Providing Dataset Path and Datatype Information in a Schema
Schemas provide four types of metadata to simplify or improve how RAQL queries interact with XML, JSON or CSV datasets:
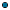
Locator information to define which objects represent rows in XML or JSON datasets.
Locator information that indicates where to find the column values in XML or JSON datasets.
Datatype information for each column in the dataset for XML, JSON or CSV datasets. For columns that are a date type, this can also include the lexical format for the data. Text columns may be specified as being compared case-insensitively.
The delimiter character and whether the dataset has column names in the first row for CSV datasets.
See
Dataset Schema Syntax for information on how to define a dataset schema.
The scope of this schema is based on where you define it: within a single mashup or as a global
MashZone NextGen attribute that can be used in any number of mashups. See
Dataset Schemas Defined in Mashups and
Global Dataset Schemas as
MashZone NextGen
Attributes for information.
Dataset Schema Syntax
Schemas for datasets define an optional table name for the schema, a set of columns with datatype, optional format and path information and an optional set of options for a dataset. The schema syntax is in the form:
define dataset [table name](
[column-name datatype [locator=column-locator] [format|case_insensitive] [,
column-name datatype [locator=column-locator] [format|case_insensitive] ]...
]
)
[with options option-name = value [,
option-name = value ]...
]
For example:
define dataset (
symbol string case_insensitive,
date datetime "yyyy-MM-dd",
open decimal,
close decimal,
high decimal,
low decimal,
volume decimal locator="volume[1]")
with options record="/stocks/stock"
See
Valid
RAQL
Datatypes for the types you can use in dataset schemas.
The
format metadata for date or time type columns accepts any lexical pattern that is valid for the Java
SimpleDate class. For the most common patterns you can use, see the
Date Formatter function for the Transformer block in
Wires.
When specifying case_insensitive, RAQL will perform any comparisons of column values case-insensitively.
The optional column path specifies an XPath expression that is evaluated relative to the row element for extracting the column value. If no path is specified, it defaults to the first child element matching the column name (as in the example above). It is only necessary to specify the column path if it diverges from this default, e.g., for selecting attribute values.
The optional column locator specifies an XQuery expression that is evaluated relative to the row object for extracting the column value. If no locator is specified, it defaults to the first child object matching the column name (as in the example above). It is only necessary to specify the column path if it diverges from this default, e.g., for selecting XML attribute values or objects with deeper nesting.
For XML, the locator is a an XQuery path expression that identifies the column value, relative to the row element.
A JSON document is represented in XQuery as a nested structure of maps and arrays. A column locator for JSON is an XQuery 3.1 lookup expression, relative to the row object, that identifies the column value. For details of the lookup expression syntax, see https://www.w3.org/TR/xquery-31/#id-lookup.
There are three different options you can specify:
record=locator-expression identifies the objects within the dataset, starting from the root, that should be used as rows. This uses the same syntax as paths you specify in a From clause,
excluding the variable name.
delimiter="character" identifies the delimiter used in CSV datasets when it is not the default delimiter (commas).
header=[true|false] indicates whether CSV datasets have column names as the first row. The default is true.
The options are comma separated.
Examples:
define dataset ...with options header=false
define dataset ...with options header=false, delimiter=";"
Dataset Schemas Defined in Mashups
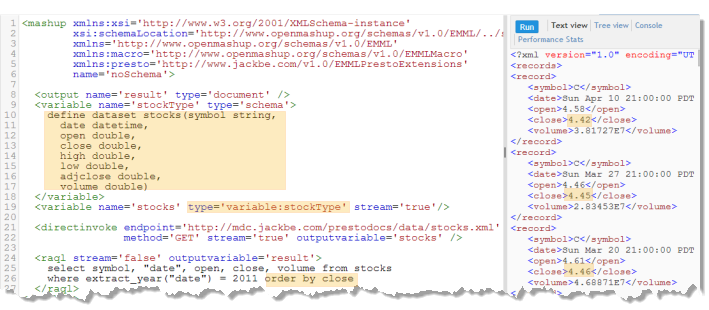
You can declare a dataset schema in the mashup that loads a dataset using the EMML<variable> statement and a type of schema. For example:
<mashup xmlns:xsi='http://www.w3.org/2001/XMLSchema-instance'
xsi:schemaLocation='http://www.openmashup.org/schemas/v1.0/EMML/
../schemas/EMMLPrestoSpec.xsd'
xmlns='http://www.openmashup.org/schemas/v1.0/EMML'
xmlns:macro='http://www.openmashup.org/schemas/v1.0/EMMLMacro'
xmlns:presto='http://www.jackbe.com/v1.0/EMMLPrestoExtensions'
name='xmlSchema'>
<output name='result' type='document' />
<variable name="stockType" type="schema">
define dataset (symbol string,
date datetime,
open decimal,
close decimal,
high decimal,
low decimal,
volume decimal,
adjclose decimal)
</variable>
<variable name="stocks" type="variable:stockType" stream="true"/>
<directinvoke method='GET' stream='true' outputvariable='stocks'
endpoint='http://mdc.jackbe.com/prestodocs/data/stocks.xml'/>
<raql outputvariable='result'>
select symbol, "date", open, close, volume from stocks
where extract_year("date") = 2011 order by close
</raql>
</mashup>
The variable named
stockType defines a schema for the stock dataset introduced in
Use an
In-Memory Store
to Store and Load Datasets for
MashZone NextGen
Analytics in Getting Started. This variable is then
referenced in the variable named
stocks, using a
type of
variable:stockType, that will hold the dataset once it is loaded. The
type identifies the named variable containing the schema for this dataset.
