このドキュメントでは ADAORD ユーティリティについて説明します。
次のトピックについて説明します。
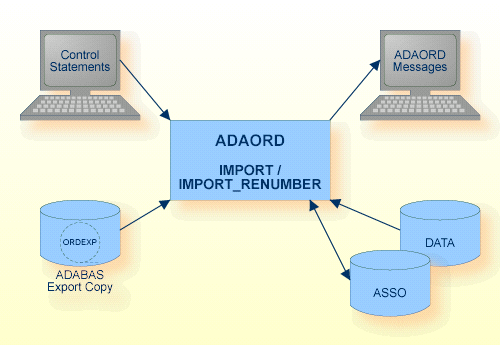
リオーダユーティリティ ADAORD は、データベース全体を再編成する機能(REORDER)とデータベース間でファイルを移行する機能(EXPORT/IMPORT)を提供します。
選択する機能によって、シーケンシャルファイル(ORDEXP)は、ADAORD が作成するファイルになったり、ADAORD の処理に必要なファイルになったりします。
ADAORD を実行する主な目的は、次のとおりです。
完全なデータベースのレイアウトを変更する。使用可能な最大ファイル番号を増やしたり、減らしたりすることも含まれます。
スペース割り当てやファイルの配置を変更する。インデックス、アドレスコンバータ、またはデータストレージに割り当てられている論理エクステント数を減らすことも含まれます。また、パディングファクタを変更したり、再確立したりします。
すべて同じデータを持つ 1 つ以上のテストファイルを作成する。このようなファイルを作成する場合には、ファイルをエクスポートしてから、別々のファイル番号を使用してインポートする必要があります。
ファイルの元の場所がどこにあったかや、データベースに使用したデバイスの種類が何であるかに関係なく、ファイルをアーカイブし、その後でファイルを再度復元する。
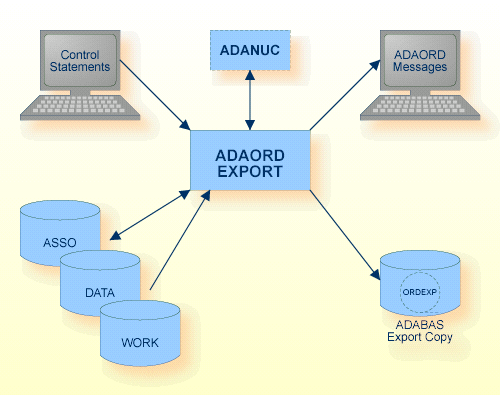
データベースからファイルをエクスポートするとき、Adabas ニュークリアスは不要です。システムファイルを処理する場合、ニュークリアスは非アクティブにする必要があります。詳細については、ニュークリアス条件の表を参照してください。
データベースにファイルをインポートするときに、Adabas ニュークリアスはアクティブである必要はありません。したがって、この手順を進めているときに、ニュークリアスを起動しても、シャットダウンしてもかまいません。
データベースをリオーダするときに、Adabas ニュークリアスがアクティブであってはいけません。
注意:
IMPORT および IMPORT_RENUMBER 機能では、以前の Adabas バージョンで作成されたエクスポートファイルを処理できますが、より新しい Adabas バージョンで作成されたエクスポートファイルは処理できません。
このユーティリティは単一機能ユーティリティです。
シーケンシャルファイル ORDEXP は複数のエクステントを持つことができますが、RAW デバイスを使用している場合に限られます。複数のエクステントを持つシーケンシャルファイルの詳細については、『Adabas Basics』の「ユーティリティの使用」を参照してください。
|
|
シーケンシャルファイル ORDEXP は複数のエクステントを持つことができますが、RAW デバイスを使用している場合に限られます。複数のエクステントを持つシーケンシャルファイルの詳細については、『Adabas Basics』の「ユーティリティの使用」を参照してください。
| データセット | 環境 変数/ 論理名 |
記憶 媒体 |
追加情報 |
|---|---|---|---|
| アソシエータ | ASSOx | ディスク | |
| データストレージ | DATAx | ディスク | |
| エクスポートコピー | ORDEXP | ディスク、テープ(* 注参照) | エクスポート(出力)、 リオーダ(入出力)、 その他の機能(入力) |
| コントロールステートメント | stdin/ SYS$INPUT |
ユーティリティマニュアル | |
| ADAORD メッセージ | stdout/ SYS$OUTPUT |
メッセージおよびコード | |
| ワークストレージ | WORK1 | ディスク |
注意:
(*)このシーケンシャルファイルには、名前付きパイプは使用できません(詳細については『管理マニュアル』の「ユーティリティの使用」を参照)。
次の表は、各機能に対するニュークリアス条件と記録チェックポイントを示しています。
| 機能 | ニュークリアスのアクティブ化が必要 | ニュークリアスの非アクティブ化が必要 | ニュークリアスは不要 | 記録チェックポイント |
|---|---|---|---|---|
| CONTENTS | X | - | ||
