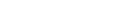
This document covers the following topics:
If a program is to access data in an Adabas database, it must issue Adabas commands (for further information, refer to the Command Reference section). Because the Adabas direct-call command interface is a low-level interface, Software AG also offers several higher-level interfaces to Adabas:
The development environment Natural, where the access to Adabas is integrated in the programming language.
The Adabas SQL Gateway, which is an SQL interface for Adabas.
The Adabas SOA Gateway, which is the Adabas interface into a service-oriented architecture (SOA).
A program that issues Adabas commands is called an Adabas client. The Adabas commands are executed by a database server called the Adabas nucleus.
In order to access the database, the Adabas client must be linked with an Adabas interface, for example ADALNKX, which is part of the Adabas client package. For further information, refer to Command Reference, Linking Application Programs.
The Adabas client may either run locally on the same (physical or virtual) machine as the Adabas nucleus, or remotely on another machine. The additional product Entire Net-Work is required for remote access.
In addition to the Adabas nucleus, there are also a number of Adabas utilities for database administration purposes, which access the Adabas database.
The following figure shows how programs access Adabas:
Note
The database containers can also be stored on separate storage
servers.
Caution
The database containers may be accessible from different
machines. However, the consistency of the database is only guaranteed if
all utility and nucleus processes accessing the database containers of a
database concurrently are running on the same machine, because IPC
resources only visible on the same machine are used for the synchronization
between the utility and nucleus processes. An exception is remote utilities
that do not access the database containers, but perform special remote Adabas
calls. When all utility and nucleus processes for a database have been
terminated, you can restart the database processes on another machine, but the
database administrator is responsible to ensure that no database process is
started on the new machine as long as a database process for the database is
still active on the old machine; this is not checked by Adabas.
The performance of a system is measured by the time and computer resources required to run it. These may be important for the following reasons:
Some system functions may have to be completed within a specified time;
The system may compete for computer resources with other systems which have more stringent time constraints.
Performance may not, however, be the most important objective. Trade-offs will often have to be made between performance and the following:
Flexibility;
Data independence;
Accessibility of information;
Security considerations;
Currency of information;
Ease of scheduling and impact on concurrent users of the database;
Disk space.
In some cases, performance may be a constraint to be met rather than an objective to be optimized. If the system meets its time and volume requirements, attention may be turned from performance to other areas.
The need to achieve satisfactory performance may affect one or more of the following:
Hardware design;
The design of the database;
The options used when loading data into the database;
The logic of application functions (for example, whether to use direct access or a combination of sorts and sequential accesses);
Operations procedures and scheduling.
Performance requirements must be considered early in the system design process. The following procedure may be used as a basis for controlling performance:
Obtain from the users the time constraints for each major system function. These requirements are likely to be absolute, i.e., the system is probably useless if it cannot meet them;
Evaluate if the available hardware resources are sufficient, either by experience with other databases, or by simulating the expected load. If you need new hardware consider the following:
You may have to decide between computers with a small number of fast, but expensive hardware threads, and computers with a large number of cheap, but relative slow hardware threads. Often the computers with the large number of hardware threads provide larger computing power for less money, but only if the parallelism can really be used. Adabas is able to use these hardware threads in parallel, when there are enough parallel users, but if you use Adabas mainly to run sequential batch programs without parallelism, Adabas is not able to work in parallel.
The hardware threads may be distributed across more than one socket, and the sockets may be distributed across more than one board. In such a case, the synchronization times between the hardware threads may be significantly longer when they are on different sockets than when they are on the same socket. A synchronization is always required when a database block is read from the buffer pool, and because each database command must read several database blocks (index and data blocks, address converter, file control block, field description table), the advantage of having more computing power by means of additional threads may be outranged by the increased synchronization times if additional threads are on a different socket or board.
Another problem is that the memory is usually distributed across the sockets; access to the socket's own memory is relatively fast, while access to the memory belonging to a different socket is relatively slow, especially if it is located on a different board. Depending on the hardware, the access times to remote and local memory differ by a factor of a little more than 1 and about 3 (NUMA architecture: Non-Uniform Memory Access).
Therefore, you should restrict ADANUC to hardware threads on the same socket or board. This can be achieved with special operating system commands, or by using operating system virtualization concepts. Usually you get a better performance this way - the reduced synchronization costs and the faster memory access to local memory is larger than the advantage of more parallelization.
In order to increase the performance on such modern architectures, Adabas uses the concept of Adabas Processing Units (ADANUC parameter APU): one Adabas processing unit (APU) consists of a command queue and its own threads where the commands are processed. If the operating system recognizes that the threads belonging to one APU belong together, and schedules them on the same socket/board, you may get a better performance than with binding the complete nucleus process to one socket/ board. Using the APU concept may also increase the performance, if the complete nucleus process is running on one socket, because the usage of more than one command queue reduces the number of lock conflicts compared to the usage of one large command queue.
However, Software AG cannot give a general recommendation for the optimal configuration of CPU binding and APU usage because the differences between the different operating systems and the different hardware implementations are simply too big. It may also be that APU usage brings no advantage at all. We recommend trying different configurations in your hardware environment and chosing the one that gives the best results for your database load.
Consider usage of modern storage systems. They can avoid downtimes because of disk failures and provide good performance.
Consider also the section Database Design, Recovery/Restart Design, Locations of Database Conatiners, Backup Files, and Protection Logs.
Adabas containers can be included in high availability clusters, but they are not directly supported by Adabas - it is necessary that you write the required scripts yourself. Load balancing in the clusters is not supported.
