
This document describes the utility "ADASEL".
The following topics are covered:
The ADASEL utility selects records from Protection log files and WORK containers.
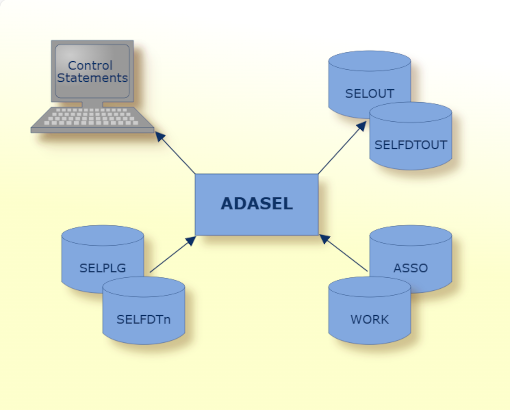
|
Data Set |
Environment Variable/Logical Name |
Storage Medium |
Additional Information |
|---|---|---|---|
|
Associator |
ASSOx |
Disk |
n/a |
|
Alternate FDTs |
SELFDTn |
Disk |
Only required if you process a query with keyword FDTINPUT, to read the FDT from a file (file number 'n'), instead of the database. In case all files are defined as alternate FDT, then no database is required. |
|
Optional output |
SELOUT |
Disk |
The output file location can be defined here. Otherwise, the output is written to stdout. |
|
Optional FDT output |
SELFDTOUT |
Disk |
The FDT output file location can be defined here. The FDTs used in the selection will be exported here, if the FDT parameter is selected. |
|
Protection log |
SELPLG |
Disk |
The input PLOG file is defined here. Alternatively, a directory can be specified here, so that all NUCPLG files in there will be processed. |
|
Control statements |
stdin |
- |
Utilities Manual |
|
ADASEL report |
stdout |
- |
Messages and Codes |
|
Work storage |
WORK1 |
Disk |
Utilities Manual |
The sequential file SELPLG can have multiple extents. For information about sequential files with multiple extents, see Adabas Basics, Using Utilities.
The utility writes no checkpoints.
The following control parameters are available:
D DATASET = { PLOG | WORK }
DBID = number
[NO]DELTA
FDT
FILE = <filepath>
FORMAT = { CSV | DISPLAY | JSON | JSONPRETTY }
SELECT = <select query>
SELECTALL { = FDTINPUT }
SEPARATOR = character | \character
D [NO]STAT
Note
The query is case insensitive.
DATASET = { PLOG | WORK }
This parameter selects the file containing the protection log information to be processed. The keyword can take the values PLOG or WORK, where PLOG is the default.
adasel: dataset=work
The WORK dataset is selected.
DBID = number
This parameter behaves differently based on the dataset defined.
PLOG dataset
It can be used to select a different database than the one defined in the PLOG file. The default is the database number defined in the PLOG file.
WORK dataset
It must be used to define the database containing the WORK dataset. There is no default in this case.
adasel: dbid=200
The database currently being used is database 200. The PLOG dataset is selected by default.
adasel: dbid=200 dataset=WORK
The database currently being used is database 200. The WORK dataset is selected.
[NO]DELTA
This parameter indicates whether only changed fields are displayed after an update. The produced output remains the same for inserted and deleted records. The delta record will be built for updated records, where only modified field values are generated. The default is NODELTA.
FDT
The file FDTs used in the selection will be exported as JSON with this parameter. This will be written to a file, if the environment variable SELFDTOUT is defined. Otherwise, it is printed to stdout.
FILE = <filepath>
This function reads a text file containing one or more queries on the dataset.
adasel: file=query.in
The content of the file query.in will be executed on the dataset.
FORMAT = { CSV | DISPLAY | JSON | JSONPRETTY }
This parameter selects the output format. The selection CSV creates a “comma-separated values” output. If DISPLAY is selected, then the output format will be similar to the mainframe output. The JSON and JSONPRETTY selections create a JSON file in CDC style. The JSON format is for machine processing, while the JSONPRETTY format is human readable. The default is DISPLAY.
SELECT = <select query>
The select function executes a text string containing one or more queries on the dataset.
adasel: select=select all from file 1 display all end
The specified query will be executed on the dataset.