| EXPORT | X(* 注参照) | X | SYNX | |
| IMPORT | X(* 注参照) | X | SYNP | |
| IMPORT_ RENUMBER |
X(* 注参照) | X | SYNP | |
| REORDER | X | X | SYNP |
注意:
(*)Adabas システムファイルの処理時。
EXPORT 機能の場合、ADAORD は 1 つのチェックポイントを書き出し、指定したファイルすべてがエクスポートされてシーケンシャル出力ファイル(ORDEXP)がクローズすると、UCB エントリを削除します。
IMPORT 機能の場合、ADAORD はチェックポイントを書き出し、ファイルが正常にインポートされるたびにファイルがロードされたことをニュークリアスに知らせます。
UCB エントリは、指定したファイルすべてがインポートすると削除されます。ユーティリティをオフラインで実行すると、複数のチェックポイントが書き出されるので、チェックポイントブロック(CPB)オーバーフローの可能性が大きくなります。Adabas ニュークリアスを起動して CPB を空にできるように、チェックポイントファイルは常に存在していなければなりません。
データベースレベルでの REORDER 機能の場合、ADAORD は 1 つのチェックポイントを書き出し、この機能が終了すると UCB エントリを削除します。
次のコントロールパラメータを使用できます。
CONTENTS
DBID = number
EXPORT = (number[-number][,number[-number]]...)
[,FDT]
D [,SORTSEQ = ({descriptor_name|ISN|PHYSICAL},...)]
FILES = (number[[-number], number[-number]] ...)
IMPORT = (number[-number][,number[-number]]...)
[,ACRABN = number]
[,ASSOPFAC = number]
[,DATAPFAC = number]
[,DSRABN = number] [,DSSIZE = number[B|M] ]
[,LOBACRABN = number]
[,LOBDSRABN = number]
[,LOBNIRABN = number]
[,LOBSIZE = numberM]
[,LOBUIRABN = number]
[,MAXISN = number]
[,NIRABN = number|(number,number)]
[,NISIZE = number[B|M]|(number[B|M],number[B|M])]
[,UIRABN = number|(number,number)]
[,UISIZE = number[B|M]|(number[B|M],number[B|M])]
IMPORT_RENUMBER = (number, number[,number])
[,ACRABN = number]
[,ASSOPFAC = number]
[,DATAPFAC = number]
[,DSRABN = number] [,DSSIZE = number[B|M] ]
[,LOBACRABN = number]
[,LOBDSRABN = number]
[,LOBNIRABN = number]
[,LOBSIZE = numberM]
[,LOBUIRABN = number]
[,MAXISN = number]
[,NIRABN = number|(number,number)]
[,NISIZE = number[B|M]|(number[B|M],number[B|M])]
[,UIRABN = number|(number,number)]
[,UISIZE = number[B|M]|(number[B|M],number[B|M])]
REORDER = *
CONTENTS
この機能は、前回の EXPORT パラメータの実行で作成されたシーケンシャル出力ファイル(ORDEXP)内のファイルのリストを表示するものです。
DBID = number
このパラメータは、使用対象となるデータベースを選択するためのものです。
EXPORT = (number[-number][,number[-number]]...)
[,FDT]
[,SORTSEQ = ({descriptor_name|ISN|PHYSICAL},...)]