Describe each function in terms of the logical design model specifying:
The manner in which each record type is processed;
The access path and the sequence in which records are required;
The frequency and volume of the run;
The time available;
Decide which programs are most performance-critical. The choice may involve volumes, frequency, deadlines and the effect on the performance or scheduling of other systems. Other programs may also have minimum performance requirements which may constrain the extent to which critical functions can be optimized;
Optimize the performance of each critical function by shortening its access paths, optimizing its logic, eliminating database features which increase overheads, etc. In the first pass, an attempt should be made to optimize performance without sacrificing flexibility, accessibility of information, or other functional requirements of the system;
Estimate the performance of each critical function. If this does not yield a satisfactory solution, a relaxation of the time constraints or the functional requirements will have to be negotiated or a hardware upgrade may be required;
Estimate the performance of other system functions. Calculate the total cost and compare the cost and peak period resource requirements with the economic constraints. If the estimates do not meet the constraints, then a solution must be negotiated with the user, operations or senior management;
If possible, validate the estimates by loading a test database in order to time various functions. The test database should be similar to the planned one in terms of the number of records contained in each file and the number of values for descriptors. The size of each record is less important except for tests of sequential processing and then only if records are to be processed in something close to their physical sequence.
Adabas supports Unicode on the basis of International Components for Unicode (ICU) libraries (V3.2). Please refer to the ICU homepage at https://www.ibm.com/software/globalization/icu for further information about ICU. The wide character field format (W) has been introduced for Unicode fields. The Adabas user can specify the external encoding used in Adabas calls or for the compression and decompression utilities ADACMP and ADADCU, but internally all data is stored in UTF-8.
The external encoding can be specified in:
the Adabas OP command, where you can specify the default encoding for an Adabas session;
the format and search buffers, where you can specify encodings at the field level;
the utilities ADACMP and ADADCU, where you can specify the default encoding to be used during the execution of the utility.
For search and sort operations, the Unicode byte order is not usually of much importance, but language-specific collations are - for this reason, Adabas supports collation descriptors. A collation descriptor generates a binary string from the original character string by applying Unicode Collation Algorithms and language-specific rules.
The following points should be taken into consideration if you intend to write applications using Unicode character sets and when you intend to run the applications on both mainframes and Linux/Windows platforms:
Software AG recommends that you use the W format for text fields. The A format should only be used if the values only contain characters that are available in ASCII and EBCDIC, if the different ASCII and EBCDIC collations are not relevant, and if no collation descriptors are required.
On mainframes, you can select the internal encoding yourself, but on Linux/Windows platforms all W format fields are stored internally as UTF-8. Since the length of a string depends on its decoding, you should either use UTF-8 for internal encoding on mainframes as well, or you should ensure that your applications only store values that cannot overflow with the internal encoding on other platforms.
On mainframes, W format fields are based on ECS, but on Linux/Windows platforms they are based on ICU - you should, therefore, only use encodings that are available on all platforms.
On Linux/Windows platforms, collation descriptors are based on ICU, but on mainframes, the user has to provide user exits to generate collation descriptors. These user exits must generate collation sequences that are compatible with the ICU collations used on Linux/Windows platforms. On Linux/Windows platforms, you must use the HE option in order to achieve the same behaviour as on mainframes.
The Adabas direct commands on mainframes and Linux/Windows platforms are not fully compatible with respect to their handling of W format fields. You should ensure that only compatible commands are used in cross-platform applications.
It is possible to design an Adabas database with one file for each record type as identified during the conceptual design stage. Although such a structure would support any application functions required of it and is the easiest to manipulate in ad hoc queries, it may not be the best from the performance point of view:
The number of Adabas calls would be increased. Each Adabas call requires interpretation, validation and queueing overhead;
Accessing at least one index, Address Converter and Data Storage block from each of the files. In addition to the I/Os necessary for this process, it will require buffer pool space and perhaps result in the overwriting of blocks needed for a later request.
It is, therefore, often advisable to reduce the number of Adabas files used by critical programs. The following techniques may be used for this procedure:
Using multiple-value fields and periodic groups;
Using multiple record types in one Adabas file;
Controlled data duplication.
Each of these techniques is described in the following sections.
In the example shown below, ORDER-ITEM is defined as a periodic group in the ORDER file. Each order record contains a variable number of order items.
Order Order Date Customer Item
Number Date Required Number Code Quantity
A1234E 29MAR 10JUN UK432M 24801K 200 1ST OCCUR.
30419T 100 2ND OCCUR.
273952 300 3RD OCCUR.
A multiple-value field or a periodic group may be retrieved/updated in the same call and with the same I/Os as the main record. This can result in a saving in both CPU time and I/O requirements.
There are certain constraints concerning the usage of multiple-value fields and periodic groups that the user should be aware of:
A periodic group cannot contain another periodic group;
Depending on the compressed size of one occurrence, their usage can result in extremely large record sizes which may be larger than the maximum record size supported by Adabas.
Descriptors contained within a periodic group or derived from fields within a periodic group cannot be used as a sort key in FIND and SORT commands. In addition, specific rules apply to the methods in which search requests that involve one or more descriptors defined as multiple-value fields and/or contained within a periodic group may be used. These rules are described in the Command Reference Manual.
Another method of reducing the number of files is to store data belonging to two logical record types in the same Adabas file. For example, the figure Multiple Record Types (i) below shows how a customer file and an order file might be combined. This technique takes advantage of the Adabas null-value suppression facility.
Fields in the Field Definition Table for the combined file:
Key, Record Type, Order Data, Order Item Data
Stored records:
Key Type Order Data *
Key Type * Order Item Data
* indicates suppressed null values.
The key of an order item record could be order number plus line sequence number within this order.
This technique reduces I/Os by allowing the customer and order record types to share various control blocks and higher-level index blocks. Thus fewer blocks have to be read before processing of the file can start, and more space is left free in the buffer pool for other types of blocks.
The customer and order records can be grouped together in Data Storage reducing the number of blocks which have to be read to retrieve all the orders for a given customer. If all the orders are added at the same time as the customer, the total I/Os required will also be reduced.
The key must be designed carefully to ensure that both customer and order data can be accessed efficiently. The key for a customer record will usually have the null value of the suffix which distinguishes different orders belonging to the same customer appended to it as shown in the figure Multiple Record Types (ii) below.
A00231 000 Order header for order A00231 A00231 001 Order item 1 A00231 002 Order item 2 A00231 003 Order item 3 A00232 000 Order header for order A00232 A00232 001 Order item 1
A record type field is not necessary if the program can tell whether it is dealing with a customer or order record by the contents of the key suffix. It may be necessary for a program to reread a record in order to read additional fields or else have Adabas return all the fields relevant in any of the record types.
