Natural は配列の処理をサポートしています。 配列は、複数次元のテーブル、つまり、単一の名前で識別される 2 つ以上の論理的に関連する要素です。 配列は、複数次元の単一データ要素、または連続する構造体や個別の要素を含む階層的なデータ構造で構成できます。
このドキュメントでは、次のトピックについて説明します。
Natural では、1 次元、2 次元、または 3 次元の配列を使用できます。 配列は、独立した変数、より大きなデータ構造の一部、またはデータベースビューの一部です。
重要:
ダイナミック変数は配列定義には使用できません。
![]() 1 次元配列を定義するには
1 次元配列を定義するには
フォーマットと長さの後に、スラッシュと "インデックス表記"、つまり配列のオカレンス数を指定します。
例えば、以下の 1 次元配列には、3 つのオカレンス(各オカレンスのフォーマット/長さは A10)があります。
DEFINE DATA LOCAL 1 #ARRAY (A10/1:3) END-DEFINE ...
![]() 2 次元配列を定義するには
2 次元配列を定義するには
両方の次元に対するインデックス表記を指定します。
DEFINE DATA LOCAL 1 #ARRAY (A10/1:3,1:4) END-DEFINE ...
2 次元配列はテーブルとして表すことができます。 上記の例で定義されている配列は、3 つの "行" および 4 つの "列" から成るテーブルです。
配列の 1 つ以上のオカレンスに初期値を割り当てるには、以下の例のように、"通常の"変数 に対する初期値定義と同様に INIT 指定を使用します。
以下の例は、初期値が 1 次元配列にどのように割り当てられるかを説明しています。
初期値を 1 つのオカレンスに割り当てる場合、次を指定します。
1 #ARRAY (A1/1:3) INIT (2) <'A'>
A は、2 番目のオカレンスに割り当てられます。
同じ初期値をすべてのオカレンスに割り当てるには、以下のように指定します。
1 #ARRAY (A1/1:3) INIT ALL <'A'>
A は、すべてのオカレンスに割り当てられます。 または、次を指定できます。
1 #ARRAY (A1/1:3) INIT (*) <'A'>
同じ初期値を複数オカレンスの範囲に割り当てるには、以下のように指定します。
1 #ARRAY (A1/1:3) INIT (2:3) <'A'>
A は、2~3 番目のオカレンスに割り当てられます。
異なる初期値を全オカレンスに割り当てるには、以下のように指定します。
1 #ARRAY (A1/1:3) INIT <'A','B','C'>
A は最初のオカレンス、B は 2 番目のオカレンス、C は 3 番目のオカレンスにそれぞれ割り当てられます。
異なる初期値をいくつかのオカレンス(全オカレンスではなく)に割り当てるには、以下のように指定します。
1 #ARRAY (A1/1:3) INIT (1) <'A'> (3) <'C'>
A は最初のオカレンス、C は 3 番目のオカレンスに割り当てられますが、2 番目のオカレンスには値は割り当てられません。
または、次を指定できます。
1 #ARRAY (A1/1:3) INIT <'A',,'C'>
オカレンス数より少ない数の初期値が指定されると、残ったオカレンスは空のままになります。
1 #ARRAY (A1/1:3) INIT <'A','B'>
A は最初のオカレンス、B は 2 番目のオカレンスに割り当てられますが、3 番目のオカレンスには値は割り当てられません。
このセクションでは、2 次元配列に初期値を割り当てる方法について説明します。 以下のトピックについて説明します。
このセクションの例では、3 オカレンスの第 1 次元("行")と 4 オカレンスの第 2 次元("列")を持つ 2 次元配列を使用するものとします。
1 #ARRAY (A1/1:3,1:4)
| (1,1) | (1,2) | (1,3) | (1,4) |
| (2,1) | (2,2) | (2,3) | (2,4) |
| (3,1) | (3,2) | (3,3) | (3,4) |
以下の最初の例では、同じ初期値を 2 次元配列のオカレンスにどのように割り当てるのかを説明します。2 番目の例では、異なる初期値をどのように割り当てるのかを説明します。