この機能は、データベースから 1 つ以上のファイルをシーケンシャル出力ファイル(ORDEXP)にエクスポート(コピー)するものです。エクスポートコピーで参照整合性を維持するために、指定されたファイルに参照制約を介して接続されているすべてのファイルもエクスポートされます。指定されたファイル番号は、基本ファイルのファイル番号である場合にのみ考慮されます。選択したファイルに対応する LOB ファイルは、基本ファイルとともに自動的にエクスポートされるので、指定する必要はありません。EXPORT は、各ファイルのデータストレージをそのインデックスの再構築に必要な情報とともにコピーします。処理対象のすべてのファイルは、指定された順に ORDEXP に書き出されます。重複する範囲と番号は削除されます。
注意:
チェックポイントファイルがファイルリストに含まれている場合は、最後に書き出されます。
このパラメータは、処理対象のファイルの FDT を表示します。
このパラメータは、データストレージが処理される順序を制御します。ディスクリプタ、サブディスクリプタまたはスーパーディスクリプタのフィールド名か、キーワード "ISN" または "PHYSICAL" のいずれかを指定できます。
デフォルトは物理順です。
次の値を指定することができます。
| 値 | シーケンス |
|---|---|
| descriptor_name |
ディスクリプタ、サブディスクリプタまたはスーパーディスクリプタのフィールド名を指定する場合、データレコードはそのフィールド名が参照するディスクリプタ値の昇順の論理順に処理されます。 MU、MC、または NU オプションを持つフィールドや、このようなフィールドから派生したピリオディックグループ、サブディスクリプタ、スーパーディスクリプタに含まれるフィールドは、指定することができません。 論理順は、単一のファイルを選択した場合のみ使用できます。 |
| ISN |
ISN を指定すると、データレコードは ISN の昇順に処理されます。 |
| PHYSICAL |
PHYSICAL を指定する場合または SORTSEQ パラメータを指定しない場合、データレコードはデータストレージに格納されている物理順に処理されます。 |
データベースがオンラインであれば(さらにバッファプールの大きさが十分に大きい場合)、論理順および ISN 順で処理するときのパフォーマンスは向上します。
1 つの値を SORTSEQ に対して指定する場合、その値が全ファイルに有効です。複数の値を指定する場合、値の個数は EXPORT パラメータに指定されたファイル範囲の数と同じでなければなりません。この場合、最初のファイル範囲は最初に指定されたソート順でエクスポートされ、2 番目の範囲は 2 番目に指定されたソート順でエクスポートされ、次々と同様にエクスポートされます。
EXPORT = (1, 20-30, 40) SORTSEQ = (AA, PHYSICAL, ISN)
ファイル 1 はディスクリプタ AA の順番でエクスポートされます。ファイル 20~30 は物理順で、ファイル 40 は ISN 順でエクスポートされます。
FILES = (number[[-number], number[-number]] ...)
このパラメータは、シーケンシャル入力ファイル(ORDEXP)に含まれているファイルを指定し、そのステータスに関する情報を表示させるために使用します。
IMPORT = (number[-number][,number[-number]]...)
[,ACRABN = number]
[,ASSOPFAC = number]
[,DATAPFAC = number]
[,DSRABN = number] [,DSSIZE = number[B|M] ]
[,LOBACRABN = number]
[,LOBDSRABN = number]
[,LOBNIRABN = number]
[,LOBSIZE = numberM]
[,LOBUIRABN = number]
[,MAXISN = number]
[,NIRABN = number|(number,number)]
[,NISIZE = number[B|M]|(number[B|M],number[B|M])]
[,UIRABN = number|(number,number)]
[,UISIZE = number[B|M]|(number[B|M],number[B|M])]
この機能は、前回の ADAORD の実行で作成されたシーケンシャルファイル(ORDEXP)のデータを使用して、データベースに 1 つ以上のファイルをインポートします。参照整合性を維持するために、指定されたファイルに参照制約を介して接続されているすべてのファイルもインポートされます。指定されたファイル番号は、基本ファイルのファイル番号である場合にのみ考慮されます。選択したファイルに対応する LOB ファイルは、基本ファイルとともに自動的にエクスポートされるので、指定する必要はありません。指定されたファイル番号は昇順でソートされます。重複する範囲と番号は削除されます。
