This document describes the utility "ADAMUP".
The following topics are covered:
The mass update utility ADAMUP adds records to, or deletes records from a file in a database. It does not require the Adabas nucleus to be active.
The output files produced by the compression utility ADACMP or the unload utility ADAULD may be used as input for a mass add.
Note:
The ADAMUP ADD function can process MUPDTA/MUPDVT files created with
earlier Adabas versions, but not MUPDTA/MUPDVT files created with later Adabas
versions.
Input files produced by ADACMP or ADAULD with the SINGLE_FILE option or from a previous run of ADAMUP using the DELETE function with the LOG option can also be used.
Input files produced without descriptor value tables (SHORT option in ADAULD or LOG=SHORT option in ADAMUP) can be processed if the database file to be processed does not contain any descriptors.
The input for the DELETE function is provided in an input file. Each record contains one or more ISNs or ISN ranges.
Records may be both added to and deleted from a database file during a single run of ADAMUP.
If the utility writes records to the error file, it will exit with a non-zero status.
This utility is a single-function utility.
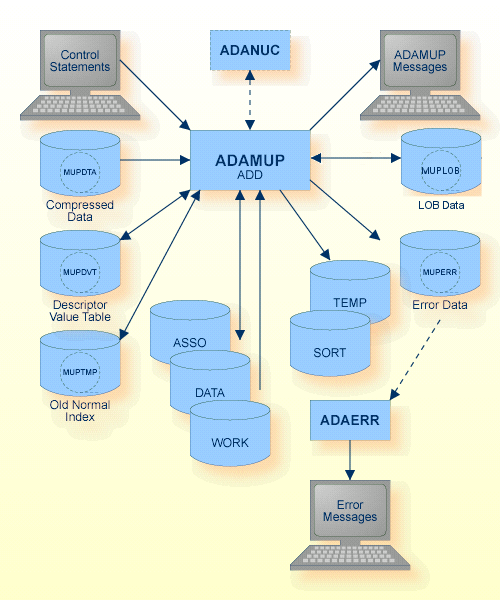
The sequential files MUPDTA, MUPDVT, MUPTMP, MUPLOB and MUPERR can have multiple extents. For detailed information about sequential files with multiple extents, see Administration, Using Utilities.
| Data Set | Environment Variable/ Logical Name |
Storage Medium |
Additional Information |
|---|---|---|---|
| Associator | ASSOx | Disk | |
| Data storage | DATAx | Disk | |
| Compressed input data |
MUPDTA | Tape, Disk | |
| Descriptor values | MUPDVT | Tape, Disk | |
| Rejected data | MUPERR | Disk, Tape (* see note) | |
| LOB data | MUPLOB | Disk, Tape | Temporary working space, will be deleted again when ADAMUP terminates |
| Normal index | MUPTMP | Disk, Tape | Temporary working space, will be deleted again when ADAMUP terminates |
| Sort storage | SORTx TEMPLOCx |
Disk | Administration Manual, temporary working space |
| Control statements | stdin/ SYS$INPUT |
Utilities Manual | |
| ADAMUP messages | stdout/ SYS$OUTPUT |
Messages and Codes | |
| Temporary storage | TEMPx | Disk | |
| Work | WORK1 | Disk |
Note:
(*) A named pipe can be used for this sequential file
(not on OpenVMS, see Administration, Using
Utilities for details).
In cases without an active nucleus and no pending AUTORESTART, the WORK may be used as TEMP by setting the environment variable/logical name TEMP1 to the same value as WORK1.