In some cases, a few fields from a header record are required almost every time a detail record is accessed. For example, the production of an invoice may require both the order item data and the product description which is part of the PRODUCT record. The simplest way to make this information quickly available to the invoicing program is to hold a copy of the product description in the order item data. This is termed physical duplication because it involves holding a duplicate copy of data which is already physically represented elsewhere.
Physical duplication can also be in effect if some fields from each detail record are stored as a periodic group in a header record.
Assume that a credit control routine needs the sum of all invoices sent to the customer. This information can be derived by reading and totalling the relevant invoices, but this might involve accessing randomly quite a large number of records. It can be obtained much more quickly if it is stored permanently in the customer record, provided it is correctly maintained. This is termed logical duplication because the duplicate information is not already stored elsewhere but is implied by the contents of other records.
Programs which update information that is physically or logically duplicated are likely to run more slowly because they must also update the duplicate copies. Physical duplication seldom causes much of a problem because it usually involves fields which are infrequently updated. Logical duplication almost always requires duplicate updating because the change of any one record can affect data in other records.
Once an Adabas file structure has been determined, the next step is usually to define the field definition table for the file. The field definitions are entered as described in the chapter FDT Record Structure. This section describes the performance implications of some of the options which may be used for fields.
The fields should be arranged such that those which are read or updated most often are nearest to the start of the record. This will reduce the CPU time required to locate the fields within the record. Fields which are seldom read but are mainly used as search criteria should be placed last.
The use of groups results in more efficient internal processing of read and update commands. This is the result of shorter format buffers which take less time to process and require less space in the internal format-buffer pool maintained by Adabas.
Numeric fields should be loaded in the format in which they will most frequently be used. This will minimize the amount of format conversion required. However, the relation between CPU time saved and extra disk space required has to be considered.
The use of the fixed storage (FI) option normally reduces the processing time of the field, but may result in a larger disk storage requirement, particularly if the field is contained in a periodic group. NU fields should be grouped together wherever possible. FI fields should be grouped together wherever possible.
It is important that each Adabas base record must fit into one data block, which can be up to 32KB in size (see the section Container Files for further information about block sizes). For further information about the space required for the Adabas fields, see the section Disk Space Usage. In addition to the space required for the Adabas fields, 4 bytes are needed for each data block and 6 bytes for each Adabas record.
Normally, each Adabas record must fit into one data block, but there is the exception that values larger than 253 bytes (so-called large object values - LOB values) can be stored by Adabas in a separate internal Adabas file, the associated LOB file. The original Adabas file is called the base file, the records in the base file are called base records, and the records in the LOB file are called LOB records. The following rules apply to LOB values:
If there is no LOB file associated with an Adabas file, all values are stored in the base record - the maximum field length is then limited to 16381 bytes.
If a LOB field is a descriptor or a parent field of a derived descriptor, the field values are always stored in the base record, and the maximum field length is limited to 16381 bytes.
In all other cases, values up to 253 bytes are always stored in the base record, values larger than 253 bytes are stored in one or more LOB segment records in the LOB file - then the base record contains a 16 byte LOB value reference instead.
The following table provides an overview of the terms used in conjunction with LOB values in the Adabas documentation:
| Term | Definition |
|---|---|
| Base file | An Adabas file with a user-defined FDT that contains one or more LOB fields |
| Base record | A record in a base file. The LOB values in the record are represented by LOB value references pointing to LOB segment records in the LOB file. The actual LOB values are contained in these segment records |
| LOB | Large Object. Initially, a LOB value in Adabas can have a size of up to ca. 2GB (theoretically) |
| LOB field | A new type of field in an Adabas file that stores LOB values |
| LOB file | An Adabas file with a predefined FDT containing LOB values that are spread over one or more LOB segment records |
| LOB file group | The pair consisting of base file and LOB file, viewed as a single unit |
| LOB segment | One portion of a LOB value that was partitioned. A LOB value consists of one or more LOB segments |
| LOB segment record | A record in a LOB file that contains a LOB segment as payload data and other information as control data |
| LOB value | An instance of a LOB |
| LOB value reference | A reference or pointer from a base record to the LOB segment records that contain the partitioned LOB value |
It is possible to define the following types of LOB fields:
Binary large objects (BLOBs). These LOB fields are defined with format A (ALPHANUMERIC) and the following options: LB (values > 16381 bytes are supported), NB (blanks at the end of the value are not truncated) and NV (binary values without ASCII / EBCDIC conversion between Open Systems platforms and mainframe platforms).
Character (ASCII / EBCDIC) large objects (CLOBs). These LOB fields are defined with format A and option LB, but without option NB and NV. In addition, the field options MU, NC, NN, NU can be defined with the usual rules for these options; a LOB field can also be defined as a member of a periodic group.
Notes:
From Adabas Version 6.7, records can be spanned in a database. When record spanning is enabled, the size of compressed records in a file may exceed the maximum data storage block size of 32 KB.
Notes:
The Adabas nucleus uses some internal Adabas files, the so-called Adabas system files, to store internal data. While the checkpoint file, the security file and the user data file are always required for an Adabas database and are defined when the database is created, the replication system files are only created when you initialize the Adabas-to-Adabas replication - please refer to the section Adabas-to-Adabas (A2A) Replication for further details.The RBAC system file is only created when you define it explicitly - please refer to the section Authorization for Adabas Utilities for further details.
The following Adabas system files exist:
The Adabas checkpoint file is used to log some important events, the Adabas checkpoints; these checkpoints are written for:
Adabas utility executions
Nucleus starts and stops
Adabas user sessions with exclusive access to Adabas files
User-defined checkpoints
The checkpoints can be displayed with the utility ADAREP parameter CHECKPOINTS. The documentation of this parameter contains a description of the different checkpoint types.
The checkpoints are especially important for the utility ADAREC (database recovery), which re-applies all database updates performed after a database backup: because ADAREC cannot recover some utility operations, it stops when it detects a SYNP checkpoint that indicates the execution of a utility which cannot be recovered by ADAREC, and which must be re-executed manually.
