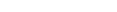
We now transform this informal description into a more formal conceptual model.
In traditional conceptual modeling (such as Entity Relationship Diagrams
or Object Role Modeling), nouns would end up as entities (or
attributes) and verbs would end up as relationships. However, in the
context of modern information systems this approach can create more problems
than it solves. For example: what should we do with
Collaboration-collaborate or with reviews-Review?
Should we use the verb or the noun? Which represents this concept better: an
entity or a relationship?
This ambiguity is one reason for taking a different approach and removing the artificial separation between entity and relationship: in our model, both nouns and verbs become Assets. What is new here is that the classic relationships are treated on the same level as entities: as things. This syntactical reification (reify = to make into a thing) leads to a considerable simplification of the conceptual model, and has some other advantages, too. In particular, it results in models that are easy to transform into XML.
When modeling nouns and verbs as assets, there are two notable exceptions:
The verb "has" indicates either that an asset is attributed with a property, as in:
A person has a name and a birth date.
or that an asset aggregates other assets, as in:
A saxophone has a mouthpiece.
The expression "is a" indicates that an asset acquires properties from another asset, as in:
A jazz musician is a person.
The noun on the left hand side (jazz musician) is usually a more specific term; the noun on the right hand side is usually a more general term (person).
Let us see how we can model a rather complex sentence like:
A jam session is performed at a location and at a particular time.
A possible resolution is to model jam_session,
performance, and location as assets. The asset
performance has a qualifying property: time. Usually
we use the noun form (performance) of a verb
(performed) to name the corresponding asset.
In the most general sense, an asset is anything we can talk about. But for the purpose of modeling we want to categorize the things we can talk about into assets and properties.
In our informal description, properties are usually indicated
by the verb "has": A saxophone has a
color.
Anything which plays a certain role in the context of our business is definitely an asset.
Tip:
In many cases the distinction between a property and an asset can be
made using a simple rule: A property can belong to an asset, but an asset
cannot belong to a property. For example: a color cannot have a
saxophone.
However, the distinction between both is not always so easy, and depends in some cases on the context. Take for example:
An instrument has a maker.
A saxophone has a mouthpiece.
In the context of our small knowledge base, maker and
mouthpiece do not play any particular role. So it is acceptable to
model them as properties of instrument or saxophone.
However, in the context of a supply chain for musical instruments,
maker and mouthpiece would certainly play a role (as
manufacturer and product), so we would have to model them as assets.
An item that is only connected to a single asset (like
maker) is always a candidate for becoming a property. In contrast,
an item that also has other relationships must be modeled as an asset. Take for
example:
A project can result in an album.
Here, album could be modeled as a property of
project, if we had not specified:
An album is reviewed by critics.
In contrast to classic Entity Relationship Diagrams, we allow
composite properties. Above, we modeled performance and
location (for example, Cotton Club, Savoy Ballroom, or
Centralstation) as separate assets. But if these locations play no particular
role in our business case, we can just use a composite property to represent
these items.
For
A jam session is performed at a location and at a particular time.
we might define a property performed_at that includes the
sub-properties location and time.
Similarly, the property name of asset person
may include the sub-properties first, middle, and
last. A mouthpiece may have sub-properties
body and reed. This technique of composite (or
nested) properties allows us to arrive at very compact models and – not
surprisingly – results in very appropriate XML representations.
We are now ready to introduce a more formal notation for assets.
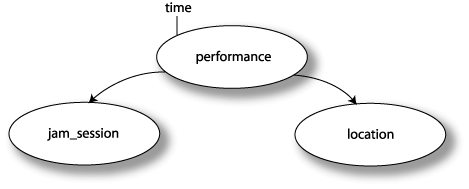
The figure below shows the graphic representation of an asset. The first line contains the asset name. This is followed by a key definition (we discuss this later), a list of properties, and a list of constraints (also discussed later). The optional display label at the top of the asset is used when the names of asset instances should differ from the asset name. In this case the display label shows the possible names of asset instances. When an asset does not have instances (i.e. when the asset is abstract) the display label is grayed out.
