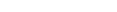
W3C released the Recommendation for XML Schema in May 2001 (http://www.w3.org/TR/xmlschema-0). The definition of the standard not only took into account existing schema languages such as XSchema, DDML, XML-Data, XDR and SOX, but also relied on the active participation of wide parts of the IT industry, especially database manufacturers. Most XML communities are now moving towards XML Schema.
If you are new to XML Schema, it is best to think of it as DTD + Datatypes + Namespaces and worry about the rest later. As you are probably already familiar with DTDs, we begin with datatypes.
The introduction of a full type system (http://www.w3.org/TR/xmlschema-2/) for elements and attributes is probably the most important aspect of XML Schema. It includes the attribute types already familiar from DTDs, but also introduces a wide range of datatypes taken from SQL and programming languages.
XML Schema differentiates between simple datatypes and complex datatypes. Complex datatypes are - as the name indicates - composed of other, simpler datatypes and are only applicable to XML elements, because only elements can contain child nodes. Simple datatypes, at the other hand, are applicable to both elements and attributes.
Simple datatypes are either built-in datatypes, or are derived from these datatypes. Each simple datatype is characterized by a primitive (built-in) datatype on which it is based, and by a set of constraining facets that are applied to the Value Space or the Lexical Space of the datatype.
XML Schema's type system makes a clear distinction between value space and lexical space. Whereas the value space consists of an abstract collection of valid values for a datatype, the lexical space contains the lexical representations of these values – i.e. the tokens that appear in the XML document.
For example, canonical lexical representations for an item of datatype
boolean are the
strings"true"and"false".
But alternative string representations such as "1"
and "0" are also valid lexical representations. The
value space for the datatype boolean, at the other hand, contains
the Boolean values true and false.
XML Schema defines a large number of built-in primitive datatypes, all of which are supported by Tamino.
| Datatype | Description | Lexical representation | SQL equivalent |
|---|---|---|---|
| string | Character string of unlimited length. | A short string | VARCHAR |
| boolean | Boolean value. | "true","false", "1", "0" | BIT |
| decimal | Decimal number. A minimum precision of 18 digits is supported by conforming processors. | "-1.23", "126.54", "0.0", "+100000.00", "210" | DECIMAL |
| float | A single-precision 32-bit floating point type according to IEEE 754-1985. Special values are positive and negative zero, positive and negative infinity, and not-a-number. | "-1E4", "127.433E12", "12.78e-2", "12", "0", "-0", "INF", "-INF", "NaN" | REAL |
| double | A double-precision 64-bit floating point type according to IEEE 754-1985. | "-1E4", "127.433E12", "12.78e-2", "12", "0", "-0", "INF", "-INF", "NaN" | DOUBLE |
| duration | Specifies a period of time. The value space is a six-dimensional space where the coordinates designate the Gregorian year, month, day, hour, minute, and second. | The lexical
representation follows the format PnYnMnDTnHnMnS. An optional
fractional part for seconds is allowed. Negative durations are allowed, too.
Examples: "PT1H3M13.5S" "P1Y5M" "-PT3H" |
INTERVAL |
| time | A specific time of day as defined in section 5.3 of ISO 8601 |
The lexical representation follows the format
An optional fractional part for seconds is allowed. Additionally, a
time zone can be specified: "Z" for UTC, or a signed
time difference in the format Examples: "05:20:23.2" "13:20:00-05:00" |
TIME |
| date | A Gregorian calendar date according to section 5.2.1 of ISO 8601. |
The lexical representation follows the format
Example: "1999-05-31" |
DATE |
| dateTime | A specific instant of time (a combination of date and time) as defined in section 5.4 of ISO 8601. |
The lexical representation follows the format
Examples: "1999-05-31T13:20:00-05:00" "2001-12-01T05:20:23.2" |
TIMESTAMP (slightly different lexical representation) |
| gYearMonth | Represents a specific Gregorian month in a specific Gregorian year. | The lexical
representation follows the format CCYY-MMZ. "Z"
denotes an optional time zone.
Examples: "2001-05" |
DATE |
| gYear | Represents a Gregorian year. | The lexical
representation follows the format CCYYZ. "Z" denotes
an optional time zone.
