Tamino text retrieval operations consider text as sequences of words. A word is a sequence of characters that is delimited by characters such as whitespace or punctuation characters. The process of analyzing text and determining words and delimiters is called tokenization. Depending on the language, there are different tokenizers available in Tamino. The default, so-called "white space-separated" tokenizer is suitable for most letter-based languages. However, ideographic languages such as Chinese, Japanese or Korean (often referred together as CJK languages) have a totally different concept of segmenting a sequence of ideographs into "word" tokens. Tamino offers a special tokenizer for Japanese.
Tokens are categorized into character classes such as "character", "delimiter" or "number". You can find detailed information about this topic in the section Implications Concerning Text Retrieval in Unicode and Text Retrieval.
For the purpose of doing text retrieval in XQuery, it is sufficient to think of full text in terms of words and delimiters. In this context, "words" are referred to as word tokens, regardless of whether a tokenizer analyzed a series of letters or of ideographs.
This document covers the following topics:
There are two possibilities to search nodes in XML documents for some text: You can either use an exact search or search for word tokens. Let us look for divers among the patients in our hospital database. We know that there is someone who is a "professional diver":
for $a in input()/patient
where $a/occupation = "Professional Diver"
return <divers level="professional">{ $a/name }</divers>
And Tamino will return Mr. Atkins as the only representative of the hospital's professional divers. To find all divers, professional or not, you are inclined to ask:
for $a in input()/patient
where $a/occupation = "diver"
return <divers>{ $a/name }</divers>
The result is an empty sequence, so we lost even the professional diver.
The where clause contains an equality expression that is true if
the text contents of the node read exactly "diver".
Since the occupation element in Mr. Atkin's reads
"Professional Diver", the result is false and no
divers are returned. However, using the function tf:containsText
you can search for the word "diver" somewhere in the
node occupation and without looking at the case:
for $a in input()/patient
where tf:containsText($a/occupation, "diver")
return <divers>{ $a/name }</divers>
Now Tamino returns Mr. Atkins in the diver list, since the tokenizer
identifies "Diver" as a word, delimited on the left
by a space character. After applying lower case as standard tokenizer rule the
token "diver" is found and the function
tf:containsText returns true. Please note that this
function looks for word tokens, so using tf:containsText($a/occupation,
"dive") would yield false, since
"dive" is not a token that can be found in any of
the occupation nodes. Similarly, a query using
tf:containsText($a/occupation, "professional diver") returns
true, since the two word tokens are found in that order in the
occupation node. However, tf:containsText($a/occupation,
"diver professional") returns false: Although both tokens
are found, they are not in the specified order.
With context operations you can search for expressions that consist of one or more words which do not necessarily follow after one another. For example, you can search for variants of the expression "text retrieval" such as "retrieval of text" or in "text storage and retrieval". In Tamino, there are functions that let you specify the following context operations (here, "#" stands for one token):
Maximum word distance
"text # # retrieval" matches
"text retrieval" and "text storage and
retrieval"
Word order
If word order is not significant, "text
retrieval" matches "text retrieval"
and "retrieval of text"
The functions tf:containsAdjacentText and
tf:containsNearText both expect a maximum word distance as second
argument. Consider the following query:
let $text := text{"One, Two, Three, Four, Can I have a little more?"}
return tf:containsAdjacentText($text, 9, "one", "more")
This graphics shows you the search string, its tokens and how the query matches the search string:

The function tf:containsAdjacentText returns
true if the tokens "one" and
"more" are found in that order within a distance of
less than nine tokens. Since there are eight unmatched tokens, the function
returns true for the above query. Let us slightly change the query
expression:
let $text := text{"One, Two, Three, Four, Can I have a little more?"}
return tf:containsAdjacentText($text, 9, "one", "four", "more")
The function returns true if all the tokens
"one", "four" and
"more" are found in that order within a distance of
less than nine tokens, not including any matched tokens in between such as
"four". Since there are seven unmatched tokens, the
function returns true for the above query.
Generally, if you use a distance value of
"1", it means that the tokens follow immediately one
after another. It follows that tf:containsAdjacentText($mynode, 1,
"search", "text") is equivalent to tf:containsText($mynode,
"search text").