SELECTALL { = FDTINPUT }
The 'select all' function creates an output containing the complete content of the dataset. This happens without any library call. If the optional parameter FDTINUT is set, then FDT information will be retrieved from the files defined in the environment variable(s) SELFDTn.
SEPARATOR = character | \character
This parameter defines the separator character for the CSV output. The default is comma.
[NO]STAT
This function enables or disables the display of performance statistics at the end of the execution. The default is NOSTAT.
adasel: stat
------------------------------------------------------------------------------------------------
Total run time: 84,371,489 us, 84.37 sec
Library init/next: 814 us
Processing time: 67,242,964 us, 67.24 sec, 14,581,622 PLOG records
Process FDT cache: 1,202,276 us, 1.20 sec, 1,199,999 hits, avg: 1 us
100 % hit rate, 1 file(s)
Decompress time: 3,707,651 us, 3.70 sec, 1,200,000 records, avg: 3 us
Library run: 33,869,021 us, 33.86 sec, 1,200,000 calls, avg: 28 us
Print time: 8,331,534 us, 8.33 sec, 1,200,000 records
Library finish: 36 us
----- Library measurements ------------
Init/Next Total: 400 us
Init/Next Set-Up: 147 us
Compile query: 238 us
Stackm. Set-Up: 2 us
Criterion handover: 11 us
Run Total: 45,322,926 us
Run Setup: 73,677 us
Parsing PLOG: 6,271,616 us
Stack machine: 12,986,070 us
Run Handover: 25,991,563 us
------------------------------------------------------------------------------------------------
The following paragraphs detail the currently implemented keywords, their control flow, and their function. The keywords are given in capital letters but can be written in any case.
The only exceptions from this rule are field names. These are case sensitive, making AA1 different from Aa1, aA1, and aa1. On top of that, special formatting and naming rules apply, which are explained further down. See FDT Record Structure for more naming recommendations.
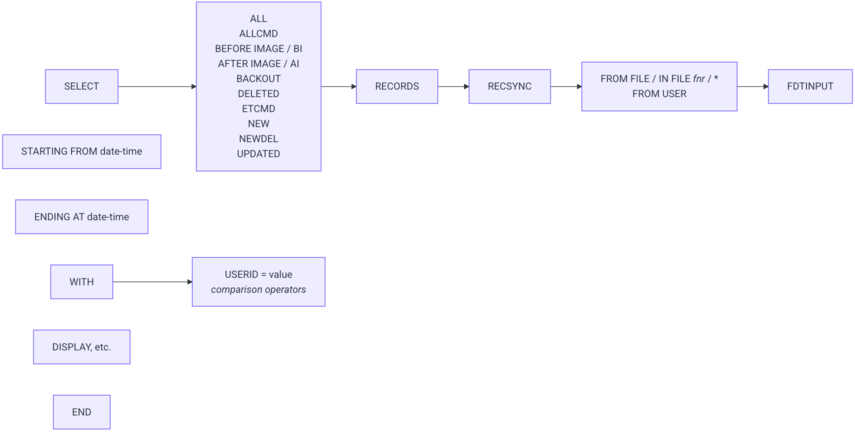
SELECT
Marks the beginning of a query
Must be paired with an END statement
Select options:
ALL
Is a combination of all options except BACKOUT and
ETCMD
ALLCMD
Is a combination of all select options
BEFORE IMAGE / BI
Selects before images derived from A1 and E1 commands
Alternatively, the shorter form SELECT BI can be used
AFTER IMAGE / AI
Selects after images derived from A1 and N1 commands
Alternatively, the shorter form SELECT AI can be used
BACKOUT
Selects before and after images derived from BT commands
DELETED
Selects before images derived from E1 commands
ETCMD
Selects ET information
NEW
Selects after images derived from N1 commands
NEWDEL
Selects after images derived from N1 and E1 commands
UPDATED
Selects before and after images derived from A1 commands
RECORDS
Optional keyword, may be omitted
Mode options:
The mode options are mutually exclusive, only one can be used at a time
FROM FILE / IN FILE
Marks the selection of blocks based on file number
* (asterisk) can be used for searching all files
File number or * have to follow immediately after
FROM FILE and IN FILE have the same function, they act like synonyms
FROM USER
Marks the selection of blocks by user
Username can be supplied in WITH statement
If username is omitted, blocks from all users are displayed
This can act as an alternative to SELECT FROM FILE *
FDTINPUT
