This document describes the utility "ADAORD".
The following topics are covered:
The reorder utility ADAORD provides functions to reorganize a whole database (REORDER) and to migrate files between databases (EXPORT/IMPORT).
Depending on the function selected, ADAORD produces or requires a sequential file (ORDEXP).
The main reasons for running ADAORD are:
To change the layout of a complete database. This includes increasing or decreasing the maximum number of files permitted;
To change the space allocation or placement of a file, to reduce the number of logical extents assigned to its index, Address Converter or Data Storage and to change or re-establish the padding factors;
To create one or more test files that all contain the same data. This procedure requires a file to be exported and then imported using a different file number;
To archive and subsequently reestablish a file, independent of its original placement and the database device types used.
When exporting files from a database, the Adabas nucleus is not required. If a system file is processed, the nucleus must be inactive. For detailed information, please refer to the table of nucleus requirements.
When importing files into a database, the Adabas nucleus is not required to be active. The nucleus may be either started or shut down during this procedure.
When reordering the database, the nucleus must be inactive.
Note:
The IMPORT and IMPORT_RENUMBER functions can process export files
created with earlier Adabas versions, but not export files created with later
Adabas versions.
This utility is a single-function utility.
The sequential file ORDEXP can have multiple extents, but only if you are using raw devices. For detailed information about sequential files with multiple extents, see Administration, Using Utilities.
|
|
The sequential file ORDEXP can have multiple extents, but only if you are using raw devices. For detailed information about sequential files with multiple extents, see Administration, Using Utilities.
| Data Set | Environment Variable/ Logical Name |
Storage Medium |
Additional Information |
|---|---|---|---|
| Associator | ASSOx | Disk | |
| Data storage | DATAx | Disk | |
| Export copy | ORDEXP | Disk, Tape (* see note) | Export (out), Reorder (in/out), other functions (in) |
| Control statements | stdin/ SYS$INPUT |
Utilities Manual | |
| ADAORD messages | stdout/ SYS$OUTPUT |
Messages and Codes | |
| Work storage | WORK1 | Disk |
Note:
(*) A named pipe cannot be used for this sequential
file (see Administration,
Using Utilities for details).
The following table shows the nucleus requirements for each function and the checkpoints written:
| Function | Nucleus must be active | Nucleus must NOT be active | Nucleus is NOT required | Checkpoint written |
|---|---|---|---|---|
| CONTENTS | X | - | ||
| EXPORT | X(* see note) | X | SYNX | |
| IMPORT | X(* see note) | X | SYNP | |
| IMPORT_ RENUMBER |
X(* see note) | X | SYNP | |
| REORDER | X | X | SYNP |
Note:
(*) When processing an Adabas system file
In the case of the EXPORT function, ADAORD writes a single checkpoint and removes the UCB entry when all of the specified files have been exported and the sequential output file (ORDEXP) has been closed.
In the case of the IMPORT function, ADAORD writes a checkpoint and informs the nucleus that the file has been loaded every time a file is successfully imported.
The UCB entry is removed when all of the specified files have been imported. When the utility is executed offline, writing multiple checkpoints increases the probability of a checkpoint block (CPB) overflow. The checkpoint file should, therefore, always be present to allow the Adabas nucleus to be started in order to empty the CPB.
In the case of the REORDER function, ADAORD writes a single checkpoint and removes the UCB entry when the function terminates.
The following control parameters are available:
CONTENTS
DBID = number
EXPORT = (number[-number][,number[-number]]...)
[,FDT]
D [,SORTSEQ = ({descriptor_name|ISN|PHYSICAL},...)]
FILES = (number[[-number], number[-number]] ...)
IMPORT = (number[-number][,number[-number]]...)