While tf:containsAdjacentText respects the word order, the
function tf:containsNearText does not. The following query using
tf:containsNearText returns true, using
tf:containsAdjacentText it would return false:
let $text := text{"One, Two, Three, Four, Can I have a little more?"}
return tf:containsNearText($text, 2, "four", "one", "two")
When retrieving information from some text corpus, it is desirable to
visualize the information found. In Tamino XQuery, you can do so by
"highlighting" retrieval results. Consider the following query
from the Tamino XQuery reference guide which searches in all
review nodes for the word
"discussion":
for $a in input()/reviews/entry let $ref := tf:createTextReference($a/review, "discussion") where $ref return tf:highlight($a, $ref, "REV_DISC")
A Tamino client application could highlight the results as follows:
<entry> <title>Data on the Web</title> <price>34.95</price> <review>A very good discussion of semi-structured database systems and XML.</review> </entry> <entry> <title>Advanced Programming in the Unix environment</title> <price>65.95</price> <review>A clear and detailed discussion of UNIX programming.</review> </entry>
You can see from the query expression that there are two steps involved when highlighting retrieval results:
Generate a reference description to the locations that should be highlighted.
Apply highlighting to the document according to the locations.
A reference description is necessary for highlighting later on. It consists of at least the following global information:
collection
document type ("doctype")
document number
node id
References to text within a node further need to describe the locations
of start and end points, the range. You can create reference
descriptions by using the following functions:
tf:createAdjacentTextReference,
tf:createNearTextReference, and
tf:createTextReference. These functions work exactly like their
tf:containsXXXText counterparts, only
that they return reference descriptions of text ranges instead of a Boolean
value. There is another function tf:createNodeReference to create
reference descriptions of nodes. Let us have a look at the reference
descriptions that will be used in our example query:
for $a in input()/reviews/entry return tf:createTextReference($a/review, "discussion")
Tamino will return these two object descriptions in its response:

The figure below shows you the text ranges for which reference descriptions have been created:
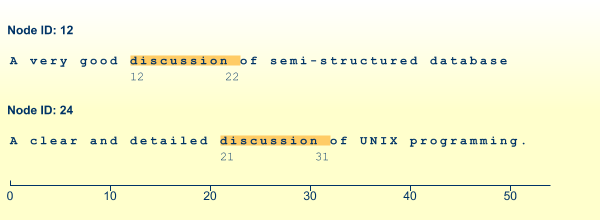
Any location, for which a reference description exists, can be
highlighted by using the function tf:highlight. The query
performing the highlighting is repeated here for your convenience:
for $a in input()/reviews/entry let $ref := tf:createTextReference($a/review, "discussion") where $ref return tf:highlight($a, $ref, "REV_DISC")
As arguments, the function tf:highlight requires a node, a
previously-generated reference description and a marker string. Tamino uses
processing instructions (PIs) to indicate the start and end of the range to be
highlighted so that a client application receiving the Tamino response document
can parse and process them. The marker string is used as the so-called PI
target. You can easily identify the highlighted text ranges in the response
document for the above query:
<entry> <title>Data on the Web</title> <price>34.95</price> <review>A very good <?REV_DISC + 1 ?>discussion<?REV_DISC - 1 ?> of semi-structured database systems and XML.</review> </entry> <entry> <title>Advanced Programming in the Unix environment</title> <price>65.95</price> <review>A clear and detailed <?REV_DISC + 2 ?>discussion<?REV_DISC - 2 ?> of UNIX programming.</review> </entry>
The start and end of the highlighted text range are indicated by the plus and minus signs in the PI. Furthermore, highlighted ranges are numbered. This is also true when highlighting complete nodes:
for $a in input()/bib let $ref:= tf:createNodeReference($a/book[1]) return tf:highlight($a, $ref, "FIRST")
The resulting document is:
<book year="1994"><?FIRST + 1?> <title>TCP/IP Illustrated</title> <author><last>Stevens</last><first>W.</first></author> <publisher>Addison-Wesley</publisher> <price>65.95</price> <?FIRST - 1?></book>
A "phonetic search" allows you to search for words that are
phonetically equivalent. Linguistically speaking, you are looking for
homophones. For example, in English the letters c and s as in
"city" and "song" are
both pronounced [s], and the words "eight" and
"ate" are both pronounced
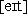 (in square brackets
you see the phonetic transcription using the IPA, the International Phonetic
Alphabet).