Examples: "1984" |
DATE |
| gMonthDay | Specifies a recurring Gregorian date. | The lexical
representation follows the format --MM-DDZ. "Z"
denotes an optional time zone.
Examples: "--04-01" |
DATE |
| gMonth | Denotes a Gregorian month that recurs every year. | The lexical
representation follows the format --MM--Z. "Z"
denotes an optional time zone.
Examples: "--07--" |
DATE |
| gDay | Denotes a Gregorian day that recurs every month. | The lexical
representation follows the format ---DDZ. "Z"
denotes an optional time zone.
Examples: "---13" |
DATE |
| hexBinary | Arbitrary hex-encoded binary data. | "9a7f", "FFFF3", "0100" | BINARY/BLOB |
| base64Binary | Base64-encoded arbitrary binary data. The entire binary stream is encoded using the Base64 Content-Transfer-Encoding defined in Section 6.8 of RFC 2045. | BINARY/BLOB | |
| anyURI | A Uniform Resource Identifier reference (URI). | VARCHAR | |
| QName | An XML qualified name consisting of namespace name and local part. | VARCHAR | |
| NOTATION | Represents the NOTATION attribute type from XML attributes. | This datatype is abstract; users must derive their own datatype from it. | VARCHAR |
In addition to these primitive datatypes, the Recommendation also
defines built-in datatypes that are derived from these primitive datatypes by
applying constraining facets. For example, the datatype
nonNegativeInteger is derived from the datatype
integer by constraining its value space to non-negative values,
i.e. by applying the constraining facet minInclusive
value="0".
Another set of built-in datatypes is constructed from other built-in datatypes by list extension. The datatypes NMTOKENS, IDREFS, and ENTITIES are derived in this way from NMTOKEN, IDREF, and ENTITY. An attribute or element with such a datatype can contain several values separated by blanks.
In addition to these built-in datatypes, XML Schema allows the user to define simple datatypes by applying constraining facets to existing simple datatypes, a process which is also supported by Tamino. Each facet controls a different aspect of a datatype, for example the total number of digits or the number of fractional digits for a decimal datatype.
The following constraining facets are available:
| Facet | Description |
|---|---|
| length | Defines the length of a datatype value (number of characters for strings, number of octets for binary, etc.). |
| minLength | Lower bound for the length of a datatype value. |
| maxLength | Upper bound for the length of a datatype value. |
| pattern | Restricts the values of a datatype by constraining the lexical space to a specific pattern. Patterns are defined via regular expressions. The syntax for the specification of patterns uses almost the same tokens and escape symbols as other languages that support patterns (such as Perl). |
| enumeration | Constrains the value space of a datatype to the specified enumeration values. |
| whitespace | This is not really a
constraining facet but specifies a policy for handling whitespace in input
values: preserve keeps all whitespace characters,
replace replaces each whitespace character with the blank
character, collapse reduces all sequences of whitespace characters
to a single blank character.
|
| maxInclusive | Upper bound for the value space of a datatype, includes the specified value. |
| maxExclusive | Upper bound for the value space of a datatype, excludes the specified value. |
| minInclusive | Lower bound for the value space of a datatype, includes the specified value. |
| minExclusive | Lower bound for the value space of a datatype, excludes the specified value. |
| totalDigits | Maximum total number of decimal digits in the values of datatypes derived from datatype decimal. |
| fractionDigits | Maximum number of decimal digits in the fractional part of values of datatypes derived from decimal. |
In addition to the primitive built-in datatypes shown above, the following derived datatypes are also available in XML Schema:
| Datatype | Derived from | Description | SQL equivalent |
|---|---|---|---|
| normalizedString | string | Cannot contain carriage return (#xD), line feed (#xA) or tab (#x9) characters. | VARCHAR VARWCHAR |
| token | normalizedString | Cannot contain line feed (#xA) or tab (#x9) characters, cannot have leading or trailing spaces (#x20) and cannot have internal sequences of two or more spaces. | VARCHAR VARWCHAR |
| language | token | Language identifiers as defined by ISO 639 and ISO 3166. | VARCHAR VARWCHAR |
|
NMTOKEN NMTOKENS Name NCName ID IDREF IDREFS ENTITY ENTITIES |
token | Represent the corresponding attribute type from XML 1.0 (DTD). | VARCHAR VARWCHAR |
| integer | decimal | The standard
mathematical integer datatype of arbitrary size. Derived from datatype
decimal by setting the facet fractionDigits to 0.