[,ACRABN = number]
[,ASSOPFAC = number]
[,DATAPFAC = number]
[,DSRABN = number] [,DSSIZE = number[B|M] ]
[,LOBACRABN = number]
[,LOBDSRABN = number]
[,LOBNIRABN = number]
[,LOBSIZE = numberM]
[,LOBUIRABN = number]
[,MAXISN = number]
[,NIRABN = number|(number,number)]
[,NISIZE = number[B|M]|(number[B|M],number[B|M])]
[,UIRABN = number|(number,number)]
[,UISIZE = number[B|M]|(number[B|M],number[B|M])]
IMPORT_RENUMBER = (number, number[,number])
[,ACRABN = number]
[,ASSOPFAC = number]
[,DATAPFAC = number]
[,DSRABN = number] [,DSSIZE = number[B|M] ]
[,LOBACRABN = number]
[,LOBDSRABN = number]
[,LOBNIRABN = number]
[,LOBSIZE = numberM]
[,LOBUIRABN = number]
[,MAXISN = number]
[,NIRABN = number|(number,number)]
[,NISIZE = number[B|M]|(number[B|M],number[B|M])]
[,UIRABN = number|(number,number)]
[,UISIZE = number[B|M]|(number[B|M],number[B|M])]
REORDER = *
CONTENTS
This function displays the list of files contained in the sequential output file (ORDEXP) created by a previous run of the EXPORT function.
DBID = number
This parameter selects the database to be used.
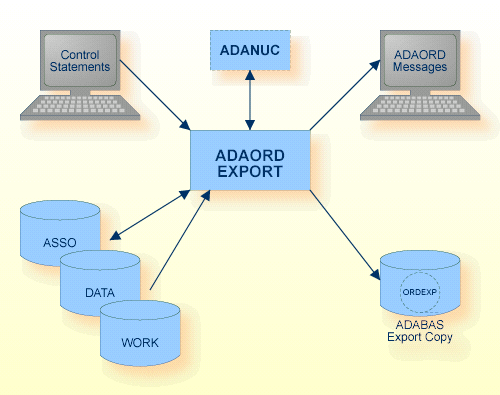
EXPORT = (number[-number][,number[-number]]...)
[,FDT]
[,SORTSEQ = ({descriptor_name|ISN|PHYSICAL},...)]
This function exports (copies) one or more files from the database to a sequential output file (ORDEXP). In order to maintain referential integrity in the export copy, all files that are connected via referential constraints to a specified file are also exported. The file numbers specified are only taken into consideration if they are the file numbers of base files; the corresponding LOB files for the selected files are exported automatically with the base files without having to be specified. An EXPORT consists of copying each file's Data Storage, together with the information that is required to reestablish its index. All of the files to be processed are written to ORDEXP in the sequence in which they are specified. Overlapping ranges and numbers are removed.
Note:
If the checkpoint file is included in the file list,
it will be processed last.
This parameter displays the FDT of the file to be processed.
This parameter controls the sequence in which the Data Storage is processed. If specifies either the field name of a descriptor, subdescriptor or superdescriptor, or the keyword `ISN' or `PHYSICAL'.
The default is physical sequence.
The following values can be specified:
| Value | Sequence |
|---|---|
| descriptor_name |
If the name of a descriptor, sub- or superdescriptor is specified, the data records are processed in ascending logical sequence of the descriptor values to which the field name refers. A field with the MU, MC or NU option or one that is contained in a periodic group or a sub- or superdescriptor derived from such a field must not be specified. Logical sequence can be used only if a single file has been selected. |
| ISN |
If ISN is specified, the data records are processed in ascending ISN sequence. |
| PHYSICAL |
If PHYSICAL is specified or if the SORTSEQ parameter is omitted, the data records are processed in the physical sequence in which they are stored in the Data Storage. |
The performance when processing in logical sequence and ISN sequence is better if the database is online (provided that the buffer pool is large enough).
If one value is specified for SORTSEQ, that value is valid for all files. If more than one value is specified, the number of values must be the same as the number of file ranges specified for the EXPORT parameter. In this case, the first file range is exported in the first specified sort sequence, the second file range is exported in the second specified sort sequence, and so on.
