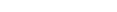
COMPOPT [option=value
...]
|
Mit diesem Kommando können Sie verschiedene Kompilierungsoptionen setzen. Die Optionen werden wirksam, wenn ein Natural-Programmierobjekt kompiliert wird.
Wenn Sie das Kommando COMPOPT ohne Optionen
eingeben, wird ein Schirm angezeigt, auf dem Sie die unten beschriebenen
Optionen ein- bzw. ausschalten können.
Die Standardwerte für die einzelnen Optionen werden mit den
Schlüsselwort-Subparametern im Parametermakro
NTCMPO
im Natural-Parametermodul bzw. im entsprechenden Profilparameter
CMPO
gesetzt. Wenn Sie die Library wechseln, werden die
COMPOPT-Optionen wieder auf ihre Standardwerte
zurückgesetzt.
Folgende Themen werden behandelt:
COMPOPT |
Wenn Sie nur das Kommando
COMPOPT eingeben, wird der Compilations
Options-Schirm angezeigt, auf dem Sie die unten beschriebenen
Optionen ein- bzw. ausschalten können. Die dort vorhandenen Schlüsselwörter
werden nachfolgend beschrieben.
|
COMPOPT
option=value |
Die Schlüsselwörter für die einzelnen Optionen werden nachfolgend beschrieben. Die einer Compiler-Option zugewiesene Einstellung bleibt
solange gültig, bis Sie das nächste |
Compiler-Schlüsselwortparameter können Sie auf verschiedenen Ebenen angeben:
Die Standardeinstellungen der einzelnen
Compiler-Schlüsselwortparameter werden mit dem Parameter-Makro
NTCMPO
vorgenommen. Diese Einstellungen werden im Natural-Parametermodul
gespeichert.
Zu Beginn einer Natural-Session können Sie die
Compiler-Schlüsselwortparameter überschreiben, indem Sie die Werte im
entsprechenden Profilparameter CMPO setzen.
Während einer aktiven Natural-Session haben Sie zwei
Möglichkeiten, die Compiler-Parameterwerte mit dem Systemkommando
COMPOPT zu ändern: Entweder direkt mittels
Kommandozuordnung (COMPOPT
option=value)
oder indem Sie das Kommando COMPOPT ohne Optionen
absetzen, woraufhin der Schirm Compilation Options
erscheint.
Bei einem LOGON auf eine andere
Library, werden die mit dem Makro
NTCMPO
und/oder dem Profilparameter CMPO vorgenommenen
Standardeinstellungen (siehe Punkt 1) wieder hergestellt. Beispiel:
OPTIONS KCHECK=ON DEFINE DATA LOCAL 1 #A (A25) INIT <'Hello World'> END-DEFINE WRITE #A END
In einem Natural-Programmierobjekt (z.B. Programm, Subprogramm)
können Sie Compiler-Parameter mit dem OPTIONS-Statement setzen.
Beispiel:
OPTIONS KCHECK=ON WRITE 'Hello World' END
Die in einem OPTIONS-Statement angegebenen
Compiler-Optionen betreffen nur die Kompilierung dieses Programmierobjekts, sie
aktualisieren jedoch nicht die mit dem Systemkommando
COMPOPT gesetzten Optionen.
Folgende Compiler-Optionen stehen zur Verfügung:
CPAGE - Codepage-Unterstützung bei alphanumerischen Konstanten
DB2ARRY - Unterstützung von DB2-Arrays in SQL SELECT- und INSERT-Statements
DB2BIN - Generierung von SQL Binärdatentypen bei Natural-Binärfeldern
DB2PKYU – Primäre Schlüsselfelder in das Natural DML Statement UPDATE stellen
DB2TSTI – Generierung des SQL TIMESTAMP-Datentyps für Natural-TIME-Felder
LUWCOMP - Auf UNIX oder Windows nicht verfügbare Syntax unterbinden
MEMOPT - Speicheroptimierung für lokal deklarierte Variablen
NMOVE22 - Zuordnung von numerischen Variablen mit derselben Länge und Genauigkeit
PSIGNF - Interne Darstellung des positiven Vorzeichens bei gepackten Zahlen
Diese Compiler-Optionen entsprechen den gleichnamigen
Schlüsselwortparametern des Profilparameters CMPO bzw. des
Parameter-Makros NTCMPO.
Mit der Option CHKRULE können Sie eine während des
Katalogisierungsvorgangs für Masken (Maps) stattfindende Validierungsprüfung
ein- bzw. ausschalten.
ON |
Die INCDIR-Validierung ist
eingeschaltet. Wenn die bzw. das im INCDIR-Kontrollstatement
referenzierte Datei (DDM) bzw. Feld nicht existiert, wird zur Kompilierungszeit
ein Syntaxfehler (NAT0721) ausgegeben.
Beim Anlegen einer Map können Sie Felder einfügen, die
schon in einem anderen existierenden Programmierobjekt definiert sind. Das
funktioniert bei fast allen Arten von Objekten, in denen Sie Variablen
definieren können, und ebenso bei DDMs. Wenn es sich bei dem eingefügten Feld
um eine Datenbankvariable handelt, fügt der Map Editor automatisch (neben dem
eingefügten Feld) ein Die Funktionsweise ist ähnlich dem Vorgang bei der
Verarbeitung eines Bei Übernahme von Feldern aus einer DDM in eine Map,
werden entsprechende |
OFF |
Die INCDIR-Validierung ist ausgeschaltet.
Dies ist der Standardwert.
|
Mit der CPAGE-Option können Sie eine
Konvertierungsroutine aktivieren, die, wenn das Objekt zur Laufzeit gestartet
wird, alle alphanumerischen Konstanten von der Codepage, die bei der
Kompilierung aktiv war, in die Codepage, die zur Laufzeit aktiv ist,
umsetzt.
Siehe auch Abschnitt Compiler-Option CPAGE in der Dokumentation Unicode- und Codepage-Unterstützung.
ON |
Codepage-Unterstützung für alphanumerische Zeichenketten ist eingeschaltet. |
OFF |
Codepage-Unterstützung für alphanumerische Zeichenketten ist ausgeschaltet. Dies ist der Standardwert. |
Interpretation von Datenbankfeld-Namen in Programmierobjekten.
Ein in einem DDM definiertes Datenbankfeld wird durch zwei Namen beschrieben:
durch den Kurznamen mit einer Länge von zwei Zeichen, der von Natural für die Kommunikation mit der Datenbank (insbesondere mit Adabas) verwendet wird;
durch den Langnamen mit einer Länge von 3 bis 32 Zeichen (1 bis 32 Zeichen, wenn die darunter liegende Datenbank DB2/SQL ist), der zum Referenzieren des Feldes im Natural-Programmcode verwendet werden soll.
Unter speziellen Bedingungen können Sie in einem Natural-Programm ein Datenbankfeld mit seinem Kurznamen statt mit dem Langnamen referenzieren. Dies gilt, falls Sie Natural im Reporting Mode ohne Natural Security benutzen und falls das für den Datenbankzugriff verwendete Statement statt einer Referenz auf ein View eine Referenz auf ein DDM enthält.
Die Entscheidung, ob ein Feldname als eine Kurznamen-Referenz
betrachtet wird, erfolgt abhängig von der Länge des Namens. Wenn die
Feldkennung (Identifier) aus zwei Zeichen besteht, wird davon ausgegangen, dass
eine Kurznamen-Referenz vorliegt; ein Feldname mit einer anderen Länge wird als
Langnamen-Referenz betrachtet. Diese standardmäßige Interpretation können Sie
zusätzlich beeinflussen, indem Sie die Compiler-Option DBSHORT auf
ON oder OFF setzen:
ON |
Die Verwendung eines Kurznamens zum Referenzieren
eines Datenbankfeldes ist erlaubt, jedoch wird die Verwendung eines
Datenbank-Kurznamens nicht generell gestattet (selbst wenn
DBSHORT=ON)
Dies ist der Standardwert. |
OFF |
Ein Datenbankfeld kann nur über seinen Langnamen
referenziert werden. Jede Datenbankfeldkennung wird unabhängig von ihrer Länge
als Langnamen-Referenz betrachtet.
Wenn ein zwei Zeichen langer Name geliefert wird, der nur als Kurzname und nicht als Langname gefunden werden kann, wird bei der Kompilierung ein Syntaxfehler NAT0981 ausgegeben. Dies ermöglicht die Verwendung von Langnamen, die in einer DDM mit einer Kennungslänge von 2 Byte definiert wurden. Diese Option ist wichtig, wenn die darunter liegende Datenbank, auf die Sie mit diesem DDM zugreifen wollen, vom Typ SQL (DB2) ist und wenn dort Tabellenspalten mit einem zwei Zeichen langen Namen existieren. Dagegen wird bei allen anderen Datenbanktypen (zum Beispiel Adabas) jeder Versuch, ein Langnamenfeld mit einer Namenslänge von 2 Bytes zu definieren bei der DDM-Generierung zurückgewiesen. Darüber hinaus wird das Programm, wenn keine
Kurznamenreferenzen verwendet werden (was durch |
Gegeben sei die folgende Datenbankfelddefinition in dem DDM
EMPLOYEES:
| Kurzname | Langname |
|---|---|
AA |
PERSONNEL-ID |
Beispiel 1:
OPTIONS DBSHORT=ON READ EMPLOYEES DISPLAY AA /* Datenbankfeldkurzname AA ist erlaubt END
Beispiel 2:
OPTIONS DBSHORT=OFF READ EMPLOYEES DISPLAY AA /* Syntaxfehler NAT0981, weil DBSHORT=OFF END
Beispiel 3:
OPTIONS DBSHORT=ON
DEFINE DATA LOCAL
1 V1 VIEW OF EMPLOYEES
2 PERSONNEL-ID
END-DEFINE
READ V1 BY PERSONNEL-ID
DISPLAY AA /* Syntaxfehler NAT0981, weil PERSONNEL-ID im View definiert ist;
/* (selbst wenn DBSHORT=ON)
END-READ
END
Mit der Option DB2ARRY können Sie die Recherche
und/oder das Einfügen in mehreren Reihen in DB2 mit nur einer Ausführung eines
SQL SELECT- oder
INSERT-Statements
aktivieren. Dies ermöglicht die Angabe von Arrays als Zielfelder im SQL
SELECT-Statement oder als Quellfelder im SQL
INSERT-Statement. Wenn DB2ARRY auf ON
gesetzt ist, ist es nicht mehr möglich, alphanumerische Natural-Arrays für DB2
VARCHAR/GRAPHIC-Spalten zu verwenden. Stattdessen müssen Sie lange
alphanumerische Natural-Variablen verwenden.
ON |
DB2-Array-Unterstützung ist eingeschaltet. |
OFF |
DB2-Array-Unterstützung ist ausgeschaltet. Dies ist der Standardwert. |
Die Option DB2BIN kann benutzt werden, um die
DB2-Datentypen BINARY und VARBINARY zu unterstützen.
Wenn DB2BIN auf OFF gesetzt ist, werden
die Natural-Binärfelder (Format B(n))
als SQL-Datentyp CHAR (n<= 253) oder
VARCHAR (253<n<=32767) generiert,
so wie es in früheren Releases der Fall war. DB2BIN=OFF ist für
jene Anwender gedacht, die Natural-Binärfelder wie SQL CHAR-Felder benutzten.
B2 und B4 werden als SQL SMALLINT und INTEGER behandelt.
Wenn DB2BIN auf ON gesetzt ist, werden
die Natural-Binärfelder (Format B(n))
als SQL-Datentyp BINARY (n<=255)
oder VARBIN (255<n<=32767)
generiert. DB2BIN=ON ist für jene Anwender gedacht, die
SQL-Binärspalten benutzen wollen. B2 und B4 werden ebenfalls als SQL BINARY(2)
und BINARY(4) behandelt.
Anmerkung:
Die Einstellung von DB2BIN wird am Ende der
Kompilierung für das gesamte Natural-Objekt benutzt. Sie kann nicht für Teile
des Natural-Objekts geändert werden.
ON |
Die SQL-Typen BINARY und VARBIN werden für Natural-Felder im Binärformat generiert. |
OFF |
Die SQL-Typen CHAR und VARCHAR werden für
Natural-Felder im Binärformat außer B2 und B4 generiert. Letztere werden als
SQL-Datentyp SMALLINT und INTEGER behandelt.
Dies ist der Standardwert. |
Die Option DB2PKYU gilt nur, wenn die in Ihrer
Umgebung installierte Version von Natural for DB2 diese Option unterstützt.
Die Option DB2PKYU kann benutzt werden, um primäre
DB2-Schlüsselfelder mit einem Natural DML Statement UPDATE zu
aktualisieren. Bei den primären DB2-Schlüsselfeldern handelt es sich um Felder,
deren Kurznamen im DDM mit dem Zeichen O beginnen.
Anmerkung:
Die Einstellung der Option DB2PKYU am Ende der
Kompilierung wird für das gesamte Natural-Objekt benutzt. Sie kann nicht für
Teile eines Natural-Objekts geändert werden.
ON |
Primäre DB2-Schlüsselfelder werden aktualisiert.
Primäre DB2-Schlüsselfelder, die innerhalb des
Natural-Programms aktualisiert werden, werden in das resultierende
Positioned
|
OFF |
Primäre DB2-Schlüsselfelder werden nicht
aktualisiert.
Primäre DB2-Schlüsselfelder, die innerhalb des
Natural-Programms aktualisiert werden, werden nicht in das resultierende
Positioned Dies ist der Standardwert. |
Die Option DB2TSTI kann benutzt werden, um
Natural-Variablen vom Typ TIME statt auf den
SQL-Datentyp TIME auf den SQL-Datentyp TIMESTAMP abzubilden.
ON |
Der SQL-Datentyp TIMESTAMP wird für
Natural-TIME-Felder des Natural-Datenformats T generiert.
Dies gilt für das gesamte Natural-Objekt. Durch Setzen
der Option |
OFF |
Der SQL-Datentyp TIME wird für Natural-TIME-Felder
des Natural-Datenformats T generiert.
Dies ist der Standardwert. |
Anmerkung:
Die Genauigkeit eines Natural-TIME-Feldes beträgt
nur Zehntelsekunden, wohingegen eine SQL-TIMESTAMP-Spalte eine viel höhere
Genauigkeit haben kann. Deshalb kann es passieren, dass der aus der Datenbank
gelesene TIMESTAMP-Wert abgeschnitten wird, wenn DB2TSTI=ON
gesetzt ist.
ON |
Der Compiler prüft das Vorhandensein eines
Programmierobjekts, welches in einem objektaufrufenden Statement angegeben ist,
zum Beispiel in FETCH
[RETURN/REPEAT], RUN
[REPEAT], CALLNAT,
PERFORM,
INPUT USING
MAP,
PROCESS PAGE
USING, Function
Call, Helproutine-Aufruf.
Die Existenzprüfung basiert auf der Suche nach dem
katalogisierten Objekt oder nach der Source des Objekts, wenn es von einem
Dazu ist erforderlich, dass der Name des aufzurufen bzw.
auszuführenden ( Andernfalls hat die Einstellung Fehler-Behandlung bei
ECHECK=ON
Die Existenzprüfung wird nur dann ausgeführt, wenn das Objekt keine syntaktischen Fehler enthält. Die Existenzprüfung wird bei jedem Statement ausgeführt, welches ein Objekt aufruft. Gesteuert wird die Existenzprüfung durch den
Profilparameter Probleme bei der Benutzung des
CATALL-Kammandos mit ECHECK=ON
Wenn ein Wenn ein GDAs, LDAs, PDAs, Functions, Subprogramme, externe Subroutinen, Helproutinen, Maps, Adapter, Programme, Klassen. Bei Objekten desselben Typs bestimmt die alphabetische Reihenfolge der Namen die Abfolge, in der sie katalogisiert werden. Wie zuvor erwähnt wird die erfolgreiche Ausführung des
das Objekt aufrufenden Statements gegen die kompilierte Form des aufgerufenen
Subprogramms geprüft. Wenn das aufrufende Objekt (das momentan kompiliert wird
und das das Objekt aufrufende Statements enthält) vor dem aufgerufenen Objekt
katalogisiert wird, kann das Lösung:
|
OFF |
Es erfolgt keine Existenzprüfung. Dies ist der Standardwert. |
Diese Option dient dazu, Informationen über die Struktur einer GDA (Global Data Area) zu speichern, um so zu bestimmen, ob ein Natural-Fehler ausgegeben werden soll, wenn eine unveränderte GDA katalogisiert wird.
Die GDA-Informationen (GDA-Signatur) ändern sich nur dann, wenn eine GDA geändert wird. Die GDA-Signatur ändert sich nicht, wenn eine GDA (versehentlich) katalogisiert wird, aber nicht nicht geändert wurde.
Die Signatur der GDA und die in allen Natural-Objekten, welche diese GDA referenzieren, gespeicherten GDA-Signaturen werden zur Ausführungszeit verglichen, und zwar zusätzlich zu den Zeitstempeln der Objekte.
ON |
GDA-Signaturen werden gespeichert und bei der Ausführung verglichen. Natural gibt nur dann eine Fehlermeldung aus, wenn die Signaturen nicht identisch sind. |
OFF |
GDA-Signaturen werden nicht gespeichert. Dies ist der Standardwert. |
Mit dieser Option können Sie Naturals interne Generierung globaler Formatkennungen (Global Format IDs) steuern, um damit das Leistungsverhalten von Adabas bei der Wiederverwendbarkeit von Format-Buffer-Übersetzungen zu beeinflussen.
ON |
Global Format IDs werden für alle Views generiert. Dies ist der Standardwert. |
VID |
Global Format IDs werden nur für in Local/Global Data Areas definierte Views generiert, aber nicht für innerhalb von Programmen definierte Views. |
OFF |
Es werden keine Global Format IDs generiert. |
Weitere Informationen zu Global Format IDs siehe Adabas-Dokumentation.
GFID=abccddee
| dabei steht | für |
|---|---|
a |
x'F9' |
b |
x'22' oder x'21' in Abhängigkeit vom DB-Statement |
cc |
physische Datenbanknummer (2 Bytes) |
dd |
physische Dateinummer (2 Bytes) |
ee |
zur Laufzeit generierte Nummer (2 Bytes) |
GFID=abbbbbbc
| dabei steht | für |
|---|---|
a |
x'F8' oder x'F7' oder x'F6' |
bbbbbb |
Bytes 1-6 des STOD-Werts |
c |
physische Dateinummer |
Anmerkung:
STOD ist der Rückmeldewert der Store Clock Machine
Instruction (STCK).
Prüfung auf Schlüsselwörter.
ON |
Felddeklarationen in einem Programmierobjekt werden gegen einen Satz kritischer Natural-Schlüsselwörter geprüft. Falls ein Variablenname mit einem dieser Schlüsselwörter übereinstimmt, wird ein Syntaxfehler ausgegeben, wenn das Programmierobjekt geprüft oder katalogisiert wird. |
OFF |
Es erfolgt keine solche Prüfung. Dies ist der Standardwert. |
Der Abschnitt Prüfung der für Natural
reservierten Schlüsselwörter durchführen im
Leitfaden zur Programmierung enthält eine Liste der
Natural-Schlüsselwörter, die von der KCHECK-Option abgeprüft
werden.
Der Abschnitt Alphabetische Liste der für Natural reservierten Schlüsselwörter im Leitfaden zur Programmierung enthält eine Übersicht über alle Natural-Schlüsselwörter und reservierten Wörter.
Diese Option unterstützt die Verwendung von Programmen in Sourceform mit Kleinschreibung oder gemischter Schreibweise auf Großrechnerplattformen und erleichtert so die Übertragung von derartigen Programmen von anderen Plattformen in eine Großrechnerumgebung.
ON |
Gestattet jede Art von Zeichen in Klein-/Großschreibung in Source-Programmen. |
OFF |
Gestattet nur Großschreibung. Das bedeutet, dass Schlüsselwörter, Variablennamen und Identifier in Großbuchstaben definiert werden müssen. Dies ist der Standardwert. |
Wenn Sie Zeichen in Kleinschreibung mit LOWSRCE=ON
verwenden, müssen Sie folgendes berücksichsichtigen:
Die Syntaxregeln für Variablennamen erlauben es, ab der zweiten Stelle Zeichen in Kleinschreibung zu benutzen. Sie können deshalb zwei Variablen gleichen Namens definieren, indem Sie die eine in Kleinschreibung und die andere in Großschreibung angeben, zum Beispiel:
DEFINE DATA LOCAL 1 #Vari (A20) 1 #VARI (A20)
Mit LOWSRCE=OFF werden die im Beispiel
angegebenen Variablen als zwei verschiedene Variablen behandelt.
