We now present a few more use cases for the Tamino API. These examples cover a multi-document join, the validation of integrity constraints, and the validation of unique keys.
All three examples introduce not only into programing with the Tamino API but also into the programming with DOM and JDOM. The Tamino API has a pluggable object model interface and allows to use various object models.
JDOM is a popular (albeit non-standard) API that provides a simpler interface than the standard DOM implementations. Because it allows to merge different documents easily we use it for our first example where we join multiple documents.
The preferred object model, however, is DOM which we will use for the following two examples. DOM is a W3C recommendation and has bindings into many programming languages, which is not the case for JDOM.
The DOM Level 2 specification is available at http://www.w3.org/TR/DOM-Level-2-HTML/. You will find a tutorial http://www.w3schools.com/dom/.
We have chosen to implement a small knowledge base about jazz musicians and jazz music. In this scenario, jazz musicians play together in different types of collaborations (jam session, project, band) and produce results in form of albums.
For the following examples readers should have general knowledge about XML and DOM and should have practical experience with Tamino, especially with the Tamino Schema Editor, the Tamino Interactive Interface, and the Tamino Manager.
The examples are presented under the following topics:
The section describing the Tamino API package explains where you will find the example files used below.
To set up the stage start the Tamino Manager
and create a new database with the name jazz. A small database
with the default settings will do.
Our conceptual model of the jazz knowledge base consists of three document types:
a document type jazzMusician. The property
type determines the type of jazzMusician: an
instrumentalist, a composer, or a singer. The property ID
establishes a key for each musician which we construct from the last name and
the first name: "GillespieDizzy",
"ColtraneJohn", etc.
a document type collaboration. The property
type determines the type of collaboration: a band, a
project, or a jam session. A collaboration is either a single event (jam
session) performed at a specific time and place, or it exists over a period of
time. Each collaboration relates to at least two jazz musicians that take part
in that collaboration. A collaboration can also relate to one or several albums
which result from that collaboration.
a document type album. Here we have properties such as
product number (which acts also as key), publisher, and information about each
track.
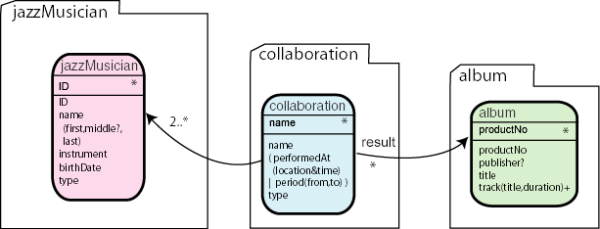
Based on this simple conceptual model we can now define our schemata
with the help of the Tamino Schema Editor. All three
schemata will be in a new Tamino collection which we
will name encyclopedia.
We begin with jazzMusician. We set the schema name to
"jazzMusician" and the collection name to
"encyclopedia":
Then we define the document structure:
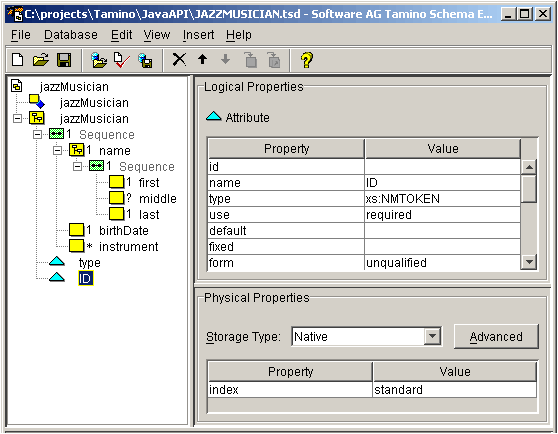
Here, we can see the complete schema as it appears in the
Tamino Schema Editor. We have chosen to implement
the properties ID and type as attributes, and we have
declared ID as a standard index.
Both attributes have the type xs:NMTOKEN. The type of
attribute type has been restricted by an enumeration to the values
"instrumentalist",
"jazzSinger", and
"jazzComposer". The element birthDate
has the type xs:date, and the other elements have the type
xs:string or xs:normalizedString.
