Dies ist notwendig, da der Db2-Precompiler
kein Komma in dezimalen Literalen unterstützt.
Wenn DCTODP OFF angegeben ist, findet keine
Konvertierung von Komma in Punkt statt. DCTODP OFF ist der
Standardwert.
Wenn DCTODP ON angegeben ist, wird bei der
statischen Generierung ein Komma (,) als Dezimalzeichen in einen
Punkt (.) umgewandelt.
Wenn DCTODP ON verwendet wird, sollten Sie
sicherstellen, dass Ihre Programme eindeutig kodiert sind, wenn Sie das Komma
als Trennzeichen in Funktionsaufrufen und verschiedenen SQL-Klauseln wie
IN oder ORDER BY verwenden, damit das Komma als
Trennzeichen in Elementlisten nicht als Dezimalpunkt eines Dezimal-Literales
fehlinterpretiert werden kann.
Wenn Sie zum Beispiel eine SQL IN-Klausel unter
Verwendung von DC=',' wie folgt kodieren:
Column-name IN (10,20,30,40).
Die statische Generierung mit DCTODP ON ändert die
IN-Klausel in
Column-name IN (10,20 , 30,40).
Die IN-Liste enthält zwei Werte 10.20 und
30.40.
Die gleiche IN-Klausel bei statischer Generierung
mit DCTODP OFF (Standardwert) wird geändert in
Column-name IN (10,20 , 30,40).
Die IN-Liste enthält vier Werte
Wenn Sie Folgendes codiert hätten:
Column-name IN (10 , 20 , 30 , 40).
Die statische Generierung generiert die IN-Klausel
immer mit DCTODP entweder ON oder OFF
zu
Column-name IN (10 , 20 , 30 , 40).
In diesem Schritt wird der Precompiler aufgerufen, um das generierte temporäre Assembler-Programm vorzukompilieren. Die Ausgabe des Precompilers besteht aus dem DBRM und einem vorkompilierten temporären Assembler-Programm, das alle Datenbankzugriffs-Statements enthält, die von SQL-Statements in Assembler-Statements umgewandelt wurden.
Später dient das DBRM als Input für den BIND-Schritt
und das Assembler-Programm als Input für den Änderungsschritt.
Der Änderungsvorgang ändert die beteiligten Natural-Objekte, indem
er Precompiler-Informationen in das Objekt schreibt und den Objekt-Header mit
dem static-name markiert, der mit dem
Kommando CMD CREATE angegeben wurde.
Darüber hinaus werden alle vorhandenen Kopien dieser Objekte im
globalen Natural-Buffer Pool (falls vorhanden) gelöscht und
XREF-Daten in Predict geschrieben (falls beim Generierungsvorgang
angegeben).
Um den Änderungsvorgang auszuführen:
Melden Sie sich bei der Natural Library SYSDB2 an.
Geben Sie das Kommando CMD MODIFY
mit der folgenden Syntax ein:
CMD
MODIFY [XREF]
|
Der Input für den Modifizierungsschritt ist die
Precompiler-Ausgabe, die sich in einem Datensatz befinden muss, der als
Natural-Arbeitsdatei CMWKF01 definiert ist.
Die Ausgabe besteht aus Precompiler-Informationen, die in die
entsprechenden Natural-Objekte geschrieben werden. Außerdem wird eine Meldung
zurückgegeben, die angibt, ob ein Objekt zum ersten Mal für die statische
Ausführung modifiziert wurde (modified) oder ob es bereits zuvor
modifiziert wurde (re-modified).
Wenn Sie die Option XREF des Kommandos
CMD MODIFY angeben, wird eine Ausgabeliste in der
Arbeitsdatei CMWKF02 erstellt, die den DBRM-Namen und die
Assembler Statement-Nummer jedes statisch erzeugten SQL-Statements zusammen mit
der entsprechenden Natural-Quellcode-Zeilennummer, dem Programmnamen, dem
Library-Namen, der Datenbankkennung und der Dateinummer enthält.
-------------------------------------------------------------------------....
DBRMNAME STMTNO LINE NATPROG NATLIB DB FNR COMMENT ....
-------------------------------------------------------------------------....
TESTDBRM 000627 0390 TESTPROG SAG 010 042 INSERT ....
000641 0430 INSERT ....
000652 0510 SELECT ....
000674 0570 SELECT ....
000698 0570 SELECT 2ND ....
000728 0650 UPD/DEL ....
