The Tamino Non-XML Indexer is based on and extends Tamino's facilities for storing and retrieving non-XML objects; these facilities are described in the sections Storing Non-XML Objects in Tamino, Using Shadow Functions and Shadow Functions. Tamino's basic functionality allows you to store, update and delete non-XML objects; you can retrieve a non-XML object on the basis of its ino:id or its ino:docname. These two pieces of information, the ino:id and the ino:docname, can be regarded as metadata associated with the original non-XML object.
The Tamino Non-XML Indexer plugin modules, which can be either the standard plugins supplied by Software AG or user-written plugins, work in conjunction with Tamino to extend the set of metadata that is associated with non-XML objects. The plugin produces a well-formed XML document that conforms to the metadata schema. Typically, the plugin populates the contents of the elements and the attributes with values contained in or derived from the original non-XML file, for example author's name, date last modified, or file size. For certain kinds of input data, the plugin can derive data directly from the input data; for example, the PDF plugin can read the text contents out of most PDF files and store them in the shadow file.
Whenever an insert or update operation is processed for a document whose
MIME type has been declared to the Tamino Non-XML
Indexer, Tamino calls the server extension
(SXSBlobIndexer). The server extension's dispatcher
then activates the appropriate method in the appropriate plugin. The
plugin:
Analyses the document, and extracts the raw data contained in the document if appropriate (for example, the plain text is extracted from a Microsoft Word document) and also metadata that describes the document;
Creates a well-formed XML document containing this information;
Passes this XML document as a shadow document to Tamino, which writes it to the database.
Both the non-XML object (or the pseudo non-XML object, which is a BLOB of size zero, if the option "storeShadowOnly" is activated) and its associated XML shadow object have the same ino:id.
If the document schema includes the tsd:noConversion element, the document is processed as follows:
The Tamino Non-XML Indexer receives the document as an unaltered bytestream. (In particular, the document has not yet been subjected to Unicode translations.)
If the MIME-type indicates that the document is a text file, then:
If there is no encoding information, the shadow document is empty and a warning is issued;
If translation is not supported, the shadow document is empty and a warning is issued;
Otherwise, the Tamino Non-XML Indexer translates the incoming bytestream into a text stream as indicated by the encoding information.
If translation succeeds, the Tamino Non-XML Indexer processes the resulting string as though the string had been passed to the putText() function.
The non-XML object can be accessed by plain URL addressing, unless the option "storeShadowOnly" has been activated. The associated XML shadow document can be accessed by issuing a query (for example in XQuery or X-Query form). Note that non-XML objects stored in Tamino can be accessed in this manner even if the Tamino Non-XML Indexer is not installed; the difference is in the variety of different metadata fields that can be queried.
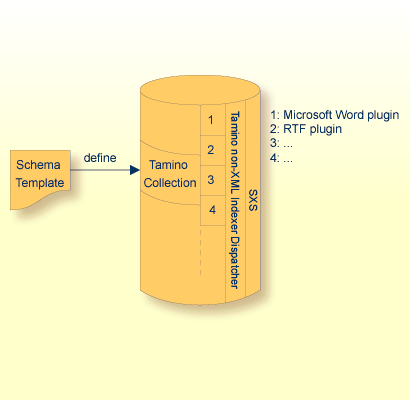
Tamino Non-XML Indexer services are logically provided by software at two levels, as shown in the diagram above:
The Tamino Non-XML Indexer dispatcher;
One or more plugin modules (represented in the diagram by the numbers 1, 2, 3, 4...). Each plugin services one or more MIME types.