Before we go into the details of database tuning, we should make clear that due to ongoing development and tuning of the Tamino engine the performance hints given here are only based on a snapshot of the current situation. Future versions of Tamino may perform differently.
Optimizing Tamino for efficient querying involves three steps: Data Modeling, Index Definition, Query Definition.
First we should get the data model right:
Your document types should implement whole business objects and documents such as customers, suppliers, purchase orders, jazz musicians, albums, etc. You should avoid "relational" designs such as First Normal Form. Business objects represented by an ensemble of flat tables are suitable for relational databases, but not for native XML databases.
For our example, we created one document type for each of the business
objects style, jazzMusician,
collaboration and album.
Avoid "all-in-one" documents. Large documents can slow down processing considerably. For example, the current Tamino version compresses documents larger than 32 KB in order to save disk space and speed up disk access, so documents above this size need more CPU time.
For example, with XML it would be easily possible to create a single document containing our whole jazz encyclopedia (which, eventually, could grow into a size of several hundred MB). But do not expect good performance from such a design.
If a document contains clearly identifiable hot spots and cold areas, i.e. a small area is accessed frequently whereas another large area is accessed only rarely, consider separating these two areas into two separate documents. This increases the processing speed for the frequently accessed area.
In our example, we have stored the album reviews in separate documents.
These reviews are far less likely to be accessed than the album
document itself.
Sometimes it can be appropriate to re-introduce redundant data elements in order to speed up retrieval. The downside to this is that updating becomes more complicated and takes more time.
For example, if we frequently need to know how many albums a jazz
musician has published, retrieval performance could be improved by including
this information in each jazzMusician document; we would no longer
need to search all collaborations of a musician and then count the albums.
However, we would need to update all referenced jazzMusician
documents each time we insert, update or delete a collaboration
document.
The next step is to define indexes correctly:
Associate all primary and foreign keys used in the conceptual model with indexes of search type "standard" in Tamino. Search type "standard" results in the classical database index.
In our example, primary keys are:
jazzMusician/@ID, style/@name,
collaboration/@ID, album/@albumNo,
critic/@ID, and review/@URL. We might omit
review/@URL from this list, as we address review
documents via URL. Internally, review/@ino:docname serves as a
primary key.
The schema element tsd:unique
can be used to ensure that keys are unique. This is particularly relevant for
primary keys.
Foreign keys are:
jazzMusician/belongsTo/style/@name jazzMusician/influence/influences/@ID collaboration/jazzMusician/@ID collaboration/result/@albumNo album/review/@URL review/critic/@ID
Nodes that are used as sort criteria should also be defined as indexes of search type "standard".
In our example, a typical candidate is
jazzMusician/name/last.
Other nodes that are expected to be used as search criteria should also be defined as indexes. However, if a node is not very selective it does not make much sense as an index. For example, a node describing the gender of a person can only take one of two values. Such a node would make a bad index, because each index value would select half of the population; however, it could make sense as part of a compound index.
In our example, we would definitely not declare
jazzMusician/instrument/color as an index.
If you expect the contains operator (~=) to
be used frequently for a specific node, define this node as a key of search
type "text". This creates a word index, which speeds
up text
retrieval operations on the current node and child nodes.
Do not use search type "text" too liberally, because
it slows down write operations to the database.
In our example, we declare style/description and
review/text as text indexes. This allows us to search for words
and word combinations in these elements.
If you expect wildcard characters to be used at the beginning and end
of a search word, such as *cit* to find
"citation", "recite",
"recitation", you should consider setting word
fragment index to "true" for the database.
But note that this results in a huge index and slows down write operations even
more.
If you expect queries on document nodes that are not defined in the
document schema, consider setting structureIndex to
"CONDENSED" (see Indexing::Declaring an index). If you
expect queries on optional document nodes that appear only sparingly in
document instances, consider setting structureIndex to
"FULL".
Finally, we look at the queries. In this section, the majority of the examples are based on X-Query, but equivalent processing is possible in XQuery. For examples of equivalent coding in X-Query and XQuery, see the Performance Guide in the Tamino documentation set.
Internal query processing can involve a pre-selection step and a post-processing step, depending on the nature of the query. If the query involves searching on one or more indexes, the pre-selection step finds the documents that satisfy the index search criteria; if the query involves search criteria that do not use indexes, the post-processing step is required.