Note
The information stored in the checkpoint file does not contain
all of the information required to re-execute the utilities. Software AG
therefore strongly recommends that you document all utility executions in order
to be able to recover the database if necessary.
The Adabas security file contains the Adabas security definitions. For more information on Adabas security, For further information, please refer to the documentation of the ADASCR utility, which is used to maintain the Adabas security definitions.
The user data file is used to store information about the last transaction for all User IDs (ETIDs) specified in the Additions1 field for an OP command. The idea of specifying ETIDs is to enable the implementation of restart processing for programs using Adabas, following a crash. If you don't do this, it doesn't make sense to specify ETIDs.
Notes:
You can delete the data in the user data file by using the ADADBM REFRESH function; of course then all user data stored in the file are lost.
Please refer to the section Adabas-to-Adabas (A2A) Replication for detailed information about the replication system files.
Please refer to the section Adabas Role-Based Security (ADARBA) for detailed information about the RBAC system file.
Descriptors are fields for which Adabas has created an index for efficient search operations, to control a logical sequential read and as a sort key in certain Adabas commands such as FIND and SORT ISN LIST. The use of descriptors is, therefore, closely related to the access strategy to be used for a file. Additional disk space and processing overhead is required for each descriptor, particularly those which are updated frequently. The following guidelines may be used in determining the number and type of descriptors to be defined for a file:
The value distribution of the descriptor should be such that it may be used to select a small percentage of the total number of records in the file;
Additional descriptors should not be defined to further refine search criteria if a reasonably small number of records can be selected using existing descriptors;
If two or three descriptors are used in combination frequently (for example, area, department, branch), a superdescriptor may be used instead of defining separate descriptors;
If the selection criterion for a descriptor always involves a range of values, a subdescriptor may be used;
If the selection criterion for a descriptor never involves the selection of null values, and a large number of null values are possible for the descriptor, the descriptor should be defined with the null value suppression option;
If a field is updated very frequently, you should be aware that the faster search operations achieved by using the index created for a descriptor have to be paid for by slower database update operations, since the index also has to be updated;
If you don't define a field as a descriptor and you perform a non-descriptor search, you should be aware that the performance may be good with a small test database, but that it may be poor with a large production database.
If you store descriptor values larger than 253 bytes in the database, they are stored in index blocks with a block size of at least 16 KB. If you want to store such values, the database must have an appropriate ASSO container file or there must be a location defined so that the database can create such an ASSO container.
The maximum length of a descriptor value is 1144 bytes. Normally, database operations that attempt to insert a larger value will be rejected, but if you specify the index truncation option for the descriptor, larger index values are truncated. The consequence of this is that the results of search operations may no longer be exact if truncated index values are involved; a warning is issued in such cases.
A superdescriptor is a descriptor which is created from a combination of up to 20 fields (or portions thereof). The fields from which a superdescriptor is derived may or may not be descriptors. Superdescriptors are more efficient than combinations of ordinary descriptors when the search criteria involves a combination of values. This is because Adabas has only to access one inverted list instead of several and does not have to AND several ISN lists to produce the final list of qualifying records. Superdescriptors may also be used in the same manner as ordinary descriptors to control the logical sequence in which a file is read and to sort ISN lists.
The values for search criteria which use superdescriptors must be provided in the format of the superdescriptor (binary for superdescriptors derived from all numeric fields, otherwise alphanumeric). If the superdescriptor format is binary, the input of the search value using an ad hoc query or report facility may be difficult.
A subdescriptor is a descriptor which is derived from a portion of a field. The field used to derive the subdescriptor may or may not be a descriptor. If a search criteria involves a range of values which is contained in the first n bytes of an alphanumeric field or the last n bytes of a numeric field, a subdescriptor derived from the relevant bytes of the field may be defined. This will enable the search criterion to be represented as a single value rather than a range which will, in turn, result in more efficient searching since Adabas will not need to merge intermediate ISN lists. For example, assume an alphanumeric field AREA of 8 bytes, the first 3 of which represent the REGION and the last 5 the DEPARTMENT. If only records for REGION 111 are desired, a search criteria of AREA = 11100000 through 11199999 would be required. If the first three bytes of AREA were defined as a subdescriptor, a search criteria equal to REGION = 111 could be specified.
A phonetic descriptor may be defined to perform phonetic searches. The use of a phonetic descriptor in a FIND command results in the return of all the records which contain similar phonetic values. The phonetic value of a descriptor is based on the first 20 bytes of the field value with only alphabetic values being considered (numeric values, special characters and blanks are ignored).
The hyperdescriptor enables descriptor values to be generated based on a user-supplied algorithm coded in a hyperexit. Up to 255 different user-written hyperexits can be defined for a single Adabas database, and each hyperexit can handle multiple hyperdescriptors.
Hyperdescriptors can be used to implement n-component superdescriptors, derived keys, or other key constructs. See FDT Record Structure and User Exits and Hyperexits in this manual for more information about hyperdescriptors.
A multi-file query may be performed by specifying a field to be used for inter-file linkage in the search criteria. This feature is called soft coupling and does not require the files to be physically coupled.
Each record in an Adabas file has an internal sequence number (ISN), which is a 4 byte unsigned integer >0. ISNs are used by Adabas internally to perform queries efficiently, and the result of Adabas FIND commands represents the result as an ISN list.
If the ISN of a record is known, it is very efficient to access the record via its ISN (Adabas L1 command).
The user has the option of assigning the ISN of each record in a file rather than having this done by Adabas. This technique permits subsequent retrieval using the ISN directly rather than using the inverted lists. This requires that the user develop his own algorithm for the assignment of ISNs. The resulting range of ISNs must be within the space allocated for the Address Converter for the file (please refer to the description of the MAXISN parameter in the chapter ADAFDU in the Utilities Manual for more information), and each application which adds records to the file must contain the user's ISN assignment algorithm.
The user may store the ISNs of related records in another record in order to be able to read the related records directly without using the inverted lists.