The resulting schema definition should look like this:
<?xml version = "1.0" encoding = "UTF-8"?>
<xs:schema xmlns:xs = "http://www.w3.org/2001/XMLSchema"
xmlns:tsd = "http://namespaces.softwareag.com/tamino/TaminoSchemaDefinition">
<xs:annotation>
<xs:appinfo>
<tsd:schemaInfo name = "jazzMusician">
<tsd:collection name = "encyclopedia">
</tsd:collection>
<tsd:doctype name = "jazzMusician">
<tsd:logical>
<tsd:content>open</tsd:content>
</tsd:logical>
</tsd:doctype>
</tsd:schemaInfo>
</xs:appinfo>
</xs:annotation>
<xs:element name = "jazzMusician">
<xs:complexType>
<xs:sequence>
<xs:element name = "name">
<xs:complexType>
<xs:sequence>
<xs:element name = "first"
type = "xs:normalizedString"/>
<xs:element name = "middle"
type = "xs:normalizedString"
minOccurs = "0"/>
<xs:element name = "last"
type = "xs:normalizedString"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name = "birthDate" type = "xs:date">
</xs:element>
<xs:element name = "instrument"
type = "xs:string"
minOccurs = "0"
maxOccurs = "unbounded"/>
</xs:sequence>
<xs:attribute name = "type">
<xs:simpleType>
<xs:restriction base = "xs:NMTOKEN">
<xs:enumeration value = "instrumentalist"/>
<xs:enumeration value = "jazzSinger"/>
<xs:enumeration value = "jazzComposer"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
<xs:attribute name = "ID"
type = "xs:NMTOKEN" use = "required">
<xs:annotation>
<xs:appinfo>
<tsd:attributeInfo>
<tsd:physical>
<tsd:native>
<tsd:index>
<tsd:standard/>
</tsd:index>
</tsd:native>
</tsd:physical>
</tsd:attributeInfo>
</xs:appinfo>
</xs:annotation>
</xs:attribute>
</xs:complexType>
</xs:element>
</xs:schema>
We can now define this schema in the database. We can do this directly
from the Tamino Schema Editor. In the
menu, select . If you are not already connected to the jazz
database, choose the button
and enter your user name and password to connect. Then select the
jazz database from the list and choose the
button.
Again, the property type is defined as an attribute of
type xs:NMTOKEN restricted by the enumeration [jamSession,
project, band]. The elements jazzMusician and
result (which relates to album) are of type
xs:NMTOKEN, too, and are declared as standard indexes. The element
time is declared as type xs:dateTime while the
elements from and to are declared as type
xs:date. The other elements are declared as strings or normalized
strings.
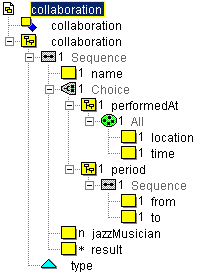
The resulting schema should look like this:
<?xml version = "1.0" encoding = "UTF-8"?>
<xs:schema xmlns:xs = "http://www.w3.org/2001/XMLSchema"
xmlns:tsd = "http://namespaces.softwareag.com/tamino/TaminoSchemaDefinition">
<xs:annotation>
<xs:appinfo>
<tsd:schemaInfo name = "collaboration">
<tsd:collection name = "encyclopedia">
</tsd:collection>
<tsd:doctype name = "collaboration">
<tsd:logical>
<tsd:content>closed</tsd:content>
</tsd:logical>
</tsd:doctype>
</tsd:schemaInfo>
</xs:appinfo>
</xs:annotation> <xs:element name = "collaboration">
<xs:complexType>
<xs:sequence>
<xs:element name = "name" type = "xs:NMTOKEN">
</xs:element>
<xs:choice>
<xs:element name = "performedAt">
<xs:complexType>
<xs:all>
<xs:element name = "location"
type = "xs:normalizedString"/>
<xs:element name = "time" type = "xs:dateTime"/>
</xs:all>
</xs:complexType>
</xs:element>
<xs:element name = "period">
<xs:complexType>
<xs:sequence>
<xs:element name = "from" type = "xs:date"/>
<xs:element name = "to" type = "xs:date"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:choice>
<xs:element name = "jazzMusician"
type = "xs:NMTOKEN"
minOccurs = "2"
maxOccurs = "unbounded">
<xs:annotation>
<xs:appinfo>
<tsd:elementInfo>
<tsd:physical>
<tsd:native>
<tsd:index>
<tsd:standard/>
</tsd:index>
</tsd:native>
</tsd:physical>
</tsd:elementInfo>
</xs:appinfo>
</xs:annotation>
</xs:element>
<xs:element name = "result"
type = "xs:NMTOKEN"
minOccurs = "0"
maxOccurs = "unbounded">
<xs:annotation>
<xs:appinfo>
<tsd:elementInfo>
<tsd:physical>
<tsd:native>
<tsd:index>
<tsd:standard/>
</tsd:index>
</tsd:native>
</tsd:physical>
</tsd:elementInfo>
</xs:appinfo>
</xs:annotation>
</xs:element>
</xs:sequence>
<xs:attribute name = "type" use = "required">
<xs:simpleType>
<xs:restriction base = "xs:NMTOKEN">
<xs:enumeration value = "jamSession"/>
<xs:enumeration value = "project"/>
<xs:enumeration value = "band"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
</xs:element>
</xs:schema>
For document type album we have defined element
productNo as a standard index of type xs:NMTOKEN. The
element duration is declared as xs:short while all
other elements are declared as strings or normalized strings.
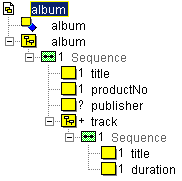
The resulting schema should look like this:
<?xml version = "1.0" encoding = "UTF-8"?>
<xs:schema xmlns:xs = "http://www.w3.org/2001/XMLSchema"
xmlns:tsd = "http://namespaces.softwareag.com/tamino/TaminoSchemaDefinition">
<xs:annotation>
<xs:appinfo>
<tsd:schemaInfo name = "album">
<tsd:collection name = "encyclopedia">
</tsd:collection>
<tsd:doctype name = "album">
<tsd:logical>
<tsd:content>open</tsd:content>
</tsd:logical>
</tsd:doctype>
</tsd:schemaInfo>
</xs:appinfo>
</xs:annotation>
<xs:element name = "album">
<xs:complexType>
<xs:sequence>
<xs:element name = "title" type = "xs:normalizedString">
</xs:element>
<xs:element name = "productNo" type = "xs:normalizedString">
<xs:annotation>
<xs:appinfo>
<tsd:elementInfo>
<tsd:physical>
<tsd:native>
<tsd:index>
<tsd:standard/>
</tsd:index>
</tsd:native>
</tsd:physical>
</tsd:elementInfo>
</xs:appinfo>
</xs:annotation>
</xs:element>
<xs:element name = "publisher"
type = "xs:string" minOccurs = "0"/>
<xs:element name = "track" maxOccurs = "unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name = "title" type = "xs:string"/>
<xs:element name = "duration" type = "xs:short"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
We define both schemata collaboration and
album to the jazz database.
Next, we add some test data to our database. We start with two famous jazz musicians. We create parker.xml:
<?xml version="1.0"?>
<jazzMusician type="instrumentalist" ID="ParkerCharlie">
<name>
<first>Charlie</first>
<last>Parker</last>
</name>
<birthDate>1920-08-19</birthDate>
<instrument>saxophone</instrument>
</jazzMusician>
and dizzy.xml:
<?xml version="1.0"?>
<jazzMusician type="instrumentalist" ID="GillespieDizzy">
<name>
<first>Dizzy</first>
<last>Gillespie</last>
</name>
<birthDate>1917-10-21</birthDate>
<instrument>trumpet</instrument>
</jazzMusician>
Then, we create a (fictional) jam session post-election-jam.xml:
<?xml version="1.0"?>
<collaboration type="jamSession">
<name>post-election-jam</name>
<performedAt>
<location>Blues House</location>
<time>1945-10-21T20:00:00</time>
</performedAt>
<jazzMusician>GillespieDizzy</jazzMusician>
<jazzMusician>ParkerCharlie</jazzMusician>
<result>BGJ-47</result>
</collaboration>
and an album document blueshouse.xml
as the result of that session:
<?xml version="1.0" encoding = "UTF-8"?>
<album>
<title>Blues House Jam</title>
<productNo>BGJ-47</productNo>
<track>
<title>Post Election Jam I</title>
<duration>1175</duration>
</track>
<track>
<title>Post Election Jam II</title>
<duration>1235</duration>
</track>
</album>
We add these four documents to our encyclopedia collection
in database jazz. We can use the Tamino
Interactive Interface to do so.
