The physical schema specifies physical storage information, for example for mapping and indexing.
This section describes the Tamino-specific extensions to the physical schema under the following headings:
The following topics are covered in this section:
This element specifies whether a structure index is created for the
corresponding doctype. The element is of type
xs:NMTOKEN.
The tsd:structureIndex element
can have one of the following values:
No structural indexing is done.
The repository registers the existence of an undeclared node for the doctype.
The repository registers both the existence of undeclared nodes and the instances in which they occur.
The default value is condensed.
Computed indexes defined for a doctype allow for user-defined indexing based on an indexing function defined in an XQuery module. For details refer to the section Advanced Indexes in the Performance Guide.
For a description of how to define unique keys, refer to the topic Definition of Unique Keys in the section Physical Schema for Elements and Attributes.
The tsd:compress element specifies
compression options for the physical storage of the data. It specifies whether
instances belonging to the corresponding doctype are physically stored in a
compressed or an uncompressed format (the latter is recommended for small data
records only). Also, the user can specify maximum compression or optimal
performance. The tsd:compress element is of
type
xs:NMTOKEN.
Note:
This option is not applicable for non-XML data.
The following values are allowed:
This is the default value. Tamino checks the data to be stored and uses the best compromise between speed and size.
Always compress as much as possible. This choice is appropriate if you are primarily interested in reducing storage size. Especially for small documents, this minimizes disk space but increases retrieval time.
Do not compress small data records. Large documents are not affected by this setting. This setting is recommended if you expect most of your documents to be small (< 8000 characters) and you want to optimize processing speed, at the price of increased storage space.
Do no compression at all.
Each character is replaced by its UTF-8 representation. This can result in a compression factor of up to 4, depending on platform and data.
Indexing of non-XML data is possible, but in a somewhat different
manner than the indexing of XML data. The following example shows how to define
a non-XML index using the tsd:nonXML element:
<?xml version = "1.0" encoding = "UTF-8"?>
<xs:schema
xmlns:xs = "http://www.w3.org/2001/XMLSchema"
xmlns:tsd = "http://namespaces.softwareag.com/tamino/TaminoSchemaDefinition">
<xs:annotation>
<xs:appinfo>
<tsd:schemaInfo name = "nonXML">
<tsd:collection name = "Hospital"></tsd:collection>
<tsd:doctype name = "X-Rays">
<tsd:nonXML>
<tsd:index>
<tsd:text></tsd:text>
</tsd:index>
</tsd:nonXML>
</tsd:doctype>
</tsd:schemaInfo>
</xs:appinfo>
</xs:annotation>
.
.
.
</xs:schema>
A plain text index is created for non-XML character data.
This section deals with the following topics:
The figures in The Schema
Header show those parts of the metaschema describing
information that can be associated with elements and attributes via
xs:annotation and
xs:appinfo using
tsd:elementInfo
and tsd:attributeInfo, respectively:
The meaning and usage of these extension elements and attributes are
explained in detail in the
Tamino XML
Schema Reference Guide. A general explanation of the
tsd:elementInfo/tsd:attributeInfo subtree follows.
The tsd:which element enables you to
specify different physical schema information represented by different
tsd:physical elements
inside a single tsd:elementInfo or
tsd:attributeInfo (i.e. an element or
attribute), if a node can be reached via multiple paths because of references
to global elements or attributes. Physical schemas for different absolute path
expressions can be grouped together. Therefore, if necessary, multiple
tsd:which elements are
allowed in one tsd:physical element to specify
different possible access paths. If no
tsd:which element is
specified within a tsd:physical element, all possible
paths not explicitly given in any
tsd:which within a sibling
tsd:physical have the same physical
schema information.
The tsd:which element contains a string of
type xs:string that describes an
XPath
expression, which must match the following constraints:
It must be an absolute path expression of the following form:
/doctypeName/element/.../{currentElementName | @ currentAttributeName }
The XPath expression must refer to an element or attribute defined in the schema (including the imported schema information).
Each XPath expression of each
tsd:physical child of one
element must be unique.
At most one tsd:physical without a
tsd:which element is
allowed.
The following rules apply for the default behavior of the
tsd:which element:
The default for a non-recursive element is all absolute paths to this element.
If no tsd:which element is
specified, the default applies.
For a recursive element, the following applies: If
tsd:which is applied with the
default option, it relates to the first stage of recursion.
Attachment of physical schema definition is not possible without
the tsd:which element below
recursive elements.
One situation where the usage of the
tsd:which element is very
advantageous is multi-path
indexing. You can find an explained example including usage of the
tsd:which element
here.
The context attribute is used in
tsd:elementInfo or
tsd:attributeInfo elements
specified within tsd:schemaInfo. Similar to
tsd:which, its value is a path that
determines the xs:element or
xs:attribute node to which
the tsd:elementInfo or
tsd:attributeInfo element
belongs.
Starting with version 4.2, Tamino allows you to specify a uniqueness constraint at the doctype level. This means that you can indicate, during schema definition, fields or combinations of fields that Tamino should monitor, ensuring that they have a unique value within their doctype. The necessary checks are performed automatically when data are inserted and updated (or update-defined). An error message is issued if an attempt is made to violate a uniqueness constraint.
Unique keys are defined centrally in
tsd:schemaInfo/tsd:doctype/tsd:logical. Below
tsd:logical, you can define
tsd:unique elements having one or more
tsd:field children. These
tsd:field children allow you to
specify how the uniqueness constraint is composed of one or more fields. Each
tsd:field child element has an
attribute xpath of type
xs:string.
Note:
The path is relative to the root element.
Caution:
If there are multiple
tsd:field child elements of a given
tsd:unique element, each child's
xpath attribute must be distinct.
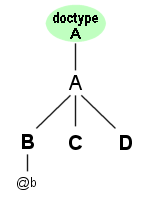
Based on that, the following schema fragment shows how to define two unique keys for the structure displayed in the diagram:
<tsd:doctype name="A">
.
.
.
<tsd:unique name="CB-key">
<tsd:field xpath="C" />
<tsd:field xpath="B/@b" />
</tsd:unique>
<tsd:unique name="D-key">
<tsd:field xpath="D" />
</tsd:unique>
.
.
.
</tsd:doctype>
In the example, two uniqueness constraints are defined: one for the
combined key comprising the element C and the
attribute b of element
B; and the other one for element
D.
Note:
You can define an arbitrary number of
tsd:unique elements below the
tsd:logical element.
The names of the fields to which the uniqueness constraint applies are
specified using the xpath attribute of the
tsd:field element. This
attribute is mandatory. It is of type
xs:string, with the additional
requirement that its value must be a valid
XPath
expression, i.e. it must comply with the
XML Path
Language (XPath) Version 1.0 specification published by
the W3C.
Valid xpath attributes are:
Any XPath expression that uses only the axes "child" and "attribute" and does not have more than one attribute;
The special case of a single dot ".", which denotes the contents of the root element as a unique constraint.
The following rules apply for unique key definitions:
Order of Components
The order of components is not significant.
Example: The following unique key definitions are equivalent:
<tsd:doctype name="A">
.
.
.
<tsd:unique name="CD-key">
<tsd:field xpath="C"/>
<tsd:field xpath="D"/>
</tsd:unique>
.
.
.
</tsd:doctype>
and:
<tsd:doctype name="A">
.
.
.
<tsd:unique name="CD-key">
<tsd:field xpath="D"/>
<tsd:field xpath="C"/>
</tsd:unique>
.
.
.
</tsd:doctype>
Number of Possible Uniqueness Constraints per Doctype
There is no theoretical limit to the number of uniqueness
constraints that can be specified for one doctype.
Condition for Constraint Names
Each constraint name must be unique within the doctype.
Condition for Number of Components of Constraint
Each constraint must have one or more components. Empty constraints
are not allowed
Exclusion of Double Declarations
In any given constraint, the same component may not be used
twice.
Mixing Elements and Attributes
Elements and attributes may be mixed.
Mixing Datatypes
Different datatypes may be mixed within one single unique key
definition.
Mixing Collations
The mixing of different collations within one single unique key
definition is not supported.
Condition for Multiplicity of a Component
Currently, each component of a unique key must have multiplicity of
exactly 1. Further restrictions result from this constraint:
Variety list Not Allowed
A uniqueness constraint must not reference a node of simple type
with variety "list". This includes the predefined
datatypes xs:ENTITIES, xs:IDREFS and
xs:NMTOKENS.
Reference to Nillable Elements
A uniqueness constraint must not refer to an element with
nillable="true".
Variety union Not Allowed
A uniqueness constraint must not reference a node of simple type
with variety "union".
Condition for XPath Expressions
XPath expressions are relative to
the root element.
Addressing the Root Element
The expression xpath="." refers to the root
element.
XPath Expressions and Mapped Nodes
XPath expressions must not point to nodes with
Adabas, SQL or SXS mapping.
For correct operation of the unique key constraints, all relevant nodes must be updated under the control of Tamino. This is true for all natively-stored data, but not for data under the control of an external system, nor for mapped data whose update cannot be fully controlled by Tamino.
Unique Key Definitions and Compound Index Definitions on
Identical Fields
There is no interaction between unique key definitions and compound
index definitions (which are technically related and are discussed
later in this document). You can
define a unique key constraint and a compound index that are based on the same
fields. It does not matter whether or not the fields appear in the same
order.
Criterion for Identity of Extremely Long Keys
In order to guarantee uniqueness, Tamino
uses an index to keep track of all keys. Tamino
truncates keys if they are too long. Currently, the length limit of a key in
Tamino's unique key storage area is 1,004 bytes in UTF-8 representation. As a
consequence, two keys are considered to be identical if the first 1,004 UTF-8
characters of both keys are identical.
Date/Time Types Not Allowed
Unique constraints may not be defined on elements or attributes of
the following types:
Any datatype that allows an optional timezone indicator, e.g.
xs:dateTime.
For more information about how to achieve the best performance when using the unique key feature, see the Performance Guide.
This section discusses some aspects of the various kinds of indices that Tamino offers and of indexing in XML databases in general. In detail, the following topics are discussed here:
One of the most important reasons for defining a schema for XML data is to index the data for "native"storage, i.e. storing the data in Tamino's internal XML store, although a schema may also be needed for validation and extension purposes.
The performance of database systems depends largely on correct indexing. This is just as true for Tamino as it is for other database systems. Correct indexing is very important, as it is a prerequisite for efficient database processing and retrieval.
However, if you have data for native storage for which no index is
required, it is not necessary to make any descriptions, declarations or
specifications at all, as native is the default
storage option for XML data in Tamino, and no
indexing is also the default.
In general, an index is a look-up table for reducing the time taken to query data stored in a database. The look-up table usually stores the corresponding record number for each occurrence of a given value in a database field. It is possible to define an index:
on a single field;
on a combination of fields.
For example, assume a document with the structure displayed in the
picture below: a root element A has multiple
children B, each having two children named
C and D. Also assume that
there are two instances of this document with the ino:id values 17 and 31
containing the names given in the lowest row of the picture.
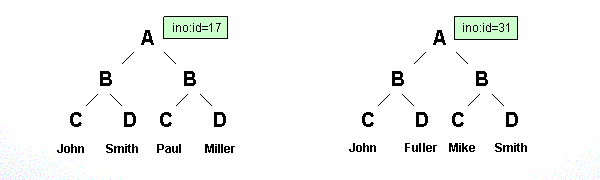
Then the index look-up table for A/B/C based on these
instances would look like this:
| John | 17, 31 |
| Mike | 31 |
| Paul | 17 |
Similarly, the look-up table for an index for A/B/D
would look like the following:
| Fuller | 31 |
| Miller | 17 |
| Smith | 17, 31 |
However, Tamino does not use record
numbers; rather, it uses the ino:id to identify data within the
database.
Tamino also offers more complex types of indices: see the following sections.
There are two ways of classifying indices in Tamino:
Firstly, indices can be classified according to the search technology on which they are based. From this point of view, we distinguish between text and standard indices.
A standard index is the classical database index. It is based on standard database indexing technology and is usually datatype independent.
The complete node content is used as the index value. When a document is stored or updated, Tamino puts data into a specific index, thus enabling efficient queries.
Tamino offers standard indexing support for all available XML Schema datatypes.
In contrast to a standard index, a text index uses special full-text searching technology based on a word-by-word analysis of text data. Single words are stored in the index.
For more detailed information about text indexing, see the section Text Retrieval of the Advanced Concepts documentation.
A special kind of index is the structure index that is described above.
On the other hand, different technologies can be applied to various index types. From this point of view, we distinguish between the following kinds of index definitions:
These indices represent the normal type of index. They are quite comparable to the indices that may be defined in standard database systems. Such indices have been available in Tamino versions both prior to and following version 4.2.1. The term "simple" in this context denotes that the index is less complex than the other types discussed here.
This type of index was introduced in Tamino version 4.2.1.
For more information, see the section Multi-Path Indices.
This type of index was introduced in Tamino version 4.2.1.
Compound indices may only be defined as standard indices.
For more information, see the section Compound Indices.