指定されたファイル番号はデータベースにロードしないでください。
デフォルトとして、ADAORD はファイル配置や割り当て量を制御します。デフォルトを上書きするためのパラメータは、単一ファイルが選択されたときだけ使用できます。
パラメータの詳細については、IMPORT_RENUMBER 機能の説明を参照してください。
IMPORT_RENUMBER = (number, number[,number])
[,ACRABN = number]
[,ASSOPFAC = number]
[,DATAPFAC = number]
[,DSRABN = number] [,DSSIZE = number[B|M] ]
[,LOBACRABN = number]
[,LOBDSRABN = number]
[,LOBNIRABN = number]
[,LOBSIZE = numberM]
[,LOBUIRABN = number]
[,MAXISN = number]
[,NIRABN = number|(number,number)]
[,NISIZE = number[B|M]|(number[B|M],number[B|M])]
[,UIRABN = number|(number,number)]
[,UISIZE = number[B|M]|(number[B|M],number[B|M])]
この機能は、前の ADAORD 実行で出力されたシーケンシャルファイル(ORDEXP)のデータを使用して、ファイルをデータベースにインポートします。別のファイルに参照整合性を介して接続されているファイルは、インポートして番号を変更することはできません。ファイルをエクスポートする前に制約をドロップするか、ファイルを番号変更せずにインポートして後で番号を変更する必要があります(ADADBM RENUMBER)。最初に指定された番号は、インポートする基本ファイルを定義します。2 番目の番号は、そのファイルに割り当てる新しいファイル番号になります。第 3 の任意指定の数値は、LOB ファイルの新しいファイル番号です。第 3 の数値を指定しない場合、LOB ファイル番号(存在する場合)は変更されません。
新しいファイル番号をデータベースにロードしないでください。
特にそうしないという明示的な指定がない限り、ADAORD はファイル配置と割り当て量を制御します。
このパラメータは、アドレスコンバータ(AC)のスペース割り当てを開始する RABN を指定するものです。
このパラメータ指定がなければ、ADAORD が開始 RABN を割り当てます。
このパラメータは、ファイルのインデックスに使用する新しいパディングファクタを指定します。ADAORD やその後で実行する一括更新ユーティリティ ADAMUP で使用されない各インデックスブロックの割合を数値で指定します。このパディングエリアは、Adabas ニュークリアスによって、将来ブロックにエントリを追加する必要が発生した場合に使用できるように予約されています。これにより、オーバーフローエントリを他のブロックに再配置する必要がなくなります。
指定可能な値の範囲は 0~95 です。
ディスクリプタの更新頻度が少ないかまったくない場合には、小さいパディングファクタ(0~10)を指定します。大きいパディングファクタ(10~50)は、新規にディスクリプタ値が作成されて、大量のディスクリプタの更新が予想される場合に指定する必要があります。
このパラメータを省略すると、ファイルのインデックスで現在有効なパディングファクタが使用されます。
このパラメータは、ファイルのデータストレージに使用する新しいパディングファクタを指定します。各データブロックのうち ADAORD によって使用されない部分の割合を数値として指定します。このパディングエリアは、将来 Adabas ニュークリアスによるレコード更新の結果として、ブロック内のレコードに追加スペースが必要になった場合に使用するため予約されます。これにより、オーバーフローエントリを他のブロックに再配置する必要がなくなります。
指定可能な値の範囲は 0~95 です。
レコード拡張の頻度が少ないかまったくない場合は、小さいパディングファクタ(0~10)を指定します。拡張が発生するような大量のレコード更新がある場合は、大きなパディングファクタ(10~50)を指定します。
このパラメータを省略すると、ファイルのデータストレージで現在有効なパディングファクタが使用されます。
このパラメータは、ファイルのデータストレージ(DS)のスペース割り当てを開始する RABN を指定するものです。
このパラメータを省略した場合、ADAORD が開始 RABN を割り当てます。
このパラメータは、ファイルのデータストレージ(DS)に最初に割り当てられるブロック数またはメガバイト数を指定するものです。デフォルトでは、サイズはメガバイト単位で認識されます。