000738 0650 UPD/DEL 2ND ....
000751 0700 SELECT ....
000775 0700 SELECT 2ND .... |
| Spalte | Erläuterung |
|---|---|
DBRMNAME |
Name des DBRM, das das statische SQL-Statement enthält. |
STMTNO |
Assembler-Statement-Nummer des statischen SQL-Statements. |
LINE |
Entsprechende Natural-Quellcode-Zeilennummer. |
NATPROG |
Name des Natural-Programms, das das statische SQL-Statement enthält. |
NATLIB |
Name der Natural Library, die das Natural-Programm enthält. |
DB / FNR |
Natural-Datenbankkennung und -Dateinummer. |
COMMENT |
Typ des SQL-Statements, wobei 2ND anzeigt, dass das entsprechende Statement für eine erneute Auswahl verwendet wird. Siehe auch File Server-Konzept. |
Wir empfehlen Ihnen, das Db2-Kommando
BIND nach dem Kommando CMD
MODIFY auszuführen.
Das Db2-Kommando BIND bindet das DBRM
in ein Db2 Package ein. Sie können ein oder mehrere Db2-Packages in einen
Db2-Anwendungsplan einbinden. Zusätzlich zu den Packages der statischen DBRMs,
die mit dem Kommando CMD CREATE erstellt wurden,
kann dieser Anwendungsplan auch das Package der DBRM des
NDBIOMO-Moduls enthalten, das Natural für die dynamische
SQL-Ausführung bereitstellt.
Ein DBRM kann in eine beliebige Anzahl von Packages eingebunden werden und die Packages können bei Bedarf in eine beliebige Anzahl von Anwendungsplänen eingebunden werden. Ein Plan ist physisch unabhängig von der Umgebung, in der das Programm ausgeführt werden soll. Sie können Ihre Packages jedoch logisch in Plänen gruppieren, die entweder für die Batch- oder die Online-Verarbeitung verwendet werden sollen, wobei dasselbe Package sowohl Teil eines Batch-Plans als auch eines Online-Plans sein kann.
Sofern Sie keine Planumschaltung verwenden, kann nur ein Plan pro
Natural-Sitzung ausgeführt werden. Daher müssen Sie sicherstellen, dass der im
BIND-Schritt angegebene Plan-Name mit dem Namen
übereinstimmt, der für die Ausführung von Natural verwendet wird.
Um Natural im statischen Modus ausführen zu können, müssen alle
Natural-Benutzer das Db2-Privileg EXECUTE PLAN/PACKAGE für den im
BIND-Schritt erstellten Plan besitzen.
Um statisches SQL auszuführen, müssen Sie Natural starten und das entsprechende Natural-Programm ausführen. Intern wertet die Natural-Laufzeitschnittstelle die in das Natural-Objekt geschriebenen Precompiler-Daten aus und führt dann die statischen Zugriffe aus.
Für den Benutzer gibt es keinen Unterschied zwischen dynamischer und statischer Ausführung.
Es ist möglich, Natural in einem gemischten statischen und dynamischen Modus zu betreiben, wobei für einige Programme statisches SQL generiert wird und für andere nicht.
Der Modus, in dem ein Programm ausgeführt wird, wird durch das Natural-Objektprogramm selbst bestimmt. Wenn im ausführenden Programm ein statisches DBRM referenziert wird, werden alle Statements in diesem Programm im statischen Modus ausgeführt.
Anmerkung:
Natural-Programme, die einen Laufzeitfehler zurückgeben, werden
nicht automatisch im dynamischen Modus ausgeführt. Stattdessen muss entweder
der Fehler behoben werden oder das Natural-Programm muss vorübergehend neu
katalogisiert werden, um im dynamischen Modus ausgeführt werden zu
können.
Innerhalb ein und derselben Natural-Sitzung können statische und dynamische Programme ohne weitere Angaben gemischt werden. Die Entscheidung, welcher Modus verwendet werden soll, wird von jedem einzelnen Natural-Programm getroffen.
Eine Liste der Fehlermeldungen, die während der statischen Generierung ausgegeben werden können, finden Sie unter Static Generation Messages and Codes Issued under NDB in der Natural Messages and Codes-Dokumentation.
In diesem Abschnitt wird beschrieben, wie Sie Anwendungspläne innerhalb derselben Natural-Sitzung in verschiedenen TP-Monitorumgebungen oder im Batch-Modus wechseln können.
