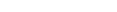
As we have seen, with XML and XML Schema we have many options for designing XML documents. Let us return to our conceptual model.
We are now in a position to add some type information to our model:
In the diagram, we have defined the XML Schema type system as the
default type system of our model (Asset Oriented Modeling can handle multiple
type systems within one model). Most of the properties and sub-properties in
this model are now prefixed with a type name (separated by a blank). All
properties used as primary keys are defined with datatype NMTOKEN.
This will save us a lot of trouble later, when we want to transport a key value
in the query part of a URL. (White space character handling in URLs is
awkward.)
We see, too, that the type properties in the assets
jazzMusician and collaboration are defined with an
enumeration as type. This would translate into the XML Schema type
xs:string with appropriate enumeration facets. The
property grade in asset saxophone has a type that is
constrained with the facets totalDigits and
fractionsDigits.
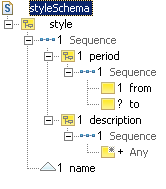
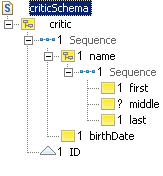
In addition, we have factored out some complex properties
(name and period) as explicit types. This is done by
defining the abstract assets (indicated by the grayed-out label area)
tName and tPeriod. We use the names of these assets
as type names in various other assets such as jazzMusician,
critic, style, belongsTo and
collaboration. Note that we have improved the definition of
tPeriod somewhat by making the property to optional.
This allows for open-ended periods.
Now we are ready to translate our conceptual model into XML Schema source code. However, the question arises, how we should best divide our model into individual schemas.
One extreme would be to create one XML document type for each asset.
However, this has a disadvantage: because the existence of some asset instances
can depend on the presence of other asset instances, we would require extra
operations when deleting and updating assets. For example, if we wanted to
delete a certain instance of jazzMusician, we would also have to
delete the instruments he or she plays.
The other extreme would be to create a single document containing the whole model. This is even worse because such an implementation would not scale well. Such a document can become very big, and consequently various operations (loading, saving, parsing, etc.) would be very slow. Although Tamino can insert, delete, and update document subtrees, each update operation would lock the whole model and would not allow concurrent updates, even if the concurrent operation wants to update another asset.
We therefore choose the best compromise between these extremes and implement each business object as a single document. (In a more business-oriented scenario we would treat business documents such as Purchase Orders or Invoices in the same way.) This has the following advantages:
The existence of business objects does not depend on other objects. Business objects by definition exist in their own right. Deleting a single business object, for example, does not require the deletion of other objects.
Modifications made to a single business object do not lock the whole model. Concurrent update operations to other business objects are possible.
This implementation fits well with current standards in application design. For example, the construction of a Java access layer for such a document would result in an implementation of the corresponding Java business object class.
The resulting set of schemas is very intuitive. Each schema instance (i.e. each XML document) represents a business object or a business document. This is why we call this design method document-centric.
Note that if a model is divided into separate object types as described here, it is possible for an application to reconstruct a view of the whole model by using appropriate XQuery join queries, or by using several X-Query commands and postprocessing the results.
Our model contains global type definitions (the assets
tPeriod and tName) that are not specific to a
particular business object, and consequently in our design will not be specific
to a specific schema. It makes sense to create a global type library that
contains the XML Schema definition of these assets. Such a type library is
created as an independent XML Schema file with the same target namespace:
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified"
attributeFormDefault="unqualified">
<xs:complexType name="tPeriod">
<xs:sequence>
<xs:element name="from" type="xs:date"/>
<xs:element name="to" type="xs:date" minOccurs="0"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="tName">
<xs:sequence>
<xs:element name="first" type="xs:token"/>
<xs:element name="middle" type="xs:token" minOccurs="0"/>
<xs:element name="last" type="xs:token"/>
</xs:sequence>
</xs:complexType>
</xs:schema>
This file can then be imported into the schema files that implement business objects. The XML Schema syntax to import a foreign schema file into the current schema is:
<xs:import namespace="..." schemaLocation = "typelib.xsd"/>
The xs:import clause is specified as a direct
child of the xs:schema clause and must be specified at the very
beginning of this clause. The attribute schemaLocation specifies
the location of the imported file as a relative or absolute URL.
