Setting up API Portal HA setup
This procedure describes in detail the setting up of the HA setup for API Portal.
Prerequisites:
Install API Portal 10.0 but do not start any runnables.
To configure API Portal HA set up
1. Create a 3-node environment.
a. On machine1, create a nodelist.pt file in the folder C:\SoftwareAG\API_Portal\server, which contains the following lines:
add node n1 machine1 @18006 Clous g3h31m
add node n2 machine2 @18006 Clous g3h31m
add node n3 machine3 @18006 Clous g3h31m
set current node n1
Note: | The value 18006 is based on the version. |
b. Replace machine1, machine2, and machine3 with the names or IP addresses of your machines.
c. Run the following command:
C:\SoftwareAG\API_Portal\server>acc\acc.bat -n
C:\SoftwareAG\API_Portal\server\nodelist.pt –c
C:\SoftwareAG\API_Portal\server\generated.apptypes.cfg
This creates an ensemble between the instances in the cluster.
d. To view the 3-node cluster in ACC, run the command:
ACC+ n1>list nodes
the 3-node cluster has all nodes listed listening on port 18006 using REST services as follows:
n1 : machine1 (18006) OK
n2 : machine2 (18006) OK
n3 : machine3 (18006) OK
2. Cleanup the unnecessary runnables by running the following commands, in ACC, to deconfigure the runnables for all the 3 nodes:
ACC+ n1>on n1 deconfigure zoo_m
ACC+ n1>on n1 deconfigure cloudsearch_m
ACC+ n1>on n1 deconfigure apiportalbundle_m
ACC+ n1>on n2 deconfigure zoo_m
ACC+ n1>on n2 deconfigure postgres_m
ACC+ n1>on n2 deconfigure loadbalancer_m
ACC+ n1>on n3 deconfigure zoo_m
ACC+ n1>on n3 deconfigure postgres_m
ACC+ n1>on n3 deconfigure loadbalancer_m
3. Create a zookeeper cluster in ACC by running the following commands:
ACC+ n1>on n1 add zk
ACC+ n1>on n2 add zk
ACC+ n1>on n3 add zk
ACC+ n1>commit zk changes
You can view the following configuration using the ACC command after you start the zoo runnables:
ACC+ n1>list zk instances
3 Zookeeper instances:
Node InstID MyID State Cl Port Port A Port B Type
n1 zoo0 1 STARTED 14281 14285 14290 Master
n2 zoo0 2 STARTED 14281 14285 14290 Master
n3 zoo0 3 STARTED 14281 14285 14290 Master
4. Reconfigure the three elasticsearch runnables to form a cluster through ACC by running the following commands:
ACC+ n1>on n1 reconfigure elastic_m +ELASTICSEARCH.cluster.name = apiportal
ELASTICSEARCH.discovery.zen.ping.unicast.hosts"machine1:<esTCPport>,
machine2:<esTCPport>, machine3:<esTCPport>"
+ELASTICSEARCH.discovery.zen.minimum_master_nodes=2 -zookeeper.connect.string
+ELASTICSEARCH.node.local = false +ELASTICSEARCH.index.number_of_replicas=1
-ELASTICSEARCH.sonian.elasticsearch.zookeeper.client.host
ACC+ n1>on n2 reconfigure elastic_m +ELASTICSEARCH.cluster.name = apiportal
ELASTICSEARCH.discovery.zen.ping.unicast.hosts="machine1:<esTCPport>,
machine2:<esTCPport>, machine3:<esTCPport>"
+ELASTICSEARCH.discovery.zen.minimum_master_nodes=2 -zookeeper.connect.string
+ELASTICSEARCH.node.local = false +ELASTICSEARCH.index.number_of_replicas=1
-ELASTICSEARCH.sonian.elasticsearch.zookeeper.client.host
ACC+ n1>on n3 reconfigure elastic_m +ELASTICSEARCH.cluster.name = apiportal
ELASTICSEARCH.discovery.zen.ping.unicast.hosts="machine1:<esTCPport>,
machine2:<esTCPport>, machine3:<esTCPport>"
+ELASTICSEARCH.discovery.zen.minimum_master_nodes=2 -zookeeper.connect.string
+ELASTICSEARCH.node.local = false +ELASTICSEARCH.index.number_of_replicas=1
-ELASTICSEARCH.sonian.elasticsearch.zookeeper.client.host
Note: | In the three commands above, replace machine1, machine2, and machine3 with the names or IP addresses of your machine s and esTCPport with elasticsearch TCP Port. |
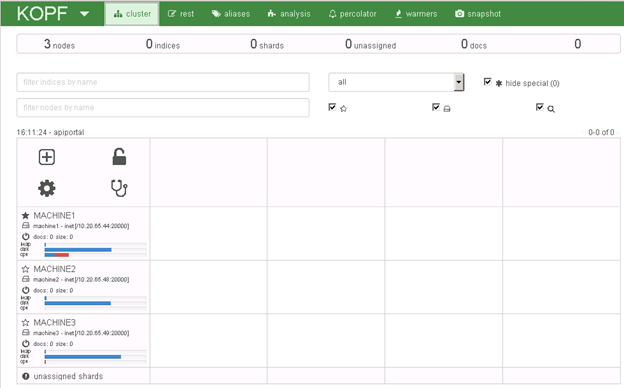
To ensure everything is working fine, view the cluster at http://<machine name>:<elasticsearchhttpPort>/_plugin/kopf. You can see that the elasticsearch cluster consists of three nodes, that the cluster name is apiportal, and that machine1 is the master node, indicated by a solid star as shown.