Die folgenden Themen werden behandelt:
Durch "Application Plan Switching" können Sie innerhalb einer Natural-Sitzung auf einen anderen Anwendungsplan umschalten.
Soll ein zweiter Anwendungsplan verwendet werden, so kann dieser
durch Ausführen des Natural-Programms NATPLAN festgelegt werden.
NATPLAN ist in der Natural System Library SYSDB2 enthalten und
kann entweder aus einem Natural-Programm heraus oder dynamisch durch Eingabe
des Kommandos NATPLAN an der
NEXT-Eingabeaufforderung aufgerufen werden. Der einzige
Eingabewert, der für NATPLAN benötigt wird, ist ein achtstelliger
Plan-Name. Wenn kein Plan-Name angegeben ist, werden Sie vom System dazu
aufgefordert, dies zu tun.
Bevor Sie NATPLAN ausführen, müssen Sie sicherstellen, dass alle offenen Db2-Wiederherstellungseinheiten geschlossen sind.
Da das Programm NATPLAN auch in Quellcodeform zur
Verfügung gestellt wird, können benutzerdefinierte Planumschaltprogramme mit
ähnlicher Logik erstellt werden.
Der tatsächliche Wechsel von einem Plan zu einem anderen unterscheidet sich in den verschiedenen unterstützten Umgebungen. Die Funktion ist unter Com-plete, CICS und IMS TM MPP verfügbar. Bei Verwendung der Call Attachment Facility (CAF) oder Resource Recovery Services Attachment Facility (RRSAF) ist sie auch in TSO- und Batch-Umgebungen verfügbar.
In einigen dieser Umgebungen muss anstelle eines Plan-Namens eine Transaktionskennung oder ein Code angegeben werden.
Unter CICS haben Sie die Möglichkeit, entweder die Planumschaltung
durch Transaktionskennung (Standard) oder dynamische Planauswahl-Exit-Routinen
zu verwenden. Indem Sie das Feld #SWITCH-BY- TRANSACTION-ID im
Programm NATPLAN auf TRUE oder FALSE
setzen, wird entweder die Subroutine CMTRNSET oder der gewünschte
Plan-Name in eine temporäre Speicherwarteschlange geschrieben.
Weitere Informationen zur Aktivierung der Planumschaltung unter CICS finden Sie unter Installation Steps Specific to CICS in der Installing Natural for DB2 on z/OS-Dokumentation.
Nachfolgend finden Sie Informationen zu:
Wenn #SWITCH-BY-TRANSACTION-ID auf
FALSE gesetzt ist, wird der gewünschte Plan-Name in eine temporäre
Speicherwarteschlange für eine CICS/Db2-Exit-Routine geschrieben, die als
PLANExit-Attribut eines DB2ENTRY oder der
DB2CONN-Definition angegeben ist. Das
NATPLAN-Programm muss vor dem ersten Db2-Zugriff aufgerufen
werden. Natural for Db2 bietet NDBUEXT als
CICS-Db2-Planauswahl-Exit-Programm. Weitere Informationen zu
CICS/Db2-Exit-Routinen finden Sie in der entsprechenden IBM-Literatur.
Der Name der temporären Speicherwarteschlange lautet
PLANxxxx, wobei
ssss die Kennung des entfernten oder
lokalen CICS-Systems und tttt die
CICS-Terminalkennung ist.
In einer CICSplex-Umgebung muss die CICS-Warteschlange
PLANxxxx, die den Namen des Plans
enthält, mit TYPE=SHARED oder TYPE=REMOTE in einem
CICS-TST definiert werden.
Für jede neue Db2-Wiederherstellungseinheit wird automatisch die entsprechende Planauswahl-Exit-Routine aufgerufen. Diese Exit-Routine liest den temporären Speichersatz und verwendet den darin enthaltenen Plan-Namen für die Planauswahl.
Wenn für die Natural-Sitzung kein temporärer Speichersatz existiert, kann ein im Plan-Exit enthaltener Standard-Plan-Name verwendet werden. Wenn durch den Exit kein Plan-Name angegeben ist, wird der Name des Plans verwendet, der dem Namen des statischen Programms (DBRM) entspricht, das den SQL-Aufruf absetzt. Wenn kein solcher Plan-Name existiert, kommt es zu einem SQL-Fehler.
In Com-plete-Umgebungen wird der Planwechsel mit Hilfe der Call Attachment Facility (CAF) durchgeführt, die den verwendeten Thread freigibt und einen anderen mit einem anderen Plan-Namen anhängt.