|
no equivalent (value range too big) |
| nonPositiveInteger | integer | Integer less than or equal to zero. | no equivalent |
| negativeInteger | nonPositiveInteger | Integer less than zero. | no equivalent |
| long | integer | Integer in the range from -9223372036854775808 to 9223372036854775807. | BIGINT |
| int | long | Integer in the range from -2147483648 to 2147483647. | INTEGER |
| short | int | Integer in the range from -32768 to 32767. | SMALLINT |
| byte | short | Integer in the range from -128 to 127. | TINYINT |
| nonNegativeInteger | integer | Integer greater than or equal to zero. | no equivalent |
| unsignedLong | nonNegativeInteger | Integer in the range from 0 to 18446744073709551615. | no equivalent |
| unsignedInt | unsignedLong | Integer in the range from 0 to 4294967295. | no equivalent |
| unsignedShort | unsignedInt | Integer in the range from 0 to 65535. | no equivalent |
| unsignedByte | unsignedShort | Integer in the range from 0 to 255. | TINYINT |
| positiveInteger | nonNegativeInteger | Integer greater than zero. | no equivalent |
As we have already mentioned above, it is possible for the user to
restrict built-in datatypes even further. Let us look at an example. We want to
declare a schema for the business object jazzMusician. We choose
to represent the property type as an attribute. Since only three
values are allowed, we want to declare the attribute accordingly, restricting
its value range to "instrumentalist",
"jazzSinger", and
"jazzComposer". We can achieve this with the
following definition:
<xs:attribute name = "type">
<xs:simpleType>
<xs:restriction base = "xs:NMTOKEN">
<xs:enumeration value = "instrumentalist"/>
<xs:enumeration value = "jazzSinger"/>
<xs:enumeration value = "jazzComposer"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
Here we declare a simple datatype on the fly. This new anonymous
datatype, which is only used for the attribute with the name type,
is derived from the built-in datatype xs:NMTOKEN by restriction.
We then use three occurrences of the xs:enumeration facet to
define the three possible values.
Similarly, we could define an element grade (for the
saxophone mouthpiece):
<xs:element name = "grade">
<xs:simpleType>
<xs:restriction base = "xs:decimal">
<xs:fractionDigits value = "1"/>
<xs:totalDigits value = "2"/>
</xs:restriction>
</xs:simpleType>
</xs:element>
Here we use a restricted form of the built-in datatype
xs:decimal; we only allow one decimal digit before and one decimal
digit after the decimal point.
Instead of using a derived simple type anonymously, we can also give it a name:
<xs:simpleType name="gradeType">
<xs:restriction base = "xs:decimal">
<xs:fractionDigits value = "1"/>
<xs:totalDigits value = "2"/>
</xs:restriction>
</xs:simpleType>
Such a type definition must be made at the schema level, as a direct
child node of the <xs:schema> element. Later we can refer to
that type definition by quoting the type name:
<xs:element name = "grade" type="gradeType"/>
In contrast to the simpleType declaration there is also a
complexType declaration. Complex datatypes are used to combine
several XML elements and attributes into one datatype. Thus they are a central
element in schema definition. In particular, complex datatypes are used to
define elements that contain child elements and/or have attributes. As with
simple datatypes, we can use complex types here as anonymous types, defined on
the fly, or as explicitly named types for later reference.
Here is an example:
<xs:complexType name="periodType">
<xs:sequence>
<xs:element name = "from" type = "xs:date"/>
<xs:element name = "to" type = "xs:date"/>
</xs:sequence>
</xs:complexType>
and
<xs:element name = "period" type="periodType"/>
Here we simply define a complex element that contains a period of time:
the first child element from contains the start date, the second
child element to contains the end date. The elements are bound
together with the xs:sequence connector. This constructor requires
that instance documents always use the prescribed sequence of elements. For
example:
<period> <from>1917-05-23</from> <to>1918-11-05</to> </period>
is valid, whereas
<period> <to>1918-11-05</to> <from>1917-05-23</from> </period>
is invalid.
