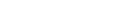
このドキュメントでは ADAINV ユーティリティについて説明します。
次のトピックについて説明します。
インバーテッドリストユーティリティ ADAINV は、データベース内にロードされたファイルに対するインバーテッドリストの作成、削除および検証を行います。Adabas ニュークリアスがアクティブである必要はありません。ADAINV の実行中に、ニュークリアスはアクティブな場合も、シャットダウンされている場合もあります。利用できる機能は次のとおりです。
INVERT 機能は、新しいディスクリプタを確立します。
REINVERT 機能は、RELEASE および INVERT を実行します。
RELEASE 機能は、既存のディスクリプタを削除します。
RESET_UQ 機能は、ディスクリプタのユニークステータスを解除します。
SET_UQ 機能は、既存のディスクリプタをユニークステータスに設定します。
SUMMARY 機能は、指定ディスクリプタのスペースの全体的な状態と、これらのディスクリプタを処理するために必要なサイズを表示します。
VERIFY 機能は、インバーテッドリストの整合性をチェックします。
LOB ファイルは、REINVERT 機能、SUMMARY 機能、VERIFY 機能のみに指定できます。
これらの機能は相互に排他的であり、このユーティリティの 1 回の実行では、これらの機能の 1 つのみを実行できます。
注意:
ADAINV がオンラインモードで実行されている場合は、ADAINV の実行中に、ファイルにアクセスする Adabas ユーザーがアクティブになっている可能性があります。
| 機能 | ACC ユーザー | UPD ユーザー |
|---|---|---|
| INVERT | ○ | × |
| REINVERT | × | × |
| RELEASE | × | × |
| RESET_UQ | ○ | × |
| SET_UQ | ○ | × |
| SUMMARY | ○ | ○ |
| VERIFY | ○ | × |
Adabas ユーザーは、ファイルの読み取りまたは検索処理のみを実行した場合、または適切なオープンコマンドを実行した場合、ACC ユーザーとなります。また、ファイルの挿入、更新、または削除処理を実行した場合、ファイルの ISN を排他的ホールド状態にした場合、または適切なオープンコマンドを実行した場合は、UPD ユーザーになります。
上記の表で定義されているように、許可されていないファイルのユーザーが存在する場合、ADAINV はエラー ADA048 で失敗します。
注意:
エラーファイルにレコードが書き込まれると、ユーティリティはゼロ以外のステータスで終了します。
このユーティリティは単一機能ユーティリティです。
シーケンシャルファイル INVERR は複数エクステントを持つことがあります。複数のエクステントを持つシーケンシャルファイルの詳細については、『Adabas Basics』の「ユーティリティの使用」を参照してください。
| データセット | 環境 変数/ 論理名 |
記憶 媒体 |
追加情報 |
|---|---|---|---|
| アソシエータ | ASSOx | ディスク | |
| データストレージ | DATAx | ディスク | |
| 拒否データ | INVERR | ディスク、テープ(* 注参照) | ADAINVの出力 |
| ソートストレージ | SORTx TEMPLOCx |
ディスク | Adabas Basics マニュアル、一時ワークスペース |
| コントロールステートメント | stdin/ SYS$INPUT |
ユーティリティマニュアル | |
| ADAINV メッセージ | stdout/ SYS$OUTPUT |
メッセージおよびコード | |
| 一時ストレージ | TEMPx | ディスク | |
| ワークストレージ | WORK1 | ディスク |
注意:
(*)このシーケンシャルファイルには、名前付きパイプを使用できます(OpenVMS にはない。詳細については、『Adabas Basics』の「ユーティリティの使用」を参照)。
ニュークリアスがアクティブでなく、かつ保留中の AUTORESTART がない場合は、WORK コンテナのパス名または RAW ディスクセクションに環境変数/論理名 TEMP1 を設定して、WORK を TEMP として使用できます。
次の表は、各機能に対するニュークリアス条件と記録チェックポイントを示しています。
| 機能 | ニュークリアスのアクティブ化が必要 | ニュークリアスの非アクティブ化が必要 | ニュークリアスは不要 | 記録チェックポイント | 有効なニュークリアス操作 |
|---|---|---|---|---|---|
| INVERT | X | SYNP | R | ||
| REINVERT | X(* 注参照) | X | SYNP | ||
| RELEASE | X | SYNP | R | ||
| RESET_UQ | X | SYNP | R | ||
| SET_UQ | X | SYNP | R | ||
| SUMMARY | X | W | |||
| VERIFY | X(* 注参照) | X | SYNX | R |
注意:
(*)Adabas システムファイルの処理時。
R:処理するファイルに許可される読み取り操作。
W:処理するファイルに許可される読み取り操作と書き込み操作。
次のコントロールパラメータを使用できます。
M DBID = number INVERT = number, FIELDS {field_name [,UQ] [,TR] | derived_descriptor_definition | FDT}, ... [END_OF_FIELDS] [,FDT] D [,LWP = number[K|M]] D [,UQ_CONFLICT = keyword] D [NO]LOWER_CASE_FIELD_NAMES REINVERT = number, {ALL_FIELDS | FIELDS {descriptor_name | FDT}, ... [END_OF_FIELDS]} [,FDT] D [,[NO]FORMAT] D [,LWP = number[K|M]] D [,UQ_CONFLICT = keyword] RELEASE = number, {ALL_FIELDS | FIELDS {descriptor_name | FDT}, ... [END_OF_FIELDS]} [,FDT] D [,[NO]FORMAT] RESET_UQ = number, {ALL_FIELDS | FIELDS {descriptor_name | FDT}, ... [END_OF_FIELDS]} [,FDT] SET_UQ = number, {ALL_FIELDS | FIELDS {descriptor_name | FDT}, ... [END_OF_FIELDS]} [,FDT] D [,UQ_CONFLICT = keyword] SUMMARY = number, {ALL_FIELDS | FIELDS {descriptor_name | derived_descriptor_definition | FDT}, ... [END_OF_FIELDS]} [,FDT] D [,FULL] VERIFY = number, {ALL_FIELDS | FIELDS {descriptor_name | FDT}, ... [END_OF_FIELDS]} D [,ERRORS = number] [,FDT] D [,LWP = number[K|M]]
DBID = number
このパラメータは、使用対象となるデータベースを選択するためのものです。
INVERT = number,
FIELDS {field_name [,UQ] [,TR] | derived_descriptor_definition | FDT},
... [END_OF_FIELDS]
[,FDT]
[,LWP = number[K|M]]
[,UQ_CONFLICT = keyword]
この機能は、ファイルが初めてロードされた後の任意の時点で、新しいエレメンタリディスクリプタ、サブディスクリプタ、スーパーディスクリプタ、ハイパーディスクリプタ、フォネティックディスクリプタ、および照合ディスクリプタを確立するものです。"number" には、インバート対象フィールドを含むファイルを指定します。LOB ファイルの数を指定することはできません。
このパラメータは、選択したファイルの FDT を表示します。このパラメータは、フィールド指定リストの前または中に指定できます。
このパラメータは、インバート対象フィールドを指定します。このパラメータには、次の要素を任意の組み合わせで指定できます。
フィールド名
フォネティックディスクリプタ
サブディスクリプタ、スーパーディスクリプタ、ハイパーディスクリプタ、照合ディスクリプタ
各要素は別々の行に指定します。フィールド名、フォネティックディスクリプタ、サブディスクリプタ、スーパーディスクリプタ、ハイパーディスクリプタ、または照合ディスクリプタの有効な指定については、『管理マニュアル』の「FDT のレコード構造」を参照してください。
オプション UQ と TR の用途は、目的のフィールドがユニークディスクリプタかどうか、またはインデックス切り捨てが実行されるかどうかを指定することです。UQ オプションと TR オプションの詳細については、『管理マニュアル』の「定義オプション」を参照してください。
注意:
基本ファイルに値が保存されているフィールドのみを、ディスクリプタとして、または派生ディスクリプタの親フィールドとして使用できます。このため、インバートするフィールド、または作成する派生ディスクリプタの親フィールドに LA オプションか LB オプションがあって、値が
LOB ファイルに保存される場合、INVERT 機能は異常終了します。LA フィールドと LB フィールドは、ディスクリプタとして、または派生ディスクリプタの親フィールドとして使用できますが、その場合はすべての値が 16 KB - 3 に制限され、LA
フィールド値か LB フィールド値を含む基本レコードが 1 つのデータブロックに収まる必要があります。
END_OF_FIELDS パラメータを使用してフィールド定義を消去する場合、LOWER_CASE_FIELD_NAMES パラメータを使用するときに、このパラメータを大文字で指定する必要があります。また、LOWER_CASE_FIELD_NAMES を使用する場合は、FDT パラメータも大文字で指定する必要があります。