Sobald die Db2-Verbindung hergestellt ist, wird derselbe Plan-Name
so lange verwendet, bis der Plan explizit über die IBM Call Attachment
Language-Schnittstelle (DSNALI) geändert wird. Weitere
Informationen über die CAF-Schnittstelle finden Sie in der einschlägigen
IBM-Literatur.
Unter Com-plete gibt das NATPLAN-Programm zunächst
ein END TRANSACTION-Statement aus und ruft dann unter Verwendung
von DB2SERV eine Assembler-Routine auf.
Die Assembler-Routine führt die eigentliche Umschaltung durch. Sie
gibt eine CLOSE-Anforderung an DSNALI aus, um die
Db2-Verbindung zu beenden (falls eine besteht). Anschließend sendet sie eine
OPEN-Anforderung, um die Db2-Verbindung wiederherzustellen und die
für die Ausführung des angegebenen Plans erforderlichen Ressourcen
zuzuordnen.
Wenn NATPLAN nicht vor dem ersten SQL-Aufruf
ausgeführt wurde, wird standardmäßig der Plan verwendet, der in den
Startparametern von Com-plete definiert wurde. Sobald ein Plan mit
NDBPLAN geändert wurde, bleibt er eingeplant, bis ein anderer Plan
von NDBPLAN eingeplant wird oder bis zum Ende der
Natural-Sitzung.
In einer IMS-MPP-Umgebung wird der Wechsel durch direkte oder verzögertes Message Switching erreicht. Da jedem IMS-Anwendungsprogramm ein anderer Anwendungsplan zugeordnet ist, wird beim Message Switching von einem Transaktionscode zu einem anderen automatisch der verwendete Anwendungsplan gewechselt.
Da Natural-Anwendungen direktes oder verzögertes Message Switching
durchführen können, indem sie die entsprechenden mitgelieferten Routinen
aufrufen, ist die Verwendung des Programms NATPLAN für die
Planumschaltung optional.
NATPLAN ruft die Assembler-Routine
CMDEFSW auf, die den neuen Transaktionscode festlegt, der bei der
nächstfolgenden Terminal-E/A verwendet werden soll.
In TSO- und Batch-Umgebungen wird der Planwechsel mit Hilfe der Call Attachment Facility (CAF) oder der Resource Recovery Services Attachment Facility (RRSAF) durchgeführt. Beide Einrichtungen geben den verwendeten Thread frei und hängen einen anderen an, der einen anderen Plan-Namen hat.
Nachfolgend finden Sie Informationen über:
Die initialen Verbindungs- und Planeinstellungen können mit den
Subparametern DB2PLAN
und DB2SSID
des NTDB2-Makros
oder des Profilparameters DB2 vorgenommen
werden, ohne das Programm NATPLAN zu verwenden. Die ursprünglichen
Einstellungen könnten jedoch durch die Verwendung des Programms
NATPLAN überschrieben werden.
Bei Verwendung der Call Attachment Facility (CAF) erfolgt die Planauswahl entweder implizit oder explizit. Wenn vor dem ersten SQL-Aufruf noch keine Db2-Verbindung hergestellt wurde, wird ein Plan-Name von Db2 ausgewählt. In diesem Fall ist der verwendete Plan-Name derselbe wie der Name des Programms (DBRM), das den SQL-Aufruf absetzt.
Sobald die Db2-Verbindung hergestellt ist, wird der Plan-Name
beibehalten, bis er explizit von der IBM Call Attachment Language Interface
(DSNALI) geändert wird. Weitere Informationen über die
CAF-Schnittstelle finden Sie in der entsprechenden IBM-Literatur.
Under TSO and in batch mode, the NATPLAN program
first issues an END
TRANSACTION statement and then invokes an Assembler routine
by using DB2SERV.
Unter TSO und im Batch-Modus gibt das
NATPLAN-Programm zuerst ein END TRANSACTION-Statement aus
und ruft dann unter Verwendung von DB2SERV eine Assembler-Routine
auf.
Anmerkung:
Ändern Sie das NATPLAN-Programm, indem Sie das
Feld #SSM auf den aktuellen Db2-Subsystem-Namen setzen. Der der Standardname
ist DB2.
Die Assembler-Routine führt die eigentliche Umschaltung durch.
Sie sendet eine CLOSE-Anforderung an
DSNALI, um eine mögliche Db2-Verbindung zu beenden. Anschließend
sendet sie eine OPEN-Anforderung, um die Db2-Verbindung
wiederherzustellen und die für die Ausführung des angegebenen Plans
erforderlichen Ressourcen zuzuordnen.
Wenn NATPLAN nicht vor dem ersten SQL-Aufruf
ausgeführt wurde, erfolgt die Planauswahl durch DSNALI. In diesem
Fall ist der verwendete Plan-Name derselbe wie der Name des Programms, das den
SQL-Aufruf tätigt. Die verwendete Subsystemkennung ist diejenige, die bei der
Db2-Installation angegeben wurde. Wenn kein solcher Plan-Name oder keine
Subsystemkennung existiert, wird eine Natural-Fehlermeldung zurückgegeben.
Wenn ein statisches DBRM den SQL-Aufruf ausführt, muss ein Plan-Name mit demselben Namen wie der des statischen DBRM vorhanden sein.
Wenn dynamisches SQL verwendet wird, muss ein Db2-Plan
existieren, der ein Package mit dem DBRM des NDBIOMO-Moduls
enthält. Wenn der Name des Db2-Plans weder im NATPLAN-Programm
noch mit dem Schlüsselwort-Subparameter DB2PLAN
definiert wurde, verwendet die Db2 Call Attachment Facility (CAF) den Namen des
NDBIOMO-DBRM als Standard-Plan-Namen.
Anmerkung:
Um Verwirrung bezüglich des gewählten Plan-Namens und/oder
der Subsystemkennung zu vermeiden, sollten Sie NATPLAN immer vor
dem ersten SQL-Aufruf aufrufen.
Die initialen Verbindungs- und Planeinstellungen können mit den
Schlüsselwort-Subparametern DB2COLL,
DB2GROV,
DB2PLAN,
DB2SSID
und DB2XID des
Makros NTDB2
oder des Profilparameters DB2 vorgenommen
werden, ohne das Programm NATPLAN zu verwenden. Die initialen
Einstellungen können jedoch durch die Verwendung des Programms
NATPLAN überschrieben werden.
Bei Verwendung der Resource Recovery Services Attachment Facility (RRSAF) erfolgt die Planauswahl explizit.
RRSAF wird verwendet, wenn das
DSNRLI-Schnittstellenmodul von IBM mit Natural verbunden ist.
Sobald die Db2-Verbindung hergestellt ist, wird der Name des Plans beibehalten,
bis er explizit mit RRSAF geändert wird. Weitere Informationen zu RRSAF finden
Sie in der entsprechenden IBM-Literatur.
Das Programm NATPLAN führt die eigentliche
Umschaltung durch. Es sendet eine TERMINATE IDENTIFY-Anforderung
an DSNRLI, um eine mögliche Db2-Verbindung zu beenden.
NATPLAN gibt dann eine IDENTIFY-Anforderung aus, um
die Db2-Verbindung wiederherzustellen. Auf diese Anforderung folgen die
Anforderungen SIGNON und CREATE
THREAD.
In einer RRSAF-Umgebung können bis zu vier der folgenden
Parameter in NATPLAN angegeben werden, wobei
#PLAN obligatorisch ist:
| Parameter | Standardwert | Format | Erläuterung |
|---|---|---|---|
#PLAN |
None | A8 | Name des Plans, der für die SQL-Verarbeitung in dem
erzeugten Thread (CREATE THREAD) verwendet wird.
|
#SSM |
DB2 |
A4 | Subsystemkennung des angeschlossenen Db2-Servers
(IDENTIFY).
|
#COLLID |
COLLID |
A18 | Wird nur verwendet, wenn das erste Zeichen von
#PLAN ein Fragezeichen (?) ist.
Collection ID, die für die SQL-Verarbeitung in dem
erstellten Thread ( |
#XID |
1 |
I4 | Gibt an, dass eine globale Transaktionskennung
verwendet wird.
Wenn auf |
Beispiel für Planauswahl mit RRSAF unter TSO
Das folgende Beispiel zeigt die Planauswahl unter TSO unter Verwendung von RRSAF:
NATPLAN
<Enter>
Please enter new plan name NDBPLAN4
,SUB SYSTEM ID DB27
,COLLECTION ID
,global XID (0/1) __________1
<Enter>
Das folgende Beispiel veranschaulicht die Planauswahl im Batch-Modus unter Verwendung von RRSAF:
NATPLAN NDBPLAN4,DB27, ,1