Some special aspects of logical features of the Tamino Schema Definition are described in the following sections:
The validation of instances of a doctype defined in a TSD schema
is controlled by the value of the
tsd:content element in the
respective tsd:doctype element. This value may be either
"closed" or "open".
Closed content validation means that the instances are validated against the corresponding TSD schema, which is strictly based on the XML Schema Recommendation.
As a special feature, Tamino also enables you to use open content.
Open content validation is defined locally for the
complex type
definition of one element. For an element
"e", we define its child-element-name-set (CNS) as
the set of names of the children in e's content
model (i.e. the names of all elements that might appear as child nodes in
"e", including globally declared elements that are
referenced via an xs:any wildcard). Open content
validation validates all child nodes in "e" that
have a name contained in its CNS as usual. All other child nodes are
ignored.
For an element e, we define its
attribute-name-set (ANS) as the set of names of attributes in
e's content model (i.e. the names of all attributes
that might appear with "e", including globally
declared attributes that are referenced via an
xs:anyAttribute wildcard).
Open content validation validates all attributes in
e that have a name contained in its ANS as usual.
All other attributes are ignored. For elements with
xs:simpleType, the open content
validation is not changed compared to closed content. It is not possible to
define an appropriate validation for mixed content with
xs:simpleType other than
xs:string.
Note:
The open content validation of attributes is equivalent to the
addition of an <xs:anyAttribute processContents="lax"
namespace="##any"> statement to every element. If
xs:anyAttribute is already specified, the looser definition
applies.
<xs:element name = "PLAY">
<xs:complexType>
<xs:sequence>
<xs:element name="THEATRE"
type="xs:string"/>
<xs:element name = "ACT">
<xs:complexType>
<xs:sequence>
<xs:element name = "TITLE" type = "xs:string"/>
<xs:element name = "COMMENT"
type = "xs:string"
maxOccurs = "2"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
The CNS of PLAY is
{THEATRE, ACT}. The CNS
of ACT is {TITLE,
COMMENT}. The following instance validates, because
the elements MYTITLE and
THEATRE, which are not in the content model of
ACT, are not in the CNS of
ACT, thus they are ignored during open content
validation:
<PLAY>
<THEATRE>aTheater</THEATRE>
<ACT>
<MYTITLE>anotherTitle</MYTITLE>
<TITLE>aTitle</TITLE>
<THEATRE>anotherTHEATRE</THEATRE>
<COMMENT>c1</COMMENT>
<COMMENT>c2</COMMENT>
</ACT>
</PLAY>
The following instance does not validate, because
THEATRE appears in the CNS of
PLAY and appears too often in the document.
Furthermore, COMMENT belongs to the CNS of
ACT and must not appear before
TITLE child elements.
<PLAY>
<THEATRE>aTheater</THEATRE>
<THEATRE>anotherTHEATRE</THEATRE>
<ACT>
<MYTITLE>anotherTitle</MYTITLE>
<COMMENT>c3</COMMENT>
<TITLE>aTitle</TITLE>
<THEATRE>anotherTHEATRE</THEATRE>
<COMMENT>c1</COMMENT>
<COMMENT>c2</COMMENT>
</ACT>
</PLAY>
Open content validation can be compared to an
xs:any wildcard or an
xs:anyAttribute wildcard with
processContents="lax". It validates known elements and attributes
and accepts unknown elements and attributes. For "lax", all global
elements are known elements, whereas for open content the CNS consists of known
elements.
Extensive usage of
xs:any often leads to ambiguous, i.e.
invalid schemas. To circumvent this problem, either do not allow such open
content or specify xs:any for element content where you do know
more details but cannot express this without creating ambiguity. In addition to
XML
Schema's xs:any element,
Tamino's open content allows you to describe known
schema constraints while at the same time allowing for a priori unknown child
elements.
The default value is closed content
(<tsd:content>closed</tsd:content>).
Open content is a feature of Tamino
that is neither defined in DTD nor in
XML
Schema, but nevertheless makes working with
Tamino easier. In addition, xs:any as
defined by XML
Schema is supported. The xs:any element is supported
with all possible values of the processContents
attributes, i.e. "skip",
"lax" and "strict").
Schema evolution (also called "update schema") for open content is described in the section Schema Evolution for Open Content (Update Schema Processing).