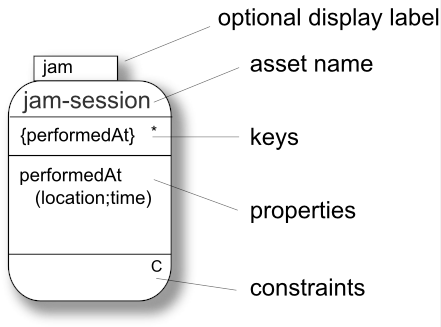
We introduce the following notation for properties:
| Syntax | Description | Example |
|---|---|---|
| prop | An atomic component without further structure. |
birthDate |
| (...) | A property particle, i.e. a structure consisting of several sub-properties. The parentheses contain nested expressions consisting of the following structures: | See following rows. |
| (sub,...,sub) | Sequence (ordered list). |
name(first, middle?,last) Here, we require that the sub-properties of |
| (sub&...&sub) | Bag (unordered list). |
reed(maker&grade) Here, we do not prescribe a particular sequence in which
|
| (sub|...|sub) | Choice (alternative). |
(period(from,to) | performedAt(location&time)) A property is either a |
Both properties and particles can be suffixed with one of the following modifiers:
| Syntax | Description | Example |
|---|---|---|
| (no modifier) | mandatory [1..1] |
last A last name is always required. |
| prop? | optional [0..1] |
middle? Not everybody has a middle name, so we make this property optional. |
| prop+ | repeated [1..n] |
track+ An album has one or several tracks. |
| prop* | optional and repeated [0..n] |
album* An arbitrary number of albums. |
| prop[n..m] | a minimum of n occurrences and a maximum of m occurrences with 0 <= n <= m |
track[1..25] The number of tracks is restricted to 25 at most. |
The following notation allows recursively structured properties to be defined:
| Syntax | Description | Example |
|---|---|---|
| label{...label...} | A label defines a reference point to the expression within the curly braces. Later occurrences of the label are substituted with this expression. In particular, labels allow recursive structures to be defined. |
r{part(partNo,r*)}
specifies a tree-like structure of parts. Note that the *-modifier ensures that the recursive structure is finite. |
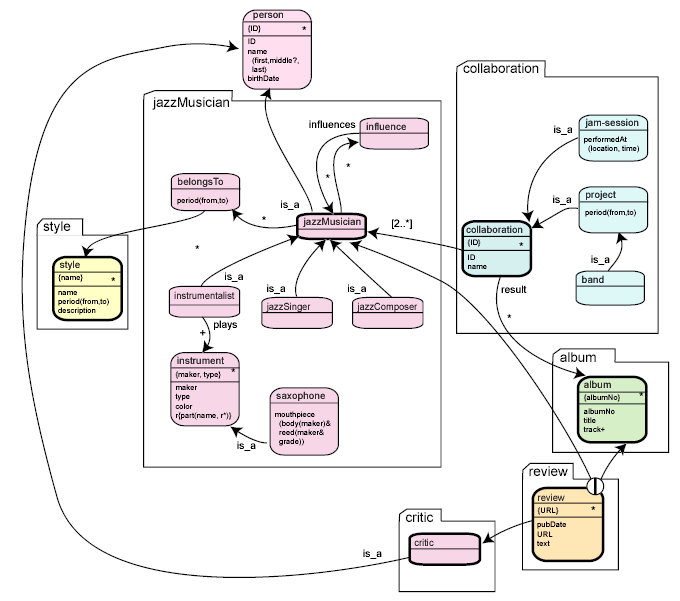
Given this notation, we now define our complete model. We have added a few more properties.