(in square brackets
you see the phonetic transcription using the IPA, the International Phonetic
Alphabet).
There are many areas where this facility proves valuable: Imagine a patient database having lots of patients with German names. Now you want to retrieve all patients with the name "Maier". In German, it is an everyday surname, just as "Kim", "Smith", and "Andersson" are for Korean, English and Swedish respectively. You can use a query performing a simple text search such as:
for $a in input()/patient where $a/name = "Maier" return $a/name
or you can use tf:containsText:
for $a in input()/patient where tf:containsText($a/name, "Maier") return $a/name
Unfortunately, there are at least four variants of the name which are
all pronounced 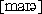 :
"Maier", "Mayer",
"Meier", and "Meyer".
Instead of constructing long Boolean expressions that try to cover all existing
homophones, you can use
:
"Maier", "Mayer",
"Meier", and "Meyer".
Instead of constructing long Boolean expressions that try to cover all existing
homophones, you can use tf:phonetic in the scope of one of the
search functions:
for $a in input()/patient
where tf:containsText($a/name, tf:phonetic("Maier"))
return $a/name
This query will return all patients whose names sound like
.
Tamino uses a set of rules to determine phonetic equivalency. There are rules pre-defined, which are explained in more detail in the reference documentation to tf:phonetic. These rules are suitable for German and English, but you can create your own set of rules. See the section Rules for Searches Using Phonetic Values and Stemming below.
Note:
You can not use tf:phonetic standalone, but only in the
context of one of the following functions: tf:containsText,
tf:containsAdjacentText, tf:containsNearText,
tf:createAdjacentTextReference,
tf:createNearTextReference, tf:createTextReference.
This means that the result of calling this function in another context is
unspecified and might change in a future Tamino version.
A corpus with text in an inflecting language such as English or German often contains words in inflected forms: nouns are declined and verbs are conjugated: "The nightingales were singing in the trees." If you want to search for all occurrences of the verb "to sing" or of the nouns "nightingale" and "tree", you need to know how these words are inflected and derived. One method is to reduce any inflected form to its word stem. It is the stem to which morphemes are attached to construct a certain grammatical form: So "were" + "sing" + "-ing" indicates the past continuous tense of the verb "to sing".
In Tamino, you can use the function tf:stem to retrieve
occurrences of all word forms belonging to the same word stem. Similarly to
tf:phonetic, it works only in the scope of one of the search
functions:
let $text :=
<chapter>
<para>Die Bank eröffnete drei neue Filialen im Verlauf der letzten fünf Jahre.</para>
<para>Ermüdet von dem Spaziergang setzte sich die alte Dame erleichtert auf die
gepflegt wirkende Bank mitten im Stadtpark.</para>
<para>Die aktuelle Bilanz der Bank zeigt einen Anstieg der liquiden Mittel im
Vergleich zum Vorjahresquartal.</para>
</chapter>
for $a in $text//para
let $check :=
for $value in ("Geld", "Bilanz", "Filiale", "monetär", "Aktie")
return tf:containsNearText($a, 10, tf:stem($value), tf:stem("Bank"))
where count($check[. eq true()]) > 0
return $a
This returns all para elements whose text
contains at least one word which is related to a specific reading of the German
word "Bank". The resulting document contains the
first and the third para element, but not the
second, since it does not contain any of the words defined in the sequence
("Geld", "Bilanz", "Filiale", "monetär", "Aktie") in a distance of
less than ten words from "Bank".