This type of index was introduced in Tamino version 4.2.1. It is based on the idea that only a sub-tree of the document tree is indexed in this particular index.
For more information, see the section The Reference Index: Indexing with Respect to Sub-Trees of a Document.
Note:
For non-XML data, it is also possible to define text indices. This
option is described in the section Built-In Indexing of Non-XML
Data.
For more information about achieving the best performance when using these advanced indices, see the appropriate section of the Performance Guide.
This can be accomplished either with help from a tool or manually. These options are described in the following sections:
Using the Tamino Schema Editor documentation, it is easy to define an index:
 To define an index using the Tamino Schema Editor
To define an index using the Tamino Schema Editor
Choose the element or attribute that is to be indexed in the tree-display on the left side of the Tamino Schema Editor.
On the right side of the Tamino Schema Editor, two areas labeled with:
Logical properties
Physical properties
will appear.
In the Physical properties area, set the
value for the property <index> to
"standard" if you intend to define a standard index,
or to "text" if you intend to define a text
index.
Instances of the chosen element or attribute will be indexed to optimize queries containing relations like comparisons in retrieval expressions.
Note:
There is also a "standard+text"
option available if you want to define both standard and text indices
synchronously.
For more information, see the documentation of the Tamino Schema Editor.
To define an index manually
To define a simple index for an element or attribute manually,
find the definition of the element or attribute in the schema file and insert a
tsd:index element as a child element
of the corresponding tsd:native element in the definition
of the element or attribute.
To define advanced types of indices manually, add child elements to
tsd:index that contain the appropriate
information.
tsd:index
Element
The tsd:index element may contain:
tsd:text elementThis indicates that the node is indexed for full text retrieval.
tsd:standard elementA standard index is built. This option is usually applied for data typing.
No indexing is performed.
A text index and a standard index may also be defined synchronously.
In a simple index, neither the only
tsd:text element nor the only
tsd:standard element may have any
child element.
The challenge in indexing XML data lies in deciding which XML data you wish to store and what the important queries against the stored data are likely to be. Since the "meat" of the data often lies in terminal nodes or sub-trees, the guiding principle is therefore to define an access path, i.e. an index, to those terminal nodes that are likely to be queried. Subtrees that are not relevant for filter conditions do not need to be indexed.
Tamino provides default settings for attributes that allow you to generate a Tamino schema without any editing. By default, neither elements nor attributes are indexed. Thus, for a natively-stored node without index nothing at all needs to be specified. Furthermore, it is very simple to add indexing to a natively-stored node:
To create an index for a natively-stored node
Specifying an index element with a text child element (i.e. an
tsd:index element with a
tsd:text child element) on the
root node causes full text indexing in the whole instance tree. Doing this
again on individual terminal nodes causes double indexing; this may be useful
in cases where you wish to make information accessible via full text searches
across a whole doctype as well as via specific search expressions (for example,
"Give me patient records that contain the string Atkins", as well
as "Give me the record of the patient whose surname is
Atkins".
A special case of defining schemas for XML data is the representation of recursive structures in a schema.
The practical management of indexing is explained in the section Examples.
A simple index indicates that a node belongs to a certain document, but it does not contain any more precise information. This may lead to poor performance if the document contains similar or equal sub-trees occurring with multiplicity that would have to be searched. Tamino provides reference indexing so that you can tune your schema for better performance in these situations.
Reference indices provide improved support for very large documents and for high-complexity documents.
We speak of high complexity if sub-trees with multiplicity occur in the schema. The complexity is even greater if recursive structures occur in the schema.
The general idea behind reference definitions and reference index definitions is to keep an additional index containing only references for a predefined partial tree of the document and to identify these references for later use.
For example, if /Doc/A/B is specified as the reference
node for the reference index within the contents of the
tsd:refers element,
B nodes will be registered in the reference
index.
In more detail, this leads to the following consequences:
In contrast to earlier versions of Tamino, document fragments (partial sub-trees of the document tree) can now be specifically addressed.
The target node of a reference index is a "dedicated" node. Such nodes define a reference chain.
Special queries can be significantly accelerated by defining a reference index. A particularly relevant acceleration happens to queries that contain a logical AND operation, if the AND operation is performed relative to a reference node.
Appropriate index definition is even possible in complex schemas containing recursive definitions.
Again, assume a document with the structure displayed in the picture
below: a root element A has multiple children
B, each having two children named
C and D. Also assume
there are two instances with the ino:id values 17 and 31
containing the names given in the lowest row of the picture.
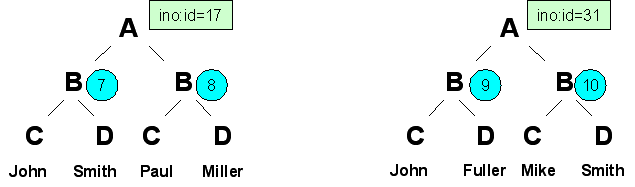
We now introduce reference numbers to identify the
B nodes that appear with multiplicity; we also
replace the ino:ids in the right column of the traditional index look-up table
by the reference numbers of the B nodes that appear
with multiplicity.
The look-up table for an index for A/B/C based on these
instances looks like this:
| John | 7,9 |
| Mike | 10 |
| Paul | 8 |
Similarly, the look-up table for a reference index for
A/B/D looks like the following:
| Fuller | 9 |
| Miller | 8 |
| Smith | 7,10 |
The tsd:refers element of TSD can be used
in two different ways, depending on the intention:
For Reference
Definition: This is done by using it in the context of either
tsd:standard or
tsd:text. See the section
Reference
Definition for more information;
For Reference Index
Definition: This is done by using it in the context of
tsd:reference.
You can define a reference based on either a standard index or a text index.
To define a standard index or a text index that references a
particular path, add a tsd:refers element as a child element
of the respective tsd:standard or
tsd:text element. The content of this
tsd:refers element is the path to the
node that is to be used as a base for a reference. (This node is marked as a
reference node.) It is given there as an absolute path according to the rules
of the W3C's
XPath
language.
This means that not the whole document tree is covered by the index,
but only the sub-tree below that path (in the example below it is
/A/B, for example).
...
<xs:element name = "C" type = "xs:string">
...
<tsd:elementInfo>
<tsd:physical>
<tsd:which>
/Doc/A/B/C
</tsd:which>
<tsd:native>
<tsd:index>
<tsd:text>
<tsd:refers>
/Doc/A/B
<tsd:refers>
</tsd:text>
</tsd:index>
</tsd:native>
</tsd:physical>
</tsd:elementInfo>
...
</xs:element>
...
The following rules apply:
The element describing the index (in the contents of the
accompanying tsd:which element) must have an
ancestor that matches the
XPath
expression of the tsd:refers value.
Only absolute path expressions without wildcards are supported in this context.
As long as these conditions are fulfilled, recursive structures can be indexed.
A node B to be referenced in indexing can
be defined as follows:
...
<xs:element name = "B" maxOccurs = "unbounded">
...
<tsd:elementInfo>
<tsd:physical>
<tsd:native>
<tsd:index>
<tsd:reference>
<tsd:refers/>
</tsd:reference>
</tsd:index>
</tsd:native>
</tsd:physical>
</tsd:elementInfo>
...
</xs:element>
If this node has a child element C that
should have a reference index relative to B, this is
accomplished as follows:
For more complex schemas and their corresponding
documents, TSD's reference index definitions offer the possibility of two-stage
modeling, e.g. /Doc/A/B refers to /Doc/A and
/Doc/A refers to the document id.
For example, imagine an element named B
that should have an ancestor named A and should be
described by the following element definition schema fragment:
The element B is defined by this element
definition from the schema fragment with a reference index definition that
works in such a way that references pointing to node
B should now point to its parent
/Doc/A, for which a reference must have been defined.
Note:
This schema fragment sets up a reference chain from
B over A to the document
root. This reference chain can also be denoted as
B->A->Doc.
Another motivation for using reference index definitions may come from the fact that recursive structures can also be indexed if the rules given below are not violated.
The following rules apply generally for reference index definitions:
If a tsd:which element has been specified
in this context:
The parent element of the element mentioned within the contents of
the accompanying tsd:which must match the
XPath
expression specified below the
tsd:refers element.
Only absolute path expressions without wildcards are allowed in the XPath expression.
A tsd:text or
tsd:standard element may have only one
single tsd:refers as a child element.
Note:
However, if you want to define more than one reference index on
the same node, you can achieve this by using multiple
tsd:text or
tsd:standard elements.
tsd:reference may not be specified for
attribute nodes.
The tsd:refers child element of the
tsd:reference element behaves the same
as it does in a reference definition as described
above.
Reference index definitions can also be combined with other index definitions, for example multi-path indices and compound indices.
Multiple reference index definitions are not allowed on the same node.
<xs:element name = "B" maxOccurs = "unbounded">
...
<tsd:elementInfo>
<tsd:physical>
<tsd:native>
<tsd:index>
<tsd:reference>
<tsd:refers>/Doc/A<tsd:refers>
</tsd:reference>
...
</tsd:index>
</tsd:native>
</tsd:physical>
</tsd:elementInfo>
...
</xs:element>
The above fragment is valid.
<xs:element name = "B" maxOccurs = "unbounded">
...
<tsd:elementInfo>
<tsd:physical>
<tsd:native>
<tsd:index>
<tsd:reference>
<tsd:refers>/Doc/A<tsd:refers>
</tsd:reference>
<tsd:reference>
<tsd:refers>/Doc/C/D<tsd:refers>
</tsd:reference>
...
</tsd:index>
</tsd:native>
</tsd:physical>
</tsd:elementInfo>
...
</xs:element>
The above fragment is invalid: multiple
tsd:reference elements are not
allowed.
Defining a reference index is only allowed if the structure index is set to either "condensed" or "full".
You can find a more detailed example below in the section Example 6: Defining a Reference Index. For example, the index definitions made there accelerate the processing of the following queries:
/Doc/A/B[C~='my' and D=1]
/Doc/A[B[C~='my' and D<1]]
/Doc[A/B[C~='my' and D<1]]
However, the following queries do not benefit from the definition of a reference index:
/Doc/A[B/C~='my' and B/D<1]]
Note:
Indeed, for this query the execution time is longer if a
reference index is defined on B (compared to a
simple index).
/Doc[A/B/C~='my' and A/B/D>2] index lookup C and D
Note:
This query is more efficient with a simple index than with a
reference index.
The following rules concerning combination possibilities apply to reference indices:
A reference index can be defined along with a standard or a text index.
Reference indices can be combined with both compound indices and multi-path indices.
Within one tsd:index element, currently only one
tsd:text element containing a
tsd:refers element is allowed.
A reference index can be used in combination with any other kind of index (standard, text, compound, multipath).
Improved selectivity by combining values relative to subtrees.
Sorting over the index with
tsd:refers is not possible.
The number of documents in a doctype is limited by the number of allowed entries.
The number of documents that can be stored in a Tamino database decreases significantly when reference indices are used, especially when multiple definitions of a reference index have been made in this doctype.
The correct choice of reference indices can have a significant effect on performance. This is discussed in more detail in the Performance Guide.
In contrast to previous versions of Tamino, where every index reflected an absolute XPath address, it is now possible to define an index in Tamino whose XPath address matches special criteria. This index is called a multipath index. The definition of multi-path indices is discussed here under the following headings:
The reasons that lead to the introduction of multi-path indices are as follows:
Versions of Tamino prior to 4.2.1 did not support indices for recursive or highly nested structures. In order to improve the usability of Tamino in such situations and also to avoid possible loss of performance, as from Tamino 4.2.1 both recursive and highly nested structures can be indexed using multi-path indices.
In earlier Tamino versions, index
support was missing for queries that contain wildcard expressions, for example
/Play//Title. Queries containing wildcard expressions performed
badly, due to the time-consuming analysis of all matching indices with respect
to the given predicate.
A multi-path index allows data from multiple paths to be collected in a single index.
Whereas in simple indexing each index reflects an absolute XPath address, this does not hold for a multi-path index.
A multi-path index is filled by the data of all nodes that match the various XPath conditions. This increases the performance for queries with wildcards significantly, as only the sum of all relevant entries is searched (and not all possible combinations, as in a simple index).
A multi-path index can be defined either as a text index or as a
standard index, depending on which was specified as the parent element of the
tsd:multiPath element in the
schema.
It is also possible to combine multi-path indexing with any other kind of indexing within one node:
- Simple standard index;
- Simple text index;
- Compound index.
Practically, a multi-path index is defined as follows:
All nodes (this includes both element nodes and attribute nodes) that should contribute to the multi-path index are identified by a special label that is unique within the entire schema. This allows you to specify easily the values that should be assembled into each index.
In the schema definition for a multi-path index, this is simply
expressed as an additional element
tsd:multiPath which contains the
common label to be used in the index definitions of all nodes that should be
indexed. All nodes (i.e. elements and attributes) that have the same label in
their index definition address the same index.
For example, as you can find in the contents of the
tsd:multiPath element, the three
labels MultiPathIndex0, MultiPathIndex2 and
MultiPathIndex3 are used in the example below.
This approach offers the following solutions:
It is now possible to define an index on nodes that are part of a recursive schema. Multi-path indexing provides efficient indexing, even on recursive structures that could not be indexed in earlier versions of Tamino.
Support for highly connected schemas is offered.
Highly connected schemas in this sense are schemas that contain
nodes that are referenced many times from other nodes (for example by usage of
the xs:any or
xs:anyAttribute elements within the
schema).
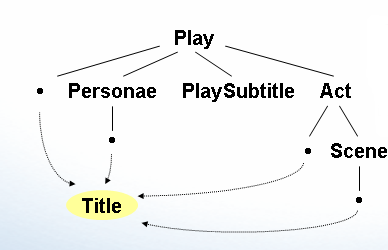
First we discuss a simple example, showing the use of multi-path indexing in a recursive situation.
Imagine, for example, an element title
that may be addressed as a child element within a recursive schema. See the
illustration below:
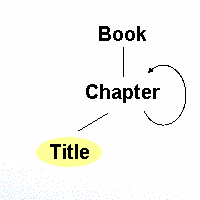
To create a multi-path index for the element
title, add the following lines to its
tsd:native element:
.
.
.
<tsd:index>
<tsd:text>
<tsd:multiPath>Title index<tsd:multiPath>
</tsd:text>
</tsd:index>
.
.
.
This code creates a multi-path index named Title
index that covers all possible access paths that lead to
title by recursion. One single index covers all
recursion levels.
Now let us have a look at a simple example for highly connected schemas.
Imagine, for example, an element title
that can be addressed via multiple paths within a highly connected schema. See
the illustration below:
To create a multi-path index for title,
simply add the same lines as in the preceding example to its
tsd:native element:
.
.
.
<tsd:index>
<tsd:text>
<tsd:multiPath>Title index<tsd:multiPath>
</tsd:text>
</tsd:index>
.
.
.
This code creates a multi-path index named Title
index covering all access paths that lead to
title. However, index generation does not depend on
the path leading to title in this case.
The generated multi-path index accelerates queries such as:
Play [ .//Title ~= "King" ]
Finally, let us discuss a more complex example:
.
.
.
<!-- global Element Definition for Title -->
<xs:element name = "Title" type = "xs:string">
<xs:annotation>
<xs:appinfo>
<tsd:elementInfo>
<tsd:physical>
<!-- default which for global Element Definition Title -->
<tsd:native>
<tsd:index>
<tsd:text>
<tsd:multiPath>MultiPathIndex0</tsd:>
</tsd:text>
</tsd:index>
</tsd:native>
</tsd:physical>
.
.
.
<tsd:physical>
<tsd:which>/Play/Act/Title</tsd:which>
<tsd:native>
<tsd:index>
<tsd:text>
<tsd:multiPath>MultiPathIndex2</tsd:multiPath>
</tsd:text>
</tsd:index>
</tsd:native>
</tsd:physical>
<tsd:physical>
<tsd:which>/Play/Act/Scene/Title</tsd:which>
<tsd:native>
<tsd:index>
<tsd:text>
<tsd:multiPath>MultiPathIndex3</tsd:multiPath>
</tsd:text>
</tsd:index>
</tsd:native>
</tsd:physical>
</tsd:elementInfo>
</xs:appinfo>
</xs:annotation>
</xs:element>
.
.
.
<!-- local Element Definition for /Play/Prologue /Title -->
<xs:element name = "Title" type = "xs:string">
<xs:annotation>
<xs:appinfo>
<tsd:elementInfo>
<tsd:physical>
<tsd:native>
<tsd:index>
<tsd:text>
<tsd:multiPath>MultiPathIndex2</tsd:multiPath>
</tsd:text>
</tsd:index>
</tsd:native>
</tsd:physical>
</tsd:elementInfo>
</xs:appinfo>
</xs:annotation>
</xs:element>
.
.
.
<!-- local Element Definition for /Play/Act/Abstract/Title -->
<xs:element name = "Title" type = "xs:string">
<xs:annotation>
<xs:appinfo>
<tsd:elementInfo>
<tsd:physical>
<tsd:native>
<tsd:index>
<tsd:text>
<tsd:multiPath>MultiPathIndex3</tsd:multiPath>
</tsd:text>
</tsd:index>
</tsd:native>
</tsd:physical>
</tsd:elementInfo>
</xs:appinfo>
</xs:annotation>
</xs:element>
.
.
.
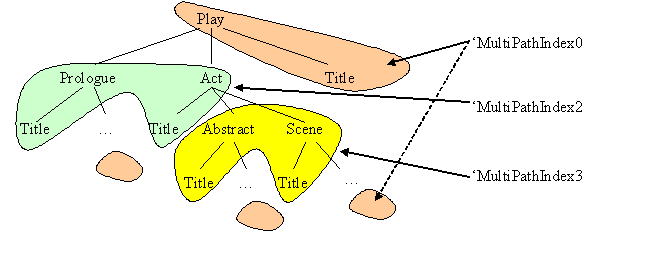
This definition creates three multi-path indices that cover all
Title nodes, namely:
An index for /Play/*/Title, labeled as
MultiPathIndex2, containing:
Data from the global title element restricted by the
<tsd:which>/Play/Act/Title, and
Data from the local element in /Play/Prologue.
This index covers the green area in the illustration.
An index for /Play/Act/*/Title, labeled as
MultiPathIndex3, containing:
Data from the global title element restricted by the
<tsd:which>/Play/Act/Scene/Title, and
Data from the local element in
/Play/Act/Abstract.
This index covers the yellow area in the illustration.
An index for all other Title nodes, labeled as
MultiPathIndex0.
This index covers the light brown area in the illustration.
This situation is depicted in the following graphic:
You can find another example in the section Example 4: Defining of a Multipath Index. For example, the index definitions discussed there accelerate the processing of the following queries:
/Doc[A//E/F ='Hy']
/Doc/A[.//E/F ='Hy']
/Doc/A[B/C='my' and .//E/F='Hy']
The following rules concerning combination possibilities apply to multi-path indices:
A multi-path index may be defined along with a standard or a text index.
A multi-path index can be combined with both compound indices and reference indices.
The following constraints apply to the definition of multi-path indices:
The combination of indices from different paths into one physical multi-path index requires that the participating indices all be of the same kind.
The following combinations are invalid:
Combination of standard and text indices.
Combination of different datatypes:
All datatypes of nodes (i.e. elements and attributes) contributing to the multi-path index must be of the same common datatype.
For standard indices, a common
XML
Schema datatype must be chosen for all nodes.
For compound indices, the datatypes of all parts that are
combined must be the same.