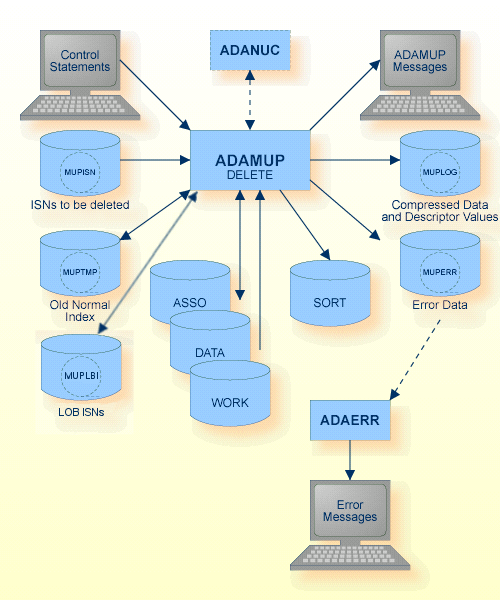
The sequential files MUPTMP, MUPLBI, MUPLOG and MUPERR can have multiple extents. For detailed information about sequential files with multiple extents, see Administration, Using Utilities.
| Data Set | Environment Variable/ Logical Name |
Storage Medium |
Additional Information |
|---|---|---|---|
| Associator | ASSOx | Disk | |
| Data storage | DATAx | Disk | |
| Rejected data | MUPERR | Disk, Tape (* see note) | |
| ISNs to be deleted | MUPISN | Disk, Tape | |
| LOB ISNs | MUPLBI | Disk, Tape | Temporary working space, will be deleted again when ADAMUP terminates |
| Compressed data | MUPLOG | Disk, Tape | |
| Normal index | MUPTMP | Disk, Tape | Temporary working space, will be deleted again when ADAMUP terminates |
| Sort storage | SORTx TEMPLOCx |
Disk | Administration Manual, temporary working space |
| Control statements | stdin/ SYS$INPUT |
Utilities Manual | |
| ADAMUP messages | stdout/ SYS$OUTPUT |
Messages and Codes | |
| Work | WORK1 | Disk |
Note:
(*) A named pipe can be used for this sequential file
(not on OpenVMS, see Administration, Using
Utilities for details).
The following table shows the nucleus requirements for each function and the checkpoints written:
| Function | Nucleus must be active | Nucleus must NOT be active | Nucleus is NOT required | Checkpoint written |
|---|---|---|---|---|
| FDT | X | - | ||
| UPDATE | X(* see note 1) | X(* see note 2) | X(* see note 3) | SYNP |
| SUMMARY | X | - |
Notes:
The following control parameters are available:
M DBID = number
FDT
SUMMARY
UPDATE = number [,FDT]
[ADD [,add_keywords]]
[DELETE [,delete_keywords]]
D [,[NO]FORMAT]
D [LWP = number[K]]
DBID = number
This parameter selects the database to be used.
FDT
This parameter displays the Field Definition Table (FDT) of the selected file in the database. If records are to be added to a file, the FDT of the sequential input file containing these records can also be displayed. This parameter may also be used in an ADD/DELETE specification.
Depending on the context in which the FDT parameter is used, the Field Definition Table contained in the sequential input file MUPDTA and/or the Field Definition Table contained in the selected database file is displayed.
SUMMARY
This parameter displays the Descriptor Space Summary (DSS) on the sequential input file that contains the compressed records. This display is identical to the one at the end of the ADACMP, ADAULD or ADAMUP run which generated this input file, and can be used to estimate the space required in the index.
Because the information has to be obtained from the last block of the input file on magnetic tape, a mechanical fast wind is required and some delay should be expected.
Additionally, the following information is displayed:
required SORT size (for default LWP)
recommended TEMP size (the size required to do the index update in one pass)
current size of SORT (if present)
LWP needed for memory-resident sort
Recommended size of LWP and SORT (if LWP is large enough to allow a smaller SORT size to be used).
Note:
If the default LWP is large enough to do a
memory-resident sort, SORT sizes are not displayed.
UPDATE = number [,FDT]
[ADD [,add_keywords]]
[DELETE [,delete_keywords]]
[,[NO]FORMAT]
[LWP = number[K]]
This function specifies the file to which records are to be added/deleted. Since ADAMUP requires exclusive control of the file, it cannot be used for an Adabas system file while the nucleus is active. You are not allowed to specify a LOB file.
ADD [,DE_MATCH = keyword] [,FDT] [,[NO]NEW_FDT] [,NUMREC = number] [,SKIPREC = number] [,UQ_CONFLICT = keyword] [,RI_CONFLICT = keyword] [,[NO]USERISN]
This parameter indicates that records are to be added to the file specified by the UPDATE parameter.