Here is another example:
<xs:element name = "performedAt">
<xs:complexType>
<xs:all>
<xs:element name = "location" type = "xs:normalizedString"/>
<xs:element name = "time" type = "xs:dateTime"/>
</xs:all>
</xs:complexType>
</xs:element>
Here we have used the connector xs:all. This connector
creates a bag (i.e. an unordered list) of elements, so both of the following
instances are valid:
<performedAt> <location>Dixie Park</location> <time>1910-03-27T17:15:00</time> </performedAt>
<performedAt> <time>1910-03-27T17:15:00</time> <location>Dixie Park</location> </performedAt>
As you can see, XML Schema makes it easy to specify unordered sequences. With the DTD one had to resort to specifying alternatives of all possible permutations of the child elements; quite a laborious process.
The third possibility to connect elements is the xs:choice
connector, which specifies alternatives.
All of these connectors can be nested to create complex element
structures. There is one exception: the xs:all connector cannot
directly contain other connectors (but it can contain other complex elements).
In the following example we define an element that is either a
period or a performedAt type element:
<xs:element name = "collaborationContext">
<xs:complexType>
<xs:choice>
<xs:sequence>
<xs:element name = "from" type = "xs:date"/>
<xs:element name = "to" type = "xs:date"/>
</xs:sequence>
<xs:all>
<xs:element name = "location" type = "xs:normalizedString"/>
<xs:element name = "time" type = "xs:dateTime"/>
</xs:all>
</xs:choice>
</xs:complexType>
</xs:element>
Caution:
Schema designers should always design schemas that are
deterministic. A schema is deterministic if the parser can decide at each
choice point which branch to take without having to look ahead in the document.
For example, the particle ((a,b)|(a,c)) is not deterministic,
because the parser does not have enough information when it is parsing the
element a to decide which branch to take. As required by XML
Schema, Tamino refuses to accept such a schema (with an
INOXDE7909 response code). The solution is to factor the
common a element out and redesign the particle into
(a,(b|c)). Similarly, ((a,b)|(c&a)) is not
deterministic because the all group (c&a) allows
valid instances of (a&c). Here we would need to redesign the
particle as ((a,(b|c))|(c,a)).
By default, an element of complex type must only contain attributes and
child elements, but no other content. To allow for mixed content (i.e. text
interspersed between child elements) we must specify mixed="true"
for the complex type definition. Thus, XML Schema allows control over the
number and order of child elements within mixed content, which is not possible
in a DTD.
<xs:element name = "track">
<xs:complexType mixed = "true">
<xs:sequence>
<xs:element name = "duration" type = "xs:duration"/>
</xs:sequence>
</xs:complexType>
</xs:element>
Here we have equipped the property track from the business
object album with an additional element duration.
This defines the duration of each track. In addition, the element
track contains the title of each track as text content. This is
possible because xs:complexType was specified with
mixed="true". Thus we would allow instances such as
<track>Blue Monk<duration>PT7M37S</duration></track>
The connectors discussed above (sequence, choice, all) are always necessary when you want to nest XML elements. Even if an element has only a single child element, the child element must be placed into a sequence. If an element has no child elements but only attributes, then we do not need these connectors. However, the type of the element is still complex.
In this case we can specify xs:attribute elements as
children of the xs:complexType element. The result would be an
empty element equipped with attributes (XML Schema does not have
an"EMPTY" specifier as the DTD has).
Alternatively, we can specify the xs:attribute elements
within an xs:simpleContent declaration, as shown in the following
example:
<xs:element maxOccurs = "unbounded" name = "track">
<xs:complexType>
<xs:simpleContent>
<xs:extension base = "xs:normalizedString">
<xs:attribute name = "duration" type = "xs:duration" use = "required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
Here we have defined duration as an attribute of
track.
We have also explicitly defined the cardinality constraint
maxOccurs for the element track. XML Schema has two
cardinality constraints: maxOccurs and minOccurs.
minOccurs defines the minimum number of element occurrences
required, maxOccurs the maximum. The default value for both is 1,
so if nothing is specified, an element must appear once and only once. These
constraints replace and extend the element modifiers as we know them from
DTDs.
| minOccurs | maxOccurs | DTD | Description |
|---|---|---|---|
| 1 | 1 | none | single element required |
| 1 | unbounded | + | one or more elements, at least one required |
| 0 | 1 | ? | optional single element |
| 0 | unbounded | * | zero or more elements, optional |
| n | m | no equivalent | at least n elements, at most m elements. |
| n | unbounded | no equivalent | at least n elements. |
Caution:
A maxOccurs value greater than 1 is not allowed for
elements that contain an xs:all connector, or for elements
contained in an xs:all connector.
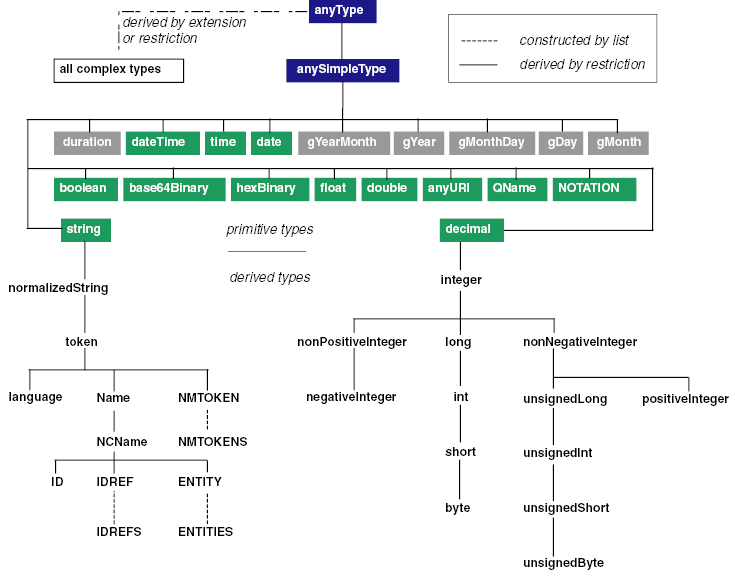
Here is a complete schema definition for the business object
collaboration. In the XML prologue we first define a namespace
prefix for XML Schema:
<?xml version = "1.0" encoding = "UTF-8"?>
<xs:schema xmlns:xs = "http://www.w3.org/2001/XMLSchema">
<xs:element name = "collaboration">
<xs:complexType>
<xs:sequence>
<xs:element name = "name" type = "xs:NMTOKEN"/>
<xs:choice>
<xs:element name = "performedAt">
<xs:complexType>
<xs:all>
<xs:element name = "location" type = "xs:normalizedString"/>
<xs:element name = "time" type = "xs:dateTime"/>
</xs:all>
</xs:complexType>
</xs:element>
<xs:element name = "period">
<xs:complexType>
<xs:sequence>
<xs:element name = "from" type = "xs:date"/>
<xs:element name = "to" type = "xs:date"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:choice>
<xs:element name = "jazzMusician" type = "xs:NMTOKEN" maxOccurs = "unbounded" minOccurs = "2"/>
<xs:element name = "result" type = "xs:NMTOKEN" maxOccurs = "unbounded" minOccurs = "0"/>
</xs:sequence>
<xs:attribute name = "type" use = "required">
<xs:simpleType>
<xs:restriction base = "xs:NMTOKEN">
<xs:enumeration value = "jamSession"/>
<xs:enumeration value = "project"/>
<xs:enumeration value = "band"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
</xs:element>
</xs:schema>
The root element is collaboration. This element has an
attribute type, and a sequence of child elements consisting of the
element name and a choice of the elements performedAt
and period, followed by the elements jazzMusician and
result.
XML Schema gets a bit lengthy at times. Tamino's schema editor can give you a much better overview of the structure of a document, so we shall use this representation for structural overviews.
