The GTMapper™ allows you to create and execute your masking definitions in one clean, easy-to-use program.
The GTMapper.exe can be found in your c:\gtsdm folder. It can also be found as a shortcut in your Start Menu as a subfolder of Grid-Tools.
Note:
The Build Version and Date are displayed in the top left corner for
reference. This information can also be found in the GTSDM.exe and GTSDM.jar
files in GTSDM folder.
Once opened, GTMapper™ will present you with the following window. This is the window in which you are able to create and execute all your masking definitions. Along the top of the window you will notice three tabs; Connection Parameters, Scramble Functions and Scramble Options.
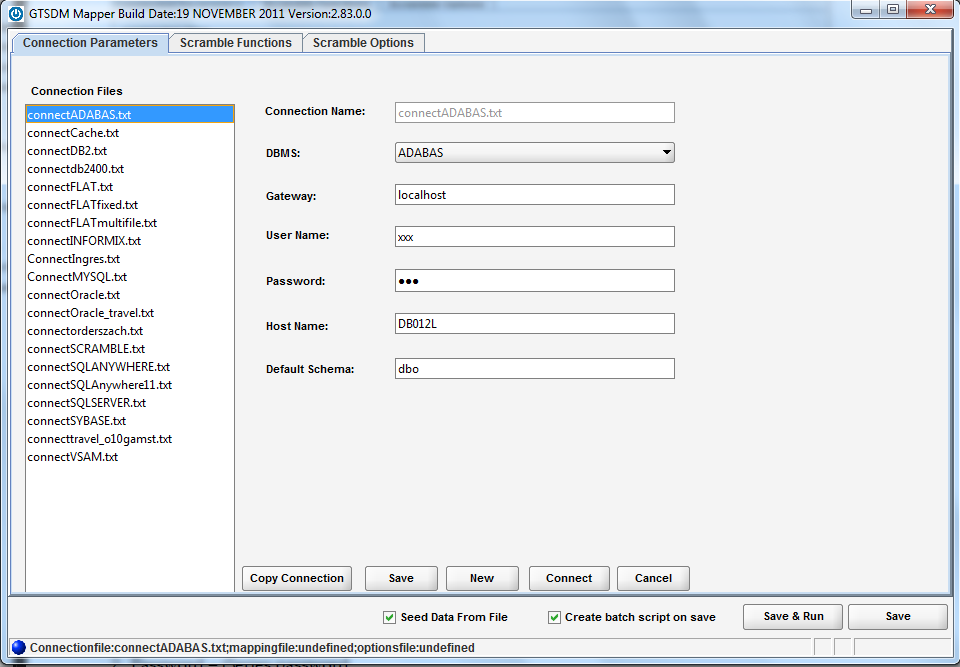
The first window you see will be the Connection Parameters tab. The left-hand panel offers a list of available connections. The connection details are shown to the right.
Note:
For a connection file to be visible in the GTMapper™ Connection
Parameters tab, it must be saved as a connect<filename>.txt
file, i.e. connectORACLE.txt
iSeries users can click on the default connection file
connectdb2400.txt and change the following parameters:
Username – iSeries username
Password – iSeries password
Database = Default Schema = iSeries Library or SQL Schema that contains the tables to be masked
Once your connection is set, click the Connect button in the bottom right-hand corner of the window to establish your connection to the database selected.
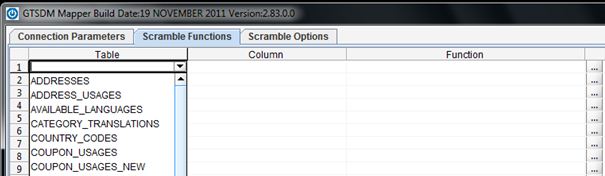
In Scramble Functions, you can create a new map, or edit an existing one.
In order to open an existing CSV file, select Open Mapping in the bottom right-hand corner of the window and select the previously created file from the GTSDM folder.
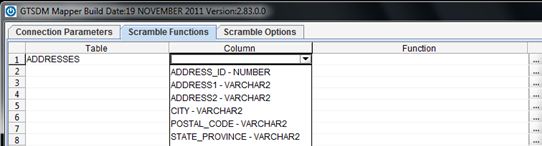
The Scramble Functions tab gives users the ability to see and select; any table in the default schema, any column in the selected table and any applicable masking functions for the selected column.
To select from any of the possible Table, Column or Function options, left click on the desired cell and choose from the drop-down menu.
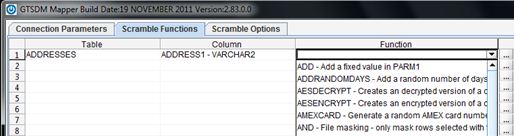
When saving your masking definition, GTMapper™ also gives users the option to Save & Run directly from this screen, using the button in the right-hand corner.
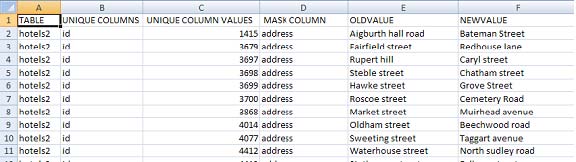
Save the file as a CSV. The details of the mask are shown in the screen shown below.
Note:
db2400 and db2 for iSeries users are discouraged from this as it may
cause the transfer or large amounts of data from iSeries to their Windows
machine. These users should consider using the button when they have small amounts of data.
The Scramble Options tab allows you to set some very important options for the masking process. These include additional parameters to control the run, for example, you may wish to adjust the commit frequency.
The options available are explained below:
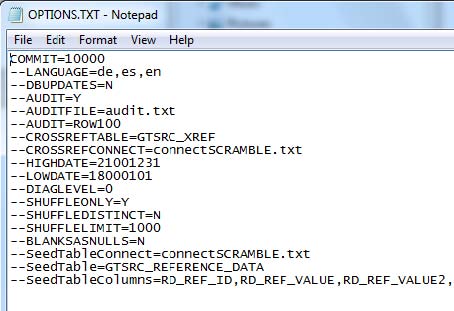
The Audit file contains the table name, the column name(s) that constitute a unique row for the table, the values for these column(s), and the old and new values for columns that are being masked. The Audit options are as follows:
| COMMIT=nnnn | Commit after nnnn rows for each table to be masked. |
| AUDIT=ALL | All rows will be audited. |
| AUDIT=ROWnnn | Where nnn is equal to the number of rows that will be audited, for example ROW1000 will audit the first 1000 rows. |
| AUDIT=SAMPLEnnn | Where every nnn rows will be displayed, for example SAMPLE100 will audit every 100th row. |
| AUDITFILE= | The filename. The format will be comma separated. |
| AUDITONLYCOLUMNS= | Allows you to provide a comma separated list of column names to be audited, for example: EMPLOYEE.FIRST_NAME, EMPLOYEE_ADDRESS.CITY |
| AUDITVALUES= | N = do not show old and new values in AUDIT file. The default setting is to show both. |
| CROSSREFTABLE= | gtsrc_xref - the name of the table to read and write cross reference data to. |
| CROSSREFCONNECT= | This refers to a file containing the connection information of the schema that contains the cross reference table. |
| CASEINSENSITIVEXREF= | Make comparisons case insensitive (For Cross-Reference) |
| TRIMMEDXREF= | Trim values before comparing (For Cross-Reference) |
Each database type will have a starter connection .txt file. Copy the appropriate file for your RDBMS to your own file name and begin editing this file. Sample files for different RDBMS are shown in the Building Maps Files for Standard RDBMS section.
| CDATE= | Override todays date for the purposes of date calculation functions, for example, DOB (format: YYYYMMDD). |
| HIGHDATE= | Override the highest date that offset date functions will process, for example, dates later than 22000101 will be ignored. |
| LOWDATE= | Override the lowest date that offset date functions will process, for example, dates earlier than 18000101 will be ignored. |
GTSDM currently supports 3 languages for messaging – English, German and Spanish.
When GTSDM starts, it checks the current default locale - if the language is supported (for example, one of the three above), it will process messages in that language. If the language is not supported, it will default to English, unless set in the Options file.
You can override the locale language by altering the language option as follows:
| LANGUAGE= | en (English), de (German) or es (Spanish). |
| XPATH ELEMENT | The location of the XML data you wish to be masked. |
| PARALLEL=4 | Enables users to separate a maximum of 4 masking threads. |
SDM will assign a separate thread for each table in a CSV if there is more than one. However, more typically, a CSV will have just one table but be split using WHERE clauses.
For example, a CSV using the WHERE clauses below would
have 4 spilts:
WHERE, CUSTID<100 ....
WHERE, CUSTID BETWEEN 100 AND 200 ....
WHERE, CUSTID BETWEEN 200 AND 300 ....
WHERE, CUSTID>100
| SEEDTABLECONNECT= | connectscramble.txt - the name of the connection file to get seed data from. |
| SEEDTABLE= | gtsrc_reference_data - the name of the table to get the seed data from. |
| SEEDTABLECOLUMNS= | Comma separated list of the columns in SEEDTABLE. |
| SHUFFLEDISTINCT Y/N | Y selects distinct values for the shuffle creates. N is default and selects all values. |
| SHUFFLELIMIT n | Only select n values for the shuffle. |
| SHUFFLEONLY Y/N | Y does not update the database, instead it just produces the shuffle files or database shuffle values. |
| BADDATESTRING= | For DOB/DOD on dates stored in character fields. Specify the date to replace the unparseable data as YYYY/MM/DD. | |
| BLANKSASNULLS=Y | Sets all blank values as Nulls.
Note: |
|
| CASEINSENSITIVESEED= |
Y - Makes the search on rd_ref_value column, using RANDLOV1 function case insensitive Note: |
|
| DBUPDATES= | N | Run in simulation mode. |
| S | Creates SQL file <table
name>_UPDATES.sql
Note: |
|
| P |
|
|
| V | Do not perform database update, just validate CSV map. | |
| DB2BATCHUPDATE= |
N (Default). If Y, use fast batched updates rather standard ‘update where current of’ cursor method (DB2 only). |
|
| DIAGLEVEL= | 0,1 or 2. Debug info will be output according to value. | |
| EMPTYASNULL=Y |
Treats all blanks or spaces as null values Note: |
|
| LOADALLSEEDDATA= | N (default) - Loads all seed data into Java memory for the RANDLOV1 function, irrespective of the distribution of rd_ ref_values in the table to be masked. | |
| ORDERBY= |
Y (Default) - Decides whether or not selected data will be ordered by PK columns. You may wish to turn off for VMS. Note: |
|
| PROCESSCOUNT= | Limits the number of rows processed in a run, allowing you to check the mapping without doing a full masking run. | |
| RELAXNONINDEXVALID= | XREF on non varchar columns of no PK/UK tables. | |
| WHEREASSUBSET |
Y (default) - use as WHERE subset on flat files. N - use WHERE as criteria for masking and output all records. |
|
| USERFAASINDEX= | Use RFA in WHERE clause of the update SQL (VMS DB ONLY). | |
| USERRNASINDEX= | For non-indexed tables, use RRN function to get row identifier - then combine with DB2BATCHUPDATE to use fast method (DB2400 ONLY). | |