This Dokument covers the following topics:
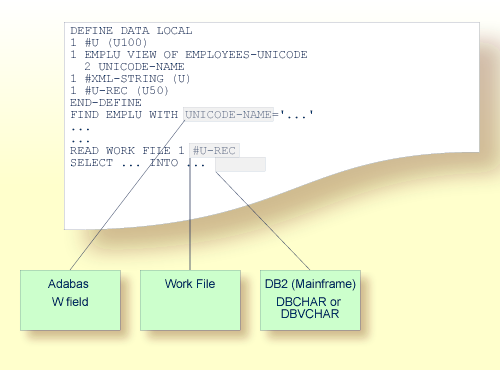
Die folgende Grafik veranschaulicht, wie auf Unicode-Daten und -Parameter zugegriffen wird:
Folgende Themen werden behandelt:
Natural ermöglicht es Benutzern, auf Wide-Character-Fields (Format W) in einer Adabas-Datenbank zuzugreifen.
- Datendefinitionsmodule
Adabas Wide-Character-Fields (W) werden auf Natural-Format U (Unicode) abgebildet.
- Zugriffskonfiguration
Natural erhält Daten aus Adabas und sendet Daten zurück an Adabas und benutzt dazu UTF-16 als übliche Zeichencodierung.
Diese Kodierung wird mit dem Profilparameter
OPRBangegeben und an Adabas mit derOpen-Anforderung gesendet. Sie wird für Wide-Character-Fields benutzt und gilt für die gesamte Adabas-Benutzer-Session.
Weitere Informationen siehe Unicode-Daten im Abschnitt Daten in einer Adabas-Datenbank aufrufen im Leitfaden zur Programmierung.
Natural ermöglicht es, dass Benutzer auf CHAR-
und/oder WCHAR-Felder in einer DB2-Datenbank als Unicode-Daten
zuzugreifen.
Siehe auch Natural for DB2 in der Datenbankmanagementsystem-Schnittstellen-Dokumentation.
Folgende Themen werden behandelt:
Beim Schreiben oder Lesen von Arbeitsdateien werden Unicode-Daten nicht besonders berücksichtigt. Wie alle anderen Daten werden Unicode-Daten so geschriben und gelesen, wie sie sind, ohne Umwandlung.
Wenn Unicode-Daten an Druckdateien gesendet werden, finden eine oder zwei Umsetzungen statt.
Als ersten Schritt werden in einer Druckzeile enthaltene Unicode-Daten in die Standard-Codepage der Session umgewandelt. Infolgedessen werden alle Zeichen, die nicht in dieser Standard-Codepage enthalten sind, durch das Ersatzzeichen ersetzt.
Bevor die umgewandelte Druckzeile an die eigentliche
Druckzugriffsmethode übergeben wird, erfolgt eine zusätzliche Prüfung, ob eine
Codepage für den logischen Drucker angegeben worden ist. Das kann mit dem
CODEPAGE-Operanden des DEFINE PRINTER-Statements
oder dem Schlüsselwort-Subparameter CP des
Profilparameters PRINT vorgenommen
werden. Wenn eine solche Codepage angeben worden ist, dann wird im zweiten
Schritt die gesamte Druckzeile (nicht nur ihr Unicode-Teil) entsprechend
umgewandelt.
Die umgewandelte Druckzeile wird an die Zugriffsmethode übergeben, was bedeutet, dass Druckzugriffsmethoden keine Unicode-Daten erhalten.
Beispiel:
DEFINE PRINTER (1) CODEPAGE 'IBM01140' WRITE (1) 'HELLO' U'WORLD' END