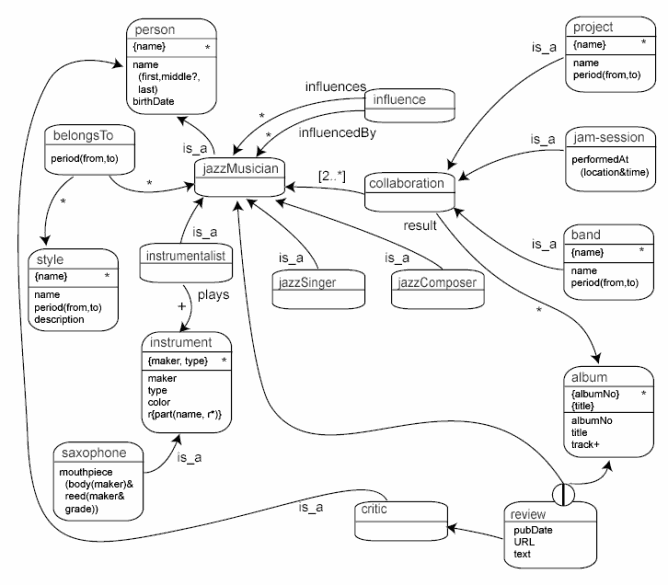
Assets are connected via directed arcs. You should not misinterpret these arcs as classic relationships in the sense of Entity Relationship Diagrams. (Remember that relationships are assets too.) For this reason, arcs do not have names; however, the origin of an arc may be decorated with a role name.
Similar to the notation used for properties, we use XML syntax to denote the cardinality of each arc:
| + | 1..n |
| * | 0..n |
| ? | 0..1 |
| [n..m] | n..m (0<= n <= m) |
Caution:
Avoid situations in which the constraints of the
model can never be satisfied, for example:
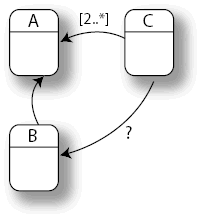
Here, each instance of asset type C requires the existence of at least two instances of asset type A and at most one instance of asset type B. This is in contradiction with the implicit constraint between B and A which dictates a 1:1 relation between both.
Important:
Therefore, we should always make sure that the intersection of
all constraint cardinalities used within a cyclic structure is not empty. This
is always the case when we only use the first three constraint types: their
intersection contains always 1..1.
In addition to constraints, we may attribute the origin of each arc with
a role name. Take for example the asset influence. This
asset has two arcs that connect it with jazzMusician – one in the
role of the influenced musician and one in the role of the musician who has
influenced the first.
You will also have noticed that we have represented the
is_a relationships not as assets but merely as arcs, the origin of
the arc being decorated with the role name is_a. This makes it
easier to identify such inheritance and classification relationships. In
contrast to normal arcs, inheritance arcs may only be attributed with the
"?" modifier indicating optional inheritance.
The has relationship (if it does not result in a property)
results in a simple arc, too, pointing from the asset that "has"
to the asset which is "had". This is, for example, the case for
the relationship between jazzMusician and
collaboration. By using the noun form (collaboration) of
"collaborates", the sentence
A jazz musician collaborates with other jazz musicians.
is interpreted as
A collaboration has jazz musicians.
a relationship which is modeled with a simple arc.
A further design decision is to downgrade "plays" and "results_in" in
An instrumentalist plays one or several instruments.
and
A project can result in an album.
We replace these relationships with the simple "has" relationship, too (i.e. "plays" and "can result" do not become assets). In order to retain the semantic information, we use "plays" and "result" as role names. This is not always easy to decide. If, for example, we had the relationship
An instrumentalist owns one or several instruments.
then we would probably model "owns" as a
separate asset ownership because this asset could become the
subject of a new business relation:
After four weeks ownership is transferred to the pawn broker.
The asset review shows another interesting construct: a
cluster. A cluster is used to denote alternatives, and is represented by a
circle containing the choice operator. In our case the cluster says that a
review relates either to an album or to a jazz musician. A cluster is a
union of disjoint asset types. Clusters are possible for normal arcs and
inheritance arcs.