Tamino uses a set of rules to determine whether a word token belongs to some stem. There is a pre-defined rule set that works reasonably well for German. However, you can create your own set of rules. See the section Rules for Searches Using Phonetic Values and Stemming below. You can reach the pre-defined rules set using the following query:
declare namespace ino="http://namespaces.softwareag.com/tamino/response2"
collection("ino:vocabulary")/ino:stemrules
Note:
Do not use tf:stem standalone; use it only in the
context of one of the following functions: tf:containsText,
tf:containsAdjacentText, tf:containsNearText,
tf:createAdjacentTextReference,
tf:createNearTextReference, tf:createTextReference.
The result of calling this function in any other context is unspecified and
might change in a future Tamino version.
For queries that involve phonetics and stemming, Tamino internally uses
the same mechanism, implemented as a finite-state machine, that rewrites the
function argument according to a set of rules. These rules are described by XML
schemas stored in the collection ino:vocabulary and have the names
PHONRULES and STEMRULES:
This is the schema for PHONRULES:
<xs:complexType>
<xs:sequence>
<xs:element name="phonrule" minOccurs="1" maxOccurs="unbounded">
<xs:complexType>
<xs:attribute name="phonStage" type="xs:integer" use="required" />
<xs:attribute name="phonType" type="xs:string" use="required" />
<xs:attribute name="phonReqs" type="xs:integer" use="required" />
<xs:attribute name="phonMinChars" type="xs:integer" use="required" />
<xs:attribute name="phonChars" type="xs:string" use="required" />
<xs:attribute name="phonReplaceChars" type="xs:string" use="required" />
<xs:attribute name="phonNextStage" type="xs:integer" use="required" />
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
This is the schema for STEMRULES:
<xs:complexType>
<xs:sequence>
<xs:element name="stemrule" minOccurs="1" maxOccurs="unbounded">
<xs:complexType>
<xs:attribute name="stemStage" type="xs:integer" use="required" />
<xs:attribute name="stemType" type="xs:string" use="required" />
<xs:attribute name="stemReqs" type="xs:integer" use="required" />
<xs:attribute name="stemMinChars" type="xs:integer" use="required" />
<xs:attribute name="stemChars" type="xs:string" use="required" />
<xs:attribute name="stemReplaceChars" type="xs:string" use="required" />
<xs:attribute name="stemNextStage" type="xs:integer" use="required" />
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
So a set of rules consists of a series of
ino:phonrule or
ino:stemrule elements. The semantics of a rule are
determined by its attributes, all of which are mandatory:
Location
The attributes ino:phonType and
ino:stemType define the part of word affected by
the rule: This is one of the values "SUFFIX",
"INFIX" or "PREFIX"
Character Substitution
These attributes define the characters to look for and their
replacement:
The attributes ino:phonChars and
ino:stemChars define the sequence of characters
to look for in a string
The attributes ino:phonReplaceChars
and ino:stemReplaceChars define the substitution
string.
State Machine Control
These attributes control the way the state machine is treating this
rule:
The attributes ino:phonStage and
ino:stemStage define the state in which the rule
will be active. The attribute value is a number from 1 to n. In most
of the rules there will be no state change.
The attributes ino:phonNextStage and
ino:stemNextStage define the next state when the
rule has fired. If the value is "0" the machine
stops and the result is computed.
Restrictions
If a restriction is violated, the rule will not be executed.
The attributes ino:phonMinChars and
ino:stemMinChars define the minimum length of
the word fragment for the rule to be applied.
The attributes ino:phonReqs and
ino:stemReqs define the minimum number of
syllables in the word fragment for the rule to be applied. For
ino:phonReqs this is practically always the
value "0".
The order of the rules is significant. The following stem rules protect the substitution of "EAR":
<ino:stemrule ino:stemType='SUFFIX' ino:stemStage='2' ino:stemNextStage='0' ino:stemChars='EAR' ino:stemReplaceChars='EAR' ino:stemReqs='0' ino:stemMinChars='6' /> <ino:stemrule ino:stemType='SUFFIX' ino:stemStage='2' ino:stemNextStage='0' ino:stemChars='AR' ino:stemReplaceChars='' ino:stemReqs='0' ino:stemMinChars='5' />
A thesaurus is a special kind of dictionary that is ordered by topic or semantic relationships. A regular dictionary uses a lexicographic order: for example, letter-based languages use the language's alphabet; ideographic languages use the base signs and the number of strokes. In contrast, a thesaurus is ordered by meaning: it helps you find words or phrases for general ideas. Semantic relationships let you explore words along two directions: horizontally by looking up variants with the same context of meaning (e.g., synonyms, antonyms) or vertically by finding broader, superordinate terms (hypernyms), and narrower, subordinate terms (hyponyms). In Tamino, this adds another dimension of text retrieval functionality: now you can retrieve contents not only by using the graphemic representation or syntactic variants of the search term, but also by using its semantic properties.