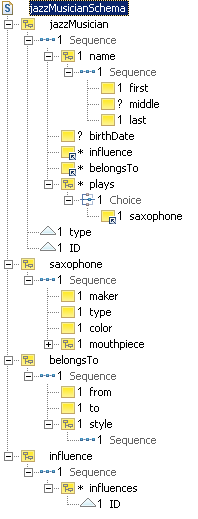
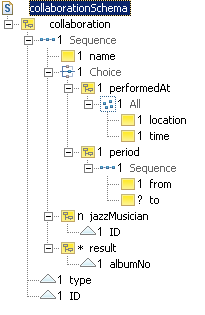
Our model now results - apart from the global type library - in the following schemas:
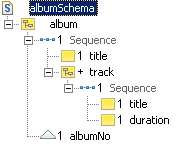
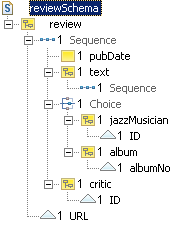
album, collaboration, critic,
jazzMusician, review, style.
 |
 |
 |
 |
 |
 |
The following paragraphs discuss some implementation decisions:
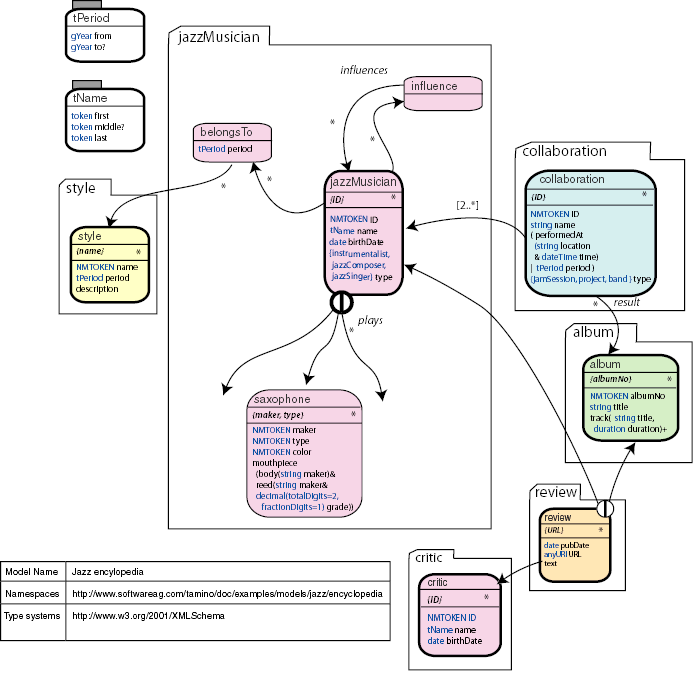
We have implemented all assets as global elements, and all properties
as local elements. Aggregations of assets, such as in
jazzMusician, are implemented via references to global elements.
This allows us to identify assets and properties in schema source code
easily.
In the schema jazzMusician, the instrument
cluster is implemented as a choice connector containing the
different instruments (only saxophone is shown here).
We have implemented all primary keys and qualifying properties such as
kind and type as attributes. This is just for the
sake of this example - you are of course free to use elements and attributes at
your own discretion.
Arcs to other business objects are implemented as a kind of foreign key. The concept of a foreign key, familiar from relational systems, is not defined in XML Schema. However, we use the term loosely here to indicate an implicit reference to an external asset. Each foreign key consists of a local element definition. The element name reflects the arc's role name (or the name of the arc's target asset when no role name is specified). This element has an attribute which matches the primary key attribute of the target asset in name and type. Again, the choice to use attributes as foreign key implementations is only for the sake of this example.
The properties description of asset style
and text of asset review are implemented as
wildcards. The any declaration allows the element to contain XHTML
markup, for example. We have set processContents to
"lax" for these elements and namespace
to "http://www.w3.org/1999/xhtml", so parsers will
check for valid XHTML content when an XHTML schema is available. We have also
set maxOccurs to "unbounded" for each
any declaration, to allow for multiple XHTML elements within a
wildcard.
Although this document-centric approach is the preferred way to implement a conceptual model, it is sometimes necessary to make compromises, especially when documents become too large, or when operations become inefficient.
Large documents have several drawbacks:
Parsing a large document takes a long time. This affects almost any processing of XML documents (for example, transformation with an XSLT style sheet), because most XML processing involves parsing.
Processing a large document with the DOM API requires a large amount of resources. The whole document is converted into object form (each document node becomes a separate object) and this whole set of objects is kept resident in memory. Recent DOM parsers feature lazy instantiation, which is less resource hungry. However, in the worst case, they require the same amount of memory as conventional DOM parsers.
Collaborative authoring of large documents is awkward. Most database systems (and also standards for distributed authoring like WebDAV) support locking only at the document level. So when one client changes a document, the document is locked for others until the first client commits. Also, the exchange of such documents between authors can take a long time.
It therefore seems sensible to split large documents into smaller ones.