After we have obtained a first draft of our model, we should normalize it. Unlike relational technology, XML allows a physical data format that very closely follows the structures of the actual business data – there is no need to break complex information items into a multitude of "flat" tables. We shall find that an XML document can represent a conceptual entity almost unmodified.
This does not mean that no normalization is required. We still must make sure that our information model does not have redundancies, and that we end up with an implementation that is easy to maintain and consistently matches the "real world" relationships between information items. We make sure that:
Asset types are primitive, i.e. their properties do not
contain assets that could be modeled as independent asset types. For example,
the asset type album must not embed data from
jazzMusician.
Asset types are minimal, i.e. they do not contain redundant
properties, meaning none of their properties can be derived from other
properties. For example, the asset type person must not contain a
property age as this can be derived from
birthDate.
Asset types must be complete, i.e. other assets contained in the real world scenario can be derived from the defined asset types. Our example is not complete, as we made no provision for solo albums. Our model contains only albums that are the result of a collaboration. Also, albums usually contain information about which musician played which instrument. This is not covered by our model.
Asset types must not be redundant, i.e. it must not
be possible to derive any of the defined asset types from other asset types. In
our example, we have a redundant asset. A band is a kind of project - the main
difference is that it exists over a longer period of time and probably produces
more albums. We could reflect this situation in our model by removing the
properties name and period(from,to) from asset
band, and by routing the is_a arc from
band to project instead of
collaboration.
All asset types must have a unique meaning.
Assets should have a key. Keys must be minimal, i.e. they
must consist of the smallest set of properties that can uniquely identify an
instance. In our example, not every asset has a key (for example,
belongsTo, influence, collaboration and
review don't have a key). We should introduce suitable keys for
these assets. jazzMusician, instrumentalist,
jazzSinger, jazzComposer, and critic do
not need their own key, because they inherit one from person. If
an asset type does not have suitable properties that can act as keys, we can
easily equip them with some kind of a unique property (for example by
generating a UUID for each instance).
While the steps discussed above already result in a pretty robust model, there is one more thing we can do. Assets finally result in XML elements or documents, and can thus be subject to transformations (for example, via an XSLT stylesheet). To make the keys robust against such transformations, we should make sure that each asset is in Partitioned Normal Form (PNF).
An asset type or property is in Partitioned Normal Form (PNF) if the atomic properties of an asset constitute a key of the asset and all non-atomic properties and sub-properties are in Partitioned Normal Form themselves.
Or, in other words: All complex structures in the model (assets and complex properties) must have atomic child nodes that can act as a key.
In our example, the following asset types are not in PNF:
person, because the key
name(first,middle?,last) is a composite. A solution would be to
introduce a personal ID. Here, we opt to introduce an atomic ID composed from
last name, middle name and first name, such as MingusCharles.
jamSession, because the key performedAt(time,
location) is a composite. Here we opt for a different solution. We
resolve the property performedAt into two independent properties:
time and location. These two properties are atomic
and can thus constitute a multi-field primary key that conforms to PNF.
saxophone, because the composite property
mouthpiece is not in PNF (it has no atomic property which could
act as key). Here we should rather remove the property mouthpiece and use
mouthpiece_body and reed directly as parts of
saxophone (because mouthpiece is in fact not a single
physical entity).
In particular, if we plan to store assets in relational databases, PNF is essential. Relational technology requires fragmenting complex structures into flat relational tables. Keys that span complex structures would be lost during such a transformation to First Normal Form (1NF).
Business objects are assets that play a prominent role in our scenario. In order to be able to identify a business object, we must not only have an idea about the structure of the information, but also what it will be used for.
In our example, all jazzMusician asset types,
style, all collaboration asset types,
album, review, and critic could be
business object classes. Jazz musicians are clearly the most important topic in
our knowledge base, but similarly important are style and the
various collaborations. album could play a separate role when we
connect our knowledge base with a mail order system. And review is
probably an external resource to which we have to link via URL.
On the other hand, we made the decision not to model
instrument as a separate business object. We are only interested
here in the instrument that a given musician plays; we do not plan to set up a
knowledge base about musical instruments as such. Consequently, we incorporate
instrument and its subtypes into the jazzMusician
business object.
We then group the remaining assets around the assets designated as business objects. Here, we have shown this by demarcating each business object with a labeled box. We use a bold outline for the identifying asset of each business object.
However, there is one constraint that we must enforce when constructing business objects from assets:
Important:
Starting from the identifying asset of a business object, we
must be able to reach any asset belonging to that business object by following
the arcs in the indicated direction.
This constraint allows us to interpret each business object as an aggregation, and later allows us to easily implement the business objects in hierarchical XML documents.
When we check this constraint for our model, we encounter two problems:
From the assets belongsTo and influence, both arrows
lead to asset jazzMusician. This is bad, because when starting at
jazzMusician we cannot reach belongsTo and
influence.
In order to solve these problems, we simply reverse one arc for each of
the assets belongsTo and influence. This results in a
slightly different interpretation; we are now saying:
A jazzMusician has a "belonging" to a style.
and
A jazzMusician has influence.
By doing so, we have completed the former syntactic reification of
relationships with a semantic reification –
"belonging" and
"influence" have become true assets of
jazzMusician.
Caution:
When we reverse an arc, any cardinality constraint of that arc
becomes invalid. Therefore, we always decorate reversed arcs with an asterisk
(*) to indicate that there are no cardinality constraints for that arc. By
doing so, however, we may lose some structural information.
In addition, we have taken the opportunity to fix some problems with
keys. collaboration and review definitely need keys,
because they are identifying assets of business objects. The identifying asset
of a business object must always have a key, because otherwise
instances of business object classes could become inaccessible. We have
equipped collaboration with a new property, namely
ID, which we use as a key. The reason is that the property
name may not be unique.
To prepare the model for implementation with XML, we resolve all
is_a relations. Because DTDs and XML Schema do not really support
inheritance, we have to find solutions for the various is_a
relations. (DTDs do not have an inheritance mechanism at all; XML Schema cannot
handle multiple inheritance.) We have the following options:
Separate implementation of parent and child. For example, we could
implement separate person documents which would constitute a
generic person data base. jazzMusician and critic
instances would have to refer to these person instances.
Inclusion of parent properties in the child class. For example, we
could include the properties of person into the asset types
jazzMusician and critic.
Inclusion of child properties in the parent class. The child type
would be stored in an extra property in the parent instance. For example, we
could represent instrumentalist, jazzSinger, and
jazzComposer in a generic document type jazzMusician
and indicate the type of musician in a special property. However, we would
suffer some information loss: because jazz singers and composers do not
necessarily play an instrument, we would have to use the *-cardinality for the
connection to instrument, and not the +-cardinality. The
constraint that a instrumentalist must play at least one instrument would be
lost. We would have to represent this through an extra constraint that depends
on the type of musician. We shall later see how to formulate this sort of
constraint.
As an further possibility, the is_a relations could be
implemented similarly to an aggregation that would, for example, allow a jazz
musician to be a composer, a singer, an instrumentalist or any combination of
these. The problem of cardinality (* or +) would not appear if the instruments
are only allowed in the context of the instrumentalist. This would be possible
using the xs:all element of XML Schema, whereby
jazzMusician could be an element whose schema definition contains
an xs:all element that in turn contains elements
Instrumentalist, Composer
and Singer.