EXPORT = (1, 20-30, 40) SORTSEQ = (AA, PHYSICAL, ISN)
File 1 is exported in the sequence of descriptor AA, files 20-30 are exported in physical sequence and file 40 is exported in ISN sequence.
FILES = (number[[-number], number[-number]] ...)
This parameter is used to display information concerning the status of the specified files contained on the sequential input file (ORDEXP).
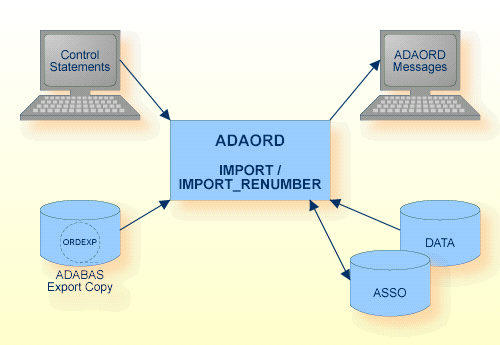
IMPORT = (number[-number][,number[-number]]...)
[,ACRABN = number]
[,ASSOPFAC = number]
[,DATAPFAC = number]
[,DSRABN = number] [,DSSIZE = number[B|M] ]
[,LOBACRABN = number]
[,LOBDSRABN = number]
[,LOBNIRABN = number]
[,LOBSIZE = numberM]
[,LOBUIRABN = number]
[,MAXISN = number]
[,NIRABN = number|(number,number)]
[,NISIZE = number[B|M]|(number[B|M],number[B|M])]
[,UIRABN = number|(number,number)]
[,UISIZE = number[B|M]|(number[B|M],number[B|M])]
This function imports one or more files into a database, using the data on the sequential file (ORDEXP) produced by a previous run of ADAORD. In order to maintain referential integrity, all files connected via referential constraints to a specified file are also imported. The file numbers specified are only taken into consideration if they are the file numbers of base files; the corresponding LOB files for the selected files are imported automatically with the base files without having to be specified. The file numbers specified are sorted into ascending sequence. Overlapping ranges and numbers are removed.
The file numbers specified must not be loaded in the database.
By default, ADAORD controls the file placement and the allocation quantities. The parameters that can be used to overwrite these defaults may be used only if a single file has been selected.
Please refer to the IMPORT_RENUMBER function for the description of the parameters.
IMPORT_RENUMBER = (number, number[,number])
[,ACRABN = number]
[,ASSOPFAC = number]
[,DATAPFAC = number]
[,DSRABN = number] [,DSSIZE = number[B|M] ]
[,LOBACRABN = number]
[,LOBDSRABN = number]
[,LOBNIRABN = number]
[,LOBSIZE = numberM]
[,LOBUIRABN = number]
[,MAXISN = number]
[,NIRABN = number|(number,number)]
[,NISIZE = number[B|M]|(number[B|M],number[B|M])]
[,UIRABN = number|(number,number)]
[,UISIZE = number[B|M]|(number[B|M],number[B|M])]
This function imports a file into a database, using the data on the sequential file (ORDEXP) produced by a previous run of ADAORD. It is not possible to import and renumber a file that is connected to another file via referential integrity. Constraints must either dropped before exporting the files, or the files must be imported without renumbering and be renumbered later (ADADBM RENUMBER). The first number given defines the base file to be imported, and the second number is the new file number to be assigned to the file. The third, optional number is the new file number for the LOB file. If the third number is not specified, the LOB file number (if it exists) remains unchanged.
The new file number must not be loaded in the database.
Unless otherwise specified, ADAORD controls the file placement and the allocation quantities.
This parameter specifies the RABN at which the space allocation for the Address Converter (AC) is to start.
If this parameter is omitted, ADAORD assigns the starting RABN.
This parameter specifies the new padding factor to be used for the file's index. The number specified is the percentage of each index block which is not to be used by ADAORD or a subsequent run of the mass update utility ADAMUP. This padding area is reserved for future use if additional entries have to be added to the block by the Adabas nucleus. This avoids the necessity of having to relocate overflow entries to another block.