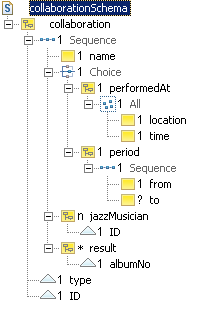
Namespaces were introduced into XML in order to avoid name clashes between different vocabularies. The concept of namespaces allows us, for example, to mix language elements from SVG with those of XHTML, or to process our own XML documents with XSLT. Last but not least, it allows us to define schemas with XML Schema, because by using namespace prefixes we can differentiate between XML Schema tags and our own element names.
Each namespace identifier must be globally unique - usually a URI is
used for that purpose. The definition within XML documents is simple: a
document node is equipped with an xmlns attribute to define the
default namespace. Similarly, additional namespaces can be introduced by
defining namespace prefixes using attributes of the form
xmlns:<prefix>="<uri>".
The scope of such a definition is the node in which it is defined plus all
child elements, unless a child element overrides it with another namespace
declaration. So, if we declare namespaces in the root element of a document
their scope usually is the whole document.
We say that the name of an element is qualified if that element is within the scope of a default namespace declaration, or if its name is specified with a namespace prefix within the scope of the namespace declaration for this prefix. An attribute is qualified if its name is equipped with a namespace prefix.
Now, let's get back to XML Schema. One major advantage of XML Schema over DTDs is that XML Schema fully supports XML namespaces. In order to do so, XML Schema introduces the concept of the target namespace. Each schema file may declare at most one target namespace. All elements defined in this schema file must belong to this namespace. So, a schema file may define either namespace-less elements, or elements belonging to the specified target namespace.
Does this mean that we cannot define multi-namespace schemas? No; the emphasis is here on schema file. We can always compose multi-namespace schemas by importing (see below) other schema files into a schema.
The import statement is used in XML Schema to compose
multi-namespace schemas. A typical example is given below:
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema targetNamespace="http://www.softwareag.com/tamino/doc/examples/models/jazz/encyclopedia"
xmlns="http://www.softwareag.com/tamino/doc/examples/models/jazz/encyclopedia"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:i="http://www.softwareag.com/tamino/doc/examples/models/instruments">
<xs:import namespace="http://www.softwareag.com/tamino/doc/examples/models/instruments"
schemaLocation="instrument.xsd"/>
...
</xs:schema>
import statements are always given at the beginning of a
schema clause. An import statement always specifies a namespace to
import, and may optionally specify an associated schema file with the
schemaLocation attribute. Note that this attribute only gives a
hint to the XML processor about the location of the schema file associated with
the imported namespace. XML processors are not required to use this attribute,
but may use their own logic to find the associated schema. The same is, by the
way, true for the xsi:schemaLocation attribute in document
instances.
Another mechanism to allow for foreign namespaces is the use of
wildcards. A wildcard (i.e. an element or attribute of arbitrary
content) can be declared with the XML Schema elements
<xs:any> or <xs:anyAttribute>. This
allows for the inclusion of elements and attributes from foreign schemas. For
example, sections of XHTML, SVG, RDF and other content could be included into a
document. A typical application would be the description property
in the style asset of our jazz model, where we could use XHTML to
mark up the content.
It is possible to constrain the namespace of the content of such a
wildcard. This is done with the attribute namespace. This
attribute can contain:
either a list of namespace identifiers, each consisting of:
an explicit namespace URI;
the string "##targetNamespace", which denotes the target namespace of the current schema file;
the string "##local", which specifies the namespace of the respective document instance;
or one of the following string values:
the string "##any", which allows any
namespace. This is also the default value of the namespace
attribute. This value is often used together with
processContents="skip";
the string "##other", which stands for any namespace other than the target namespace.
It is also possible to specify how the content of such an element should be processed by the parser:
processContents="strict" causes the parser to check the
wildcard instance for valid content;
processContents="lax" causes the parser to
check the content of the wildcard instance if there is an appropriate
declaration, otherwise the element or attribute can be skipped;
processContents="skip" stops the parser from checking the
wildcard instance for valid content.