For example, assume an application needs to read an order record and then find and read all customer records for the order. If the ISN of the customer record (if there is more than one customer per order, a multiple-value field could be used) were stored in the order record, the customer record could be read directly since the ISN is available in the order record. This would avoid the necessity of issuing a FIND command to the customer file to determine the customer records for the order. This technique requires that the field containing the ISNs of the customer records be established and maintained in the order record, and assumes that the ISN assignment in the customer file will not be changed as a result of a file unload and reload in which the same ISN assignment is not retained.
The Adabas Direct Access Method (ADAM) facility permits the retrieval of records directly from Data Storage without access to the inverted lists. The Data Storage block number in which a record is located is calculated using a randomizing algorithm based on the ADAM key of the record. The use of ADAM is completely transparent to application programs.
The main performance advantage of using ADAM descriptors is the reduction in the number of accesses made to inverted lists. The main advantage of using an ISN as an ADAM key is the reduction in the number of accesses to the Address Converter.
ADAM will generally use an average of 1.2 to 1.5 (logical) I/O operations (including an average of overflow records stored under Associator control in other blocks of the file) to search for a record via the Adam key, as opposed to the three to four I/O operations required to search fora record using the inverted lists. Overflow records are also retrieved using normal Associator inverted-list references.
The ADAM key of each record must be a unique value. The ISN of a record may also be used as the ADAM key.
Notes:
The file definition utility ADAFDU is used to define a descriptor or ISN as an ADAM key. There are 3 parameters:
| Parameter | Meaning |
|---|---|
| ADAM_KEY | define ADAM key |
| ADAM_PARAMETER | parameter to influence data record distribution algorithm |
| ADAM_OVERFLOW | number of overflow blocks |
The data space for ADAM is calculated as (DSSIZE (in blocks) - ADAM_OVERFLOW):

The data space for ADAM cannot be subsequently extended, only the ADAM overflow area can grow. However, the ADAM area can cover multiple DS extents within the initialization. The ADAM area is formatted and marked as in use during the execution of ADAFDU.
The number of blocks to be used for the overflow area is defined with the ADAM_OVERFLOW parameter. A minimum of one block is required, and more blocks can be added later. The overflow blocks are used if there is no space for the ADAM-calculated block for a new record. The gain in performance obtained by using ADAM is decreased if a large number of records is stored in the overflow area. The distribution of records in the ADAM file can be checked using the file information utility ADAFIN.
If the space reusage option has been set for the file, it only applies to the overflow area. The DATA padding factor applies to both areas (DATA and overflow).
The ADAM_PARAMETER parameter is used to influence the distribution of the data records.
If the ADAM key is ISN or a fixed-point descriptor, it determines the number of consecutive values that are to be stored in one block. The basic algorithm is
DS number = (actual value/ADAM_PARAMETER) modulo number_adam_blocks
If the format of the ADAM key is alphanumeric, binary or floating point, then the ADAM parameter defines the offset from the end of the value for an 8-byte extraction.
ADAM_PARAMETER = 3 Value's lengths = 5, 10, 15
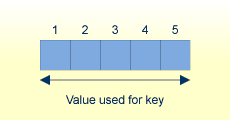
If the value is less than or equal to 8 bytes long, the complete value is taken as the extraction value.
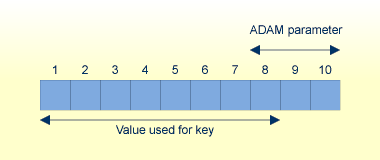
Otherwise, if (value length - ADAM parameter) is less than or equal to 8 bytes long, the first 8 bytes are taken as the extraction value.
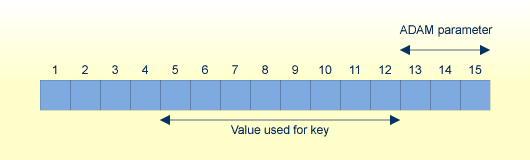
Otherwise the last 8 bytes after removing (ADAM parameter) bytes are taken as the extraction value.
The algorithm for calculating a relative DS number is:
DS number = (extraction value) modulo (number of ADAM blocks)
If the format of the ADAM key is packed or unpacked, then the ADAM parameter defines the offset from the end of the value to the position of the value to be considered for the ADAM value. This ADAM value from position 1 to the position (value length - ADAM_parameter) will be converted to a 8-byte integer value.
ADAM_PARAMETER = 2 Value's length = 8
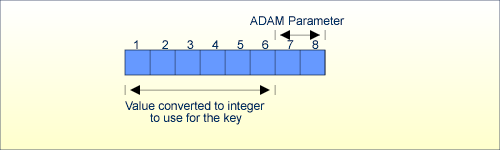
The algorithm for calculating a relative DS number is:
DS number = (integer value) modulo (number of ADAM blocks)
If the format of the ADAM key is fixed point or if the ADAM key is the ISN, the extraction value is (ADAM key value) / (ADAM parameter).
The following values are entered in ADAFDU:
DSSIZE = 40 B ADAM_KEY = FF ADAM_OVERFLOW = 10 ADAM_PARAMETER = 12
The file is an ADAM file, and the unique descriptor FF is used as an ADAM key. 30 blocks will be used for the ADAM DS area, with 10 blocks reserved for the overflow area. 12 consecutive values will be stored in each block.
The values will be stored in the DS blocks as follows:
| FF Value | DS Block |
|---|---|
| 0 - 11 | 1 |
| 12 - 23 | 2 |
| 24 - 35 | 3 |
| ... | ... |
| 348 - 359 | 30 |
| 360 - 371 | 1 |
| 372 - 383 | 2 |
| ... | ... |
The efficient use of disk space is especially important in a database environment because:
The sharing of data between several users, possibly concurrently and in different combinations, normally requires that a large proportion of an organization's data be stored online;
Some applications contain extremely large amounts of data.
Decisions concerning the efficient usage of disk space must be made while considering other objectives of the system (performance, flexibility, ease of use). This section discusses the techniques and considerations involved in making trade-offs between these objectives and the efficient usage of disk space.
Each field may be defined to Adabas with one of three compression options:
Ordinary compression (the default) which causes Adabas to remove trailing blanks from alphanumeric fields and leading zeros from numeric fields, but requires one additional length byte if the compressed value length is <= 126, or two if the compressed value length is larger. The null value is compressed to a length byte = 1.
