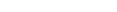
SORTKEY (character-string)
|
このシステム関数は、"不正にソートされた" 文字(または文字の組み合わせ)を、ソートプログラムまたはデータベースシステムでアルファベット順に "正しくソートされる" 他の文字(または文字の組み合わせ)に変換するために使用します。
| フォーマット/長さ: | A253 |
国によっては、ソートプログラムまたはデータベースシステムによって正確なアルファベット順にソートされない文字(または文字の組み合わせ)が言語に含まれます。コンピュータで使用される文字セットの文字のシーケンスが必ずしもアルファベット順に相当するとは限らないためです。
例えば、スペイン語の "CH" は、ソートプログラムやデータベースシステムでは 2 文字の文字列とみなされ、"CG" と "CI" の間にソートされます。しかし、実際、スペイン語では、これは "C" と "D" の間に属する 1 文字となります。
または、要求に反して、小文字と大文字がソート順で同等に扱われないこともあります。文字は(数字の前にソートされることを希望しているにもかかわらず)数字の後にソートされることもあります。あるいは、特殊文字(例:ダブル名のハイフン)によって予期しないソート順が生じることもあります。
このような場合、システム関数 SORTKEY(character-string) を使用できます。SORTKEY で計算された値はソート条件にしか使用できず、エンドユーザーとのやり取りには元の値が使用されます。
COMPUTE ステートメントおよび論理条件の算術演算オペランドとして SORTKEY 関数を使用できます。
character-string として、英数字定数や変数、または英数字配列の単一オカレンスを指定できます。
Natural プログラムに SORTKEY 関数を指定すると、ユーザー出口 NATUSKnn が呼び出されます。nn は現在の言語コード(システム変数 *LANGUAGE の現在の値)です。
このユーザー出口は、標準 CALL インターフェイスを提供する任意のプログラミング言語で記述できます。SORTKEY に指定された character-string は、そのユーザー出口に渡されます。ユーザー出口は、この文字列内の "不正にソートされた" 文字を "正しくソートされた" 文字に変換するようにプログラミングされている必要があります。続けて、変換された文字列が Natural プログラムで使用され、さらに処理が実行されます。
外部プログラムの一般的な呼び出し規則については、CALL ステートメントの説明を参照してください。
ユーザー出口の呼び出し規則の詳細については、「ユーザー出口」を参照してください。
DEFINE DATA LOCAL 1 CUST VIEW OF CUSTOMERFILE 2 NAME 2 SORTNAME END-DEFINE ... *LANGUAGE := 4 ... REPEAT INPUT NAME SORTNAME := SORTKEY(NAME) STORE CUST END TRANSACTION ... END-REPEAT ... READ CUST BY SORTNAME DISPLAY NAME END-READ ...
上記の例では、INPUT ステートメントの繰り返しの実行で、次の値が入力されるものと仮定しています。"Sanchez", "Sandino" および "Sancinto".
SORTNAME への SORTKEY(NAME) の割り当てで、ユーザー出口 NATUSK04 が呼び出されます。このユーザー出口は、最初にすべての小文字を大文字に変換し、次に文字の組み合わせ "CH" を "Cx" に変換します。この場合、x は使用する文字セットの最終文字、つまり 16 進の H'FF'(この最終文字は出力不可能な文字とみなされる)に対応します。
"元"の名前(NAME)は、希望するソート(SORTNAME)に使用する変換済みの名前とともに保存されます。ファイルを読み込むには、SORTNAME を使用します。DISPLAY ステートメントは、次のように正しいスペイン語のアルファベット順に名前を出力します。
Sancinto Sanchez Sandino