Now we are ready to write our first Java program to retrieve information from our database. What we want to do is to find a particular jazz musician and retrieve all the information about this musician. We want to include information about the collaborations in which the musician participated and about the albums that resulted from these collaborations. We don't want to list the albums with all details. The title, product number, and publisher will be sufficient.
This task requires us to join information from three document types. We have to retrieve the appropriate documents, and we must construct a new result document from the information combined.
To retrieve the right jazzMusician document is easy. We
just query for the ID attribute with the query
jazzMusician[@ID='?'] where we replace '?' with the
actual ID, for example with "ParkerCharlie".
To find the corresponding collaborations is just as easy. We simply
query for the jazzMusician element in document type
collaboration:
collaboration[jazzMusician='?']
Finding the resulting albums requires a bit more work. We first have to
extract the content of element result from each
collaboration instance. Then we have to use this value in the
following query:
album[productNo='?']
Tip:
It is a good idea to test these queries with the
Tamino Interactive Interface before implementing
them in Java.
We implement our example program as a Java class
MusicianCollaborationResult that can be executed from the command
line.
The key value (ID attribute) of the jazzMusician document
that we want to retrieve is passed as a command line parameter to the main
method. The main method is implemented as a class
method. Therefore, it must first create a new instance of the class
MusicianCollaborationResult. Then it calls the instance method
show and passes the key value as a parameter to this
method:
public static void main(String[] args) throws Exception {
MusicianCollaborationResult musicianCollaborationResult =
new MusicianCollaborationResult( DATABASE_URI , COLLECTION );
musicianCollaborationResult.show(args[0]);
}
We have used here a few constants that we still have to declare:
// Constant for the database URI.
private final static String DATABASE_URI =
"http://localhost/tamino/jazz";
// Constant for the collection.
private final static String COLLECTION = "encyclopedia";
We also introduce a namespace constant for the namespace prefix
ino:. This constant will later be used to identify
Tamino-specific attributes such as
ino:id. Namespaces are identified by URIs, and the
INO_NAMESPACE constant establishes the connection between
namespace prefix and namespace URI.
// Constant for ino namespace.
private final static Namespace INO_NAMESPACE =
Namespace.getNamespace("ino",
"http://namespaces.softwareag.com/tamino/response2");
Then we set up two instance variables. The variable
connection will hold a Tamino
connection object while the variable accessor will hold a
TXMLObjectAccessor instance. Accessor objects provide
the necessary methods to query, insert, update, or delete documents in a
specific collection and via a specific connection.
// The database connection. private TConnection connection = null; // The accessor instance, here a high level TXMLObjectAccessor. private TXMLObjectAccessor accessor = null;
Both variables are initialized in the class constructor which is
executed when the class method show creates a new
MusicianCollaborationResult instance. The connection is not
created directly. Instead, we first create an instance of a connection factory.
public MusicianCollaborationResult(String databaseURI,
String collection)
throws TConnectionException {
// Obtain the connection factory
TConnectionFactory connectionFactory =
TConnectionFactory.getInstance();
Note:
Instances of TConnectionFactory,
TXMLObjectAccessor, TDOMObjectModel, and
TJDOMObjectModel are not created with a new
instruction but with the class method
getInstance().
Then we let the connection factory create the actual connection:
// Obtain the connection to the database connection = connectionFactory.newConnection( databaseURI );
Finally we create the accessor object:
// Obtain the concrete TXMLObjectAccessor
// with an underlying JDOM object model
accessor = connection.newXMLObjectAccessor(
TAccessLocation.newInstance( collection ),
TJDOMObjectModel.getInstance() );
}
Now, that we have established a connection and obtained an accessor object we are ready to query the database:
// show result
private void show(String keyValue) throws Exception {
try {
// Build a query and process it
TResponse response =
processQuery( "jazzMusician[@ID"+"='" + keyValue + "']" );
From the key value passed as a parameter we construct a query string as
shown above and hand it over to the private method
processQuery(). This method constructs a query object
from a string parameter and passes it to the query
method of the accessor object. It also handles the case of a
TQueryException.
// process query
private TResponse processQuery(String s) throws Exception {
TQuery query = TQuery.newInstance( s );
try {
// Invoke the query operation.
return accessor.query( query );
}
catch (TQueryException queryException) {
// Tell about the reason for the failure.
showAccessFailure(queryException);
return null;
}
}
This method returns a Tamino response object
which can contain one or several result documents. Since we assume that the ID
of a jazz musician is unique, we expect at most a single result document. We
retrieve this document from the response object and get its top level JDOM
element (jazzMusician).
// Get first (and single) object
if (!response.hasFirstXMLObject())
throw new Exception("Nothing found");
TXMLObject xmlObject = response.getFirstXMLObject();
// Get top level JDOM element
Element jazzMusician = (Element) xmlObject.getElement();
Next, we retrieve collaboration documents that match the key value (jazz musician ID):
response = processQuery(
"collaboration[jazzMusician"+"='" + keyValue + '"]" );
Because this query may result in several documents we use an iterator object to loop through all result documents:
// Iterate over result documents
TXMLObjectIterator collabIt = response.getXMLObjectIterator();
while (collabIt.hasNext()) {
xmlObject = collabIt.next();
// Get top level JDOM element
Element collab = (Element) xmlObject.getElement();
Because we later want to paste these collaboration elements
into the jazzMusician document, we have to clone them.
This operation removes the context (such as the parent information) from the
current node and allows us to insert it into another context (i.e. to merge
documents):
// clone to remove context
collab = (Element) collab.clone();
Note:
This technique is specific to JDOM. While DOM Level 1 does not
support the merging of documents at all, DOM Level 2 introduces an
importmethod. This method must be used to import a
foreign node into a target document before the foreign node can be added to a
node of the target document.
Now we retrieve the content of all result elements in each
collaboration document. Using JDOM methods, we first construct a
list of all result child elements:
// Get a list of all direct children with name "result"
List resultChildren = collab.getChildren("result");
Then we iterate over this list and extract the text from each element:
// get iterator over children
ListIterator resultIt = resultChildren.listIterator();
// now loop over the "result" children
while (resultIt.hasNext()) {
// get a single "result" child
Element resultElement = (Element) resultIt.next();
// get the content
String resultID = resultElement.getText();
// now read album records with resultID as key
By now we have obtained the values of all result elements
in all collaborations of a jazz musician. We can use these values to retrieve
the albums that are results of these collaborations. We do so by querying for
album documents with a productNo equal to
resultID:
// now read album records with resultID as key
response = processQuery("album[productNo"+"='"
+ resultID + "']" );
Again we expect only a single result document per key:
// Process the album if we have one
if (response.hasFirstXMLObject()) {
// get first (and only) result document
xmlObject = response.getFirstXMLObject();
// Get top level JDOM element
Element album = (Element) xmlObject.getElement();
Once again, we clone this element and remove all track
child elements because we are not interested in that information.
// clone to remove context
album = (Element) album.clone();
// remove "track" elements
album.removeChildren("track");
We also want to remove the Tamino specific
ino:id attribute. To identify this attribute we use the constant
INO_NAMESPACE that connects the prefix ino: with the
Tamino namespace URI.
// remove ino:id
album.removeAttribute("id",INO_NAMESPACE);
Then, we simply add the remaining structure to our
collaboration element stored in collab and close the
loop:
// add album to collaboration clone
collab.addContent(album);
}
By now we have joined document album to document
collaboration. In the next step we join the resulting
collaboration document to document jazzMusician.
Similarly, we remove the result elements from the
collaboration element (because this information is already
contained in the productNo attributes of the added
album elements), and the ino:id.
// remove "result" elements from collaboration
collab.removeChildren("result");
// remove ino:id
collab.removeAttribute("id",INO_NAMESPACE);
Then we add the collaboration element to our jazz musician
element and close the loop:
// and add collab to jazzMusician
jazzMusician.addContent(collab);
}
Done. What remains to do is to print the result:
// Output with JDOM output tool XMLOutputter outputter = new XMLOutputter(); outputter.output(jazzMusician, System.out);
and to finally close the connection:
// Close the connection. connection.close();
The complete listing is shown in
MusicianCollaborationResult.java. This file
contains also the necessary code for exception handling consisting of the
private method showAccessFailure and try,
catch, and finally clauses in the method
show:
We can execute this program from the command line or from our favorite IDE. If we invoke the program with parameter "ParkerCharlie" we should get the following result:
<jazzMusician
xmlns:ino="http://namespaces.softwareag.com/tamino/response2"
ino:id="2"
type="instrumentalist"
ID="ParkerCharlie">
<name>
<first>Charlie</first>
<last>Parker</last>
</name>
<birthDate>1920-08-19</birthDate>
<instrument>saxophone</instrument>
<collaboration type="jamSession">
<name>post-election-jam</name>
<performedAt>
<location>Blues House</location>
<time>1945-10-21T20:00:00</time>
</performedAt>
<jazzMusician>GillespieDizzy</jazzMusician>
<jazzMusician>ParkerCharlie</jazzMusician>
<album>
<title>Blues House Jam</title>
<productNo>BGJ-47</productNo>
</album>
</collaboration>
</jazzMusician>
Our next example is a program that tests for integrity constraints
between two document types before inserting a new document. When inserting a
new collaboration document we want to make sure that the
alternative elements collaboration/performedAt/time and
collaboration/period/from do not contain events that take place
before the birth date of each participating musician. To make such a test
"waterproof" against competing transactions we must perform it in the same
transaction as the insert operation. Therefore, prior to the test we establish
a local transaction. If the test succeeds we perform the insert operation and
explicitly commit the transaction. Otherwise, we simply rollback the
transaction.
Again, we write a Java program that can be executed from the command line. The file name of the document which we wish to insert is specified as a parameter.
The basic setup (constants, instance variables, constructor) is similar to the previous example in section Joining documents. However, this time we use the DOM object model instead of JDOM. In addition to establishing a connection we make sure that we run in a transaction safe environment and therefore set the lock mode of the connection to "shared":
// Set lock mode to "shared" connection.setLockMode(TLockMode.SHARED) ;
Also, the main() method looks similar to the
one shown in the previous example:
public static void main(String[] args) throws Exception {
InsertConstraintCheck insertConstraintCheck =
new InsertConstraintCheck( DATABASE_URI , COLLECTION );
// perform the transaction
insertConstraintCheck.processTransaction(args[0]);
}
The actual work is done in method
processTransaction(). Here, we first setup a few
variables, read the specified file into a DOM Tamino
XML Object, and extract the DOM document object
(collaborationDoc):
TLocalTransaction myTransaction = null;
boolean abortTransaction = false;
try {
// Read file into a DOM Tamino XML object.
// Instantiate an empty TXMLObject instance
// related to the DOM object model.
TXMLObject collaborationObject =
TXMLObject.newInstance( TDOMObjectModel.getInstance() );
// Establish the DOM representation by reading the content
// from a file input stream.
collaborationObject.readFrom( new FileInputStream(filename ));
// get DOM document
Document collaborationDoc =
(Document) collaborationObject.getDocument();
Now we can start a new local transaction.
// Set local transaction mode and get a transaction object
myTransaction = connection.useLocalTransactionMode();
Then we begin with the tests for constraint violation. We first extract
the start date of the collaboration – which is defined either by
collaboration/performedAt/time or alternatively by
collaboration/period/from – and convert the string value of these
elements into a Java Date value. Because there are no other
time and from elements in the document, we can access
these elements on document level via the DOM method
getElementsByTagName:
// initialize start date
Element startDateElement = null;
// get a "from" elements if defined
NodeList fromList =
collaborationDoc.getElementsByTagName("from");
if (fromList.getLength() > 0) {
// get the only child
startDateElement = (Element) fromList.item(0);
} else {
// alternatively, get the "time" element
startDateElement =
(Element) collaborationDoc.getElementsByTagName("time").item(0);
}
// get start date value
String startDateValue = getText(startDateElement);
// convert to Date
Date startDate = toDate(startDateValue);
The conversion to the Java Date format is done with the
private method toDate which is shown in the full
listing. The text content of element startDateElement was
extracted with the private method getText. Text
content is treated in DOM as a separate child element, and consequently we
first use the DOM method getFirstChild() followed by
method getData():
// get text content from element
private String getText(Element element) {
return ((CharacterData) element.getFirstChild()).getData();
}
Now, we loop over all jazzMusician elements of the new
collaboration document
// Get jazzMusician elements
NodeList collaborateurs =
collaborationDoc.getElementsByTagName("jazzMusician");
// now loop over the "jazzMusician" children
for (int i=0; i < collaborateurs.getLength(); i++) {
We extract their content and use it to query the database for
jazzMusician documents:
// get a single "jazzMusician" child
Element collaborateurElement =
(Element) collaborateurs.item(i);
// check if this item has content
if (collaborateurElement.hasChildNodes()) {
// get the string content
String collaborateurID = getText(collaborateurElement);
// Perform query for jazzMusicians
// identified by collaborateurID
TResponse response =
processQuery("jazzMusician[@ID"+"='" + collaborateurID + "']");
For each query we check if we have found a document. If so, we extract
the birth date, convert it to the Java Date format and compare it
with the collaboration start date. If the birth date is larger than the
collaboration start date, or if the referenced jazzMusician
document did not exist, we report an appropriate error message and indicate
that the transaction needs to be aborted.
