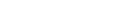
このドキュメントでは ADAMUP ユーティリティについて説明します。
次のトピックについて説明します。
一括更新ユーティリティ ADAMUP は、データベースのファイルにレコードを追加またはファイルからのレコードの削除を行います。Adabas ニュークリアスがアクティブである必要はありません。
圧縮ユーティリティ ADACMP またはアンロードユーティリティ ADAULD によって生成された出力ファイルを、大量追加の入力として使用できます。
注意:
ADAMUP ADD 機能は、以前の Adabas バージョンで作成された MUPDTA/MUPDVT ファイルを処理できますが、より新しい Adabas バージョンで作成された MUPDTA/MUPDVT ファイルは処理できません。
SINGLE_FILE オプションを指定した ADACMP または ADAULD によって生成された入力ファイルまたは LOG オプション指定の DELETE 機能を使用した ADAMUP の以前の実行によって生成された入力ファイルも使用できます。
処理対象のデータベースファイルにディスクリプタがなければ、ディスクリプタバリューテーブルなしに生成された入力ファイル(ADAULD の SHORT オプションまたは ADAMUP の LOG=SHORT オプション)が処理できます。
DELETE 機能に対する入力は、入力ファイルの指定の中に含まれます。各レコードには 1 つ以上の INS または ISN 範囲が含まれています。
ADAMUP の 1 回の実行中に、データベースファイルへのレコードの追加とデータベースファイルからのレコードの削除の両方を行うことが可能です。
エラーファイルにレコードが書き込まれると、ユーティリティはゼロ以外のステータスで終了します。
注意:
FDT が同じフィールドを含んでいても、照合ディスクリプタが異なる ICU バージョンに属している場合は、異なっていると見なされます。つまり、ICU バージョンが異なるファイルにデータをロードできるのは、ファイルが空で、かつ NEW_FDT パラメータを使用している場合だけです。
このユーティリティは単一機能ユーティリティです。
シーケンシャルファイル MUPDTA、MUPDVT、MUPTMP、MUPLOB、および MUPERR は複数エクステントを持つことができます。複数のエクステントを持つシーケンシャルファイルの詳細については、『Adabas Basics』の「ユーティリティの使用」を参照してください。
| データセット | 環境 変数/ 論理名 |
記憶 媒体 |
追加情報 |
|---|---|---|---|
| アソシエータ | ASSOx | ディスク | |
| データストレージ | DATAx | ディスク | |
| 圧縮済み入力 データ |
MUPDTA | テープ、ディスク | |
| ディスクリプタ値 | MUPDVT | テープ、ディスク | |
| 拒否データ | MUPERR | ディスク、テープ(* 注参照) | |
| LOB データ | MUPLOB | ディスク、テープ | 一時ワークスペース(ADAMUP 終了時に再度削除されます) |
| ノーマルインデックス | MUPTMP | ディスク、テープ | 一時ワークスペース(ADAMUP 終了時に再度削除されます) |
| ソートストレージ | SORTx TEMPLOCx |
ディスク | Adabas Basics マニュアル、一時ワークスペース |
| コントロールステートメント | stdin/ SYS$INPUT |
ユーティリティマニュアル | |
| ADAMUP メッセージ | stdout/ SYS$OUTPUT |
メッセージおよびコード | |
| 一時ストレージ | TEMPx | ディスク | |
| WORK | WORK1 | ディスク |
注意:
(*)このシーケンシャルファイルには、名前付きパイプを使用できます(OpenVMS にはない。詳細については、『Adabas Basics』の「ユーティリティの使用」を参照)。
アクティブなニュークリアスがなく、かつ保留になっている AUTORESTART もない場合は、環境変数/論理名 TEMP1 を WORK1 と同じ値に設定して、WORK を TEMP として使用できます。
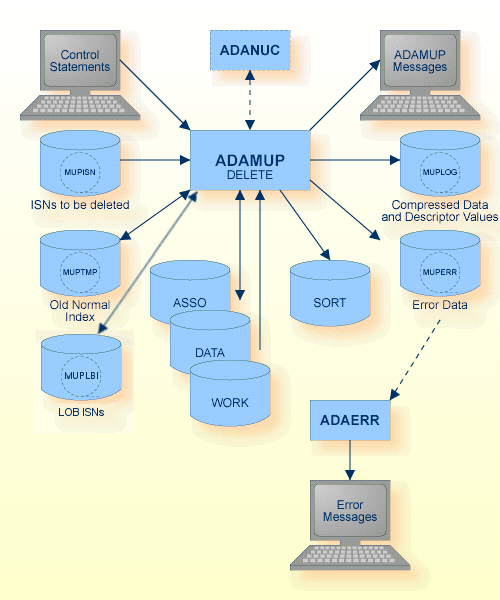
シーケンシャルファイル MUPTMP、MUPLBI、MUPLOG および MUPERR は複数エクステントを持つことができます。複数のエクステントを持つシーケンシャルファイルの詳細については、『Adabas Basics』の「ユーティリティの使用」を参照してください。
