In the following sections, XQuery keywords are rendered bold
and in color. If you have already set up a
database, you can directly copy the text and paste it into the
XQuery text field of the Tamino Interactive Interface. In
the Collection text field, enter
"XMP" for the doctypes bib and
reviews, and "Hospital" for the doctype
patient.
A central concept of XQuery is compositionality: You can use constructors to compose new XML elements.
<fact>This section contains {3 + 6} examples.</fact>
This first query returns the following result from Tamino as presented by Microsoft's Internet Explorer:
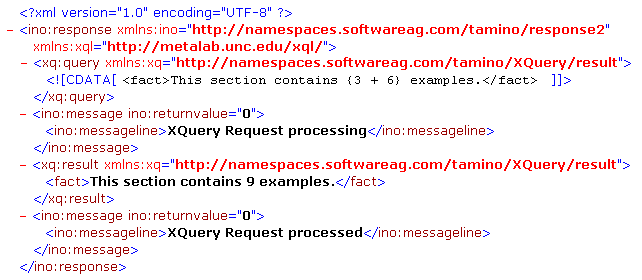
Tamino returns a well-formed XML document with the document element
ino:response. It contains information about the
query and its processing: the query expression itself
(xq:query), messages about any actions before and
after processing (ino:message) and in between the
actual query result embedded into the xq:result
element that reads:
<fact>This section contains 9 examples.</fact>
You can also reduce the output of Tamino to the bare query result. See the section Suppressing the Response Wrapper for details.
Here, an element constructor creates the element
fact. It contains the expression 3 + 6
that is enclosed by braces. The arithmetic expression is evaluated and the
constructed element is embedded into the output document element returned by
Tamino.
There are other constructors that you can use to create other types of nodes such as attribute nodes.
See AdditiveExpr and ElementConstructor in the Tamino XQuery Reference Guide for details.
In this query we use the technique of constructing elements in a FLWOR expression:
for $b in input()/bib/book return $b/title
It returns a list of all book titles:
<title>TCP/IP Illustrated</title> <title>Advanced Programming in the Unix environment</title> <title>Data on the Web</title> <title>The Economics of Technology and Content for Digital TV</title>
The basic form of a FLWOR expression (pronounced:
"flower") is used here. You could very roughly
compare a FLWOR expression with the SQL expression SELECT -
FROM - WHERE. The letters in FLWOR stand for the
XQuery keywords for, let, where,
order by and return, two of which are used here. Let
us examine them more closely:
for $b in input()/bib/book
The for clause binds all values that are evaluated from
the expression following the keyword in as an ordered sequence of
items to the variable $b. The expression
input()/bib/book evaluates to all instances of
bib/book elements in the default collection
(input()). So the variable $b iterates over a sequence
with four complete book elements.
return $b/title
The return clause uses the expression following the
keyword return to construct the result of the FLWOR expression.
Here, for each book element its child element
title is returned.
See FLWORExpr in the language reference for details.
Note:
According to the XQuery specification, all keywords in XQuery must
be written in lower case. It is an error to use upper case or mixed
case.
You can use filters to restrict the result sequence of a query. You can
specify a filter by using a where clause in a FLWOR
expression:
for $b in input()/bib/book where $b/@year > 1994 return <book> { $b/@year } { $b/title } </book>
This query returns all book/title elements
of the current collection together with the year of publication provided that
the year of publication is 1995 or later:
<book year="2000"> <title>Data on the Web</title> </book> <book year="1999"> <title>The Economics of Technology and Content for Digital TV</title> </book>
Again, a FLWOR expression is used in the query, but this time there is
an additional where clause:
where $b/@year > 1994
It restricts the bindings to the variable $b to those that
meet the condition in the expression following the keyword where:
Only those book elements are retained that have an
attribute year whose numerical value is greater
than 1994. So it has the same effect as the WHERE clause in
SQL.
return
<book>
{ $b/@year }
{ $b/title }
</book>
An element constructor is used that creates a new element
book which is then filled by two enclosed
expressions: the first one evaluates to an attribute that is attached to the
element book, the second expression is used as before.