After applying these operations, our model could look like this:
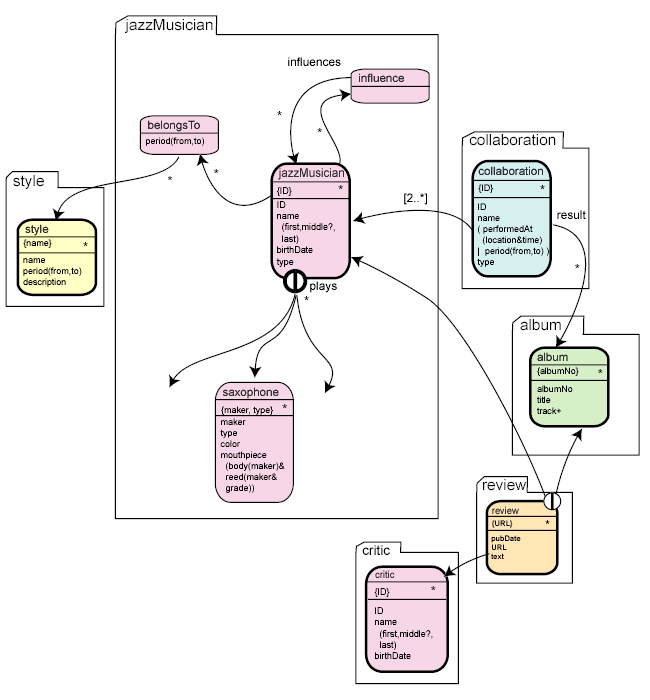
Here we have resolved the generic instrument asset into
single instrument types such as saxophone, guitar,
trombone, etc. The different instruments are just too different to
be represented in one generic type. The consequence is that the asset type
instrumentalist has a connection to all of these types. This is
done with a cluster, a construct already discussed above.
Structurally, our conceptual model is now complete. In later chapters we discuss how additional constraints and operations can be defined. But before we do so, we discuss how to derive XML schemas from the conceptual model. We give a short introduction to XML Schema in the next section (Introduction to XML Schema).
In some cases it is necessary to reengineer existing relational schemas. This is especially the case if we plan to convert existing relational data into XML or to map relational structures onto XML structures. If the original conceptual model is not available, we should try to reconstruct such a model from the relational schemas. This usually results in XML data structures of higher quality than the naive approach of mapping relational data directly onto XML.
Transforming relational schemas into an Asset Oriented Model is almost trivial:
Each table is mapped to an asset.
Each table column (except foreign keys) is mapped to an asset property.
Each corresponding foreign/primary key pair is represented as an arc pointing from the owner of the foreign key to the owner of the primary key.
The following is a classical example for a relational schema:
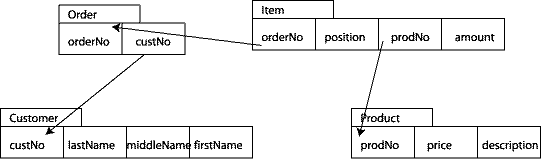
By applying the above rules, we arrive at the following asset-oriented model:
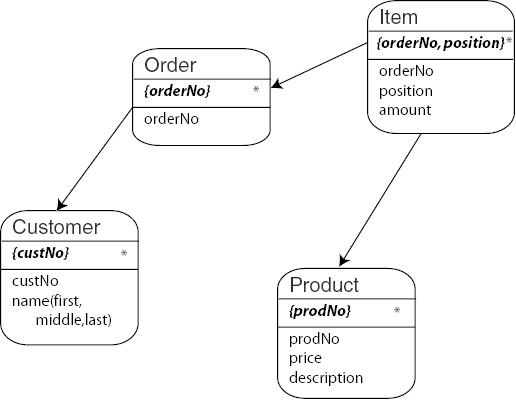
Note that we cheated a bit here. We regrouped the three columns
lastName, middleName, and firstName into
a complex property called name. Relational schemas flatten complex
data structures such as name (to achieve First Normal Form) and
thereby lose structural information. Regrouping of such columns, however, needs
an understanding of the semantics of the model and cannot be prescribed by
simple rules.
In the next step, we determine our business objects and group the assets around them, as discussed above in the section Determining business objects.