A collation defines an ordering relationship (less than, equal, greater than) between pairs of characters. It applies when comparing characters or strings; by extension, it also applies when sorting characters or strings. More exactly, the process of arranging elements of a set into a particular order is defined as collation. A collation can also specify the ordering of modified letters, e.g. letters with umlauts that appear in some languages like German or the Scandinavian languages.
Tamino uses the ICU (International Components for Unicode) software package for collation.
Extensive documentation on the ICU package can be found at http://www.icu-project.org/docs/.
In TSD, collations are handled by a
tsd:collation element,
which provides some child elements for specifying
Tamino's collation-specific behavior.
Notes:
<tsd:collation/>. In
this special case, the root locale (in which the pure Unicode Collation
Algorithm (UCA) is applied) has to be used.
tsd:languageSpecifies information about the language to be used. Typically, you choose a predefined table by selecting a language.
Note:
If notsd:languagechild element is specified, the root locale is used as default.tsd:strengthSpecifies strength information, i.e. the level of comparison which applies for the collation. (There are five possible levels of comparison for collations.)
tsd:caseFirstSpecifies whether special treatment for uppercase and lowercase characters is intended.
tsd:alternateSpecifies information on punctuation handling in sorting.
tsd:caseLevelEnables different handling of case levels, see below.
tsd:frenchSpecifies French accent sorting order information.
tsd:normalizationSpecifies information on normalization.
The default values for each collation attribute refer to the root
locale, and not the default for any specific locale specified in the
tsd:language element. For example, if
the language is Latvian "lv", the default for
tsd:caseFirst is
"upperfirst", and not
"off" (which is the "default" for the
root locale which is language-neutral). Another similar language-specific
default is the tsd:french option that is
defaulted to "true" and not
"false" if the current language is specified as
French ("fr").
The tsd:collation element is located in
the logical subtree of the
tsd:elementInfo or
tsd:attributeInfo element.
The tsd:language element specifies the
language and the country for which to apply the sorting order table. This is
done by assigning a string containing the locale of the according language and
country to the value attribute of the
tsd:language element.
Tamino's locale is exactly the
ICU
locale, since Tamino uses the ICU software
package.
A locale in the sense of ICU has up to three parts:
ISO 639 Language Code
The first argument is a valid ISO language code. These codes
are the lowercase two-letter codes as defined by the ISO 639 standard.
You can find a full list of these codes at http://www.loc.gov/standards/iso639-2/iso639jac.html.
(This standard also defines three-letter codes, which are not applicable in Tamino.)
ISO 3166 Country Code
The second argument is a valid ISO country code. These codes
are the uppercase two letter codes as defined by the ISO 3166 standard. You can
find a full list of these codes at
http://www.iso.org/iso/country_codes.htm.
(This standard also defines three-letter codes, which are not applicable in Tamino.)
Suffix
A suffix can be specified for various purposes, for example
EURO for specifying a table containing a Euro currency symbol (€).
Note:
There is no difference in the sorting order whether EURO is
specified or not.
In ICU, a locale is represented simply by a string that consists of a mandatory ISO-639 language code as explained above plus an optional ISO 3166 country code plus an optional suffix. Tamino allows two different styles of syntax:
RFC-1766 Style (recommended)
The fields are separated by a minus sign. For example, German
for Germany with a Euro sign would be expressed as de-DE-EURO.
ICU Style
The fields are separated by an underscore sign. For example,
German for Germany with a Euro sign would be expressed as
de_DE_EURO.
Note:
Locale names are case-insensitive. By convention, the language
code is lowercase, the country code is uppercase and the variant part is
uppercase.
The table listing the values that are available for the
value attribute of the
tsd:language element can be found in
the appendix.
The tsd:strength element has a
value attribute that specifies the strength
information, i.e. the level on which comparison operations are performed.
Thevalue attribute can have one of 5 possible
values:
primaryLevel 1: The base characters are compared, e.g., "a" < "b". No other aspects are taken into account.
secondaryLevel 2: Not only the characters themselves are compared, but also accents on characters are compared, e.g. "as" < "às" < "at".
tertiaryLevel 3 (default): Case-sensitive comparison: uppercase and lowercase characters are compared, e.g. "ao" < "Ao" < "aò". This is ignored if a difference is found on level 1 or level 2.
quaternaryLevel 4: Punctuation-sensitive comparison distinguishes words with and without punctuation, e.g. "ab" < "a-b" < "aB". This is ignored if a difference is found on level 1-3, and should be used only if a distinction based on punctuation is required.
identicalLevel 5: This comparison level is used if levels 1-4 would yield identical results. The Unicode code point values are compared. Note that this level of comparison can impact performance negatively.
