Under High Availability we understand an environment with engineered redundancy which, if any one component fails, guarantees the integrity of the system as a whole. To achieve high availability, EntireX uses existing third-party clustering technology.
This document provides an introduction to clustering technology and describes how to set up in EntireX the redundant RPC servers and brokers you will need to achieve high availability. It covers the following topics:
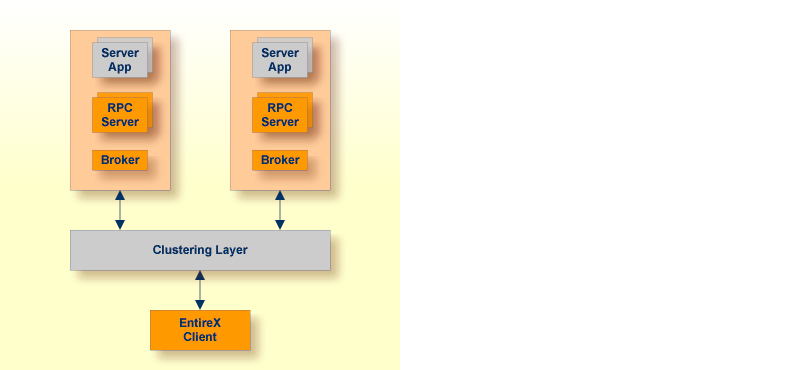
This is achieved by adding redundancy to the system, so that failure of a component does not mean failure of the entire system. Virtual IP addressing allows you to have several redundant systems to eliminate single points of failures that can be combined with external load balancing solution. In the picture below, you can imagine that there are several hosts, each host with one Broker, multiple RPC servers and server applications.
Note:
This solution applies to simple synchronous scenarios only; see Client Considerations for details and prerequisites.
If one Broker fails, goes down or the host goes down, the current call will fail but the client will notice that and resend the call. The call will then automatically routed to a different Broker and can be processed there.
EntireX provides a variety of monitoring, logging and tracing facilities:
Command Central offers live monitoring of EntireX Broker and RPC servers
CIS (Command and Info Services) allows you to retrieve a wide range of live information from an EntireX Broker
Logs at several different log levels allow detailed analysis
The scenario you choose depends on the platform where your clustering environment is set up, typically the environment where your broker is running: