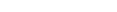
This document describes the utility "ADAULD".
The following topics are covered:
The utility ADAULD unloads an Adabas file, i.e. records are retrieved from a database or an Adabas backup copy, and written to a sequential file.
The main reasons for unloading a file are:
To change the space allocation, to reduce the number of logical extents assigned to the index, Address Converter or Data Storage, and/or to change the padding factor. In this case, the file has to be unloaded, deleted and reloaded. These features are also available with ADAORD;
To create one or more test files, all containing the same data. This procedure requires a file to be unloaded and then reloaded using a different file number. This feature is also available with ADAORD;
To extract data from a file for subsequent input to ADAMUP. This is useful for moving records from a production database to an archive database;
To re-establish a file that has been archived on an Adabas backup copy.
When unloading a file from a database, the records may be unloaded in:
- Logical sequence
The records are unloaded in an ascending sequence based on the values of a user-specified descriptor;
- ISN sequence
The records are unloaded in ascending ISN sequence;
- Physical sequence
The records are unloaded in the order in which they are physically located in Data Storage.
Unloading in logical or ISN sequence requires the nucleus to be active. The nucleus is not required when unloading in physical sequence, provided ADAULD has access to the database container files.
When unloading from an Adabas backup copy, the records are unloaded in the sequence in which they were stored by ADABCK. This is generally in ascending data RABN sequence. However, this sequence cannot be guaranteed when the DRIVES option was used or when the dump was made online (please refer to the DRIVES option of the utility ADABCK for more detailed information).
The unloaded records are output in compressed format and are identical to the records produced by the compression utility ADACMP. Since each data record is preceded by its ISN, these ISNs can be used as user ISNs when reloading the file (please refer to the USERISN option of the utility ADAMUP for more detailed information).
The user can specify that the descriptor values required to recreate the index for the file are omitted during the UNLOAD process (SHORT option). This reduces the unload processing time. This option must not be used if the output is intended as direct input for ADAMUP.
Note
If the file contains collation descriptors, the ICU version is
not changed for the unloaded data. You can load the data with ADAMUP to a file
with the same fields, but a different ICU version only if the file is empty,
and if you use the NEW_FDT option for ADAMUP.
After completion, ADAULD returns one of the following exit status values:
- 0
Records have been successfully unloaded, and no database corruption was detected.
- 12
The unload was successful, but corrupted data records were detected, which were not unloaded. It is recommended that you run ADAVFY in order to obtain more information about the database corruptions.
- 15
The unload was successful, but no records were unloaded. In scripts, you can check for this status value if further activities are required only after unloading at least one record.
- 255
Unload was not successful.
This utility is a single-function utility. For more information about single- and multi-function utilities, see Adabas Basics, Using Utilities.
Encryption:
When using ADAULD on encrypted data, the corresponding encryption context is derived in the following way:
When unloading from an encrypted database, the encryption information stored in ASSO1 is used.
When unloading from one or multiple BCK-files, the encryption information in BCK001 is used.

The sequential files ULD00n, ULDDTA, ULDDVT can have multiple extents. For detailed information about files with multiple extents, see Adabas Basics, Using Utilities.
The sequential files ULDDTA, ULDDVT can have multiple extents. For detailed information about files with multiple extents, see Adabas Basics, Using Utilities.
|
Data Set |
Environment Variable/ Logical Name |
Storage Medium |
Additional Information |
|---|---|---|---|
|
Associator |
ASSOx |
Disk |
see note 2 |
|
Data storage |
DATAx |
Disk |
see note 2 |
|
Backup copy |
ULD00n |
Disk |
Output of ADABCK's DUMP function, input for ADAULD |
|
Unloaded data |
ULDDTA |
Disk (see note 1) |
|
|
Unloaded descriptor values |
ULDDVT |
Disk (see note 1) |
|
|
Control statements |
stdin |
Utilities Manual |
|
|
ADAULD messages |
stdout |
Messages and Codes |
|
|
Temporary storage |
TEMPx |
Disk |
see note 3 and 4 |
|
Work storage |
WORK1 |
Disk |
see note 2 |
Notes:
The following table shows the nucleus requirements for each function and the checkpoint written:
| Function | Nucleus must be active | Nucleus must NOT be active | Nucleus is NOT required | Checkpoint written |
|---|---|---|---|---|
| BACKUP_COPY | X | - | ||
| DBID | X(see note 1) | X(see note 3) | X(see note2) | SYNX |
Notes:
The following control parameters are available:
BACKUP_COPY = number, FILE = number
[,FDT]
[,NUMREC = number]
D [,[NO]ONLINE]
D [, [NO]SHORT | [NO]SINGLE_FILE ]
[,SKIPREC = number]
D [,[NO]USEREXIT]
DBID = number , FILE = number
[,FDT]
D [,[NO]LITERAL]
[,NUMREC = number]
[,SEARCH_BUFFER = string, VALUE_BUFFER = string]
D [, [NO]SHORT | [NO]SINGLE_FILE ]
[,SKIPREC = number]
[,SORTSEQ = { string | ISN } ]
[,STARTISN = number]
D [,[NO]USEREXIT]
BACKUP_COPY = number
,FILE = number
[,FDT]
[,NUMREC = number]
[,[NO]ONLINE]
[,[NO]SHORT | [NO]SINGLE_FILE ]
[,SKIPREC = number]
[,[NO]USEREXIT]
This function unloads records from an Adabas backup copy. You are not allowed to specify a LOB file. "BACKUP_COPY=number" specifies the ID of the database from which the backup copy was derived, and "FILE=number" specifies the file number. Both offline and online backup copies can be used. If a LOB file is assigned to the file specified, a partial reload using the ADAMUP parameters NUMREC, SKIPREC is not possible.
This parameter displays the FDT of the file to be unloaded.
This parameter specifies the file to be unloaded.
This parameter limits the number of data records retrieved from the file when unloading. All records are unloaded if NUMREC is omitted and SKIPREC is not specified. You cannot use NUMREC if a LOB file is assigned to the file to be reloaded.
This option indicates whether the backup copy might contain online data storage blocks for the file to be unloaded.
If the backup copy is expected to contain online data storage blocks, two passes are made when processing the backup copy. This is because the most recent version of each data storage block has to be found. Setting this option to NOONLINE unloads in one pass and saves a considerable amount of processing time, at the risk of ADAULD terminating with an error message if an online data storage block is detected.
The default used depends on whether or not the Adabas nucleus was active when the backup was made.
This option indicates whether the descriptor values used to build up the index should be included in the output or omitted.
If SHORT is specified, no descriptor values are unloaded.
If the output is intended as direct input for the mass update utility, the file must be unloaded in NOSHORT mode.
SHORT and SINGLE_FILE are mutually exclusive.
NOSHORT is the default.
If this option is set to SINGLE_FILE, ADAULD writes the DVT and DATA information to a single data set (ULDDTA).
SINGLE_FILE and SHORT are mutually exclusive.
The default is NOSINGLE_FILE.
This parameter specifies the number of records to be skipped before unloading is started. You cannot use SKIPREC if a LOB file is assigned to the file to be reloaded.
A user-written routine is dynamically loaded. A pointer to an input parameter block and a pointer to an output parameter are passed with each call (please see the include file adauex.h for more information). For each record retrieved from the database, the decision can be made whether to unload the record (write it to the unload file), skip it or terminate execution immediately.
The environment variable/logical name ADAUEX_7 must point to a user-written routine.
See Adabas Basics, User Exits and Hyperexits for more details.
NOUSEREXIT is the default.
DBID = number
,FILE = number
[,FDT]
[,[NO]LITERAL
[,NUMREC = number]
[,SEARCH_BUFFER = string]
[,[NO]SHORT | [NO]SINGLE_FILE ]
[,SKIPREC = number]
[,SORTSEQ = { string | ISN }]
[,STARTISN = number]
[,[NO]USEREXIT]
[,VALUE_BUFFER = string]
This function unloads records from the specified database.
This parameter displays the FDT of the file to be unloaded.
This parameter specifies the file to be unloaded. You are not allowed to specify a LOB file.
If this option is set to LITERAL, leading blanks and lower case characters can be specified in the value buffer and remain relevant in the string, i.e. they are not removed or converted to upper case. If NOLITERAL is set, lower case characters will be transformed to upper case, and leading blanks will be suppressed except when the value is specified as a hexadecimal value.
NOLITERAL is the default.
This parameter limits the number of data records retrieved from the file when unloading. All records of the file are unloaded if NUMREC is omitted and SKIPREC or STARTISN are not specified.
This parameter is used to restrict the unloaded records to those which meet the selection criterion provided. The selection criterion must be provided according to the syntax for search buffer entries as described in the Command Reference Manual.
The maximum length of this parameter is 200 bytes. For complex entries, use the following method:
adauld: search_buffer=aa,20,a,d,\ > ab,10,a.