The input for mass add is produced by the compression utility ADACMP, the unload utility ADAULD or by a previous run of the mass update utility ADAMUP using the DELETE function with the LOG option set.
ADAMUP compares the FDT in the sequential input file that contains the compressed records with the FDT of the database file specified. The FDTs must have identical layouts and must use the same field names, formats, lengths and options.
Descriptors in the database file can be a subset of the descriptors defined in the FDT in the sequential input file, but the input file must contain descriptor value table (DVT) entries for all descriptors defined in the database file. Therefore, input files produced without descriptor value tables (SHORT option) can only be processed if there are no descriptors currently defined in the database file to be updated.
If the input for mass update contains LOB data, the Adabas file must have an assigned LOB file.
This parameter is used to indicate which action is to be taken if a descriptor provided with the input data is not a descriptor in the actual FDT of the file. If keyword = IDENTICAL, ADAMUP terminates processing and returns an error message. If keyword = SUBSET, ADAMUP ignores a descriptor which is in the input file, but which has been removed from the database file.
The default is DE_MATCH=IDENTICAL.
If NEW_FDT is specified, the FDT of the file is replaced by the FDT of the MUPDTA file. NEW_FDT can only be specified if the file is empty when ADAMUP is started.
NEW_FDT must be specified if the FDT of the file in the database and the FDT of the MUPDTA file are different - a mass update is not possible if the FDTs are different and the file is not empty.
The default is NONEW_FDT.
This parameter specifies the number of records to be added. If NUMREC is specified, ADAMUP terminates after adding the predefined number of records, unless an end-of-file condition on the input file causes ADAMUP processing to end. If NUMREC is omitted and SKIPREC is not specified, all records in the input file are added.
This parameter specifies the number of records in the input file to be skipped before starting to add records.
This parameter is used to indicate which action is to be taken if duplicate values are found for a unique descriptor. 'keyword` may take the values ABORT or RESET. If ABORT is specified, ADAMUP terminates execution and returns an error status if duplicate UQ descriptor values are found. If RESET is specified, conflicting ISNs are written to the error log, the UQ status of the descriptors in question is removed and processing continues.
The default is UQ_CONFLICT=ABORT.
This parameter is used to indicate which action is to be taken if referential integrity is violated. 'keyword` may take the values ABORT or RESET. If ABORT is specified, ADAMUP terminates execution and returns an error status. The index is marked as not accessible. If RESET is specified, the violated constraint is removed. In both cases the violating ISNs are stored in the error log.
The default is RI_CONFLICT=ABORT.
This option indicates whether the ISN to be assigned to each record is to be taken from the input file or not.
This option should be set to USERISN if the user wants to control ISN assignment for each record added to the database file. Each ISN provided must be:
a four-byte binary number immediately preceding each data record;
within the current limit (MAXISN) for the file - the file's Address Converter is not automatically extended;
unique within the specified file.
Otherwise ADAMUP terminates execution and returns an error message.
Note that problems could arise if this option is set to USERISN for an input file created by an unload that is based on a descriptor which is a multiple-value field. This is because the same record may have been unloaded more than once. Please refer to the ADAULD utility, SORTSEQ parameter for more information.
If this option is set to NOUSERISN, the ISN for each record is assigned by ADAMUP. However, the ISN of a DVT record that has been previously re-vectored by a hyperexit will not be changed by ADAMUP.
The default is NOUSERISN.
DELETE
[,DATA_FORMAT = keyword]
[,FDT]
[,ISN_NOT_PRESENT = keyword]
[,LOG = keyword | ,NOLOG]
This parameter indicates that records are to be deleted from the file specified by the UPDATE parameter. The ISNs of the records to be deleted are given in an input file.
This parameter defines the data type of the records in the input file containing the ISNs to be deleted. Each record contains one or more ISNs or ISN ranges.
Valid ISNs are within the range 1...MAXISN.
In accordance with the formats supported, `keyword' may take the following values:
| Keyword | Meaning |
|---|---|
| BINARY |
A single ISN is contained in a 4 byte binary value, an ISN range is contained in two consecutive binary values, with the high-order bit set in the second value. Blocks in this file start with 2 byte exclusive length field. Note: |
| DECIMAL |
Each record has the following layout: [number[-number] [,number[-number]]...] [;comment] where `number' is decimal number with 1 to 10 digits. |
ADAMUP validates all input records in a first step. ADAMUP displays the line number and the offset for each error that is detected. If an error is detected, ADAMUP terminates execution once the input file has been completely parsed.
The default is DATA_FORMAT = BINARY.
This parameter indicates the action to be taken when an ISN given in the input file of records to be deleted is:
not within the current limit (MAXISN) for the file;
not in the file's Address Converter.
`keyword' may take the following values:
| Keyword | Meaning |
|---|---|
| ABORT | ADAMUP aborts execution and returns an error message if a conflicting ISN is detected. |
| IGNORE | ADAMUP writes the conflicting ISNs to the error log and continues processing. |
The default is ISN_NOT_PRESENT=IGNORE
LOG=keyword indicates that the deleted records are logged in a sequential file. The records are written in compressed format and are identical to those produced by the compression utility ADACMP and the unload utility ADAULD. Because each data record is preceded by its ISN, these ISNs can be used as user ISNs when reloading or mass-adding this file (see the USERISN option described above).
`keyword' may take the following values:
| Keyword | Meaning |
|---|---|
| FULL | The descriptor values which are required to build the index, are included in the output file. |
| SHORT | The descriptor values which are required to build the index, are omitted from the output file. |
ADAMUP writes both the compressed data records and the descriptor values generated to a single file.
The default is NOLOG.
This option may be used to format blocks at the end of the file's Normal Index (NI) and Upper Index (UI) extents if the new index (after the modifications have been made) requires less space than the old index did. This may be the result of deletions within the index, recovery of lost index blocks or re-establishing the padding factor.
Because these blocks are returned to the file's unused blocks, there are no side-effects if the data stored in these blocks is not deleted. If this option is set to FORMAT, ADAMUP overwrites these blocks with binary zeros.
The default is NOFORMAT.
This parameter specifies the size of the Work Pool to be used for the sort during ADAMUP execution.
The minimum size and the default size is 0 bytes.
ADAMUP has no restart capability. An abnormally terminated ADAMUP must be rerun from the beginning.
If the Data Storage space becomes exhausted, ADAMUP will not abort, but will attempt to build the index for the records that have already been loaded; this means that the file is consistent, and the remaining records can then be loaded with the SKIPREC option after additional Data Storage space has been allocated.
It is recommended that the SORT data set does not reside on the same volume as the Associator and the input file that contains the Descriptor Value Tables.
The SORT data set may be omitted when adding only small amounts of data. ADAMUP then performs an in-core sort.
Use the SUMMARY function to get information about the required SORT and LWP sizes.
It is recommended that the TEMP data set does not reside on the same volume as the input file that contains the Descriptor Value Tables and the SORT. Although the size of TEMP is closely related to the performance when loading the Normal/Main Index, successful execution does not depend on a given size or the presence of a TEMP.
Use the SUMMARY function to display the recommended TEMP size.
adamup: dbid=1 adamup: update=10 adamup: add, userisn
File 10 of database 1 is updated by adding new records. The ISN given with each input record is used.
adamup: dbid=1 adamup: update=10 adamup: delete
The records identified by the ISNs provided on the input file are to be deleted from file 10 of database 1. The ISNs to be deleted are in binary format.
adamup: dbid=1 adamup: update=10 adamup: add, skiprec=1000 adamup: delete, data_format=decimal, log=full
New records are to be added while old ones are deleted from file 10 of database 1. The first thousand records found on the input file are not added. The ISN for each record added is assigned by ADAMUP. The ISNs of the records to be deleted are supplied in decimal format on the input file. All records which have been deleted are logged on an output file. The values required to re-create the inverted list when reloading are included in the log.