Tamino supports the most important aspects of a thesaurus: synonyms,
hypernyms and hyponyms. There is no pre-defined thesaurus, so you can specify
one tailored to the special vocabulary of your Tamino application scenario. You
can define one or more thesauri in a single database. The collection
ino:vocabulary holds thesaurus entries as
term elements, each of which is assigned to a single
thesaurus using the attribute ino:thesaurus. A
term element can contain the following elements:
termNamedefines the name of the thesaurus entry (mandatory)
synonymdefines a term which is synonymous to
termName
broaderTermdefines a term which is superordinate to
termName (hypernym)
narrowerTermdefines a term which is subordinate to
termName (hyponym)
To create a sample thesaurus with words having to do with animals, load
the following data into the collection ino:vocabulary of an
existing database. Please refer to the section
Loading Data into
Tamino for more information about loading data into
Tamino.
<?xml version="1.0"?>
<term ino:thesaurus="animals"
xmlns:ino="http://namespaces.softwareag.com/tamino/response2">
<ino:termName>dog</ino:termName>
<ino:synonym>canine</ino:synonym>
<ino:synonym>pooch</ino:synonym>
<ino:synonym>doggie</ino:synonym>
<ino:synonym>bow-wow</ino:synonym>
<ino:synonym>puppy-dog</ino:synonym>
<ino:synonym>perp</ino:synonym>
<ino:synonym>whelp</ino:synonym>
<ino:broaderTerm>carnivore</ino:broaderTerm>
</term> |
<?xml version="1.0"?>
<term ino:thesaurus="animals"
xmlns:ino="http://namespaces.softwareag.com/tamino/response2">
<ino:termName>carnivore</ino:termName>
<ino:broaderTerm>mammal</ino:broaderTerm>
</term> |
These two files establish the thesaurus
"animals" for the given database. In the vertical
direction the following hierarchy can be derived: A dog is a carnivore; a
carnivore is a mammal. This is because the
ino:broaderTerm contents
("carnivore") in the thesaurus entry for
"dog" matches the
ino:termName of another thesaurus entry, namely
"carnivore".
Furthermore synonyms are defined for the entry "dog" that denote a dog using colloquial language, biological terms, pet names, etc.
Return all paragraphs in the specified document that contain a synonym of "dog":
let $doc := <doc>
<p>Have you seen the large dog around the corner?</p>
<p>On the farm nearby, a checkered whelp was playing on the ground with some cats.</p>
<p>Also, some horses could be seen in the stable.</p>
</doc>
for $p in $doc/p
where tf:containsText($p,tf:synonym("dog"))
return $p
As a result, the first two paragraphs are returned. Strictly speaking, only "whelp" is defined as a proper synonym, but Tamino follows the intuitive assumption that you also expect the term itself to be part of the result set. This holds for other thesaurus functions as well.
The following query returns all superordinate terms of
"dog", for which you use the Tamino function
tf:broaderTerms:
declare namespace ino="http://namespaces.softwareag.com/tamino/response2"
for $p in collection("ino:vocabulary")/ino:term
where tf:containsText($p/ino:termName,tf:broaderTerms("dog"))
return $p/ino:termName
Here, the two ino:termName instances for dog and carnivore
are returned.
