Check whether two values are equal or not.
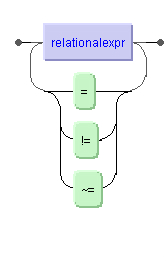
By using the operators = and != you can check if
two values are equal or not. In addition, you can test with the help of the
contains operator ~= if the left operand contains the word pattern
specified by the right operand. The result of the comparison is always one of
the Boolean values "true" and
"false". If there is a collation defined for either
of the operands or if both operands have the same collation defined, then the
comparison is based on this collation, otherwise it is character-based (this
does not apply for the operator ~=).
When using the white space-separated tokenizer (default), there are also rules for handling character variants such as umlauts or accented characters. As an example the French "é" and "è" will be mapped to "e", before comparison takes place. The German umlauts "ä", "ö", and "ü" will be mapped to "ae", "oe" and "ue" respectively. For a complete and detailed description of how characters are mapped by default and how you can customize this behaviour, please see the section Unicode and Text Retrieval.
With the contains operator you can perform text retrieval including the
use of a wildcard character: the value of the right operand is searched word by
word regardless of case. The result is "true", if it
could be found in the node's value irrespective of its location. A word
consists of a non-empty sequence of characters. A wildcard character matches
zero or more characters in a word so that a single
"*" represents a single word. If the value of the
right operand contains more than one word such as in the expression [node
~= "word1 word2"] then it is treated as [node ~= "word1" adj
"word2"].
The wildcard character is always the asterisk
"*" (Unicode value U+002A).
The equality operators = and != correspond to
the expression EqualityExpr defined in XPath,
Section 3.4, Rule
23. For the additional X-Query operator ~=, there is no
equivalent in XPath.
The examples below are distinguished according to the tokenizer used. For a given database, you can set the tokenizer using the Tamino Manager.
Select all patients born in 1950 (all patient nodes that
satisfy the following predicate expression: the value of the born
child node equals the numerical value 1950):
/patient[born = 1950]
Select all patients not born in 1950 (all patient nodes
that satisfy the following predicate expression: the value of the
born child node is not equal to the numerical value 1950):
/patient[born != 1950]
Select all patients born before 1959:
/patient[born < 1959]
Select all patients doing a professional job (all patient
nodes that satisfy the following predicate expression: the value
occupation child node contains any case-insensitive form of
"Professional"):
/patient[occupation ~= 'Professional']
Select all patients doing a professional job (all patient
nodes that satisfy the following predicate expression: the value
occupation child node contains any case-insensitive form of
"Professional" which is followed by a single word):
/patient[occupation ~= 'Professional *']
Note:
This predicate expression is equivalent with
/patient[occupation ~= 'Professional' adj '*'].
Select all patients whose surname contains a word beginning with "At":
/patient/name[surname ~= 'At*']
Select all patients whose surname contains a word ending with "ins":
/patient/name[surname ~= '*ins']
Select all patients whose surname contains a word with the sequence "ins":
/patient/name[surname ~= '*ins*']
Examples using the Japanese tokenizer are available in the section Pattern Matching in the XQuery User Guide.
RelationalExpr |