In particular, this is the case when a document is subject to unrestricted
growth. Take for example the document type album from the example
above. If we opted to include the text of all reviews in the respective
album document, we could get a nasty surprise. If a lot of people
review an album, our album document could become very large. That
is one reason why we decided to model review as an explicit
business object.
However, segmentation can also create problems. During retrieval we need more join operations, and some aggregating functions become slow. For example, if we want to find out the number of albums in which a jazz musician has participated, we would first have to retrieve all collaborations of that musician, and then count the albums referenced as a result of the collaboration.
This can be improved by adding redundancy to our document base. For
example, we could include an album count in each jazzMusician
document. The downside of this is that update operations become more
complicated. When we add new albums, or when we delete albums, we have to
update the respective counters in the jazzMusician instances as
well. So, tuning of schemas is always a compromise. The best way almost always
depends on the frequency of updates and retrievals, and whether it is more
important to offer fast response times for retrieval or for update, and so on.
Database tuning is not an exact science, but depends very much on heuristics,
experience, and skill.
Let's return to the multi-namespace model defined in section Models and Namespaces. This model featured four namespaces:
the default namespace
http://www.softwareag.com/tamino/doc/examples/models/jazz/shop,
the namespace
http://www.softwareag.com/tamino/doc/examples/models/jazz/encyclopedia
for the jazz knowledge base,
the namespace
http://www.softwareag.com/tamino/doc/examples/models/instruments
for the musical instruments,
and the namespace
http://www.softwareag.com/tamino/doc/examples/models/order/reengineered
for the order model.
How does this affect our XML schemas? The asset CD is
defined as a separate business object, and thus results in a separate schema
file with its own target namespace
(http://www.softwareag.com/tamino/doc/examples/models/jazz/shop).
We now have to implement the inherited arcs that lead to asset CD
(from e:collaboration, e:review, and
o:item). These arcs are implemented in the usual way within the
respective schema files, in addition (and similar) to the arcs leading to
e:album and o:product. Since these arcs are
implemented via primary and foreign key constructs and not via reference or
inclusion, all schemas stay single-namespace schemas.
Note, however, that the instruments are implemented differently.
Instruments such as i:saxophone and i:trombone are
part of the jazzMusician business object, and are consequently
referred to (via an xs:element ref= clause) within the
jazzMusician schema file. But because these instruments belong to a different
model (and thus to a different namespace), they must be implemented in a schema
file with target namespace
http://www.softwareag.com/tamino/doc/examples/models/instruments.
Let us assume that all instruments are defined as global elements in a schema
file called instrument.xsd.
What we have to do then, is to import the file instrument.xsd into the file jazzMusician.xsd. And this is how it's done:
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema targetNamespace="http://www.softwareag.com/tamino/doc/examples/models/jazz/encyclopedia"
xmlns:e="http://www.softwareag.com/tamino/doc/examples/models/jazz/encyclopedia"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:i="http://www.softwareag.com/tamino/doc/examples/models/instruments"
elementFormDefault="qualified"
attributeFormDefault="unqualified">
<xs:import schemaLocation="typelib.xsd"/>
<xs:import namespace="http://www.softwareag.com/tamino/doc/examples/models/instruments"
schemaLocation="instrument.xsd"/>
<xs:element name="e:jazzMusician">
<xs:complexType>
<xs:sequence>
<xs:element name="e:name" type="e:tName"/>
...
<xs:element name="e:plays"
minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:choice>
<xs:element ref="i:saxophone"/>
</xs:choice>
</xs:complexType>
</xs:element>
</xs:sequence>
...
</xs:complexType>
</xs:element>
...
</xs:schema>
The two xs:import clauses are specified at the very
beginning of the xs:schema clause. The namespace
attribute specifies the namespace to be imported (this must match the target
namespace definition in the imported schema file), and the
schemaLocation attribute specifies the location of the file to be
imported. In addition, we must specify a namespace prefix for the imported
namespace. This is done in the xmlns:i attribute of the
xs:schema clause. This prefix is used when we refer to a musical
instrument, for example xs:element ref="i:saxophone". Note that
there can be several import clauses in one schema, and even several import
clauses for a given namespace.
As you can see, we have opted to use the prefix
"e:" for the schema's target namespace
http://www.softwareag.com/tamino/doc/examples/models/jazz/encyclopedia.
This is just to preserve the namespace prefix usage in the conceptual model -
continuing using this namespace as the default namespace for the schema would
also be valid.