このパラメータを省略した場合、ADAORD は、割り当てられているブロック数の古い数値と新旧パディングファクタの差に基づいてサイズを計算します。
このパラメータの値は、LOB ファイルのアドレスコンバータ(AC)のスペース割り当てがどこから始まるのかを示す RABN です。
このパラメータを省略した場合、ADAORD が開始 RABN を割り当てます。
このパラメータの値は、LOB ファイルのデータストレージ(DS)のスペース割り当てがどこから始まるのかを示す RABN です。
このパラメータを省略した場合、ADAORD が開始 RABN を割り当てます。
このパラメータの値は、LOB ファイルのノーマルインデックス(NI)のスペース割り当てがどこから始まるのかを示す RABN です。
このパラメータを省略した場合、ADAORD が開始 RABN を割り当てます。
このパラメータの値は、LOB ファイルのデータストレージ(DS)に最初に割り当てられるメガバイトの数です。LOB ファイルの AC サイズ、NI サイズ、UI サイズは、このサイズから派生します。
このパラメータを省略した場合、ADAORD は、割り当てられているブロック数の古い数値と新旧パディングファクタの差に基づいてサイズを計算します。
このパラメータの値は、LOB ファイルのアッパーインデックス(UI)のスペース割り当てがどこから始まるのかを示す RABN です。
このパラメータを省略した場合、ADAORD が開始 RABN を割り当てます。
このパラメータは、ファイルに対する最大許容 ISN を指定するものです。ADAORD は、このパラメータを使用して、ファイルのアドレスコンバータ(AC)に割り当てられるスペース量を決定します。
初期割り当ての自動拡張機能がないため、ファイルの最初のフリー ISN よりも値が小さいと、アドレスコンバータに入らない ISN が存在する場合、ADAORD は実行を終了し、エラーステータスを返します。
このパラメータを指定しないと、ファイルのアドレスコンバータに対して現在有効な MAXISN の値が使用されます。
できるだけ連続領域をとるように試行されます。
このパラメータは、ファイルのノーマルインデックス(NI)のスペース割り当てを開始する RABN(複数可)を指定するものです。通常、Adabas は小さいインデックスブロック(ブロックサイズが 16 KB 未満の場合)には小さいディスクリプタ値(253 バイト以下)を、大きいインデックスブロック(ブロックサイズが 16 KB 以上の場合)には大きいディスクリプタ値を格納します。このため、2 つの RABN を指定することが可能です。RABN を 2 つ指定する場合、一方は 16 KB 未満のブロックサイズ、もう一方は 16 KB 以上のブロックサイズにする必要があります。
このパラメータを省略した場合、ADAORD が開始 RABN を割り当てます。
このパラメータは、ファイルのノーマルインデックス(NI)に最初に割り当てられるブロック数またはメガバイト数を指定するものです。デフォルトでは、サイズはメガバイト単位で認識されます。2 つの値が指定され、NIRABN パラメータも指定された場合、最初の値は NIRABN パラメータの最初の値に対応し、2 番目の値は NIRABN パラメータの 2 番目に対応します。2 つの値が指定され、NIRABN パラメータが指定されていない場合、最初の値は小さいノーマルインデックスブロック(16 KB 未満)のサイズを指定し、2 番目の値は大きい NI ブロック(16 KB 以上)のサイズを指定します。
このパラメータを省略した場合、ADAORD は、割り当てられているブロック数の古い数値と新旧パディングファクタの差に基づいてサイズを計算します。
このパラメータは、ファイルのアッパーインデックス(UI)のスペース割り当てを開始する RABN(複数可)を指定するものです。通常、Adabas は小さいインデックスブロック(ブロックサイズが 16 KB 未満の場合)には小さいディスクリプタ値(253 バイト以下)を、大きいインデックスブロック(ブロックサイズが 16 KB 以上の場合)には大きいディスクリプタ値を格納します。このため、2 つの RABN を指定することが可能です。RABN を 2 つ指定する場合、一方は 16 KB 未満のブロックサイズ、もう一方は 16 KB 以上のブロックサイズにする必要があります。
このパラメータを省略した場合、ADAORD が開始 RABN を割り当てます。
このパラメータは、ファイルのアッパーインデックス(UI)に最初に割り当てられるブロック数(B)またはメガバイト数(M)を指定するものです。デフォルトでは、サイズはメガバイト単位で認識されます。2 つの値が指定され、UIRABN パラメータも指定された場合、最初の値は UIRABN パラメータの最初の値に対応し、2 番目の値は UIRABN パラメータの 2 番目に対応します。2 つの値が指定されて、UIRABN パラメータが指定されていない場合、最初の値は小さいアッパーインデックスブロック(16 KB 未満)のサイズを指定し、2 番目の値は大きい UI ブロック(16 KB 以上)のサイズを指定します。
