Cluster Framework: Replication
For
Licensing Prerequisites, please refer to the relevant chapter.
Data replication in a cluster aims to achieve a synchronized state between all nodes at all times. The secondary nodes in the cluster keep read-only replicas of the data from the primary node.
Provider Library
The Provider library named libadaclu.so of version 4.9 or higher is part of the Adabas package and is loaded at start-up, if a cluster port is defined.
Provider library log messages are written to the Adabas nucleus log file, they are marked with [WSREP], e.g. on log level INFO.
Example:
...
2022-01-01 00:00:00.000 %ADANUC-I-WSREP, wsrep_load(): loading provider library '<ADAPROGDIR>/lib/libadaclu.so'
2022-01-01 00:00:00.000 %ADANUC-I-WSREP, wsrep_load(): Galera 4.9(rc71a9890) by Codership Oy <info@codership.com> loaded successfully.
...
2022-01-01 00:00:00.000 %ADANUC-I-WSREP, gcomm: connected
...
2022-01-01 00:00:00.000 %ADANUC-I-WSREP, Restored state OPEN -> JOINED (1)
...
The log messages from wsrep hooks (callbacks) are marked with [ADAADC] keyword at the beginning.
Example:
...
2022-01-10 09:31:32.140 %ADANUC-I-ADAADC, Cluster connected as PRIMARY
2022-01-10 09:31:32.140 %ADANUC-I-ADAADC, View state: b2958546-8f33-11ec-b845-072964f24b19:1(PRIMARY), 1 members
2022-01-10 09:31:32.140 %ADANUC-I-ADAADC, View member * 0: b294a235-8f33-11ec-89b4-624f354e9d1a 'susada2c-55189' incoming:'adatcp://susada2c:56189'
...
2022-01-10 09:31:32.481 %ADANUC-I-ADAADC, Cluster synced
...
Write-Set Replication API
Synchronous replication systems generally use eager replication. Nodes in a cluster will synchronize with all other nodes by updating the replicas through a single transaction. This means that when a transaction is committed, all of the nodes will have the same value. This process takes place using write-set replication through group communication.
Database Management System (DBMS)
The Adabas database server that runs on an individual node.
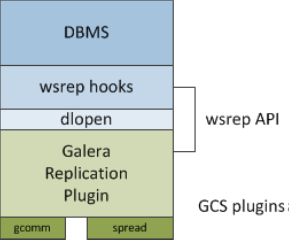
wsrep API: This is the interface to the database server and it’s the replication provider. It consists of two main elements:
wsrep Hooks: This integrates with the database server engine for write-set replication.
dlopen(): This function makes the wsrep provider available to the wsrep hooks.
Replication Plugin: This plugin enables write-set replication service functionality.
Group Communication Plugins: There are several group communication systems available to the cluster (note: gcomm is used in Adabas integration).
wsrep API
The wsrep API is a generic replication plugin interface for databases. It defines a set of application callbacks and replication plugin calls.
The wsrep API uses a replication model that considers the database server to have a state. That state refers to the contents of the database. When a database is in use and clients modify the database content, its state is changed. The wsrep API represents changes in the database state as a series of atomic changes, or transactions.
In a database cluster, all nodes always have the same state. They synchronize with each other by replicating and applying state changes in the same serial order.
From a more technical perspective, the Cluster handles state changes in the following way:
On one node in the cluster, a state change occurs in the database.
In the database, the wsrep hooks translate the changes to the write-set.
dlopen() then makes the wsrep provider functions available to the wsrep hooks.
The framework’s Replication plugin handles write-set certification and replication to the cluster.
For each node in the cluster, the application process occurs by high-priority transactions.
Global Transaction ID
To keep the state identical across the cluster, the wsrep API uses a Global Transaction ID, or GTID. This allows it to identify state changes and to identify the current state in relation to the last state change. Below is an example of a GTID:
45eec521-2f34-11e0-0800-2a36050b826b:94530586304
The Global Transaction ID consists of the following components:
State UUID:
This is a unique identifier for the state and the sequence of changes that it undergoes.
Ordinal Sequence Number:
The seqno is a 64-bit signed integer used to denote the position of the change in the sequence.
The Global Transaction ID allows you to compare the application state and establish the order of state changes. You can use it to determine whether a change was applied and whether the change is applicable to a given state.