| データセット | 環境 変数/ 論理名 |
記憶 媒体 |
追加情報 |
|---|---|---|---|
| アソシエータ | ASSOx | ディスク | |
| データストレージ | DATAx | ディスク | |
| 拒否データ | MUPERR | ディスク、テープ(* 注参照) | |
| 削除する ISN | MUPISN | ディスク、テープ | |
| LOB ISN | MUPLBI | ディスク、テープ | 一時ワークスペース(ADAMUP 終了時に再度削除されます) |
| 圧縮データ | MUPLOG | ディスク、テープ | |
| ノーマルインデックス | MUPTMP | ディスク、テープ | 一時ワークスペース(ADAMUP 終了時に再度削除されます) |
| ソートストレージ | SORTx TEMPLOCx |
ディスク | Adabas Basics マニュアル、一時ワークスペース |
| コントロールステートメント | stdin/ SYS$INPUT |
ユーティリティマニュアル | |
| ADAMUP メッセージ | stdout/ SYS$OUTPUT |
メッセージおよびコード | |
| WORK | WORK1 | ディスク |
注意:
(*)このシーケンシャルファイルには、名前付きパイプを使用できます(OpenVMS にはない。詳細については、『Adabas Basics』の「ユーティリティの使用」を参照)。
次の表は、各機能に対するニュークリアス条件と記録チェックポイントを示しています。
| 機能 | ニュークリアスのアクティブ化が必要 | ニュークリアスの非アクティブ化が必要 | ニュークリアスは不要 | 記録チェックポイント |
|---|---|---|---|---|
| FDT | X | - | ||
| UPDATE | X(* 注 1 参照) | X(* 注 2 参照) | X(* 注 3 参照) | SYNP |
| SUMMARY | X | - |
注意:
次のコントロールパラメータを使用できます。
M DBID = number FDT SUMMARY UPDATE = number [,FDT] [ADD [,add_keywords]] [DELETE [,delete_keywords]] D [,[NO]FORMAT] D [LWP = number[K|M]]
DBID = number
このパラメータは、使用対象となるデータベースを選択するためのものです。
FDT
このパラメータは、データベースの選択されたファイルのフィールド定義テーブル(FDT)を表示します。ファイルにレコードを追加する場合、これらのレコードを含むシーケンシャル入力ファイルの FDT も表示することができます。このパラメータは ADD/DELETE 指定に使用することもできます。
FDT パラメータが使用される状況によって、シーケンシャル入力ファイル MUPDTA に含まれていたフィールド定義テーブルと、選択されたデータベースファイルに含まれていたフィールド定義テーブルのいずれか、または両方が表示されます。
adamup db=2 fdt update=11 add
MUPDTA ファイルに保存された FDT が表示されます。
adamup db=2 update=11,fdt add
データベース 2 のファイル 11 の FDT が表示されます。
adamup db=2 fdt update=11,fdt add
MUPDTA ファイルに保存された FDT が最初に表示され、次にデータベース 2 のファイル 11 の FDT が表示されます。
SUMMARY
このパラメータは、圧縮レコードが存在するシーケンシャル入力ファイルのディスクリプタスペースサマリ(DSS)を表示するものです。この表示は、この入力ファイルを生成した ADACMP、ADAULD または ADAMUP の実行の最後のものと同一であり、インデックスに必要なスペースの見積もりに使用できます。
さらに、次の情報が表示されます。
必要な SORT サイズ(デフォルトの LWP に対する)
TEMP の推奨サイズ(1 回のパスでインデックス更新を行うために必要なサイズ)
SORT の現在のサイズ(存在する場合)
メモリ内のソートに必要な LWP
LWP および SORT の推奨サイズ(小規模な SORT サイズを使用できるほど LWP が十分な大きさの場合)
注意:
デフォルトの LWP がメモリ内でソートを行うために十分な大きさの場合、SORT サイズは表示されません。
ADAMUP SUMMARY 処理の詳細については、『管理マニュアル』の「ADAMUP および ADAINV 処理の最適化」を参照してください。
