Character-Based Similarity Functions
Levenshtein
The Levenshtein distance (or edit distance) between two strings is the minimum number of single-character edit operations (insertion, deletion, or replacement) required to change one string to the other.
Levenshtein Example
The Levenshtein distance between “filip” and “philipp” is 3, because the change from “filip” to “philipp” is possible with these three edits:

Replace 'p' for 'f' = pilip
Insert h into philip = philip
Insert 'p' to philip = philipp
The maximum Levenshtein distance between two strings t 1 and t 2 (if they are completely different) is:
For example, transforming “xxx” into “yyyy” requires three replacements and one insertion. That is, a total of 4 edits.
The Levenshtein similarity s between two strings t 1 and t 2 can be defined as:
Where, levenshteinDist(s 1, s 2 ) is the Levenshtein distance between s 1 and s 2. Therefore, the similarity is measured with the values [0,1].
Damerau-Levenshtein
The Damerau-Levenshtein Algorithm is an extension of the Levenshtein algorithm. In addition to the edit operations in Levenshtein, adjacent character swaps count as a single operation instead of, for example, two operations (delete and insert). This is because adjacent character swaps are the most common data entry errors.
Damerau-Levenshtein Example
The Levenshtein distance between “Peter” and “Peetr” is 2 because the change from Peter to Peetr is possible only with two edits:
Deletion of 't'= Peer
Insertion of 't' = Peetr
The Damerau-Levenshtein algorithm requires just a single operation to arrive at the same result:
Swap the position of 't' and 'e' in ‘Peter’ = Peetr
Jaro
The Jaro similarity compares two strings s 1 and s 2 by first identifying the characters common to both strings. Two characters are said to be common to s 1 and s 2 if they are identical, and if their positions within the two strings do not differ by more than half the length of the shorter string. When all common characters have been identified, both s 1 and s 2 are traversed sequentially, and we determine the number t of transpositions of common characters. A transposition occurs when the ith common character of s 1 is not equal to the ith common character of s 2.
Given the set of common characters c and the number of transpositions t, the Jaro similarity is computed as:
Jaro Example
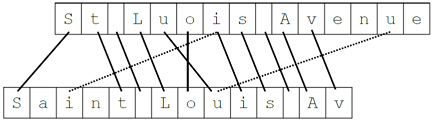
Comparing the strings “St Luois Avenue" and “Saint Louis Av":
Length of string 1 is |
s 1| = 15.
Length of string 2 is |
s 2| = 14.
String 2, with length 14, is the shorter one.
The common characters should be within the range of 14/2 = 7.
There are thirteen identical characters between the two strings:
Each character is counted only once. So the repetitions (dotted lines in the illustration above) can be ignored, and only eleven common characters can be taken into account.
Character transpositions are easily recognized by the crossed lines in the illustration above, and there is only one transposition.
Therefore, the Jaro similarity for the strings “St Luois Avenue" and “Saint Louis Av" is:
Jaro-Winkler
Winkler's extension of the Jaro similarity, called the Jaro-Winkler similarity, gives a higher score to strings that share a common prefix.
Given two strings s1 and s2 with a common prefix p, the Jaro-Winkler similarity is computed as:
Where, f is a constant scaling factor for how much the similarity is corrected upwards based on the common prefix p. For example f = 0.1.
Sift3
The Sift3 similarity is a heuristic similar to Jaro. For each character in a string, Sift3 similarity tries to find a matching character in the other string. It not only considers the same index position, but also considers few characters placed later in the string. The parameter maxOffset configures how many characters that are placed later must be considered.
Sift3 is a good similarity approximation that performs quicker computations than Levenshtein or Damerau-Levenshtein. As a character-based algorithm it is sensitive to whole word swaps, but it also handles swaps, deletions, and insertions of small character groups effectively. By using a larger maxOffset, it also handles larger gaps.
The final score s between two strings t 1 and t 2 is:
That is, the number of matching characters is related to the averaged length of the two strings.
Sift3 Example
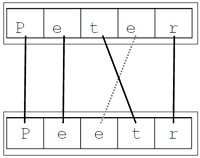
Comparing the strings “Peter” and “Peetr” with a maxOffset of 1, Sift3 would match ‘P’ at index 0, and ‘e’ at index 1. For the character ‘t’ in “Peter,” Sift3 looks at position 2 in “Peetr”. If it does not find a match in position 2, it advances to compare position 3 and 4, and position 4 and 3. Both ‘e’ and ‘t’ would match in this case.
Sift3 processing of “Peter” to “Peetr” involves the following steps:
1. Checking characters in position 0 and 0.
They are the same, so the counter is incremented to 1.
2. Checking characters in position 1 and 1.
They are the same, so the counter is incremented to 2.
3. Checking characters on position 2 and 2.
They are not the same. So:
a. The maxOffset is used to look 1 character ahead to find a match. The algorithm finds the matching characters ‘e’. The offset of 1, which was used to look ahead and find the match, is saved for the next iteration.
4. Checking characters in position 4 = 3 + 1(offset) and 3.
No similarity is found, so the offset of the pointer is reset to 0.
5. After resetting the offset to 0, characters in position 3 in each string is checked. ‘e’ and ‘t’ do not match.
a. The maxOffset is used to checks one character later in string 1 “Peter”.
b. ‘r’ and ‘t’ did not match, so Sift3 looks one character later in string 2 “Peetr”, but ‘e’ and ‘r’ also don’t match.
