コンフィグレーションファイル NATCONV.INI の設定が A フォーマットに適用されます。U フォーマットの場合は、ICU ライブラリが使用されます。
このドキュメントでは、Natural がどのように文字セットをサポートしているかについて説明します。次のトピックについて説明します。
さまざまな文字セットを使用した複数言語のサポートは、国際化に対する Natural のアプローチを表しています。次を使用する場合に役立ちます。
すべて同じ Natural 環境と通信するさまざまな文字セットを持つ端末およびプリンタ。
1 つのデータベースを共有し、異なるプラットフォームに配置された複数の Natural 環境。
言語固有の文字の大文字/小文字変換。
Natural の識別子、オブジェクト名、およびライブラリ名に使用される言語固有の文字。
マスク定義と比較したオペランド内の言語固有の文字(『プログラミングガイド』の「MASK オプション」を参照)。
Natural では、最下位の 7 ビットの ASCII 文字セットに従ったあらゆるシングルバイト文字セットをサポートしています。
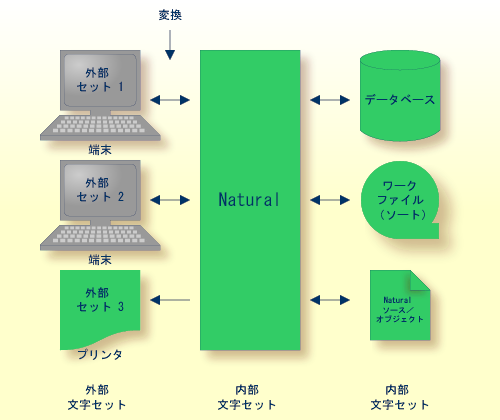
Natural では、内部文字といくつかの外部文字セットを区別します。内部文字セットは、Natural 自体によって使用されます。
次の図に示すように、内部文字セットと外部文字セット間の変換は、端末からの入力後、端末またはプリンタへの出力前に実行されます。ワークファイル I/O、データベース I/O、および Natural オブジェクトの読み取り/書き込みに使用できる外部文字セットへの変換はできません。
デフォルトでは、Natural は内部文字セット ISO8859_1 を使用します。デフォルトの文字セットが要件を満たしていない場合は、Natural またはその他の標準の文字セットで提供されている定義済みの文字セットのいずれかを選択できます。
注意:
同じデータベースを共有している内部文字セットが異なるコンピュータを実行した場合、またはこれらのコンピュータ間でデータや Natural オブジェクトを交換しようとした場合に、問題が発生する可能性があります。
任意の端末およびプリンタに外部文字セットを定義できます。
端末の場合、文字セットの名前は端末データベースの TCS エントリによって定義されます。次に例を示します。
:TCS = usascii:
また、すべての TCS 設定を上書きする UNIX 環境変数 $NATTCHARSET を使用することもできます。
TCS エントリと論理 NATTCHARSET(環境変数 $NATTCHARSET で設定)のどちらも定義されていない場合、端末 I/O 中に変換は実行されません。
プリンタの場合、プリンタプロファイルで外部文字セット名を定義できます。これは、グローバルコンフィグレーションファイルの一部です。『コンフィグレーションユーティリティ』ドキュメントの「コンフィグレーションファイルのパラメータの概要」内の「プリンタプロファイル」を参照してください。
言語固有の文字をサポートするために Natural で使用されるすべてのチェック、変換、および分類テーブルが、コンフィグレーションファイル NATCONV.INI 内に存在します。デフォルトでは、このファイルは Natural の etc ディレクトリにあります。
NATCONV.INI を変更して、ローカルまたはアプリケーション固有の文字セットをサポートできます。
標準アプリケーションでは NATCONV.INI を変更する必要はありません。変更すると、特に Natural オブジェクトとデータベースデータがすでに存在する場合に、重大な不整合が発生する可能性があるため、変更しないでください。
次のいずれかのことを行う場合は、変更が必要です。
デフォルト以外の内部文字セットを使用する場合、
NATCONV.INI でサポートされていない文字セットを含む端末またはプリンタを使用する場合、
識別子で特定の文字の使用を許可または禁止する場合、
MASK オプションの評価にローカル文字をサポートする場合。
NATCONV.INI を変更する場合は十分に検討し、慎重に実行する必要があります。そうでない場合、特定が困難な問題が発生する可能性があります。
NATCONV.INI はセクションとサブセクションに分かれています。次のセクションが定義されています。
| セクション | 説明 |
|---|---|
CHARACTERSET-DEFINITION |
このセクションでは、内部文字セットの名前を定義します。デフォルトは ISO8859_1 です。
別の文字セットを選択する場合は、この文字セットのサブセクションを以下のセクションに含める必要があります。 |
CHARACTERSET-TRANSLATION |
このセクションでは、内部文字セットと外部文字セット間の変換に必要なテーブルについて説明します。
例えば、
|
CASE-TRANSLATION |
このセクションには、次のいずれかが指定された場合に実行される大文字から小文字への変換に必要なテーブルが含まれています。
|
IDENTIFIER-VALIDATION |
このセクションには、識別子(ソースプログラムのユーザー定義変数)、オブジェクト名、およびライブラリ名の検証に必要なテーブルが含まれています。定義されたそれぞれの内部文字セットのサブセクションを含んでいます。
特殊文字 "#"(データベース変数以外の場合)、"+"(アプリケーション独立変数の場合)、"@"(SQL および Adabas の空値/長さインジケータの場合)、および"&"(ダイナミックソース生成の場合)は、このセクションで再定義できます。さらに、識別子、オブジェクト名、およびライブラリ名で有効な最初の文字と後続の文字のセットを変更できます。 注意: |
CHARACTER-CLASSIFICATION |
このセクションには、文字の分類に必要なテーブルが含まれています。例えば、MASK オプションを評価するときに使用されます。定義されたそれぞれの内部文字セットのサブセクションを含んでいます。
|
セクション CHARACTERSET-DEFINITION と各サブセクションには、文字の変換方法と、どの文字がどの属性に関連しているかを示す行が含まれています。これらの行は次のように表されます。
line ::= key = value
key ::= name_key | range_key
name_key ::= keyword{ CHARS }
keyword ::= INTERNAL-CHARACTERSET | NON-DB-VARI | DYNAMIC-SOURCE |
GLOBAL-VARI | FIRST-CHAR | SUBSEQUENT-CHAR |
LIB-FIRST-CHAR | LIB-SUBSEQUENT-CHAR | ALTERNATE-CARET
ISASCII | ISALPHA | ISALNUM | ISDIGIT | ISXDIGIT |
ISLOWER | ISUPPER | ISCNTRL | ISPRINT | ISPUNCT |
ISGRAPH | ISSPACE
range_key ::= hexnum | hexnum-hexnum
value ::= val {, val }
val ::= hexnum | hexnum-hexnum
hexnum ::= xhexdigithexdigit | xhexdigithexdigit
注意:
range_key 変数が左側に指定されている場合、右側に指定されている値の数は、キー範囲に指定されている値の数に対応している必要があります。ただし、右側に指定されている値が 1 つのみの場合は、キー範囲の各要素に割り当てられます。
name_key 変数が左側に指定され、対応する文字コードのリストが 1 行に収まらない場合は、name_key = を再度指定することで次の行に続けることができます。行の先頭に空白またはタブを使用しないでください。
| x00-x1f = x00 | x00 と x1f との間のすべての文字が x00 に変換されます。
|
| x00-x7f = x00-x7f | x00 と x7f との間の文字は変換されません。
|
| x00-x08 = x00,x01-x07,x00 | 文字 x00 および x08 が x00 に変換され、x01 と x07 との間の文字は変換されません。
|
|
ISALPHA = x41-x5a,x61-x7a,xc0-xd6,xd8 |
この 2 行で指定されたすべての文字に ISALPHA 属性が割り当てられます。
|
| x41 = 'A' | 文字はすべて 16 進形式で指定する必要があります。 |
| 0x00-0x1f = 0x00 | 16 進値は、次のいずれかの方法で指定する必要があります。
xdigitdigit |
| x00-x0f = x00,x01 | 指定された値の数が、キー範囲の要素の数に対応していません。 |