いくつかのディスクリプタ値に対して、ADAINV がメモリ内のワークプールを使用します。多くの場合、ワークプールのデフォルトサイズは、ADAINV に最適なパフォーマンスをもたらします。LWP パラメータにより、ワークプールを増やすことができます。デフォルトのワークプールサイズに追加されるスペースをバイト、キロバイト(K)、またはメガバイト(M)単位で定義します。
ワークプールサイズを大きくすると、次の場合に役立ちます。
お使いの環境で、大規模なワークプールを使用するとパフォーマンスが向上する場合。
SORT コンテナがディスクリプタ値をソートするには小さすぎる場合。適切な LWP パラメータにより、SORT コンテナの必要なサイズを縮小できます。
このパラメータに必要な値は、SUMMARY 機能を使用して特定できます。
このパラメータは、ユニークディスクリプタに重複する値が見つかった場合に実行されるアクションを特定します。"keyword" に使用できる値は ABORT または RESET です。ABORT を指定した場合、重複する UQ ディスクリプタ値が見つかると ADAINV は実行を終了し、エラーステータスを返します。RESET を指定した場合、問題のディスクリプタの UQ ステータスが削除され、処理が続行されます。
デフォルトは UQ_CONFLICT = ABORT です。
[NO]LOWER_CASE_FIELD_NAMES
LOWER_CASE_FIELD_NAMES が指定されている場合、Adabas フィールド名は、大文字に変換されません。NOLOWER_CASE_FIELD_NAMES が指定されている場合、Adabas フィールド名は、大文字に変換されます。デフォルトは、NOLOWER_CASE_FIELD_NAMES です。
このパラメータは、FIELDS パラメータの前に指定する必要があります。
REINVERT = number,
{ALL_FIELDS | FIELDS {descriptor_name | FDT}, ... [END_OF_FIELDS]}
[,FDT]
[,[NO]FORMAT]
[,LWP = number[K|M]]
[,UQ_CONFLICT = keyword]
この機能は、RELEASE および INVERT を実行します。これは、入力ミス、特にサブディスクリプタとスーパーディスクリプタに対する入力ミスの可能性を減少させます。
注意:
ADAINV REINVERT の目的は、多数の更新の結果としてインデックスツリーのバランスが崩れた場合、またはインデックスエラーが発生した場合に、ディスクリプタを再作成することです。ディスクリプタは、常に前と同じ定義で再作成されます。例えば、スーパーディスクリプタなど、ディスクリプタの定義を変更する場合は、ADAINV
RELEASE の後に、新しいディスクリプタ定義で ADAINV INVERT を実行する必要があります。
このパラメータは、選択ファイルの全ディスクリプタを解放/インバートすることを指定します。
このパラメータは、選択したファイルの FDT を表示します。このオプションは、フィールド指定リストの前またはリスト内に指定できます。
このパラメータは、解放/再インバートされるディスクリプタを指定します。その後には、1 つまたは複数のフィールド名を指定できます。各フィールド名は独立した行に指定します。有効なフィールド名の指定方法については、『管理マニュアル』の「FDT レコード構造」を参照してください。
END_OF_FIELDS パラメータを使用してフィールド定義を消去する場合、LOWER_CASE_FIELD_NAMES パラメータを使用するときに、このパラメータを大文字で指定する必要があります。また、LOWER_CASE_FIELD_NAMES を使用する場合は、FDT パラメータも大文字で指定する必要があります。
ディスクリプタが解放または再インバートされた場合、通常古いインデックスより小さく、必要なディスクスペースが少ない新しいインデックスが作成されます。FORMAT オプションは、インデックスによって使用されなくなったにもかかわらず、まだファイルに割り当てられているブロックをフォーマットするために使用します。
デフォルトは NOFORMAT です。
いくつかのディスクリプタ値に対して、ADAINV がメモリ内のワークプールを使用します。多くの場合、ワークプールのデフォルトサイズは、ADAINV に最適なパフォーマンスをもたらします。LWP パラメータにより、ワークプールを増やすことができます。デフォルトのワークプールサイズに追加されるスペースをバイト、キロバイト(K)、またはメガバイト(M)単位で定義します。
ワークプールサイズを大きくすると、次の場合に役立ちます。
お使いの環境で、大規模なワークプールを使用するとパフォーマンスが向上する場合。
SORT コンテナがディスクリプタ値をソートするには小さすぎる場合。適切な LWP パラメータにより、SORT コンテナの必要なサイズを縮小できます。
このパラメータに必要な値は、SUMMARY 機能を使用して特定できます。