// Process the musician document if we have one
if (!response.hasFirstXMLObject()) {
abortTransaction = true;
System.out.println("Error: Referenced jazzMusician "
+collaborateurID+" does not exist");
} else {
// get first (and only) result document
TXMLObject jazzMusicianObject =
response.getFirstXMLObject();
// Get top level DOM element
Document jazzMusicianDoc =
(Document) jazzMusicianObject.getDocument();
// get birthDate
Element birthDateElement = (Element)
jazzMusicianDoc.getElementsByTagName("birthDate").item(0);
// get string value
String birthDateValue = getText(birthDateElement);
// convert to date
Date birthDate = toDate(birthDateValue);
// compare with startDate
if (startDate.compareTo(birthDate) <= 0) {
abortTransaction = true;
// Report violation of integrity constraint
System.out.println(
"Error: Collaboration start date before birth date of jazz musician "
+collaborateurID);
}
}
After we have looped through all collaborators we are ready to insert
the new collaboration document into the database. If the indicator
abortTransaction was set, we rollback the transaction. Otherwise
we perform the insert operation and commit the transaction.
if (abortTransaction) {
myTransaction.rollback();
// Report abort of operation
System.out.println("Error: Insert not performed");
} else {
performInsert( collaborationObject );
myTransaction.commit();
// Show the collection, doctype and id
System.out.println(
"Message: Insert succeeded, ino:collection="
+ collaborationObject.getCollection() + ", ino:doctype="
+ collaborationObject.getDoctype() +", ino:id="
+ collaborationObject.getId() );
}
The actual insert operation is performed in the private method
performInsert() which is quite similar to the previous
processQuery() method, and which is shown in the full
listing in
InsertConstraintCheck.java.
When we execute this program with parameter C:/projects/jazz/post-election-jam.xml (or wherever else this file may be stored) we get a protocol similar to the following:
Message: Insert succeeded, ino:collection=encyclopedia, ino:doctype=collaboration, ino:id=3
However, if we change the time entry in this document
from
<time>1945-10-21T20:00:00</time>
into
<time>1915-10-21T20:00:00</time>
and try to insert it again, we obtain:
Error: Collaboration start date before birth date of jazz musician GillespieDizzy
Error: Collaboration start date before birth date of jazz musician ParkerCharlie
Error: Insert not performed
Note:
As a matter of fact, we would need similar checks when we update a
collaboration document and, of course, when we update
jazzMusician documents.
The third example deals with the problem of inserting a document that
has a primary (unique) key. Both our jazzMusician and
album document are equipped with a primary key:
jazzMusician with the attribute ID, and
album with the element productNo. When we want to add
one of these documents, we must make sure that a document with the same key
value does not already exist in the database.
This must be done in a transactionally safe way, and there are several ways to achieve that. For the purpose of this example, we have chosen an optimistic method which consists of the following steps:
Start a transaction.
IInsert the document with the lock mode set to "shared".
Retrieve all documents with the same key value and with lock mode set to "unprotected".
If there are more than one document returned, rollback the transaction. Otherwise commit the transaction.
However, this leaves us with a problem. Tamino does not allow us to change the lock mode of a connection within a transaction. The solution is to open two connections. Connection A is set to "shared" and performs the steps 1, 2, and 4. Connection B is set to "unprotected" and performs step 3.