Marks the use of an external FDT
The FDT has to be supplied in the environment variable SELPLGn
STARTING FROM
ENDING AT
Sets a timeframe for the selection of a PLOG record
The borders are inclusive
The date and time can be supplied in the following ways:
Gregorian in the format YYYYMMDD/HHMMSS
Julian in the format J(YYYYDDD/HHMMSS)
The time zone of the supplied date and time will be the one of the local machine, but then converted to a Unix timestamp in UTC
If omitted, it defaults to the timeframe
Unix timestamp 0 (January 1, 1970 00:00:00 (UTC))
Unix timestamp 9223372036854775807 (max_int64, theoretically August 17, 292278994 07:12:55 (UTC))
If given, overrides the corresponding default value
WITH
Acts like a second stage for the SELECT statement
For more restrictive and faster processing, less record decompression, and fewer query calls,
evaluated PLOG blocks can be limited using the following parameters with =:
USER, e.g. USER = 'testuser'
NODE, e.g. NODE = 'testnode'
LOGIN, e.g. LOGIN = 'nodeuser'
ESPID, e.g. ESPID = 123456
To avoid logical inconsistencies, only one of the above parameters is allowed
Conditional statements can only be joined with AND
More elaborate conditional statements can be specified in an IF block
END
Marks the end of a SELECT statement or query
Note
The RECSYNC keyword is always set to TRUE for correct processing of
PLOG blocks and no longer needs to be specified by the user. Therefore, it is omitted
from the syntax.
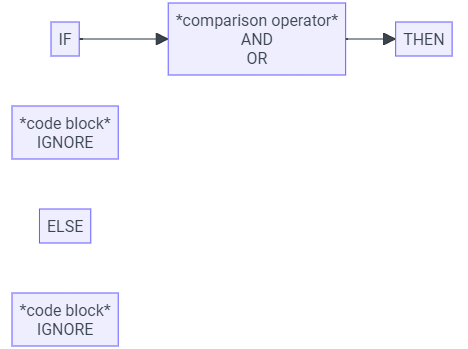
IF
Provides a conditional logic similar to other programming languages
Accepts every comparison operator
Comparison operators can be connected with OR as well as AND
IFs can also be nested
When DISPLAY clause comes beforehand, use IFF to avoid
ambiguities in case of a single-line query or when the DISPLAY clause
is on the same line
THEN
Keyword is optional
Marks the part if logical statement is true
ELSE
Code block that is executed when the conditional statement is false
IGNORE
Stands in for an empty code block
DO / DOEND
Acts similar to curly brackets in other programming languages
Can be used to enclose a multi-line code block for THEN or ELSE part
Can be omitted if code is on a single line only
Evaluates a statement to TRUE or FALSE
Evaluates fields against literals or literals against literals
The evaluation depends on the format of the first literal value
Statement will either evaluate numerical comparison or string comparison
AA = 'Test' => string comparison
AB(1) >= 10 => numerical comparison
USER < '*adatst ' => string comparison
SESSNUM != 2 => numerical comparison
If the value formats do not match a runtime error is thrown
If two fields are compared, a numerical comparison is attempted first, if it fails a string comparison will occur
If a field which is not contained in a record is used in a comparison, the
statement will default to FALSE
EQUAL
Can be specified by EQUALS, EQUAL, EQ, or
=
GREATER THAN
Can be specified by GREATER THAN, GT, or >
LESS THAN
Can be specified by LESS THAN, LT, or <
GREATER THAN OR EQUAL
Can be specified by GREATER EQUAL, GE, or >=
LESS THAN OR EQUAL
Can be specified by LESS EQUAL, LE, or <=
NOT EQUAL
Can be specified by NOTEQUAL, NOT EQUAL, NE,
¬=, ^=, or !=
THRU
Specifies a range of values
The borders are inclusive
Syntax can only be used with equal operator, e.g.
