Tiering Options
Ehcache supports the concept of tiered caching. This section covers the different available configuration options. It also explains rules and best practices to benefit the most from tiered caching.
For a general overview of the available storage tiers, see the section
Storage Tiers in the
About Terracotta Ehcache guide.
Moving out of heap
The moment you have a tier other than the heap tier in a cache, a few things happen:

Adding a mapping to the cache means that the key and value have to be serialized.
Reading a mapping from the cache means that the key and value may have to be deserialized.
With these two points above, you need to realize that the binary representation of the data and how it is transformed to and from serialized data will play a significant role in caching performance. Make sure you know about the options available for serializers (see the section
Serializers). Also this means that some configurations, while making sense on paper, may not offer the best performance depending on the real use case of the application.
Single tier setups
All tiering options can be used in isolation. For example, you can have caches with data only in offheap or only clustered.
The following possibilities are valid configurations:
heap
offheap
disk
clustered
For this, simply define the single resource in the cache configuration:
CacheConfigurationBuilder.newCacheConfigurationBuilder(
Long.class, String.class, // 1
ResourcePoolsBuilder.newResourcePoolsBuilder()
.offheap(2, MemoryUnit.GB)).build(); // 2
1 | Start with defining the key and value type in the configuration builder. |
2 | Then specify the resource (the tier) you want to use. Here we use off-heap only. |
Heap Tier
The starting point of every cache and also the faster since no serialization is necessary. You can optionally use copiers (see the section
Serializers and Copiers) to pass keys and values by-value, the default being by-reference.
A heap tier can be sized by entries or by size.
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(10, EntryUnit.ENTRIES); // 1
// or
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(10); // 2
// or
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(10, MemoryUnit.MB); // 3
1 | Only 10 entries are allowed on heap. Eviction will occur when full. |
2 | A shortcut to specify 10 entries. |
3 | Only 10 MB are allowed. Eviction will occur when full. |
Byte-sized heap
For every tier except the heap tier, calculating the size of the cache is fairly easy. You more or less sum the size of all byte buffers containing the serialized entries.
When heap is limited by size instead of entries, it is a bit more complicated.
Note:
Byte sizing has a runtime performance impact that depends on the size and graph complexity of the data cached.
CacheConfiguration<Long, String> usesConfiguredInCacheConfig =
CacheConfigurationBuilder.newCacheConfigurationBuilder(
Long.class, String.class,
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(10, MemoryUnit.KB) // 1
.offheap(10, MemoryUnit.MB)) // 2
.withSizeOfMaxObjectGraph(1000)
.withSizeOfMaxObjectSize(1000, MemoryUnit.B) // 3
.build();
CacheConfiguration<Long, String> usesDefaultSizeOfEngineConfig =
CacheConfigurationBuilder.newCacheConfigurationBuilder(
Long.class, String.class,
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(10, MemoryUnit.KB))
.build();
CacheManager cacheManager =
CacheManagerBuilder.newCacheManagerBuilder()
.withDefaultSizeOfMaxObjectSize(500, MemoryUnit.B)
.withDefaultSizeOfMaxObjectGraph(2000) // 4
.withCache("usesConfiguredInCache", usesConfiguredInCacheConfig)
.withCache("usesDefaultSizeOfEngine",
usesDefaultSizeOfEngineConfig)
.build(true);
1 | This will limit the amount of memory used by the heap tier for storing key-value pairs. There is a cost associated with sizing objects. |
2 | The settings are only used by the heap tier. So off-heap won't use it at all. |
3 | The sizing can also be further restrained by 2 additional configuration settings: The first one specifies the maximum number of objects to traverse while walking the object graph (default: 1000), the second defines the maximum size of a single object (default: Long.MAX_VALUE, so almost infinite). If the sizing goes above any of these two limits, the entry won't be stored in cache. |
4 | A default configuration can be provided at CacheManager level to be used by the caches unless defined explicitly. |
Off-heap Tier
If you wish to use off-heap, you'll have to define a resource pool, giving the memory size you want to allocate.