Replication Plugin
The Replication Plugin implements the wsrep API. It operates as the wsrep Provider. From a more technical perspective, the Replication Plugin consists of the following components:
Certification Layer:
This layer prepares the write-sets and performs the certification checks on them, ensuring that they can be applied.
Replication Layer:
This layer manages the replication protocol and provides the total ordering capability.
Group Communication Framework:
This layer provides a plugin architecture for the various group communication systems that connect to the Cluster.
Group Communication Plugins
The Group Communication Framework provides a plugin architecture for the various gcomm systems.
The Cluster Framework is built on top of a proprietary group communication system layer, which implements a virtual synchrony QoS. Virtual synchrony unifies the data delivery and cluster membership services, providing a clear formalism for message delivery semantics.
While virtual synchrony guarantees consistency, it does not guarantee temporal synchrony, which would be necessary for smooth operations with several primary nodes. To address this, the Cluster Framework implements its own runtime-configurable temporal flow control. Flow control keeps nodes synchronized within a fraction of a second.
The Group Communication Framework also provides a total ordering of messages from multiple sources. It uses this to generate Global Transaction ID’s in a cluster employing several primary nodes.
At the transport level, the Cluster Framework is a symmetric, undirected graph. All database nodes connect to each other over a TCP connection. By default, TCP is used for both message replication and the cluster membership services. However, you can also use UDP multicast for replication in a LAN.
Certification-Based Replication
Certification-based replication uses group communication and transaction ordering techniques to achieve synchronous replication.
Transactions execute optimistically in a single node, or replica, and then, at commit time, they run a coordinated certification process to enforce global consistency. This ensures global coordination with the help of a broadcast service, establishing a global total order among concurrent transactions.
Certification-Based Replication Requirements
It’s not possible to implement certification-based replication for all database systems. Specific features of the database are required for this to work:
Transactional Database:
The database must be transactional. Specifically, it must be able to rollback uncommitted changes.
Atomic Changes:
Replication events must be able to change the database atomically. All, of a series of database operations in a transaction, must occur, or else, nothing occurs.
Global Ordering:
Replication events must be ordered globally. Specifically, they are applied on all instances in the same order.
How Certification-Based Replication Works
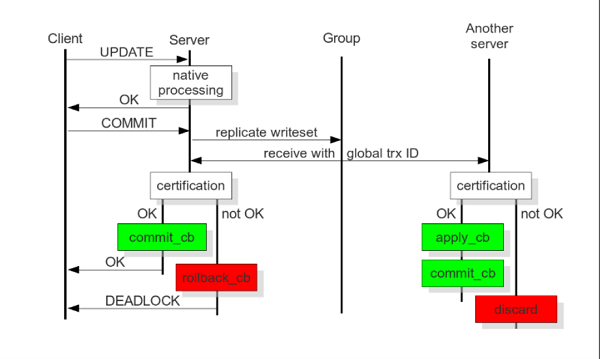
The main idea in certification-based replication is that a transaction executes conventionally until it reaches the commit point, while assuming that there is no conflict. This is called optimistic execution.
When the client issues a COMMIT command, before the actual commit occurs, all changes made to the database by the transaction and primary keys of the changed rows, are collected into a write-set. The database then sends this write-set to all other nodes.
The write-set then undergoes a deterministic certification test, using the primary keys. This is done on each node in the cluster, including the node that originates the write-set. It determines whether the node can apply the write-set.
If the certification test fails, the node drops the write-set and the cluster rolls back the original transaction. However, if the test succeeds, the transaction commits and the write-set is applied to the rest of the cluster.
Certification-Based Replication in the Adabas Cluster Framework
The implementation of certification-based replication in the Cluster Framework depends on the global ordering of transactions.
During replication, the Cluster assigns to each transaction a global ordinal sequence number, or seqno. When a transaction reaches the commit point, the node checks the sequence number and compares it to the last successful transaction. The interval between the two is the areaof concern, given that transactions that occur within this interval have not seen the effects of each other. All transactions in this interval are checked for primary key conflicts with the transaction in question. The certification test fails if it detects a conflict.
The procedure is deterministic and all replica receive transactions in the same order. Thus, all nodes reach the same decision about the outcome of the transaction. The node that started the transaction can then notify the client application if it has committed the transaction.