UPDATE = number [,FDT]
[ADD [,add_keywords]]
[DELETE [,delete_keywords]]
[,[NO]FORMAT]
[LWP = number[K|M]]
このパラメータは、レコードを追加/削除するファイルを指定するものです。ADAMUP にはファイルの排他制御が必要なので、ニュークリアスがアクティブの間は、Adabas システムファイルに ADAMUP を使用できません。LOB ファイルを指定することはできません。
ADD [,DE_MATCH = keyword] [,FDT] [,[NO]NEW_FDT] [,NUMREC = number] [,SKIPREC = number] [,UQ_CONFLICT = keyword] [,RI_CONFLICT = keyword] [,[NO]USERISN]
このパラメータは、UPDATE パラメータによって指定されるファイルにレコードを追加することを指示します。
大量追加に対する入力は、圧縮ユーティリティ ADACMP、アンロードユーティリティ ADAULD によって、または LOG パラメータをセットした DELETE パラメータを使用する一括更新ユーティリティ ADAMUP の以前の実行によって生成されます。
ADAMUP は、圧縮レコードが存在するシーケンシャル入力ファイルの FDT を指定データベースファイルの FDT と比較します。FDT は、同一レイアウトの必要があり、同じフィールド名、形式、長さおよびパラメータを使用しなければなりません。
データベースファイル内のディスクリプタは、シーケンシャル入力ファイルにおける FDT で定義されたディスクリプタのサブセットにすることができますが、入力ファイルは、データベースファイルに定義されたすべてのディスクリプタのためのディスクリプタバリューテーブル(DVT)のエントリを含んでいる必要があります。したがって、ディスクリプタバリューテーブルなし(SHORT オプション)で作成された入力ファイルは、現在のデータベースファイルにおいてディスクリプタ定義がない場合のみ更新処理が可能です。
一括更新の入力に LOB データが含まれる場合、Adabas ファイルには LOB ファイルが割り当てられている必要があります。
このパラメータは、入力データとともに提供されたディスクリプタがファイルの実際の FDT にあるディスクリプタではない場合の対応処置の指示に使用します。キーワードに IDENTICAL を指定した場合、ADAMUP は処理を終了してエラーメッセージを返します。キーワードに SUBSET を指定した場合、ADAMUP は入力ファイルにあるディスクリプタを無視し、そのディスクリプタはデータベースファイルから除去されます。
デフォルトは DE_MATCH=IDENTICAL です。
NEW_FDT が指定されると、ファイルの FDT は MUPDTA ファイルの FDT で置換されます。ADAMUP が開始するときにファイルが空であるときにだけ、NEW_FDT は指定することができます。
データベース内のファイルの FDT および MUPDTA ファイルの FDT が異なる場合は、NEW_FDT を指定しなければなりません。FDT が異なっていて、ファイルが空でない場合は、一括更新は実行できません。
デフォルトは NONEW_FDT です。
このパラメータは、追加対象のレコード数を指定します。NUMREC を指定した場合、入力ファイルのエンドオブファイル条件によって ADAMUP 処理が終了しない限り、ADAMUP はあらかじめ NUMREC に定義されたレコード数の追加後に終了します。NUMREC および SKIPREC を指定しない場合、入力ファイルにある全レコードが追加されます。
このパラメータは、レコードの追加を始める前にスキップする入力ファイルのレコード数を指定します。
このパラメータは、ユニークディスクリプタに対して重複値が発見された場合の対応処置の指示に使用します。"keyword" の値は ABORT または RESET です。ABORT を指定した場合、重複する UQ ディスクリプタ値が検出されると、ADAMUP は処理を終了してエラーステータスを返します。RESET を指定した場合、矛盾する ISN はエラーログに書き込まれ、該当ディスクリプタの UQ ステータスが解除され、処理は続行します。
デフォルトは UQ_CONFLICT=ABORT です。
このパラメータは、参照整合性に違反した場合に実行するアクションを示すために使用します。"keyword" の値は ABORT または RESET です。ABORT を指定した場合、ADAMUP は終了し、エラーステータスが返されます。これらのインデックスはアクセス不可としてマークされます。RESET が指定されている場合、違反している制約は削除されます。どちらの場合も、違反した ISN はエラーログに保存されます。
デフォルトは RI_CONFLICT=ABORT です。
このオプションは、各レコードに割り当てられる ISN として入力ファイルの ISN を使用するかどうかを指示します。
ユーザーは、データベースファイルに追加する各レコードに対する ISN 割り当てを制御したい場合は、このオプションを USERISN に設定する必要があります。指定する各 ISN は次の条件を満たさなければなりません。
各データレコードの直前に付く 4 バイトの 2 進数であること。
ファイルに対する現在の制限(MAXISN)の範囲に入っていること。ファイルのアドレスコンバータは自動的に拡張されません。
指定ファイル内でユニークであること
上記の条件に当てはまらないと、ADAMUP は処理を終了してエラーメッセージを返します。
マルチプルバリューフィールドであるディスクリプタに基づいてアンロードによって作成された入力ファイルに対して、このパラメータを USERISN に設定すると、問題が発生する可能性があるので注意してください。その理由は、同じレコードが 2 回以上アンロードされていることがあるためです。詳細については、ADAULD ユーティリティの説明の中にある、SORTSEQ パラメータに関する説明を参照してください。
このオプションを NOUSERISN に設定する場合、各レコードの ISN は ADAMUP によって割り当てられます。ただし、ハイパー出口によって以前に再設定された DVT レコードの ISN は ADAMUP で変更されません。
デフォルトは NOUSERISN です。
DELETE
[,DATA_FORMAT = keyword]
[,FDT]
[,ISN_NOT_PRESENT = keyword]
[,LOG = keyword | ,NOLOG]
このパラメータは、UPDATE パラメータによって指定されるファイルからレコードを削除するために使用します。削除対象レコードの ISN は、入力ファイル内に与えられます。
このパラメータは、入力ファイルの削除対象 ISN を指定するレコードのデータタイプを定義します。各レコードには 1 つ以上の INS または ISN 範囲が含まれています。
正しい ISN は 1 から MAXISN までの範囲です。
サポートされるフォーマットに従って、次の "keyword" の値を指定できます。
| キーワード | 説明 |
|---|---|
| BINARY |
単一の ISN は 4 バイトのバイナリ値に含まれます。ISN 範囲は 2 つの連続するバイナリ値に含まれ、2 番目の値の最上位ビットが設定されます。 このファイル内のブロックは 2 バイトの長さフィールド(長さフィールド自体の長さを除く)から始まります。 注意: |
| DECIMAL |
各レコードは次のレイアウトを持ちます。 [number[-number] [,number[-number]]...] [;comment] "number" は 1 から 10 桁までの 10 進数です。 |
ADAMUP は、すべての入力レコードを第 1 ステップで検証します。ADAMUP は、検出されたエラーごとに行番号とオフセットを表示します。エラーが検出されるか、または入力ファイルがすべて解析されると、ADAMUP は実行を終了します。
デフォルトは DATA_FORMAT=BINARY です。
このパラメータは、入力ファイル内で指定された削除対象レコードの ISN が次のような場合の対応処置を指示します。
現在の制限(MAXISN)内にない場合
ファイルのアドレスコンバータ内にない場合
"keyword" に使用できる値は、次のとおりです。
| キーワード | 説明 |
|---|---|
| ABORT | 矛盾する ISN が検出されると、ADAMUP は実行を強制終了してエラーメッセージを返します。 |
| IGNORE | ADAMUP は、矛盾する ISN をエラーログに書き込み、処理を続行します。 |
デフォルトは ISN_NOT_PRESENT=IGNORE です。
LOG=keyword は、削除レコードをシーケンシャルファイルに記録することを指示します。レコードは圧縮形式で書き込まれ、圧縮ユーティリティ ADACMP およびアンロードユーティリティ ADAULD によって生成されるものと同じです。各データレコードの先頭にはその ISN が付くので、このファイルの再ロード時や大量追加時にこれらの ISN をユーザー ISN として使用できます(前述の USERISN パラメータを参照)。