ResourcePoolsBuilder.newResourcePoolsBuilder()
.offheap(10, MemoryUnit.MB); // 1
1 | Only 10 MB are allowed off-heap. Eviction will occur when full. |
The example above allocates a very small amount of off-heap. You will normally use a much bigger space.
Remember that data stored off-heap will have to be serialized and deserialized - and is thus slower than heap.
You should thus favor off-heap for large amounts of data where on-heap would have too severe an impact on garbage collection.
Do not forget to define in the Java options the -XX:MaxDirectMemorySize option, according to the off-heap size you intend to use.
Disk Tier
For the Disk tier, the data is stored on disk. The faster and more dedicated the disk is, the faster accessing the data will be.
PersistentCacheManager persistentCacheManager =
CacheManagerBuilder.newCacheManagerBuilder() // <1>
.with(CacheManagerBuilder.persistence(new File(
getStoragePath(), "myData"))) // <2>
.withCache("persistent-cache",
CacheConfigurationBuilder.newCacheConfigurationBuilder(
Long.class, String.class,
ResourcePoolsBuilder.newResourcePoolsBuilder()
.disk(10, MemoryUnit.MB, true)) // <3>
)
.build(true);
persistentCacheManager.close();
1 | Obtain a PersistentCacheManager, which is a normal CacheManager but with the ability to destroy caches. See the section
Destroying Persistent Tiers for further information. |
2 | Provide a location where data should be stored. |
3 | Define a resource pool for the disk that will be used by the cache. The third parameter is a boolean value which is used to set whether the disk pool is persistent. When set to true, the pool is persistent. When the version with 2 parameters disk(long, MemoryUnit) is used, the pool is not persistent. |
The example above allocates a very small amount of disk storage. You will normally use a much bigger storage.
Persistence means the cache will survive a JVM restart. Everything that was in the cache will still be there after restarting the JVM and creating a CacheManager disk persistence at the same location.
Note:
A disk tier can't be shared between cache managers. A persistence directory is dedicated to one cache manager at the time.
Remember that data stored on disk will have to be serialized / deserialized and written to / read from disk - and is thus slower than heap and offheap. So disk storage is interesting if:
You have a large amount of data that can't fit off-heap
Your disk is much faster than the storage it is caching
You are interested in persistence
Note:
The open source disk tier offers no data integrity guarantee in the case of a crash. There is an enterprise version that provides this and more, see below.
Segments
Disk storage is separated into segments which provide concurrency access but also hold open file pointers. The default is 16. In some cases, you might want to reduce the concurrency and save resources by reducing the number of segments.
String storagePath = getStoragePath();
PersistentCacheManager persistentCacheManager =
CacheManagerBuilder.newCacheManagerBuilder()
.with(CacheManagerBuilder.persistence(new File(storagePath, "myData")))
.withCache("less-segments",
CacheConfigurationBuilder.newCacheConfigurationBuilder(
Long.class, String.class,
ResourcePoolsBuilder.newResourcePoolsBuilder()
.disk(10, MemoryUnit.MB))
.add(new OffHeapDiskStoreConfiguration(2)) // 1
)
.build(true);
persistentCacheManager.close();
1 | Define an OffHeapDiskStoreConfiguration instance specifying the required number of segments. |
Clustered
A clustered tier means the client connects to the Terracotta Server Array where the cached data is stored. It is also as way to have a shared cache between JVMs.
See the section
Clustered Caches for details of using the cluster tier.
Multiple tier setup
If you want to use more than one tier, you have to observe some constraints:
1. There must always be a heap tier in a multi-tier setup.
2. You cannot combine disk tiers and clustered tiers.
3. Tiers should be sized in a pyramidal fashion, i.e. tiers higher up the pyramid are configured to use less memory than tiers lower down.
For 1, this is a limitation of the current implementation.
For 2, this restriction is necessary, because having two tiers with content that can outlive the life of a single JVM can lead to consistency questions on restart.
