How does Cross-DC Support Detect Data Center Failures?
All the data centers are connected together to form a consistent hash ring using gRPC channel. The consistent hash ring is maintained properly with the help of Gossiping protocol. Using Gossiping protocol, API Gateway detects the failure of nodes. Here nodes represent the data centers.
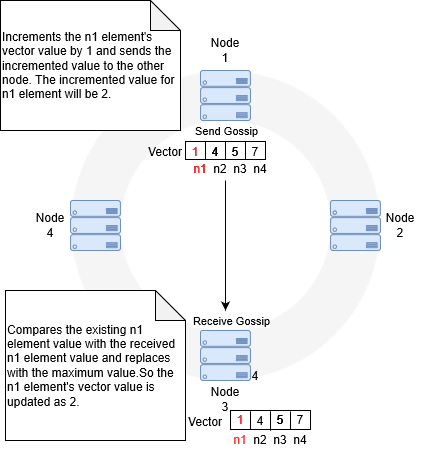
This is how the Gossiping protocol works in Cross-DC support in active-active mode. Each node sends and receives gossip between one another to ensure that they are up and running. Each node has a vector of elements. For example, if there are n nodes in a ring then each node has a vector with n elements.
Each node sends and receives gossips with one another. When a node receives a gossip, it compares the received vector element value with the existing vector element value and replaces the vector element of the received node with the maximum value. When the vector element value is replaced, then that particular time frame gets captured. If the last updated time interval happens to be greater than permissible time interval between two consecutive gossips (that you define in the pg_Dataspace_TimeToFail extended settings), then that particular node is marked as dead. If the last updated time interval is twice as that of permissible time interval, then that particular node is removed from the ring. When the dead nodes are up, the Gossiping protocol detects them and rehashes the nodes.
As in active-active mode, the hot standby mode also uses consistent hash ring and Gossiping protocol to detect the failure of nodes. But in the hot standby mode there are only two nodes in the ring. In hot standby mode, if the primary node goes down, the API Gateway administrator receives a notification and reconfigures the load balancer with the secondary node details. Hence, the secondary node handles the client request. When the primary node is restored back, the node gets added to the ring automatically. If the secondary node goes down, when the primary is active, then the secondary node is removed from the ring. When the secondary is restored it gets added to ring automatically.