AA EQ 10 THRU 50
USERID EQ 'USER_0 ' THRU 'USER_10'
CHANGES
Tracks if a field changes from before image to after image during an update command, for example:
AA CHANGES
BB2(3) CHANGES
TRUE if field changes, has been added, or removed
FALSE if field stays the same or does not belong to an update command
Only one field can be used per query
Select options, like SELECT BEFORE IMAGE or SELECT AFTER IMAGE can be used to
only display changed before or after images
OR
Joins two conditional operations together
Evaluates to TRUE if one of the two or both operations are TRUE
AND
Joins two conditional operations together
Evaluates to TRUE if both operations are TRUE
When used in conjunction, AND takes precedence over OR, similar to how
multiplication is "faster" than addition
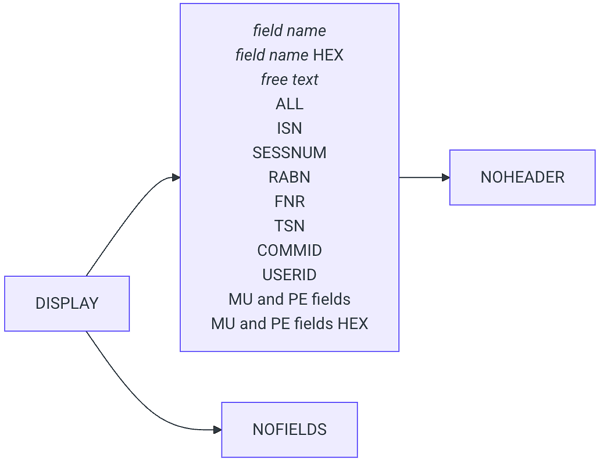
DISPLAY
Prints content to STDOUT or SELOUT, if specified.
Must be enclosed in a SELECT statement.
Prints a header section for each record.
For multi-line queries, the DISPLAY clause ends after a new
line
Is followed by an output specifier:
field name
Prints the content of one field.
Field names must follow the patterns [A-Za-z][A-Za-z0-9], [A-Za-z][A-Za-z0-9]d+ or [A-Za-z][A-Za-z0-9]d+(d+), for example, AA, zA5, bb5(10).
If the specified field is missing from a record, it will not be displayed.
free text
Prints a free text, text has to be encased in quotation marks.
ALL
Prints all data fields in the record.
ISN
Prints the ISN of the record.
SESSNUM
Prints the session number of the record.
MU and PE fields
Format XXI(J):
XX: field specifier
I: PE number
J: MU number
XXJ / XXI(J): Prints the specified field.
XXI(1-n): Prints all MU fields in the given range for a given PE field I.
e.g. AA5(1-10): Prints the fields AA5(1)
through AA5(10).
XXI(1-N): Searches and prints all MU fields for a given PE field I.
XX1-n(J): Prints the given MU field J for a given range of PE fields.
e.g. AA1-10(5): Prints the fields AA1(5)
through AA10(5).
XX1-N(J): Searches and prints all PE fields that have a given MU field J.
XX1-N(1-N): Searches and prints all PE and MU fields.
RABN
Prints the Relative Adabas Block Number (RABN) of the record.
FNR
Prints the file number of the record.
COMM
Prints the communication ID of the record.
TSN
Prints the transaction number of the record.
ESPID
Prints the process ID of the record.
USER
Prints the name of the Adabas user who modified the data in the record.
NODE
Prints the name of the node (executing computer) on which the record was modified.
LOGIN
Prints the login ID of the user on the executing computer who modified the record.
CMDCOUNT
Prints the sequence number of the command that created or modified the PLOG block.
NOHEADER
Switches off the output of the header.
The header will be turned off for all output produced.
Has no effect for the options format=json or
format=jsonpretty.
NOHEADER only needs to be specified once per SELECT statement.
NOFIELDS
Suppresses record decompression and output of fields.
Cannot be used in conjunction with any other keywords in DISPLAY.
Since no record decompression happens, fields, e.g. AA = 10 or
AB(1) != 100
cannot be used in conditional statements within IF or WHEN.
Only header information such as SESSNUM, ISN,
RABN, FNR, COMM,
TSN, CMDCOUNT, ESPID, USER,
and LOGIN are allowed.