You could also introduce an additional variable that is bound to the
attribute year by using the let
clause. The query then reads:
for $b in input()/bib/book let $y := $b/@year where $y > 1994 return <book> { $y } { $b/title } </book>
The let clause adds an additional binding so that you can
refer to $y instead of referring to $b/@year.
See FLWORExpr in the language reference for details.
Note:
Although a sequence of book elements is
not a well-formed XML element by itself, the resulting node sequence is
serialized by Tamino into an xq:result node, which
is in itself a new well-formed XML document.
The facility of sorting is available with the expression sort
by. You can use it for sorting query results as in the following
example:
for $b in (input()/bib/book) sort by (title) let $y := $b/@year where $y > 1991 return <book> <year> { string($y) } </year> { $b/title } </book>
This query returns all book elements sorted
by their title:
<book> <year>1992</year> <title>Advanced Programming in the Unix environment</title> </book> <book> <year>2000</year> <title>Data on the Web</title> </book> <book> <year>1994</year> <title>TCP/IP Illustrated</title> </book> <book> <year>1999</year> <title>The Economics of Technology and Content for Digital TV</title> </book>
Building upon the FLWOR expression from the last example, we modified
the return clause:
return
<book>
<year> { string($y) } </year>
{ $b/title }
</book>
The year of publication is now the contents of the new element
year. As the expression $b/@year
represents an attribute node, we need to turn its value into a string by
applying the function string().
sort by (title)
All book elements are sorted by their child
element title in ascending order. The FLWOR
expression evaluates to a sequence of items and determines the context node for
sort by (XQuery calls this evaluation context inner
focus). These input items are then reordered according to the sort
criterion and returned as a sequence of output items. As
book is the context node for each input item, the
result is a sequence of book elements sorted
alphabetically by title in the default order, which is
ascending.
An alternative version of this query is:
for $b in input()/bib/book let $y := $b/@year where $y > 1991 return <book> <year> { string($y) } </year> { $b/title } </book> sort by (title)
Putting the sort at the end of the for clause has the
advantage that the data type of title is retained
and the query can be optimized, while newly constructed nodes have no type
information.
See SortExpr and fn:string in the language reference for details.
You can perform join operations on documents of different doctypes and collections:
for $b in input()/bib/book, $a in input()/reviews/entry where $b/title = $a/title return <book> { $b/author } { $b/title } { $a/review } </book>
This join query returns all books for which a review exists, with all authors, title and the review text.
<book> <author><last>Stevens</last><first>W.</first></author> <title>TCP/IP Illustrated</title> <review>One of the best books on TCP/IP.</review> </book> <book> <author><last>Stevens</last><first>W.</first></author> <title>Advanced Programming in the Unix environment</title> <review>A clear and detailed discussion of UNIX programming.</review> </book> <book> <author><last>Abiteboul</last><first>Serge</first></author> <author><last>Buneman</last><first>Peter</first></author> <author><last>Suciu</last><first>Dan</first></author> <title>Data on the Web</title> <review>A very good discussion of semi-structured database systems and XML.</review> </book>
A join is constructed in a similar way as in SQL: you identify the items that must match, determine the join criterion and define the output:
for $b in input()/bib/book, $a in input()/reviews/entry
Two variables $a and $b are bound:
$b is bound to all instances of bib/book, while
$a is bound to all instances of reviews/entry. Both
doctypes, bib and reviews, are available in the same collection (XMP).
where $b/title = $a/title
The FLWOR expression is processed by repeated construction: tuples
consisting of an item bound to $a and an item bound to
$b. Only those tuples are retained that satisfy the condition that
$b/title of doctype bib is equal to
$a/title of doctype reviews. Equality is based on the
value of the nodes. This is what you could call an equijoin in XML
Query.
return
<book>
{ $b/author }
{ $b/title }
{ $a/review }
</book>
As before, we use constructors with embedded expressions to define the
output. Note that { $b/author } applies to all instances of
author so that the third book appears with all three
authors. Also, as the author element contains
child elements, these are included as well.