Null value suppression which results in ordinary compression and, in addition, suppresses the null value for the field.
Fixed storage (FI), in which the field is not compressed at all, but the additional length byte in Data Storage is omitted.
The figure Adabas Compression below illustrates how various values of a five-byte alphanumeric field are stored using each compression option. The number preceding each stored value is an inclusive length byte (not used for FI fields). The asterisk shown under null value suppression indicates a suppressed field count. This is a one-byte field which indicates the number of empty (suppressed) fields present at this point in the record. A `b' means a blank.
Field Ordinary Fixed Null Value
Value Compression Storage Suppression
ABCbb 04414243 4142432020 04414243
(4 bytes) (5 bytes) (4 bytes)
ABCDb 0541424344 4142434420 0541424344
(5 bytes) (5 bytes) (5 bytes)
ABCDE 064142434445 4142434445 064142434445
(6 bytes) (5 bytes) (6 bytes)
bbbbb 01 2020202020 *
(2 bytes) (5 bytes) (1 byte)
The compression options chosen also affect the creation of the inverted list for the field (if it is a descriptor) and the processing time needed for compression and decompression of the field.
Fixed storage indicates that no compression is to be performed on the field. The field is stored according to its standard length with no length byte. Fixed storage is useful for small fields and for fields for which little or no compression is possible. See FDT Record Structure for information about the various restrictions related to the use of FI fields.
Ordinary compression results in the removal of trailing blanks from alphanumeric fields and leading zeros from numeric fields. As can be seen in the figure Adabas Compression above, ordinary compression will result in a saving in disk space if at least 2 bytes of trailing blanks or leading zeros are removed.
If null value suppression is specified for a field, and the field value is null, a one-byte empty field indicator will be stored instead of a length byte and the compressed null value (see figure above). This empty field indicator specifies the number of consecutive null-value suppressed fields which contain null values at this point in the record. Up to 63 empty fields can be represented by one byte. It is, therefore, advantageous to physically position fields which are frequently empty next to one another in the record and to define each with the null-value suppression option.
If the field is a descriptor, the use of null value suppression will result in the omission of the null value from the inverted lists. This means that a FIND command, in which the null value of the descriptor is used will always result in no qualifying records even if there are records in Data Storage which contain a null value for the descriptor. This applies also to subdescriptors and superdescriptors derived from a field defined with null value suppression. No entry will be made for a subdescriptor if the bytes of the field from which it is derived contain a null value and the field is defined with the null-value suppression option. No entry will be made for a superdescriptor if the bytes of any of the fields from which it is derived contain a null value and the field is defined with the null-value suppression option.
The use of null value suppression with descriptor fields, therefore, depends on the need to search for null values, and, if the descriptor is used to control logical sequential reading or sorting, the need to read records containing a null value. If such a need does not exist, null value suppression is normally used (unless the FI option is used).
Null value suppression is normally recommended for multiple-value fields and fields within periodic groups in order to reduce both the amount of disk space required and the internal processing requirements of these types of fields. The updating of such fields varies according to the compression option used. If a multiple-value field defined with null value suppression is updated with a null value, all values to the right are shifted left, and the value count is reduced accordingly. If all the fields of a periodic group are defined with null value suppression, and the entire group is updated to a null value, the occurrence count will be reduced only if the occurrence updated is the highest (last) occurrence. For detailed information about the updating of multiple-value fields and periodic groups, see FDT Record Structure and the Command Reference, A1 command and Command Reference, N1/N2 command.
The values for multiple-value fields and periodic groups are normally preceded by an 8-byte header (or sometimes by a one byte MU or PE count). Each occurrence of a periodic group is preceded by a two-byte length indicator. If a periodic group contains empty occurrences, up to 32767 empty occurrences are compressed to a 2-byte empty periodic group occurrence counter.
A large amount of record update activity (A1 command) may result in a considerable amount of record migration, i.e. moving the record from its current block to another block in which there is sufficient space for the expanded record. Record migration may be considerably reduced by defining a larger padding factor for Data Storage for the file when it is loaded. The padding factor represents the percentage of each physical block that is to be reserved for record expansion. The padding area is not used during file loading or when adding new records to a file. A large padding factor should not be used if only a small percentage of the records are likely to expand, since the padding area of all the blocks in which non-expanding records are located would be wasted.
If a large amount of record update/addition is to be performed, in which a large number of new values must be inserted into the current value range of one or more descriptors, a considerable amount of migration may also occur within the Associator. This may be reduced by assigning a larger padding factor for the Associator.
The disadvantages of a large padding factor are a larger disk-space requirement (less records or entries per block) and possible degradation of sequential processing, since more physical blocks will have to be read.
Padding factors are specified when a file is defined (using utility ADAFDU) and can be changed (using utility ADAORD).
This section describes the general considerations which should be made concerning database security and explains the Adabas facilities which may be used to secure data contained within the database.
Effective security measures must take account of the following points:
A system is only as secure as its weakest component. This may be a non-DP area of the system: for example, failure to properly secure printed listings;
It is rarely possible to design a 'foolproof' system. A security violation will probably be committed if the gain is likely to exceed the cost;
Security costs can be high. These costs include inconvenience, machine resources and the time required to coordinate the planning of security measures and monitor their effectiveness.
The cost of security measures is usually much easier to quantify than the risk or cost of a security violation. The calculation may, however, be complicated by the fact that some security measures may offer benefits outside the area of security. The cost of a security violation depends on the nature of the violation. Possible types of cost include:
Loss of time while the violation is being recovered;
Penalties under privacy legislation, contracts, etc.;
Damage in relationships with customers, suppliers, etc.
This section contains an overview of the security facilities provided by Adabas and its subsystems. For more detailed information about the facilities discussed in this section, please refer to the section Adabas Security Facilities.
Adabas Authentication provides a means for applications to access the database in the context of a user by having the user provide valid credentials.
For more detailed information about Adabas Authentication, please refer to Adabas Authentication in the section Adabas Security Facilities.
Authorization for Utilities provides a means of restricting the usage of Adabas utilities on databases by assigning users a role which has selective access privileges.
