Reading Partial Characters
The following table describes how the parser reads partial characters:
Character Boundary Condition | How the Parser Handles the Condition |
Reading a fixed position field that begins in the middle of a multi-byte character. | The field starts on the next complete character. The partial character is ignored. |
Reading a fixed position field that ends in the middle of a multi-byte character. | The field ends on the previous complete character. The partial character is not included in the field. |
Reading a fixed position record that begins or ends in the middle of a multi-byte character. | If the bytes encode to an invalid character, an exception is thrown. Note: | If the bytes that begin or end the record are encoded to a valid character, it will be the wrong character. |
|
To illustrate a case where the parser reads fixed position records that begin and end in the middle of a multi-byte character, consider the following multi-byte encoding:
12121212
These eight bytes represent four two-byte characters. If we specified a fixed length file with a record length of three bytes instead of two bytes, the parser would read this encoding as follows, producing an undesirable result:
Record 1: | 121 |
Record 2: | 212 |
Record 3: | 12 |
Note that:
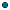
Record 1 contains one character, formed by the first two bytes of the file. The last byte is a partial character; the parser ignores it.
Record 2 contains one character, formed by the fifth and sixth bytes of the file. The character formed by the third and fourth bytes is lost because these bytes span Records 1 and 2, and cannot be properly decoded.
Record 3 contains one character, formed by the seventh and eighth bytes.