If specified, this element makes case the most significant factor
when performing collation at the tertiary level (level 3). Collation at primary
and secondary levels is unaffected by this option. It has the
value attribute, which can have one of the
following three values:
- "upperFirst"
With "upperFirst", words starting with uppercase are sorted together before words starting with lowercase.
- "lowerFirst"
A value of "lowerFirst" causes exactly the opposite behavior.
- "off"
A value of "off" indicates no distinction is made between uppercase and lowercase during sorting.
The default is "off"
Note:
If this option is set to either
"upperFirst" or
"lowerFirst", words starting with the same case are
sorted together either uppercase or lowercase first. Mixed case words (e.g.
"AbC", "aBc") are therefore always sorted between
uppercase and lowercase.
This element is used for specifying information on the handling of punctuation in sorting. Its value attribute can take the following values:
The value "shifted" sorts words containing punctuation marks together (e.g. bi-weekly and biweekly). This means that punctuation is ignored for levels 1-3.
The value "nonIgnorable" (default) distinguishes these words and sorts them separately. This means that punctuation marks are taken into account.
The tsd:caseLevel element has a
value attribute that can have the value
"true" or "false". This
option, which is independent of the strength of comparison, introduces an extra
level for case differences between secondary and tertiary if set to
"true". It can be used in Japanese to make
small/large Japanese Kana characters more significant than other tertiary
differences. It can also be used to ignore tertiary or secondary differences
except for case. For example, if strength is set to
"primary" and case level is
"true", the comparison ignores accents and other
tertiary differences except for case. The default for the value attribute is
"false".
This element is used for specifying French accent sorting order information. (French and some other languages require words to be ordered on the secondary level according to the last accent difference.)
Possible values for the value
attribute are "true" and "false".
The value "true" produces French accent sorting. The default is "false", but the function is switched on if the collation language is "fr".
This element has a value attribute that is used to decide whether or not text normalization is performed.
Possible values for the value
attribute are "true" and "false".
The value "true" produces results as if text were normalized. The default is "false", meaning that no normalization is done. Most languages require the value "true" for consistent results.
The Tamino Schema Language allows you to define a non-XML doctype. Thus it is possible to store non-XML objects in Tamino, for example, word processor documents, spreadsheets, SGML instances, HTML documents, "broken" (i.e., not well-formed) XML, graphic files, multimedia files, etc.
These objects are stored using HTTP PUT requests or
Tamino _process commands
by referring to the object's database URL (see the
URL format for
plain URL addressing).
Schema definition for storing and retrieving non-XML objects is described under the following headings:
You can write a simple XML Schema for the objects to be stored. You can use the Tamino Schema Editor or a text editor to create a Tamino schema, since writing a schema for a non-XML object is usually trivial.
The following is a description of attribute values specific to storing non-XML objects.
tsd:nonXMLelementThe
tsd:nonXMLelement in the definition of a doctype indicates that data belonging to this defined doctype is stored in Tamino as non-XML data (and not in the standard XML data storage area). This element may only occur within a doctype definition. It excludes all options for defining conditions for XML storage. It offers the possibility to define a text index (see below).tsd:indexIn this context, this element is a child element of
tsd:nonXML. It specifies that a non-XML doctype declared with the containingtsd:nonXMLelement will be indexed with a full text index. For example, the doctype element could look like this if a text index is defined for the specific doctype (only the fragment of the whole schema definition belonging to the doctype element is shown):<tsd:doctype name = "X-Rays"> <tsd:nonXML> <tsd:index> <tsd:text/> </tsd:index> </tsd:nonXML> </tsd:doctype>Note:
A standard indexing option does not make sense in this context and is therefore not available for non-XML data.
Note:
A doctype that stores non-XML data has a name just like any
other doctype. Unlike a doctype for XML data, no global element whose name
corresponds to this is required.