Consequently, we have to initiate two database connections and two accessor instances. Here are the definition for the instances variables:
// Database connection A private TConnection connectionA = null; // Accessor A private TXMLObjectAccessor accessorA = null; // Database connection B private TConnection connectionB = null; // Accessor B private TXMLObjectAccessor accessorB = null;
The initialization, which is performed in the constructor of the class, looks like this:
public InsertUnique (String databaseURI,String collection)
throws TConnectionException {
// Obtain the connection factory
TConnectionFactory connectionFactory =
TConnectionFactory.getInstance();
// Obtain the first connection to the database
connectionA = connectionFactory.newConnection( databaseURI );
// Obtain the concrete TXMLObjectAccessor with
// an underyling DOM object model
accessorA = connectionA.newXMLObjectAccessor(
TAccessLocation.newInstance( collection ) ,
TDOMObjectModel.getInstance() );
// Set local transaction mode to "shared"
connectionA.setLockMode(TLockMode.SHARED) ;
// Obtain the second connection to the database
connectionB = connectionFactory.newConnection( databaseURI );
// Obtain the second accessor
accessorB = connectionB.newXMLObjectAccessor(
TAccessLocation.newInstance( collection ) ,
TDOMObjectModel.getInstance() );
// Set lock mode of connection 2 to "unprotected"
connectionB.setLockMode(TLockMode.UNPROTECTED) ;
}
Our example program InsertUnique is written in a generic
way. It accepts as parameters the name of the XML file to be inserted and the
name of the key to test (if the key is an attribute it is prefixed with an
@). These parameters are passed to the private method
processTransaction().
Similar as in the previous example in section Testing integrity constraints we first read the document to be inserted from an XML file:
private void processTransaction(String filename, String key)
throws Exception {
TLocalTransaction myTransaction = null;
try {
// Read file into a DOM Tamino XML object.
// Instantiate an empty TXMLObject instance
// related to the DOM object model.
TXMLObject xmlObject =
TXMLObject.newInstance( TDOMObjectModel.getInstance() );
// Establish the DOM representation
// by reading the content from a file input stream.
xmlObject.readFrom( new FileInputStream(filename ));
// get DOM document
Document doc = (Document) xmlObject.getDocument();
// get top level element
Element root = (Element) xmlObject.getElement();
Then we try to get the value of the key element or key attribute. In
case of an attribute we first must remove the @ from the key name
which is done with method substring(1).
// get key value
String keyValue = null;
// check if key is an attribute or an element
if (key.startsWith("@")) {
// get attribute value
keyValue = root.getAttribute(key.substring(1));
} else {
// get element node list
NodeList nl = doc.getElementsByTagName(key);
if (nl.getLength() == 0)
throw new Exception("Key not found");
// get only element
Element elem = (Element) nl.item(0);
// get element content
keyValue = getText(elem);
}
// Check for proper content
if (keyValue == "") throw new Exception("Key not found");
The private method getText retrieves the text
content of an element and is defined as in the previous example in section
Testing integrity
constraints.
Now we can start a transaction on connection A and insert the document:
// Start the transaction
myTransaction = connectionA.useLocalTransactionMode();
// Insert the document
performInsert( xmlObject );
Then we ask for the number of documents matching the key value. We do this through connection B which was set to lock mode "unprotected". If the number of matching documents is unequal 1 we rollback the transaction, otherwise we perform a commit.
// Get number of matching documents
int c = getCount( xmlObject.getDoctype()
+ "["+key+"='" + keyValue + "']" );
if (c == 1) {
// Unique - commit the transaction
myTransaction.commit();
System.out.println("Transaction committed");
} else {
// Bad - rollback the transaction
myTransaction.rollback();
throw new Exception("Key not unique: "
+c+" occurrences. Transaction aborted.");
}
The number of matching documents is determined by private method
getCount(). This method simply wraps an XQuery
count() function around the query string, performs the query, and
converts the result into an integer format.
private int getCount(String path) throws Exception {
try {
// Construct TQuery object
TQuery query = TQuery.newInstance("count("+path+")");
// perform the query
TResponse response = accessorB.query(query);
// get the number of documents found
String s = response.getQueryContentAsString();
// convert to integer
return Integer.valueOf(s).intValue();
}
catch (TQueryException queryException) {
showAccessFailure( queryException );
return 0;
}
}
The complete code of class InsertUnique is contained in
InsertUnique.java.
We can test this program by invoking it with the parameters
"C:\projects\jazz\dizzy.xml" and "@ID".
We should get the following result (because we previously have already added dizzy.xml to the database):
java.lang.Exception: Key not unique: 2 occurrences. Transaction aborted.
at com.softwareag.tamino.db.api.examples.jazz.InsertUnique.processTransaction(InsertUnique.java:123)
at com.softwareag.tamino.db.api.examples.jazz.InsertUnique.main(InsertUnique.java:145)
Exception in thread "main"