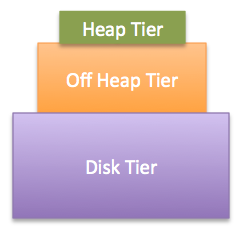
For 3, the idea is that tiers are related to each other. The fastest tier (the heap tier) is on top, while the slower tiers are below. In general, heap is more constrained than the total memory of the machine, and offheap memory is more constrained than disk or the memory available on the cluster. This leads to the typical pyramid shape for a multi-tiered setup.
Illustration that displays the tiers stacked as pyramid. On top, the mandatory, fastest but smallest heap tier. Beneath, the off-heap tier. As base, the large but slow disk tier, which could alternatively but not simultaneously be on a cluster.
Ehcache requires the size of the heap tier to be smaller than the size of the offheap tier, and the size of the offheap tier to be smaller than the size of the disk tier. While Ehcache cannot verify at configuration time that a count-based sizing for the heap tier will be smaller than a byte-based sizing for another tier, you should make sure that is the case during testing.
Taking the above into account, the following possibilities are valid configurations:
heap + offheap
heap + offheap + disk
heap + offheap + clustered
heap + disk
heap + clustered
Here is an example using heap, offheap and clustered.
PersistentCacheManager persistentCacheManager =
CacheManagerBuilder.newCacheManagerBuilder()
.with(cluster(CLUSTER_URI).autoCreate()) // 1
.withCache("threeTierCache",
CacheConfigurationBuilder.newCacheConfigurationBuilder(
Long.class, String.class,
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(10, EntryUnit.ENTRIES) // 2
.offheap(1, MemoryUnit.MB) // 3
.with(ClusteredResourcePoolBuilder.clusteredDedicated(
"primary-server-resource", 2, MemoryUnit.MB)) // 4
)
).build(true);
1 | Cluster-specific information telling how to connect to the Terracotta cluster |
2 | Define the Heap tier, which is the smallest but fastest caching tier. |
3 | Define the Offheap tier. Next in line as caching tier. |
4 | Define the Clustered tier. The authoritative tier for this cache |
Resource Pools
Tiers are configured using resource pools. Most of the time using a ResourcePoolsBuilder. Let's revisit an example used earlier:
PersistentCacheManager persistentCacheManager =
CacheManagerBuilder.newCacheManagerBuilder()
.with(CacheManagerBuilder.persistence(
new File(getStoragePath(), "myData")))
.withCache("threeTieredCache",
CacheConfigurationBuilder.newCacheConfigurationBuilder(
Long.class, String.class,
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(10, EntryUnit.ENTRIES)
.offheap(1, MemoryUnit.MB)
.disk(20, MemoryUnit.MB, true)
)
).build(true);
This is a cache using 3 tiers (heap, offheap, disk). They are created and chained using the ResourcePoolsBuilder. The declaration order doesn't matter (e.g. offheap can be declared before heap) because each tier has a height. The higher the height of a tier is, the closer the tier will be to the client.
It is really important to understand that a resource pool is only specifying a configuration. It is not an actual pool that can be shared between caches. Consider for instance this code:
ResourcePools pool = ResourcePoolsBuilder.heap(10).build();
CacheManager cacheManager = CacheManagerBuilder.newCacheManagerBuilder()
.withCache("test-cache1", CacheConfigurationBuilder.newCacheConfigurationBuilder(
Integer.class, String.class, pool))
.withCache("test-cache2", CacheConfigurationBuilder.newCacheConfigurationBuilder(
Integer.class, String.class, pool))
.build(true);
You will end up with two caches that can contain 10 entries each. Not a shared pool of 10 entries. Pools are never shared between caches. The exception being clustered caches, that can be shared or dedicated.
Updating Resource Pools
Limited size adjustment can be performed on a live cache.
Note:
updateResourcePools() only allows you to change the heap tier sizing, not the pool type. Thus you can't change the sizing of off-heap or disk tiers.