By default, Tamino converts all text documents stored in a non-XML document to an internal UNICODE-based encoding. In some scenarios, e.g. for usage with WebDAV, this means that the document returned upon retrieval may not be identical to the document that was originally stored. This can be prevented by using the following schema fragment:
<tsd:doctype name="...">
<tsd:nonXML>
<tsd:noConversion/>
</tsd:nonXML>
</tsd:doctype>
You could theoretically specify a single schema to describe all the non-XML objects you wish to store in Tamino. In practice, however, you may wish to differentiate between types of objects and/or object domains. For example, if patients' X-rays are to be stored electronically in Tamino, but their format can differ (for example, GIF or JPG), you can define a doctype "X-Rays" to store any instance.
Note:
If you want to verify this, use plain HTTP requests or the
Tamino X-Plorer, for example.
 To store a non-XML object using the Tamino Interactive
Interface
To store a non-XML object using the Tamino Interactive
Interface
Set the Tamino database URL to the database. Enter the following in the collection field:
collection/doctype/filename
With the cursor in the Process field of the Tamino Interactive Interface, browse to the object you wish to load and choose .
To retrieve a non-XML object using the Tamino Interactive
Interface
Set the Tamino database URL to the full path of the target as follows:
http://localhost/tamino/database/collection/doctype/filename
Type an asterisk "*" in the X-Query field and choose to retrieve the object.
The following example illustrates a schema for storing non-XML objects in Tamino. The objective is to store X-ray pictures electronically in the Hospital collection.
In the TSD, this can be defined by the following XML document fragment:
<xs:schema
xmlns:xs = "http://www.w3.org/2001/XMLSchema"
xmlns:tsd = "http://namespaces.softwareag.com/tamino/TaminoSchemaDefinition">
<xs:annotation>
<xs:appinfo>
<tsd:schemaInfo name = "nonXML">
<tsd:collection name = "Hospital">
</tsd:collection>
<tsd:doctype name = "X-Rays">
<tsd:nonXML>
</tsd:nonXML>
</tsd:doctype>
</tsd:schemaInfo>
</xs:appinfo>
</xs:annotation>
</xs:schema>
To retrieve a single instance by file name (xatkins.gif, for example) from the collection "hospital" in the Tamino database "ino":
http://hostname/tamino/ino/hospital/X-Rays/xatkins.gif
To retrieve a single instance by object ID (4711, for example) from the collection "Hospital" in the Tamino database "ino":
http://hostname/Tamino/ino/hospital/X-Rays/@4711
This section discusses the technique of defining shadow functions under the following topics:
A shadow function creates a shadow document for a non-XML document. The non-XML document can be stored in Tamino or outside Tamino. A shadow document is an XML document that can contain information such as metadata, index values and other generated values for the corresponding non-XML document. The purpose of the shadow document is to store information that can be used for queries that would not be possible on the original document.
In order to gain maximum benefit from these techniques, it is necessary to apply suitably designed shadow functions.
The schema that defines the non-XML document must also contain appropriate statements to indicate that a shadow function will be used. The next section explains how to do this.
To indicate that a doctype is intended to store non-XML data,
add a tsd:nonXML element to the
tsd:doctype element below
tsd:schemaInfo.
In order to specify which server extension will act as a shadow
function, code a tsd:shadowXML element as a child of
tsd:doctype.
Note:
This is analogous to the
tsd:index child element, which allows
you to specify information on indexing options.
As the requirements for shadow functions can be quite different
depending on the kind of data to be processed, separate shadow functions can be
established that cater either for text data or for binary data. These shadow
functions can be specified using the child elements of the
tsd:shadowXML element:
In order to define a binary shadow function, the
tsd:shadowXML element must have a
tsd:onBinaryInsert element specifying
the name of the shadow function that processes binary data.
In order to define a text-based shadow function, the
tsd:shadowXML element must have a
tsd:onTextInsert element specifying
the name of the shadow function that processes text data.
Notes:
tsd:onBinaryInsert or
tsd:onTextInsert must be present in
the schema in order to define a valid
tsd:shadowXML element.
It is possible to store the shadow document in Tamino without storing the original non-XML document in Tamino. The non-XML document can reside externally, for example in the file system. This allows applications to retrieve indexing information from the shadow document without the requirement to have the non-XML document itself stored in Tamino. Requests to return the non-XML document itself (for example, using plain URL addressing) rather than indexing information about the non-XML document will fail with an HTTP status 404 (file not found).
This feature is activated by the
tsd:storeShadowOnly element in the
definition of the shadow document.
If both a binary shadow function and a text-based shadow function are present, the appropriate function is executed as determined by the criteria described in the section Media Type Requirements of the X-Machine Programming documentation.