Each schema file contains exactly one
<xs:schema> element, which serves as the root element for
the schema definition. Any global element may be used as the root element of a
valid XML instance. The attribute
elementFormDefault of the
xs:schema element specifies whether locally defined
elements in instances of the schema must be qualified with a namespace, either
by using an explicit prefix or via the use of a default namespace in the
instance. Similarly, the attribute
attributeFormDefault of the
xs:schema element specifies whether locally defined
attributes in instances of the schema must be qualified with a namespace,
either explicitly or implicitly as for elements. The
form attribute specified on an element or
attribute definition in the schema overrides the effect of the corresponding
elementFormDefault or
attributeFormDefault setting.
A schema clause can have several attributes, such as in:
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns="http://www.softwareag.com/tamino/doc/examples/models/jazz/encyclopedia"
targetNamespace="http://www.softwareag.com/tamino/doc/examples/models/jazz/encyclopedia"
elementFormDefault="qualified"
attributeFormDefault="unqualified"> ...
</xs:schema>
The default namespace is set identical with the target namespace, and the prefix "xs:" is defined for the XML Schema namespace. This means that we do not have to prefix our own definitions within the schema, but we have to prefix all XML Schema tags with "xs:". We also specify that document instances must use elements in a qualified form, either by setting the default namespace of the document instance root element to "http://www.softwareag.com/tamino/doc/examples/models/jazz/encyclopedia" or by defining and using an appropriate namespace prefix.
In XML Schema it is possible to define elements and attributes both
locally and globally. In contrast, a DTD can define elements only globally, and
attributes only locally. This has always been a problem. For example, with a
DTD it would not be possible to implement our musical instruments (within
jazzMusician) correctly: both saxophone and trombone have a
mouthpiece, but in the case of the saxophone the mouthpiece consists of a body
and a reed, in the case of the trombone it is just the body. Obviously, a
single global definition for mouthpiece is not appropriate. With
XML Schema there is no problem: we simply define mouthpiece
locally, once in the context of trombone, and once in the context
of saxophone.
Sometimes, however, we want to reuse an element
definition. In this case we define the element as a global element, as a direct
child of the xs:schema clause. For example:
<xs:schema ...>
<xs:element name = "jazzMusician">
...
</xs:element>
<xs:element name = "maker" type = "xs:string"/>
</xs:schema>
When we want to reuse this definition we simply use an element reference like this:
<xs:element ref = "maker">
The same technique is possible with attributes when we want to reuse attribute definitions.
By defining a simple or complex datatype as a child
element of the xs:schema element, it can be used as
a global datatype. The name attribute of the
appropriate xs:simpleType or
xs:complexType element must be assigned a value that
can be referred to by other elements in the schema.
Other reuse constructs are named global element groups and named global attribute groups. Here is an example of a named element group:
<xs:group name="nameGroup">
<xs:sequence>
<xs:element name="first" type="xs:token"/>
<xs:element name="middle" type="xs:token" minOccurs="0"/>
<xs:element name="last" type="xs:token"/>
</xs:sequence>
</xs:group>
We can then use this group definition within an element definition:
<xs:element name="name">
<xs:complexType>
<xs:group ref="nameGroup"/>
</xs:complexType>
</xs:element>
Named element groups are also the preferred way to express recursive structures:
<xs:group name="partGroup">
<xs:sequence>
<xs:element name="partNo" type="xs:token"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="part" minOccurs = "0">
<xs:complexType>
<xs:group ref="partGroup"/>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:group>
In this example, the part
element must be optional (minOccurs="0") so that the recursion
does not specify an infinite loop.
In the XML community (and previously in the SGML community) there had always been a heated debate: when to use an element to model an information or data item and when to use an attribute. The question is one of the most frequently asked by developers that are new to XML. The question has been asked since SGML existed; however, we shall see that now, with XML Schema available, the answer has changed.
Let us look at an instance of the collaboration schema
shown above:
<collaboration type="jamSession">
<name>Antibes1960</name>
<performedAt>
<location>Antibes</location>
<time>1960-07-13T20:00:00<time/>
</performedAt>
<jazzMusician>MingusCharles</jazzMusician>
<jazzMusician>DolphyEric</jazzMusician>
<jazzMusician>PowellBud</jazzMusician>
<result>CD53013</result>
</collaboration>
This layout is almost completely based on the use of elements. Only the
property type has been implemented as an attribute.
A completely attribute-based layout could look like the following:
<collaboration
type="jamSession"
name="Antibes1960"
performedAt-location="Antibes"
performedAt-time="1960-07-13T20:00:00"
jazzMusician="MingusCharles DolphyEric PowellBud"
result="CD53013" />
Note that we have lost some structural information. Only by adopting a
(custom) naming pattern were we able to maintain the structural relationship
between performedAt, location and time.
An alternative would be to use only a single attribute such as:
performedAt="Antibes 1960-07-13T20:00:00"
However, we would lose some of the descriptive power of XML and would require a custom parser to process this attribute value.
Also, since an attribute for an element cannot appear more than once, the names of the jazz musicians have been combined here into a single attribute. This is a custom solution and would require a custom parser to process the value. Other custom solutions are possible, for example, the use of separate attributes jazzMusician-1, jazzMusician-2 etc.
Another attribute based approach makes extensive use of ID- and IDREF-attributes. The whole document is "flattened" into elements that have only attributes but no child elements:
<collaboration root="1">
<root id="1"
type="jamSession"
name="Antibes1960"
performedAt="2"
jazzMusician="MingusCharles DolphyEric PowellBud"
result="CD53013" />
<performedAt id="2"
location="Antibes"
time="1960-07-13T20:00:00" />
</collaboration>
In this example the attribute performedAt would have been
defined as an IDREF attribute. It identifies the element with
id="2" which is performedAt.
This technique can be used to represent arbitrary structures as a list of empty elements. Basically, each XML document mimics a small relational database. While this technique offers a consistent approach to all kinds of information structures, it suffers from two drawbacks: such documents are hard to read, and they are awkward to query.
Juxtaposed to this design is to throw out attributes altogether. In our case this would require us to implement the attribute type as an element, which is easy:
<type>jamSession</type>
The truth lies somewhere between these two extremes and largely depends on context and personal taste. Is it essential that the documents should be as short as possible, or is it important to keep the processing logic simple? Is the document only to be used by machines, or is it also to be read be humans? Are the documents machine generated or are they authored by humans, and when yes, with which tools?
Especially when using DTDs for schema definition, there are some strong reasons for using attributes in some cases:
In DTDs, only attributes support the construction of relationships with ID/IDREF keys.
DTDs allow the definition of default and fixed values only for attributes.
A DTD does not allow type definitions (ID, IDREF, NMTOKEN, etc.) for elements.
In DTDs, only attributes of an element form an unordered set. This can sometimes be useful when no predetermined sequence order between information items is required.
Attributes are much easier to access in DOM and SAX.
When authoring document-centric XML in an appropriate XML editor, it is often more convenient to use attributes for annotating text. The attributes do not litter the running text, and spell checking is only applied to elements.
However, with XML Schema the reasons 1-4 no longer apply:
Elements can now be defined as ID or IDREF.
A wide range of datatypes is available for elements and attributes.
Elements can now have default or fixed values.
The all connector allows unordered sequences of
elements.
This gives elements a certain advantage:
Elements can repeat. This is not possible with attributes.
It is possible to define choices (alternatives) between elements. This is not possible with attributes.
Elements are easy to extend when necessary by adding child elements or attributes.
Attributes of an element always form an unordered set, so it is not possible to establish a sequence order across attributes.
Elements can contain whitespace and delimiters; whitespace handling can be specified at the element level.
Elements are easier to search for in search engines.
When editing data-centric XML in an XML editor, storing content in attributes makes the editing process more difficult: often extra keystrokes or mouse actions are required to view the attributes.
These are strong reasons for using elements. We would suggest using attributes to describe annotation only (such as language identifier, element author, element version, element ID, etc.), and using elements to represent content. However, what is content and what is metadata can depend on the context. A good definition to distinguish content from annotation is based on a suggestion by Elliot Kimber: If I removed this data, would my understanding of or my ability to comprehend the content change? If the answer is no, it's annotation, if the answer is yes, it's content.