6. The counter goes up to position 4. The algorithm matches ‘r’ and ‘r’ and terminates the check because at least one string has ended.
7. To compute a similarity score, Sift3 counts the number of characters that match. Applying the following computation formula, the algorithm returns a similarity score of 0.8 with a given maxOffset of 1. There are four matching characters related to an average string length of 5.
Similarly, if the strings, “St Luois Avenue” and “Saint Louis Av” are compared, there are 10 matching characters. The average string length is 14.5. So the final similarity score is 10/14.5 = 0.69.
Needleman-Wunsch
The Needleman-Wunsch similarity can be seen as a generalization of the classic Levenshtein algorithm. Needleman-Wunsch similarity is also based on the principle of edit operations (insert, delete, replace).
Needleman-Wunsch finds the optimal global alignment of two strings by finding the sequence of edit operations with the lowest costs. This is similar to Levenshtein. However, while Levenshtein defines fixed costs for the insert, delete, and replace operations (usually +1), Needleman-Wunsch allows more flexible cost definitions.
An arbitrary function can be used to define the cost of a replace operation. For example, this function may take (phonetic) character similarities into account. The insert and delete operations are interpreted as a gap in either one or the other string, and Needleman-Wunsch allows a constant to be specified as the gap cost.
If s 1 and s 2 are two input strings of length n and m. s 1 [i] should be the ith character in string s 1. Consider the following substitution cost function. It defines a cost of +2 if the characters do not match, and a cost of +1 if they have similarities:
We could define two characters as phonetically similar (~) if they are in the same group: (d, t), (g, j), (l, r), (m, n), (b, p, v), (a, e, i, o, u)
Needleman-Wunsch Example
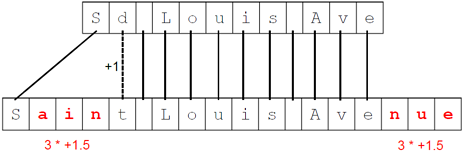
Comparing the two strings “Sd Louis Ave” and “Saint Louis Avenue” with a gap cost of g = 1.5, the strings would be aligned as follows:
The solid lines in the illustration represent exact matches between characters which have a cost of ±0. Each of the character sequences marked in red form a gap of length 3. The overall costs for the optimal alignment (omitting zero values for matching characters) is:
(3 * 1.5) + (3 * 1.5) + 1 = 10
Considering the minimum and maximum costs possible for the two strings. This cost value is used to produce a normalized similarity score value between 0.0 and 1.0. The final score depends on the length of both input strings, the gap costs, as well as the minimum and maximum possible substitution costs. The normalized Needleman-Wunsch similarity score between “Sd Louis Ave” and “Saint Louis Avenue” is ~0.7.
Smith-Waterman
Smith-Waterman extends the functionality of the Needleman-Wunsch algorithm. While Needleman-Wunsch finds the optimal global alignment between two strings, Smith Waterman finds the optimal local alignment. In other words, the Smith-Waterman algorithm finds sub-strings with the best match (sub-strings with the highest score).
Unlike Needleman-Wunsch, Smith-Waterman does not need a cost function, but requires a scoring function. Without the scoring function, sub-strings of 0 length would always have the lowest costs. In addition, it allows leading and trailing gaps in the alignment of the two strings if the trailing gap improves the costs. The values of the cost functions need to be positive for character matches, and need to be negative for dissimilarities in order to model a penalty.
Smith-Waterman Example
Consider the following scoring function as an example:
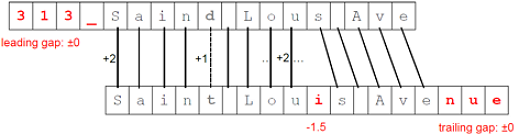
Using a gap score or penalty of g = -1.5 and ~ defined as in the example for
Needleman-Wunsch, the two strings “313 Saind Lous Ave” and “Saint Louis Avenue” would be aligned as:
The overall score for the optimal alignment is:
13 * (+2) + 1 * (+1) + 1 * (-0.5) = 26.5
13 characters in the optimal alignment match exactly, one pair is similar (d and t), and there is one gap in the middle (missing i).
Smith-Waterman-Gotoh
Gotoh extends the Smith-Waterman algorithm, incorporating affine gaps. Instead of the constant gap costs or scores (as in Smith-Waterman and Needleman-Wunsch), Smith-Waterman-Gotoh uses a gap score function. The gap score function allows for a more sophisticated modeling of the influence of a gap. Although any mathematical function is possible, usually an affine or linear function is used. The gap function defines the costs for opening and extending a gap.
Consider k to be the length of the gap, c o the cost for opening a gap, and c e the cost for extending a gap by one character. The affine gap functions would then take the following form:
For example:
Smith-Waterman-Gotoh Example
If we apply the gap function
to the two strings “313 Saind Lous Ave” and “Saint Louis Avenue,” the overall score is computed as:
13 * (+2) + 1 * (+1) + 1 * (-3) = 24
Here, there is only a single gap of length 1 which costs -3 to open. If this gap were 3 characters long, the gap costs would increase to -3 + 2 * -0.5 = -4.