例では、* と V の表記の使用に特に注意してください。 これらの表記は両方とも、該当する次元のすべてのオカレンスを参照します。* は、その次元のすべてのオカレンスを同じ値で初期化することを示します。一方、V は、その次元のすべてのオカレンスを異なる値で初期化することを示します。
初期値を 1 つのオカレンスに割り当てる場合、次を指定します。
1 #ARRAY (A1/1:3,1:4) INIT (2,3) <'A'>
| A | |||
同じ初期値を第 2 次元の 1 オカレンス(第 1 次元の全オカレンス)に割り当てるには、以下のように指定します。
1 #ARRAY (A1/1:3,1:4) INIT (*,3) <'A'>
| A | |||
| A | |||
| A |
同じ初期値を第 1 次元のオカレンス範囲(第 2 次元の全オカレンス)に割り当てるには、以下のように指定します。
1 #ARRAY (A1/1:3,1:4) INIT (2:3,*) <'A'>
| A | A | A | A |
| A | A | A | A |
同じ初期値を各次元のオカレンス範囲に割り当てるには、以下のように指定します。
1 #ARRAY (A1/1:3,1:4) INIT (2:3,1:2) <'A'>
| A | A | ||
| A | A |
同じ初期値を全オカレンス(両方の次元)に割り当てるには、以下のように指定します。
1 #ARRAY (A1/1:3,1:4) INIT ALL <'A'>
| A | A | A | A |
| A | A | A | A |
| A | A | A | A |
または、次を指定できます。
1 #ARRAY (A1/1:3,1:4) INIT (*,*) <'A'>
1 #ARRAY (A1/1:3,1:4) INIT (V,2) <'A','B','C'>
| A | |||
| B | |||
| C |
1 #ARRAY (A1/1:3,1:4) INIT (V,2:3) <'A','B','C'>
| A | A | ||
| B | B | ||
| C | C |
1 #ARRAY (A1/1:3,1:4) INIT (V,*) <'A','B','C'>
| A | A | A | A |
| B | B | B | B |
| C | C | C | C |
1 #ARRAY (A1/1:3,1:4) INIT (V,*) <'A',,'C'>
| A | A | A | A |
| C | C | C | C |
1 #ARRAY (A1/1:3,1:4) INIT (V,*) <'A','B'>
| A | A | A | A |
| B | B | B | B |
1 #ARRAY (A1/1:3,1:4) INIT (V,1) <'A','B','C'> (V,3) <'D','E','F'>
| A | D | ||
| B | E | ||
| C | F |
1 #ARRAY (A1/1:3,1:4) INIT (3,V) <'A','B','C','D'>
| A | B | C | D |
1 #ARRAY (A1/1:3,1:4) INIT (*,V) <'A','B','C','D'>
| A | B | C | D |
| A | B | C | D |
| A | B | C | D |
1 #ARRAY (A1/1:3,1:4) INIT (2,1) <'A'> (*,2) <'B'> (3,3) <'C'> (3,4) <'D'>
| B | |||
| A | B | ||
| B | C | D |
1 #ARRAY (A1/1:3,1:4) INIT (2,1) <'A'> (V,2) <'B',C',D'> (3,3) <'E'> (3,4) <'F'>
| B | |||
| A | C | ||
| D | E | F |
3 次元配列は以下のように表すことができます。
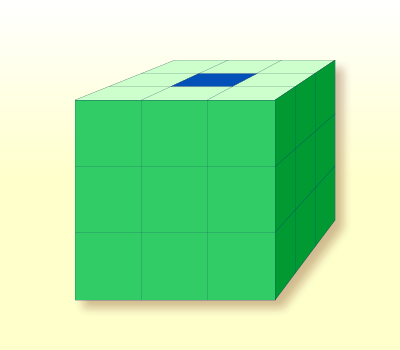
上記の配列は、以下のように定義します(同時に、行 1、列 2、および面 2 の強調表示されたフィールドに初期値を割り当てます)。
DEFINE DATA LOCAL
1 #ARRAY2
2 #ROW (1:4)
3 #COLUMN (1:3)
4 #PLANE (1:3)
5 #FIELD2 (P3) INIT (1,2,2) <100>
END-DEFINE
...
データエリアエディタでローカルデータエリアとして定義すると、同じ配列は以下のように表示されます。
I T L Name F Leng Index/Init/EM/Name/Comment
- - - -------------------------------- - ---- ---------------------------------
1 #ARRAY2
2 #ROW (1:4)
3 #COLUMN (1:3)
4 #PLANE (1:3)
I 5 #FIELD2 P 3
複数次元の配列を使用すると、COBOL または PL1 の構造体に類似したデータ構造体を定義できます。
DEFINE DATA LOCAL
1 #AREA
2 #FIELD1 (A10)
2 #GROUP1 (1:10)
3 #FIELD2 (P2)
3 #FIELD3 (N1/1:4)
END-DEFINE
...
この例では、データエリア #AREA の全体のサイズは以下のとおりです。
10 + (10 * (2 + (1 * 4))) バイト = 70 バイト
#FIELD1 は 10 バイトの長さの英数字です。 #GROUP1 は #AREA 内のサブエリアの名前で、2 つのフィールドから成り、10 オカレンスを持っています。 #FIELD2 は、パック型数値で長さは 2 です。 #FIELD3 は、4 オカレンスを持つ、#GROUP1 の 2 番目のフィールドで長さ 1 の数値です。
#FIELD3 の特定のオカレンスを参照するには、2 つのインデックスを使用する必要があります。最初のインデックスで #GROUP1 のオカレンスを指定し、2 番目のインデックスで #FIELD3 の特定のオカレンスを指定する必要があります。 例えば、同じプログラムにおいて、後から ADD ステートメントで #FIELD3 を参照するには、以下のように指定します。
ADD 2 TO #FIELD3 (3,2)
Adabas は、マルチプルバリューフィールドおよびピリオディックグループの形で、データベース内の配列構造をサポートします。 これらについては、「データベース配列」を参照してください。
以下の例は、マルチプルバリューフィールドを含むビューの DEFINE DATA での定義を示しています。
DEFINE DATA LOCAL 1 EMPLOYEES-VIEW VIEW OF EMPLOYEES 2 NAME 2 ADDRESS-LINE (1:10) /* <--- MULTIPLE-VALUE FIELD END-DEFINE ...
同じビューが、ローカルデータエリアでは以下のように表示されます。
I T L Name F Leng Index/Init/EM/Name/Comment
- - - -------------------------------- - ---- ---------------------------------
V 1 EMPLOYEES-VIEW EMPLOYEES
2 NAME A 20
M 2 ADDRESS-LINE A 20 (1:10) /* MU-FIELD
配列のオカレンス範囲を表すために簡単な演算式をインデックスとして使用できます。
例:
MA (I:I+5) |
値 I から I + 5 までの範囲のフィールド MA の値が参照されます。
|
MA (I+2:J-3) |
値 I + 2 から J - 3 までの範囲のフィールド MA の値が参照されます。
|
添字の演算に使用できる演算子は、プラス(+)およびマイナス(-)のみです。
配列演算のサポートには、配列レベル、行/列レベル、および個々の要素レベルでの演算が含まれています。
配列演算では、1 つまたは 2 つのオペランドと受け取りフィールドの 3 番目の変数(任意)を使用した簡単な演算式のみを使用できます。
添字の範囲を定義する式には、演算子プラス(+)およびマイナス(-)のみを使用できます。
以下の例では、次のフィールド定義を想定しています。
DEFINE DATA LOCAL 01 #A (N5/1:10,1:10) 01 #B (N5/1:10,1:10) 01 #C (N5) END-DEFINE ...
ADD #A(*,*) TO #B(*,*)
結果オペランドである配列 #B には、配列 #A と配列 #B の元の値を要素ごとに加算した結果が格納されます。
ADD 4 TO #A(*,2)
配列 #A の 2 番目の列は、その元の値に 4 を加えた値で置き換えられます。
ADD 2 TO #A(2,*)
配列 #A の 2 番目の行は、その元の値に 2 を加えた値で置き換えられます。
ADD #A(2,*) TO #B(4,*)
配列 #A の 2 番目の行の値は、配列 #B の 4 番目の行に加算されます。
ADD #A(2,*) TO #B(*,2)
これは不正な演算であるため、構文エラーが発生します。 行は行に、列は列にのみ加算できます。
ADD #A(2,*) TO #C
配列 #A の 2 番目の行のすべての値は、スカラ値 #C に加算されます。
ADD #A(2,5:7) TO #C
配列 #A の 2 番目の行の 5、6、7 番目の列の値がスカラ値 #C に加算されます。