A value may be specified in the range of 0 to 95.
A small padding factor (0 to 10) should be specified if little or no descriptor updating is expected. A larger padding factor (10 to 50) should be specified if a large amount of descriptor updating is expected in which new descriptor values are created.
If this parameter is omitted, the current padding factor in effect for the file's index is used.
This parameter specifies the new padding factor to be used for the file's Data Storage. The number specified is the percentage of each data block which is not to be used by ADAORD. This padding area is reserved for future use if any record in a block requires additional space as result of record updating by the Adabas nucleus. This avoids the necessity of having to relocate overflow entries to another block.
A value may be specified in the range of 0 to 95.
A small padding factor (0 to 10) should be specified if there is little or no record expansion. A larger padding factor (10 to 50) should be specified if there is a large amount of record updating which will cause expansion.
If this parameter is omitted, the current padding factor in effect for the file's Data Storage is used.
This parameter specifies the RABN at which the space allocation for the file's Data Storage (DS) is to start.
If this parameter is omitted, ADAORD assigns the start RABN.
This parameter specifies the number of blocks (B) or megabytes (M) to be initially assigned to the file's Data Storage (DS). By default, the size is given in megabytes.
If this parameter is omitted, ADAORD calculates the size based on the old number of blocks allocated and the difference between the old and new padding factor.
This parameter specifies the RABN at which the space allocation for the LOB file's Address Converter (AC) is to start.
If this parameter is omitted, ADAORD assigns the start RABN.
This parameter specifies the RABN at which the space allocation for the LOB file's Data Storage (DS) is to start.
If this parameter is omitted, ADAORD assigns the start RABN.
This parameter specifies the RABN at which the space allocation for the LOB file's Normal Index (NI) is to start.
If this parameter is omitted, ADAORD assigns the start RABN.
This parameter specifies the number of megabytes to be initially assigned to the LOB file's Data Storage (DS). The AC size, NI size and UI size for the LOB file are derived from this size.
If this parameter is omitted, ADAORD calculates the size based on the old number of blocks allocated and the difference between the old and new padding factor.
This parameter specifies the RABN at which the space allocation for the LOB file's Upper Index (UI) is to start.
If this parameter is omitted, ADAORD assigns the start RABN.
This parameter specifies the highest permissible ISN for the file. ADAORD uses this parameter to determine the amount of space to be allocated for the file's Address Converter (AC).
Because there is no automatic extension of the initial allocation, a value that is smaller than the file's current first free ISN will cause ADAORD to terminate execution and return an error status if there are ISNs outside the Address Converter.
If this parameter is omitted, the value of MAXISN currently in effect for the file's Address Converter is used.
A contiguous-best-try allocation is used.
This parameter specifies the RABN(s) at which the space allocation for the file's Normal Index (NI) is to start. Adabas usually stores small descriptor values (<= 253 bytes) in small index blocks (block size < 16 KB) and large descriptor values in large index blocks (block size >= 16 KB. For this reason, it is possible to specify 2 RABNs - if you specify 2 RABNs, one must have a block size < 16 KB, and the other must have a block size >=16 KB.
If this parameter is omitted, ADAORD assigns the start RABN.
This parameter specifies the number of blocks (B) or megabytes (M) to be initially assigned to the file's Normal Index (NI). By default, the size is given in megabytes. If two values are specified and the NIRABN parameter is also specified, the first value corresponds to the first value of the NIRABN parameter, and the second value corresponds to the second value of the NIRABN parameter. If two values are specified and the NIRABN parameter is not specified, the first value specifies the size of small normal index blocks (< 16 KB), and the second value specifies the size of large NI blocks (>= 16 KB).
If this parameter is omitted, ADAORD calculates the size based on the old number of blocks allocated and the difference between the old and new padding factor.