For more detailed information about Authorization for Adabas Utilities, please refer to Authorization for Adabas Utilities in the section Adabas Security Facilities.
For more detailed information about the Adabas Password Security (ADASCR), please refer to Adabas Password Security in the section Adabas Security Facilities.
Ciphering prevents the unauthorized analysis of Adabas container files. Adabas can cipher the data that it stores in container files. This, however, only applies to the data records that are stored in the Data storage, but not to the inverted lists on the Associator.
For more detailed information about ciphering, please refer to Ciphering in the section Adabas Security Facilities.
An important concept for all databases is the availability of a transaction concept in order to guarantee database integrity. A transaction guarantees that a set of database update operations will either be committed, i.e. they all the updates become persistent in the database, or in case of an error, the update operations already performed will be completely be rolled back.
This section is just a short overview on the transaction concept; please refer to the Command Reference section for further information.
Adabas has the following database commands to support the transaction concept:
ET - End of Transaction, commits a transaction
BT - Backout Transaction, rolls back a transaction.
For some files, it can be desirable that they do not take part in normal transaction logic, and that all database modifications for the file are kept in the database even if a transaction is rolled back. An example for such a file is a log file, in which all activities of a user are to be logged including activities within a transaction that is later backed out.
In order to guarantee database integrity, it must not be possible for another user to update records that required for a transaction. To this end, Adabas lets you lock records for the duration of a transaction.
Adabas supports the following types of lock:
| Lock Type | Usage |
|---|---|
| Share or read lock (S) | You can acquire a shared or read lock if no other user has already acquired an exclusive lock for the record. S locks allow you to guarantee that nobody else can update one or more of the records as long as you have these records locked, while other users can still also get a shared lock. |
| Exclusive or write lock (X) | You can only acquire an exclusive or write lock for an Adabas record if no other user has already acquired an S or X lock for this record. Modification or deletion of a record is only possible with an X lock of the record. If you create a new record, this record is automatically locked exclusively. |
Sometimes it is can be necessary to roll back not the complete transaction, but only a subset of the transaction. To this end, Adabas has a subtransaction concept, which is implemented via special options of the ET and BT commands.
Sometimes it is necessary for the database to be in a consistent state:
If you create a backup of the database with ADABCK;
If you perform an external backup with ADAOPR EXT_BACKUP;
If you switch to a new protection log (PLOG).
Note
Switching to a new PLOG extent does not require ET
synchronization, because all extents of a PLOG are considered as one PLOG.
In all of these cases, an ET synchronization must be performed for the database - this means:
All currently-active transactions continue to work until the transaction is terminated or until a timeout occurs. The timeout period is defined by the Adabas nucleus parameter TT or, in case of ADABCK, by the parameter ET_SYNC_WAIT;
If an Adabas command tries to start a new transaction, the command has to wait until the ET synchronization is finished;
As soon as all active transactions are terminated, phase 2 of the ET synchronization begins: all activities to be done in the consistent state can be done, for example a buffer flush, in order to ensure that the consistent state of the database is stored on disk;
Once phase 2 of the ET synchronization has finished, any commands waiting for the end of the ET synchronization can continue.
If you create a backup on the file level using ADABCK DUMP without the option NEW_PLOG, an ET synchronization is only performed on the file level:
The ET synchronization waits only for the termination of transactions that access the dumped files;
New transactions can start as long as they only access other files. However, as soon as such a transaction is extended to one of the dumped files, the command has to wait until the end of the ET synchronization.
This section discusses the design aspects of database recovery/restart.
Correct recovery/restart planning is an important part of the design of the system, particularly one in which a database is used. Most of the causes of failure can be anticipated, evaluated and resolved as part of the basic system design process.
Recoverability is often an implied objective. Everyone assumes that, regardless of what happens, the system can be recovered and restarted. There are, however, specific facts to be determined about the level of recovery needed by the various users of the system. Recoverability is an area where the DBA has to take the initiative and establish necessary facts. Initially, each potential user of the system should be asked about their recovery/restart requirements. The most important considerations are:
How long can the user manage without the system?
How long can each phase be delayed?
What manual procedures, if any, does the user have for checking input/output and how long do these take?
What special procedures, if any, need to be performed to ensure that data integrity has been maintained in a recovery/restart situation?
The following topics are covered:
Once the recovery/restart requirements have been established, the DBA can proceed to plan the measures necessary to meet these requirements. The methodology provided in this section may be used as a basic guideline.
A determination should be made as to the level and degree to which data is shared by the various users of the system.
The recovery parameters for the system should be established. This includes a predicted/actual breakdown rate, an average delay and items affected, and items subject to security.
An outline containing recovery design points should be prepared. Information in this outline should include:
Validation planning. Validation of data should be performed as close as possible to its point of input to the system. Intermediate updates to data sharing the record with the input will make recovery more difficult and costly;
Dumps (back-up copies) of the database or selected files;
User and Adabas checkpoints;
Use of ET logic, exclusive file control, ET data.
The recovery strategy should be subjected to all possible breakdown situations to determine the suitability, effectiveness, and cost of the strategy.
Operations personnel should be consulted to determine whether all resources required for recovery/restart can be made available if and when they are needed.
The final recovery design should be documented and reviewed with users, operations personnel and any others involved with the system.
When you restart the database after a database crash, an autorestart is performed: All transactions that were active when the nucleus crashed are rolled back, and all missing database updates are written to the ASSO and DATA containers. For this purpose, the update operations have been logged on the WORK container. Nevertheless, in case of a disk corruption, it may be that the autorestart fails. In this case, it is important that you can recover the state of your database from a backup and the protection logs. This can be guaranteed only if your backup files and protection logs (PLOGs) are stored on separate, independent disks. Note that Adabas logs the update operations twice: once on WORK for the autorestart, and once on PLOGs for restore/recover to enable the recovery of the current database state in case a disk where a log is stored becomes corrupted.
Notes:
Once the general recovery requirements have been designed, the next step is to select the relevant Adabas and non-Adabas facilities to be used to implement recovery/restart. The following sections describe the Adabas facilities related to recovery/restart.