The shadow function must be implemented by the
user as a Tamino Server
Extension. It is called when the non-XML document is
stored. If tsd:storeShadowOnly is defined in the
schema, the shadow document is stored in Tamino but the non-XML document is not
copied into Tamino.
By calling the shadow function, the user can create an XML document containing values derived from the non-XML document. The XML document is then stored in the Tamino X-Machine as the shadow document that is associated with the non-XML document.
The shadow document can be queried using the XQuery or X-Query query language syntax, just like an ordinary XML document. In fact, all XQuery or X-Query requests will deliver the content of the shadow document instead of the original non-XML document's content.
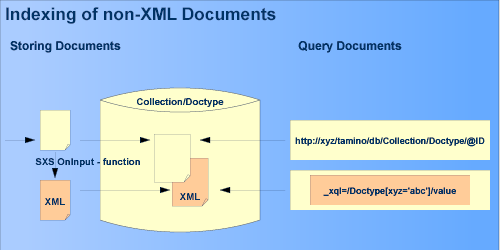
When a non-XML document is processed, it is passed as a parameter of a suitable binary or textual datatype to the shadow function, which creates the shadow document. The X-Machine inserts the shadow document and performs index processing on it.
The result is stored as a "shadow" of the original non-XML document node in the Tamino server.
We now consider what happens in the following three situations:
Document Retrieval
As discussed and shown above, all queries issued in
Tamino's query languages X-Query and XQuery deliver
the shadow document and not the original non-XML document.
In the case of direct access via plain URL
addressing, the non-XML original document is delivered instead of the shadow
document. If, however, the option
tsd:storeShadowOnly is used in the
schema definition, the non-XML document is not stored in Tamino, so an HTTP
status 404 (file not found) is returned instead.
Deletion of the Original Non-XML Document
that is stored in Tamino
Deleting the instance in Tamino deletes the
shadow document as well.
Updating the Original Non-XML Document
that is stored in Tamino
Updating the instance in Tamino deletes the shadow document
and re-creates it by executing the shadow function on the updated non-XML
document.
Note:
Updating based on XQuery is not permitted.
The following schema fragment shows how to define support for
shadow functions within a Tamino schema defining
shadow functions named SXSBinaryIndexer.put for binary
data and SXSTextIndexer.put for text data:
<?xml version="1.0" encoding="windows-1252" ?>
<xs:schema
elementFormDefault="qualified"
xmlns:tsd="http://namespaces.softwareag.com/tamino/TaminoSchemaDefinition"
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:annotation>
<xs:appinfo>
<tsd:schemaInfo name="nox">
<tsd:collection name="nox" />
<tsd:doctype name="nox ">
<tsd:nonXML>
<tsd:shadowXML>
<tsd:onBinaryInsert>
SXSBinaryIndexer.put
</tsd:onBinaryInsert>
<tsd:onTextInsert>
SXSTextIndexer.put
</tsd:onTextInsert>
</tsd:shadowXML>
</tsd:nonXML>
</tsd:doctype>
</tsd:schemaInfo>
</xs:appinfo>
</xs:annotation>
<xs:element name="blob">
.
.
.
</xs:element>
.
.
.
</xs:schema>
Indexing of non-XML data differs significantly from the usual indexing of XML data as described in the section Indexing XML Data for Native Storage. One possibility is to define a text index based on classic full-text search algorithms, as described in the section Built-In Indexing of Non-XML Data of this document.
However, this approach is not always appropriate:
This approach is only applicable when working with text data, not with binary data. In this case shadow functions provide the only possibility to define an index for binary non-XML data.
If storing non-XML documents, it is not possible to search on content or metadata of such a document other than the docname.
This happens, for example, if a user wants to store and index office documents (e.g. XML documents created by Microsoft Office programs, HTML or images) and wants to retrieve the documents on behalf of an index document, which should already be created when the document is stored.
Alternatively, you can avoid these disadvantages by using shadow functions to create index values for non-XML documents.
The Tamino non-XML indexing software tool is an exemplary application of shadow functions.
The Tamino Non-XML Indexer extends Tamino's facilities for storing and retrieving non-XML objects. It seamlessly integrates non-XML files such as Microsoft Office documents or Star Office documents into the Tamino environment. It enables meaningful searches on the content and/or metadata (such as the date when the document was last changed, the author, etc.) of such non-XML files.