You can conveniently perform text searches with the help of search patterns. Tamino's text retrieval system allows for efficient queries using special characters that match one or more characters in a word. In Tamino XQuery the following functions support text search using pattern matching:
tf:containsText
tf:containsAdjacentText
tf:containsNearText
tf:createTextReference
tf:createAdjacentTextReference
tf:createNearTextReference
The tokenizer that is being used determines the pattern matching facilities that are available. The following table gives an overview of the characters that have a special meaning when used in one of the above functions:
| Character | Tokenizer Availability | Effect |
|---|---|---|
? (maskcard)
|
white space-separated | match a single character in a word |
* (wildcard)
|
CJK |
match zero or more characters in a word |
\ (escapecard)
|
white space-separated | cancel the special meaning of the following character |
The default tokenizer ("white space-separated") supports all types of special characters, whereas the Japanese tokenizer only supports wildcard characters. The section Wildcard Characters provides details about the peculiarities when using the Japanese tokenizer.
The table above shows the
default settings. However, with the white space-separated tokenizer you can use
a different character for each of these special characters. If, for example,
your data frequently uses the asterisk sign as a regular character, it is more
convenient to redefine the wildcard character instead of having to escape the
asterisks using the escapecard character every time they occur. See the section
Customizing Special Character
Settings for information on how to change these settings. The
discussion here assumes the default settings as defined in
ino:transliteration and, if not stated otherwise,
the usage of the standard white space-separated tokenizer.
In the context of pattern matching, a word consists of a non-empty
sequence of characters: for example, a wildcard character (default: asterisk)
matches zero or more characters in a word, so that a single
"*" represents a single word. If the search string
contains more than one word, such as in the expression
tf:containsText($node, "word1 word2") then it is treated as
tf:containsAdjacentText($node, 1, "word1", "word2").
The following sections contain more information about searching with any of these special characters and how to change the default setting:
The maskcard character, which by default is a question mark
"?", stands for a single character in a word. A
pattern theat?? thus matches theatre as well as
theater, but not theatrical since ??
only match ri and the rest (cal) is not matched.
Consider the following query:
let $text := text{"one two three four five six seven eight nine ten"}
return
(tf:containsText($text, "??"), tf:containsText($text, "t??"), tf:containsText($text, "two?three"))
The query returns a sequence of three items, each being a Boolean value
that indicates whether the specified pattern matches the contents of the text
node in $text. Attempting to match the first
pattern ?? yields "false", since there
are no numerals with only two letters. The second pattern t??
matches all three-letter numerals beginning with t, namely
two and ten, so "true" is
returned. The last pattern fails again, although the pattern
two?three seems to match the value "two
three". However, since pattern matching is always performed on
the basis of a word, the match does not succeed: the string "two
three" is treated as two words delimited by the space character
in between.
Note:
Introducing the question mark as a maskcard character also has the
effect that it is no longer classified as a delimiter character in the default
transliteration.
In contrast to the maskcard character, which matches exactly one character, the wildcard character matches zero or more characters in a word. By default, the wildcard character is an asterisk "*".
Consider the following query:
let $text := text{"one, two"}
return tf:containsAdjacentText($text, 1, "one", "*", "*")
This query returns false, since
tf:containsAdjacentText expects two word tokens adjacent to
"one".
If you use the default tokenizer, i.e. the white space-separated
tokenizer, then the wildcard character is always the asterisk
"*" (Unicode value U+002A).
If you use the Japanese tokenizer, all of the following characters are recognized as wildcard characters:
| Unicode Name | Code Value |
|---|---|
ASTERISK |
U+002A |
ARABIC FIVE POINTED STAR |
U+066D |
ASTERISK OPERATOR |
U+2217 |
HEAVY ASTERISK |
U+2731 |
SMALL ASTERISK |
U+FE61 |
FULL WIDTH ASTERISK |
U+FF0A |
Note:
In contrast to the standard white space-separated tokenizer, this
definition of wildcard characters is fixed and cannot be changed.
The Japanese tokenizer does not support wildcard characters in the
middle of a word, since there are no explicit delimiter characters. So
"疾*患" will be treated as
"疾*" adj "患".
The example queries below focus on the contents of the
patient/submitted/diagnosis nodes to show the effect of performing
search operations with or without wildcard characters on segmentation of
Japanese words.
| Contents | 心臓に問題がある | |||
|---|---|---|---|---|
| Translation | problems with the heart | |||
| Segmentation | Word Tokens | 心臓 | ある | 問題 |
| Translation | heart (physical) | has | problem | |
| Contents | 心臓麻痺 | ||
|---|---|---|---|
| Translation | heart attack | ||
| Segmentation | Word Tokens | 心臓 | 麻痺 |
| Translation | heart | paralysis | |
| Contents | 心臓疾患 | ||
|---|---|---|---|
| Translation | heart disease | ||
| Segmentation | Word Tokens | 心臓 | 疾患 |
| Translation | heart | disease | |
| Contents | 心臓血管疾患 | ||
|---|---|---|---|
| Translation | cardiovascular disease | ||
| Segmentation | Word Tokens | 心臓血管 | 疾患 |
| Translation | heart angio (cardiovascular) | disease | |
The following example queries all use the same query skeleton:
for $a in input()/patient/submitted/diagnosis where <function-call> return $a
| XQuery Function Call | Matching Samples |
|---|---|
tf:containsText($a, "心臓") |
1, 2, 3 |
tf:containsText($a, "心臓病") |
— |
tf:containsText($a, "心*") |
1, 2, 3, 4 |
tf:containsText($a, "心臓*") |
1, 2, 3 |
tf:containsText($a, "心臓疾患") |
3 |
tf:containsAdjacentText($a, 1, "心臓", "疾患") |
|
tf:containsNearText($a, 1, "心臓", "問題") |
— |
tf:containsNearText($a, 1, "心*", "*患") |
3, 4 |
With the help of the escapecard character you can negate any special meaning of the following single character. By default, the escapecard character is the backslash character "\". Use it if you want to look for any of the maskcard, escapecard or wildcard characters as literal characters.
let $text:= text{"** End of code **"}
return tf:containsText($text, "\*\*")
Here, the match succeeds if there is any two-letter word in
$text that consists only of asterisks. This is
true for the first and last words in $text.
The following checks the path separator character that is used in
$path and returns the result as plain text,
ordered by platform:
{?serialization method="text" media-type="text/plain"?}
let $path := text{"C:\Program Files\Software AG\Tamino"}
return
( "Path Separators Used
",
"DOS/Windows	: ", tf:containsText($path, "*\\*"), "
",
"UNIX	: ", tf:containsText($path, "*/*"), "
",
"MacOS	: ", tf:containsText($path, "*:*")
)
In the pattern, the path separator character must be enclosed by the
regular wildcard character, since it would not form a word on its own. Provided
that the path separator character is defined as a regular character, the query
reports for each platform whether its standard path separator character is
used, although this example is certainly not a bullet-proof method. However, if
the path separator is not defined as a regular character, it will be
interpreted as a delimiter. Using the default settings, the pattern in function
call tf:containsText($path, "*\\*") will thus be interpreted as if
"* *" were used, since the escapecard character tries to mask an
invalid character and the text retrieval system uses a delimiter instead. This
would yield "true", since there are two occurrences
of two adjacent words separated by a space character ("Program
Files" and "Software AG"). In cases
like these you should ensure that the transliteration is appropriately defined
according to what your application expects.
Note:
In contrast to "*", the characters
"\" and "?" are normally
not classified as regular characters in the collection
ino:transliteration. See the section
Customizing
Transliterations for instructions how to customize this special
collection.
If you use the default tokenizer (white space-separated), you can
customize the settings for the special characters used in pattern matching.
They are declared as attributes to ino:transliteration in the
special collection ino:vocabulary:
| escapecard character | ino:escapechar |
| maskcard character | ino:maskchar |
| wildcard character | ino:wildchar |
To change the value of any of these attributes, you can use a query similar to the following, which sets the value of the maskcard character to the default value:
declare namespace ino="http://namespaces.softwareag.com/tamino/response2"
update insert attribute ino:maskchar {"?"}
into input()/ino:transliteration
You can check your changes with the following query:
declare namespace ino="http://namespaces.softwareag.com/tamino/response2" for $a in input()/ino:transliteration/@* return $a
Note that only attributes that have been modified are returned.