Combination of different collation specifications:
Items with non-matching
tsd:collation elements are
rejected. All child elements of
tsd:collation must
match.
Combination of compound and non-compound indices.
Combination of compound indices with different layouts (number of components and sequence of datatypes).
Note:
However, the paths may differ.
The label contained in the
tsd:multiPath element must not be
empty.
If you want to work with multi-path indices, the structure index must have been activated by setting it to either "condensed" or "full".
The main advantage of multi-path indexing is easy indexing of recursive and highly-connected structures.
The main disadvantage of multi-path indexing is that sort operations are not supported.
This section discusses the following topics related to compound indices:
In some queries, combined value conditions on inner nodes (i.e. nodes
that are neither the root note nor leaf nodes) appear with a multiplicity of
more than one. For example, /A[B[C="x" and D="y"]] represents such
a query. Characteristic for this construct is:
the multiplicity of B greater than 1,
and:
there is an AND operation below B.
In general, such queries perform poorly using simple indices. This is because the simple index delivers a superset of the final result, which must then be filtered in a subsequent processing step. The compound indices that are available in Tamino since version 4.2.1 are ideally suited to accelerate such queries.
Note:
Reference indices are also well suited in this situation. To
decide whether to use compound indexing or reference indexing, read the
sections about the advantages and disadvantages of each kind of indexing in
this document.
A compound index is somewhat different from the other kinds of index
discussed here. A simple index, a reference index and a multi-path index (as
discussed above) are each bound to one specific element or attribute. This not
true for a compound index, which comprises two or more different components,
called fields. The definition, however, takes place in the inner node
(B), which is the parent of both elements in the
condition (C and D in the
example).
To define a compound index, add a
tsd:field element as a child element
directly below the tsd:standard element.
The tsd:field element must appear at least
twice (with different xpath attributes) to
define a valid compound index.
Note:
If the tsd:field element appears as a child
element of the tsd:standard element, in order to
define a valid compound index it must appear at least twice, since at least two
fields are required to set up a compound index. The xpath
attributes of at least two tsd:field elements belonging to the
same tsd:standard element must be
different.
You can use the xpath attribute of the
tsd:field element to specify a path to
an element or attribute contributing to the compound index.
Important:
The xpath attribute is required.
A tsd:field element with a corresponding
xpath attribute must be defined for each
XPath
address to be included in the compound index. Each path is relative to the
element in which it is defined.
Note:
The order of the
tsd:field elements is significant; it
determines the order in which the values contribute to the index entry.
Supported xpath attributes are:
Any XPath expression that uses only the axes "child" and "attribute".
The special case of a single dot ".", which indicates that the index is to be created from the value of the element and of the values of its attributes.
Caution:
It is possible, although generally not desirable, to define a
schema with multiple equivalent definitions of compound indices. In this case,
redundant indices are created.
Assume a document with the structure displayed below with a root
element A having multiple children
B, each having two children named
C and D. Also assume
there are two instances with the ino:id values 17 and 31 containing the names
given in the lowest row of the picture.
The look-up table for a compound index for B(C,D) based
on these instances is as follows:
| John_Fuller | 31 |
| John_Smith | 17 |
| Mike_Smith | 31 |
| Paul_Miller | 17 |
Let A be the root element of a document.
A has child elements B
and C (there may also be others).
B has an attribute named
b.
The following example defines a compound index for the combination of
attribute b of element
B and the element C:
<xs:element ...>
.
.
.
<tsd:elementInfo>
<tsd:physical>
<tsd:native>
<tsd:index>
<tsd:standard>
<tsd:field xpath="C"/>
<tsd:field xpath="B/@b" />
</tsd:standard>
.
.
.
</tsd:index>
</tsd:native>
</tsd:physical>
</tsd:elementInfo>
</xs:element>
The compound index created by this schema definition contains an
entry for each combination of C and
B/@b occurring below
the element in whose tsd:elementInfo it appears.
The performance of queries such as /A[@b="x" and C="y"]
is improved by this compound index.
You can find a more detailed example in the section Example 3: Defining a Compound Index of this document. The index definitions discussed there improve the performance of the following queries:
/Doc/A/B[C= 'my' and D=1]
/Doc/A[B[C= 'my' and D<1]]
/Doc[A/B[C= 'my' and D<1]]
The following rules concerning combination possibilities apply to compound indices:
A compound index can be combined with a reference index or with a multi-path index.
The order of the components in the definition of the compound index is significant.
You can define a compound index that covers more than two fields.
You can define an arbitrary number of compound indices for one schema, as long as the limit on the total number of indices required by a schema is not violated.
Components with arbitrary datatypes and collations are supported.
The following constraints apply for the definition of compound indices:
A compound index definition with exactly one
tsd:field element is invalid.
If the path specified in the xpath attribute of one or
more tsd:field child elements of the
tsd:standard element is invalid in the
sense of the W3C XML Path Language (XPath) Version 1.0
specification, then the compound index specification is
invalid in its entirety.
It is not possible to define a compound index definition for text indices, see above.
A compound index whose components point to nodes with mapping to Adabas, SQL or Tamino Server Extensions is not allowed.
A compound index may not be defined below attributes. It can only be defined on an element.
A compound index can be used together with all kinds of indices except text indices (standard, reference and multipath indices are supported).
Improved selectivity by combining values relative to subtrees.
Only one index look-up instead of multiple index look-ups.
Sort over all components is possible.
Compound index definitions are not available for text indexing.
The Tamino XML Schema Reference Guide. Includes the descriptions of all TSD language elements that are required for index definition in Tamino schemas.
The Advanced Concepts documentation. It also discusses indexing on a more general level.
The documentation on X-Machine Programming. The ino:DisplayIndex function that can display index data is described there.
To map parts of XML documents to externally stored data
(Adabas, or using a
Tamino Server Extension), use the
tsd:map element.
An example showing a mapping for an element follows:
<xs:element>
<xs:annotation>
<xs:appinfo>
<tsd:elementInfo>
<tsd:physical>
<tsd:map>
.
.
.
</tsd:map>
</tsd:physical>
</tsd:elementInfo>
</xs:appinfo>
</xs:annotation>
.
.
.
</xs:element>
The tsd:map element may contain an
optional tsd:ignoreUpdate child element. If
present, Tamino does not pass the corresponding part
of the XML document to the internal data storage or
X-Node during processing.
This section covers the following topics:
The Tamino schema provides constructs that allow you to store data in an Adabas file and/or retrieve data from an Adabas file via the Tamino X-Node.
Mapping to Adabas is done on a file basis. In other words, you do not have to model the whole of an Adabas database using the Tamino schema language; you model only those files and fields that you wish to access using Tamino.