このパラメータを省略した場合、ADAORD は、割り当てられているブロック数の古い数値と新旧パディングファクタの差に基づいてサイズを計算します。
REORDER = *
この機能は、データベース全体のレイアウトを変更するために使用します。データベースのグローバルエリアを再配置し、DSST およびファイルのアドレスコンバータ、データストレージ、ノーマルインデックス、アッパーインデックスエクステントの物理的な位置を変更することにより、それらに含まれるフラグメントを除去します。また、ファイルのパディングファクタを再設定します。データベースコンテナファイルに対する排他制御が必要です。
データベースに対する REORDER は、ファイルを暗黙的にエクスポートし、データベースから削除し、再度インポートします。REORDER の実行中に作成されたシーケンシャルファイル(ORDEXP)はそのまま残ります。
注意:
ADAORD は、ファイルのディスクスペースを割り当てる最適なアルゴリズムを使用します。そのため、特定のタイプの最初のコンテナに続いて、最初のコンテナよりも小さく適切なブロックサイズを持つ別のコンテナが存在する場合、最初のコンテナが空のままになることがあります。
ADAORD は、再スタート機能を備えていません。
EXPORT が異常終了した場合は、最初から再実行しなければなりません。
1 つ以上のファイルの IMPORT が異常終了した場合、最後にインポートしていたファイルの RABN が失われます。これらの RABN は、ADADBM の RECOVER 機能を実行することで回復できます。割り込み発生時に処理中のファイルより前のファイルは、データベース内で利用できます。このため、割り込みの発生時点のファイル番号から IMPORT 機能を再実行する必要があります。
IMPORT_RENUMBER が異常終了すると、インポートしているファイルの RABN が失われます。これらの RABN は、ADADBM の RECOVER 機能を実行することで回復できます。IMPORT_RENUMBER 機能は最初からやり直す必要があります。
データベースレベルでの REORDER が異常終了した場合、データベースのグローバル領域(GCB、FST、DSST など)の再構築時に割り込みが発生すると、データベースにアクセスできなくなります。この場合、ADAFRM を使用して新規に空のデータベースを作成するか、ADABCK の RESTORE 機能を使用して、Adabas のバックアップコピーから古いデータベースを再設定しなければなりません。再インポート時に割り込みが発生すると、最後にインポートしていたファイルの RABN が失われます。これらの RABN は、ADADBM の RECOVER 機能を実行することで回復できます。割り込み発生時に処理中のファイルより前のファイルは、データベース内で利用できます。残りのファイルは、ADAORD の IMPORT 機能を使用してシーケンシャル WORK ファイル(ORDEXP)から取得できます。
次の例では、データベース 1 にファイル 1、2、4、6、7、8、10、11、12、および 25 がロードされています。データベース 2 には、ファイル 3、6、11 が含まれています。
adaord: dbid = 1 adaord: export = (1-4,7,10-25)
ファイル 1、2、4、7、10、11、12、および 25 がデータベース 1 からエクスポートされます。
adaord: dbid = 2 adaord: import = (1-10,12)
ファイル 1、2、4、7、10、および 12 がデータベース 2 にインポートされます。「import=(1-12)」は指定できません。ADAORD は、インポートするいずれかのファイルがすでにロードされているかどうかを先に確認し、ロードされている場合はインポート全体を拒否することが理由です。ここでは、ファイル 11 はすでにロードされています。
adaord: dbid = 2 adaord: import_renumber = (11,19), acrabn = 131, datapfac = 20
ファイル 11 は新規ファイル番号 19(11 はすでに使用されているため)を使用してデータベース 2 にインポートされます。ファイルのアドレスコンバータ(AC)は、ASSO RABN 131 に割り当てられます。データストレージ(DS)の新規パディングファクタは 20 %です。
adaord: dbid = 1 adaord: reorder = *
データベース全体がリオーダされます。