"keyword" に使用できる値は、次のとおりです。
| キーワード | 説明 |
|---|---|
| FULL | インデックスの構築に必要なディスクリプタ値を出力ファイルに含める。 |
| SHORT | インデックスの構築に必要なディスクリプタ値を出力ファイルに含めない。 |
ADAMUP は、生成された圧縮データレコードとディスクリプタ値の両方を 1 つのファイルに書き込みます。
デフォルトは NOLOG です。
このパラメータは、(修正が行われた後)新インデックスが旧インデックスよりも少ないスペースしか必要としないときに、ファイルのノーマルインデックス(NI)のエクステントとアッパーインデックス(UI)のエクステントの最後にあるブロックの、フォーマット化を行うことができます。必要スペースが少なくなるというのは、インデックス内の削除、失われたインデックスブロックの修復またはパディングファクタの再確保の結果です。
これらのブロックはファイルの未使用ブロックに戻されるので、これらのブロックに格納されたデータが削除されていない場合は影響がありません。このパラメータを FORMAT に設定されると、ADAMUP はこれらのブロックをバイナリのゼロで上書きします。
デフォルトは NOFORMAT です。
ディスクリプタ値のソートのために、ADAMUP はメモリ内のワークプールを使用します。多くの場合、ワークプールのデフォルトサイズで、ADAMUP に最適なパフォーマンスがもたらされます。LWP パラメータにより、ワークプールを増やすことができます。デフォルトのワークプールサイズに追加されるスペースをバイト、キロバイト(K)、またはメガバイト(M)単位で定義します。
ワークプールサイズを大きくすると、次の場合に役立ちます。
お使いの環境で、大規模なワークプールを使用するとパフォーマンスが向上する場合。
SORT コンテナがディスクリプタ値をソートするには小さすぎる場合。適切な LWP パラメータにより、SORT コンテナの必要なサイズを縮小できます。
このパラメータに必要な値は、SUMMARY 機能を使用して特定できます。
ADAMUP は再スタート機能を備えていません。異常終了した ADAMUP は、最初から再実行しなければなりません。
データストレージスペースを使い果たした場合、ADAMUP は異常終了せずに、ロード済みのレコードのインデックスの構築を試みます。つまり、そのファイルの内容は変わらないので、追加のデータストレージスペースを割り当てれば、SKIPREC オプションを使って残りのレコードをロードできます。
SORT データセットは、アソシエータ、およびディスクリプタバリューテーブルが存在する入力ファイルと同じボリュームに置かないことをお勧めします。
SORT データセットは、少量のデータのみの追加時は省略できます。このとき、ADAMUP は、インコアソートを実行します。
必要な SORT および LWP サイズについての情報を得るには、SUMMARY 機能を使用します。
TEMP データセットは、ディスクリプタバリューテーブルが存在する入力ファイルおよび SORT と同じボリュームに置かないことがお勧めします。TEMP のサイズはノーマル/メインインデックスのロード時のパフォーマンスと密接な関係がありますが、ロードが正常に終了するどうかは、TEMP のサイズや有無とは関係がありません。
TEMP の推奨サイズを表示するには、SUMMARY 機能を使用します。
adamup: dbid=1 adamup: update=10 adamup: add, userisn
データベース 1 のファイル 10 に、新規レコードを追加します。各入力レコードに付けられた ISN が使用されます。
adamup: dbid=1 adamup: update=10 adamup: delete
入力ファイルに指定される ISN によって識別されるレコードが、データベース 1 のファイル 10 から削除されます。削除対象 ISN はバイナリ形式です。
adamup: dbid=1 adamup: update=10 adamup: add, skiprec=1000 adamup: delete, data_format=decimal, log=full
データベース 1 のファイル 10 を対象に、新規レコードの追加と、古いレコードの削除を行います。入力ファイルにある最初の 1000 レコードは追加されません。追加される各レコードの ISN は、ADAMUP によって割り当てられます。削除対象レコードの ISN は、入力ファイルに 10 進数形式で格納されます。削除されたすべてのレコードは、出力ファイルに記録されます。再ロードする場合、インバーテッドリストの再作成に必要な値はログに記録されています。