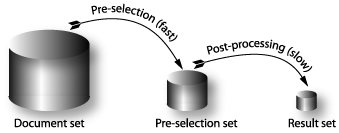
In the pre-selection step, the indexes are used to select an intermediate result set. In the post-processing step, this set is narrowed by applying the remaining search criteria. This post-processing step involves detailed analysis of each record contained in the intermediate result set.
For example, in the query:
jazzMusician[belongsTo/style/@name="Bebop" and
name/first="Charlie"]
the expression belongsTo/style/@name="Bebop"
is processed as a pre-selection because the foreign key
belongsTo/style/@name is defined as a standard index.
The rest of the filter expression name/first="Charlie" is
processed during the post-processing phase because name/first is
not defined as an index.
The same is true for the equivalent XQuery 4 expression. In
for $j in input()
where $j/belongsTo/style/@name="Bebop" and $j/name/first="Charlie"
return {$j}
$j/belongsTo/style/@name="Bebop" is executed first to
construct the pre-selection set, then $j/name/first="Charlie" is
executed.
Queries that do not have a pre-selection step (because there are no
indexes among the search criteria) cause a long response time when only a few
records are extracted from a large collection. You can easily determine whether
a pre-selection is used with your query: put your X-Query query string in
ino:explain(...) and Tamino will tell
you whether your query involves a pre-selection and whether it involves
post-processing.
In XQuery 4 we can obtain the same information by including the
expression {?explain?} in the query prologue.
The query above, for example:
ino:explain(jazzMusician[belongsTo/style/@name="Bebop"
and name/first="Charlie"])
results in:
<xql:result>
<ino:explanation ino:preselection="TRUE"
ino:postprocessing="TRUE" />
</xql:result>
As already explained above, this query involves both a pre-selection and
a post-processing phase. Not surprisingly, both ino:preselection
and ino:postprocessing have the value
"TRUE".
Because Tamino automatically separates pre-selection and post-processing criteria and applies further query optimization, the sequence of search criteria in a filter expression does not matter. For example, the query
jazzMusician[belongsTo/style/@name="Bebop"
and name/first="Charlie"]
is executed at the same speed as
jazzMusician[name/first="Charlie"
and belongsTo/style/@name="Bebop"]
(Remember, belongTo/style/@name is indexed,
name/first is not.)
Here are a few more guidelines for efficient querying:
There is one situation in which an indexed node cannot be processed during pre-selection: the query for the non-existence of the node. If a node does not exist, its value is not contained in the index, and consequently the test for non-existence cannot rely on the index. This test is therefore processed during the post-processing phase. Depending on the size of the pre-selected document set, this can be slow.
For example, let us assume that we had declared
jazzMusician/name/middle as a standard index. The query for jazz
musicians without a middle name:
jazzMusician[not(name/middle)]
would still require a scan through all jazzMusician
documents.
Avoid using the equality operator (=) when only a
"text" index is defined, or the contains operator
(~=) when only a "standard" index is
defined. In both cases, Tamino correctly evaluates
the query, but via post-processing! If you frequently apply both operators on
the same node, consider defining it as both a standard and text
index.
For example, the query
style[@name~="Cool*"] would be handled in the post-processing
stage, after reading all style documents. This is because
style/@name was defined as a standard index, not as a text
index.
Make use of Tamino's X-QUERY extensions to XPath. These extensions perform better than the equivalent standard XPath expressions.
For example, use [age between 40,65] instead of
[age >= 40 and age <= 65]. (For the definition of
jazzMusician/age please see
Utilizing
Server Extensions::Derived
elements).
Not only is it good style to make key and search expression type-compatible (e.g. to use a string search value for an alphanumeric key or a numeric search value for a numeric key); this also ensures that you always obtain correct results. Comparing an alphanumeric constant with a numeric element, for example, causes the numeric element to be converted into a string and a string comparison to be performed. This would probably not return the expected results. The performance suffers from this conversion too.
For example, write [age = 55] and not [age =
"55"] if you have defined age as an element of type
integer. Write [@ino:id=42] and not
[@ino:id="42"].
XQuery 4, on the other hand, checks for type consistency in expressions and throws an error if you try to compare an integer with a string. (Remember that XQuery 4 supports the full XML Schema type system.) In XQuery 4 you always must specify a correctly typed literal, as in:
where $j.birthdate = xs:date("1923-07-27").
Queries that do not use post-processing are especially
useful when it is not necessary to access any documents, for example, when
using the count() function.