Notes:
The output of a display command contains a header section and an output body. An example in the main frame format can look as follows:
SELECT ALL FROM FILE 1
DISPLAY 'GIVE ME FIVE' USER SESSNUM ISN ALL
END
SNR FNR ISN COMM TSN USER LOGIN AFTER IMAGE 2026-02-12 12:32:42
1 1 4626 4 1 *adatst xxxx
- GIVE ME FIVE
USER *adatst
SESSNUM 1
ISN 4626
AA 100
AD USER_0
AF
AG
AN XY
For the main frame format, the header section contains the following fields:
session number
file number
ISN
communication ID
transaction number
user ID
login ID
record type
time stamp of the data block
The body of the output lists the desired output fields as described in the query. In
the example, e.g. the output specifier ISN results in the display of the
corresponding number and the specifier ALL lists all the data fields
contained in the block. The result of each output specifier will always be printed in a
separate line. It is possible to combine multiple specifiers in one DISPLAY
command or have multiple DISPLAY commands.
The same example in JSON format can look like this:
{
{
"PLOG":[
{
"action":"insert",
"after":{
"sessnum":1,
"time":1770895962,
"rabn":138,
"isn":4626,
"fnr":1,
"comm":4,
"tsn":1,
"user":"*adatst",
"login":"xxxx",
"fields":{
"-":"GIVE ME FIVE",
"user":"*adatst ",
"sessnum":"1",
"isn":"4626",
"AA":"100",
"AD":"USER_0",
"AF":" ",
"AG":" ",
"AN":"XY"
}
}
}
]
}
The JSON format lists all blocks as an array structure. This structure is machine
readable and can be used to interface with other applications, programs, scripts, etc.
The option format=json produces a compact output which is more memory
efficient. The option format=jsonpretty produces the output above with tabs
and line breaks for better readability.
Yet the same example in CSV format can look like this:
action,session,time,rabn,isn,fnr,comm,tsn,user,login,fields AI,1,1770895962,138,4626,1,4,1,*adatst,xxxx,GIVE ME FIVE,*adatst ,1,4626,100,USER_0, , ,XY AI,1,1770895962,151,4627,1,4,1,*adatst,xxxx,GIVE ME FIVE,*adatst ,1,4627,101, , ,ABC,DEF,GHI,ZZ AI,1,1770895962,151,4628,1,4,1,*adatst,xxxx,GIVE ME FIVE,*adatst ,1,4628,102, , ,ABC,AA,5,LT
The CSV format list all blocks in a table structure and can be produced with the option
format=csv. The output is either machine readable or can be evaluated
with a spreadsheet program, e.g. Microsoft Excel. The content of the header section is
identical to the main frame and json format. Selected records with header and field
information follow below.
The OUTPUT command on the mainframe version of ADASEL was meant to produce a
machine-readable hex dump.
For the Linux version, use the option format=json or format=jsonpretty.
NEWPAGE
In the mainframe version, it was meant to create a page break or feed paper through to the next top of the page.
For the Linux version, the keyword is parsed for backwards compatibility, but no new page is generated.

SKIP
Produces line breaks in the output
If ADASEL is called with the option format=json or format=jsonpretty,
no line break will be produced
Number of lines:
Specifies the number of lines to be skipped
Can be omitted
If omitted, it will produce 1 line break
LINES
Closes SKIP instruction
Keyword can be omitted
Examples:
SKIP: produces one line break
SKIP 2: produces two line breaks
SKIP 3 LINES: produces three line breaks
The following section lists examples and special cases.
In this example a DISPLAY clause is directly followed by an
IF clause. The first case is a multi-line query, the second case a
single-line query.
SELECT ALLCMD FROM FILE * DISPLAY AA IF ISN = 1 DISPLAY BB END --- SELECT ALLCMD FROM FILE * DISPLAY AA IFF ISN = 1 DISPLAY BB END
For a multi-line query, the DISPLAY clause ends at the line break and does
not need any further consideration.
For a single-line query, it is unclear where the DISPLAY clause ends.
Using an IF clause would be interpreted as a field identifier and is
necessary should a field IF be required. To resolve this situation, an IFF
clause should be used. This signals an end of the DISPLAY clause and allows
for correct parsing of the following IF clause.