Mit LOWSRCE=ON unterscheidet der Compiler nicht
zwischen Klein- und Großschreibung. Dies führt zu einem Syntaxfehler, weil eine
doppelte Namensvergabe bei Variablen nicht erlaubt ist.
Bei Verwendung des Session-Parameters
EM (Edit
Mask) in einem I/O-Statement oder in einem MOVE EDITED-Statement gibt es
Zeichen, die das Daten-Layout, das einer Variablen
(EM-Steuerzeichen) zugeordnet ist, und Zeichen, die
Textfragmente in das Datenfeld einfügen.
Beispiel:
#VARI :='1234567890' WRITE #VARI (EM=XXXXXxxXXXXX)
Bei LOWSRCE=OFF ist die Ausgabe
12345xx67890, weil bei Variablen im Alpha-Format nur X-, H- und
Zirkumflex-(ˆ)-Zeichen in Großschreibung verwendet werden können.
Bei LOWSRCE=ON ist die Ausgabe
1234567890, weil das Zeichen x wie der Großbuchstabe C behandelt
und deshalb als EM-Steuerzeichen für dieses Feldformat
interpretiert wird. Um dieses Problem zu vermeiden, sollten Sie
Textkonstantenfragmente in Apostrophe (') einschließen.
Beispiel:
WRITE #VARI(EM=XXXXX'xx'XXXXX)
Das Textfragment wird, unabhängig von den
LOWSRCE-Einstellungen, nicht als ein
EM-Steuerzeichen betrachtet.
Da bei der Einstellung LOWSRCE=ON alle
Variablennamen in Großbuchstaben umgesetzt werden, ist die Anzeige von
Variablennamen in I/O-Statements (INPUT,
WRITE oder
DISPLAY)
unterschiedlich.
Beispiel:
MOVE 'ABC' to #Vari DISPLAY #Vari
Bei LOWSRCE=OFF ist die Ausgabe:
#Vari -------------------- ABC
Bei LOWSRCE=ON ist die Ausgabe:
#VARI -------------------- ABC
Die Option LUWCOMP prüft, ob die Syntax der seit
Natural für Großrechner Version 8.2 zur
Verfügung stehenden Funktionalität auch durch Natural für UNIX
Version 8.3 und Natural für Windows
Version 8.3 unterstützt wird. Falls
Syntaxunverträglichkeiten zwischen dem Großrechner und UNIX oder Windows
festgestellt werden, wird die Kompilierung unter Natural für Großrechner
Version 8.2 mit entsprechender Fehlermeldung und Reason Code abgebrochen.
Mögliche Werte:
ON |
Wenn ein Programm kompiliert wird, wird jeder Versuch, ein Syntaxkonstrukt zu verwenden, das von Natural für Großrechner, aber nicht von Natural für UNIX oder Natural für Windows unterstützt wird, mit dem Syntaxfehler NAT0598 und einem enstprechenden Reason Code (siehe unten) zurückgewiesen. |
OFF |
Es erfolgt keine Syntaxprüfung. Inkonsistenzen zwischen zwischen dem Großrechner und UNIX oder Windows werden ignoriert. Dies ist die Standardeinstellung. |
Die folgenden Reason Codes zeigen an, welche Syntaxteile nicht unter UNIX oder Windows unterstützt werden:
| Reason Code | Ungültige Syntax auf UNIX oder Windows |
|---|---|
| 001 | Es wird eine Variable mit Format P/N
oder eine numerische Konstante mit mehr als 7 Dezimalstellen definiert.
Beispiel: DEFINE DATA LOCAL 1 #P(P5.8) |
| 004 | Eine der beden folgenden
Compiler-Optionen wird benutzt:
Beispiel: OPTIONS MAXPREC=10 |
| 007 | In einem MOVE
ALL-Statement wird eine SUBSTR-Option beim Quell- oder
Zielfeld benutzt.
Example: MOVE ALL 'X' TO SUBSTR(#A, 3, 5) |
| 011 | Die ADJUST-Option wird in
einem READ WORK FILE-Statement benutzt, um die Größe eines
X-Array-Feldes beim Zugriff automatisch zu ändern.
Beispiel: READ WORK FILE 1 #XARR(*) AND ADJUST |
| 012 | Das in der REINPUT ...
MARK-Klausel referenzierte Feld wird mit einer
(CV=...)-Option geliefert.
Beispiel: REINPUT 'text' MARK *#FLD (CV=#C) |
| 013 | In der List der Felder bei einem
WRITE WORK FILE-Statement werden Systemvariablen referenziert. .
|
| 014 | In einem
READ- oder
FIND-Statement wird
Folgendes verwendet:
|
| 015 | Eines der folgenden beiden Statements wird benutzt: |
| 016 | Das Quellfeld in
einem SEPARATE-Statement war als ein Array definiert.
Beispiel: SEPARATE #TEXT(*) INTO ... |
| 017 |
Die POSITION-Klausel wird in einem
SEPARATE-Statement benutzt.
|
| 019 | Eine der folgenden neuen Systemvariablen wurde benutzt: |
Mit dieser Option können Sie die MASK-Option mit dem
MOVE EDITED-Statement kompatibel machen.
ON |
Der Bereich der gültigen Jahreswerte, die zu den
YYYY-Maskenzeichen passen, ist 1582 bis
2699, damit die MASK-Option mit dem MOVE
EDITED-Statement kompatibel wird. Wenn der Profilparameter
MAXYEAR auf 9999 gesetzt ist, erstreckt
sich der Bereich der gültigen Jahreswerte von 1582 bis
9999.
|
OFF |
Der Bereich der gültigen Jahreswerte, die zu den
YYYY-Maskenzeichen passen, ist 0000 - 2699. Dies ist
der Standardwert.
Wenn der Profilparameter |
Mit dieser Option können Sie die maximale Anzahl der Nachkommastellen festlegen, die der Compiler bei den Ergebnissen von arithmetischen Operationen erzeugt.
7 -
29 |
Dieser Wert gibt die maximale Anzahl der
Nachkommastellen an, die der Compiler bei den Ergebnissen von arithmetischen
Operationen erzeugt.
Der Vorgabewert ist Falls bei Zwischenergebnissen eine höhere Genauigkeit
benötigt wird, sollte der Wert von Die Einstellung von DEFINE DATA LOCAL 1 P (P1.15) END-DEFINE P := P + 0.1234567890123456 END Weitere Informationen siehe Genauigkeit von Ergebnissen bei arithmetischen Operationen im Leitfaden zur Programmierung. |
| Warnung: Wenn Sie den beim Katalogisieren eines Natural-Objekts verwendeten Wert der Option MAXPREC ändern, kann das
auch dann zu unterschiedlichen Ergebnissen führen, wenn Sie die Objekt-Source
nicht geändert haben. Siehe folgendes Beispiel: |
Beispiel:
DEFINE DATA LOCAL 1 #R (P1.7) END-DEFINE #R := 1.0008 * 1.0008 * 1.0008 IF #R = 1.0024018 THEN ... ELSE ... END-IF
Der Wert von #R nach der Berechnung und Ausführung
des IF-Statements ist abhängig von der Einstellung der Option
MAXPREC:
| Beim Kompilieren wirksame Einstellung von MAXPREC | Wert von #R | Ausgeführte Klausel des IF-Statements |
|---|---|---|
MAXPREC=7 |
1.0024018 |
THEN-Klausel
|
MAXPREC=12 |
1.0024019 |
ELSE-Klausel
|
Diese Option bestimmt, ob für unbenutzte, auf Programmebene 1
befindliche Felder oder Gruppen, die lokal definiert (DEFINE DATA
LOCAL) wurden, Speicher zugeordnet wird oder nicht.
ON |
Speicher wird zugeordnet nur für
|
OFF |
Datenspeicher wird für alle Gruppen und Felder zugeordnet, die lokal benannt wurden. Dies ist der Standardwert. |
| ON | Die Zuordnung von numerischen Variablen, bei denen Source und Target dieselbe Länge und Genauigkeit haben, erfolgt wie bei Natural Version 2.2. |
|---|---|
| OFF | Die Zuordnung von numerischen Variablen, bei denen Source und Target dieselbe Länge und Genauigkeit haben, erfolgt wie bei Natural Version 2.3 und höher, d.h., sie werden so verarbeitet, als ob Source und Target eine unterschiedliche Länge oder Genauigkeit hätten. Dies ist die Standardeinstellung. |
Prüfung der Parameter bei Objekt aufrufenden Statements.
ON |
Der Compiler prüft Anzahl, Format, Länge und
Array-Index-Grenzen der Parameter, die in einem Objekt aufrufenden Statement
(zum Beispiel CALLNAT,
PERFORM,
INPUT USING
MAP, PROCESS PAGE
USING, Function
Call, Helproutine-Aufruf), angegeben
sind. Darüber hinaus wird bei der Parameterprüfung das
OPTIONAL-Feature
des DEFINE DATA
PARAMETER-Statements berücksichtigt.
Die Parameterprüfung basiert auf dem Vergleich der
Parameter des Objekt aufrufenden Statements mit den Dazu ist folgendes erforderlich:
Andernfalls hat die Einstellung Fehler-Behandlung bei
ECHECK=ON
Die Parameterprüfung wird nur dann ausgeführt, wenn das Objekt keine syntaktischen Fehler enthält. Die Parameterprüfung wird bei jedem Statement ausgeführt, welches ein Objekt aufruft. Gesteuert wird die Parameterprüfung durch den
Profilparameter Probleme bei der Benutzung des
CATALL-Kammandos mit PCHECK=ON
Wenn ein
Wenn ein Wie zuvor erwähnt werden die Parameter des des Objekt
aufrufenden Statements gegen die kompilierte Form des aufgerufenen Subprogramms
geprüft. Wenn das rufende Objekt (das momentan kompiliert wird und das Objekt
aufrufende Statements enthält) vor dem aufgerufenen Objekt katalogisiert wird,
kann das Das hat zur Folge, dass das neue
Parameterlayout im Objekt aufrufenden Statement mit dem alten
Parameterlayout im Lösung:
|
OFF |
Es erfolgt keine Parameterprüfung. Dies ist der Standardwert. |
ON |
Das positive Vorzeichen einer gepackten Zahl wird intern als H'F' dargestellt. Dies ist der Standardwert. |
OFF |
Das positive Vorzeichen einer gepackten Zahl wird intern als H'C' dargestellt. |
Mit dieser Option können Sie beim Kompilieren die Verwendung des
Tausendertrennzeichens ermöglichen oder unterdrücken. Siehe auch Profil- und
Session-Parameter THSEPCH sowie
Abschnitt Trennzeichen-Angaben
standardisieren (im Leitfaden zur
Programmierung).
ON |
Das Tausendertrennzeichen wird verwendet. Jedes Tausendertrennzeichen, das nicht Teil eines Zeichenketten-Literals ist, wird intern durch ein Steuerzeichen ersetzt. |
OFF |
Das Tausendertrennzeichen wird nicht verwendet, d.h. der Compiler erzeugt kein Steuerzeichen für Tausendertrennzeichen. Dies ist die Kompatibilitätseinstellung. |
Mit dieser Option können Sie Anführungszeichen (") in Apostrophe (') umsetzen.
ON |
Jedes Anführungszeichen (") in einer Textkonstante wird als Apostroph (') ausgegeben. Dies ist der Standardwert. |
OFF |
Anführungszeichen (") in einer Textkonstante werden nicht umgesetzt, sondern als Anführungszeichen beibehalten. |
Beispiel:
RESET A (A5) A:= 'AB"CD' WRITE '12"34' / A / A (EM=H(5)) END
Mit TQMARK ON sieht die Ausgabe so aus:
12'34 AB'CD C1C27DC3C4
Mit TQMARK OFF sieht die Ausgabe so aus:
12"34 AB"CD C1C27FC3C4
Diese Option bestimmt, ob der Profilparameter
TS für
Natural-System-Libraries (d.h. für Libraries, deren Namen mit SYS
beginnt, außer SYSTEM) gilt oder auch für alle
Benutzer-Libraries.
Natural-Objekte, die mit der Einstellung TSENABL=ON
katalogisiert werden, bestimmen die Verwendung des
TS-Parameters auch dann, wenn sie sich nicht in einer
System-Library befinden.
ON |
Der Profilparameter TS gilt für
alle Libraries.
|
OFF |
Der Profilparameter TS gilt nur
für Natural-System-Libraries. Dies ist der Standardwert.
|