このパラメータは、ユニークディスクリプタに重複する値が見つかった場合に実行されるアクションを特定します。"keyword" に使用できる値は ABORT または RESET です。ABORT を指定した場合、重複する UQ ディスクリプタ値が見つかると ADAINV は実行を終了し、エラーステータスを返します。RESET を指定した場合、問題のディスクリプタの UQ ステータスが削除され、処理が続行されます。
デフォルトは UQ_CONFLICT = ABORT です。
RELEASE = number,
{ALL_FIELDS | FIELDS {descriptor_name | FDT}, ... [END_OF_FIELDS]}
[,FDT]
[,[NO]FORMAT]
この機能は、"number" で指定するファイルからエレメンタリディスクリプタ、サブディスクリプタ、スーパーディスクリプタ、ハイパーディスクリプタ、フォネティックディスクリプタ、および照合ディスクリプタを除去するものです。LOB ファイルの数を指定することはできません。
このパラメータは、選択ファイルの全ディスクリプタを解放することを指定します。
このパラメータは、選択したファイルの FDT を表示します。このオプションは、フィールド指定リストの前またはリスト内に指定できます。
このパラメータは、解放されるディスクリプタを指定します。その後には、1 つまたは複数のフィールド名を指定できます。各フィールド名は独立した行に指定します。有効なフィールド名の指定方法については、『管理マニュアル』の「FDT レコード構造」を参照してください。
END_OF_FIELDS パラメータを使用してフィールド定義を消去する場合、LOWER_CASE_FIELD_NAMES パラメータを使用するときに、このパラメータを大文字で指定する必要があります。また、LOWER_CASE_FIELD_NAMES を使用する場合は、FDT パラメータも大文字で指定する必要があります。
ディスクリプタが解放または再インバートされた場合、通常古いインデックスより小さく、必要なディスクスペースが少ない新しいインデックスが作成されます。FORMAT オプションは、インデックスによって使用されなくなったにもかかわらず、まだファイルに割り当てられているブロックをフォーマットするために使用します。
デフォルトは NOFORMAT です。
RESET_UQ = number,
{ALL_FIELDS | FIELDS {descriptor_name | FDT}, ... [END_OF_FIELDS]}
[,FDT]
この機能は、"number" で指定するファイル内に定義されたエレメンタリディスクリプタ、サブディスクリプタ、ハイパーディスクリプタ、スーパーディスクリプタ、および照合ディスクリプタのユニークステータスを解除します。LOB ファイルの数を指定することはできません。
このパラメータは、指定ファイルにあるすべてのユニークディスクリプタからユニークステータスを解除することを指定するものです。
このパラメータは、選択ファイルのフィールド定義テーブル(FDT)を表示します。このオプションは、フィールド指定リストの前またはリスト内に指定できます。
このパラメータは、ユニークステータスを解除するディスクリプタを指定します。その後には、1 つまたは複数のフィールド名を指定できます。各フィールド名は独立した行に指定します。有効なフィールド名の指定方法については、『管理マニュアル』の「FDT レコード構造」を参照してください。
END_OF_FIELDS パラメータを使用してフィールド定義を消去する場合、LOWER_CASE_FIELD_NAMES パラメータを使用するときに、このパラメータを大文字で指定する必要があります。また、LOWER_CASE_FIELD_NAMES を使用する場合は、FDT パラメータも大文字で指定する必要があります。
SET_UQ = number,
{ALL_FIELDS | FIELDS {descriptor_name | FDT}, ... [END_OF_FIELDS]}
[,FDT]
[,UQ_CONFLICT = keyword]
この機能は、"number" で指定するファイル内に定義されたエレメンタリディスクリプタ、サブディスクリプタ、ハイパーディスクリプタ、スーパーディスクリプタ、および照合ディスクリプタにユニークステータスを設定します。LOB ファイルの数を指定することはできません。
このパラメータは、指定ファイル内に定義されたすべてのエレメンタリディスクリプタ、サブディスクリプタ、ハイパーディスクリプタ、スーパーディスクリプタ、および照合ディスクリプタにユニークステータスを設定することを指定します。
このパラメータは、選択したファイルの FDT を表示します。このオプションは、フィールド指定リストの前またはリスト内に指定できます。
このパラメータは、ユニークステータスを設定するディスクリプタを指定します。その後には、1 つまたは複数のフィールド名を指定できます。各フィールド名は独立した行に指定します。有効なフィールド名の指定方法については、『管理マニュアル』の「FDT レコード構造」を参照してください。
END_OF_FIELDS パラメータを使用してフィールド定義を消去する場合、LOWER_CASE_FIELD_NAMES パラメータを使用するときに、このパラメータを大文字で指定する必要があります。また、LOWER_CASE_FIELD_NAMES を使用する場合は、FDT パラメータも大文字で指定する必要があります。