5. Reconfigure kibana runnable on the nodes n2 and n3 as follows:
on n1 reconfigure kibana_m -zookeeper.connect.string
on n2 reconfigure kibana_m -zookeeper.connect.string
on n3 reconfigure kibana_m -zookeeper.connect.string
6. To reconfigure the PostgreSQL database on n1 so that it knows about all zookeeper cluster members and accepts connections from all locations:
on n1 reconfigure postgres_m -zookeeper.connect.string
+postgresql.listen_addresses = "'*'"
7. Define two cloudsearch instances, on the nodes n2 and n3, where each one belongs to a different data center:
on n2 reconfigure cloudsearch_m -zookeeper.connect.string
+zookeeper.application.instance.datacenter = n2
on n3 reconfigure cloudsearch_m -zookeeper.connect.string
+zookeeper.application.instance.datacenter = n3
8. Reconfigure the apiportalbundle runnable on the nodes n2 and n3 as follows:
on n2 reconfigure apiportalbundle_m -zookeeper.connect.string
on n3 reconfigure apiportalbundle_m -zookeeper.connect.string
9. Reconfigure the loadbalancer on n1 to point to all three zookeeper cluster members as follows:
on n1 reconfigure loadbalancer_m -zookeeper.connect.string
10. Change the startup order of the runnables by running the following commands:
ACC+ n1>on n1 set runnable.order = "zoo0 < (elastic_m, postgres_m)
< loadbalancer_m"
ACC+ n1>on n2 set runnable.order = "zoo0 < (elastic_m, kibana_m)
< cloudsearch_m < apiportalbundle_m"
ACC+ n1>on n3 set runnable.order = "zoo0 < (elastic_m, kibana_m)
< cloudsearch_m < apiportalbundle_m"
11. Start all runnables using the startup script.
#
# start Zookeeper Ensemble
#
on n1 start zoo0
on n2 start zoo0
on n3 start zoo0
on n1 wait for STARTED of zoo0
on n2 wait for STARTED of zoo0
on n3 wait for STARTED of zoo0
#
# start ElasticSearch Cluster
#
on n1 start elastic_m
on n2 start elastic_m
on n3 start elastic_m
on n1 wait for STARTED of elastic_m
on n2 wait for STARTED of elastic_m
on n3 wait for STARTED of elastic_m
#
# start Kibana
#
on n1 start kibana_m
on n2 start kibana_m
on n3 start kibana_m
on n1 wait for STARTED of kibana_m
on n2 wait for STARTED of kibana_m
on n3 wait for STARTED of kibana_m
#
# start PostgreSQL Database
#
on n1 start postgres_m
on n1 wait for STARTED of postgres_m
#
# start CloudSearch
#
on n2 start cloudsearch_m
on n3 start cloudsearch_m
on n2 wait for STARTED of cloudsearch_m
on n3 wait for STARTED of cloudsearch_m
#
# start API Portal Bundle
#
on n2 start apiportalbundle_m
on n3 start apiportalbundle_m
on n2 wait for STARTED of apiportalbundle_m
on n3 wait for STARTED of apiportalbundle_m
#
# finally, start loadbalancer
#
on n1 start loadbalancer_m
on n1 wait for STARTED of loadbalancer_m
12. Ensure the HA setup is successfully running.
In the default installation, access the User Management Component (UMC) at http://<machine name>/umc, the ARIS Document Storage (ADS) at http://<machine name>/ads, the collaboration component at http://<machine name>/collaboration, and the API Portal at http:/<machine name>.
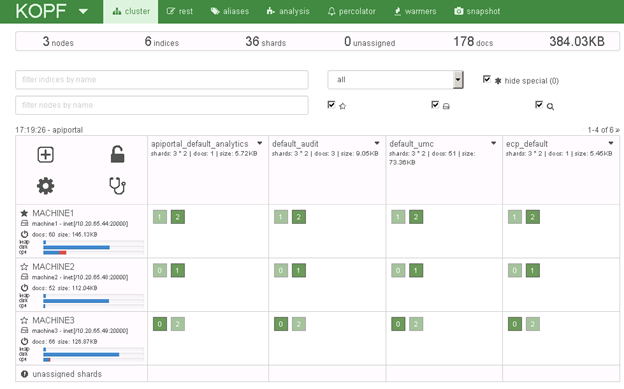
Each index is split in 3 parts, called shards, which are replicated once and distributed over the three available nodes as shown. If one node goes offline, the system can still fill up the complete index making it a fail-over system.