ResourcePools pools = ResourcePoolsBuilder
.newResourcePoolsBuilder().heap(20L, EntryUnit.ENTRIES).build(); // 1
cache.getRuntimeConfiguration().updateResourcePools(pools); // 2
assertThat(cache.getRuntimeConfiguration().getResourcePools()
.getPoolForResource(ResourceType.Core.HEAP).getSize(), is(20L));
1 | You will need to create a new ResourcePools object with resources of the required size, using ResourcePoolsBuilder. This object can then be passed to the said method so as to trigger the update. |
2 | To update the capacity of ResourcePools, the updateResourcePools(ResourcePools) method in RuntimeConfiguration can be of help. The ResourcePools object created earlier can then be passed to this method so as to trigger the update. |
Destroying Persistent Tiers
The disk tier and cluster tier are the two persistent tiers. This means that when the JVM is stopped, all the created caches and their data still exist on disk or on the cluster.
Once in a while, you might want to fully remove them. Their definition as PersistentCacheManager gives access to the following methods:
destroy()
This method destroys everything related to the cache manager (including caches, of course). The cache manager must be closed or uninitialized to call this method. Also, for a cluster tier, no other cache manager should currently be connected to the same cache manager server entity.
destroyCache(String cacheName)
Ths method destroys a given cache. The cache shouldn't be in use by another cache manager.
Sequence Flow for Cache Operations with Multiple Tiers
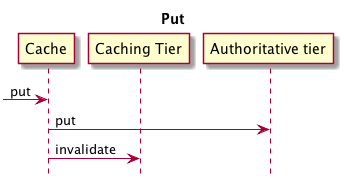
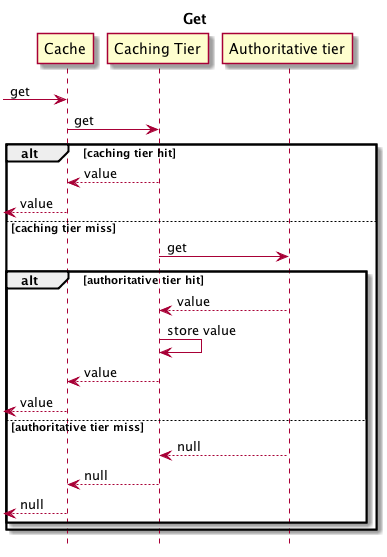
In order to understand what happens for different cache operations when using multiple tiers, here are examples of Put and Get operations. The sequence diagrams are oversimplified but still show the main points.
Multiple tiers using Put: Diagram showing the Get operation and its variations. As in the previous graphic, there is from left to right the sequence of the Cache, the Caching Tier and the Authorative Tier. Following the direction of the tiers, the get reaches the Cache and is handed to the Caching Tier.
Multiple tiers using Get: Diagram showing the alternative, interdependent partial operational. The implemented behaviour depends on whether the get delivers a hit or a miss on the tier following their hierarchical sequence. Procedure A: The get delivers a hit in the Caching tier and returns the value. Or .. The get results in a miss in the Caching Tier and is handed straight on to the Authorative Tier. Depending on whether the Autorative Tier delivers a hit or a miss, Procedure B kicks in: If the Authorative Tier delivers a hit, the value is handed on to the preceding Caching Tier. Here the value is stored and from there returned as result of the Get request. Or ... If the Authorative Tier delivers a miss, a null value is handed to the preceding Caching Tier and from there returned as null to the Get request.
You should then notice the following:
When putting a value into the cache, it goes straight to the authoritative tier, which is the lowest tier.
A following
get will push the value upwards in the caching tiers.
Of course, as soon as a value is put in the authoritative tier, all higher-level caching tiers are invalidated.
A full cache miss (the value isn't on any tier) will always go all the way down to the authoritative tier.
Note:
The slower your authoritative tier, the slower your put operations will be. For a normal cache usage, it usually doesn't matter since get operations are much more frequent than put operations. The opposite would mean you probably shouldn't be using a cache in the first place.