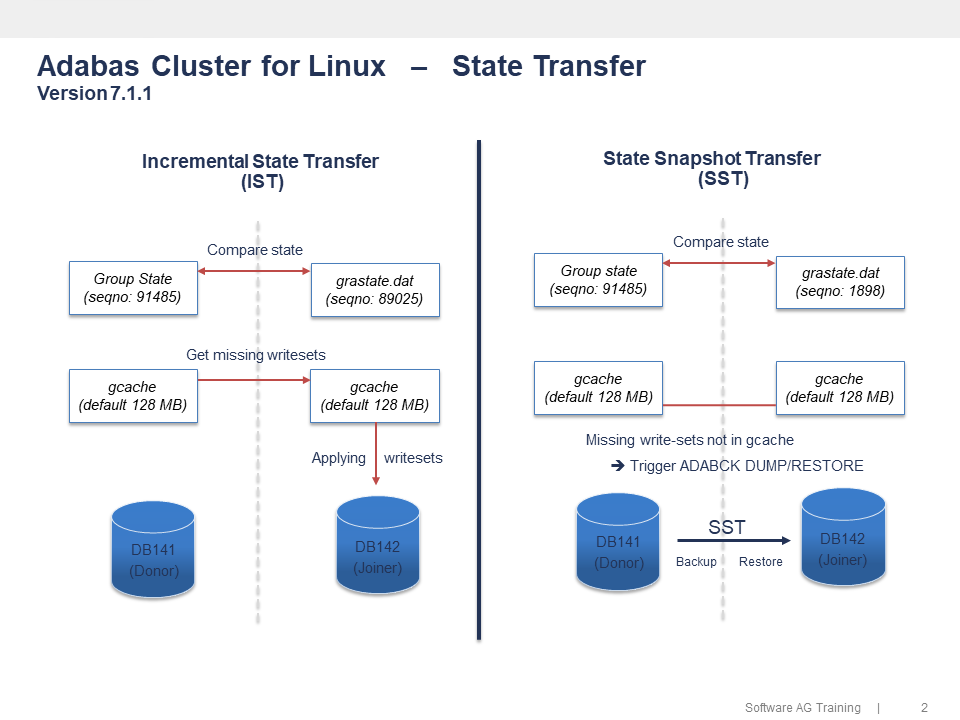
State Transfer - IST versus SST
When an Adabas node joins an existing cluster, a 'state snapshot transfer' (SST) will be initiated - the Donor node executes an 'adabck dump=*' , sends it to the Joiner node and an 'adabck restore=*' will be executed.
When an Adabas node re-joins a cluster, it will check the local gcache file to determine whether it needs to perform 'incremental state transfer' (IST) or 'state snapshottransfer' (SST).The gap between group state and the local state stored in grastate.dat will be calculated. If all of the missing writesets can be found in the Donor's gcache file, it will perform IST by getting the missing writesets and catching up the group by replaying them. This is faster than SST, and not blocking the Donor side.
For more detailed information regarding Initial State processing, see
Initial State.
Node States
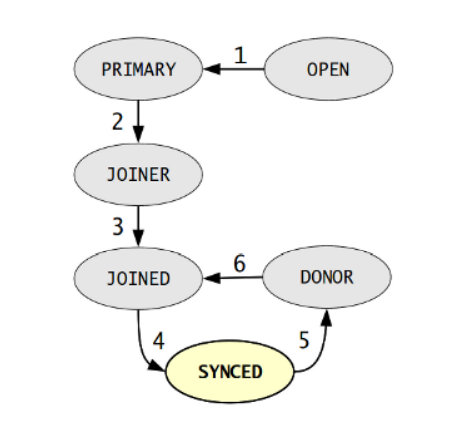
Following node states are possible:
 UNDEFINED
UNDEFINED indicates a starting node that is not part of the Primary Component and therefore not allowed to accept update commands.
JOINER indicates a node that is part of the Primary Component and is receiving a state snapshot transfer.
DONOR indicates a node that is part of the Primary Component and is sending a state snapshot transfer.
JOINED indicates a node that is part of the Primary Component and is in a complete state and is catching up with the cluster.
SYNCED indicates a node that is syncrhonized with the cluster.
ERROR indicates that an error has occurred. This status string may provide an error code in the nucleus log file with more information on what occurred.
1. The node starts and establishes a connection to the Primary Component.
2. When the node succeeds with a state transfer request, it begins to cache write-sets.
3. The node receives a State Snapshot Transfer. It now has all cluster data and begins to apply the cached write-sets.
4. The node finishes catching up with the cluster.
5. The node receives a state transfer request. Flow Control relaxes to DONOR. The node caches all write-sets it cannot apply.
6. The node completes the state transfer to Joiner Node.