Once a schema has been defined, it is very unlikely that it will always stay in the same state. Business requirements change and bugs are detected, so the schema must be modified in order to adapt to changing circumstances. In this section we discuss how a schema can be modified safely. "Safe" in this context means that the modified schema must still cover all existing valid document instances of the original schema. The following guidelines ensure that the new schema is at least as "wide" as the original schema:
Never make cardinality constraints narrower. You may increase
maxOccurs and decrease minOccurs. However, decreasing
maxOccurs or increasing minOccurs might render
existing instances invalid. This logic also applies when adding or removing
elements or attributes. Any non-existing element can be seen as an element with
minOccurs="0" and maxOccurs="0". If you want to add a
new element, just imagine that it already exists with
minOccurs="0" and maxOccurs="0". Consequently, leave
minOccurs at "0" and increase only maxOccurs to
comply with the above rule. This means that all new elements must be optional.
On the other hand, if you no longer need a given element, simply set
minOccurs="0". This makes the element optional, so both new and
old instances are covered. The same logic applies to attributes. New attributes
should only be added with use="optional", and for attributes that
are no longer needed, use should also be set to
optional.
You can always introduce new choices into a schema: you can wrap
existing element definitions, element references, model group definitions
(xs:sequence, xs:all) or references to global groups
in an xs:choice clause and add more alternatives. Existing
instances remain valid but the new alternatives allow for additional
instances.
Never introduce new fixed or default values or modify existing fixed values. This might render existing instances invalid.
Never restrict the definition of existing simple type definitions. For
example, you can safely change a type definition from xs:short to
xs:integer, but not vice versa. The same applies for extension by
list: you can safely replace xs:NMTOKEN with
xs:NMTOKENS, but not vice versa. Do not introduce new facets into
a type definition, and do not make the definition of existing facets narrower
(e.g. reduce the number of total digits from 7 to 5).
These are general guidelines. You can also modify a schema in a way that is inconsistent with existing documents, providing you subsequently validate all affected documents, but this of course could be very time-consuming.
In Tamino XQuery 4, you can modify documents by using the
xquery update statement to insert, delete, replace or rename
nodes, but the resulting documents must comply with the existing schema; the
schema itself cannot be modified by xquery update.
Schema developers cannot always predict the requirements that may arise
in the field. XML Schema therefore provides extension mechanisms that allow
document authors to include elements and attributes into document instances
that are not declared in the schema. These extension mechanisms are implemented
in XML Schema as wildcards (xs:any and
xs:anyAttribute).
Let us assume, for example, that we want to make the definition of
tName more generic, allowing document authors to include a
title child element. We can allow document authors to insert any
number of extra child elements before, between, and after the existing child
elements with the following definition:
<xs:complexType name="tName">
<xs:sequence>
<xs:any namespace="##other" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
<xs:element name="first" type="xs:token"/>
<xs:element name="middle" type="xs:token" minOccurs="0"/>
<xs:any namespace="##other" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
<xs:element name="last" type="xs:token"/>
<xs:any processContents="lax" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:anyAttribute processContents="lax"/>
</xs:complexType>
We have also added an xs:anyAttribute clause to allow for
additional attributes.
Note the specification of namespace="##other" for the first
two wildcards. This is to avoid non-determinism. Without such a specification,
the wildcard could contain elements from the same namespace. When encountering
a first or a last element in a document instance, the
parser would not be able to decide if such an element should be accepted by the
wildcard or by the following element specification without looking ahead in the
input stream. For the same reason we did not introduce a wildcard in front of
the element definition middle. middle is optional, so
a parser would not know where to place an instance element: into the wildcard
before or after the element middle.
Note that Tamino allows for an alternative (non-standard) open content model that does not suffer from this problem (see From Schema to Tamino::Schema level Definitions).
There are two questions that arise when we create a new version of an existing schema:
The first question is: Should we change the target namespace of the new schema? The answer is simple: If you want to invalidate the schema against existing document instances, and against existing schemas that might include or import this schema, do so. In this case, you should retain the old schema version in order to support existing applications. Usually, this option is taken when the changes in the schema are severe. In all other cases, leave the target namespace unchanged and indicate the new schema version by other means.
This leads us to the second question: How do we indicate a version
number within a schema? The good news is that XML Schema features a
version attribute in the xs:schema clause. The bad
news is that parsers do not evaluate this attribute, so you won't see the
version number when you access a document instance through a DOM API; extra
application logic is required to read out the version number. This version
number is meant for human consumption, it indicates the version of the schema
to the schema author. To convey version information to applications, the best
method is to specify a version attribute for the root element of a
schema. We can give this attribute a fixed value reflecting the current
version. This attribute does not show up in document instances, but
applications can see it through the DOM API. Of course, nobody stops us from
defining such version attributes for other elements than the root element, too,
so you could add different version information to different subsections of the
same schema.