This parameter specifies the RABN(s) at which the space allocation for the file's Upper Index (UI) is to start. Adabas usually stores small descriptor values (<= 253 bytes) in small index blocks (block size < 16 KB) and large descriptor values in large index blocks (block size >= 16 KB. For this reason, it is possible to specify 2 RABNs - if you specify 2 RABNs, one must have a block size < 16 KB, and the other must have a block size >=16 KB.
If this parameter is omitted, ADAORD assigns the start RABN.
This parameter specifies the number of blocks (B) or megabytes (M) to be initially assigned to the file's Upper Index (UI). By default, the size is given in megabytes. If two values are specified and the UIRABN parameter is also specified, the first value corresponds to the first value of the UIRABN parameter, and the second value corresponds to the second value of the UIRABN parameter. If two values are specified and the UIRABN parameter is not specified, the first value specifies the size of small upper index blocks (< 16 KB), and the second value specifies the size of large UI blocks (>= 16 KB).
If this parameter is omitted, ADAORD calculates the size based on the old number of blocks allocated and the difference between the old and new padding factor.
REORDER = *
This function is used to change the layout of a whole database. It rearranges the database's global areas, eliminates fragmentation in the DSST and the files' Address Converter, Data Storage, Normal Index and Upper Index extents by physically changing their placement. It also re-establishes the files' padding factors. Exclusive control of the database container files is required.
A REORDER database implicitly exports the files, deletes them from the database and then re-imports them. The sequential file (ORDEXP) that is created during the REORDER is kept.
Note:
ADAORD uses a best-fit algorithm for the allocation of the disk
space for the files. Therefore, it may occur that the first container of a
given type remains empty if it is followed by another container with adequate
block size which is smaller than the first one.
ADAORD has no restart capability.
An abnormally terminated EXPORT must be rerun from the beginning.
An abnormally terminated IMPORT of one or more files will result in lost RABNs for the last file being imported. These RABNs can be recovered by executing ADADBM's RECOVER function. The files preceding the one being processed when the interrupt occurred will be available in the database. Therefore, the IMPORT function should be rerun starting with the file number at which the interrupt occurred.
An abnormally terminated IMPORT_RENUMBER will result in lost RABNs for the file being imported. These RABNs can be recovered by executing ADADBM's RECOVER function. The IMPORT_RENUMBER function has to be rerun from the beginning.
An abnormally terminated REORDER at the database level may result in a database that cannot be accessed if the interrupt occurred while reordering the database's global areas (GCB, FST, DSST, etc.). In this case, either a new empty database has to be created using ADAFRM or the old database has to be reestablished from an Adabas backup copy, using ADABCK's RESTORE database function. If the interrupt occurred during the re-import phase, it will result in lost RABNs for the last file being imported. These RABNs can be recovered by executing ADADBM's RECOVER function. The files preceding the one being processed when the interrupt occurred will be available in the database. The remaining files can be obtained from the sequential work file (ORDEXP) by using ADAORD's IMPORT function.
In the examples below, the files 1, 2, 4, 6, 7, 8, 10, 11, 12 and 25 are loaded in database 1. Database 2 contains files 3, 6 and 11.
adaord: dbid = 1 adaord: export = (1-4,7,10-25)
Files 1, 2, 4, 7, 10, 11, 12 and 25 are exported from database 1.
adaord: dbid = 2 adaord: import = (1-10,12)
Files 1, 2, 4, 7, 10 and 12 are imported into database 2. It is not
possible to specify "import=(1-12)" because ADAORD first checks to
see if one of the files to be imported is already loaded , and if it is, then
the whole import is rejected - in this case file 11 is already loaded.
adaord: dbid = 2 adaord: import_renumber = (11,19), acrabn = 131, datapfac = 20
File 11 is imported into database 2 using a new file number of 19 (because 11 is already in use). The file's Address Converter (AC) is to be allocated at ASSO RABN 131. The new padding factor for the Data Storage (DS) is 20 percent.
adaord: dbid = 1 adaord: reorder = *
The whole database is reordered.