このパラメータは、ユニークディスクリプタに重複する値が見つかった場合に実行されるアクションを特定します。"keyword" に使用できる値は ABORT または RESET です。ABORT を指定する場合、重複するディスクリプタ値が検出されると、ADAINV は実行を終了してエラーステータスを返します。RESET を指定する場合、重複するディスクリプタ値があってもユニークステータスにはならず、処理が続行されます。
デフォルトは UQ_CONFLICT=ABORT です。
SUMMARY = number,
{ALL_FIELDS | FIELDS
{descriptor_name | derived_descriptor_definition | FDT},
... [END_OF_FIELDS]}
[,FDT]
[,FULL]
この機能は、指定したディスクリプタに対するディスクリプタスペースサマリ(DSS)と、ディスクリプタを処理するために必要なサイズを表示します。
注意:
表示されるサイズの精度は、状況に応じていろいろと変わります。正確なサイズは、表示される値よりも少し小さ目のサイズになることもあります。SUMMARY 機能の実行中または実行後にファイルが更新された場合には、表示される値がかなり小さなサイズになることもあります。
ADAINV SUMMARY 処理の詳細については、『管理マニュアル』の「ADAMUP および ADAINV 処理の最適化」を参照してください。
このパラメータを指定すると、選択されたファイルの全ディスクリプタがチェックされます。
このパラメータは、選択したファイルの FDT を表示します。このオプションは、フィールド指定リストの前またはリスト内に指定できます。
このパラメータは、ユニークステータスを設定するディスクリプタを指定します。それぞれ個別の行で開始している 1 つ以上のフィールド名、フォネティックディスクリプタ、サブディスクリプタ、スーパーディスクリプタ、ハイパーディスクリプタ、または照合ディスクリプタの前に指定できます。ディスクリプタであるフィールドやディスクリプタでないフィールドを指定することができます。有効なフィールド名の指定方法については、『管理マニュアル』の「FDT レコード構造」を参照してください。
END_OF_FIELDS パラメータを使用してフィールド定義を消去する場合、LOWER_CASE_FIELD_NAMES パラメータを使用するときに、このパラメータを大文字で指定する必要があります。また、LOWER_CASE_FIELD_NAMES を使用する場合は、FDT パラメータも大文字で指定する必要があります。
これを指定すると、各ディスクリプタの表示に、ディスクリプタに必要なサイズが加わります。指定するフィールドすべてを処理するとは限らない場合、これは有用です。
VERIFY = number,
{ALL_FIELDS | FIELDS {descriptor_name | FDT}, ... [END_OF_FIELDS]}
[,ERRORS = number]
[,FDT]
[,LWP = number[K|M]]
この機能は、"number" に指定するファイルのインバーテッドリストの整合性をチェックするものです。
このパラメータは、選択ファイルの全ディスクリプタがチェックされることを指定します。
このパラメータは、ディスクリプタの検証を終了するまでに何件エラーをレポートするかを指定します。
デフォルトは、20 です。
このパラメータは、選択したファイルの FDT を表示します。このオプションは、フィールド指定リストの前またはリスト内に指定できます。
このパラメータは、検証対象ディスクリプタフィールドを指定します。その後には、1 つまたは複数のフィールド名を指定できます。各フィールド名は独立した行に指定します。有効なフィールド名の指定方法については、『管理マニュアル』の「FDT レコード構造」を参照してください。
END_OF_FIELDS パラメータを使用してフィールド定義を消去する場合、LOWER_CASE_FIELD_NAMES パラメータを使用するときに、このパラメータを大文字で指定する必要があります。また、LOWER_CASE_FIELD_NAMES を使用する場合は、FDT パラメータも大文字で指定する必要があります。
いくつかのディスクリプタ値に対して、ADAINV がメモリ内のワークプールを使用します。多くの場合、ワークプールのデフォルトサイズは、ADAINV に最適なパフォーマンスをもたらします。LWP パラメータにより、ワークプールを増やすことができます。デフォルトのワークプールサイズに追加されるスペースをバイト、キロバイト(K)、またはメガバイト(M)単位で定義します。
ワークプールサイズを大きくすると、次の場合に役立ちます。
お使いの環境で、大規模なワークプールを使用するとパフォーマンスが向上する場合。
SORT コンテナがディスクリプタ値をソートするには小さすぎる場合。適切な LWP パラメータにより、SORT コンテナの必要なサイズを縮小できます。
このパラメータに必要な値は、SUMMARY 機能を使用して特定できます。
ADAINV は再スタート機能を備えていません。しかし、異常終了した ADAINV を最初から再実行できるかどうかは状況により異なります。
