Design operators added
Design operators provide formal support in creating a data model. Their use ensures systematic creation of data structures and provides the person who looks at an existing data structure with insights into the design process. Based on existing terms, new terms are developed by using design operators. This process is an intellectual procedure running at the level of business management knowledge. The examination of business management facts in terms of data structures either entails that known structures are changed based on new approaches, or that entirely new conclusions are drawn.
Of the numerous and various approaches for extending ERM modeling, four basic design operators have become accepted (see Scheer, Business Process Engineering, 1994, p. 35 et sqq.):

Classification,
Generalization,
Aggregation, and
Grouping.
Classification
Through classification, objects (entities) of the same type are identified and assigned to a term (entity type). Two objects are identical if the same properties (attributes) are used to describe them.
Classification thus results in the previously described identification of entity types.
Generalization/Specialization
Generalization means that similar object types are grouped under a superior object type.
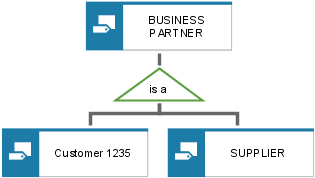
As shown in the following figure, the Customer entity type and the Supplier entity type are generalized to form the generic term Business associate. Properties (described by attributes) that both source objects share are transferred to the generalized object type. Thus, only those attributes in which the source object types differ are left to be described. The formation of the new entity type Business associate is graphically represented by a triangle, also called an 'is a' relationship.
Specialization is the breakdown of a generic term into subterms (Business associate is split into Customer and Supplier).
Specialization is the reverse of generalization. The specialized objects inherit the properties of the generalized object. Apart from these inherited attributes, the specialized object types may have their own attributes. Graphically, specialization and generalization are represented in the same way.
For this reason, the links in the illustration are not drawn as arrows indicating a direction.
While specialization primarily supports a top-down procedure when creating a data model, generalization is used to support a bottom-up procedure.
Within the scope of specialization, the completeness and disjunction (alternative) of the subsets formed can be specified as they are created.
Non-disjoint subsets are characterized by the fact that the occurrence of an object may exist in one subset as well as in another. In the above example, a customer may also be a supplier. If an occurrence can be allocated to precisely one subset only, these sets are disjoint.
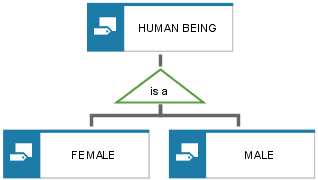
Complete specialization describes the fact that all specialized object types that meet a specific specialization criterion are listed for a generalized object type. For example, when specializing the Human being entity type the Female and Male entity types can be listed. Thus, specialization in terms of Gender is complete.
Combining these criteria results in the following four occurrences used for specifying a generalization/specialization in more detail:
disjoint/complete,
disjoint/incomplete,
non-disjoint/complete,
non-disjoint/incomplete.
Aggregation
Aggregation is the formation of new object types by combining existing object types. The new object type can be carrier of new properties.
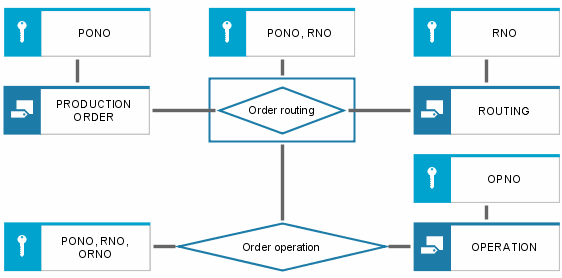
In the ERM, aggregation is expressed by the formation of relationship types (see the following figure). Aggregating the Production order and Routing entity types forms the new object Order routing.
The aggregation operator can also be applied to relationships. An existing relationship type is then treated as an entity type and can thus become the starting point for creating new relationships. An example illustrating this is shown in the following figure.
In a first aggregation step, the Order routing relationship type is formed from the Production order and Routing entity types. The production order number (PONO) and routing number (RNO) key attributes form the complex key of the order routing. Now, multiple operations can be assigned to the order routing. Therefore, the Order operation relationship is formed between the Order routing relationship type and the Operation entity type. As relationships can be created only between entity types, the original Order routing relationship type must be reinterpreted. In the following figure, this is illustrated by a framed diamond. This reinterpreted relationship type thus formed is treated as a 'normal' entity type. To graphically illustrate the formation of the relationship type, the connections of the entity types participating in that formation are drawn to the diamond. The outgoing connections of the reinterpreted relationship type that form new relationships are drawn only to the edges of the rectangle and do not touch the diamond inside the symbol.
Although, as a general rule, it is possible to replace the complex keys with simple keys, maintaining complex keys is useful in terms of tracing the data model's creation.
In an ERM, a complex structural context is split into a transparent structure. As the relation to the overall structure might become obscured, complex objects in the form of Cluster/Data models are introduced.
A Cluster/Data model is the logical view of multiple entity types and relationship types of a data model that are required for describing a complex object.
Besides entity types and relationship types, Cluster/Data models themselves can be part of a Cluster/Data model. Unlike entity and relationship types, Cluster/Data models can be arranged in any hierarchy and thus mainly supports a top-down procedure in the process of creating data models. However, forming Cluster/Data models may also be very helpful when combining and consolidating submodels during a bottom-up approach.
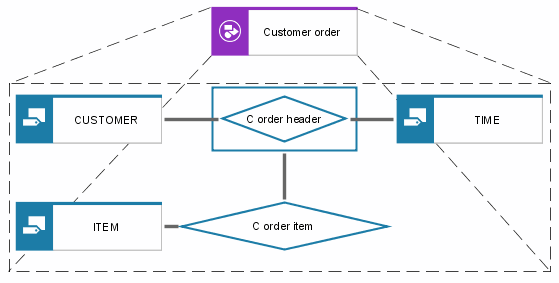
The following figure graphically displays a Cluster/Data model.
The Cluster/Data model represents a logical view of multiple entity types and relationship types. The Customer, Time, Customer order header, Item, and Customer order item entity types and relationship types are required to describe the complex Customer order object.
Grouping
Grouping forms groups from the elements of an entity set.
For example, in the following figure, all Operating resources are combined into an Operating resources group. The operating resources group is an independent object which can be described more precisely by additional attributes (name of the operating resources group, number of operating resources) not contained in the individual operating resources. Other examples are the grouping of workstations into departments or the combination of order line items into orders.