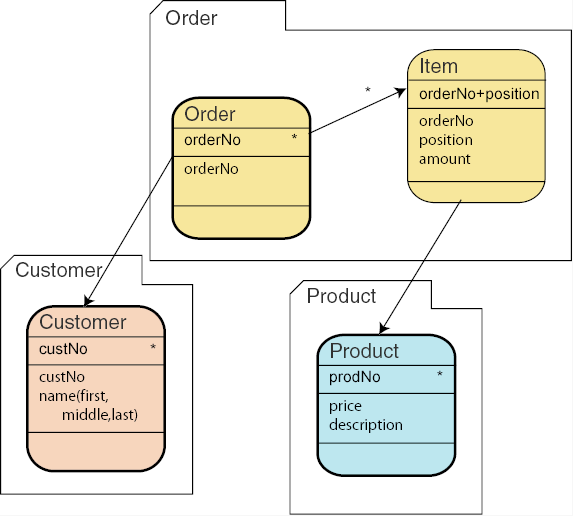
We have determined three business objects or business documents:
Customer, Order and Product, and have
grouped Item together with Order. Because the asset
Order is the identifying asset of the business object
Order we have reversed the arc between Order and
Item to indicate that Item belongs to
Order. Because we reversed this arc, we decorated it with an
asterisk (see the section Determining business
objects above). This makes sense: an order can have
several items.
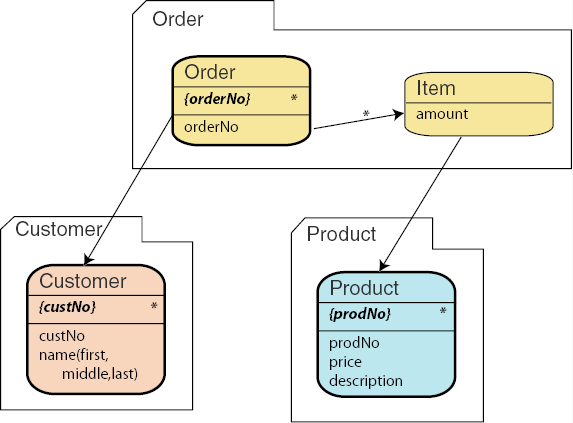
Using this technique, we finally arrive at well-structured XML documents
representing not flat tables but complex business objects. One interesting
detail is that with an implementation in XML the property position
of asset Item becomes redundant. Sequences of XML elements are
well ordered; rows in a relational table, in contrast, are not, and therefore
require an attribute such as position in order to establish an
ordered sequence. And, of course, orderNo in asset
Item also becomes redundant because it is already contained in
asset Order.
So far, we have not discussed how models are identified. A simple model
name would be not a good choice because it probably would not be unique within
a global context. A better idea is to use a URI as model identification, for
example, a URI based on a domain name. In our case we could choose
http://www.softwareag.com/tamino/doc/examples/models/jazz/encyclopedia
for the jazz model, and
http://www.softwareag.com/tamino/doc/examples/models/order/reengineered
for the order model. This technique allows us to identify models uniquely. At
the same time, such an identifier defines a default namespace for the
respective model. Because asset names are unique within a model, the
combination of namespace and local name identifies each asset uniquely within a
global context.
Let us assume that we want to separate our jazz encyclopedia model into
two models: one for the core jazz encyclopedia, and another model in which we
define musical instruments. The idea behind this is that we could reuse the
model for musical instruments in other contexts, too, for example in a
knowledge base about classical music. We would establish a model for musical
instruments under a separate namespace, for example, under
http://www.softwareag.com/tamino/doc/examples/models/instruments.
Our original jazz encyclopedia model could be reconstructed by merging the now
instrument-less jazz encyclopedia model with the new instrument model.
And this is where the concept of namespaces really becomes important:
when we start to merge models. Let us assume that we want to create a new model
for a record shop where we want to sell jazz CDs on the Web. Instead of
defining everything from scratch, we import the jazz encyclopedia model (which
already imports the instrument model) and the order model. We then create a new
asset, namely CD, which inherits its properties from both the
album asset in the jazz model and the product asset
in the order model.
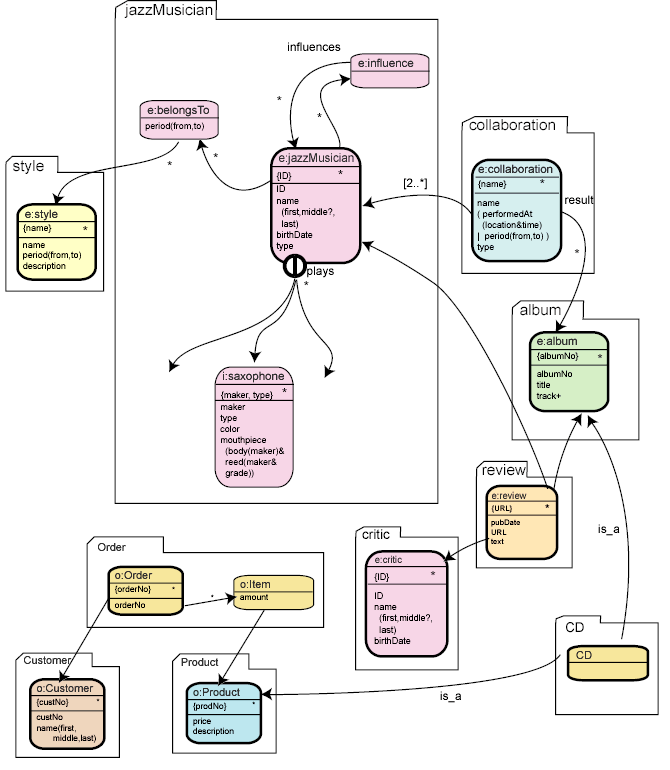
| Model name: | Record Shop |
| Namespaces: | http://www.softwareag.com/tamino/doc/examples/models/jazz/shop |
| e=http://www.softwareag.com/tamino/doc/examples/models/jazz/encyclopedia | |
| i=http://www.softwareag.com/tamino/doc/examples/models/instruments | |
| o=http://www.softwareag.com/tamino/doc/examples/models/order/reengineered |
What happened here? The new model was defined with the default namespace
http://www.softwareag.com/tamino/doc/examples/models/jazz/shop,
which also identifies it uniquely. In addition, the model declares three
namespace prefixes. The prefix "e" is assigned to
the namespace of the jazz model, the prefix "i" is
assigned to the namespace of the instrument model, and the prefix
"o" is assigned to the namespace of the order model.
All names of the assets imported from the jazz model are prefixed with
"e:", all names of the assets imported from the
instrument model are prefixed with "i:", and all
names of the assets imported from the order model are prefixed with
"o:".
What remains to do is to resolve the is_a relationships for
the asset CD. This results in the following asset definition:
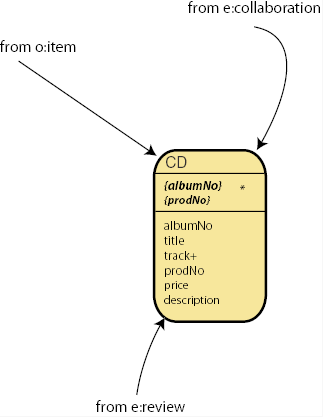
Here, we have inherited properties across namespaces. The properties
from both e:album and o:Product are incorporated into
asset CD and belong now to the namespace of the record shop
model.
What if we have name clashes between the inherited properties? Well, this problem is not specific to namespaces but can also occur during multiple inheritance in a single namespace. The conflict is resolved by combining the conflicting properties by intersection. If there are incompatible property definitions, the intersection is empty, and the property is discarded. Of course, it is always possible to override inherited properties locally.