Mapping to an Adabas file is explained under the following headings:
There are two possible approaches for mapping to an Adabas file:
Pure Mapping
This means storing the data for a document in a single
Adabas file.
Pure XA mapping defines a mapping from any XML schema to Adabas. All XML data can be stored in an Adabas file and accessed via normal XML operations, using Adabas as the XML store.
This option is especially suited for mapping from existing XML schemas to Adabas files.
Pure AX mapping defines a mapping from any Adabas schema to an XML schema. Correspondingly, all XML operations are mapped to Adabas operations. All Adabas data can be accessed via XML operations (XML view on Adabas data).
This option is especially suited for mapping from existing Adabas files to XML schemas.
A pure mapping is denoted by the presence of a
tsd:pure child element below the tsd:map element;
otherwise, the mapping is hybrid. The tsd:pure element is
described in the next subsection and in the section
tsd:pure element of
the Tamino XML Schema
Reference Guide .
In older versions of Tamino, the X-Node
implementation was only capable of representing a hybrid XA mapping. The
tsd:pure element now enables pure XA mapping. Pure
Adabas mapping is specified as a physical option for
a doctype:
<tsd:doctype xmlns:tsd="http://namespaces.softwareag.com/tamino/TaminoSchemaDefinition"> <tsd:physical> <tsd:map> <tsd:pure/> </tsd:map> </tsd:physical> </tsd:doctype>
Hybrid Mapping
Hybrid Mapping means storing the data for a document partly in
Tamino and partly in a single
Adabas file. This mapping option has been supported
by all former versions of Tamino.
Hybrid XA mapping represents the combination of several mappings together with native storage parts into one document via a single schema. Varying degrees of hybrid mapping are possible.
Hybrid AX mapping integrating existing Adabas and natively-stored data into a single XML view (XML view on Adabas and native XML data).
Data is handled in the following manner if a pure Adabas mapping is present:
Important:
In such a doctype only one
Adabas file can be mapped.
No data is stored in Tamino for that doctype.
Any real content in the document must be mapped to Adabas.
The only permitted manipulation operations on pure Adabas mapped doctypes are:
_processTo insert new documents.
In particular, inserting new documents does not assign an
ino:id, and any markup (for example comments, processing
instructions or insignificant whitespace) is lost.
XQuery Update is the only possible means to update and delete documents.
Even though a document was inserted through
Tamino, it cannot be updated with
_process, and it cannot be deleted with
_delete (updating and deletion are only possible through
_xquery update).
_xquery update does not store anything in
Tamino, any modifications of the markup (e.g.
comments) are lost.
You cannot use a full structure index in conjunction with pure mapping to Adabas.
The following conditions must be fulfilled in order to establish a pure Adabas mapping:
The root element referenced by the doctype mapped to pure must
contain one Adabas file mapping
(tsd:subTreeAdabas).
Each element declaration of simple content and each attribute
declaration must contain one Adabas field mapping
(tsd:nodeAdabasField).
An element declaration of complex content is not allowed to contain
mixed content (xs:complexType mixed="false").
The doctype must not contain recursions.
The doctype does not allow for open content, i.e.
<tsd:content>open</tsd:content> is not allowed.
Elements with type="xs:anyType" are not allowed.
No element without xs:simpleType,
xs:complexType, or type attribute may occur.
No wildcard (xs:any, xs:anyAttribute)
with processContents = "skip" or "lax" is
allowed.
The root node must be mapped to an Adabas file.
Each descendant of the root node must meet one of the following conditions:
It has a complex content model that does not allow for mixed content and is not empty;
It has simple content that is mapped to an Adabas field.
The same Adabas field may not be mapped to different paths. Otherwise a run-time error might be signaled.
Normally, when a document is inserted using plain URL addressing
(HTTP PUT), Tamino returns the ino:id of the new document in the
HTTP header field X-INO-ID. For pure X-Node Adabas
doctypes, there is no ino:id when inserting a document, and
therefore the X-INO-ID field contains zero.
Consequently, the pure X-Node Adabas documents
cannot be read using plain URL addressing (HTTP GET), even if they were
inserted through Tamino.
This section describes the attributes that are of particular relevance to Adabas mapping.
tsd:subTreeAdabas elementThis element provides the database ID and file number in its
attributes dbid and
fnr, with an optional password in the
password attribute.
dbid attributeThe dbid attribute belongs to the
tsd:subTreeAdabas element. Its value
contains the database ID of the Adabas database.
fnr attributeThe fnr attribute belongs to the
tsd:subTreeAdabas element. It
represents the file number of the Adabas file.
password attributeThe optional password attribute belongs to the
tsd:subTreeAdabas element. It contains
the password of the Adabas file to be accessed. The
password has up to 8 characters.
tsd:subTreeAdabasPE elementThis element models a mapping to an Adabas periodic group via Tamino X-Node.
tsd:nodeAdabasField elementThis element is used in conjunction with the elements
tsd:subTreeAdabas and
tsd:subTreeAdabasPE to specify the
characteristics of the leaf nodes.
shortname attributeThe shortname attribute can be an attribute either
of the tsd:subTreeAdabasPE element or of the
tsd:nodeAdabasField element. This is
the shortname (e.g. "AH") of the corresponding field in the
Adabas
file. It can also be used in conjunction with Adabas
MU fields.
Note:
This is the case if a tsd:multiple child
element is present inside tsd:nodeAdabasField.
format attributeThe format attribute belongs to the
tsd:nodeAdabasField element. It
describes the format of the corresponding field in the
Adabas file.
The following table presents a list of the possible
format attribute values and their meaning:
| format | Description/Meaning |
|---|---|
| A | Alphanumeric |
| B | Binary |
| F | Fixed Point |
| G | Floating Point |
| P | Packed Decimal |
| U | Unpacked Decimal |
Also refer to the Adabas documentation.
Note:
The format attribute can be specified either
for a tsd:nodeAdabasField element describing
a mapping to a single Adabas field (that does not
have a child element tsd:multiple) or for those
describing a mapping to an Adabas MU field (multiple field)
tsd:nodeAdabasField (that can have a
child element tsd:multiple).
This example uses the Employees file in the demo database delivered with the Windows installation of Adabas Version 3.2 to illustrate mapping to an Adabas file.
The following is the Natural view of the "Employees" database:
Note:
The lines of special interest are printed in
italics.
T L DB Name F Leng S D Remark
- - -- -------------------------------- - ---- - - ------------------------
1 AA PERSONNEL-ID A 8 D
HD=PERSONNEL/ID
G 1 AB FULL-NAME
2 AC FIRST-NAME A 20 N
2 AD MIDDLE-I A 1 N
2 AD MIDDLE-NAME A 20 N
2 AE NAME A 20 D
1 AF MAR-STAT A 1 F
HD=MARITAL/STATUS
1 AG SEX A 1 F
HD=S/E/X
1 AH BIRTH N 6.0 D
HD=DATE/OF/BIRTH
EM=99/99/99
G 1 A1 FULL-ADDRESS
M 2 AI ADDRESS-LINE A 20 N
HD=ADDRESS
* OCCURRENCES 1-6
2 AJ CITY A 20 N D
2 AK ZIP A 10 N
HD=POSTAL/ADDRESS
2 AK POST-CODE A 10 N
HD=POSTAL/ADDRESS
2 AL COUNTRY A 3 N
G 1 A2 TELEPHONE
2 AN AREA-CODE A 6 N
HD=AREA/CODE
2 AM PHONE A 15 N
HD=TELEPHONE
.
.
.
The file ada_empl.tsd is provided in
the Tamino distribution kit to illustrate the mapping to the Employee
database. Note that not all fields are mapped, so instances containing nodes
that are not mapped are rejected. The graphical representation of this schema
as it appears in the Tamino Schema Editor is shown below. The properties view
is reduced to the physical properties pane, which shows as an example the
mapping of the zip element to the
Adabas field AK:
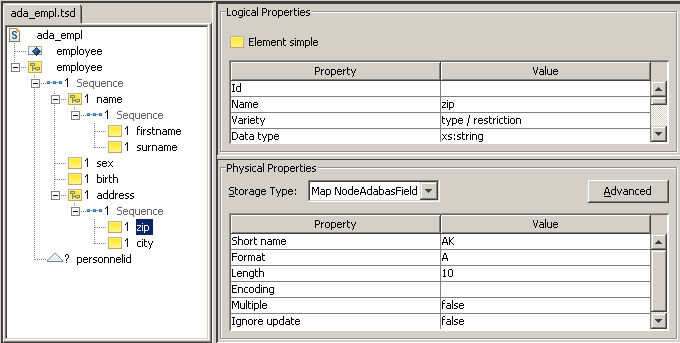
Note that such a schema could also be a subtree within a schema for another doctype.
This schema allows Adabas data to be retrieved using Tamino X-Query expressions, for example:
/employees/employee[name/surname~="A*"]
This returns all employees whose surnames start with the letter "A".
The following XML object is an instance of the above schema and can be loaded into the Adabas database and retrieved using Tamino:
<?xml version="1.0" encoding="ISO-8859-1"?> <employee personnelid="007"> <name> <firstname>James</firstname> <surname>Bond</surname> </name> <sex>M</sex> <birth>340401</birth> <address> <zip>SW13JB</zip> <city>London</city> </address> </employee>
Server Extensions allow you to extend Tamino's functionality by executing user-defined application logic (written in languages such as Java or C++) at specified points in the processing of an instance. Server Extensions can be associated with elements and attributes at any level in a Tamino schema. When an element or attribute is associated with a Server Extension, the element is said to be "mapped" to the Server Extension.
Server Extensions can be used, for example, to let external programs handle indexing, storing or retrieval of data in ways not provided as standard by Tamino.
Mapping to a Server Extension means transferring control to an external function offered by the Server Extension. One Server Extension may offer several functions. Control can be passed to a Server Extension function during parsing of an incoming instance or during composition of an XML object as the result of a query. The invocation context is specified by the name of the Server Extension-specific child elements on the node. The associated Server Extension function is specified as the element value.
Mapping to Server Extension functions is described in this section under the following headings:
This section describes the Tamino schema extensions that are of particular relevance to mapping elements to Server Extensions.
There is one single parent element in TSD offering all the
functionality needed to map Tamino Server Extensions
in conjunction with its child elements, namely the
tsd:xTension element.
TSD provides the following mappings for Server Extensions:
tsd:xTensionThis element is the parent element of the elements
tsd:onDelete and
tsd:onProcess.
The syntax of the values of these child elements is:
SXSModule.SXSFunction
tsd:onProcessSpecifies the name of the SXS function that is to be executed when
data is stored using Tamino (that is, when using the
Tamino _process request).
The SXS function is called after parsing the associated element.
tsd:onDeleteSpecifies the name of the SXS function that is to be executed when
the associated element is to be deleted (that is, when the
Tamino _delete request is issued).
The following example demonstrates the mapping to a Server Extension Function. A doctype "Mail" describes the structure of an e-mail message.
The effect of the Server Extension function is that instead of storing instances of the doctype (i.e., e-mail messages) in Tamino, they are routed to an e-mail tool, which transmits the messages to the recipient.
The TSD schema describing the "Mail" doctype with
mapping to Server Extensions contains a tsd:onProcess element
specifying the corresponding Server Extension function to be invoked when
processing a document:
<?xml version = "1.0" encoding = "UTF-8"?>
<xs:schema xmlns:xs = "http://www.w3.org/2001/XMLSchema"
xmlns:tsd = "http://namespaces.softwareag.com/tamino/TaminoSchemaDefinition">
<xs:annotation>
<xs:appinfo>
<tsd:schemaInfo name = "SXS">
<tsd:collection>MailSXS</tsd:collection>
<tsd:doctype name = "Mail">
<tsd:logical>
<tsd:content>closed</tsd:content>
<tsd:accessOptions>
<tsd:insert></tsd:insert>
</tsd:accessOptions>
</tsd:logical>
</tsd:doctype>
</tsd:schemaInfo>
</xs:appinfo>
</xs:annotation>
<xs:element name = "Mail">
<xs:annotation>
<xs:appinfo>
<tsd:elementInfo>
<!--- Beginning of mapping to Server Extension--->
<tsd:physical>
<tsd:map>
<tsd:xTension>
<tsd:onProcess>SXSMail.SendMail</tsd:onProcess>
</tsd:xTension>
</tsd:map>
</tsd:physical>
<!--- End of mapping to Server Extension--->
</tsd:elementInfo>
</xs:appinfo>
</xs:annotation>
<xs:complexType>
<xs:sequence>
<xs:element name = "Recipient" type = "xs:string"></xs:element>
<xs:element name = "Subject" type = "xs:string"></xs:element>
<xs:element name = "Body" type = "xs:string"></xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
Notes:
The following XML object is an instance of the doctype
"Mail". Using the schema definition above, this instance is not
stored in Tamino, but sent to the e-mail address in
the Recipient element:
<Mail> <Recipient>world@planet.org</Recipient> <Subject>Global greeting</Subject> <Body>Hello World!</Body> </Mail>