ADAULD will concatenate this to:
aa,20,a,d,ab,10,a.
The values which correspond to the selection criterion are provided by the VALUE_BUFFER parameter.
This option indicates whether the descriptor values used to build up the index should be included in the output or omitted.
If SHORT is specified, no descriptor values are unloaded.
If the output is intended as direct input for the mass update utility, the file must be unloaded in NOSHORT mode.
SHORT and SINGLE_FILE are mutually exclusive.
NOSHORT is the default.
If this option is set to SINGLE_FILE, ADAULD writes the DVT and DTA information to a single data set (ULDDTA).
SINGLE_FILE and SHORT are mutually exclusive.
The default is NOSINGLE_FILE.
This parameter specifies the number of data records to be skipped before unloading is started.
When used together with the STARTISN parameter, positioning is carried out before skipping.
This parameter controls the sequence in which the file is unloaded. If specified, it may either contain the field name of a descriptor, sub- or superdescriptor (1) or the keyword `ISN' (2). The default is physical sequence (3).
Logical sequence
If a string specifies a field name of a descriptor or sub/superdescriptor, the records are unloaded in ascending logical sequence of the descriptor values to which the field name refers. The field name must not refer to a descriptor contained within a periodic group.
If the field name refers to a descriptor which is a multiple-value field, the same record may be unloaded more than once (once for each different descriptor value in the record). Therefore, it is not recommended to use this type of descriptor to control the unload sequence.
If the field name refers to a descriptor defined with the NU or NC option, the records with a null value for the descriptor are not unloaded.
ISN sequence
If `ISN' is specified, the records are unloaded in ascending ISN sequence.
Physical sequence
If the SORTSEQ parameter is omitted, the records are unloaded in the physical sequence in which they are stored in the Data Storage.
If a search buffer has been specified and the SORTSEQ parameter has been omitted, the records are unloaded in ascending ISN sequence.
If the SORTSEQ = ISN option is used or a search buffer is provided, the STARTISN parameter may be specified to start unloading at a given ISN rather than from the lowest ISN in the file. If the specified ISN does not exist, unloading starts at the next highest ISN found.
A user-written routine is dynamically loaded. A pointer to an input parameter block and a pointer to an output parameter are passed with each call (please see the include file adauex.h for more information). For each record retrieved from the database, the decision can be made whether to unload the record (write it to the unload file), skip it or terminate execution immediately.
The environment variable/logical name ADAUEX_7 must point to a user-written routine.
See Adabas Basics, User Exits and Hyperexits for more details.
NOUSEREXIT is the default.
If a selection criterion is specified with the SEARCH_BUFFER parameter, this parameter is used to supply the values which correspond to the selection criterion. The maximum length of this parameter is 2000 bytes.
Note
See also [NO]LITERAL, which controls the conversion of the
value buffer to upper case.
adauld: backup_copy = 3, file = 6
File 6 on the backup copy of database 3 is unloaded. A TEMP data set and two passes through the backup copy may be required, depending on the default setting of the [NO]ONLINE option.
adauld: backup_copy = 3, file = 6 adauld: single, noonline
The same file is unloaded. Both data records and descriptor value table entries are written to the same output file. The backup copy is processed in one pass as no online blocks are expected. No TEMP data set is required.
adauld: dbid = 3, file = 6, skiprec = 100
File 6 in database 3 is unloaded. The records are unloaded in the physical sequence in which they are stored in the Data Storage. The first 100 records found are not written to the output files.
adauld: dbid = 3, file = 6 adauld: numrec = 10 adauld: sortseq = ab adauld: short
Ten records from file 6 in database 3 are unloaded. The values of the descriptor AB are used to control the sequence in which the records are retrieved. The values required to re-create the inverted list when reloading are omitted.
adauld: dbid = 3, file = 6, sortseq = isn, startisn = 123
File 6 in database 3 is unloaded. The records are unloaded in ascending ISN sequence starting at ISN 123.
When unloading from an Adabas backup copy without the NOONLINE option set, the TEMP data set is required to accumulate information about online block occurrences.
The formula TRH=DRH/1000 can be used as a rough estimate with the default TEMP block size (4 kilobytes).
The following formula may be used to calculate the exact requirements:
X = ENTIRE ((DRH / BSTD) * 4) TRH = X + ENTIRE (X / BSTD / 8) + 1
where:
ADAULD has no restart capability. An interrupted ADAULD run must be re-executed from the beginning.