ADAINV が異常終了した場合、通常、再スタートすることができます。しかし、ADAINV がインデックスを修正した場合、次の点を考慮する必要があります。
REINVERT ...FIELDS 機能は、RELEASE ...FIELDS 機能の後に INVERT ...FIELDS 機能が続いているものと同じです。そのため、ADAINV が INVERT フェーズで異常終了した場合は、処理を再スタートするために INVERT ...FIELDS 機能を実行してください。
ADAINV をオフラインで実行する場合、ディスクに書き込まれる、論理的な単位を形成するレコードの件数が少ないため、ディスクへの書き込み時間は非常に短くなります。これらのレコードの最初のレコードが書き込まれてから、最後のレコードの書き込みが終了するまでの間に、ADAINV が終了すると、ADAINV は再スタートできません。この場合、REINVERT ...ALL_FIELDS 機能が必要です。このような事態は、ADAINV をオンラインで実行した場合には起きません。
ADAINV が異常終了すると、インデックスブロックが失われることがあります。これらのインデックスブロックは REINVERT ...ALL_FIELDS 機能、ADAORD ユーティリティの使用、または ADAULD と ADAMUP ユーティリティの使用によってのみリカバリできます。
adainv: dbid=1 adainv: invert=10, fields adainv: HO
データベース 1 のファイル 10 にあるエレメンタリフィールド HO がインバートされます。
adainv: dbid=1 adainv: invert=10 adainv: lwp=600k adainv: fields adainv: ph=phon(na) adainv: sp=na(1,3),yy(1,2),uq adainv: bb,uq
データベース 1 のファイル 10 に対して、新しいディスクリプタが作成されます。PH は、フィールド NA から派生したフォネティックディスクリプタです。SP は、フィールド NA のバイト 1 から 3 およびフィールド YY の 1 から 2 から派生するユニークスーパーディスクリプタです。エレメンタリフィールド BB はディスクリプタステータスに変更され、ユニークフラグが設定されます。ソートに使用されるワークプールの大きさは 600K に増えます。
adainv: dbid=1 adainv: release=10 adainv: fields adainv: ho adainv: ph
上記の 2 つのディスクリプタ HO および PH が解除されます。
adainv: dbid = 1, verify = 10 adainv: errors = 5 adainv: fields adainv: sp adainv: na adainv: end_of_fields
ディスクリプタ SP および NA が検証されます。ディスクリプタ NA に対して生成されたディスクリプタバリューテーブルエントリと、このフィールドの非圧縮値が照合されます。各ディスクリプタのエラー数が 5 つを超えると、検証は終了します。
adainv: dbid = 1, reinvert = 10 adainv: fields adainv: na
データベース 1 のファイル 10 にあるディスクリプタ NA が再インバートされます(これは、例 4 でエラーが検出された場合に必要になることがあります)。
adainv: db=12 adainv: reinvert=9 adainv: all_fields
データベース 12 のファイル 9 の完全なインデックスが作成されます。
次の出力が生成されます。
%ADAINV-I-FILE, file 9, EMPLOYEES %ADAINV-I-UIUPD, upper index being modified %ADAINV-I-SORTDESC, sorting descriptor KA %ADAINV-I-LOADDESC, loading descriptor KA %ADAINV-I-SORTDESC, sorting descriptor S3 %ADAINV-I-LOADDESC, loading descriptor S3 %ADAINV-I-SORTDESC, sorting descriptor S2 %ADAINV-I-LOADDESC, loading descriptor S2 %ADAINV-I-SORTDESC, sorting descriptor PA %ADAINV-I-LOADDESC, loading descriptor PA %ADAINV-I-SORTDESC, sorting descriptor FB %ADAINV-I-LOADDESC, loading descriptor FB %ADAINV-I-SORTDESC, sorting descriptor AA %ADAINV-I-LOADDESC, loading descriptor AA %ADAINV-I-SORTDESC, sorting descriptor BC %ADAINV-I-LOADDESC, loading descriptor BC %ADAINV-I-SORTDESC, sorting descriptor CN %ADAINV-I-LOADDESC, loading descriptor CN %ADAINV-I-SORTDESC, sorting descriptor JA %ADAINV-I-LOADDESC, loading descriptor JA %ADAINV-I-SORTDESC, sorting descriptor H1 %ADAINV-I-LOADDESC, loading descriptor H1 %ADAINV-I-SORTDESC, sorting descriptor EA %ADAINV-I-LOADDESC, loading descriptor EA %ADAINV-I-SORTDESC, sorting descriptor LC %ADAINV-I-LOADDESC, loading descriptor LC %ADAINV-I-SORTDESC, sorting descriptor S1 %ADAINV-I-LOADDESC, loading descriptor S1 %ADAINV-I-SORTDESC, sorting descriptor AC %ADAINV-I-LOADDESC, loading descriptor AC %ADAINV-I-NULLDESC, no values for descriptor IJ %ADAINV-I-LOADDESC, loading descriptor IJ %ADAINV-I-NULLDESC, no values for descriptor IB %ADAINV-I-LOADDESC, loading descriptor IB %ADAINV-I-NULLDESC, no values for descriptor FI %ADAINV-I-LOADDESC, loading descriptor FI %ADAINV-I-UIUPD, upper index being modified %ADAINV-I-DSPASSES, data storage passes : 17 %ADAINV-I-REMOVED, dataset SORT1, file C:\Program Files\Software AG\Adabas/db012 \SORT01_3664.012 removed %ADAINV-I-IOCNT, 1 IOs on dataset SORT %ADAINV-I-IOCNT, 85 IOs on dataset DATA %ADAINV-I-IOCNT, 49 IOs on dataset ASSO
注意:
adainv: dbid = 1, set_uq=10 adainv: fields adainv: na adainv: end_of_fields adainv: uq_conflict=reset
データベース 1 のファイル 10 にあるディスクリプタ NA に対してユニークステータスが設定されます。1 つのディスクリプタ値に対して複数の ISN があると、ISN の不整合がエラーログに書き込まれ、ユニークステータスが解除されます。
adainv: dbid = 1, reset_uq=10 adainv: fields adainv: sp
データベース 1 のファイル 10 にあるディスクリプタ SP からユニークステータスが解除されます。
adainv: db=33 adainv: summary=112 adainv: fields adainv: ab adainv: ae adainv: s1=ap(1,1),aq(1,1),ar(1,1) adainv: s2=ac(1,3),ad(1,8),ae(1,9) adainv: s3=ao(2,3)
この例の出力結果は次のとおりです。
Descriptor summary:
===================
Descriptor AB : 1,194,469 bytes, 581,209 occ
Descriptor AE : 3,605,545 bytes, 538,769 occ
Descriptor S1 : 1,566,501 bytes, 581,209 occ
Descriptor S2 : 1,520,169 bytes, 72,389 occ
Descriptor S3 : 1,340,949 bytes, 446,983 occ
Required sizes to process these descriptors:
============================================
- SORTSIZE (LWP= 0 KB) = 8 MB
- LWP for incore sort = 13,230 KB
- TEMPSIZE (1 pass) = 24 MB
- TEMPSIZE (2 passes) = 13 MB
- TEMPSIZE (recommended minimum size) = 5 MB
%ADAINV-I-IOCNT, 1710 IOs on dataset DATA
%ADAINV-I-IOCNT, 3 IOs on dataset ASSO
%ADAINV-I-TERMINATED, 24-NOV-2006 14:15:06, elapsed time: 00:04:03