XML documents or elements of them can also be associated with a function by the usage of database triggers. This is quite similar to the situation when using shadow functions, also trigger functions can be initiated by the occurrence of a stimulating event. Similarly, the sub-tree of the document to be processed must be associated with the schema in order to indicate which part of the document is affected. This is described below.
The events that can initiate execution of a trigger are:
- Insert
- Update
- Delete
Triggers and trigger functions are described in more detail in Tamino Server Extensions documentation.
The tsd:trigger element contains all
information for logical nodes in the schema that define action triggers for the
Tamino Server
Extensions.
Notes:
Depending on the kind of event being processed, three different kinds of trigger functions are currently supported:
- Insert functions
For storage or processing: the "Insert" functions/triggers, which are executed before the validation phase during processing.
- Update functions
For updating: the "Update" functions/triggers, which are executed before the validation phase during the updating of an XML document.
- Delete functions
For deletion: the "Delete" functions/triggers, which are executed when an XML document is to be deleted from the database.
All these are supported by Tamino,
depending on the child elements of the
tsd:trigger element:
In order to define insert trigger functions, the
tsd:trigger element must have a
tsd:onInsert child element specifying
the name of the trigger function (Server Extension) that caters for
insertions.
In order to define update trigger functions, the
tsd:trigger element must have a
tsd:onUpdate child element specifying
the name of the trigger function (Server Extension) that caters for
updates.
In order to define delete trigger functions, the
tsd:trigger element must have a
tsd:onDelete child element specifying
the name of the trigger function (Server Extension) that caters for
deletions.
In each of these cases, the name of the trigger function (Server Extension) that caters for the insertions, updates or deletions is specified simply as the content of the respective element.
Notes:
tsd:onInsert,
tsd:onUpdate and
tsd:onDelete.
tsd:onInsert,
tsd:onUpdate and
tsd:onDelete child elements of the
tsd:trigger element each have a
required attribute type. Currently the only
permitted value to be specified for this attribute is
"action".
The following schema fragment defines trigger functions named
sxsDelete for delete events,
sxsUpdate for update events and
sxsInsert for insert events:
<xs:element name = "firstname" type="xs:string">
<xs:annotation>
<xs:appinfo>
<tsd:elementInfo>
<tsd:logical>
<tsd:trigger>
<tsd:onDelete type="action">sxsDelete</tsd:onDelete>
<tsd:onUpdate type="action">sxsUpdate</tsd:onUpdate>
<tsd:onInsert type="action">sxsInsert</tsd:onInsert>
</tsd:trigger>
</tsd:logical>
</tsd:elementInfo
</xs:appinfo>
</xs:annotation>
</xs:element>
.
.
.
A trigger function may have an arbitrary number of parameters. A single trigger function, which is implemented as a server extension, can be used in different schemas with a different set of parameters determined by the signature of the underlying server extension function. In addition, you can define an arbitrary number of trigger functions of the same type on one logical node (that is, element or attribute).
.
.
.
<xs:element name="e1" type="xs:string">
<xs:annotation>
<xs:appinfo>
<tsd:elementInfo>
<tsd:logical>
<tsd:trigger>
<tsd:onInsert type="action" name="myXtension.onInsert">
<tsd:parameters>
<tsd:parameter name="param1" type="xs:string">MyClassName</tsd:parameter>
<tsd:parameter name="param2" type="xs:int">4711</tsd:parameter>
</tsd:parameters>
</tsd:onInsert>
</tsd:trigger>
</tsd:logical>
</tsd:elementInfo>
</xs:appinfo>
</xs:annotation>
</xs:element>
.
.
.
The name of the trigger function should be specified in the
name attribute of the
tsd:onInsert,
tsd:onUpdate or
tsd:onDelete element. For backward compatibility
with older versions of Tamino, it can alternatively be specified as a text node
within the tsd:onInsert,
tsd:onUpdate or
tsd:onDelete element. This facility may be withdrawn
in future versions of Tamino.
The signature of the server extension function is the union of:
the base signature, which depends on the type of the trigger
(onInsert, onUpdate or
onDelete;
additional parameters that match the parameters specified in the schema document.
Another situation where XML documents or elements of them can be associated with a function is the usage of functions for determination of default values of elements or attributes.