Many batch-update programs process streams of input transactions that have the following characteristics:
The transaction requires the program to retrieve and add, update, and/or delete only a few records. For example, an order entry program may retrieve the customer and product records for each order, add the order and order item data to the database, and perhaps update the quantity on order field of the product record;
The program needs exclusive control of the records it uses from the start of the transaction to the end, but can release them for other users to update or delete once the transaction is complete;
A transaction must never be left incomplete, i.e. if it requires two records to be updated, either both or neither must be changed.
The use of the Adabas ET command will:
Ensure that all the adds, updates, and/or deletes performed by a completed transaction are applied to the database;
Ensure that all the effects of a transaction which is interrupted by a total or partial system failure are removed from the database;
Allow the program to store user-restart data (ET data) in an Adabas system file. This data may be retrieved on restart with the Adabas OP or RE commands;
Release all records placed in hold status while processing the transaction.
The Adabas CL command can be used to update the user's current ET data (for example, to set a job completed flag).
A user may retrieve his ET data after a user restart or at the start of a new user or Adabas session with the Adabas OP command. The user is required to provide a user identification (USERID) with the OP command. This USERID is used by Adabas to locate the user's ET data.
Another user's ET data may be read by using the RE command, provided that the USERID of the other user is known. This may be useful, for example, for staff supervision of an online update operation.
In the event of an abnormal termination of an Adabas session, the Adabas AUTOBACKOUT routine, which is automatically invoked at the beginning of every Adabas session, will remove the effects of all interrupted transactions from the database.
If an individual transaction is interrupted, Adabas will automatically remove all the changes the transaction has made to the database. An application program can explicitly cause its current transaction to be backed out by issuing the Adabas BT command.
In the case of a nucleus crashing, the following points should be taken into consideration:
All database modifications for a no-BT file issued before the last ET are applied in the database.
It is not defined whether database modifications for a no-BT file issued after the last ET are applied in the database or not.
The following limitations of Adabas transaction recovery should be considered:
The transaction recovery facility cannot function if critical portions of the ASSOCIATOR and/or the data protection area of the Adabas WORK cannot be physically read or have been overwritten. Although this situation should rarely occur, specific procedures should be prepared for such a condition. The section on recovery/restart procedures should be consulted for detailed guidelines on how to recover a physically damaged database;
The transaction recovery facility recovers only the contents of the database. It does not reposition non-Adabas files, or save the status of the user program;
It is not possible to backout the effects of a specific user's transactions, because other users may have performed subsequent transactions using the records added or updated by the first user.
Some programs cannot conveniently use ET commands because:
The program would have to hold large numbers of records for the duration of each transaction. This would increase the possibility of a deadlock situation (Adabas automatically resolves such situations by backing out the transaction of one of the two users, but a significant amount of transaction reprocessing could still result), and a very large Adabas hold queue would have to be established and maintained;
The program may process long lists of records found by complex searches and restarting part of the way through such a list may be difficult.
Such programs can use the Adabas checkpoint command (C1) to establish a point at which the file or files the program is updating can be restored if necessary. The specific command used depends on the type of updating (exclusive control) being performed.
A user can request exclusive update control of one or more Adabas files. Exclusive control is requested with the OP command and will be given only if the file is not currently being updated by another user. Once exclusive control is assigned to a user, other users may read but not update the file.
Programs which read and/or update long sequences of records, either in logical sequence or as a result of searches, may use exclusive control to prevent other users from updating the records used. This avoids the necessity of issuing a record hold command for each record.
Exclusive control users may or may not use ET commands. If ET commands are not used, checkpoints can be taken by issuing a C1 command (if user data is to be stored).
In the event of a system or program failure, the file or files being updated under exclusive control may have to be restored (using ADABCK or ADAMUP) to the state before the start of the execution of the program which failed.
The following limitations apply to exclusive file control:
Recovery to the last checkpoint is not automatic, and the data protection log in use when the failure occurred is required for the recovery process. This does not apply if the user issues ET commands;
In a restart situation following a system failure, Adabas does not check nor prevent other users from updating files which were being updated under exclusive control at the time of the system interruption.
The Adabas ET and CL commands provide an option of storing up to 2000 bytes of user data in an Adabas system file.
One record of user data is maintained for each user. This record is overwritten each time new user data is provided by the user. The data is maintained across Adabas sessions only if the user provides a user identification (USERID) with the OP command. User data may be read with an OP or RE command. A user may read another user's data with the RE command, provided that the USERID of the other user is known.
The primary purpose of user data is to enable programs to be self-restarting and to check that recovery procedures have been properly carried out. The type of information which may be useful as user data includes:
The date and time of the original program run and the time of last update. This will permit the program to send a suitable message to a terminal user, console operator or printer to allow the user and/or operator to check that recovery and restart procedures have operated correctly. In particular, it will allow terminal users to see if any work has to be rerun after a serious overnight failure that they were not aware of;
The date of collection of the input data;
Batch numbers. This will enable supervisory staff to identify and allocate any work that has to be reentered from terminals;
Identifying data. Sometimes this may simply be a supplement to or cross-check on the items described above. In other cases, it may be the principal means of deciding where to restart, e.g., a program driven by a logical sequential scan needs to know the key value at which to resume;
Transaction number/input record position. This may allow a terminal user or batch program to locate the starting point with the minimum of effort. Although Adabas returns a transaction sequence number for each transaction, the user also may want to maintain a sequence number because:
After a restart, the Adabas sequence number will be reset;
If transactions vary greatly in complexity, there may not be a simple relationship between the Adabas transaction sequence number and the position of the next input record or document;
If a transaction is backed out by the program because of an input error, Adabas does not know whether the transaction will be reentered immediately (it may have been a simple keying error) or rejected for later correction (if there was a basic error in the input document or record);
Other descriptive or intermediate data. For example, totals to be carried forward, page numbers and headings of reports, run statistics;
Job/batch completed flag. The system may fail after all processing has been completed but before the operator or user has been notified. In this case, the operator should restart the program which will be able to check this flag without having to run through to the end of the input. The same considerations apply to batches of documents entered from terminals;
Last job/program name. If several programs must update the database in a fixed sequence, they may share the same USERID and use user data to check that the sequence is maintained.
