Keypoints about High Availability and Disaster Recovery (HADR) solution
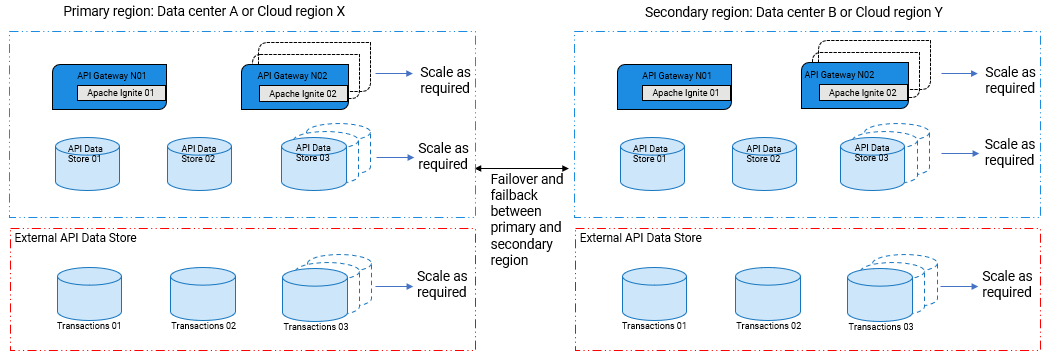
The architecture of HADR is as follows:
The keypoints about HADR solution is as follows:

Each data center or the cloud region hosts an independent cluster of its own.
Primary data center serves the traffic and is exposed to the client and you must turn on the secondary data center only when the primary data center goes down due to a disaster.
The recovery process during disaster recovery is categorized into two stages:
Failover. The failover operation is the process of switching data from a primary data center to a secondary data center.
Failback. The failback operation is the process of returning data from a secondary data center to a primary data center.
HADR solution can be set up using
Cold standby mode or
Warm standby mode. The following table explains the difference between both the modes.
Failover Mode | RTO (approximately) | RPO (customizable) | Description |
Cold standby mode | 30 minutes to 1 hour | >=15 minutes | Secondary data center remains switched off until failover operation. Hence, this approach saves cost. Backup scheduler is set to meet the RPO definition. |
Warm standby mode | 15 minutes | >=15 minutes | API Data Store is operational in the secondary data center. Backup scheduler is set to meet the RPO definition. As API Data Store is operational and data is restored from the latest backup snapshots in secondary data center, this approach reduces RTO, but the cost is higher compared to Cold standby mode. |
Before performing the failover process:
In cold standby mode:
Install
API Gateway in the secondary data center and ensure that the fix upgrades of the primary data center is applied to the secondary data center too.
Run the backup scripts periodically to take a snapshot of data from the primary data store and store the snapshots in a suitable externalized storage like AWS S3, Azure Blobs.
In warm standby mode:
Install
API Gateway in the secondary data center and ensure that the fix upgrades of the primary data center is applied to the secondary data center too.
Run the backup scripts periodically to take a snapshot of data from the primary data store and store the snapshots in a suitable externalized storage system.
Ensure that API Data Store is turned on and running.
Run the restore scripts periodically to restore the backedup snapshots from the externalized storage in the secondary data center.
During the failover process:
In cold standby mode, start API Data Store, restore the data from the snapshots in API Data Store, and then start
API Gateway in the secondary data center.
In warm standby mode, as API Data Store is up and running, and the data is already restored from the snapshots in API Data Store, you must just restart
API Gateway alone.
After completing the disaster recovery process, when you want to switch back the traffic from the secondary data center to primary data center, follow the failback process.