The tsd:function child element of the
tsd:default element allows you to
specify a function whose return value defines the default value for an element
or attribute within the schema.
Notes:
default or
fixed attribute.
The following example explains the use of the
tsd:default element and its child
element, the tsd:function element, in order to
define a function createDefaultString in the namespace
company:
<?xml version = "1.0" encoding = "UTF-8"?>
<xs:schema
xmlns:tsd = "http://namespaces.softwareag.com/tamino/TaminoSchemaDefinition"
xmlns:xs = "http://www.w3.org/2001/XMLSchema">
<xs:annotation>
<xs:appinfo>
<tsd:schemaInfo name = "person">
<tsd:collection name = "person"></tsd:collection>
<tsd:doctype name = "person"/>
</tsd:schemaInfo>
</xs:appinfo>
</xs:annotation>
<xs:element name = "person">
<xs:complexType>
<xs:sequence>
<xs:element name = "name" type = "xs:string">
<xs:annotation>
<xs:appinfo>
<tsd:logical>
<tsd:default>
<tsd:function xmlns:company="http://www.company.com/functions"
name="company:createDefaultString"/>
</tsd:default>
</tsd:logical>
</xs:appinfo>
</xs:annotation>
</xs:element>
<xs:element name = "first" type = "xs:string">
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
In Tamino, it is possible to store instances without previously defining a schema. There are two ways to store data in a collection without having to previously define a schema:
There is a special collection reserved in
Tamino for the storage of instances that have not
been supplied with a valid schema. This is the collection ino:etc,
which is also used if no collection is specified in the
_process command.
Note:
It is recommended not to use
ino:etc for storing real XML data for which a schema exists and
which could be stored in other collections. This kind of usage of
ino:etc may lead to severe problems, especially with respect to
performance, since ino:etc was not designed to store real XML
data.
Since version 4.2 of Tamino, there is an alternative way of storing data without a previously defined schema which even allows data to be stored in collections with arbitrary names. A collection can be defined so that it only accepts data complying with a previously defined schema that has explicitly been specified (the explicit case), or to accept data also without such a schema (the implicit case); both cases may apply simultaneously. In the implicit case, the system automatically generates a suitable schema and uses it internally.
In detail, this works in the following manner, depending on whether an XML or a non-XML document is affected:
A _process of an XML document into
a "schemaless" collection implicitly creates the respective
doctype via an internal, hidden schema.
The XML doctype has a text index on the root node.
A _process of a non-XML document
into a "schemaless" collection stores it in the doctype
ino:nonXML.
This feature is controlled by the
use attribute of the
tsd:schema child element of the
tsd:collection element. This attribute can have the following
values:
- "required"
This choice reproduces the behavior of the collections of Tamino versions up to 4.1: it is not permitted to store data without having previously defined a schema.
This is the default value for this option.
- "optional"
Both explicit and implicit creation of doctypes are permitted in the respective collection. If a schema is used in the
_defineoperation, then the explicit case occurs, otherwise a schema is generated implicitly.- "prohibited"
Only implicit creation of doctypes is possible within the respective collection. It is not possible to perform "normal" schema definition within this collection.
Note:
In this case, the_definecommand is used as follows: A collection can be defined by itself as an object carrying properties. This is done via a_definecommand. However, the input for the_defineis not really an XML schema. This is called "collection definition document".
Tamino offers a switch to control at
the doctype level whether the reuse of ino:id's is permitted.
In the tsd:logical element you can define a
tsd:systemGeneratedIdentity element,
which acts as a switch depending on the value of its
reuse attribute. The
reuse attribute may have the value
"true" or "false".
If reuse="true", reuse of ino:id's
is possible when inserting documents after deleting other documents. This is
the default value.
If reuse="false", reuse of ino:id's
is prohibited.
The example schema below prohibits reuse of ino:id's
for doctype A.
<?xml version="1.0" encoding="utf-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:tsd="http://namespaces.softwareag.com/tamino/TaminoSchemaDefinition">
<xs:annotation>
<xs:appinfo>
<tsd:schemaInfo name="Reusage-Schema">
<tsd:collection name="Reusage"/>
<tsd:doctype name="A">
<tsd:logical>
<tsd:systemGeneratedIdentity reuse="false"/>
</tsd:logical>
</tsd:doctype>
</tsd:schemaInfo>
</xs:appinfo>
</xs:annotation>
<xs:element name="A"/>
<xs:schema>