You can perform text search operations by using one of the functions
tf:containsText, tf:containsAdjacentText or
tf:containsNearText. Other retrieval operations include
"highlighting" of text, navigating in user-defined thesauri and
searching based on phonetic similarities, word stemming or semantic
relationships.
for $a in input()/bib/book where tf:containsText ($a/title, "UNIX") return $a
This query returns all book elements that
contain the word "UNIX" regardless of the case:
<book year="1992">
<title>Advanced Programming in the Unix environment</title>
<author>
<last>Stevens</last>
<first>W.</first>
</author>
<publisher>Addison-Wesley</publisher>
<price>65.95</price>
</book>
All book elements are checked whether they
contain the word "UNIX" in their
title element independent from case. Those that
contain this word will be returned as result.
As the function tf:containsText() is from a different
namespace than the standard namespace, you need to declare this namespace
first. In this namespace you will find all functions that are specific to
Tamino. See tf:containsText
in the language reference for details. The section
Unicode and Text
Retrieval contains more information about the fundamentals
of word-wise search in Tamino.
You can perform update operations on documents to insert, replace,
rename or delete nodes or node sequences (node-level update). It is
easy to identify any update operation, since the keyword update
always appears at the start of the expression right after the prolog.
Note:
Any update operation requires that you have permission to perform
this operation. In short, Tamino checks to see if the resulting
document is such that you may write it back into the database.
The first simple query deletes all books from the current
bib collection that have been edited by Darcy
Gerbarg:
update delete input()/bib/book[editor/last="Gerbarg"]
As the result is a modification of the current collection, you receive a confirmation that the operation has been performed successfully:
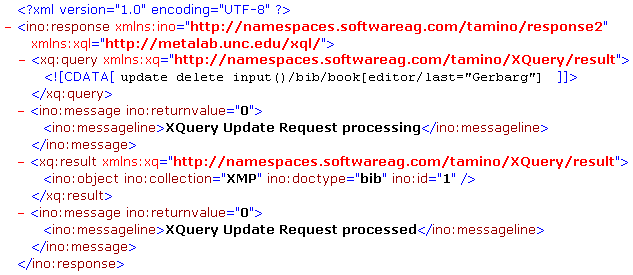
From the document returned by Tamino you can see the original query
expression in the marked CDATA section, and the
xq:result element that provides information about
where the update operation took place: The first document instance
(ino:id="1") of the document type bib
(ino:doctype="bib") in the collection XMP
(ino:collection="XMP").
You can use queries like count(input()/bib/book) to check
the number of books before and after the delete operation.
See UpdateExpr and DeleteClause in the language reference for details.
This query reinserts the book with the title "The
Economics of Technology and Content for Digital TV" into the
bib element of the current
collection.
update insert <book year="1999"> <title>The Economics of Technology and Content for Digital TV</title> <author> <last>Gerbarg</last> <first>Darcy</first> </author> <publisher>Kluwer Academic Publishers</publisher> <price>129.95</price> </book> into input()/bib
The current bib element is updated by
inserting the book element as child element. The new
book element is now the last child element of
bib.
See UpdateExpr and InsertClause in the language reference for details.
Having a closer look at the book just inserted, we see that we added
Darcy Gerbarg as an author. However, she really is the editor and not the
author of the book so we need to rename the element and insert the necessary
affiliation element:
update for $a in input()/bib/book where $a/title = "The Economics of Technology and Content for Digital TV" do ( insert <affiliation>CITI</affiliation> following $a/author/first rename $a/author as editor )
For the operation to succeed, an editor
element must be allowed at the same hierarchical position as the
author element. This means, they must be siblings as
defined in the schema, which is the case.
See UpdateExpr and RenameClause in the language reference for details.