The primary advantage of having the dataset defined is that RAQL queries now know datatypes so that filter conditions in Where, sorting criteria in Order By and functions or calculations in Over or Group By clauses work seamlessly without having to cast columns to the right datatype.
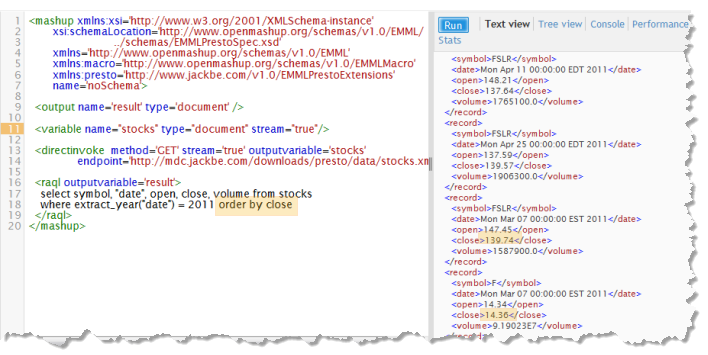
This is an example of this same mashup without schema information:
Sorting is defined on a numeric column, but because no datatype information is available from the original XML source the sort order in the result is wrong. But run the same query with schema information now available and the results are now sorted correctly:
Global Dataset Schemas as MashZone NextGen Attributes
If a dataset will be used in many RAQL queries, you can define a schema for the dataset as a MashZone NextGen global attribute that can be easily used in different mashups.
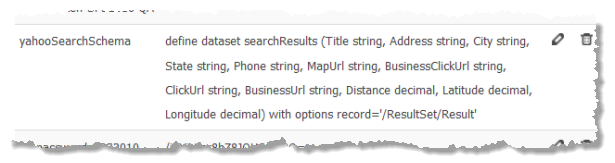
MashZone NextGen administrators can create global attributes in the Admin Console. For dataset schemas, the value of the MashZone NextGen global attribute is the full definition of the schema. In the following example:
The attribute name is yahooSearchSchema and the full definition of the schema is a single string as the attribute value.
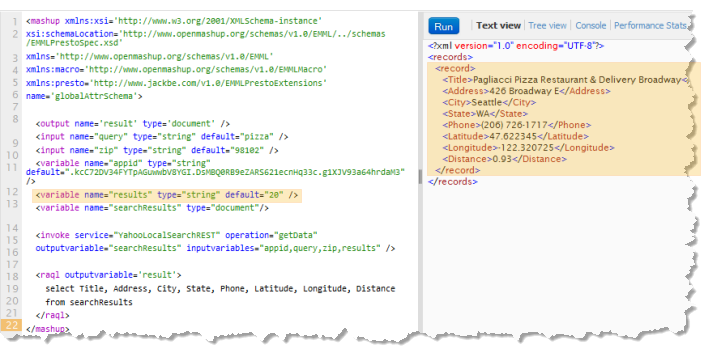
Once you have the dataset schema defined as MashZone NextGen global attribute you can use it in a mashup in a the <variable> statement with a name in the form global.attribute-name and a type of schema. This allows the mashup to use the global attribute to supply the schema definition. The following example retrieves the schema defined above from the MashZone NextGen global attribute named yahooSearchSchema:
<mashup name="globalAttrSchema"
xmlns="http://www.openmashup.org/schemas/v1.0/EMML"
xmlns:macro="http://www.openmashup.org/schemas/v1.0/EMMLMacro"
xmlns:presto="http://www.jackbe.com/v1.0/EMMLPrestoExtensions"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.openmashup.org/schemas/v1.0/
EMML/../schemas/EMMLPrestoSpec.xsd">
<output name="result" type="document"/>
<variable default="coffee" name="query" type="string"/>
<variable default="98102" name="zip" type="string"/>
<variable name="appid" type="string"
default=".kcC72DV34FYTpAGuwwbV8YGI.DsMBQ0RB9eZARS621ecnHq33c.g1XJV93a64hrdaM3" />
<variable default="20" name="results" type="string"/>
<variable name="global.yahooSearchSchema" type="schema"/>
<variable name="searchResults" type="variable:global.yahooSearchSchema"/>
<invoke inputvariables="appid,query,zip,results" operation="getData"
outputvariable="searchResults" service="YahooLocalSearchREST"/>
<raql outputvariable="result">
select Title, Address, City, State, Phone, Latitude, Longitude,
Distance
from searchResults
</raql>
</mashup>
Then add the variable to hold the dataset and reference the schema variable using a type of variable:global.attribute-name, that will hold the dataset once it is loaded. The type identifies the named variable containing the schema for this dataset, In this example, the variable searchResults has a type that pulls in the global.yahooSearchSchema global attribute containing the schema definition.
In this example query when no schema is used, the mashup shows results of a single row even though the query to Yahoo Local Search asked for up to 20 results:
When the schema is added, supplying specific path information to rows in Yahoo’s results, the query now retrieves all 20 results: